Summary
StreamVLN: Streaming Vision-and-Language Navigation via SlowFast Context Modeling
- 核心: 把 VLN-CE 建模为基于 Video-LLM 的流式 multi-turn dialogue,用 slow-fast 上下文(sliding-window KV cache + voxel-pruned long memory)解决 Video-LLM 在 VLN 中长上下文与低延迟的矛盾。
- 方法: 基于 LLaVA-Video-7B (Qwen2-7B);fast 端保留 N=8 dialogue 的滑动窗 KV,slow 端把 inactive 窗的 visual tokens 反投到 3D voxel 后做空间剪枝;co-training 包含 690K 导航数据 + 478K 通用 VL 数据。
- 结果: VLN-CE Val-Unseen RGB-only SOTA:R2R 56.9% SR / 51.9% SPL,RxR 52.9% SR / 46.0% SPL;ScanQA 上超过 NaVILA;4090 上 0.27s/4 actions,已部署到 Unitree Go2。
- Sources: paper | website | github
- Rating: 2 - Frontier(RGB-only VLN-CE 当前 SOTA,streaming + KV cache reuse 是可复用的 Video-LLM agent design pattern,但尚未定型为 foundational)
Key Takeaways:
- VLN 作为 streaming multi-turn dialogue: 之前 Video-LLM-based VLN 每一步都重置上下文重新 prefill,浪费 ≥99% 计算。StreamVLN 把每个 episode 看作一段持续 dialogue,用 KV cache 跨 turn 复用。
- Slow-Fast 解耦带宽与精度: fast 窗口(最近 N 个 dialogue)保留高分辨率 token 用于即时决策,slow memory 通过 voxel-based 空间剪枝压缩长程历史,避免 feature-level pooling 破坏 KV cache 复用。
- Voxel pruning 既减token又涨点: 把 2D patch 反投到 3D voxel,同 voxel 跨帧只留最新 token,平均省 ~20% token,同时 R2R/RxR SR 仍涨 ~1%——说明 spatial redundancy 不仅是 efficiency 问题,也是 noise。
- Data recipe 决定上限: ablation 显示 DAgger(+5.5 SR)、RxR co-train(+7.8 SR)、ScaleVLN 子集(+2.9 SR)、MMC4 interleaved(+2.0 SR)逐项可加,多模态通用数据对 zero-shot 指令泛化有显著帮助。
Teaser. StreamVLN 整体框架——流式视频输入 + 多轮对话生成动作;fast 滑动窗保即时性,slow memory 保长程推理。
