Summary
PaLM-E: An Embodied Multimodal Language Model
- 核心: 将连续传感器信号直接注入 LLM embedding 空间,构建统一的 embodied multimodal 模型
- 方法: 多模态 token 与文本 token 交错形成 multi-modal sentences,端到端训练 encoder + PaLM LLM
- 结果: 单一 562B 模型同时完成机器人规划、VQA、captioning,OK-VQA SOTA,且跨任务 positive transfer
- Sources: paper | website
- Rating: 3 - Foundation(将连续感知直接注入 LLM token 空间的开创性工作,定义了 VLM→VLA 的范式,是后续 RT-2 / OpenVLA 等的必引祖师爷)
Key Takeaways:
- Multi-modal sentences: 将视觉/状态/文本 token 交错形成统一输入序列,LLM 以完全相同的方式处理连续和离散 token
- Positive transfer: 跨机器人域 + 视觉语言数据联合训练显著提升各单域性能,少样本场景下效果尤为突出
- Scaling 减少灾难性遗忘: 562B 规模下,多模态微调仅损失 3.9% 原始语言能力(12B 损失 87.3%),且涌现 zero-shot multimodal CoT 等新能力
Teaser. PaLM-E 能力总览——跨机器人形态的任务规划、VQA、captioning、zero-shot CoT 推理
Introduction
LLM 在对话、推理、代码生成等任务上展现了强大能力,但在真实世界推理中面临 grounding 挑战——纯文本训练的 LLM 无法直接理解视觉场景的几何构型。现有方法(如 SayCan)通过外部 affordance function 间接连接 LLM 与感知,但 LLM 本身仍只接收文本输入。
PaLM-E 的核心思路是直接将连续感知信号注入 LLM 内部,使 LLM 本身成为 grounded 的决策模型。关键贡献:
- 提出 embodied language model,将连续传感器模态直接嵌入 LLM token 空间
- 证明当前通用 VLM 无法直接解决 embodied reasoning 任务
- 引入 OSRT(Object Scene Representation Transformer)等 neural scene representation 作为输入
- PaLM-E-562B 是 SOTA 视觉语言通用模型(OK-VQA),同时保持语言能力
- Scaling 模型规模可减少多模态微调导致的灾难性遗忘
PaLM-E: An Embedded Multimodal Language Model
PaLM-E 的核心架构思想:将连续 embodied observation(图像、状态估计等)编码为与文本 token 同维度的向量序列,以 “multi-modal sentences” 的形式注入 decoder-only LLM。
Figure 1. PaLM-E 架构——多模态 token 与文本 token 交错形成 multi-modal sentences
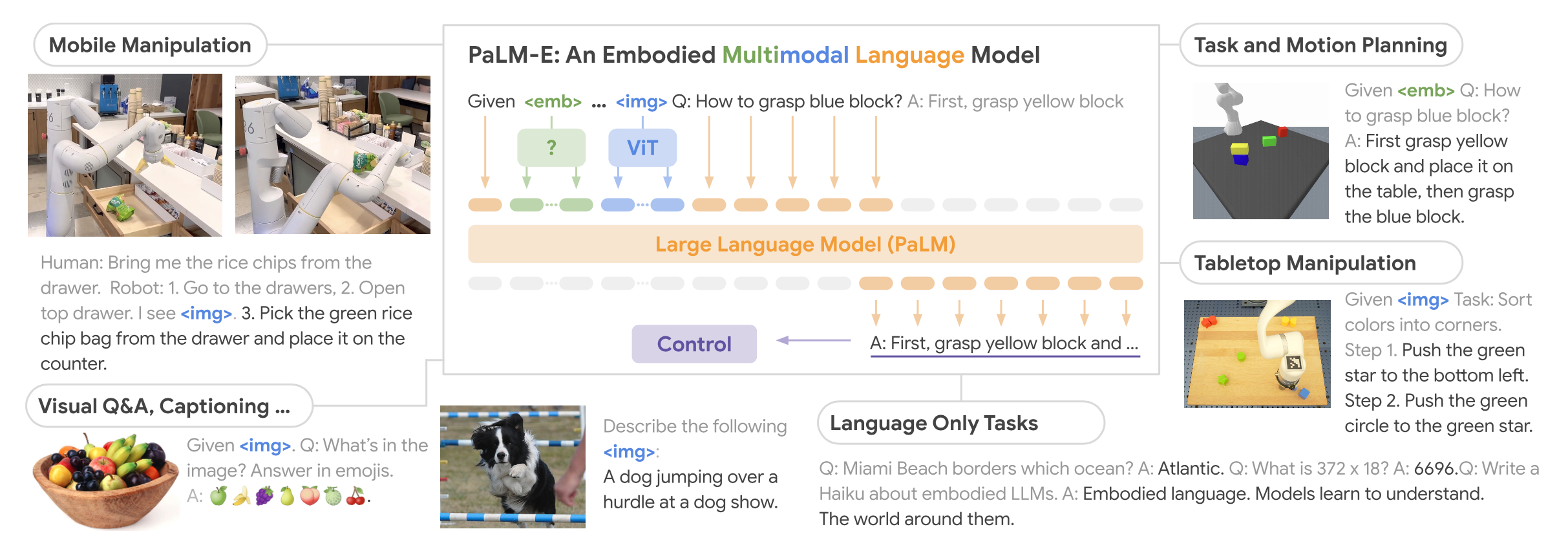
模型的输入是 text 和 observation 交错的序列。例如一个 multi-modal sentence 为 Q: What happened between <img_1> and <img_2>?,其中 <img_i> 是图像的 embedding 序列。
Equation 1. Autoregressive LLM
Equation 3. Multi-modal token embedding
符号说明: 是 word token embedder, 是将连续 observation 映射到 embedding 空间的 encoder。 含义: 每个 prefix 位置的向量要么来自文本 token 的 embedding,要么来自 encoder 对连续 observation 的编码。observation embedding 不是插入固定位置,而是动态嵌入在文本上下文中。
Embodying the output: 机器人控制回路。PaLM-E 生成的文本被解析为 low-level policy 的语言指令。当任务需要规划时,模型输出一系列 high-level step(如 “1. Go to drawers. 2. Open top drawer.“),由 low-level policy 逐步执行。每步执行后,新的视觉观测被重新输入 PaLM-E 进行 replanning,形成 closed-loop 控制。
Input & Scene Representations for Different Sensor Modalities
PaLM-E 探索了多种将不同模态映射到 LLM embedding 空间的 encoder :
- State estimation vectors: 最简单的输入——机器人状态向量 (位姿、尺寸、颜色等),通过 MLP 映射到 embedding 空间
