Summary
VLN-R1: Vision-Language Navigation via Reinforcement Fine-Tuning
- 核心: 把 VLN-CE(连续环境 Vision-Language Navigation)当作 LVLM 的下游任务,纯 ego-RGB 视频流 → 离散原子动作序列,用 SFT + GRPO-RFT 两阶段训练。
- 方法: Qwen2-VL backbone;Long-Short Memory 帧采样;预测未来 6 步动作;RFT 阶段用 Time-Decayed Reward(指数衰减加权多步动作正确性)作为 verifiable reward。
- 结果: VLN-CE R2R Val-Unseen SR 30.2%(7B),仅用 RGB 超过用 map+depth+odom 的 task-specific baselines;RFT 让 2B 追上 7B 的 SFT 水平;R2R→RxR 跨域只用 10K 样本就能超过完整数据训练的版本。
- Sources: paper | website | github
- Rating: 2 - Frontier(把 RLVR/GRPO 干净落到 VLN-CE 的代表工作,reward 设计 ablation 是同类研究的有用参考,但方法仍是离散动作 + shallow reward,非奠基性)
Key Takeaways:
- VLN 作为 LVLM downstream: 把 navigation 完全 reduce 成 next-token prediction(动作选项 + 描述文本),无需 waypoint predictor、depth、map 等专用模块。
- GRPO + Time-Decayed Reward 是关键: 相比 hard reward / uniform reward,TDR 对未来 6 步动作做 γ^k 指数衰减加权,把 R2R SR 从 23.8 → 30.2。这是把 RLVR 范式落到 sequential decision-making 的一个具体配方。
- RFT 的 small-model lift: 2B-RFT (25.6 SR) > 7B-SFT (24.9 SR),复刻 DeepSeek-R1 的 “RL 让小模型追上大模型 SFT” 现象。
- 极小数据跨域迁移: R2R 上 SFT 后,仅用 10K RxR 样本 RFT,就超过 1.2M RxR 完整训练。说明 RFT 的样本效率远高于 SFT。
Teaser. VLN-R1 vs 既往 LLM-based VLN. 第一/二象限是基于离散 topological graph + 第三人称视角做 path planning 的方案;VLN-R1(第三象限)直接吃第一人称视频流、在连续环境里输出原子动作。

1. 问题定义与动机
VLN 任务:agent 收到自然语言指令(如 “Walk past the kitchen table, turn left into the hallway, and stop at the bedroom door.“),在 3D 环境中导航到目标。主流路线两条:
- 离散图(discrete VLN):在预定义的 navigation graph 节点之间 teleport,泛化到 unseen / continuous 环境差。
- VLN-CE:连续环境,输出 low-level motor commands。但既有方法依赖 depth、global map、CLIP 等专用模块,pipeline 复杂。
LLM/LVLM 方案(NavGPT、MapGPT、NaVid、Uni-NaVid 等)虽引入了语言模型,但要么停留在离散图、要么依赖额外 modular vision pipeline。VLN-R1 主张:egocentric video → action 端到端,single LVLM 全包。
❓ “End-to-end” 在这里其实仍然是 video-in / discrete-action-token-out,没有处理低层连续控制(速度、扭矩等),所以 “VLN-CE” 中 “C” 主要体现在环境是连续的而非 graph,actions 仍是固定的 4 选 1(FORWARD / TURN-LEFT / TURN-RIGHT / STOP)+ 固定步长/角度,作者也在 limitation 中承认这点。
