Summary
NaVILA: Legged Robot Vision-Language-Action Model for Navigation
- 核心: 把 VLA 拆成 high-level VLM(生成”move forward 75cm”这类语言化 mid-level action)+ low-level vision-based RL locomotion policy 的两级架构,让 legged robot 能跑 VLN-CE 并迁移到真机
- 方法: 基于 VILA 的 image-based VLM,融合 VLN-CE / RxR-CE / EnvDrop / ScanQA / 2K YouTube 人类游览视频(通过 MASt3R 估计 metric pose 提取 trajectory)+ general VQA 做 SFT;底层用 single-stage PPO + LiDAR height map 训练 vision-based locomotion
- 结果: VLN-CE Val-Unseen SR 54%(+17% over prior SOTA,且仅用 single-view RGB 就超过用 panoramic+depth+odometry 的方法),ScanQA CIDEr 102.7 超过依赖 3D scan 的 LMM;real-world Unitree Go2/H1 + Booster T1 上 25 条指令 88% SR,跨形态零迁移
- Sources: paper | website | github
- Rating: 3 - Foundation(legged VLN 方向的奠基工作——RSS 2025 接收,“language as mid-level action” 范式 + YouTube video pipeline + VLN-CE-Isaac benchmark 已被后续 legged VLN 工作作为 de facto baseline 引用)
Key Takeaways:
- 语言作为 mid-level action 的接口:把 VLA 的输出从低维 joint command 抽象到 “turn right 30 degrees” 这种语言短语,自然解耦感知-推理与运动控制;同一个 VLA 可以替换 low-level policy 部署到 quadruped、humanoid(Go2/H1/T1)上零样本切换
- Dual-frequency 架构:VLM 因体量大只能低频跑(1-2Hz),locomotion policy 高频跑(real-time),让 obstacle avoidance 和 reasoning 在不同时间尺度上并行——这是大模型上机器人的一个 robust 的工程模式
- YouTube 人类游览视频是 navigation 的可用数据源:用 MASt3R 做 metric-pose estimation + entropy-based sampling + VLM/LLM 自动 captioning 把 2K 原视频变成 20K 监督 trajectory,是这篇论文里最 generalizable 的 contribution
- Single-stage RL + LiDAR height map 在 locomotion 上打过 teacher-student distillation:collision rate 从 ROA 的 3.09 降到 0.81,说明对 vision-based locomotion 来说,distillation 不是必须的工程范式
Teaser. NaVILA 实机演示——VLM 处理 RGB egocentric 视频生成语言指令,locomotion policy 在真实环境中执行长程导航和障碍避让。

Problem & Motivation
VLN 在过去几年里从 discrete graph navigation(MP3D 节点跳转)走向 continuous environment(VLN-CE,Habitat 模拟器内连续移动),但仍存在两个未被打通的环节:
- Continuous setting 仍然在 wheel-based / point-mass 抽象之上——agent 可以穿过 10cm 沙发缝隙,根本不考虑实体机器人物理约束。 legged robot 在 VLN 里几乎是空白
- End-to-end VLA → joint action 的范式不自然:VLM 是用语言 / 图像数据预训练的,硬把它的输出 quantize 成低维 joint command 既丢掉 LLM 的语义优势,又撞上 sim-to-real gap
NaVILA 的 first-principles 回答是:让 VLA 输出仍然停留在语言域——“move forward 75cm”、“turn left 30 degrees”——再让一个独立的 RL locomotion policy 把这些语言短语解释成 joint trajectory。这样:
- VLM 训练数据不必是 robot demonstration,可以用 VLN-CE 的 oracle action、YouTube 人类视频、ScanQA 这种异构数据混训
- 同一个 VLA 可以驱动不同形态机器人(quadruped / humanoid),只需替换 low-level policy
- 大模型低频跑 / locomotion 高频跑的 dual-frequency 模式天然 robust