- Vision Transformer (ViT): 将图像 映射为 token embedding 序列 。使用 ViT-4B 和 ViT-22B 两种规模。由于 ViT 的 embedding 维度与 LLM 不同,需要一个 learned affine projection
- Object-centric representations: 将视觉输入分解为独立物体的 token。给定 ground-truth instance mask ,ViT 对 masked 图像编码得到每个物体的表示
- OSRT (Object Scene Representation Transformer): 无需 ground-truth segmentation,通过 inductive bias(slot attention)以无监督方式发现 object slots,学习 3D-centric neural scene representation。每个 object slot 被投射为多个 embedding
Entity referrals: 对于 object-centric 表示(如 OSRT),在 prompt 中标注 Object 1 is <obj_1>. ... Object j is <obj_j>.,使 PaLM-E 能在生成的 plan 中通过 obj_j token 引用特定物体。
Training Recipes
PaLM-E 基于预训练的 PaLM(8B、62B、540B)作为 decoder-only LLM,加上预训练或从头训练的 encoder。模型变体:
- PaLM-E-12B = 8B PaLM + 4B ViT
- PaLM-E-84B = 62B PaLM + 22B ViT
- PaLM-E-562B = 540B PaLM + 22B ViT
训练使用 cross-entropy loss,仅对 non-prefix text token 计算。
Co-training across tasks: “Full mixture” 包含多种 internet-scale 视觉语言数据和机器人数据。机器人数据仅占 8.9%,其余为 WebLI、VQA、COCO 等通用数据。
Model freezing: 探索是否可以 freeze LLM 只训练 encoder——这可以理解为一种 input-conditioned soft-prompting。Freeze LLM 可保留原始语言能力,但在某些机器人任务上性能略低于 full finetuning。
Experiments
PaLM-E 在三个机器人域(TAMP、Language-Table、Mobile Manipulation)和通用视觉语言/语言任务上评估。
Robot Environments / Tasks
三个机器人环境:
- TAMP (Task and Motion Planning): 在模拟中,机器人需要 grasp/stack 物体,规划涉及复杂组合和多步决策
- Language-Table: 多物体桌面推动任务,使用真实世界 + 模拟数据,PaLM-E 集成在 control loop 中
- Mobile Manipulation: 移动机器人在厨房中导航、找物品、取物品,类似 SayCan 设置。Low-level policy 来自 RT-1
TAMP Environment
Table 1. 不同输入表示在 TAMP 环境的对比(1% 数据,320 examples)
| Object-centric | LLM pre-train | q1 | q2 | q3 | q4 | p1 | p2 | |
|---|---|---|---|---|---|---|---|---|
| SayCan (oracle afford.) | ✓ | ✓ | - | - | - | - | 38.7 | 33.3 |
| PaLI (zero-shot) | ✓ | ✓ | - | 0.0 | 0.0 | - | - | - |
| State | ✓(GT) | ✗ | 99.4 | 89.8 | 90.3 | 88.3 | 45.0 | 46.1 |
| State | ✓(GT) | ✓ | 100.0 | 96.3 | 95.1 | 93.1 | 55.9 | 49.7 |
| ViT-4B single robot | ✗ | ✓ | - | 45.9 | 78.4 | 92.2 | 30.6 | 32.9 |
| ViT-4B full mixture | ✗ | ✓ | - | 70.7 | 93.4 | 92.1 | 74.1 | 74.6 |
| OSRT | ✓ | ✓ | 99.7 | 98.2 | 100.0 | 93.7 | 82.5 | 76.2 |
Insights: OSRT 表现最佳,展示了 3D-aware object representation 的优势。ViT-4B 在 full mixture 下性能翻倍以上(p1: 30.6→74.1),是 cross-domain transfer 的直接证据。PaLI 零样本完全无法解决规划任务。
Language-Table Environment
联合训练 + full mixture 对少样本机器人规划帮助显著。仅 10 个 demo 的情况下,full mixture + LLM frozen 可达 70% 成功率(单机器人数据仅 20%)。从 12B 到 84B 在 2/3 任务上进一步提升。
Mobile Manipulation Environment