2. 数据:VLN-Ego
基于 Habitat 仿真器 + Matterport3D 场景(90 scenes:61 train / 11 val-seen / 18 val-unseen)。沿用 R2R(7,189 paths)和 RxR-English(42,023 trajectories)轨迹。
Annotation 三段式(Figure 2):
- Instruction Part:
<System Message>+<Instruction> - Vision Part:
<History Memory>(历史帧)+<Current Observation>(当前帧) - Action Part:
<Action Choices>,4 选 1 字母选项 A/B/C/D 对应 {FORWARD, TURN-LEFT, TURN-RIGHT, STOP}
Ground truth 是未来 6 个 actions(不是单步),让模型预测一段 action chunk。最终 R2R 630K + RxR 1.2M = 1.83M 训练样本。
Figure 2. VLN-Ego 数据引擎. 展示三段式 annotation 结构。

3. 方法
3.1 Architecture & Long-Short Memory Sampling
backbone 是 Qwen2-VL(2B / 7B 都试)。视频帧分两组采样:
短期密集采样近 M 帧(保证当前 context 精度),远端稀疏采样(保留长程上下文)。对照 ablation:average sampling 与 exponential decay 都不如此设计。
Figure 3. VLN-R1 模型架构. Long-Short Memory 处理视觉输入;SFT 仅监督文本输出,RFT 阶段用 Time-Decayed Reward 监督。

3.2 Stage 1: SFT
模型输出文本形如 (α_{t+k}, φ(α_{t+k})),其中 α 是动作字母(A/B/C/D),φ 是它对应的自然语言描述(如 “Turn right 30 degrees”)。loss 是标准 cross-entropy:
模型同时学习选项识别符(离散符号)和动作描述(语言)。
3.3 Stage 2: RFT with Time-Decayed Reward
RFT 用 GRPO(DeepSeek-R1-Zero 路线)。reward 设计是关键:
符号说明:γ ∈ (0,1) 是衰减系数,α* 是 ground-truth action,I 是 indicator。含义:未来 n 步动作分别给 reward,距离当前越近权重越高。比 hard reward(只看整段是否完全正确)和 uniform(所有步同权)都精细。
GRPO 标准做法:每个 prompt 采 G 条响应,组内 reward 标准化得 advantage:
KL penalty 约束策略不偏离 reference 模型太远。
❓ TDR 仍然是逐步 binary correctness 的加权和,没考虑 action sequence 的可达性 / 物理一致性(例如连续两个 STOP 也会拿到 reward)。这是个比 hard reward 更细但仍很 shallow 的 dense reward。
4. 实验
4.1 Setup
- SFT:1.8M 样本(R2R+RxR),lr=5e-6,cosine + 10% warmup,global bs=64,1 epoch ≈ 36h(7B on 8×A800)。
- RFT:每 dataset 随机 10K,lr=1e-6,β=0.04,GRPO G=8,bs=1,~12h/epoch。
- Eval on Val-Unseen 18 scenes, 指标 SR / OS / SPL / NE / TL(VLN-CE 标准)。
4.2 R2R Val-Unseen 主结果
Table 1. VLN-CE R2R Val-Unseen comparison. Task-specific 方法用 map/depth/odom 多模态输入;VLN-R1 仅用 RGB。
| Method | Map | Odom. | Depth | RGB | SR ↑ | OS ↑ | SPL ↑ | NE ↓ | TL |
