Summary
Do As I Can, Not As I Say: Grounding Language in Robotic Affordances
- 核心: 用一组预训练低层 skill 的 value function(“Can”)去约束 LLM(“Say”)对高层自然语言指令的规划,使 LLM 只在”有用 × 可执行”的交集里选下一步技能。
- 方法: 对每个候选 skill 计算 LLM 打分 (task-grounding)和 affordance (world-grounding,来自 TD-trained Q-function),取乘积 argmax,执行后把已选 skill 追加回 prompt,迭代直到 “done”。
- 结果: 在真实 mobile manipulator 上 101 条厨房指令,PaLM-SayCan 规划成功率 84%、执行成功率 74%;显示”换更强的 LLM(PaLM > FLAN)直接带来机器人性能提升”,首次把 LLM scaling 映射到 embodied 任务。
- Sources: paper | website | github
- Rating: 3 - Foundation(LLM+robotics 范式的奠基接口论文,定义了此后两年 embodied planning 的主流组合)
Key Takeaways:
- Affordance-as-prior 的概率分解: 把 “这个 skill 对 instruction 是否有用” 拆成 “LLM 相关性 × 价值函数可行性”,几乎免费地给 LLM 加上一层 world grounding,且在 zero-shot 下工作——不需要 fine-tune LLM,也不需要新的 multimodal 接口。
- Scoring 而非 generation: 不从 LLM 采样自由文本,而是对有限 skill vocabulary 打分,直接回避 open-ended generation 带来的 “不可执行动作” 问题;让 LLM 的长尾知识被安全地投影到有限动作空间。
- Value function = affordance: 稀疏奖励(成功=1/失败=0)下 RL 学到的 Q 值在概率语义上就是 “skill 在当前状态下成功的概率”,这一观察把 RL 产物直接嫁接到 LLM planner,打通了 “语言规划 ↔ 视觉-控制” 两层。
- LLM 规模单调地改善机器人: PaLM-SayCan vs FLAN-SayCan:plan 84%→70%,execute 74%→61%。LLM side 的改进几乎一对一地传导到 embodied side——这是全文最具范式意义的 claim。
- 失败分布: 101 task 中 65% 错误来自 LLM、35% 来自 affordance;长程指令(15 条)execution 仅 47%,反映”当前决策步”开环范式对级联失败无纠错。
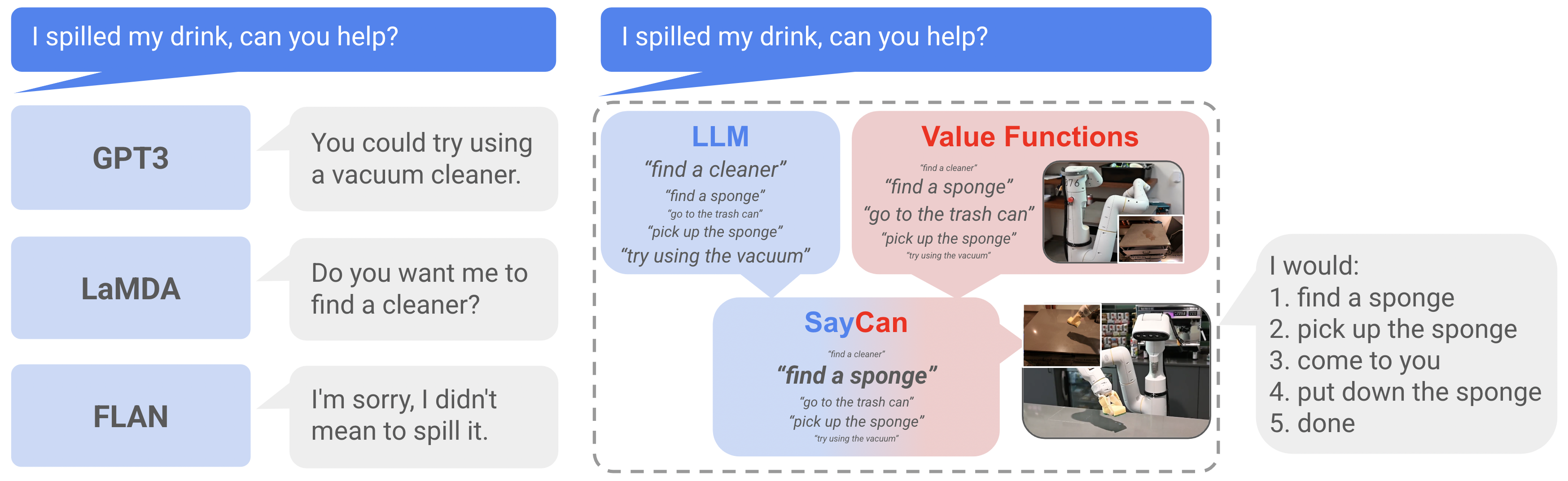
Teaser. Project page 概览视频:真实厨房下 SayCan 连贯完成 “spill + clean”、“bring drink & snack” 等长程指令。
Intro 示意图:LLM 本身不与环境交互,因此其建议可能在当前 embodiment 下不可执行;SayCan 用 pretrained skills 的 value function 做 grounding。
1. 问题设定
系统接受用户的一条高层自然语言指令 (长、抽象、歧义均可)。机器人手里有一个 skill library ,每个 skill 附带:
- 一条短文本描述 (如 “find a sponge”);
- 一个 affordance function ——在状态 下执行 成功的概率,等价于稀疏奖励 RL 的 value function。
