Summary
RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control
- 核心: 把 robot action 表示为 text token,把现成大 VLM(PaLI-X 55B / PaLM-E 12B)通过 co-fine-tuning 直接变成端到端机器人策略,从而把 web 知识迁移进低层控制
- 方法: Action 离散化为 256 bin,每维一个 token;与原始 VQA / 图文数据共训以防遗忘;输出层在 robot prompt 时 constrained decoding 仅采样 action token;55B 模型部署到多 TPU cloud 服务,机器人通过网络查询,控制频率 1–3 Hz
- 结果: 6k trial 真机评测;unseen object/background/env 平均比 RT-1 / MOO 提升 ~2×、比其他 baseline 提升 ~6×;symbol understanding / reasoning / human recognition 三类 emergent 任务上比 RT-1 提升 ~3×;CoT 变体可执行多步语义推理(如挑石头当锤子)
- Sources: paper | website
- Rating: 3 - Foundation(VLA 范式的奠基工作:action-as-token + VLM co-fine-tuning 的 recipe 被整条 VLA 谱系继承)
Key Takeaways:
- Actions-as-tokens 范式:不需要新架构,把 7-DoF action 离散化复用 VLM 现有 tokenizer(PaLI-X 直接借数字 token,PaLM-E 覆写最不常用的 256 token),从此 VLA 成为一类范式
- Co-fine-tuning 是关键:纯在 robot 数据上 fine-tune 会丢失 VLM 的 web 知识;按比例混入原 web 数据是 emergent 泛化的必要条件,scratch 训练的 5B 几乎学不动
- Emergent capability 来自 backbone 而非 robot 数据:symbol understanding / 多语言指令 / 人物属性识别全部源自预训练,robot 数据只贡献 motion skill;55B 总体最强但 PaLM-E 在数学推理上反而更优,反映预训练数据 mixture 决定下游能力分布
- Skill 不会 emergent:模型只学会用旧 skill 解决新指令,没有 acquire 新 motion;这是后续 cross-embodiment + 大规模 robot data(OXE, DROID)和 flow matching action head 的直接动机
- 推理频率瓶颈:55B 走 cloud TPU 仅 1–3 Hz,5B 约 5 Hz;autoregressive token decoding 是结构性瓶颈,催生 π0 类 flow matching / chunked action 路线
Teaser. RT-2 整体范式:把 robot action 当作另一种语言,与 web 图文数据共同训练 VLM,推理时把 token 反离散化为机器人控制指令。
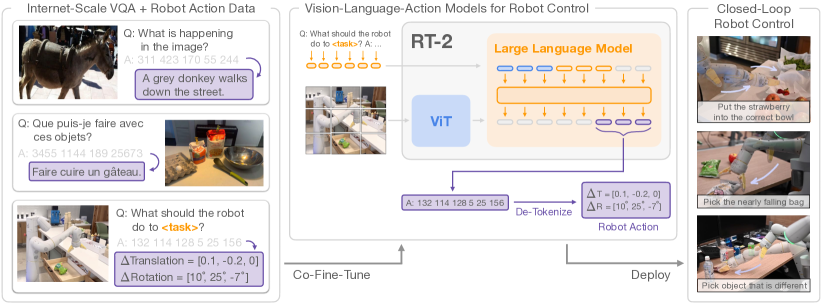
Problem & Motivation
机器人领域有一个 capability vs data 的根本错配:web-scale 预训练的 LLM / VLM 已能做 open-vocabulary 视觉理解、常识推理、多语言、符号理解,但 robot 数据规模远不足以从零训出这些能力。同时既有”VLM + robot”路线(SayCan, PaLM-E 等)通常把 VLM 当 high-level planner,再调一个独立的 low-level controller——controller 本身没享受到任何 web 预训练知识。
❓ 这种分层是否正确?作者赌的是:直接把 VLM 端到端地训成 controller,让 web 知识渗透到 action level,而不是停在 planning level。这个赌注在后续 VLA 全谱系里被反复验证(OpenVLA / π0 / Octo 等都继承了这个 end-to-end 立场)。
核心问题:能否让 VLM 不只生成自然语言 token,还直接生成可执行的 robot action token,并且保留 web pretraining 的语义泛化与推理能力?
