Summary
SpatialNav: Leveraging Spatial Scene Graphs for Zero-Shot Vision-and-Language Navigation
- 核心: 在零样本 VLN 中放宽 “纯在线感知” 的设定,允许 agent 先用 SLAM 预探索环境构建分层 Spatial Scene Graph (floor → room → object);再以三件套(agent-centric spatial map + compass-style 全景图 + remote object localization)让 MLLM 在每一步把全局空间结构和当前观测对齐使用
- 方法: 离线建图(DBSCAN 分层 + 几何启发式分房 + GPT-5 房间分类 + 微调 SpatialLM 物体检测);运行时把 SSG 投影成 7.68m 半径、agent-heading 朝上的 top-down map;八方向全景拼成 3×3 compass grid;为每个 navigable waypoint 检索周边物体语义注入上下文
- 结果: 用 GPT-5.1 作 backbone,在 R2R / REVERIE / VLN-CE / RxR-CE val-unseen 上 SR 分别达 57.7 / 49.6 / 64.0 / 32.4,全面超过 SpatialGPT、SmartWay、VLN-Zero 等 zero-shot baseline,且在 VLN-CE 上 SR 与 ETPNav 等监督方法接近;用 ground-truth 标注的上限版还能再涨 5–8 pt
- Sources: paper
- Rating: 2 - Frontier(重新定义 zero-shot VLN 设定 + 三件套 spatial representation 设计,在 VLN-CE 上 zero-shot SR 大幅领先且接近监督 SOTA,是当前 zero-shot VLN 前沿必读;但方法 novelty 偏组合、pre-exploration 设定 stretch、未开源,离 Foundation 还差 de facto 标准地位)
Key Takeaways:
- 重新定义 zero-shot VLN 的设定: 论文主张 “允许 pre-exploration” 是更贴合家用机器人(扫地机、家庭服务机器人)部署现实的 zero-shot 设定,而不是必须坚持 online-only。这是个 framing claim,比方法本身更值得讨论
- SSG = SLAM 点云 + 4 阶段标注: floor segmentation (height histogram + DBSCAN) → room segmentation (几何启发式 + 人工修正大于 20 m² 的区域) → room classification (GPT-5 看 RGB) → object detection (在 Matterport3D 上 fine-tune 的 SpatialLM)。这个流水线是经典的 hierarchical scene graph 套路,本身没什么新意
- Compass-style 全景表示: 把 8 个 90° FOV 视角拼成单张 1024×1024 图,中心放一个指北针图标。视觉 token 从 1700+(sequential)压到 ~640,性能仅小幅下降(SR 60.3 vs 62.5)
- Spatial map 单独已经很强: “SMap Only” baseline(只看 top-down map + 指令、不看任何视觉/文本观测)在 R2R-Val-Sampled 上 SR 已达 40.8。把 spatial map 加到 NavGPT、SmartWay 上都能涨 8–11 pt,可移植性好
- GT 上限说明 perception 仍是瓶颈: GT 标注版(SpatialNav†)在 VLN-CE 上 SR 提到 68.0(vs 64.0 自动版),说明房间分割和物体检测的质量是当前自动 pipeline 的主要瓶颈而非 reasoning
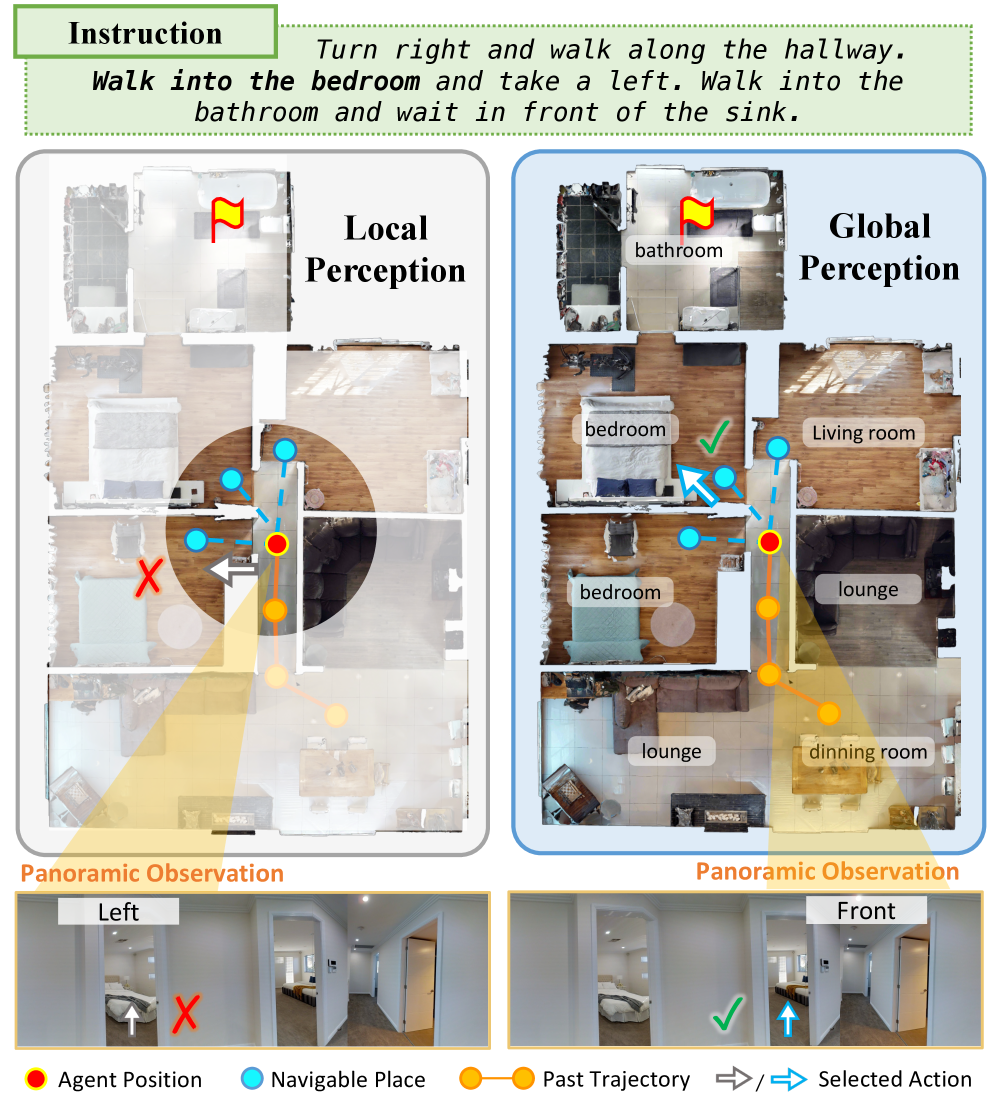