LLM 提供的是 :给定用户指令,某 skill 文本描述作为下一步的 likelihood。论文要的目标量是 ——选 后真实推进 的概率。
在”成功 skill 以 的概率推进 instruction,失败 skill 概率为 0”的假设下:
❓ 这个分解隐含一个强假设:skill 成功 ⇒ 有意义推进指令。对 “成功执行了但选错 skill”(如错拿 coke 而不是 sponge)它自动给 0 贡献——但 policy 不会知道自己 “选错了”,只要语义层面执行成功就会被当作 。这个差异在 “NL Nouns” family 上较明显(67% plan),名词空间大时 LLM 的 区分度下降,乘 affordance 也救不回来。
2. SayCan 算法
两侧信号:
- Say:对每个 skill 描述 ,用 LLM 做 scoring(不是 generation)拿到 ,其中历史 skill 以 “I would: 1. … 2. …” 形式拼入 prompt。
- Can:用每个 skill 的 value function 在当前 state 打分,得 。
迭代:
执行 ,更新 ;把 追加进 prompt;重复直到 “done”。
核心图示:Value function score(红)与 LLM score(蓝)相乘得到 combined score(绿),argmax 定下一步。
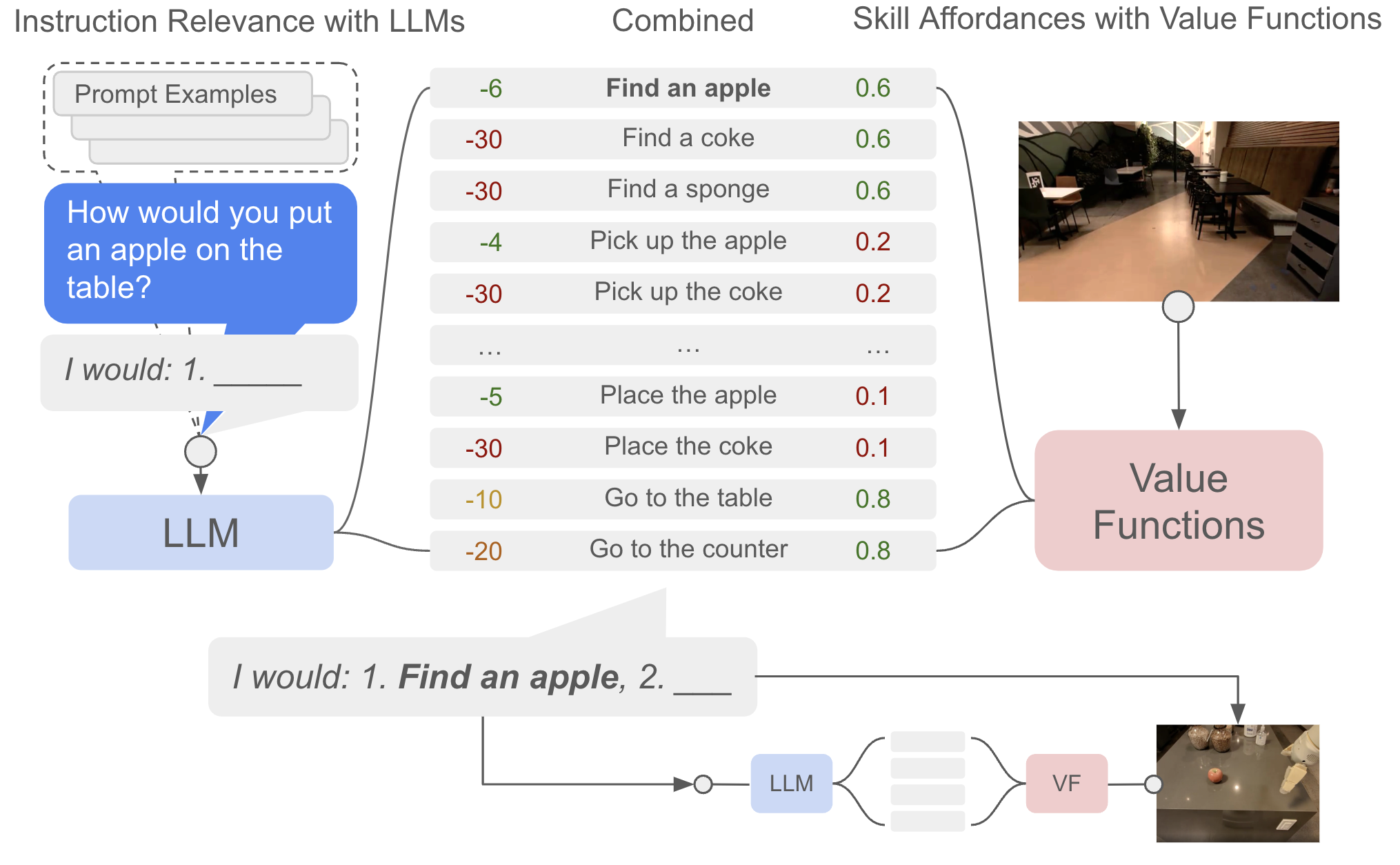
Figure 6. 决策可解释性:query 里提 “coke”,LLM 首选与 coke 相关,但 affordance 把 sponge 推到前面(用户真正要的是”清理”)。这是两路信号互补的典型例子。

为什么用 scoring 而不是 generation?
- 闭集语义:skill 集是 fixed,scoring 天然把 LLM 的输出投影到这个集合,不会生成 “call a cleaner” 这类不可执行的东西。
- 保留概率:scoring 给出 distribution over skills,可以和 affordance 相乘;generative 方式选到一个字符串后还得用 USE embedding 投影到最近邻 skill(论文的 Generative baseline),这一步丢失了概率信息、也无法和 affordance 融合——实验里 Generative 是 74% plan,PaLM-SayCan 84%,差距 10pp。
3. 机器人系统与 skill 训练
Skill 集合:7 类 skill family、17 个物体,共 551 条 skill(picking、placing、rearranging、opening/closing drawers、navigation、placement in configurations)。实验中挑选 data 已足够、性能 mature 的子集投入 101 任务评估。
Policy 训练:
- BC:基于 BC-Z,Universal Sentence Encoder(USE)embed 指令 → FiLM condition 一个 ResNet-18 视觉 backbone → MLP 输出 arm pose / gripper / termination。
- RL:基于 MT-Opt,sparse reward(成功 1、失败 0);在 Everyday Robots 仿真里用 RetinaGAN 做 sim-to-real;simulation demo 做热启动后 online RL 持续改进。Q-value 末端过 sigmoid 保证落在 。
关键抽象:BC policy 成功率更高,所以执行侧用 BC;但 value function 必须来自 RL——因为 BC 无 reward 信号,学不到 “我能不能做到” 的概率估计。SayCan 因此是 BC policy + RL value function 的异构组合。