Method
Actions-as-Tokens
VLA 的核心 trick 不是新架构,而是 representation:把 6-DoF 末端位姿增量 + gripper 开合 + 终止符共 8 维 action 离散化(continuous 维度各分 256 bin),然后用 VLM 已有 tokenizer 的某 256 个 token 来表示这些 bin。这样 robot trajectory 就完全是一个 (image, text Q, text A) 三元组,A 形如 1 128 91 241 5 101 127。
Equation 1. Action 字符串编码格式
符号说明:第一维 terminate 是离散结束信号;接着 6 维末端位置 / 旋转增量;最后是 gripper extension。
含义:每个 token 都是 VLM 词表内的现成符号,因此 VLM 的 LM head 不需要任何架构修改即可输出 action。
两个 backbone 走法不同:
- PaLI-X:tokenizer 给 [0, 1000] 整数都分配了独立 token,直接借用前 256 个数字 token 当 action bin。
- PaLM-E:tokenizer 不做整数特殊处理,作者改写 256 个最低频 token 作为 action 词表——这本质是 symbol tuning(重映射符号语义),先前在 VLM 上被验证可行。
Prompt 模版采用标准 VQA 形式:Q: what action should the robot take to [task instruction]? A:,输出限定为 action token 串。
Co-Fine-Tuning:防止灾难性遗忘的关键
朴素思路是直接 fine-tune VLM only on robot data,作者在 ablation 中证明这条路会丢失 emergent generalization。RT-2 的训练 batch 同时混入 robot trajectory 和原始 web vision-language 数据(VQA、captioning 等),并通过提高 robot dataset 采样权重平衡两者。直觉是:保留 web 任务作为 regularizer,让模型不忘记如何做语义/视觉推理。
Output Constraint:推理时若 prompt 是 robot-action 任务,decoder 仅在 256 个 action token 内采样;若是普通 VQA prompt,则放开整个自然语言词表。两种模式共存于一套权重。
Real-Time Inference
55B 模型显然无法 on-board。作者的 workaround:把模型部署到 multi-TPU cloud service,机器人通过网络 query。