|---|---|---|---|---|---|---|---|---|---|
| AG-CMTP | ✓ | ✓ | ✓ | 23.1 | 39.2 | 19.1 | 7.90 | – | |
| R2R-CMTP | ✓ | ✓ | ✓ | 26.4 | 38.0 | 22.7 | 7.90 | – | |
| VLN (SFT, Qwen2-VL-2B) | ✓ | 21.2 | 33.0 | 15.9 | 8.27 | 11.9 | |||
| VLN (SFT, Qwen2-VL-7B) | ✓ | 24.9 | 37.1 | 17.5 | 7.92 | 15.0 | |||
| VLN-R1 (Qwen2-VL-2B) | ✓ | 25.6 | 37.5 | 20.5 | 10.2 | 16.8 | |||
| VLN-R1 (Qwen2-VL-7B) | ✓ | 30.2 | 41.2 | 21.8 | 7.0 | 10.0 |
观察:(1) 仅用 RGB 即超过用 4 模态的 task-specific 方法;(2) RFT 对 2B 提升最显著(21.2→25.6,+4.4),让 2B-RFT > 7B-SFT。
4.3 RxR Val-Unseen + 跨域
Table 2. VLN-CE RxR Val-Unseen comparison. ‡ = SFT 仅在 R2R 训练,RFT 引入 RxR;S.RGB = single RGB stream。
| Method | Odom. | Depth | S.RGB | SR ↑ | OS ↑ | SPL ↑ | NE ↓ | TL |
|---|---|---|---|---|---|---|---|---|
| LAW* | ✓ | ✓ | ✓ | 8.0 | 21.0 | 8.0 | 10.9 | 4.0 |
| CM2* | ✓ | ✓ | ✓ | 14.4 | 25.3 | 9.2 | 9.0 | 12.3 |
| WS-MGMap* | ✓ | ✓ | ✓ | 15.0 | 29.8 | 12.1 | 9.8 | 10.8 |
| Seq2Seq* | ✓ | ✓ | 3.51 | 5.02 | 3.4 | 11.8 | 1.2 | |
| CMA* | ✓ | ✓ | 4.41 | 10.7 | 2.5 | 11.7 | 5.1 | |
| A² Nav† | ✓ | 16.8 | – | 6.3 | – | – | ||
| VLN (SFT, Qwen2-VL-2B)* | ✓ | 14.1 | 22.3 | 11.2 | 9.8 | 13.5 | ||
| VLN (SFT, Qwen2-VL-7B)* | ✓ | 14.9 | 23.0 | 11.9 | 10.8 | 11.9 | ||
| VLN-R1 (Qwen2-VL-2B) ‡ | ✓ | 20.7 | 30.1 | 16.9 | 10.2 | 12.6 | ||
| VLN-R1 (Qwen2-VL-7B) ‡ | ✓ | 22.7 | 30.4 | 17.6 | 9.1 | 12.4 | ||
| VLN (Qwen2-VL-2B) | ✓ | 18.7 | 27.4 | 16.2 | 11.2 | 18.4 | ||
| VLN (Qwen2-VL-7B) | ✓ | 19.5 | 27.5 | 16.7 | 10.6 | 15.3 | ||
| VLN-R1 (Qwen2-VL-2B) | ✓ | 21.4 | 30.6 | 15.5 | 10.2 | 15.6 | ||
| VLN-R1 (Qwen2-VL-7B) | ✓ | 22.3 | 33.4 | 17.5 | 10.4 | 15.3 |
Key finding:第 9-10 行(‡,仅用 R2R SFT + 10K RxR RFT 的 7B 拿到 22.7 SR)反而 ≥ 最后一行(R2R+RxR 全量 SFT+RFT 的 7B 22.3 SR)。说明 RFT 对 cross-domain transfer 极度高效——一旦 base 训过,少量 RFT 数据就能桥接到新 domain。
4.4 Ablations(Qwen2-VL-7B, R2R only)
(a) Action Space:6-discrete-action set 最优(24.9 SR),单步预测最差(15.1)。说明预测 action chunk 比 single step 重要。