1. Motivation
VLN-CE(Vision-and-Language Navigation in Continuous Environments)下,agent 必须从连续 RGB 流生成低层 action。把 Video-LLM 用作 VLA backbone 有两条已知路径,都不令人满意:
- Fixed-frame sampling(如 NaVILA):每步采固定 16 帧重新 prefill,时间分辨率受限,难以预测细粒度低层动作;且每步 refresh 整段 dialogue 浪费算力。
- Token compression(pooling / token merging):把视觉 token 压成稀疏 memory tokens,控住 token 数量但牺牲时空细节;同时压缩破坏了跨 turn 的 KV cache 复用。
StreamVLN 的核心 thesis:把 episode 建模成持续 multi-turn dialogue,用 fast-streaming dialogue context (sliding window KV) + slow-updating memory context (voxel pruning) 同时解决长上下文管理与低延迟。
2. Method
整体基于 LLaVA-Video-7B(Qwen2-7B 作为 LLM backbone),扩展为 interleaved vision-language-action 模型。
Figure 1. StreamVLN 框架。语言指令 + RGB 流作为输入;每个 episode 是 multi-turn dialogue;用固定大小滑动窗保留近期 dialogue,inactive 窗的上下文经 token pruning 进入 long memory。
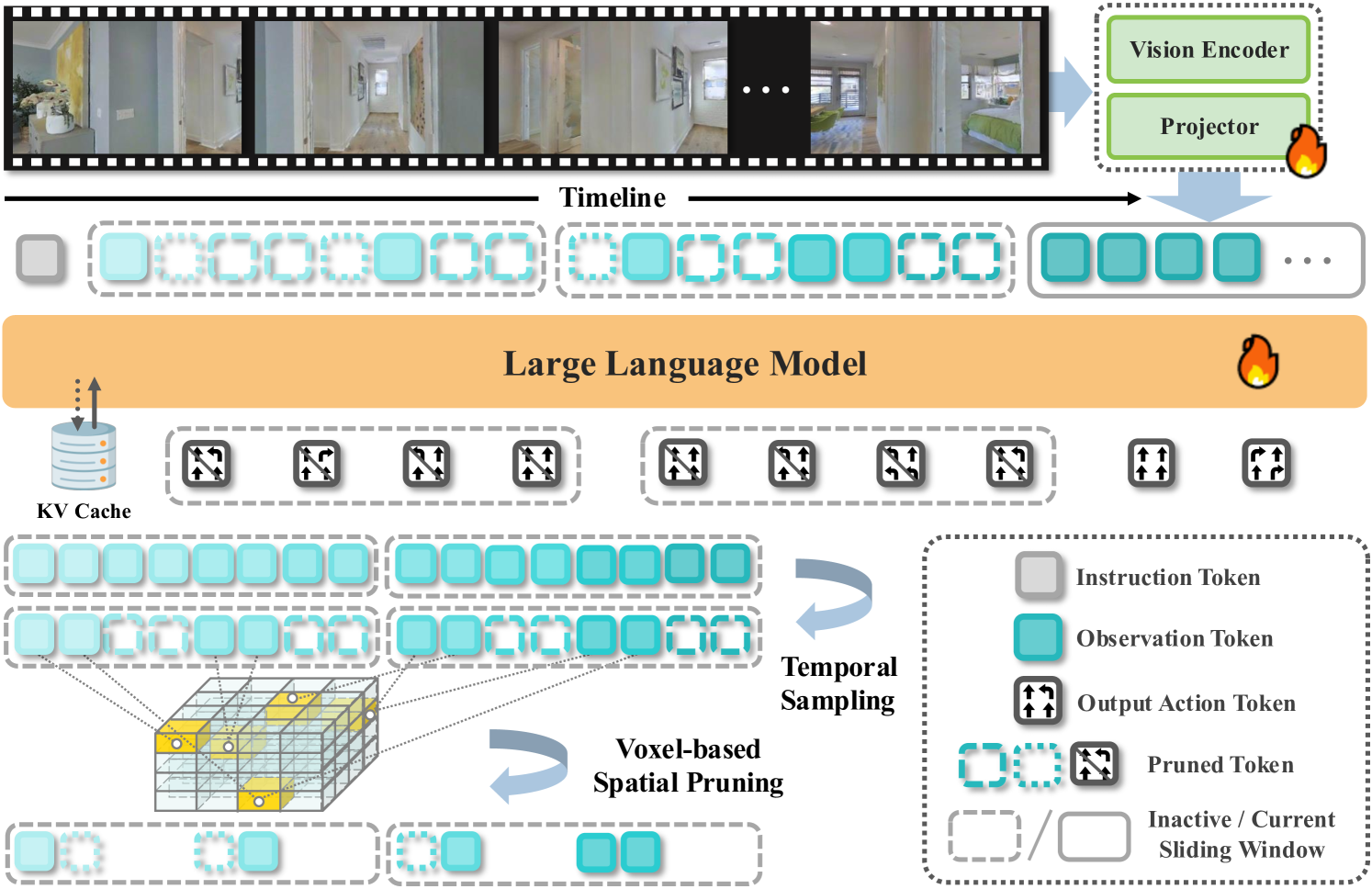
2.1 Continuous Multi-Turn Autoregressive Generation
每个 dialogue turn ,输入序列 ,模型在 prefill 阶段缓存 KV,decode 阶段按 token 自回归生成 action。如果不复用 KV,每个 turn 都要把全历史重 prefill 一遍——作者说这块复用消除了超过 99% 的 prefill 时间。
2.2 Fast-Streaming Dialogue Context(Section 3.2)
朴素的全 KV 复用会让显存线性涨(2K tokens ≈ 5GB),且 Video-LLM 在过长上下文下推理质量下降。StreamVLN 用固定大小 的滑动窗:
窗口满后,KV 从 LLM 卸载;非观测的 dialogue tokens(prompt、生成的 action)直接丢弃;观测部分进入 slow memory pipeline。新窗口的解码:
实现上 dialogues,每个 dialogue 含 4 个 action token,所以一个窗口跨 32 个低层动作。
2.3 Slow-Updating Memory Context(Section 3.3)
