Summary
ETPNav: Evolving Topological Planning for VLN-CE
- 核心: 在 VLN-CE(连续环境)中用在线自组织 topological map + trial-and-error 避障控制器, 把导航分解为高层规划与低层控制, 一次性解决 long-range 规划与 sliding-forbidden 死锁两大痛点
- 方法: depth-only waypoint predictor 在每步生成附近候选 waypoint → 用 waypoint localization 函数把它们 self-organize 成 topo graph (visited / current / ghost nodes) → 跨模态 graph transformer (含 graph-aware self-attention) 在全图上预测长期目标 → rotate-then-forward 控制器执行, 卡死时触发 “Tryout” 旋转脱困
- 结果: VLN-CE test-unseen 55 SR / 48 SPL (比 Sim2Sim +11 SR/+11 SPL); RxR-CE test-unseen 51.21 SR / 41.30 SDTW (比 CWP-RecBERT +26.36 SR/+22.25 SDTW); 2022 RxR-Habitat Challenge 冠军
- Sources: paper | github
- Rating: 2 - Frontier(VLN-CE topological-planning 范式的代表 SOTA,RxR-CE +26 SR 是范式级跃升,被后续主要 VLN-CE 工作作为 baseline,但作为奠基性工作被 LLM-based agent 路线部分替代,停在 2 而非 3)
Key Takeaways:
- Online self-organized topo map 是 VLN-CE 长程规划的有效抽象: 比起每步只看附近 waypoint 的 local planner (Reborn / CWP), 全图 ghost-node 集合允许直接 backtrack 到过去任意位置, 显著缓解 oscillation 失败模式 (Fig. 5 定性, Tab. 7 量化 +3.29 SR)
- Waypoint predictor 应该 depth-only, 不要 RGB: 反直觉但被 ablation 证实——RGB 让 predictor 过拟合 seen 环境, depth-only 同时拿到 +1.18 %Open 和 +0.77 SR (Tab. 5). spatial accessibility 不需要 semantics
- Sliding-forbidden 是 VLN-CE 被忽略的大坑: RxR-CE 大底盘 (0.18m) + 禁止贴墙滑行, 让常用 FMM/RF 控制器频繁 deadlock (Tab. 11 中 FMM 在 RxR-CE 平均碰撞 231.62 次/episode). Tryout (7 个预设朝向逐个尝试单步 FORWARD) 几乎完全消除该 gap
- Pre-training 必不可少: MLM+SAP 联合预训练相对从零训提升 +19.80 SR. 同时用 Habitat 渲染图比 MP3D 渲染图预训练更 match 下游 (+2.68 SR), 说明常用做法 (用 MP3D 预训练 VLN-CE 模型) 存在 visual domain gap
- Global planning 要配合 graph-aware self-attention (GASA): GASA 把 all-pair shortest distance 作为 attention bias, 给 global 规划带来 +1.24 SR, 显著大于 local 的 +0.77 SR——结构先验对长程规划更关键
Teaser. ETPNav 三模块流水线: 拓扑建图 → 跨模态规划 → 低层控制
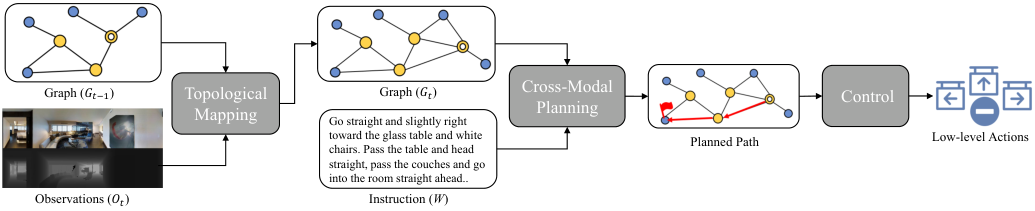
Background & Motivation
VLN (Vision-Language Navigation) 经典 setup 假设环境是离散的预定义图, agent 在固定 viewpoint 之间跳转。但真实部署中 agent 必须在 3D mesh 上以低层动作 (FORWARD 0.25m, ROTATE 15°) 移动, 所以 VLN-CE 被提出, 而其难度远高于 VLN——已发表工作的 SR 不到 VLN 的一半。
主流路线演化:
- End-to-end: 直接从语言+观察预测低层动作, 长程语言-动作 grounding 难学
- Subgoal + controller (HPN): 每步预测一个 language-conditioned waypoint 再控制到达, 但语言 grounding 与空间 accessibility 同时学很难
- Modular waypoint (CWP, Sim2Sim, Reborn): 解耦成 candidate waypoint 预测 + cross-modal 选 subgoal + controller, 是当时 SOTA
作者诊断当时 modular waypoint 路线的 3 个 drawback:
- 候选 waypoint 局限在附近, 不能捕获全局环境结构, 长程规划弱 (回退远处旧位置需要多次 plan-control 流, 误差累积)
- waypoint predictor 设计选择没研究透——RGBD 输入到底有没有用?