| Action Space Variant | SR ↑ | OS ↑ |
|---|---|---|
| Single Discrete Action | 15.1 | 33.6 |
| 4-Discrete-Action Set | 21.4 | 29.6 |
| 6-Discrete-Action Set | 24.9 | 31.7 |
| 8-Discrete-Action Set | 22.7 | 30.4 |
(b) History Memory:Long-Short 最优(24.9)。
| History Memory Method | SR ↑ | OS ↑ |
|---|---|---|
| Average Sampling (8) | 20.8 | 28.9 |
| Average Sampling (16) | 22.0 | 31.3 |
| Exponential Decay | 23.8 | 34.3 |
| Long Short Memory | 24.9 | 31.7 |
(c) RFT Generations:k=8 收敛(30.2),k=2 几乎无效(24.7,接近 SFT 基线)。
| RFT Generations | SR ↑ | OS ↑ |
|---|---|---|
| k = 2 (warm start) | 24.7 | 32.5 |
| k = 4 | 26.5 | 35.4 |
| k = 6 | 28.4 | 37.2 |
| k = 8 (convergence) | 30.2 | 41.2 |
(d) Reward Function:Exponential Decay 显著优于 hard / uniform / linear。
| Reward Type | SR ↑ | OS ↑ |
|---|---|---|
| Hard Reward | 23.8 | 32.3 |
| Uniform (all actions equal) | 25.0 | 33.0 |
| Linear Distance-weighting | 28.3 | 33.6 |
| Exponential Decay (TDR) | 30.2 | 41.2 |
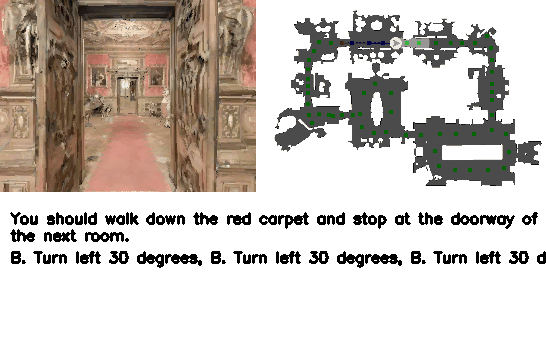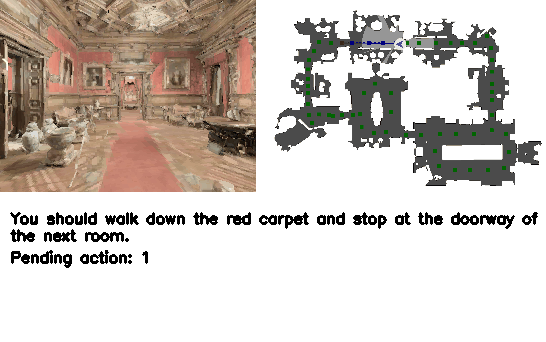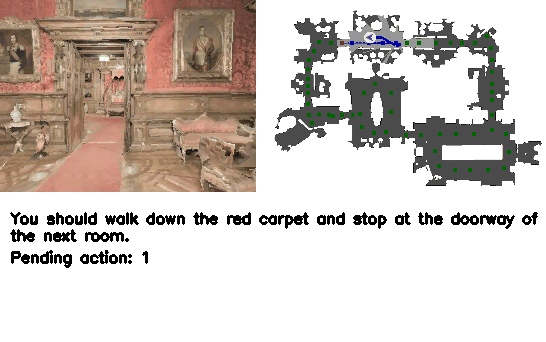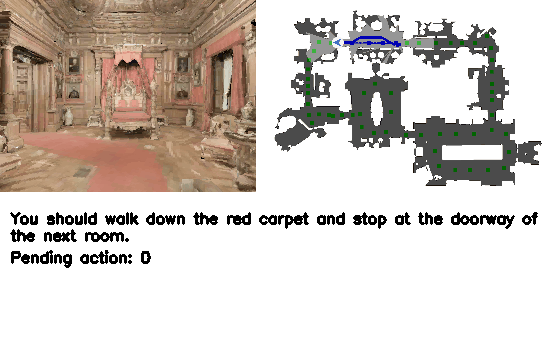
Figure 4. Qualitative results. VLN-R1 接受 ego 视频输入,在连续环境内导航至目标。

4.5 Demos(来自 project page)


关联工作
基于
- DeepSeek-R1 / GRPO: RLVR + group-relative policy optimization 是 VLN-R1 的核心 RL 框架。
- Qwen2-VL: backbone LVLM,支持 ego video 输入。
- VLN-CE / Habitat / Matterport3D: benchmark + simulator + scene dataset。
对比
- NaVid: 同样 video-based VLM 做 VLN,但用 SFT-only + 模块化 vision pipeline。VLN-R1 主要差异是 RFT 和纯端到端。
- Uni-NaVid: video-based VLA 统一多个 embodied navigation 任务,复杂的多任务统一架构。
- NaVILA: 类似 video-LLM for VLN 路线。
- VLNav、StreamVLN、VLN-PE、LH-VLN: 同期 / 后继 VLN 工作,可作为 follow-up 对比。
- NavGPT / MapGPT / InstructNav: 把 LLM 当 planner,操作离散 graph。VLN-R1 反对这条路线。
方法相关