关键设计选择:不在 feature 层做 pooling——pooling 会改变之前的 token,破坏 KV cache 一致性,无法复用。改为保持图像高分辨率,丢弃冗余 token。
Voxel-Based Spatial Pruning(Algorithm 1):
- 用深度信息把 2D patch token 反投到共享 3D 空间
- 把 3D 空间离散成均匀 voxel,跟踪每个 patch token 的 voxel index
- 在一段时间内多个 token 落到同一 voxel 时,只保留最近一帧的 token
- 沿时间维同时做 fixed-number 采样以控温度冗余
具体:voxel map ,stride ,threshold ;对每个 token 计算 , ;维护一个 latest[(p, v)] = (t, x, y) 字典。最后若某帧保留率不足 则整帧置 0。
❓ Algorithm 1 中 “如果某帧保留 token 数 < θ·H·W 就整帧丢” 是个 hack——是说稀疏帧的剩余 token 信息密度太低不如全弃?这个 threshold 没在文中给具体值,估计在附录。
2.4 Co-Training Data Recipe(Section 3.4)
Figure 2. StreamVLN 数据配方。导航专家数据 + DAgger 纠错数据 + 通用 VL 数据三路 co-train。
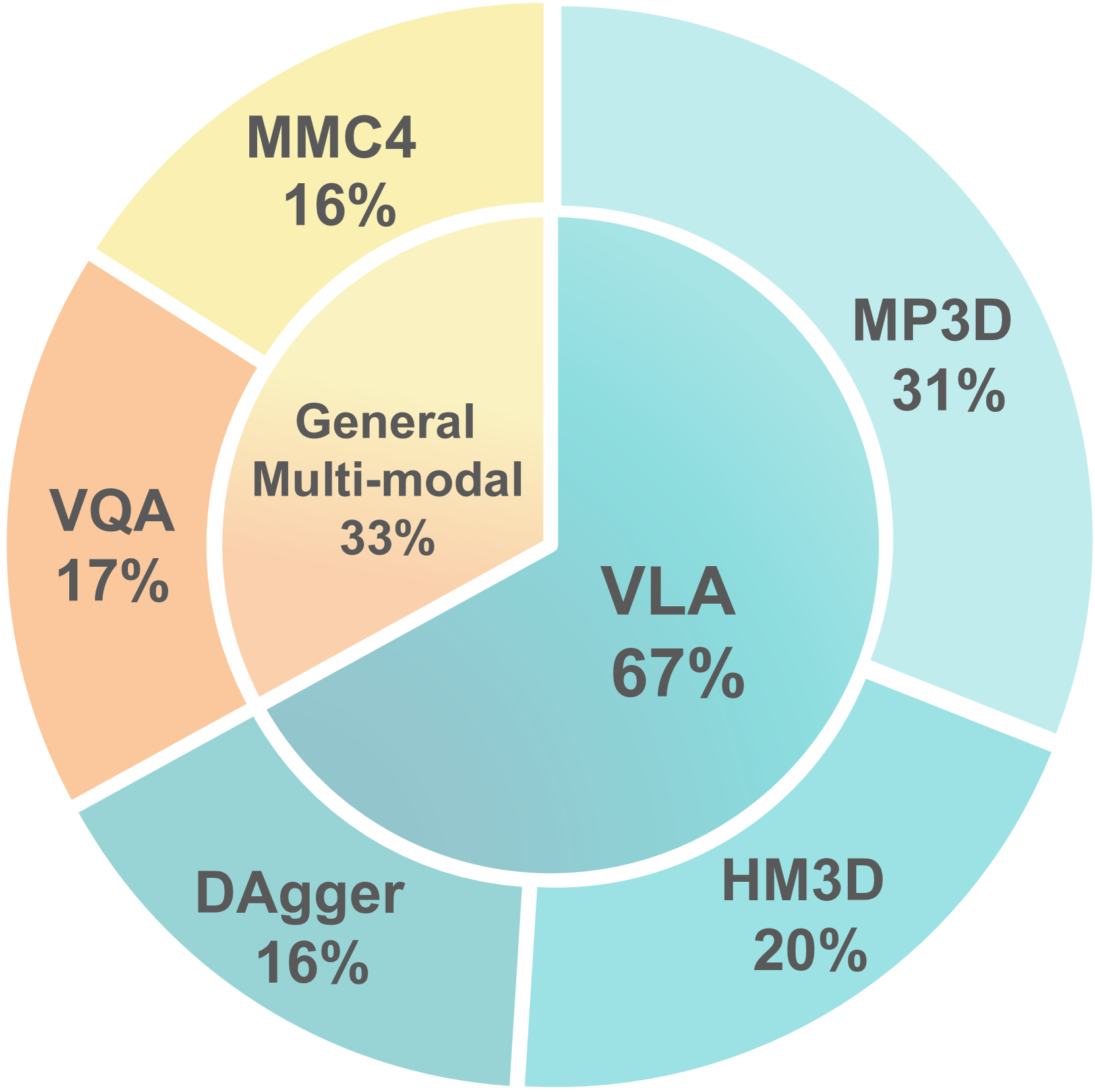
| Data Type | Source | Samples | Purpose |
|---|---|---|---|
| Navigation (Oracle) | R2R, R2R-EnvDrop, RxR | 450K | 60 个 MP3D 场景的导航专家轨迹 |
| Navigation (Oracle, extra) | ScaleVLN subset | 300K | 700 个 HM3D 场景,扩 scene 多样性 |
| Navigation (DAgger) | Habitat shortest-path follower on rollouts | 240K | 第一阶段后纠错数据,提升 novel scene 鲁棒 |
| Video QA | LLaVA-Video-178K, ScanQA | 248K | 时空 + 3D 推理 |
| Interleaved Image-Text | MMC4 | 230K | 多轮图文交互 |
DAgger 阶段:先训第一阶段(仅 oracle VLN),用其 rollout + Habitat shortest-path 作为 expert label 收集纠错数据,再 co-train 第二阶段。
3. Experiments
3.1 Setup
- Sim: VLN-CE(5.6K 英文轨迹,平均 10m)和 RxR-CE(126K 多语言指令,平均 15m),均为 Val-Unseen split;HFOV 79°
- Real-world: Unitree Go2 + RealSense D455(RGB-D,朝上)+ 远端 RTX 4090;推理 0.27s/4 actions,通信延迟室内 0.2s / 室外 1.0s