这其实和 SayCan / RT-Hierarchy 系的”LLM 出 skill name + 底层 skill 执行”思路一脉相承,但 NaVILA 的关键差异是输出的不是 discrete skill ID,而是带 continuous 数值参数的语言短语(角度、距离),这让 mid-level action 既保留语义性又有空间精度。
Method
NaVILA 是一个 2-level framework:上层是 VLA(基于 VILA 微调),输出语言化的 mid-level action;下层是 vision-based RL locomotion policy,把语言指令解释成 12 自由度的 joint position 输出。
Figure 2. NaVILA 整体架构——VLA 处理 single-view egocentric RGB 序列输出自然语言 mid-level action,locomotion policy 把它转成 joint movement。
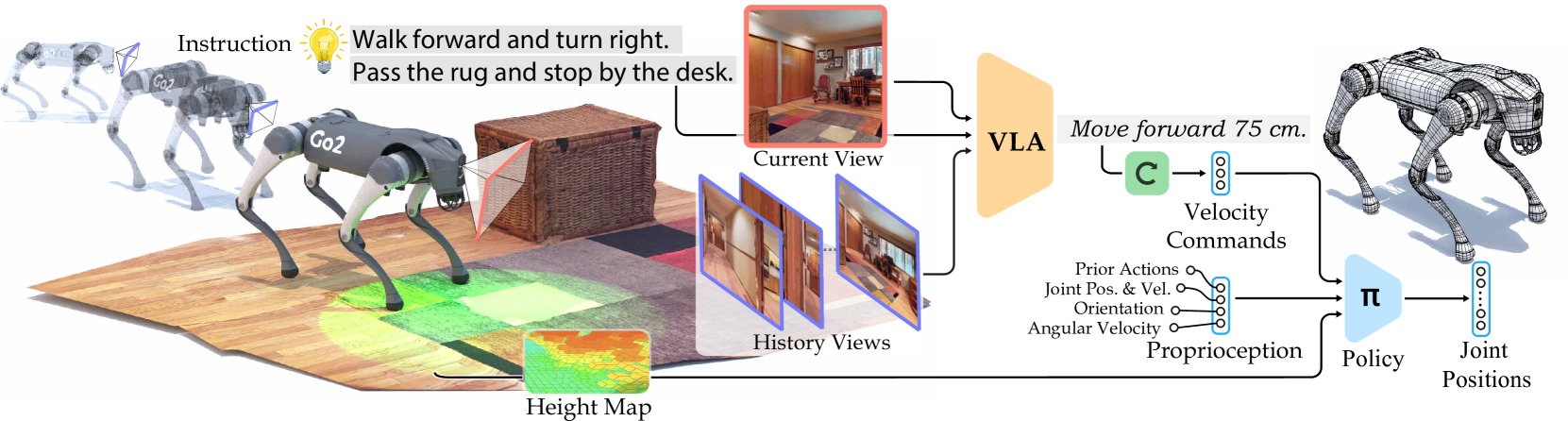
II-A High-level VLA:把 VILA 改造成 navigation agent
Backbone 选择 image-based VLM 而非 video VLM。理由是 image-text pretraining 数据规模远超 video-text,跨场景泛化更好。具体用 VILA(Vision-Language Architecture),三段式结构:vision encoder → MLP projector → LLM (Llama3-8B 量级)。
Navigation prompt 设计——VLN 任务里 “current frame” 和 “history frames” 角色不同:current 决定下一步动作,history 是 memory bank。NaVILA 的处理:
- 强制保留最新一帧作为 current observation,再从过去 t-1 帧均匀采样 + 强制保留第一帧
- 在 prompt 里用 textual cue 区分:
"a video of historical observations: <frames>... current observation: <frame_t>" - 不引入 special token——保持 LLM 输入输出都在 language domain,复用预训练 reasoning 能力
SFT 数据 blend(4 类):
- Navigational data from real videos——2K YouTube egocentric touring videos → 20K trajectories(关键贡献,下面详述)
- Navigational data from simulations——VLN-CE 和 RxR-CE,用 shortest path follower 在 Habitat 内生成 oracle action 序列。 trick:合并最多 3 个连续相同动作(两个 forward 25cm 合并成 forward 50cm),既减小数据集又增加动作多样性,并对 stop action 做 rebalancing
- Auxiliary navigational data——EnvDrop augmented instructions、ScanQA 3D QA(用 multi-view RGB 而不是 3D scan)、trajectory summarization
- General VQA datasets——保住 broad reasoning capability
YouTube 人类视频数据 pipeline(这是 NaVILA 最 reusable 的方法贡献):
Figure 4. 把 YouTube 人类游览视频转成 continuous-environment navigation supervision 的数据 pipeline——entropy-based sampling 切 trajectory,MASt3R 估计 metric camera pose 抽 step-wise action,VLM/LLM 自动生成 instruction。
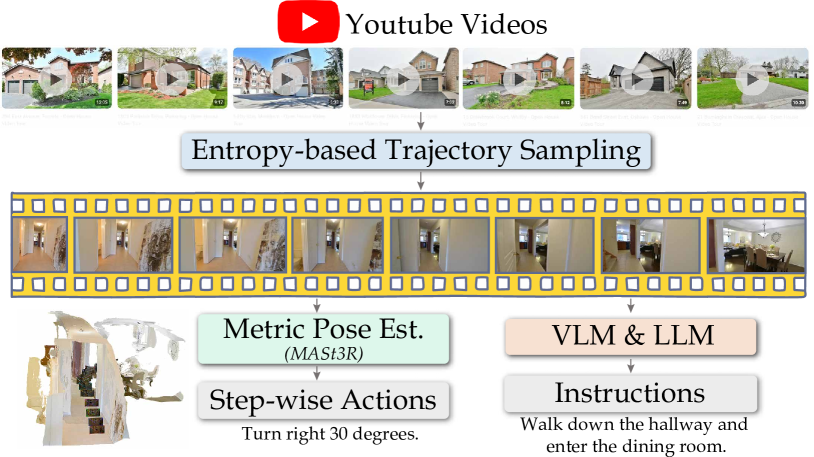
- Entropy-based sampling 把长视频切成有信息量的 trajectory 段
- MASt3R 做 metric-pose estimation(注意是 metric scale,不是 up-to-scale)—— 这是把”人类视频 → 可监督 action label”打通的关键技术依赖
- VLM-based captioning + LLM rephrasing 自动生成 instruction
Inference:用 regex parser 从 LLM 输出抽取 action type(forward / turn left / turn right / stop)+ 数值参数(距离/角度)。论文报告”all actions across all experiments are successfully matched and mapped”——这种 hard parsing 在 deployment 上简单粗暴但 reliable。
II-B Low-level:vision-based locomotion policy
Action space:只控制 12 个腿部 joint motor(base 6 DoF 自由),joint position target → torque(PD 控制)
Observation:
- Critic 用 privileged terrain height scan + proprioception
- Actor 只用 proprio history(无 linear velocity)+ 从 LiDAR point cloud 重建的 2.5D height map
Figure 5. 从 LiDAR point cloud 重建 height map:(a) Go2 在仿真里执行速度命令,红点为 raycast;右图为预处理后的 height map。 (b) 玻璃面前的安全 locomotion——top-down height map 能检测到玻璃,而 depth/RGB 不行。

LiDAR height map 的工程细节:
- Unitree L1 LiDAR:360°×90° FoV,15Hz
- 每个 voxel 取最低值;过去 5 帧做 max filter 平滑
- 选 LiDAR 而非 depth/RGB:在强阳光、玻璃面这种 corner case 上 robust
Single-stage RL(不做 teacher-student distillation):
- 之前主流做法是先训 privileged policy,再 distill 给 vision policy
- NaVILA 直接用 PPO 训 vision policy,靠 Isaac Lab 的 ray-casting 加速(>60K FPS on RTX 4090)
- Command 接口:VLM 输出的 fixed action set {move forward, turn left, turn right, stop} 映射到固定 velocity command {0.5 m/s, π/6 rad/s, -π/6 rad/s, 0},按目标距离/角度计算执行时长
这里其实牺牲了一点表达力——所有 forward 都用 0.5 m/s 跑同样长的时间,没有真正的 continuous velocity tracking。 但好处是 sim-to-real 简单,且 VLM 输出的 fine-grained 数值(“forward 75cm”)通过执行时长来体现,而不是通过 velocity magnitude。
Key Results
High-level VLA on VLN-CE benchmarks
Table I 摘要(VLN-CE / RxR-CE Val-Unseen):
| Method | Obs | R2R SR ↑ | R2R SPL ↑ | RxR SR ↑ | RxR SPL ↑ |
|---|---|---|---|---|---|
| GridMM* (waypoint) | Pano+Depth+Odo | 49.0 | 41.0 | - | - |
| ETPNav* (waypoint) | Pano+Depth+Odo | - | - | - | - |
| NaVid (video VLM) | Single RGB | 37.4 | 35.9 | - | - |
| NaVILA | Single RGB | 54.0 | 49.0 | 44.0 | 35.0 |
*indicates use of simulator pre-trained waypoint predictor
关键观察:仅用 single-view RGB 就超过用 panoramic + depth + odometry 的方法,且不依赖 simulator pretrained waypoint predictor。 +17% SR over prior SOTA 在不靠 waypoint trick 的赛道上是显著优势。
Cross-dataset generalization:仅在 R2R 上训,零样本评估 RxR Val-Unseen,比 NaVid 高 +10% SR——说明 representation 学到的不只是 R2R-specific pattern。
Spatial scene understanding (ScanQA)
| Model | CIDEr ↑ | EM ↑ | Input |
|---|---|---|---|
| LEO (3D LMM) | 101.4 | 24.5 | 3D scan |
| Scene-LLM* | 80.0 | 27.2 | 3D scan |
| NaviLLM (2D VLA) | 75.9 | 23.0 | RGB |
| NaVILA (8 frames) | 95.1 | 27.0 | RGB |
| NaVILA (64 frames) | 102.7 | 28.6 | RGB |
只用 multi-view RGB 就追平甚至超过依赖 3D scan / depth + camera pose 的 3D LMM。
Locomotion policy(Table V)
| Method | Linear Vel Err ↓ | Angular Vel Err ↓ | Collision Rate ↓ |
|---|---|---|---|
| ROA (BCLoss) | 0.189 | 0.152 | 3.25 |
| ROA | 0.161 | 0.152 | 3.09 |
| NaVILA | 0.066 | 0.113 | 0.81 |
Single-stage 比 distillation-based 全面更好,特别是 collision rate 降低 3.8 倍。
VLN-CE-Isaac benchmark(自家提出)