- 55B PaLI-X:1–3 Hz
- 5B PaLI-X:~5 Hz
❓ 这里的 “real-time” 极其勉强。1–3 Hz 控制频率对 reactive contact-rich manipulation 远远不够,但对 pick-and-place + open-loop 子轨迹勉强可接受。这是 autoregressive action decoding 的结构性代价:生成 8 个 token 需要 8 次 forward pass,模型越大越慢。这一瓶颈是后续 π0/π0.5 用 flow matching 一次性输出整个 action chunk 的直接动机。
Experiments
实验设置
- 机器人:7-DoF mobile manipulator(Everyday Robots)
- Robot 数据:复用 RT-1 数据集(~130k episode),单臂 pick/place/move/drawer 等
- 评测规模:~6,000 trial,覆盖 seen tasks + 三类 unseen 泛化(object / background / environment)+ emergent 三类(symbol / reasoning / human recognition)
- Baselines:RT-1、VC-1、R3M、MOO 等
Q1. Seen + Unseen 泛化
Figure 3. 评测中使用的泛化场景示例(unseen object / background / environment,分 easy/hard 两档)。

Figure 4. Seen + 三类 unseen 上 RT-2 与 baseline 的整体表现。Seen 上 RT-2 与 RT-1 持平;unseen 上 RT-2 平均 ~2× 于 RT-1/MOO,~6× 于其他 baseline。
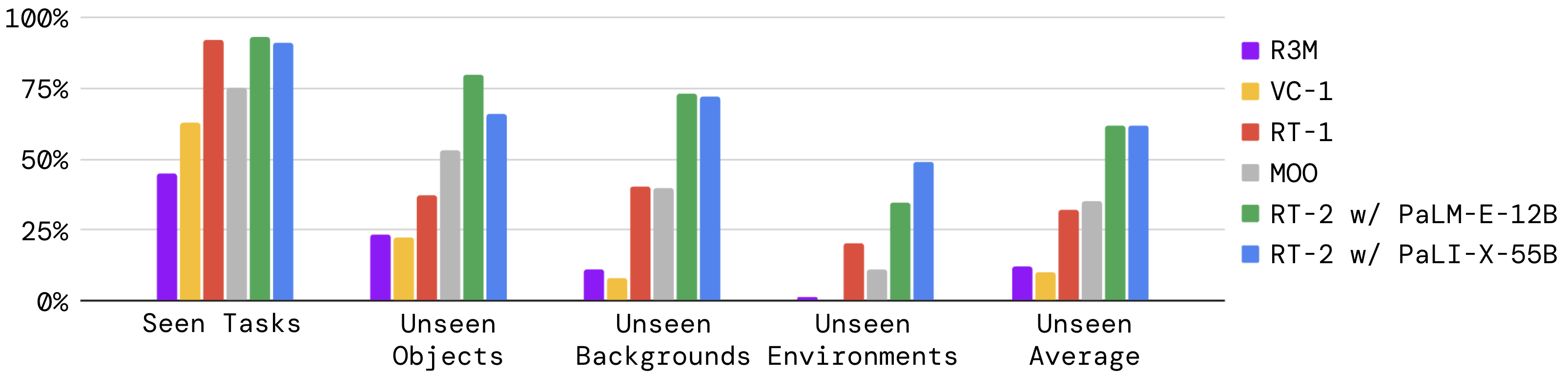
观察:seen task 上 RT-2 没有显著优势——VLM 体量没在熟悉任务上换来增益;真正的 gap 出现在三类 unseen 上,这恰恰是 web 预训练 prior 起作用的区域。两个 RT-2 instantiation 平均接近,PaLM-E 在 hard generalization 上略胜,PaLI-X 在 easy 上略胜。
Language-Table benchmark(开源仿真):用 PaLI-3B 同一 co-fine-tuning recipe 训出 ~5 Hz 策略,相对 baseline 也有显著提升,证明 recipe 不依赖于具体 backbone 体量和具体 robot platform。