Teaser. 局部感知 vs 全局感知的 motivation 对比 —— 当指令提到 “bedroom” 而场景里有多个 bedroom 时,仅靠局部感知的 agent 会困惑;具备全局空间信息的 agent 则可以消歧。
Background & Problem Formulation
Zero-shot VLN agents(NavGPT、Open-Nav、MapGPT 等)相比监督学习的 VLN agents(DUET、HAMT、ScaleVLN)在 R2R 上有 ~20 pt 的 SR gap。论文把 gap 归因为:监督 agent 通过大规模 pre-training 隐式学到了房间布局和功能共现先验(如 “kitchen 通常连 dining area”),而 zero-shot agent 只能基于 ~3 m 半径的局部观测做决策,缺乏全局空间信息。
这个归因是合理但不充分的——zero-shot agents 还有 instruction following、multi-step reasoning 等问题,把 gap 全归到 “缺空间先验” 是简化的叙述。
新的 zero-shot 设定
论文提出一个 relaxation:允许 agent 在执行任务前对环境完全 pre-explore。理由是家用机器人通常部署在固定环境(扫地机不会今天在 A 家明天去 B 家),所以 “先建图、再执行任务” 是符合实际部署的。这个设定明显偏离原版 VLN 定义,作者也承认。
❓ 这个 relaxation 的合理性见仁见智。一方面,它确实是 deployment-friendly;另一方面,把 “可以预先获得 3D point cloud + 多次 explore” 还叫 zero-shot 有点 stretch——本质上变成了一个 “given a pre-built map, navigate by instruction” 的任务,离传统 ObjectNav with semantic map 已经很近。
Method
Spatial Scene Graph 构建
输入是 SLAM(如 SLAM3R、MASt3R-SLAM、VGGT-SLAM)重建的 3D 点云(论文实际用 Matterport3D 提供的 GT 点云),通过四阶段 pipeline 标注:
Figure 2. SSG construction 概览 —— 从 point cloud 出发,依次做 floor segmentation(按高度直方图 + DBSCAN 取峰值)、room segmentation(几何启发式 + 人工修正)、room classification(GPT-5 看图归类)、object detection(fine-tune SpatialLM 输出 3D bbox + label)。最终组织成 floor → room → object 的层次图,节点是实体,边是包含关系。
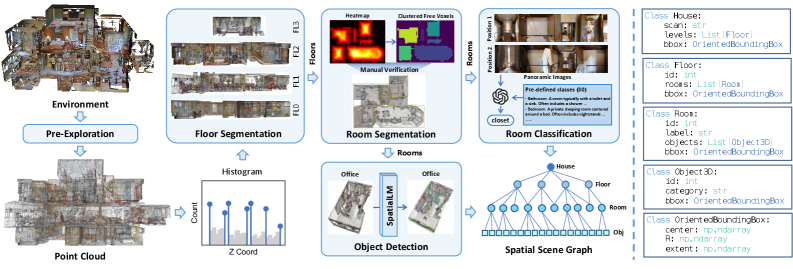
四个阶段的细节:
- Floor segmentation: 沿用 [Werby et al. ICRA-W 2024],按 z 轴坐标做高度直方图,DBSCAN 找峰
- Room segmentation: 用 Bobkov et al. 2017 的 anisotropic potential field 方法把每层切成房间。论文坦白这个方法在 open space(如开放式厨房-客厅)会失败,对面积 > 20 m² 的区域人工核验。这是 honesty 也是一个工程妥协
- Room classification: 收集 pre-exploration 阶段拍到的房间内 RGB,喂 GPT-5 按预定义房间类别分类
- Object detection: fine-tune SpatialLM(一个把点云转成 structured indoor model 的 LLM)在 Matterport3D 训练集上,输出每个物体的 3D bbox 和类别标签
⚠️ 第 2 步的 “manually verifying” 在论文里一笔带过,但这是个不可忽略的工程成本,对 “scalable / generalizable” 是个减分项。Limitations 一节也确实承认了这点。
SpatialNav agent 的三个组件