- RLVR (Reinforcement Learning with Verifiable Rewards): math、code 任务上的 RL post-training 范式,VLN-R1 把它扩展到 sequential embodied decision。
- Action chunking: 预测未来 n 步动作(这里 n=6),与 VLA 中的 action chunking(如 ACT、Diffusion Policy)思想相通,但实现是 token-level autoregressive。
- Robot-R1、Embodied-R1、ETP-R1: 同期把 R1-style RFT 用到 robotics / embodied 任务的工作群,可横向对比 reward 设计。
论文点评
Strengths
- 配方落地清晰:把 RLVR (DeepSeek-R1) 范式干净地搬到 VLN——动作正确性天然就是 verifiable reward。这给 “embodied task as LVLM downstream” 提供了一个具体可复现的模板。
- Ablation 说服力强:reward 类型 ablation(hard 23.8 → TDR 30.2,+6.4 SR)证明 dense temporal reward 不只是边角调优,而是 RFT 在 sequential decision 任务上 work 的必要条件。
- Cross-domain transfer 数字漂亮:R2R-pretrained + 10K RxR RFT 反超 1.2M 全量 SFT+RFT,是 RFT 样本效率的强证据,符合 RLVR 文献中的同类观察。
- 纯 RGB 输入:放弃 depth/map/odom 多模态拐杖,把模型架构简化到 Qwen2-VL + 文本 I/O,generalize 路线干净。
Weaknesses
- “Continuous environment” 名不副实:动作空间仍是 4 选 1 离散原子(固定步长/角度),只是环境(不是 nav-graph)连续。作者自己承认。这不是真正的低层 motor control。
- Reward 仍 shallow:TDR 仍只是逐步 binary 正确性的加权和,没考虑 action 物理可行性(连续 STOP 也得 reward)、轨迹效率(SPL 不直接进 reward)。指标上 SR 高但 NE 反而比 SFT 差(10.2 > 8.27)、TL 也更长(16.8 > 11.9),说明 RFT 在追 “对的最后一步” 而牺牲了 path quality——这与作者只奖励 action correctness 一致。
- Sim-only:评测全在 Habitat / Matterport3D 仿真。real-world transfer、动态障碍、视觉域差距都没碰。
- Baseline 对比不完全公平:与 task-specific 方法比时强调 “我只用 RGB”,但这些方法本身也是在不同输入约束下设计的;与其他 LVLM-based VLN(如 NaVid、Uni-NaVid)的直接 head-to-head 数字在 R2R 表里没有列全(NaVid、Uni-NaVid 的 SR 应当 >30,作者没正面对比)。
- Train cost 未充分披露:只报 SFT 36h × 1 epoch、RFT 12h × 1 epoch on 8×A800,但 RFT 训了几 epoch 没说;total compute 估算困难。
可信评估
Artifact 可获取性
- 代码: 部分开源——README 显示 GPT4Scene 已发布,VLN-R1 SFT 部分计划合并进 GPT4Scene,但 RFT/GRPO 训练代码状态不清晰。
- 模型权重: 未在 README 中明确发布 VLN-R1 checkpoint(截至抓取时)。
- 训练细节: 超参与高层配置披露(lr / β / G / batch size / 训练时长),但 RFT 总 epoch 数、reward γ 具体值未明示。
- 数据集: VLN-Ego 已在 HuggingFace 发布(
alexzyqi/VLN-Ego,per project page)。
Claim 可验证性
- ✅ VLN-CE R2R/RxR Val-Unseen 数字:表格完整,metric 标准(SR/OS/SPL/NE/TL),可在公开 split 复现。