Figure 5. Language-Table 真机 OOD 行为,使用相同 RT-2-PaLI-3B checkpoint。

Q2. Emergent Capability
把 emergent 能力划分为三类:
- Symbol understanding:robot 数据完全没出现的符号 / 文字,例如 “move apple to 3”、“push coke can on top of heart”
- Reasoning:颜色匹配 / 数学 / 多语言,例如 “move the apple to cup with same color”、“mueve la manzana al vaso verde”
- Human recognition:人物属性识别,如 “move the coke can to the person with glasses”
Figure 7(a). Emergent 三类任务上 RT-2 vs RT-1 / VC-1。RT-2-PaLI-X 平均 ~3× RT-1。
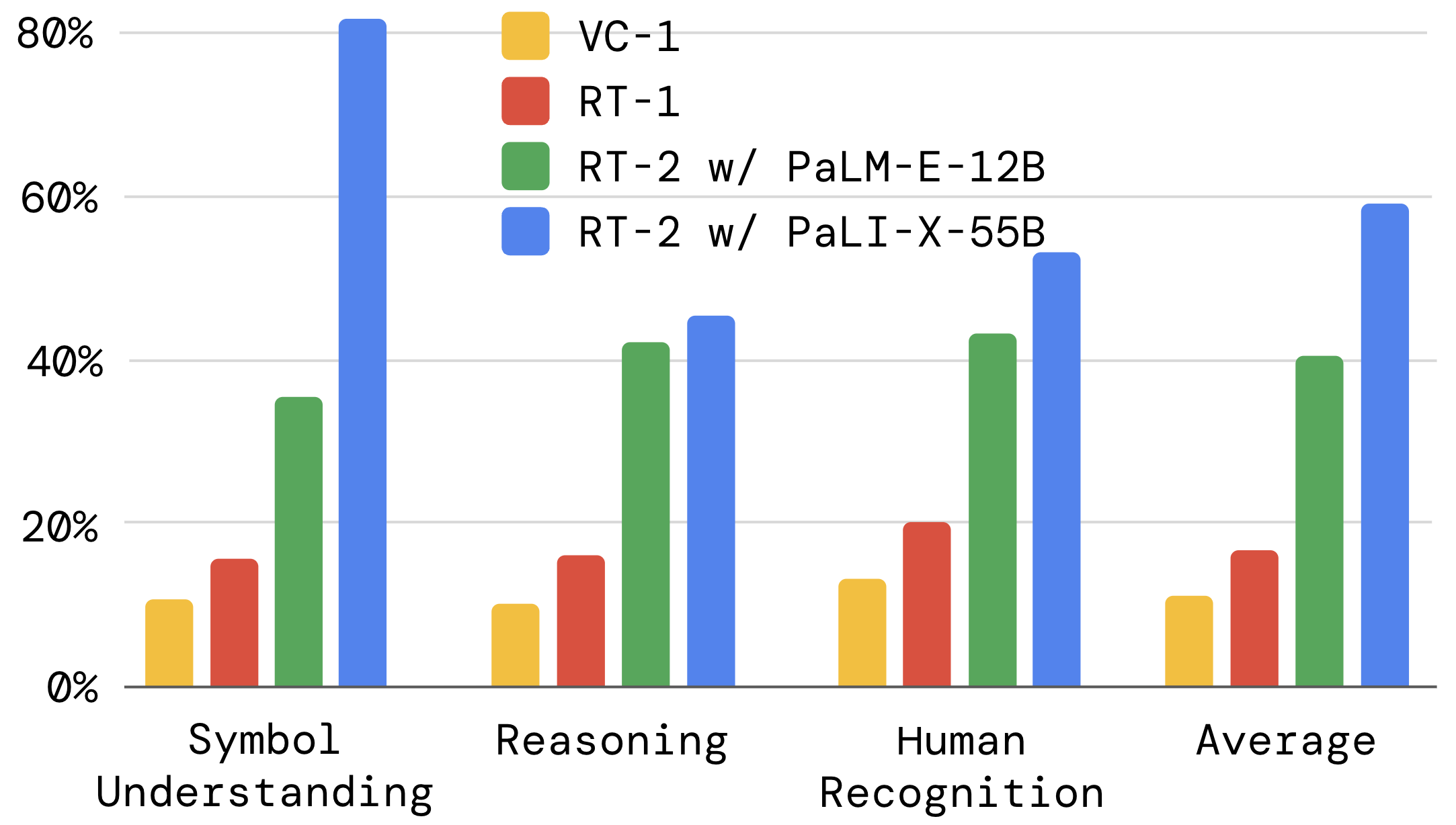
值得记的细节:PaLM-E 在数学推理子类上反超 PaLI-X,作者归因为预训练 mixture 不同——PaLM-E 见过更多文本/数学,PaLI-X 视觉权重更大。这个观察很关键:emergent capability 直接被 backbone 的预训练数据分布决定,VLA 的能力上限本质上是 VLM 的能力上限。
Q3. Scale + Co-fine-tuning Ablation
三种训练 routine ×(5B, 55B):
- From scratch(无 VLM 预训练)
- Fine-tune on robot data only
- Co-fine-tuning(默认,混 web + robot)
结论(Figure 7(b) / Appendix Table 5):
- From-scratch 5B 几乎不 work,55B 没必要再测
- Co-fine-tune > robot-only fine-tune(防灾难性遗忘)
- 模型越大泛化越好
这里其实回答了一个常被混淆的问题:“VLA 的 emergent 来自参数量还是来自预训练数据?” 答案是:参数量是必要的(5B from scratch 不行),但预训练数据的保留(通过 co-fine-tuning)才是 emergent 泛化的关键 trigger。
Q4. Chain-of-Thought 推理
把 RT-2-PaLM-E 在加了 “Plan: …” 的数据上再 fine-tune 几百步,例如:
Instruction: I'm hungry.
Plan: pick rxbar chocolate.
Action: 1 128 124 136 121 158 111 255.