Figure 3. SpatialNav 框架 —— 在每个 step:(1) 根据当前位置查 SSG 构造 agent-centric spatial map;(2) 把 8 个方向的 panoramic observation 拼成 compass image;(3) 对每个 navigable waypoint 查 SSG 拿周围物体语义。这些与 trajectory history、instruction 一起送给 MLLM 预测下一步。
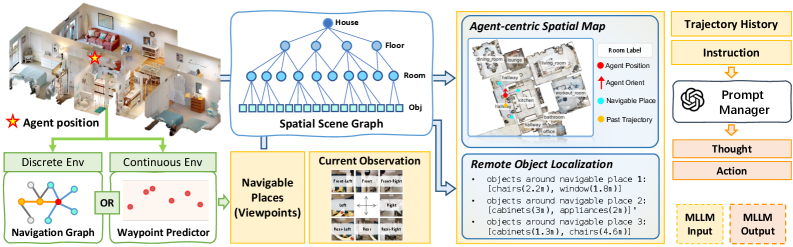
Agent-centric Spatial Map
按 agent 当前 z 坐标定层,按 x-y 定房间,然后以 agent 为中心、半径 ~7.68 m(默认)取一个圆盘内的所有 room 投影到 1024×1024 的 top-down map,agent heading 始终朝上。这个朝向对齐很关键,让 LLM 能直接用 “left / right / front” 推理而不需要做坐标变换。
这个 “head-up rotation” trick 很 simple,但确实是 LLM-friendly 的设计——避免了 LLM 在 polar / Cartesian 坐标系之间做心算。
Compass-like Visual Observation
把全景按 0°, 45°, 90°, …, 315° 切成 8 个 90° FOV 视角,每个 256×256,拼成 3×3 grid(中心放一个 compass icon 显示 agent orientation)共 1024×1024 的单张图。视觉 token 从 sequential 喂 8 张图的 ~1700 降到 ~640,是延迟和成本的实质优化。
这个表示和 “render 多视角到 collage” 的常见 trick 是一脉相承的,但显式加 compass icon 的设计配合 spatial map 的 head-up 朝向,是个细节上的 polish。
Remote Object Localization
对每个 candidate waypoint(discrete env 用 navigation graph,continuous env 用 SmartWay 的 waypoint predictor),查 SSG 拿这个 waypoint 所在房间内的 object categories + 距离,压成一段文本 “if you go to waypoint X, you will see {sofa: 1.2m, TV: 2.5m, …}” 注入 context。让 agent 能 “提前看见” 即将经过的位置有什么。
Experiments
主结果
Table 1. Discrete environment (R2R / REVERIE val-unseen) 对比 —— SpatialNav 用 GPT-5.1 backbone 在 zero-shot 组全面领先:R2R SR 57.7(vs SpatialGPT 48.4,+9.3)、REVERIE SR 49.6(vs MapGPT 31.6,+18.0)。在 REVERIE 上甚至超过监督方法 DUET(SR 47.0)。SpatialNav† (GT 标注) 微涨。
| Settings | Methods | R2R SR(↑) | R2R SPL(↑) | REVERIE SR(↑) | REVERIE SPL(↑) |
|---|---|---|---|---|---|
| Supervised | DUET | 72 | 60 | 47.0 | 33.7 |
| Supervised | DUET+ScaleVLN | 81 | 70 | 57.0 | 41.8 |
| Zero-Shot | NavGPT | 34 | 29 | 19.2 | 14.6 |
| Zero-Shot | MapGPT | 43.7 | 34.8 | 31.6 | 20.3 |
| Zero-Shot | SpatialGPT | 48.4 | 36.1 | – | – |
| Zero-Shot | SpatialNav | 57.7 | 47.8 | 49.6 | 34.6 |