- ✅ 2B-RFT > 7B-SFT:表 1 直接呈现,符合 DeepSeek-R1 在其他任务上的同类报告。
- ⚠️ “Strong performance / SOTA on VLN-CE”:与 task-specific 多模态方法比的确强,但与同样 LVLM-based 的 NaVid / Uni-NaVid 没在主表里 head-to-head(这两者在 R2R Val-Unseen 上 SR 接近或超过 30),所以 “SOTA” 措辞偏 marketing。
- ⚠️ “Cross-domain RFT 用 10K 数据反超全量”:表 2 第 9-10 行 vs 13-14 行支持此说,但全量训练版本可能未充分调参(同样的 lr/β/G 不一定对全量最优),样本规模差距 100× 下结论需谨慎。
- ⚠️ NE 与 TL 退化的解释缺失:RFT 让 SR 涨但 NE 反而恶化,论文没讨论 path quality vs success 的 trade-off。
Notes
- Pattern:R1 范式向 embodied 扩散。2025 年中起,多个工作(Robot-R1、Embodied-R1、本文 VLN-R1)都在尝试把 GRPO + verifiable reward 套到机器人/导航。共性是任务必须有”客观正确性”信号——VLN 是 action 是否匹配 expert demonstration,manipulation 可以是 task success。值得关注的是各家的 reward shape 设计(hard vs decayed vs sparse-success)哪个 generalize 得好。
- TDR 的本质:γ^k 加权多步 binary correctness,等价于把 BC loss 的 token-level CE 换成 step-level 0/1 reward + GRPO baseline normalization。这与 BC + auxiliary RL fine-tune(如 RT-2 后继工作中常见的做法)很像,但 GRPO 不需要 critic,工程上更轻。
- 遗憾:没做 reward shape 与 path-quality(SPL/NE/TL)的联合分析。如果在 reward 中加入 SPL term,是否能避免 NE 退化?
- 应用启发:对我自己感兴趣的 GUI agent / Computer-use 方向,“action chunk + verifiable reward + GRPO” 的配方理论上完全可移植——GUI 任务的 action correctness 也是 verifiable 的(点击是否落到对的元素)。VLN-R1 的 ablation(特别是 reward type 那张表)可以直接借鉴作为设计起点。
- Open question:本工作没碰真实机器人,但 4 选 1 的离散动作 + 固定步长在真实场景几乎不可用。下一步如果要把 RFT 推到 continuous control(速度、扭矩),verifiable reward 怎么定义?这是 VLA 领域目前最 open 的问题之一。
Rating
Metrics (as of 2026-04-24): citation=50, influential=3 (6.0%), velocity=4.95/mo; HF upvotes=N/A; github 517⭐ / forks=21 / 90d commits=1 / pushed 53d ago
分数:2 - Frontier 理由:方法层面是把 RLVR/GRPO 范式干净搬到 VLN-CE 的代表工作之一,reward-shape ablation(hard 23.8 → TDR 30.2)对后续”R1 范式 + embodied”的 reward 设计有直接参考价值,符合 Frontier 档”方法范式的代表工作 / 必要 baseline”的定性。够不上 Foundation 档,因为动作空间仍是离散 4 选 1、reward 仍是 shallow binary,没有定义新 benchmark 也未成为 VLN 必引的奠基工作;也不是 Archived,因为它是 2025 年中 R1-embodied 扩散群里首个 VLN-CE 落地的具体配方,仍在被同期 Robot-R1 / Embodied-R1 横向引用。