模型获得了在生成 action 前先用自然语言规划的能力,能完成更复杂语义指令(“挑一个能当锤子的”→挑石头;“给疲惫的人选饮料”→挑能量饮料)。
Figure 8. RT-2 with chain-of-thought reasoning:模型先生成 Plan,再生成 action token。

这是把 LLM-as-planner 与 low-level policy 融合到单一模型的最早 demo 之一。后续 ECoT、Embodied-CoT 等工作沿着这条线展开。
Limitations(作者自陈 + 我的补充)
作者承认:
- 不会 emergent 出新 motion——physical skill 完全来自 robot data 的分布,web 数据贡献的是 “用旧 skill 应对新指令” 的能力
- 推理成本高——55B 即使 cloud 部署也只有 1–3 Hz;高频控制场景需要量化 / 蒸馏 / 更高效结构
- 可用 VLM 极少(2023 年)——希望更多开源 VLM 出现,或闭源 VLM 开放 fine-tune API
我的补充:
- 未开源——模型权重、Everyday Robots 数据、训练 mixture 比例都未公开,社区无法复现,这直接催生了 OpenVLA 用 Llama-2 7B + OXE 复现 RT-2 范式
- 单臂、固定 base——不涉及 bimanual / mobile manipulation / dexterous,action space 简单
- Action 离散化损失精度——256 bin per dim 对 6-DoF 增量来说够 pick-and-place,对接触丰富任务(插孔、剥皮)远不够;后续 FAST tokenizer / continuous flow matching 都在解这个问题
关联工作
基于
- RT-1 (Brohan et al., 2022): action 离散化方案、机器人数据集、evaluation 框架直接来自 RT-1
- PaLM-E: 12B backbone 之一,本身就是 embodied multimodal LM
- PaLI-X (Chen et al., 2023): 55B backbone,ViT-22B vision encoder
- Symbol Tuning (Wei et al., 2023): PaLM-E 复用最低频 token 作为 action 词表,本质是 symbol tuning
对比
- RT-1: 同数据、同任务,without VLM 预训练,是衡量 web prior 增益的核心 baseline
- VC-1 / R3M: 视觉表征预训练 + 小 policy head,对比”只有 vision pretrain” vs “vision-language pretrain”
- MOO: open-vocabulary object manipulation,同样借助 VLM 但只用于 perception
方法相关 / 后续影响
- OpenVLA: 用开源 Llama-2 7B + OXE 数据复现 RT-2 范式,并把权重 / 代码完全开源——是 RT-2 范式的开源 reference implementation
- π0 / π0.5 / π0.7: 沿用 VLM-backbone-as-VLA 的立场,但用 flow matching 替代 autoregressive token decoding 解决频率瓶颈
- OpenVLA-OFT: 在 OpenVLA 基础上引入 optimized fine-tuning(含连续 action head + chunked decoding),同样在反思 RT-2 离散 token 的成本
- ECoT / Embodied-CoT (后续工作): 把 RT-2 的 CoT 变体扩展为系统性方法
- VLA Domain Map: VLA 谱系演化的整体地图
论文点评
Strengths
- 范式奠基——首次清晰地展示 “VLM backbone + action-as-token + co-fine-tuning” 的完整 recipe。VLA 这个名词从此立住,所有后续 VLA 工作(OpenVLA、π0、Octo、RT-X、CogACT、ECoT…)都在这个 frame 下迭代。
- Recipe 极简——不引入新模块、不改架构,复用 VLM 全部权重和 tokenizer。“simple, scalable, generalizable” 的三性都满足,是非常好的 research taste 范例。
- Emergent 证据强——symbol understanding / human recognition 这些 robot 数据里完全没有的能力出现,给”web 知识能迁移到具身控制”提供了 6k trial 量级的实证支持,而不是 demo level handwaving。
- Co-fine-tuning ablation 很有信息量——明确隔离了”参数量”与”预训练知识保留”两个 confound,让后续工作知道 web data 必须留在 fine-tuning loop 里。
- Chain-of-thought 变体的小实验——只用几百 gradient step 就 elicit 出 plan-then-act 行为,启发后续 embodied reasoning 路线。
Weaknesses
- 完全闭源——权重、数据、训练细节、数据配比都不公开,社区只能”读论文”而不能”复现”。对一篇定义范式的论文来说,这是 community impact 的明显折扣。
- Action 表征的长期成本被低估——离散化 + autoregressive token decoding 既损精度又慢。论文把 1–3 Hz 称为 “real-time” 是 stretching;后续 flow matching / chunked action 的兴起本质是在偿还这个 design debt。
- Skill 不 emergent 这一点的解读偏轻——作者只用一句”data not varied enough along skills”带过,但这其实暴露了 imitation-learning-only paradigm 的根本天花板:VLM 知识只能让你”重新组合”已有 skill,不能让你”学会”新 skill。这指向 RL / 真实交互数据的必要性,论文没展开讨论。