| Zero-Shot | SpatialNav† (GT) | 59.3 | 48.0 | 50.4 | 33.7 |
Table 2. Continuous environment (VLN-CE / RxR-CE val-unseen) 对比 —— SpatialNav 在 VLN-CE 上 SR 64.0,比上一代 zero-shot SOTA VLN-Zero (42.4) +21.6,比监督的 ETPNav (57.0) 还高 7 pt;只输给 NavFoM、Efficient-VLN 这种最新的大模型监督方法。在 RxR-CE(多语言指令更难)上 SR 32.4 略胜 MapNav (32.6) 不到。SpatialNav† 进一步把 VLN-CE SR 推到 68.0。
| Settings | Methods | VLN-CE SR(↑) | VLN-CE SPL(↑) | RxR-CE SR(↑) | RxR-CE SPL(↑) |
|---|---|---|---|---|---|
| Supervised | ETPNav | 57.0 | 49.0 | 54.8 | 44.9 |
| Supervised | NavFoM | 61.7 | 55.3 | 64.4 | 56.2 |
| Supervised | Efficient-VLN | 64.2 | 55.9 | 67.0 | 54.3 |
| Zero-Shot | VLN-Zero | 42.4 | 26.3 | 30.8 | 19.0 |
| Zero-Shot | Smartway | 29.0 | 22.5 | – | – |
| Zero-Shot | SpatialNav | 64.0 | 51.1 | 32.4 | 24.6 |
| Zero-Shot | SpatialNav† (GT) | 68.0 | 53.4 | 39.0 | 28.4 |
RxR-CE 上的 SR 跟 VLN-CE 差距巨大(32.4 vs 64.0),说明对长指令、多语言、复杂路径的处理还远没解决。论文里没怎么讨论这个 gap,是个值得追问的弱点。
Q1: Spatial knowledge 的可移植性
Table 3. Spatial map 加到不同 baseline 上的增益 —— 仅用 spatial map(无视觉/文本 obs)在 R2R-Val-Sampled 上 SR 40.8 已经不错;NavGPT + SMap 比 NavGPT 涨 8.6(43.5 → 52.1);SmartWay + SMap 在 VLN-CE 上涨 11(51.0 → 62.0)。说明 spatial map 是个 plug-and-play 的有效增强信号。
| Method | R2R Sampled SR(↑) | R2R Sampled SPL(↑) | REVERIE Sampled SR(↑) |
|---|---|---|---|
| SMap Only | 40.8 | 31.7 | 33.2 |
| NavGPT | 43.5 | 34.7 | 31.5 |
| NavGPT + SMap | 52.1 | 42.7 | 47.4 |
| SpatialNav | 60.3 | 50.1 | 50.9 |
Figure 4. MLLM backbone 对比 —— GPT-5.1 和 Gemini-2.5-Pro 加了 spatial map 都涨;Qwen3-VL-Plus 反而略降。论文归因为 Qwen3-VL-Plus 的输出有 ~30% 的 “Thought: I have reached/moved/entered…” 重复模板,怀疑是 fine-tune 在 VLN-style 数据上导致的过拟合。
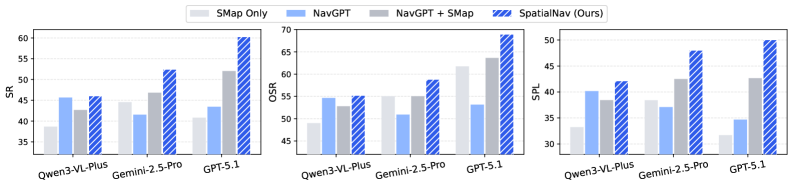
这个 “open-source 模型反而变差” 的发现挺有意思。它可能 (a) 真的是 prior fine-tuning 的问题,(b) 也可能是 prompt engineering 没适配 Qwen3-VL。论文只给了一种解释,缺少对照实验来辨析。
Q2: 组件 ablation