- Train: LLaVA-Video-7B + Qwen2-7B;2 stage(warm-up + co-train);batch 128 video clips;lr 2e-5 (LM) / 5e-6 (vision encoder);总 ~1500 A100 hours
3.2 Main Results: VLN-CE SOTA(Table 1)
StreamVLN 在 RGB-only 设定下创 SOTA:
- R2R Val-Unseen: NE 4.98, OS 64.2, SR 56.9, SPL 51.9
- RxR Val-Unseen: NE 6.22, SR 52.9, SPL 46.0, nDTW 61.9
对比 reference points:
- 与 ETPNav(用 panoramic + waypoint predictor + depth)打平
- 比 HMAT(在 ScaleVLN 3M 轨迹上训练)更好,仅用 150K ScaleVLN 子集——data efficiency 是个亮点
❓ Table 1 里 StreamVLN 标的是”RGB-only”,但 voxel pruning 显式用了 depth 反投。是仅”VLM 输入是 RGB” 而 depth 当 auxiliary signal?文中 Section 3.3 直接说”using depth information”,与 RGB-only 标签略矛盾,需要看 Table 1 的脚注才能确认。
3.3 Spatial Reasoning: ScanQA(Table 2)
为评估场景理解能力,在 ScanQA 上用 16 张多视角图回答 3D 问题:
| Method | Bleu-4 | Rouge | Meteor | Cider | EM |
|---|---|---|---|---|---|
| LEO | 13.2 | 49.2 | 101.4 | 20.0 | 24.5 |
| NaVILA (16 frames) | 15.2 | 48.3 | 99.8 | 19.6 | 27.4 |
| StreamVLN (16 frames) | 15.7 | 48.3 | 100.2 | 19.8 | 28.8 |
超过 NaviLLM、NaVILA,且无任务专用 fine-tune。作者把这个能力归因到 co-train 中的 VL 数据(VideoQA + MMC4)。
Figure 3. StreamVLN 把 visual reasoning 能力迁移到导航指令解读。

3.4 Ablations(Section 4.4)
Data Ablation (Table 3, R2R Val-Unseen):
| 配方 | NE | OS | SR | SPL |
|---|---|---|---|---|
| Stage-1(仅 oracle R2R+RxR) | 6.05 | 53.8 | 45.5 | 41.6 |
| + DAgger + VideoQA | 5.47 | 57.8 | 50.8 | 45.7 |