硬件:Everyday Robots 的 mobile manipulator,7-DoF 单臂 + 两指夹爪,RGB-only observation。
4. 实验
4.1 Setup
环境:真实 office kitchen + 同布局 mock kitchen(后者是训练环境),5 个已知位置 + 15 个物体。 LLM:默认 PaLM-540B。 任务:101 条指令,7 个 family,强调 time-horizon、语言复杂度、embodiment 变化三轴(NL Single Primitive / NL Nouns / NL Verbs / Structured / Embodiment / Crowd-Sourced / Long-Horizon 各 11–15 条)。 指标:
- Plan success:3 人中 2 人判 LLM 产出的 skill 序列对不对(不看执行)。
- Execution success:3 人中 2 人判机器人实际执行是否完成任务。
4.2 主结果与关键 ablation
Table 2. 主结果 + ablation。PaLM-SayCan 在 Mock Kitchen 达到 plan 84% / exec 74%;No VF(去掉 affordance)plan 降到 67%;BC NL(纯语言条件 BC、无 LLM)全面崩盘 0%。
| Family | N | SayCan Plan | SayCan Exec | Real Kitchen Plan | Real Kitchen Exec | No VF Plan | Generative Plan | BC NL Exec | BC USE Exec |
|---|---|---|---|---|---|---|---|---|---|
| NL Single | 15 | 100% | 100% | 93% | 87% | 73% | 87% | 0% | 60% |
| NL Nouns | 15 | 67% | 47% | 60% | 40% | 53% | 53% | 0% | 0% |
| NL Verbs | 15 | 100% | 93% | 93% | 73% | 87% | 93% | 0% | 0% |
| Structured | 15 | 93% | 87% | 93% | 47% | 93% | 100% | 0% | 0% |
| Embodiment | 11 | 64% | 55% | 64% | 55% | 18% | 36% | 0% | 0% |
| Crowd Sourced | 15 | 87% | 87% | 73% | 60% | 67% | 80% | 0% | 0% |
| Long-Horizon | 15 | 73% | 47% | 73% | 47% | 67% | 60% | 0% | 0% |
| Total | 101 | 84% | 74% | 81% | 60% | 67% | 74% | 0% | 9% |
关键读数:
- Affordance 消融最关键的地方是 Embodiment family:No VF 只有 18% plan,而 SayCan 64%。这类任务要求 “理解当前状态”(如已经拿着 coke 了就不该再去 find coke),纯 LLM 无视状态必定犯错,value function 正好提供这个信号。
- Generative baseline(= concurrent work Huang et al. 2022)74% plan,比 No VF 的 67% 好一些,但低于 SayCan 的 84%——scoring + affordance 联合 > 只做 generative + nearest-neighbor projection。
