Summary
OpenVLA: An Open-Source Vision-Language-Action Model
- 核心: 把 Prismatic-7B VLM (DINOv2+SigLIP+Llama-2) 在 970k OpenX 轨迹上做 next-token 微调,打开第一个真正开源、可复现、可微调的 generalist VLA
- 方法: 7-DoF 连续动作离散化为 256 bin、覆写 Llama tokenizer 末尾 256 个最少使用 token;fused DINOv2+SigLIP vision encoder(必须 unfreeze);27 epoch、64 A100 × 14 天
- 结果: 在 BridgeData V2 / Google Robot 共 29 个任务上比 RT-2-X (55B) 平均高 +16.5% absolute,参数仅 1/7;fine-tune 7 个 Franka 任务平均比 Diffusion Policy 高 +20.4%;LoRA (rank=32, 1.4% params) 与 full FT 平齐;int4 量化与 bfloat16 等效
- Sources: paper | website | github
- Rating: 3 - Foundation(第一个真正开源可复现的 7B VLA,成为整个 VLA 领域的 substrate 和 de facto baseline,后续工作普遍基于或对标它)
Key Takeaways:
- Open-source matters: 真正可复现的 7B VLA 把 RT-2-X 系列 closed-source 局面打破,整个社区围绕它开展 follow-up(OpenVLA-OFT、FAST tokenizer、OpenVLA-mini 等)
- Vision encoder 必须 unfreeze: 与 VLM 训练经验相反——frozen vision encoder 在 VLA 上掉 22.7%(69.7% → 47.0%),说明 Internet 视觉特征不够 fine-grained 以支撑精确控制
- VLA 需要超多 epoch: 27 epoch / action token accuracy > 95% 才停,远高于 LLM/VLM 的 1-2 epoch convention
- LoRA + 量化让 VLA 平民化: 单卡 A100 10-15 小时 LoRA 微调(vs 8 卡),int4 推理 7GB 显存(vs 16.8GB),且性能不掉
Teaser. OpenVLA 在 BridgeData V2 / Google Robot / Franka 三类平台上的 zero-shot 与 fine-tune 表现 overview。
1. Motivation
VLA 思路(直接把 VLM 当 robot policy 微调)已经被 RT-2 / RT-2-X 验证有效,但有两个落地瓶颈:
- 闭源:RT-2-X、PaLI 等的权重、架构细节、数据 mixture 全部不可见,社区无法复现也无法在自己的 robot 上 fine-tune
- 缺乏 fine-tune 最佳实践:模型太大(55B),如何在消费级 GPU 上做 efficient adaptation 完全是空白
OpenVLA 的研究问题:能否用 7B 量级的开源 VLM 训出比 55B 闭源 VLA 更强的 generalist policy,并提供完整的 fine-tune toolkit?
❓ “为什么 7B 能打 55B” 的本质——OpenVLA 给出的归因是 (a) 数据更多(970k vs 350k)+ 更细致清洗、(b) 更好的 vision backbone(DINOv2+SigLIP fused)。但 RT-2-X 并未开放,无法 controlled compare,这个对比里 confounder 很多。
2. The OpenVLA Model
2.1 Architecture
Figure 1. OpenVLA model architecture:vision encoder(DINOv2 + SigLIP concat)+ MLP projector + Llama-2 7B LLM。给定 image + language instruction,输出 7-DoF action token 序列。

三个组件:
- Vision encoder (600M):把 image patches 分别过 SigLIP 和 DINOv2,channel-wise concat。SigLIP 提供 semantic 特征,DINOv2 提供 spatial 特征——后者对机器人控制至关重要
- Projector:2-layer MLP,把视觉特征投影到 LLM embedding space
- LLM backbone:Llama-2 7B
底座是 Prismatic-7B VLM——OpenVLA 不从头训 VLM,而是 reuse Prismatic 已经在 LLaVA 1.5 ~1M image-text 数据上对齐好的版本。
2.2 Action Tokenization
把 7-DoF 连续动作转成离散 token:
- 每个 dimension 独立离散化为 256 bin
- bin 边界用训练数据中该维度的 1st / 99th quantile 之间均匀划分(不用 min-max——避免 outlier 撑大区间,损失精度)
- N 维 action 得到 N 个
[0, 255]的整数