Table 4. 不同输入组合的影响 —— 只加 spatial map (text + SMap-G) 把 SR 从 46 推到 66;只加 remote objects (text + RemObj-G) 推到 56。但 text + SMap + RemObj 反而退到 60(GT 时只有 60,predicted 时反到 56),论文归因为 text-only panorama 描述与 retrieved object 之间存在 semantic ambiguity,干扰停止决策。换成 visual panorama (compass-style) 后这个矛盾消失:visual + SMap-G + RemObj-G 达到 SR 72。
| Pano Obs | SMap | RemObj | TL | NE(↓) | SR(↑) | OSR(↑) | SPL(↑) |
|---|---|---|---|---|---|---|---|
| text | – | – | 19.1 | 5.97 | 46 | 60 | 37.0 |
| text | G | – | 17.1 | 4.61 | 66 | 76 | 53.2 |
| text | – | G | 16.8 | 4.25 | 56 | 70 | 47.9 |
| text | G | G | 18.4 | 6.51 | 60 | 72 | 48.7 |
| text | P | P | 18.3 | 5.37 | 56 | 70 | 47.9 |
| visual | G | G | 14.9 | 4.34 | 72 | 74 | 58.8 |
| visual | P | P | 15.9 | 4.92 | 62 | 70 | 50.1 |
这个 “text + RemObj 反而变差” 的结果挺值得玩味。它实际暴露了 LLM-as-policy 路线的一个常见陷阱:注入更多文本信息不总是有益,反而可能引入噪声/歧义。Visual grounding 能缓解的 hypothesis 是合理的,但论文没给出更深入的失败案例分析。
视觉表示和 perception radius 的细 ablation
Table 5. 全景表示对比 —— 1024×1024 compass image 是性价比最高的:和 8 张 sequential 图(~1700 visual tokens)的 SR 仅差 2.2 pt(60.3 vs 62.5),但视觉 token 砍到 ~640。
| Fmt | Img | Img Size | OSR(↑) | SR(↑) | SPL(↑) |
|---|---|---|---|---|---|
| cps | 1 | 1536×1536 | 68.8 | 58.1 | 45.8 |
| cps | 1 | 1024×1024 | 68.9 | 60.3 | 50.1 |
| cps | 1 | 512×512 | 69.7 | 59.9 | 46.1 |
| seq | 8 | 256×256 | 70.0 | 62.5 | 54.6 |
Table 6. Spatial map 半径 —— 7.68 m 是甜点,3.84 m 太小(≈ 局部感知,没增量),11.52 m 太大(混入无关房间,attention 被稀释)。
| Radius | OSR(↑) | SR(↑) | SPL(↑) | nDTW(↑) |
|---|---|---|---|---|
| 11.52m | 71.5 | 56.9 | 47.0 | 58.43 |
| 7.68m | 68.9 | 60.3 | 50.1 | 59.7 |
| 3.84m | 62.2 | 50.9 | 42.9 | 55.33 |
关联工作
基于
- NavGPT:第一代 LLM-based zero-shot VLN agent,本文继承其 prompting 框架,并在 Table 3 用作 +SMap 的对照
- SpatialLM (Mao et al. 2025):把 LLM 训练成消费点云、输出 structured indoor model 的工具,本文 fine-tune 它做 SSG 的 object detection 阶段