- Real kitchen vs mock kitchen:plan 81 vs 84(-3pp),execute 60 vs 74(-14pp)。规划层鲁棒,执行层对场景分布偏移敏感——瓶颈在 policy 而非 planner。
- 错误来源:65% LLM、35% affordance。Long-horizon 的 execute 降到 47%(vs plan 73%),主要是 LLM 过早 emit “done” 和级联执行失败。
4.3 LLM scaling
Table 3. 用 FLAN-137B 替换 PaLM-540B:plan 84%→70%、exec 74%→61%;FLAN 虽然是 instruction-tuned,但在 SayCan 这种长程规划上被更大的 PaLM 反超。
这是论文最 “范式级” 的一条证据:embodied 性能和 LLM 规模/能力正相关,robotics 和 NLP 的进步可以协同放大。这条主张在 2022 年对 community 的方向选择影响巨大——此后一两年 RT-2、VLA 等”把大模型当 planner/controller”的路线全部顺着这个 premise 扩张。
4.4 扩展能力
- 加新 skill(抽屉操作):加入 open / close / go-to-drawer 三个 skill + prompt 里一个 example → 能解 “restock coke/pepsi into drawer”、“bring rice chips from drawer”(后者因为单臂需要”开抽屉-取-放台面-关抽屉-再拿”的长序列);21 条 plan 100%,exec 33%(失败大多是级联操控)。
- Chain-of-thought:prompt 里加 “Explanation:” 字段,先 generative 解码一段 explanation,再 scoring 选 skill。能处理 “fruit-flavored drink without caffeine” 这类带否定/属性推理的任务,弥补 LLM 原生对 negation 的短板。
- Multilingual:PaLM 是多语 corpus 训练,切 Chinese / French / Spanish 查询后 plan success 基本不掉。
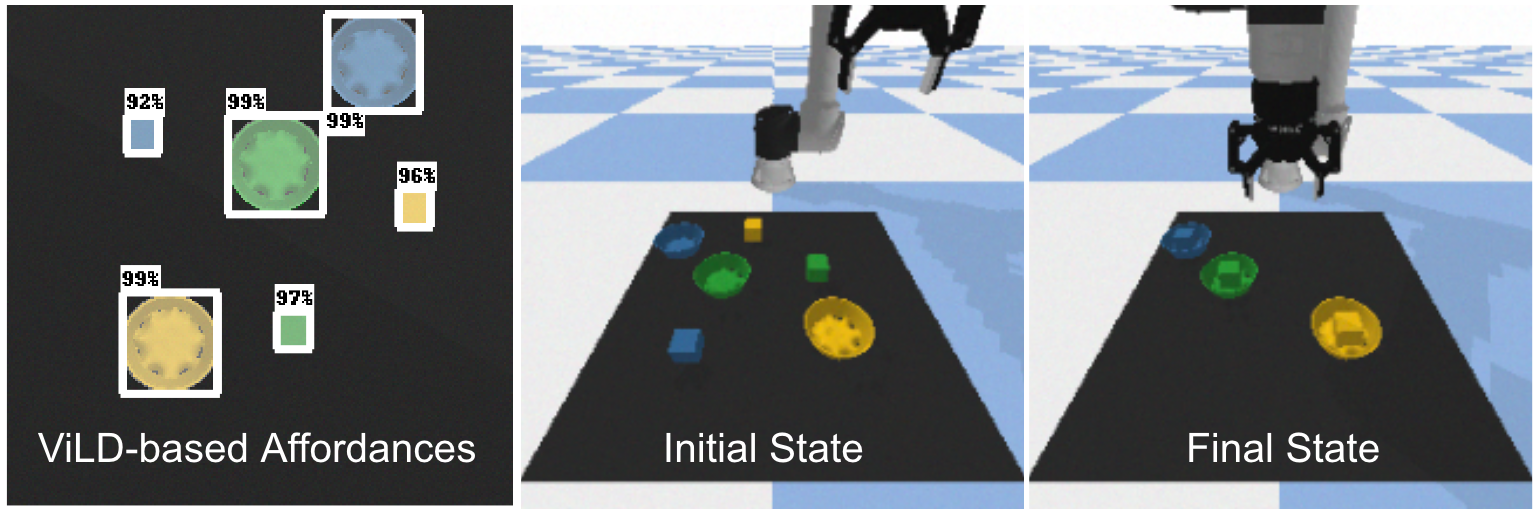
Open-source tabletop 版本:UR5 + CLIPort policy + ViLD detector(代替 value function 做 affordance)+ GPT-3(InstructGPT)scoring,Google Colab 可跑。
Figure 8. 开源 tabletop 环境示意。
5. Limitations
论文自陈:
- 继承 LLM 的 bias 和训练数据依赖。
- 瓶颈在 skill 库的广度和鲁棒性——planner 再聪明,底层 atomic skill 做不了就是做不了。
- 开环决策:每步只看当前 value function,skill 中途失败或环境突变没有在线纠错——后续 Inner Monologue 工作补上了这块。
关联工作
基于
- language-conditioned BC/RL(BC-Z、MT-Opt、RetinaGAN):构成 SayCan 的执行底座,policy 来自 BC,value function 来自 RL。
- Large Language Models(PaLM, FLAN, GPT-3): 纯 API / scoring 使用,不 fine-tune。
对比