Llama tokenizer 只为 fine-tune 预留了 100 个 special token,不够 256。OpenVLA 沿用 RT-2 的处理:直接覆写 Llama vocab 中最少使用的 256 个 token作为 action token。训练目标是标准 next-token prediction,只对 action token 算 cross-entropy loss。
❓ 覆写 tokenizer 末尾 token 是 hack——这些 “least used” token 真的不会被自然语言用到吗?这块对中文等 low-resource 语种应该有副作用,但论文未讨论。
2.3 Training Data
基础是 Open X-Embodiment 数据集(70+ datasets, 2M+ trajectories)。两步 curation:
- 统一输入输出空间:只保留含至少一个 third-person camera 且使用 single-arm end-effector control 的 manipulation dataset
- 平衡 mixture:直接复用 Octo 的 mixture weights(heuristically down-weight 低多样性数据集)
Table 3 (摘要). 训练 mixture 的主要权重(共 25 个 dataset,970k trajectories):
| Dataset | Weight |
|---|---|
| Fractal (RT-1) | 12.7% |
| Kuka | 12.7% |
| Bridge V2 | 13.3% |
| BC-Z | 7.5% |
| FMB Dataset | 7.1% |
| Stanford Hydra | 4.4% |
| Language Table | 4.4% |
| DROID | 10% (后 1/3 训练去掉) |
| …其余 17 个 dataset | < 3% each |
注意:DROID 加入时权重 10%,但 action token accuracy 始终上不去,最后 1/3 训练把它移除以保护最终模型质量。
💡 这条经验很有用:当某个高多样性 dataset 上 token accuracy 不收敛,强行混合反而拖累整体。可能需要更大模型或者更高权重。
2.4 关键 Design Decisions
通过在 BridgeData V2 上做小规模消融得出:
| Decision | 选择 | 关键观察 |
|---|---|---|
| VLM Backbone | Prismatic > LLaVA > IDEFICS-1 | LLaVA 比 IDEFICS-1 高 35%(多物体 language grounding 任务);Prismatic 再比 LLaVA 高 ~10%(归功于 DINOv2+SigLIP fused encoder 的 spatial reasoning) |
| Image Resolution | 224×224(不是 384×384) | 二者性能相同,但 384 训练时间 3x。与 VLM 不同——更高分辨率没带来 VLA gain |
| Vision Encoder | 必须 unfreeze | 与 VLM training 经验相反!frozen vision encoder 性能掉 22.7%。Internet pretraining 的视觉特征对精细机器人控制不够 |
| Training Epochs | 27 epochs(直到 action token acc > 95%) | LLM/VLM 通常 1-2 epoch;VLA 需要超多 epoch 才能 fit action distribution |
| Learning Rate | 2e-5 fixed (与 VLM 预训练相同),无 warmup | 跨多个数量级 sweep 后的最优 |
2.5 Infrastructure
- 训练:64 A100 × 14 天 = 21,500 A100-hours,batch size 2048
- 推理:bfloat16 下需 15GB GPU 内存,RTX 4090 上 ~6Hz(无 compile / speculative decoding)
- 提供 remote VLA inference server 实现:远程流式预测 action,机器人本地不需要强算力
3. Experiments
3.1 Direct Evaluation: Multi-Robot Out-of-the-Box
Figure 2. BridgeData V2 (WidowX) 评估:17 个任务 × 10 trial,覆盖 visual / motion / physical / semantic generalization 和 language grounding。OpenVLA 在所有类别(除 semantic generalization)超过 RT-2-X (55B)。

Figure 3. Google Robot 评估:12 个任务 × 5 trial。OpenVLA 与 RT-2-X 相当,显著超过 RT-1-X 和 Octo。

对比 baseline:
- RT-1-X (35M, from-scratch transformer, OpenX 子集训练)
- Octo (93M, 当时 SOTA 开源 generalist policy)
- RT-2-X (55B, closed-source VLA)
关键发现:
- BridgeData V2: OpenVLA 超 RT-2-X +16.5% absolute(参数 1/7)
- Google Robot: OpenVLA ≈ RT-2-X