- Hierarchical 3D scene graphs (Werby et al. ICRA-W 2024):本文 floor segmentation 直接沿用其 height-histogram + DBSCAN 的方案
- GPT-5 / GPT-5.1 (OpenAI 2025):room classification 和最终 navigation policy 的 backbone
对比
- SpatialGPT (Jiang & Wang 2025):另一篇用 spatial CoT + structured spatial memory 做 zero-shot VLN 的工作,是 R2R 上最强 zero-shot baseline。本文 SR +9.3
- VLN-Zero (Bhatt et al. 2025):同样 leverage pre-exploration 构建 symbolic scene graph,但只关注 symbolic constraint。本文在 VLN-CE 上 SR +21.6,论证 spatial layout + semantics 比纯 symbolic 更有效
- MapGPT (Chen et al. ACL 2024):用 map-guided prompting,是 R2R 上的另一个 zero-shot baseline
- Smartway (Shi et al. 2025):continuous env 上的 waypoint predictor + backtracking,本文借用了它的 waypoint predictor 模块;并在 Table 3(b) 用作 +SMap 的对照
- NaVid, MapNav, ETPNav, NavFoM, Efficient-VLN, DUET, StreamVLN:监督学习侧的 SOTA,作为 supervised group 的 reference points
方法相关
- VL-KnG (Mdfaa et al. 2025):另一种用 pre-exploration video 构建 object-centric knowledge graph 的工作,更聚焦 goal identification
- Hierarchical Open-Vocabulary 3D Scene Graphs (Werby et al.):给 spatial scene graph 提供了语义层 grounding 的范式参考
- ConceptGraphs / OpenScene 类工作(论文未直接引用):3D scene graph 的另一系,用 open-vocabulary CLIP feature 标注 node,可作为对比方向
论文点评
Strengths
- Setting 重定义有 actionable insight:明确把 “pre-exploration is acceptable” 提出来作为新的 zero-shot VLN 子设定,并匹配 home robot 的部署现实。这比纠结于 online-only 的纯净设定更接地气
- 三个组件 well-motivated 且互锁:head-up spatial map + compass-aligned panorama + remote object preview,三者从全局/当前/未来三个时间-空间尺度互补,设计逻辑清晰
- Plug-and-play 验证扎实:SMap Only、NavGPT+SMap、SmartWay+SMap 三个对照都做了,证明 spatial map 不是只对 SpatialNav 有效,是个通用增益
- Honesty about pipeline: 论文坦白 room segmentation 需要人工核验大房间、SpatialLM 检测不出小物体、GT vs predicted 还有 4-8 pt gap。这些 limitation 没被 sweep under the rug
- Token efficiency 的工程优化:compass-style image 把视觉成本降到 1/3,对实际部署是有意义的
Weaknesses
- “Zero-shot” 标签 stretch:允许 pre-exploration + GT 点云 + fine-tune SpatialLM + GPT-5 标注房间类型,已经离传统 zero-shot VLN 很远了。该和监督方法重新画 boundary,而不是仍归类在 zero-shot 组对比