| + DAgger + VideoQA+MMC4 | 5.43 | 62.5 | 52.8 | 47.2 |
| + 上 + ScaleVLN(150K) | 5.10 | 64.0 | 55.7 | 50.9 |
| 去掉 DAgger | 5.73 | 56.4 | 50.2 | 47.1 |
| 去掉 RxR co-train | 5.90 | 55.9 | 47.9 | 43.6 |
可加性:DAgger +5.5 SR、MMC4 +2.0 SR、ScaleVLN +2.9 SR、RxR +7.8 SR。注意这些都是正交的小增量叠加得到 SOTA,单一 ablation 看不出 component 之间是否存在互相替代。
Memory & Window Size (Table 4):
- Memory token(窗口固定 8):SR 37.3 → 45.5。
- Memory = “all”(不剪)反而不是最佳——作者解释为过长 / 多变上下文引入训练 bias,损害泛化。
- Window size = 8 是 sweet spot:window=4 训练样本数从 450K 涨到 815K,window=2 涨到 1.5M,class imbalance 加剧、训练成本线性升。
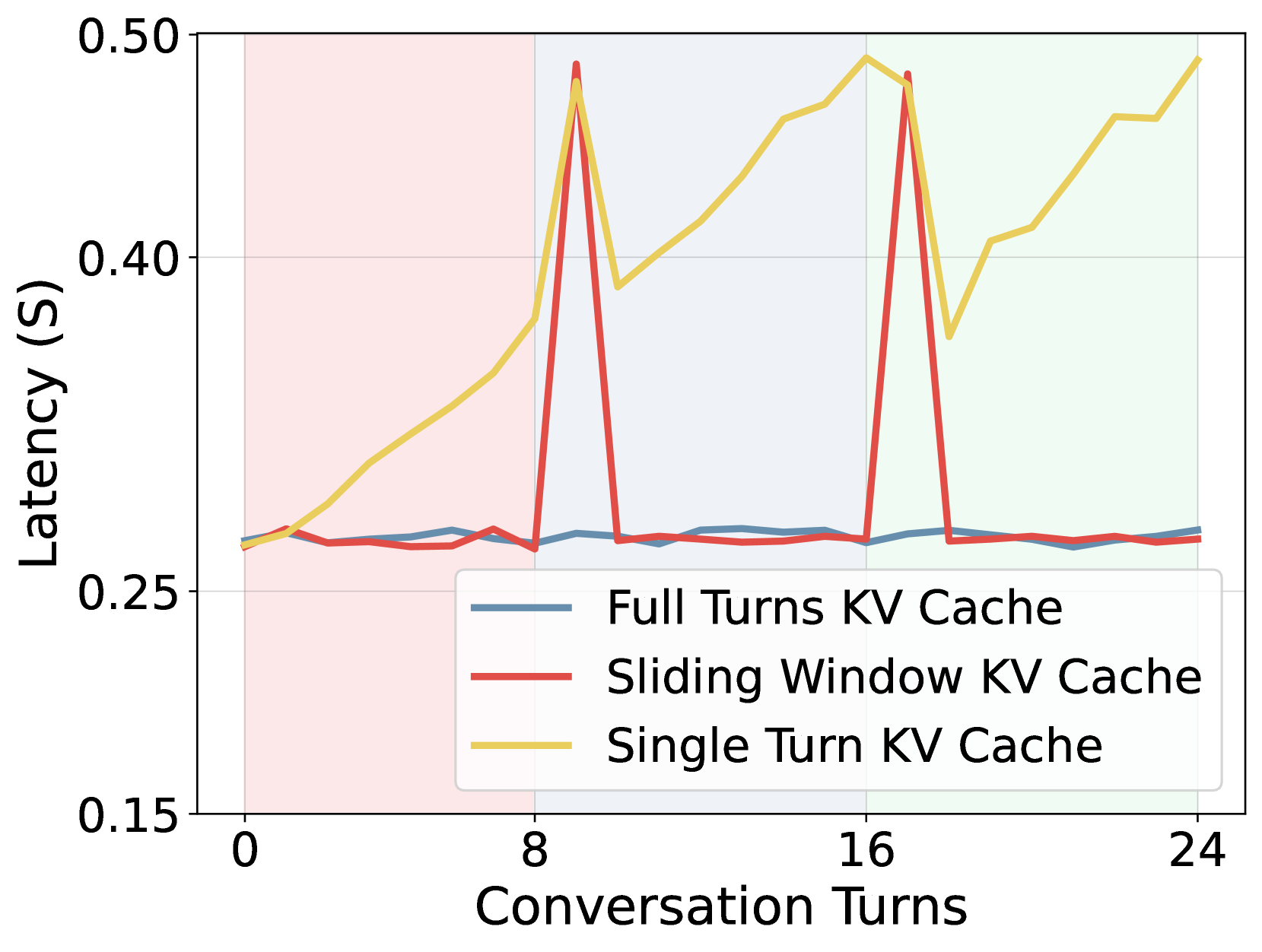
Figure 5. KV cache 复用对解码 latency 的影响(窗口大小 8)。Full Turns 恒低 latency;Sliding Window 在每个新窗起始有 prefill 抖动;Single Turn(无跨 turn 复用)线性增。
Voxel Pruning (Table 5):剪掉 ~20% token,R2R SR +1.2 / SPL +1.0;RxR SR +1.1 / SPL +1.0。剪 token 同时涨点——支持作者关于”减少 spatial 冗余反而帮助模型聚焦”的解读。
3.5 Real-World
Figure 4. StreamVLN 在 Home / Workspace / Mall / Outdoor 真实场景的轨迹。红色标注 landmark;展示对复杂指令和真实扰动的鲁棒性。

声称在多 landmark + 光照变化的 long-horizon Workspace 任务能完成;Mall 与 Outdoor 是 Go2 上的 zero-shot 部署。
4. Limitations(作者自述)
- 直接从 raw 视觉生成低层 action,对 viewpoint 变化和遮挡不够鲁棒
- 当前 hybrid context 在更长 horizon 下推理一致性仍有挑战
- 对话上下文显式包含 action history,部署时需同步过去 action,增加异步推理复杂度
关联工作
基于
- LLaVA-Video (Zhang et al.):foundational Video-LLM,提供 7B base + Qwen2-7B LM backbone
- Qwen2-7B:LLM backbone
- Habitat / VLN-CE:仿真器与 benchmark 标准
对比