- controller 对障碍鲁棒性不明, sliding-forbidden 时容易死锁
❓ Drawback #1 假设了 “long-range backtracking 是常见需求”, 这在 R2R 短指令上未必, 但在 RxR 平均 120 词长指令上显然。论文用 VLN-CE Fig. 5 的 oscillation 例子论证, 不太有说服力——单个失败 case 不能反映 “global planning 必要” 的普适性。但 Tab. 7 的 +3.29 SR 是更硬的证据。
Method
Task Setup (VLN-CE)
- 仿真器: Habitat (基于 Matterport3D)
- 观察: 12 个等间隔朝向的 panoramic RGBD (每张 30°)
- 动作空间: FORWARD (0.25m), ROTATE LEFT/RIGHT (15°), STOP
- 假设可访问 ground-truth pose (与 [10,14,63] 一致, 不解决 noisy odometry 问题)
3.1 Topological Mapping
每一步在线维护 graph , 节点分三类:
- Visited node: agent 已经到过
- Current node: agent 当前位置, 持有 panoramic 平均特征
- Ghost node: 已经被预测出来但还没访问过 (来自 waypoint), 持有部分视野的特征
边权 = 两节点 Euclidean 距离。
Figure 2. Topological mapping module: waypoint prediction → waypoint localization → graph update
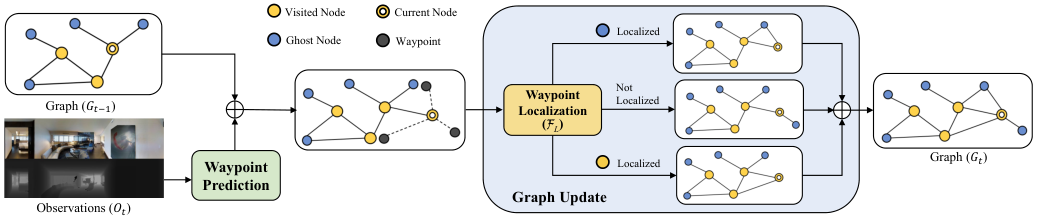
Waypoint Prediction
- 沿用 CWP 的 transformer-based 预测器: 取 depth 特征 + orientation 特征 → 2-layer transformer → MLP → 空间概率 heatmap → NMS 采样 个 waypoint
- 核心改动: 输入只用 depth, 不用 RGB——semantic 对 spatial accessibility 无用甚至有害 (overfit seen 环境)
- 预测器在 MP3D 图数据上预训练, 参数固定
Visual Representations
RGB + depth + orientation 经线性融合后送 panorama encoder (multi-layer transformer) 得到 contextual view embeddings :
- Current node = 的平均 (panoramic)
- Waypoint 由其落入的视角 embedding 表示 (例如朝向 0°-30° 的 waypoint 用 )
Graph Update via Waypoint Localization
计算 waypoint 与所有现有节点的欧氏距离, 若最近距离 < 阈值 则返回该节点。三种情况:
- 命中 visited node → 删除 waypoint, 加 current 到该 visited 的边
- 命中 ghost node → 把 waypoint 的 position/feature 累加平均到该 ghost 上 (
Acc.) - 谁也没命中 → 作为新的 ghost 加入
❓ 阈值 的选择对 graph 密度影响巨大——Tab. 6 显示 是最优, 但最优值很可能依赖 waypoint predictor 的精度, 换 predictor 就要重调。这是这个 framework 的一个隐藏脆弱点。
3.2 Cross-Modal Planning
Figure 3. 规划模块: text encoder + 跨模态 graph encoder, 输出 long-term goal 节点

Node Encoding
每个节点 visual 特征 + pose encoding (相对当前 agent 的 orientation/distance) + navigation step encoding (visited 节点用最后访问步数, ghost 用 0)。STOP 节点连接所有节点。