- Baseline 比较略偏——主要 baseline RT-1 / VC-1 / R3M / MOO 都比 RT-2 体量小数十倍,2× / 6× 的提升里有多少来自”VLM 先验” vs “纯参数量” 没有完全 disentangle。Q3 ablation(55B vs 5B)部分回答了这点,但没有 fair-compute baseline。
- 泛化定义偏窄——“unseen object/background/env” 仍在同一个 Everyday Robots 环境下 pick-and-place,没有跨 embodiment、跨任务族的评测,无法直接断言 web 知识能迁移到所有场景。
可信评估
Artifact 可获取性
- 代码: 未开源
- 模型权重: 未发布
- 训练细节: 仅高层描述(Appendix E 有部分超参);数据配比、co-fine-tuning 比例细节未完全披露
- 数据集: 私有(Everyday Robots 内部数据集,基于 RT-1 收集流程);评测的 Language-Table 部分基于公开数据
Claim 可验证性
- ✅ 6k trial 上 unseen 泛化平均 ~2× RT-1/MOO:论文 Figure 4 + Appendix Table 3 给出 per-category 数值,与图一致;A/B testing 框架降低了方差。
- ✅ Emergent 三类任务 ~3× RT-1:Figure 7(a) + Appendix H.2 有 per-task 数据;RT-1 / VC-1 baseline 公开可复算。
- ✅ Co-fine-tuning > robot-only fine-tune:Q3 ablation 明确控制变量,结论稳。
- ⚠️ “Real-time” 1–3 Hz 控制:技术上是真的,但这个频率对很多操作任务不足以闭环;“real-time” 这个词在论文 framing 里偏 marketing。读者需要自己判断目标任务能否容忍。
- ⚠️ 55B 模型推理细节:cloud TPU 部署架构、网络延迟下的实际控制时序未给出可复现细节,外部复现只能猜配置。
- ⚠️ Chain-of-thought 变体的统计显著性:Q4 主要是定性 demo(Figure 8 + Appendix I),没有 quantitative success rate 对比,更像 proof of concept。
- ⚠️ PaLM-E 在数学推理上优于 PaLI-X 的归因:“different pre-training mixture” 是合理推测但未被实验隔离;可能也有规模 / 架构混淆。
Notes
- RT-2 是 VLA 领域的奠基性工作,确立了 “VLM backbone + action token” 的范式,所有后续 VLA 工作都可视为对 RT-2 三大设计 decision(action representation / co-fine-tuning / inference 部署)中某一项的改进。
- Mental model 更新:在思考 VLA 设计空间时,可以把 RT-2 当 “原点 (0,0,0)”——
- 沿 action representation 轴:discrete token → continuous regression → flow matching → diffusion
- 沿 training objective 轴:co-fine-tune SFT → +RL → +preference learning
- 沿 deployment 轴:cloud TPU → on-device 7B → distilled small model
- 未解决的关键问题:RT-2 没回答”VLM 知识到底以什么形式被 controller 用上的”。是 vision encoder 的 feature 重要?是 LM 的 commonsense?是 multimodal alignment?没有 mechanistic 实验。这给后续 interpretability / probing 工作留了空间。
- 个人判断:RT-2 的影响力主要在 framing 而不是在 technical content——它告诉社区 “把 VLM 当 controller 训” 是 valid path。这种 framing impact 通常比 method impact 更难复制,也更深远。
- 持续监测:随着 OpenVLA / π0 等更高效、更开放的 VLA 出现,RT-2 的实际复用价值在下降,但作为 mental anchor 仍然 building block 级别。
Rating
Metrics (as of 2026-04-24): citation=2821, influential=170 (6.0%), velocity=85.74/mo; HF upvotes=32; github=N/A (无代码仓库)
分数:3 - Foundation
理由:RT-2 首次把 “VLM backbone + action-as-token + co-fine-tuning” 的完整 recipe 做透(见 Strengths 1–2),并在 6k trial 上拿出 emergent 泛化的实证(Strengths 3),几乎定义了 “VLA” 这个子方向——所有后续开源范式(OpenVLA 明确自我定位为 “open reproduction of RT-2”、π0/Octo/RT-X 全部把 RT-2 当作 reference frame)都在修它的某一条设计轴,外部引用也稳居 1k+。不是 2 的原因:它不是某个当期 SOTA,而是整个 VLA 谱系的 reference frame;不降到 1 的原因:虽然未开源、且 autoregressive discrete token 已被 flow matching 超越(Weaknesses 1–2),但作为 mental anchor 和必读背景文献,其 framing impact 仍然持续。