- Pre-exploration 成本未量化:SLAM 重建、人工修正、SpatialLM 标注都有成本,但论文没给端到端的 wall-clock / 算力对比。“home robot 可以预先建图” 是合理论据,但成本到底是 minutes 还是 hours 该说清楚
- RxR-CE 上提升有限且未深入分析:RxR-CE SR 仅 32.4,比 VLN-CE 的 64.0 差了一倍,长指令/多语言场景里 spatial map 的优势似乎被稀释。论文回避了这个 negative signal
- MLLM backbone-agnostic 的 claim 有反例:Qwen3-VL-Plus 加 SMap 反而变差,论文给的解释(output pattern repetitive)只是 hypothesis,没做 controlled experiment 验证
- 方法 novelty 偏组合:SSG(继承 ConceptGraphs / Werby et al.)+ head-up map(导航文献的老 trick)+ collage panorama + retrieval-augmented context,没有真正新的 algorithmic contribution。Insight 主要来自 “把这些拼对了”
- No code / no project page:截至检索没找到开源代码或项目页,复现成本高
可信评估
Artifact 可获取性
- 代码: 未开源(截至 2026-04-20 未发现 GitHub repo)
- 模型权重: 不适用(方法是 prompt-based,依赖 GPT-5.1 / Gemini-2.5-Pro 等闭源 backbone)
- 训练细节: 仅高层描述(SpatialLM fine-tune 在 Matterport3D 训练 scan,超参未披露;spatial map 1024×1024、grid 0.015m、半径 7.68m 等推理超参给了)
- 数据集: 评测用 R2R、REVERIE、VLN-CE、RxR-CE,全公开;环境用 Matterport3D + Habitat,公开
Claim 可验证性
- ✅ R2R / REVERIE / VLN-CE / RxR-CE val-unseen 上的 SR 数字:标准 benchmark + 标准 split + 标准 metric,可由独立方在公开数据上复现(前提是 prompt + GPT-5.1 调用复现)
- ✅ Spatial map 加到 NavGPT / SmartWay 都能涨:消融组合 + sampled subset 数字给了,可复现
- ✅ Compass image 比 sequential 视觉 token 少 ~60%:1024×1024 vs 8×256×256 是物理事实,可验证
- ⚠️ “接近 SOTA learning-based”:在 VLN-CE 上对 ETPNav 成立,但对最新的 NavFoM、Efficient-VLN 还有 4-7 pt 差距;R2R 上对 ScaleVLN 仍差 23 pt。“narrows the gap” 比 “matches SOTA” 更准确
- ⚠️ “backbone-agnostic”:Qwen3-VL-Plus 是反例,论文用 hand-wavy 的 prior fine-tuning 解释回避,未做对照
- ⚠️ “global spatial information 是 generalizable signal”:在 VLN-CE 上很 generalizable,但 RxR-CE 上提升有限。Generalization 的边界没说清
- ❌ “zero-shot agent”:在允许 pre-exploration、依赖 GT 点云、用 fine-tuned SpatialLM 的设定下,“zero-shot” 这个标签 misleading,更像 “training-free at navigation time, but offline-prepared map”
Notes