Table 4. Mobile manipulation: failure detection 和 affordance prediction (F1)
| Failure det. | Affordance | |
|---|---|---|
| PaLI (Zero-shot) | 0.73 | 0.62 |
| CLIP-FT-hindsight | 0.89 | - |
| QT-OPT | - | 0.63 |
| Single robot (pretrain, frozen) | 0.91 | 0.78 |
| Full mixture (pretrain, finetune) | 0.91 | 0.87 |
| Full mixture (pretrain, frozen) | 0.77 | 0.91 |
Insights: PaLM-E 在 failure detection 和 affordance prediction 上超越 PaLI、CLIP-FT 和 QT-OPT。Full mixture 的 transfer 效果明显。
Video. Long-horizon mobile manipulation: “Bring me the rice chips from the drawer”
Video. Generalization to unseen objects: “Bring me the green star”
Performance on General Visual-Language Tasks
Table 5. 通用视觉语言任务结果
| Model | VQAv2 test-dev | OK-VQA | COCO Karpathy |
|---|---|---|---|
| PaLM-E-12B (generalist) | 76.2 | 55.5 | 135.0 |
| PaLM-E-562B (generalist) | 80.0 | 66.1 | 138.7 |
| Flamingo (task-specific) | 82.0 | 57.8† | 138.1 |
| PaLI (task-specific) | 84.3 | 64.5 | 149.1 |
| PaLM-E-12B (task-specific) | 77.7 | 60.1 | 136.0 |
| PaLM-E-12B frozen | 70.3 | 51.5 | 128.0 |
Insights: PaLM-E-562B 在 OK-VQA 上以 66.1 分取得 SOTA(32-shot,无 task-specific finetuning),超越 PaLI 的 64.5。作为 generalist 模型同时在机器人任务上也表现优异。
Performance on General Language Tasks
Scaling 对保持语言能力至关重要:
- PaLM-E-12B (unfrozen): NLG 性能仅保留 12.7%(相对于 PaLM-8B 下降 87.3%)
- PaLM-E-562B (unfrozen): NLG 性能保留 96.1%(仅下降 3.9%)
这表明模型规模越大,多模态微调导致的灾难性遗忘越轻。
Summary of Experiments & Discussion
Generalist vs specialist — transfer: PaLM-E 在多域联合训练时,各单域性能显著优于单独训练。这种 positive transfer 在少样本场景尤为显著(full mixture 可将 TAMP 规划性能从 ~43% 提升至 ~95%)。
Data efficiency: 机器人数据稀缺,但 transfer 使得 PaLM-E 可从极少样本(Language-Table 10-80 demos、TAMP 320 examples)中学会规划。OSRT 的几何输入进一步提升数据效率。
Retaining language capabilities: Freeze LLM 或 scale up model 都可以减少灾难性遗忘。Freeze 方案在某些任务上略逊于 full finetune,但完整保留语言能力。Scale up 是更有前途的路线——562B 模型 finetune 后仅损失 3.9% 语言性能。
Emergent capabilities: PaLM-E-562B 涌现了 zero-shot multimodal chain-of-thought reasoning、OCR-free math reasoning、multi-image reasoning 等能力,尽管仅在 single-image 数据上训练。
关联工作
基于
- PaLM: 540B 参数的 decoder-only LLM,PaLM-E 的语言模型 backbone
- ViT: Vision Transformer 作为视觉 encoder(ViT-4B 和 ViT-22B 两种规模)
- OSRT: Object Scene Representation Transformer,提供 3D-aware neural scene representation
- RT-1: Mobile manipulation 实验中使用的 low-level policy
对比
- SayCan: 通过 affordance function 间接 grounding LLM,PaLM-E 证明直接注入感知信号更优