- RT-2-X 仅在 semantic generalization(互联网未见过的物体/概念)上更强——因为它有 co-fine-tuning(机器人数据 + 互联网数据混训)保护预训练知识;OpenVLA 纯机器人数据 fine-tune
性能差异归因:(a) 970k vs 350k trajectories,(b) 数据清洗(如 Bridge 上过滤了 all-zero actions,详见 Appendix C),(c) DINOv2+SigLIP fused vision encoder。
3.2 Data-Efficient Adaptation: Fine-tune to Franka
Figure 4. Adapting to new robot setups:7 个 Franka 任务,10-150 demos each。比较 Diffusion Policy (from scratch) vs Octo (fine-tune) vs OpenVLA (fine-tune) vs OpenVLA (scratch, 即直接 fine-tune Prismatic 跳过 OpenX pretraining)。OpenVLA 在所有任务上 ≥ 50% 成功率,aggregate 最高。
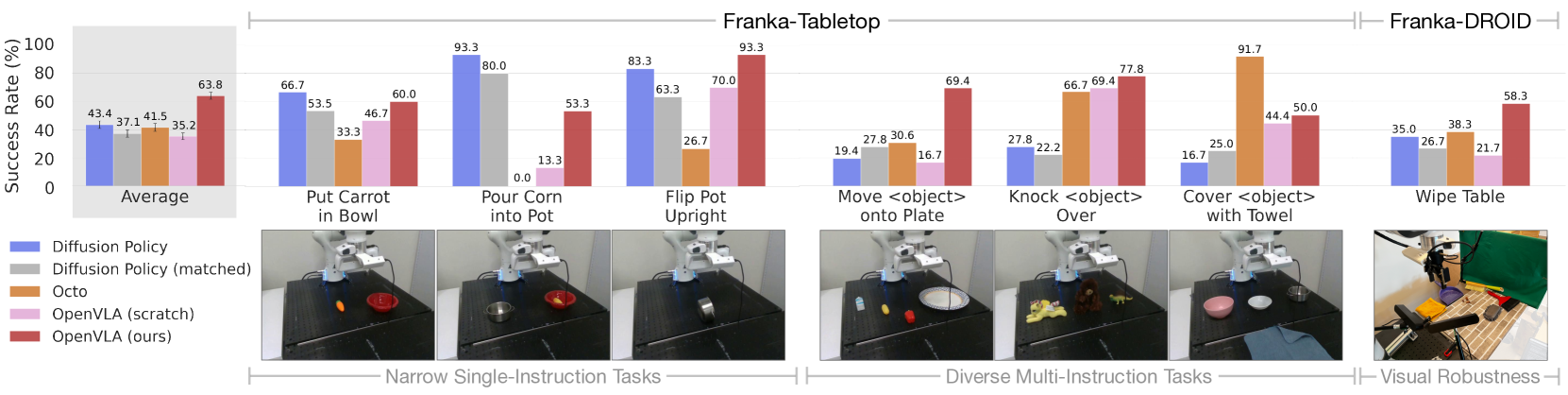
测试两个 setup:
- Franka-Tabletop: 5Hz 非阻塞控制器
- Franka-DROID: 15Hz,可移动支架
关键发现:
- 窄而专的 single-instruction 任务(如 Pour Corn into Pot): Diffusion Policy 仍然更胜,trajectories 更平滑精细
- 多物体 + language grounding 任务: pretrained generalist 显著占优——OpenVLA > Diffusion Policy by +20.4%
- OpenVLA (scratch, 无 OpenX pretraining) 在 diverse 任务上掉队,证明 OpenX pretraining 提供的 language grounding 是关键
💡 这构成了一个 trade-off:dexterity vs generalization。Diffusion Policy 的 action chunking + temporal smoothing 让它在窄任务更稳;OpenVLA 的 language conditioning 让它在 diverse 任务更强。后续 OpenVLA-OFT 正是把 action chunking + 连续 action head 融入 OpenVLA 来弥补 dexterity gap。
3.3 Parameter-Efficient Fine-Tuning
Table 1. Fine-tuning strategy 对比(Franka-Tabletop, batch size 16):
| Strategy | Success Rate | Train Params (×10⁶) | VRAM |
|---|---|---|---|
| Full FT | 69.7 ± 7.2 % | 7,188.1 | 163.3 GB (FSDP, 2 GPU) |
| Last layer only | 30.3 ± 6.1 % | 465.1 | 51.4 GB |
| Frozen vision | 47.0 ± 6.9 % | 6,760.4 | 156.2 GB (FSDP) |
| Sandwich (vision + last + embed) | 62.1 ± 7.9 % | 914.2 | 64.0 GB |
| LoRA, rank=32 | 68.2 ± 7.5 % | 97.6 | 59.7 GB |
| LoRA, rank=64 | 68.2 ± 7.8 % | 195.2 | 60.5 GB |
关键观察:
- Last layer / frozen vision 都不行——再次印证 vision encoder 必须 adapt
- LoRA rank=32 与 full FT 持平,但只训 1.4% 参数
- LoRA rank 在 32 vs 64 没差别——推荐默认 r=32
- 单 A100 GPU 10-15h 完成 fine-tune,相比 full FT 减少 8x compute
3.4 Memory-Efficient Inference: Quantization
Figure 5. OpenVLA 在不同 GPU 上的推理速度。bfloat16 与 int4 在 Ada Lovelace 架构(RTX 4090 / H100)上吞吐都很高。

Table 2. 量化对成功率的影响(8 个 BridgeData V2 任务,80 rollouts):
| Precision | Bridge Success | VRAM |
|---|---|---|
| bfloat16 | 71.3 ± 4.8 % | 16.8 GB |
| int8 | 58.1 ± 5.1 % | 10.2 GB |
| int4 | 71.9 ± 4.7 % | 7.0 GB |
反常发现:int4 与 bfloat16 性能持平甚至略高,显存只需 < 50%。int8 反而掉到 58.1%。
❓ int4 比 int8 好这个反常结果,论文未深入解释。可能是 int4 推理 pipeline (bitsandbytes 4-bit NF4) 与 int8 实现质量差异、或样本噪声所致。需要 follow-up 验证。
4. Limitations (作者承认)