- 关于 “zero-shot” 的语义漂移:这篇是又一个把 zero-shot 概念扩张的例子。原版 VLN zero-shot 指 “no task-specific training”,但允许 pre-exploration + 离线建图 + fine-tune SpatialLM 后,“zero-shot” 的边界越来越模糊。值得想:未来这类设定应该按 “online vs offline preparation”、“task-specific training vs generic perception fine-tuning” 等维度重新切分,而不是继续用一个二元 zero-shot/supervised 分类
- Spatial map 的设计哲学:head-up rotation + 7.68m radius + room-level granularity,这一组设计选择是 LLM-friendly 的(避免坐标变换、控制 attention budget、减少噪声)。这是 LLM-as-policy 范式下,给 LLM 喂什么样的空间表示 这个问题的一个具体答案。和我之前关注的 spatial representation 议题强相关
- 失败模式分析的缺失:Table 4 里 “text + RemObj 反而变差” 是个 high-information 的负结果,但论文没展开分析。如果有 case study 拆解 semantic ambiguity 具体长什么样,会更有教学价值
- 可能的 follow-up 方向:
- 把 SSG 喂给 supervised VLA / VLN 模型而不仅是 prompt-based,论文 Limitations 提到了,是个 open question
- SLAM 失败 / 部分观测 / 动态环境下的 robustness,论文 explicit 假设了 GT 点云
- 把 SSG 从 floor-room-object 扩展到包含 affordance、动态物体状态等,往 functional scene graph 走
- 写作 observation:论文做实验 ablation 时区分 G (ground-truth) vs P (predicted) 标注,让读者能看到 perception 瓶颈到底有多大。这是个值得借鉴的 reporting practice
Rating
Metrics (as of 2026-04-24): citation=7, influential=2 (28.6%), velocity=2.06/mo; HF upvotes=N/A; github=N/A (无代码仓库)
分数:2 - Frontier 理由:论文在 VLN-CE zero-shot 上 SR 64.0 大幅超过上一代 zero-shot SOTA VLN-Zero (42.4) 并接近监督 ETPNav (57.0),同时提出 head-up spatial map + compass panorama + remote object preview 的三件套组合,是 zero-shot VLN 方向当前必比的 baseline(Strengths 1-3)。但它不够 Foundation:方法 novelty 偏组合(SSG / head-up map / collage / retrieval 都继承前人,Weakness 5),“pre-exploration zero-shot” 设定 stretch(Weakness 1 + ❌ claim),且未开源(Weakness 6),短期内不会像 ConceptGraphs / ETPNav 那样成为 de facto 标准;也明显高于 Archived——RxR-CE 上表现弱归弱,但 R2R / REVERIE / VLN-CE 三个标准 split 上的 SR 提升足以使其进入 zero-shot VLN 文献的 must-compare 组。2026-04 复核:3.4 月 7 citation / 2 influential (28.6%) / velocity 2.06/mo,早期采纳信号相对 2601 月同批发布作品居上;但未开源削弱了 sustained adoption 的预期,维持 Frontier。