- PaLI: 通用 VLM baseline,在机器人规划任务上零样本完全失败
- Flamingo: VLM baseline,OK-VQA 和 COCO 上与 PaLM-E 对比
- Frozen (Tsimpoukelli et al., 2021): 最接近的前期工作——freeze LLM 训练视觉 encoder,PaLM-E 在 VQAv2 上超越其 45%
方法相关
- VIMA: 使用 multimodal prompt 进行机器人操作,与 PaLM-E 的 multi-modal sentence 思路相似
- Gato: 同为 generalist multi-embodiment agent,但 PaLM-E 展示了更强的 positive transfer
- RT-2: 直接继承 PaLM-E 的 “感知注入 LLM” 思路,进一步让 LLM 直接输出 action token,成为 VLA 范式的正式起点
论文点评
Strengths
- 统一架构设计: 用 multi-modal sentences 将异构模态统一到 LLM token 空间,方法简洁优雅,充分利用 LLM 的 in-context learning 能力
- Positive transfer 的系统验证: 在三个不同机器人域上一致地验证了跨域训练的正收益,实验设计全面(ablation 覆盖 input representation、model scale、freeze vs finetune、data mixture)
- OSRT 输入表示: 引入 3D-aware neural scene representation 作为 LLM 输入,在数据效率和 out-of-distribution 泛化上表现最佳,是一个有启发的架构选择
- Scaling insight: 量化了模型规模与灾难性遗忘的关系,562B 模型几乎无损保留语言能力,为构建 generalist embodied model 指明了 scaling 路线
Weaknesses
- Action 生成间接性: PaLM-E 仅生成高层文本指令,依赖预定义的 low-level policy 执行具体动作——不是端到端的 VLA,中间的语言瓶颈限制了精细控制
- 计算资源门槛: 562B 参数的模型极难复现和部署,关键的 scaling 结论(低灾难性遗忘、涌现能力)仅在最大规模上显著
- 机器人实验定性为主: Mobile manipulation 结果主要是定性视频展示,缺乏大规模定量 benchmark 和统计显著性报告
- OSRT 依赖: 最佳表示 OSRT 需要在 in-domain data 上训练 scene representation,限制了在新环境中的即插即用能力
可信评估
Artifact 可获取性
- 代码: 未开源
- 模型权重: 未发布
- 训练细节: 仅高层描述(loss function、data mixture 比例、model size 配置有详细说明;具体训练步数、learning rate 等超参部分缺失)
- 数据集: 部分公开(Language-Table 数据集公开,TAMP 环境可复现;mobile manipulation 数据来自内部;vision-language 数据主要使用公开数据集)
Claim 可验证性
- ✅ OSRT 是最优输入表示: Table 1 的 ablation 系统覆盖了 state / ViT / ViT+TL / OSRT,在 VQA 和 planning 任务上 OSRT 一致最优
- ✅ Cross-domain transfer 有正收益: Figure 3、Table 1 (ViT-4B single vs full mixture)、Table 2 均一致显示 full mixture 显著优于 single domain
- ✅ OK-VQA SOTA: Table 5 中 PaLM-E-562B 达到 66.1 (32-shot),数字可查证
- ⚠️ 562B 灾难性遗忘仅 3.9%: 仅有 PaLM-E-562B 一个数据点验证,且 NLU/NLG 分别表现不同(NLU 仅 +0.4%,NLG -3.8%),未报告 confidence interval
- ⚠️ Mobile manipulation real robot 能力: 主要以视频定性展示,无大规模统计定量数据支持
Notes
Rating
Metrics (as of 2026-04-24): citation=2564, influential=108 (4.2%), velocity=68.19/mo; HF upvotes=0; github=N/A (无代码仓库)
分数:3 - Foundation 理由:PaLM-E 是 “把连续感知直接注入 LLM token 空间” 的奠基工作,在 embodied AI / VLA 方向是无可绕过的必读——它定义的 multi-modal sentence 范式被 RT-2、OpenVLA、π0.5 等后续 VLA 工作直接继承,positive transfer 与 scaling 减轻灾难性遗忘两个发现被反复在后续工作中引用。相比 rating=2,它的方法范式并未过气反而被行业标准化(区别于一次性 SOTA),且作为 SayCan 之后、VLA 出现之前的关键过渡,理解这个方向历史的 pipeline 绕不开它。