Cross-Modal Graph Transformer (类 LXMERT)
每层 = 双向 cross-attention + 2 self-attention + 2 FFN。关键改动是节点的 self-attention 改成 Graph-Aware Self-Attention (GASA):
其中 是由 graph 边推出的所有节点对最短距离矩阵, 作为 attention bias 注入图拓扑先验。
Long-Term Goal Prediction
每个节点过 FFN 得分 , mask 掉 visited 和 current 节点, 只在 ghost 节点和 STOP 节点中 argmax。选中 ghost 后用 Dijkstra 在 graph 上求最短路径作为 subgoal 序列 。
3.3 Control
RF (Rotate-then-Forward)
到达每个 subgoal : 算相对 → 量化成若干 ROTATE (15°) + 若干 FORWARD (0.25m) → 顺序执行。
Handling Unreachable Goal
ghost 节点位置由预测得来, 可能不在 navigation mesh 上。策略: 进入控制阶段前先把这个 ghost 从图中删除, 防止反复选择同一个不可达目标卡死, 同时也减小后续候选池, 简化策略学习。
这个 trick 虽然简单, 但是个非常聪明的 inductive bias——把 “尝试” 行为变成 “尝试 then forget”。
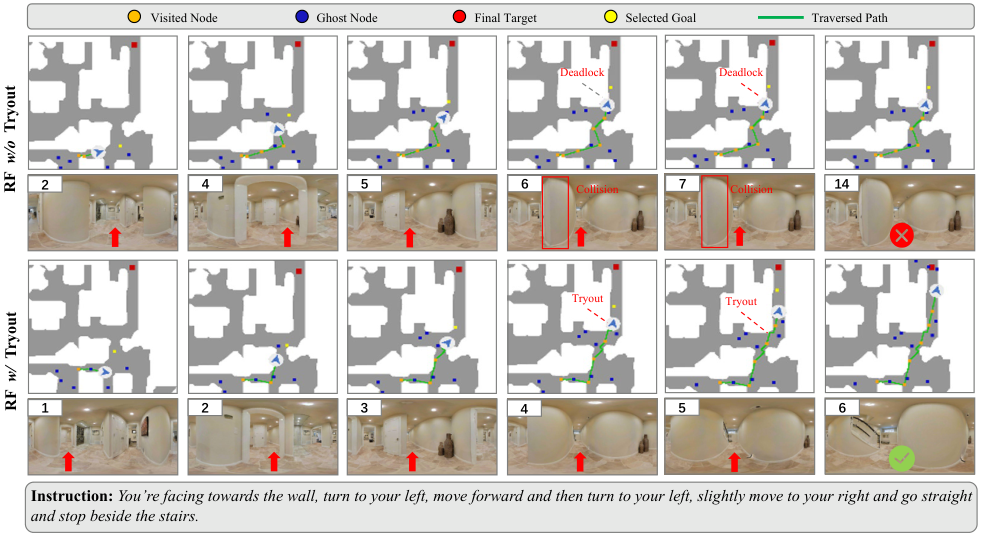
Obstacle Avoidance: Tryout
Sliding-forbidden 场景 (RxR-CE) 下, agent 撞墙后无法滑行就死锁。Tryout = 检测到 FORWARD 后位置没变 → 强制旋转一组预设角度 (7 个等间隔, ), 每次试单步 FORWARD; 如果位置变了就回到原朝向继续, 否则换下一个角度。本质类似 “brute force untrap” (Stubborn)。
3.4 Training
Pre-training (offline, 用预定义 R2R/RxR 图):
- MLM (Masked Language Modeling)
- SAP (Single Action Prediction): 给定一段 expert trajectory 子序列, 预测下一步教师 action 节点
Fine-tuning (online, Habitat):
- DAgger 风格: interactive demonstrator 给出每步教师节点
- VLN-CE: = geodesic 距离最终目标最近的 ghost
- RxR-CE: 把参考路径离散成 subgoal 序列, = 距离下一个未访问 subgoal 最近的 ghost (path-fidelity 策略)
- Scheduled sampling 从 teacher-forcing 渐进切换到 student-forcing (decay ratio 0.75 / 3000 iter)
Experiments
4.1 Datasets
| Dataset | Lang | Path Len | Sentence | Train Instr | Chassis | Sliding |
|---|---|---|---|---|---|---|
| VLN-CE | en | 9.89m | 32 词 | 10,819 | 0.10m | Allowed |
| RxR-CE | en/hi/te | 15.23m | 120 词 | 60,300 | 0.18m | Forbidden |
RxR-CE 更长更难、底盘更大、还禁滑行, 是真正考验避障的场景。
4.2 Main Results
Table 2 (VLN-CE): Val-Unseen ETPNav 57 SR / 49 SPL, 比次优 CWP-RecBERT 提高 +13 SR / +10 SPL; Test-Unseen 55/48, 比 Sim2Sim +11/+11.