- Single-image only:不支持多视角、proprio、history。真实机器人系统通常异构感知
- Inference frequency 不够:6Hz 远不够 ALOHA 50Hz 这类 dexterous bimanual 任务。需要 action chunking / speculative decoding 等加速
- 绝对成功率仍不高:跨任务 ~70% 上下,离工业可靠性距离尚远
- 缺乏理论指导:data mixture、objective、co-training 等关键设计还没有原理性结论
关联工作
基于
- Prismatic-7B VLM: OpenVLA 的 VLM backbone,提供 DINOv2+SigLIP fused vision encoder + Llama-2
- Llama-2 7B: LLM backbone,action token 通过覆写 vocab 末尾 256 个 least-used token 实现
- DINOv2 / SigLIP: 双视觉编码器,分别提供 spatial / semantic features
- RT-2: 直接继承 action discretization scheme(256-bin per dim, vocab override)和 “VLA = next-token prediction” formulation
- Open X-Embodiment: 970k 训练 trajectories 的来源
- LLaVA 1.5: Prismatic 预训练用的 vision-language data mixture
对比
- RT-2-X (55B, closed): 主要对比对象,OpenVLA 用 1/7 参数超越(除 semantic generalization)
- RT-1-X (35M, from-scratch transformer): 不带 internet pretraining 的 baseline
- Octo (93M): 当时 SOTA 开源 generalist policy,对比 fine-tune 表现
- Diffusion Policy: 数据高效 imitation learning baseline,在窄任务仍胜 OpenVLA
方法相关
- LoRA: PEFT 方法,rank=32 即可与 full FT 持平
- bitsandbytes int4 (NF4): 推理量化,与 bfloat16 性能等效
- FSDP / Flash-Attention / AMP: 训练 infra
- OpenVLA-OFT (2025-03): 后续工作,引入 continuous action head + parallel decoding,推理快 25-50x,弥补 OpenVLA 的 dexterity 与 frequency 短板
- FAST tokenizer (2025-01): Physical Intelligence 的后续,把 action chunk 压缩成更少 token,推理快 15x
- π0: 同期/后续 VLA 路线(flow matching + continuous action),与 OpenVLA 形成 discrete vs continuous action 的两条主线对比
论文点评
Strengths
- 真正完整的开源:模型权重 + 训练代码 + fine-tune notebook + 推理 server + 数据 mixture——一篇论文把”复现”和”adapt 到自己机器人”两个最大障碍同时打掉,社区影响力巨大(CoRL 2024 Outstanding Paper Finalist 实至名归)
- 设计决策的 ablation 很扎实:vision encoder unfreeze、resolution 224、27 epoch、quantile-based discretization——每条都对应一个 counter-intuitive 选择 + 实证支撑,且与 VLM 经验对比着讲,对后续做 VLA 的人是直接 transferable 的”how-to”
- DINOv2+SigLIP fused vision encoder 的设计对 spatial reasoning 的强调是个 generalizable 的 takeaway
- PEFT + 量化的可行性 第一次系统验证:LoRA rank=32 与 full FT 持平 + int4 推理无损,让 7B VLA 真的可以在消费级硬件上 deploy。这比 method paper 本身的 contribution 更影响生态
Weaknesses
- 与 RT-2-X 的对比不够公平:参数数量、数据量、训练数据 mixture 都不同,无法 isolate “model size” vs “data quality” vs “vision encoder” 各自的贡献。Appendix D 的 ablation 也没法完全 controlled
- Action 离散化是个 known bottleneck:256-bin uniform 限制了精细动作。后续 FAST tokenizer、OpenVLA-OFT 的 continuous head 都在补这个洞——说明这是核心方法层面的局限
- 6Hz 推理速度不够 dexterous 任务:ALOHA / 双臂任务直接 out of scope。这制约了 OpenVLA 能解决的任务集
- co-fine-tuning 缺失:纯机器人数据微调导致 semantic generalization 弱于 RT-2-X(保留互联网知识)。这是个明显可改进点但作者未做