Figure 6. VLN-CE-Isaac benchmark 可视化——Isaac Sim 高保真物理仿真,Go2 / H1 等 legged robot 部署在 R2R 场景中。

| Setup | Method | SR ↑ | SPL ↑ |
|---|---|---|---|
| Go2 | NaVILA-Blind (proprio only) | 36.2 | 33.3 |
| Go2 | NaVILA-Vision (LiDAR) | 50.2 | 45.5 |
| H1 | NaVILA-Blind | 24.4 | 21.0 |
| H1 | NaVILA-Vision (height scan) | 45.3 | 40.3 |
| Oracle (perfect low-level) | - | 51.3 | 46.9 |
Vision policy 比 blind 高 +14%(Go2)/ +21%(H1)SR;NaVILA-Vision 在 Go2 上几乎追平 Oracle low-level(50.2 vs 51.3),说明 vision-based locomotion 在物理仿真里基本不再是瓶颈。 H1 上仍有 6 个点 gap,humanoid 的 footing 比 quadruped 难。
Real-world deployment
25 条指令 × 3 次重复,Workspace / Home / Outdoor 三类环境,simple vs complex instruction:
- NaVILA on Unitree Go2: simple SR 1.00 / 1.00 / 1.00(across envs), complex 0.80 / 0.67 / 0.83
- NaVILA on Booster T1(humanoid): 直接用同一个 VLA 不重训,simple 0.93, complex 0.67
- vs GPT-4o baseline:NaVILA 全面碾压,特别在 complex 指令上(GPT-4o complex SR ≤0.33)
Human touring video 的 ablation:去掉 YouTube 数据后(NaVILA†),outdoor 场景 SR 从 1.00 / 0.83 跌到 0.00 / 0.00——说明 YouTube 数据对 outdoor / out-of-distribution 泛化是 critical 的。
Video. 真实世界部署演示(Unitree Go2 + LiDAR)。
Video. 跨形态部署:Booster T1 humanoid 上无需重训直接迁移。
Video. 数据 pipeline:YouTube 人类游览视频 → trajectory + instruction 对。
关联工作
基于
- VILA ([VILA Family of VLMs, NVIDIA]):image-based VLM backbone,三段式 vision encoder + MLP projector + LLM;NaVILA 从 stage-2 pretrain checkpoint 开始 SFT
- MASt3R:metric-pose estimation in the wild,是把 YouTube 视频转成可监督 trajectory 的关键技术依赖
- Habitat / VLN-CE:simulated continuous VLN 的 benchmark 平台
- Isaac Lab / Isaac Sim:locomotion policy 训练 + VLN-CE-Isaac benchmark 的物理仿真环境
- PPO:locomotion RL 训练算法
对比
- NaVid:同样是 single-view RGB 的 video VLM for VLN,NaVILA 比它 R2R SR 高 17%;架构差异在 NaVid 用 video encoder,NaVILA 用 image-based VLM + 显式区分 current/history frame
- GridMM / ETPNav 等 waypoint-based 方法:依赖 simulator 预训练的 waypoint predictor,强是强但泛化差;NaVILA 不用 waypoint 也能赢
- GPT-4o:作为 zero-shot baseline 在 real-world 测试中被 NaVILA 显著超越,特别是 complex 指令
- ROA (Regularized Online Adaptation):teacher-student distillation 的 locomotion baseline,被 single-stage RL 全面超越
- 3D LMM (LEO, Scene-LLM, 3D-LLM):依赖 3D scan / depth 输入;NaVILA 仅用 multi-view RGB 就在 ScanQA 上追平/超越
方法相关
- SayCan / RT-Hierarchy 系:同样是 high-level LLM + low-level skill 的两级架构思路;NaVILA 创新点在 mid-level action 是带连续参数的语言短语而非 discrete skill ID
- π0 / π0.5:另一类 hierarchical VLA,用 language subgoal 驱动 flow-matching action expert;与 NaVILA 的关键区别是底层用 continuous flow policy 而非 RL locomotion,且面向 manipulation