Table 4 (RxR-CE): Val-Unseen 54.79 SR / 61.90 NDTW / 45.33 SDTW; Test-Unseen 51.21/54.11/41.30, 比 CWP-RecBERT 暴涨 +26.36 SR / +22.25 SDTW。
Table 3 (vs 其他 planner, 对齐控制器和视觉编码): 在同等条件下 ETPNav vs DUET +3.5 SR / +2.72 SPL, 说明 ETPNav 增益不仅来自更好的 visual encoder/controller, 而是 planner 本身。
4.3 Ablations (VLN-CE Val-Unseen)
Waypoint Predictor (Tab. 5)
| Inputs | %Open | SR | SPL | |
|---|---|---|---|---|
| RGBD | 82.87 | 1.05 | 56.44 | 48.53 |
| RGB only | 65.34 | 1.08 | 51.66 | 42.21 |
| Depth only | 84.05 | 1.04 | 57.21 | 49.15 |
depth-only 同时赢空间指标和导航指标。RGB 显著拉低 %Open——semantic 把 predictor 带偏。
Map Construction (Tab. 6)
- 太大 → 节点过少 → SR 暴跌 (Row 10-12 比 Row 1-3 跌 ~12 SR)
- 太小 → 节点过多 → 候选池大, planner 更难学
Acc.(累加 waypoint 表示 ghost) 带来 +1.32 SRDel.(删除选中的 ghost) 带来 +4.80 SR——影响最大的设计
Planning Space (Tab. 7)
| Planning | GASA | SR | SPL |
|---|---|---|---|
| Local | ✗ | 53.15 | 46.83 |
| Local | ✓ | 53.92 | 46.43 |
| Global | ✗ | 55.97 | 48.08 |
| Global | ✓ | 57.21 | 49.15 |
GASA 对 global 增益 (+1.24 SR) > local (+0.77 SR), 说明结构先验对长程规划更重要。
Pre-training (Tab. 8 & 9)
- No init: 37.41 SR
-
- MLM: 48.23 SR
-
- SAP: 52.37 SR
-
- MLM+SAP: 57.21 SR
- 用 Habitat 渲染图预训练比用 MP3D 渲染图 +2.68 SR——揭示 MP3D→Habitat 的视觉 domain gap, 当时大多数 VLN-CE 工作 (CWP, Sim2Sim, Reborn) 都用 MP3D 预训练, 这是个普适改进点
Controllers (Tab. 10 & 11)
| Controller | R2R SPL | RxR SDTW | RxR CT (碰撞次数) |
|---|---|---|---|
| Teleportation (UB) | 49.76 | 46.04 | - |
| PointGoal (DD-PPO) | 44.05 | 43.79 | 45.23 |
| FMM | 44.34 | 21.73 | 231.62 |
| FMM w/ CMap | 44.96 | 41.09 | 40.36 |
| RF w/o Tryout | 49.15 | 18.64 (差到没法看) | 70.04 |
| RF w/ Tryout | - | 45.33 | 17.22 |
关键观察: RxR-CE 上 RF 不加 Tryout 几乎崩溃 (18.64 SDTW), 加上后接近 Teleportation 上界。FMM 单靠 occupancy map 在 sliding-forbidden 下完全失效 (碰撞 231 次/episode)。Tryout 把碰撞从 70 降到 17, 简单粗暴有效。
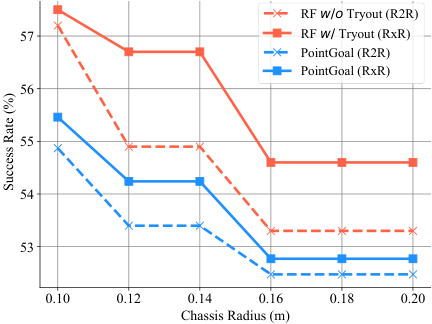
Figure 4. Chassis radius 对 SR 的影响——RF 在 RxR-CE 上对底盘大小更鲁棒
4.4 Qualitative