- NaVILA:同样基于 Video-LLM 的 VLN VLA,但用 fixed-frame 采样 + 每步 refresh 上下文;StreamVLN 的 streaming 设计正是对其的批判
- ETPNav:waypoint-based 方法的代表,依赖 panoramic + depth + waypoint predictor;StreamVLN 用 RGB + monocular 流可与之打平
- ScaleVLN:用 3M 轨迹训练;StreamVLN 仅用其 150K 子集就超过——data efficiency 对比
方法相关
- DAgger (Ross et al.):用于纠错数据收集的 imitation learning 算法
- MMC4 (Zhu et al.):interleaved image-text 数据,支撑 multi-turn 多模态推理
- ScanQA:3D scene understanding QA benchmark,既作为 train data 又作为 eval
- Voxel-based representation:spatial pruning 借鉴 3D 体素思路(与 voxel grid 表示类似但用于 token 选择)
跨任务参考
- 详见 VLN domain map 中 streaming Video-LLM 一支
论文点评
Strengths
- Problem framing 清晰:把 VLN 重新表述为 streaming multi-turn dialogue,而非 per-step inference,这是 conceptual 上较 clean 的 simplification。“99% prefill 浪费” 是个 well-defined 的痛点。
- Slow-Fast 设计有 architectural rationale:拒绝 feature-level pooling 的理由是有 grounding 的(破坏 KV cache 复用),因此选择 token-level pruning。Voxel pruning 既有 3D geometric prior 又能保持 KV 一致性。
- Voxel pruning 的双重收益:剪 20% token + 涨 1% SR——少见的 efficiency 改动同时改善 accuracy,值得记一下作为 design pattern。
- Data recipe ablation 充分:DAgger / VL data / ScaleVLN / RxR 各自的边际收益都给了,便于复现者按预算裁剪。
- Real-world 部署完整:从 Go2 + 4090 + 通信延迟拆解都给了,落地门槛低。
Weaknesses
- “RGB-only” 标签争议:voxel pruning 显式依赖 depth 反投,与 Table 1 的 “RGB-only” 标签存在 framing tension。RGB-only 应理解为 LLM 输入是 RGB;但 pipeline 整体并非 depth-free。