- RT-2:end-to-end VLA 直接输出 low-level action,是 NaVILA 想避开的范式
- LH-VLN:long-horizon VLN,与 NaVILA 在长程任务能力上有相似关注点
论文点评
Strengths
- 语言作为 mid-level action 的接口设计很优雅——既保留 VLM 的语义推理能力,又通过数值参数(距离/角度)保留空间精度,且天然支持跨形态切换。 这种 “language as action interface” 的范式在 manipulation 上也值得复制(语言化的 grasp / waypoint 描述)
- YouTube 视频数据 pipeline 是真正可复用的方法贡献——MASt3R 给出 metric pose 是关键打通点,过去用 human video 只能做 pretraining / landmark grounding,这是首次直接拿来训 continuous navigation 的 supervision label
- Single-stage vision-based locomotion 打过 teacher-student distillation(collision rate 0.81 vs 3.09)—— Isaac Lab 的 ray-casting + LiDAR height map 让单阶段 RL 在效率和性能上都赢,挑战了 legged locomotion 必须 distillation 的 convention
- Real-world 评测扎实——25 条指令 × 3 次 × 3 场景 × 2 robot platform,不是常见的”挑几条 demo 给 SR 100%“,complex outdoor 也敢报 0.83
- Dual-frequency 架构对部署 friendly——大 VLM 跑慢一点不影响 locomotion,这是把大模型上机器人的一个被验证的工程模式
Weaknesses
- Mid-level action set 极度受限——只有 4 种动作(forward / turn left / turn right / stop),forward 全速 0.5m/s,转向 π/6 rad/s 固定。 这意味着 “continuous value” 只通过执行时长间接体现,VLM 输出的 “forward 73cm” 和 “forward 75cm” 实际上无差别(都是固定速度跑 1.46s vs 1.50s)。 这种粒度对精细操作不够(侧移、对角线移动、变速避障都不支持)
- VLA 在低频跑导致 reactive obstacle avoidance 完全靠 locomotion policy——如果 VLM 决策周期是 1-2Hz,在动态障碍场景里高层 planner 来不及反应,全靠 height map + RL 兜底;论文里没有讨论 dynamic obstacle / 行人场景
- MASt3R metric pose 估计在 in-the-wild 视频上的可靠性没有量化分析——pipeline 里这个环节失败会直接污染 trajectory label,但论文没报 noise level / 失败率
- “Real-world 88% SR” 这个数字需要小心解读——25 条指令 × 3 次 = 75 trial,simple 占主导且 simple SR 几乎全 1.00,complex SR 在 outdoor 也只是 0.83。 整体均值被 simple cases 拉高
- 跨 embodiment 迁移虽然演示了 Go2 → H1 → T1,但 H1 在 VLN-CE-Isaac 上 SR 仍比 Go2 低 5 个点,且需要重新训 H1 的 locomotion policy(不是真的 zero-shot;只有 VLA 是零迁移)。 论文标题暗示的”通用 VLA”主要指 VLA 部分
可信评估
Artifact 可获取性
- 代码: inference + training 全开源(GitHub repo 列出了 train/eval scripts,locomotion code 在 legged-loco,benchmark 在 NaVILA-Bench)
- 模型权重: 已发布
a8cheng/navila-llama3-8b-8f(评估用 checkpoint)+a8cheng/navila-siglip-llama3-8b-v1.5-pretrain(pretrain 起点)on HuggingFace - 训练细节: 仅高层描述——附录 -C2 给了 VLA 超参,-C3 给了 locomotion 细节;但 SFT 数据混合的具体比例未完整披露
- 数据集: 部分公开——R2R / RxR / EnvDrop / ScanQA / Human 的 annotations 在 HuggingFace dataset 上;YouTube 人类游览原视频因版权只放 video IDs,需用户自己 yt-dlp 下载;EnvDrop 视频也需用户自己用 VLN-CE renderer 重渲染
Claim 可验证性
- ✅ “+17% SR on VLN-CE Val-Unseen vs prior SOTA”:Table I 数字清楚,对比的 baseline 公开(NaVid 等),可在公开 benchmark 上独立复现
- ✅ “single-stage RL 比 ROA distillation 更优”:Table V 三个 metric 都报了,code 开源可复现