Figure 5. Local vs Global planning: local planner 在 step 7-15 在两个错位置之间反复横跳直到失败; global planner 在 step 4 走错后, step 8 直接 backtrack 回正轨
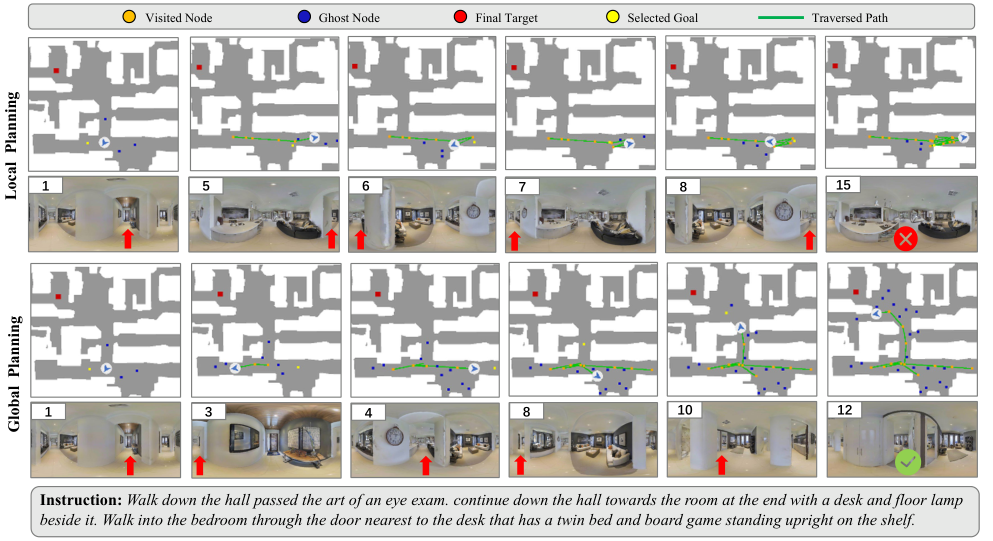
Figure 6. Tryout 效果: 不加 Tryout 时 step 6-7 撞墙后一直卡到 step 14 失败; 加了 Tryout 时 step 4 触发, 旋转脱困成功
关联工作
基于
- CWP (Hong 2022, “Bridging the Gap”): waypoint predictor 直接复用其架构和 MP3D 训练数据, ETPNav 改 depth-only
- Reborn (An 2022, RxR-Habitat Challenge 1st place): ETPNav 的前身, 用 local 规划 + 非结构化 memory; ETPNav 把 memory 升级为显式 topo graph
- HAMT (Chen 2021): cross-modal pre-training (MLM + SAP) 框架
- LXMERT (Tan 2019): cross-modal graph transformer 架构基底
对比
- HPN (Krantz 2021): 早期 waypoint-based VLN-CE
- CM2 / WS-MGMAP (Georgakis 2022, Chen 2022): metric semantic map 路线, 计算开销大
- Sim2Sim (Krantz 2022): 当时 VLN-CE SOTA, ETPNav 比它 +11 SR
- CMTP (Chen 2021): VLN-CE 离线 topo map (需要 environment pre-exploration), ETPNav 改成在线无先验
- DUET: 离散 VLN 的 dual-scale graph transformer, 被本文移植到 VLN-CE 作 baseline (Tab. 3), ETPNav 比它 +3.5 SR
- HAMT, RecBERT: 都是离散 VLN 强 baseline, 移植后被 ETPNav 超过
方法相关
- Neural Topological SLAM (Chaplot 2020): 经典在线 topo map for visual navigation, ETPNav 的 graph 结构灵感来源
- Stubborn (Luo 2022): “brute force untrap mode” 是 Tryout 的同源思想, 都是用预设动作打破 deadlock
- DD-PPO PointGoal (Wijmans 2019): 提供 depth feature 的预训练 ResNet-50, 也是 controller baseline
- CLIP ViT-B/32 (Radford 2021): RGB encoder
- DAgger (Ross 2011): student-forcing 训练框架
后续/扩展
- NaVid, LH-VLN, VLN-PE, VLN-R1, ETP-R1: 后续 VLN-CE 工作, 有的直接 build on ETPNav 的 topo map / waypoint predictor
论文点评
Strengths
- 问题诊断清晰: 把当时 modular waypoint 路线的 3 个 drawback 拆得很干净 (local 视野 / RGB 是否必要 / 控制器避障), 每个 drawback 都对应一个具体改进 + ablation 验证, 不是堆 trick
- Depth-only waypoint predictor 是反直觉的有用发现: 整个领域默认 RGBD 更好, 这篇用清晰 ablation 推翻这个 default, 而且解释合理 (semantic 让 predictor overfit seen 环境)
- Tryout 极简但有效: 7 个预设朝向 + 单步试探, 几乎不改架构, 把 RxR-CE sliding-forbidden 的 SDTW 从 18 拉到 45。“sliding-forbidden 是被忽视的关键问题” 这个 framing 本身就是贡献
