Summary
π0.7: a Steerable Generalist Robotic Foundation Model with Emergent Capabilities
- 核心: 用 diverse multimodal prompts(subtask 文本 + episode metadata + world-model 生成的 subgoal images + control mode)作为”context conditioning”,把 demonstrations、failure rollouts、autonomous evaluation data、egocentric human video、web data 这些异质混合质量的来源统一吃进单一 5B VLA,使一个通用模型在 dexterity、instruction following、cross-embodiment、compositional generalization 四个维度同时拿到”early signs”。
- 方法: Gemma3 4B + MEM 视频编码器 + 860M flow-matching action expert(5B 总参);prompt 含 subtask、metadata(speed/quality/mistake)、subgoal images(来自 BAGEL 14B world model)、control mode;训练时各组件随机 dropout,推理可任意子集;可配 CFG 在 metadata 上做 quality steering。
- 结果: 单个 π0.7 模型在 8 个困难灵巧任务上匹配甚至超过 π*0.6 的 RL specialist 和 SFT specialist;在 4 个未见厨房 + 2 个未见卧室上的指令跟随显著超 π0.5/π0.6;laundry folding 零样本迁移到从未见过该任务的 UR5e bimanual 平台,task progress 85.6%、success 80%,与 top-2% 经验的人类 teleoperator 持平;可被语言 coaching 教会 air fryer / 烤面包机等全新长时程任务。
- Sources: paper | website
- Rating: 3 - Foundation(PI 系列的下一代基础 VLA,prompt expansion 训练哲学 + cross-embodiment 零样本匹配人类 top-2% 的结果都是方向级的影响,必读必引)
Key Takeaways:
- “Diverse context conditioning” 是这篇的真正主张: 论文的方法论 punch line 不是”换了什么模块”,而是”prompt 信息扩张本身可以解锁更多数据”——subtask 文本、quality/speed/mistake metadata、subgoal images 让模型在训练时把”做什么”和”做得怎么样、用什么方式”分离。这等价于把数据集的隐变量显式化,所以可以把 failure rollout 也喂进来而不被污染。和 LLM 的”prompt expansion”训练在概念上同源。
- 从 RL specialist 到通才的 distillation: π0.7 大量使用 π*0.6 的 RL 训练 rollout 作为训练数据,配合 quality metadata 做”软分级”。结果是单个通才模型在 espresso/laundry/box building 上匹配甚至超过 RL 专家,把 RL 专家的能力”反向蒸馏”回基础模型——这给”专才→通才”的迭代设计了一条闭环。
- Subgoal images 由 lightweight world model 即时生成: BAGEL 初始化的 14B image-edit 模型(pre-train 自图像编辑/web 视频)在 inference 时按 subtask 文本+当前观测生成 future-frame subgoal,再交给 π0.7。这把”语义未消歧”的语言任务(如 “pick up the fruit on the largest plate”)变成”几乎是 inverse dynamics”的视觉任务——这是为什么 GC 变体在复杂引用、breaking dataset bias、cross-embodiment 上都明显更好。
- Cross-embodiment 不只是适应,是策略发现: 在没有 UR5e laundry 数据的情况下迁移成功的关键不是”复制 source 行为”——模型在 source bimanual robot 上学的是 tilted grasp + 双臂配合,但在 UR5e 上自动用 vertical grasp + 单臂 pick-and-place。这种 emergent 的形态适配,匹配人类 top-2% teleoperator 的 zero-shot 表现。这条线最有产业含义:高成本工业臂可以由低成本灵巧臂数据驱动。
- “Coaching → autonomous” 学习闭环: 用语言一步步教模型做新任务(air fryer 装红薯),收集这些 coaching episode,反过来 fine-tune 一个 high-level policy 自动生成同样的 subtask 序列。整个 pipeline 不收集任何新的 teleoperation 数据就能让 π0.7 自主完成全新长时程任务,coaching 后的 autonomous 表现接近 coaching 时的水平。这是把”语言指令跟随”作为新的数据扩增 primitive 来用。
- Prompt dropout + CFG 是通用的 steerability 机制: 训练时每个 prompt 组件按概率独立 dropout(subgoal 75%、metadata 15%、subtask 30%);推理时可省可加;甚至可以对 metadata 做 CFG(β=1.3–2.2)来”把模型推向更高 quality”。这套机制让一个模型同时支持”语言-only”、“语言+subgoal”、“高 quality 模式”、“高速模式”等 deployment 配置。
Teaser. π0.7 overview — diverse multimodal prompts unify heterogeneous data sources, enabling out-of-the-box dexterity and compositional generalization.