- Huang et al. 2022 (Language Models as Zero-Shot Planners):并发工作,用 generative LLM + nearest-neighbor projection 做 planning,本文的 Generative baseline 就是这一思路;SayCan 用 scoring + affordance 在 plan 上高 10pp。
方法相关
- PaLM-E:后续把 LLM 从 text-only 规划升级到 multimodal 输入,直接替代”LLM+affordance”的双路分解;某种意义上是 SayCan 的 “end-to-end 替代方案”。
- Inner Monologue:在 SayCan 之上加 environment feedback(success detector / human feedback)做 closed-loop,补上”开环”短板。
- RT-2:继续推进”大模型 → action”这条路,直接输出 discretized action token,绕过 skill library;SayCan 的 skill vocabulary 抽象被 RT-2 的 action tokenization 抽象取代。
- ECoT / Chain-of-thought 类方法:论文已经演示 CoT 对 negation 的改善,后续 embodied CoT 路线把这个思路推得更远。
- Task and Motion Planning (TAMP) 经典方法:SayCan 用 LLM 代替 symbolic planner + affordance 代替 geometric feasibility check,是 TAMP 的 learned / language-native 再实现。
论文点评
Strengths
- 概念上极简 × 工程上可落地:用一条贝叶斯式分解把”LLM planner + value function affordance”串起来,无需任何 fine-tune,直接拿 off-the-shelf LLM + RL value function 用 scoring 组合。在 2022 年这是把 LLM 搬进 robotics 最低门槛的接口。
- Scoring over fixed skill set:相比并发的 generative planner(Huang et al. 2022),用 scoring 保留概率分布、且天然 bounded by skill vocabulary,在实验上带来 +10pp plan success。这个选择至今仍是 “把 LLM 当 closed-set policy” 流派的标准动作。
- 首条 LLM-scaling → robotics-performance 的实证证据:PaLM > FLAN 的差距被忠实地传导到机器人端(14pp plan、13pp exec)。这不是一个”结果 number”,是一个方向性断言——它让 robotics community 在随后的两年里笃定地去 scale 语言和多模态模型。
- Ablation 够完整:No VF、Generative、BC NL、BC USE 四路 baseline 分别锁定 “affordance 必要性”、“scoring vs generation”、“纯 policy 无 LLM”、“soft retrieval”——每条都指向一个非平凡结论。
- 开源 tabletop 版本和数据集 使得学界能在小环境里复现关键 idea,降低了 follow-up 门槛。
Weaknesses
- Affordance 概率的 calibration 存疑。Value function 过 sigmoid 映射到 被直接当作概率乘 LLM 概率——但 TD-trained Q 值对 “语义成功率” 的 calibration 没有被独立验证。实际中两路信号的 magnitude 差了几个数量级时,argmax 会被其中一路主导;论文没给出相对 scale 的分析。