- Slow memory 的设计选择缺少更深 ablation:voxel stride / threshold 没给敏感性曲线;voxel pruning vs. 其他 spatial pruning(如 attention-based、similarity-based)的对比缺失。
- Window=8 的最优性证据偏弱:作者主要从训练成本、class imbalance 论证,但 window=2/4/16 的 SR 数字没全列出来,“sweet spot” 的论证不算完全。
- Long-horizon claim 未证伪:自己 Limitations 也承认 “longer horizon 下一致性有挑战”,但 main result 的 RxR 平均 15m 并不算特别长,没看到对 horizon 长度的稳健性曲线(例如 episode length vs. SR)。
- Co-training 对 VLN 提升的归因模糊:MMC4 +2.0 SR 是因为 interleaved 训练形式更接近 VLN 的 multi-turn 结构,还是因为额外的 vision-language alignment?没有 controlled comparison。
- 缺少和并行 Video-LLM-based VLN 的方法层 ablation:与 NaVILA 的对比只看终值,没拆解”是 streaming 改动重要还是 voxel pruning 重要还是数据多”的贡献。
可信评估
Artifact 可获取性
- 代码: inference + training 全开源(GitHub),含 DAgger 数据收集、Stage-2 co-training、real-world 部署 guide
- 模型权重: 已发布
mengwei0427/StreamVLN_Video_qwen_1_5_r2r_rxr_envdrop_scalevln_v1_3checkpoint(HuggingFace) - 训练细节: 超参(LM lr 2e-5, vision lr 5e-6, batch 128, 2 epoch)+ 数据配比(论文 Section 3.4 + Table 3)+ 总训练时长(1500 A100 hours)齐全;voxel pruning 的 stride/threshold 未在正文给出
- 数据集: 全部公开。R2R/RxR/EnvDrop/ScaleVLN 子集已转 VLN-CE 格式上传 HF dataset
cywan/StreamVLN-Trajectory-Data
Claim 可验证性
- ✅ VLN-CE R2R Val-Unseen SR 56.9 / SPL 51.9:Table 1 标准 benchmark + 公开 checkpoint,可独立复现;GitHub README 还更新了 v1-3 数据上的更好数字(SR 56.4, SPL 50.2)
- ✅ Voxel pruning 减 20% token + 涨 SR:Table 5 直接对比同模型有/无 pruning,控制变量清晰
- ✅ KV cache reuse 消除 ≥99% prefill 时间:Figure 5 latency 曲线 + 数学推断一致