- MP3D vs Habitat 预训练 gap 的揭示有普适价值, 不只服务 ETPNav, 是给整个 VLN-CE 社区的 actionable insight
- 结果暴力: VLN-CE +11 SR/SPL, RxR-CE +26 SR——这种量级的提升不是堆 trick 能堆出来的, 说明 topological global planning 抓到了真问题
- GASA 的 spatial bias 设计简洁: 把 all-pair shortest distance 作为 attention bias 加入, 是把 graph 拓扑显式编码进 transformer 的轻量做法, 有 cross-task 借鉴价值
Weaknesses
- 依赖 ground-truth pose: 假设 simulator 提供精确位姿做建图与控制, 真实部署需要 SLAM/odometry, 论文只承认这一点但没做 noise robustness 实验, 这是从 sim 到 real 的最大 gap
- 依赖预训练 waypoint predictor: 整个系统的 ghost node 质量被 CWP 的 predictor 卡住, predictor 在新场景泛化失败时整个 pipeline 失败模式不明
- Local vs Global 的定性证据较弱: Fig. 5 只是单个 cherry-picked case, 想论证 “global planning 普遍更好” 需要更系统的失败模式统计 (例如 oscillation 频率统计, NE 分布)
- Tryout 的成功部分依赖训练数据偏置: 论文自己承认 waypoint 主要落在 “straight-line accessible” 空间, 所以简单 RF + Tryout 才够用。如果 waypoint 分布更复杂 (例如真实室内带尖锐转角), Tryout 的 7 个固定朝向是否够用值得怀疑
- 没有与 LLM-based VLN-CE agent 比较 (NavGPT, NaVid 等), 当然 2023-04 时这条线还不成熟, 但作为 TPAMI 2024 终稿可以补
- 阈值的环境无关性未被检验: Tab. 6 只在 VLN-CE 上扫了 , RxR-CE (路径更长、室内布局更复杂) 是否最优 仍是 0.5 不清楚
- “我们的 topo map 与之前不同” 的新颖性 framing 略嫌过度: 在线 topo map 在 Neural Topological SLAM (Chaplot 2020) 已有, 本文真正新的是 “用预测的 waypoint 而不是观察的位置” 来 self-organize, 但 framing 写成了 mapping scheme 整体新
可信评估
Artifact 可获取性
- 代码: inference + training 全开源 (MarSaKi/ETPNav)
- 模型权重: README 提供 VLN-CE 和 RxR-CE 上的预训练 + 微调 checkpoint
- 训练细节: 完整披露 (优化器 AdamW, lr 5e-5/1e-5, batch 64/16, 2×RTX 3090, 100k pre-train + 15k fine-tune iter, scheduled sampling decay 0.75/3000 iter)
- 数据集: 开源 (VLN-CE, RxR-CE, Matterport3D, Habitat 都是公开 benchmark)
Claim 可验证性
- ✅ VLN-CE / RxR-CE 上的 SOTA 数字: 公开 benchmark + 公开代码, 可独立复现 (Tab. 2/4)
- ✅ Depth-only waypoint predictor 优于 RGBD: Tab. 5 完整 3 行 ablation, %Open / / / 导航指标四组都支持
- ✅ Tryout 在 sliding-forbidden 下消除 deadlock: Tab. 10/11 + Fig. 4 多角度证据 (SDTW, 碰撞次数, 不同 chassis radius)
- ✅ CVPR 2022 RxR-Habitat Challenge 冠军: 公开 leaderboard 可查, 但当时获奖方案是 Reborn (本文方法的前身), ETPNav 是后续改进