- Skill vocabulary 线性 scan。每步要对全部 个 skill 都做一次 LLM scoring 和一次 value evaluation—— 时成本高且延迟大。这在规模化时是硬瓶颈,论文没讨论如何剪枝或层级化。
- 开环决策 + LLM 自主 “done”。长程任务 exec 只有 47%,一半的降幅来自 LLM 提前终止;论文自己列为 limitation 但没给出哪怕启发式的缓解。
- “Scoring 是 generation 的投影”这一假设不总成立。Scoring 假设 LLM 对每条 文本计算 likelihood 就能得到合理的 task-relevance 排序,但 rare / OOV skill 描述会系统性偏低(文本概率本身就低)。论文没 ablate skill 描述的语言变体。
- Value function 必须是 language-conditioned 且 skill-separate。论文用 multi-task RL 共享网络,但要扩到几千级 skill 时 RL training 的成本会是主要阻碍;且所有 skill 共用一个 language encoder 意味着新 skill 描述的 generalization 无保证。
- 评估 metric 的人工 2/3 评分存在主观波动,尤其对 “plan success”——多种合法解存在时评分者一致性未报告。
可信评估
Artifact 可获取性
- 代码: inference-only 在 tabletop domain 开源(Colab notebook,UR5 + CLIPort + ViLD + GPT-3)。真实机器人 stack(BC-Z、MT-Opt、RetinaGAN 的集成 pipeline)未开源,依赖 Everyday Robots 硬件和内部 infra。
- 模型权重: 未发布 BC / RL policy 权重;PaLM 非公开(需 API);CLIPort / ViLD 有各自 repo。
- 训练细节: 架构图(Fig 9/10)和高层描述完整;具体超参 / 数据量 / 训练步数只在 Appendix C/D 给出”仅高层描述”级别,未到可复现粒度。
- 数据集: SayCan dataset v0(natural language instruction → solution mapping)公开 CC BY 4.0。机器人侧的 BC/RL training data 未开源。
Claim 可验证性
- ✅ “PaLM-SayCan 在 101 task 上 plan 84% / exec 74%“:有完整 Table 2/3、instruction list(Appendix E.1)、视频、评分协议。
- ✅ “去掉 value function 性能下降”(Embodiment 18% vs 64%):有 No VF ablation,直接对比。
- ✅ “Scoring > Generative”:Generative baseline 74% vs SayCan 84% 在 Table 2。
- ⚠️ “LLM 越大机器人性能越好”:只 ablate 了两个模型(PaLM-540B vs FLAN-137B),模型规模和 instruction-tuning 两个变量耦合;严格的 “scaling law” 需要在同一模型家族跨尺寸对比,论文 Appendix Table 7 给了 PaLM 8B/62B/540B 的 generative 测试,但全 pipeline 只跑了 540B 和 FLAN。
- ⚠️ “Real kitchen 泛化”:只有一个 real kitchen + 一个 mock,-14pp exec 的来源(数据分布偏移、光照、物体位姿)未细分。