- ⚠️ “State-of-the-art among RGB-only methods”:取决于”RGB-only” 的定义,voxel pruning 用了 depth;与 ETPNav 等 panoramic+depth 方法平手而非超过
- ⚠️ ScanQA 上 +0.5 Bleu-4 over NaVILA:增量很小,且 StreamVLN 在 co-train 中显式用了 ScanQA → 不是 zero-shot 比较
- ⚠️ “Real-world Go2 部署 0.27s/4 actions”:仅给定性视频,没有量化 success rate / 跨场景统计
Notes
-
Design pattern 提取:在序列模型上做 KV cache 复用时,要保持 cache 一致性,所有”压缩”操作必须是 append-only 或 mask-only(即不修改之前 token 的表示),否则 cache 失效。Voxel pruning 通过 mask 而非 feature merge 满足这个约束——值得在 future Video-LLM 长序列工作里复用。
-
与 NaVILA 的核心差异:NaVILA 是 per-step replan 的”短视频” VLA,StreamVLN 是 multi-turn dialogue 的”流式” VLA。前者每步重 prefill 16 帧,后者每步只 prefill 当前 obs。Compute 节省的渐近差异是 O(T) vs O(T²)。
-
未解决的 open question:streaming 设计在 RL fine-tune(VLN-RL / agentic-RL)下还成立吗?KV cache 复用要求训练时也按 streaming sample,与 PPO/GRPO 之类的 on-policy rollout 怎么 align?
-
复现成本估计:1500 A100 hours ≈ 62 卡日,在 8×A100 节点上约一周 wall-clock。数据已开源,是个适中的复现 budget。
Rating
Metrics (as of 2026-04-24): citation=62, influential=16 (25.8%), velocity=6.46/mo; HF upvotes=48; github 478⭐ / forks=37 / 90d commits=0 / pushed 173d ago
分数:2 - Frontier 理由:在 RGB-only VLN-CE setting 下是当前 SOTA(R2R SR 56.9 / SPL 51.9,Table 1),且 streaming multi-turn dialogue + KV cache 复用是未来 long-context Video-LLM agent 的 reusable design pattern(见 Notes 第一条),属于方向的必比 baseline。未到 Foundation 档是因为它仍是 RGB-only Video-LLM VLA 路线的优化而非范式重定义,且已自报 long-horizon 一致性等 limitations;未降至 Archived 是因为方法仍是前沿 SOTA、代码/权重/数据全开源、ICRA 2026 收录,社区复用概率高。