- ⚠️ “global planning 优于 local planning” 的普适性: Tab. 7 只在 VLN-CE 上做了对比, +3.29 SR 是 VLN-CE 数字; RxR-CE 因路径更长更应受益, 但论文没在 RxR-CE 上做 local vs global 的直接 ablation
- ⚠️ “Habitat 渲染图预训练优于 MP3D 渲染图”: Tab. 9 只有 4 行, 没扫种子, +2.68 SR 是否在统计噪声内不明
- ⚠️ 依赖 ground-truth pose: 论文承认这个限制并提议未来用 visual odometry 解决, 但没做 sim-to-real 或 noisy pose 的鲁棒性实验, 所以 “可应用于真实场景” 的隐含 claim 未被验证
Notes
- 可借鉴 idea (跨 task): GASA 的 “把 all-pair shortest distance 作为 attention bias” 是个轻量的把 graph 拓扑注入 transformer 的做法, 可借到任何 graph-on-transformer 的设置 (例如 spatial reasoning over scene graph, multi-hop QA)
- 可借鉴 trick: “选中 ghost node 后立即从 graph 删除” 这种 “尝试 then forget” 处理不可达目标的设计, 在任何 LLM agent / VLA 场景里 selecting from a candidate pool 的设计中都值得借鉴——避免反复选同一个不可行候选
- 可借鉴 finding: “用 pre-training 时尽量用与下游相同的 renderer (Habitat vs MP3D)” 这点放到 robotics 也成立——sim2real 的视觉 gap 应该在预训练阶段就缩小, 而不是只在 fine-tune 阶段缩
- Open question: ETPNav 的 ghost node 概念能否扩展到带 semantic 的 ghost (例如 “门后可能是一个房间”)? 这会把 topo map 升级为类 LLM 的 mental map, 是 LLM-based VLN agent (NavGPT) 的潜在桥梁
- Open question: Tryout 的 7 个固定朝向在更复杂的真实室内 (尖锐转角、家具拥挤) 是否够? 是否应该 learning-based 替换? 但 learning-based 又破坏了 “simple, scalable” 的优点——这是 simple-vs-learned 的经典张力
- 方向相关性: 与我的 spatial intelligence / VLN 方向直接相关, 是 VLN-CE 必引的 baseline
Rating
Metrics (as of 2026-04-24): citation=184, influential=26 (14.1%), velocity=5.03/mo; HF upvotes=N/A; github 447⭐ / forks=37 / 90d commits=0 / pushed 383d ago · stale
分数:2 - Frontier
理由:VLN-CE topological-planning 路线的代表 SOTA——RxR-CE +26 SR / +22 SDTW 是范式级跃升 (Strengths #5),online topo map + depth-only waypoint predictor + Tryout 三件套被后续主要 VLN-CE 工作 (NaVid、LH-VLN、VLN-PE、VLN-R1) 作为 baseline 或直接复用其 waypoint predictor,2025 年 OVLMap (RAL)、CityNavAgent (ACL) 等 follow-up 仍将其列为核心对照。不给到 3 是因为:方法本身正被 LLM-based / video-LLM navigation agent 路线部分替代,topological map 的显式图结构对新范式而言更多是 “参考设计” 而非必须奠基;且 VLN-CE / RxR-CE 才是 de facto benchmark,ETPNav 是该 benchmark 上的代表性方法而非 benchmark 本身。