- ✅ “VLA 跨 embodiment 零迁移到 Booster T1”:Table VI + 真机视频佐证;T1 上 simple SR 0.93 / complex 0.67 是 nontrivial 的迁移强度
- ⚠️ “88% real-world SR on 25 instructions”:trial 数 75 偏少;simple vs complex / 三类环境分布不均;GPT-4o baseline 是否在公平 prompt 下评估未细说
- ⚠️ “YouTube human videos critical for generalization”:ablation 在 outdoor 上 NaVILA† SR 0.00 vs NaVILA 1.00 的 gap 戏剧性强,但 trial 数小(每环境约 5-10 条 indoor + 几条 outdoor),不能完全排除噪声
- ⚠️ “first work to show direct training on human videos improves continuous navigation”:first 是结合 continuous + direct training 的 narrow 表述;human video 用于 navigation pretraining 此前已有工作(如 NaVid, EgoPlan)
- ❌ 没有明显的营销话术 claim
Notes
- NaVILA 的本质 takeaway 不是”language is mid-level action”这句话,而是”VLA 输出可以是 structured language with numerical parameters”——这种 representation 在 manipulation 上其实更值得探索(“grasp the cup at 30cm to your right”),目前 manipulation VLA 大都还在 token-quantized continuous action 上挣扎
- 与 π0.5 的关键 architectural 对比:π0.5 用 language subgoal 驱动 low-level flow matching action expert(continuous, diffusion-style),NaVILA 用 language action 驱动 RL locomotion policy(discrete velocity command + duration)。两者都用 hierarchy,但 NaVILA 的 low-level 更”传统”(PPO + heuristic mapping),π0.5 的 low-level 更端到端。 哪种范式更 scale?我猜 long-term 是 π0.5 这种 differentiable hierarchy 赢,但 NaVILA 的工程简洁性短期内更易部署
- YouTube 视频数据 pipeline 能否用于 manipulation?——理论上人类操作视频比游览视频更难(需要 hand pose + object 6D pose),但配上 HaMeR + FoundationPose 这类 in-the-wild estimation tool 应该可行。这是一个值得跟进的 thread
- ❓ 论文没有报告 VLM 推理频率的具体数字。 从 8B model + 8 frames 的体量推断应该是 1-2Hz,那么在动态障碍场景的 reactive 性能完全依赖 locomotion policy;这个 dual-frequency 架构在静态环境很 robust,但在人多 / 移动物体场景里 high-level decision 可能会延迟严重
- ❓ Mid-level action 的 4 类离散动作 + 固定速度,其实是个很强的 inductive bias / 限制。如果换成 humanoid 需要侧移、转身、蹲下,是否需要扩展 action vocabulary?这部分 paper 没讨论
- VLN-CE-Isaac benchmark 是个有用的 community resource,把 R2R 场景从 Habitat 抽象搬到 Isaac 物理仿真,能更真实评估 legged platform 的 navigation——后续 VLN 论文应该用这个而不是只跑 Habitat
Rating
Metrics (as of 2026-04-24): citation=169, influential=26 (15.4%), velocity=10.18/mo; HF upvotes=0; github 589⭐ / forks=54 / 90d commits=0 / pushed 247d ago · stale
分数:3 - Foundation 理由:NaVILA 是 legged VLN 方向的奠基工作——把”language as mid-level action”范式 + YouTube 人类视频 pipeline + VLN-CE-Isaac 物理仿真 benchmark 一次性打通,RSS 2025 接收,且在 VLN-CE Val-Unseen 上 +17% SR、仅用 single-view RGB 即超越 panoramic+depth 方法(见 Strength 1-4)。 相比 Frontier 档:这不是一般的 SOTA 刷分,而是范式 + benchmark + 数据 pipeline 三位一体的 foundational contribution,后续 legged VLN 工作几乎无法绕开它作为 baseline;缺点(固定 action set、低频 VLM)是工程局限,不削弱其奠基意义。