- ⚠️ “CoT 解决 negation”:只给了 4 条成功 rollout(Table 4),没报告整体成功率提升数字和失败案例,样本量不足以验证泛化。
- ❌ 无明显营销话术。论文自陈 limitation 克制。
Notes
-
从 2026 回看的定位:SayCan 是 “LLM + robotics” 路线最关键的接口论文(interface paper)——它没发明新模型,但定义了此后两年内大量工作的组合范式(LLM planner + learned value/affordance + atomic skill library)。在 VLA 路线(RT-2、OpenVLA、π0)崛起后,这种”分层解耦”的做法被 end-to-end 方案部分取代;但在 skill library 丰富、新 skill 增删频繁的场景(家居、multi-task 部署),分层的 SayCan 范式依然有生命力——见 TidyBot / BUMBLE 这一脉。
-
对当前 VLA 研究的启发:SayCan 把 “task-grounding” 和 “world-grounding” 显式分开的视角仍有用。End-to-end VLA 把这两者压到同一网络里,但在失败归因时这两种错误依然需要被区分(“模型不知道该做什么” vs “模型知道该做什么但做不到”)。SayCan 的 “plan success / execution success” 两指标本身就是一个好的 diagnostic template。
-
跨域复用 pattern:在有限动作空间上做 LLM scoring + 其他 signal 的概率乘积——CUA/GUI agent 把 action candidates 和 affordance(UI element detector)乘起来是同构思路。这使 “scoring over closed set” 成为跨 robotics / GUI / function-calling 的稳定范式。
-
需要继续追踪的线:
- SayCan → Inner Monologue → PaLM-E → RT-2 → π0 这条”逐步 end-to-end”的演化链条里,哪些能力在分层时解决不了而只能靠 end-to-end?(hypothesis: fine-grained visual grounding、闭环纠错)
- Value function 作为 affordance 的 calibration 问题是否被后续 work 正式处理过?
Rating
Metrics (as of 2026-04-24): citation=2982, influential=188 (6.3%), velocity=61.23/mo; HF upvotes=1; github 37785⭐ / forks=8395 / 90d commits=79 / pushed 0d ago
分数:3 - Foundation
理由:Building Block 档。证据:(1) 笔记 Strengths 3 指出它是”把 LLM 搬进 robotics 最低门槛的接口”并给出 LLM-scaling → embodied-performance 的首条实证,(2) 关联工作里 PaLM-E / Inner Monologue / RT-2 / π0 / TidyBot / BUMBLE 全部把 SayCan 作为必引的 baseline 或起点,(3) 方法核心”scoring over closed-set action × affordance”这一抽象已被外推到 GUI agent / function calling 等邻域。相比 2 档(Frontier/SOTA),它已经脱离了”当前 SOTA baseline”的时间窗口,但由于其接口定义地位而成为不可回避的 must-cite——这是 3 档而非 2 档的关键差别。