- DROID 拒绝拟合的问题没有深挖:直接从 mixture 里去掉而不是分析 why——这是个有 information value 的 negative result,被回避了
可信评估
Artifact 可获取性
- 代码: ✅ 完整开源(inference + LoRA fine-tune + full fine-tune + remote serving + training from scratch)
github.com/openvla/openvla - 模型权重: ✅
openvla/openvla-7b(旗舰,DINOv2+SigLIP+Llama-2 + Open-X Magic Soup++ mixture)+openvla/openvla-7b-v01(早期 SigLIP-only + Vicuña 1.5)。HuggingFace 直接拉取 - 训练细节: ✅ 完整披露——超参(lr 2e-5, batch 2048, 27 epoch)、infra(64 A100 × 14d)、data mixture weights(Appendix A)
- 数据集: ✅ Open X-Embodiment 全开源(含 Bridge、Fractal、DROID 等子数据集)
Claim 可验证性
- ✅ OpenVLA 7B > RT-2-X 55B by +16.5% absolute on BridgeData V2:170 rollouts × A/B 比较,task setup 与 BridgeData V2 evaluations 齐名,可信。但因为 RT-2-X 闭源,无法 isolated 复现这个 delta
- ✅ Fine-tune > Diffusion Policy +20.4% on diverse Franka tasks:129 rollouts,A/B 对照,控制公平
- ✅ LoRA rank=32 与 Full FT 持平 (68.2 vs 69.7):Table 1,33 rollouts,可独立 LoRA fine-tune 验证
- ✅ int4 量化与 bfloat16 性能等效 (71.9 vs 71.3):80 rollouts,可独立验证(虽然 int4 > bfloat16 这个反常需小心解读)
- ⚠️ “DINOv2+SigLIP fused encoder 提升 spatial reasoning”:归因正确性受限——只与 SigLIP-only Prismatic 比,没有控制 DINOv2-only 或 CLIP+DINOv2 等替代组合
- ⚠️ “OpenVLA 在 motion/physical generalization 强是因为数据多+清洗+vision encoder”:三因素同时变化,归因混淆
- ⚠️ “action token accuracy > 95% 即性能饱和”:作为停训信号合理,但 95% 这个具体阈值是 empirical heuristic,非 principled
- ❌ 无明显营销话术,论文措辞总体克制
Notes
- OpenVLA 可以看作 VLA 的 “BERT moment”——之后 VLA 的研究范式(discretize action / fine-tune VLM / 在 OpenX 上预训练)很大程度上 anchor 在它的设计上
- 要追问的开放问题:
- Action discretization 的极限在哪? 256-bin uniform 是否限制了 dexterous 任务?continuous head(OpenVLA-OFT、π0)的 trade-off 是什么?
- Co-fine-tuning(机器人 + 互联网数据) 在多大规模下值得?OpenVLA 没做但理论上可补 semantic generalization 的短板
- VLA scaling law:data / params / epochs 三者关系?DROID 拟合不上是 model 太小还是 mixture weight 太低?这个 negative result 值得重做
- 与我研究方向的连接:spatial intelligence 角度看,DINOv2+SigLIP fused encoder 是个明确 takeaway——纯 CLIP/SigLIP 对机器人控制空间感不够。这个 design pattern 应该可以迁移到 VLN 和 spatial reasoning 任务
Rating
Metrics (as of 2026-04-24): citation=1973, influential=332 (16.8%), velocity=88.48/mo; HF upvotes=47; github 5978⭐ / forks=708 / 90d commits=0 / pushed 396d ago · stale
分数:3 - Foundation 理由:OpenVLA 是 VLA 方向的 substrate-level 工作——Strengths 中的”真正完整开源 + LoRA/int4 可行性第一次系统验证”让它从 method 升级为 infra;关联工作显示几乎所有后续 VLA 论文(OpenVLA-OFT、π0、FAST、SmolVLA 等)都把它作为基础架构或 de facto baseline。区别于 2-Frontier:它已经过了”前沿竞争”阶段,成为范式本身(discretize action / fine-tune VLM / OpenX pretrain),GitHub 6k+ star、CoRL 2024 Outstanding Paper Finalist 及持续被引证实其奠基地位,而非一时 SOTA。