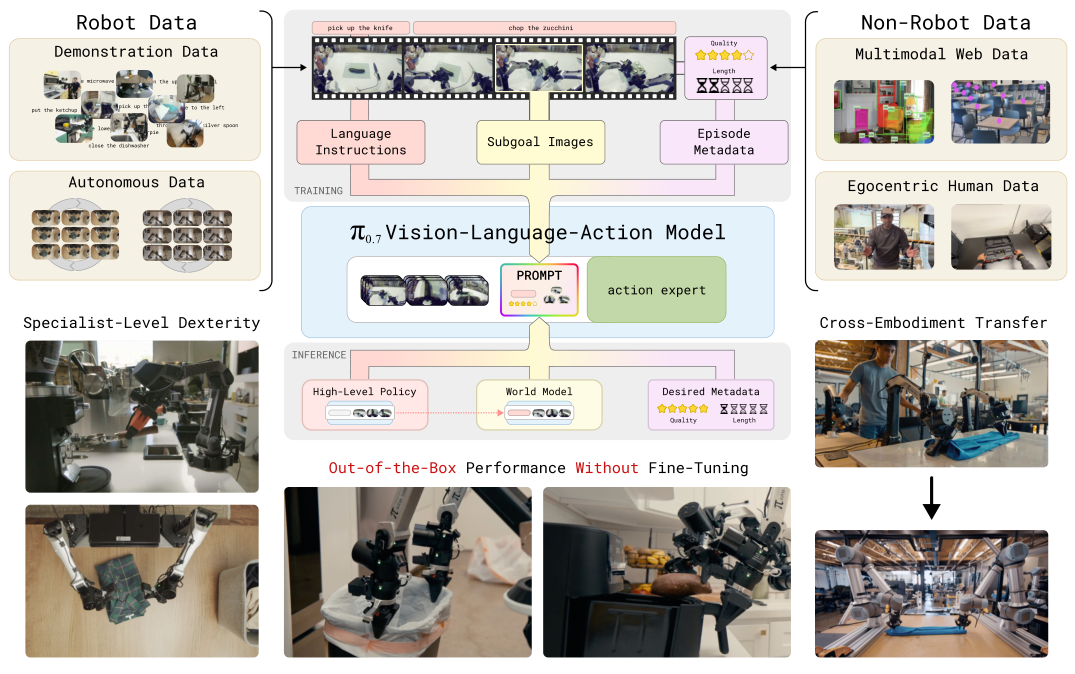
Teaser Video. Cross-embodiment laundry folding on bimanual UR5e (zero-shot, no folding data on this robot).
Introduction & Motivation
π0 系列已经把 VLA 推到了 specialist 水平的灵巧操作,但 LLM 那种 “compositional generalization”(把训练里见过的 capability 自由重组解决新问题)在 robot foundation model 上一直缺席。先前的 VLA 不仅难以解决新任务,连训练分布内的指令也常需要 task-specific fine-tuning 才能流畅执行。 π0.7 想要回答:什么样的训练 recipe 能让 VLA 像 LLM 一样,对训练数据中的 skill 做”重组”?
论文的判断:单纯加大数据并不够。机器人数据天然异质——不同 demonstrator 的策略、autonomous rollout 的质量、failure episode、跨 embodiment 的形态——naive averaging 会让模型学到”中庸的平均策略”。关键缺失的是 prompt 的表达力:如果 prompt 只有一句任务描述,模型就只能用 task identifier 做条件分布近似;如果 prompt 能描述”用什么策略、做到什么质量、希望中间状态长什么样”,那么数据集中的隐变量被显式化,混合质量数据反而成了正资产。
❓ 论文几乎没有给 prompt expansion 在 VLA 上的”为什么 work”的机制级分析(只是类比 image generation 的 prompt expansion)。从结果看 metadata 起到了 disambiguator 的作用,但具体哪些 prompt 组件对 generalization 贡献最大,是否所有组件都是必须的,文中没有完整的 leave-one-out。
Method
Architecture: 5B VLA 在 π0.6-MEM 上扩展
Figure 2. π0.7 整体架构:4B Gemma3 VLM backbone + MEM-style 历史视频编码器 + 860M flow-matching action expert。Prompt 包含语言指令、episode metadata、subgoal images。Subtask 文本由一个高层 semantic policy(同架构)生成,subgoal images 由独立的轻量 world model(BAGEL-init)生成。
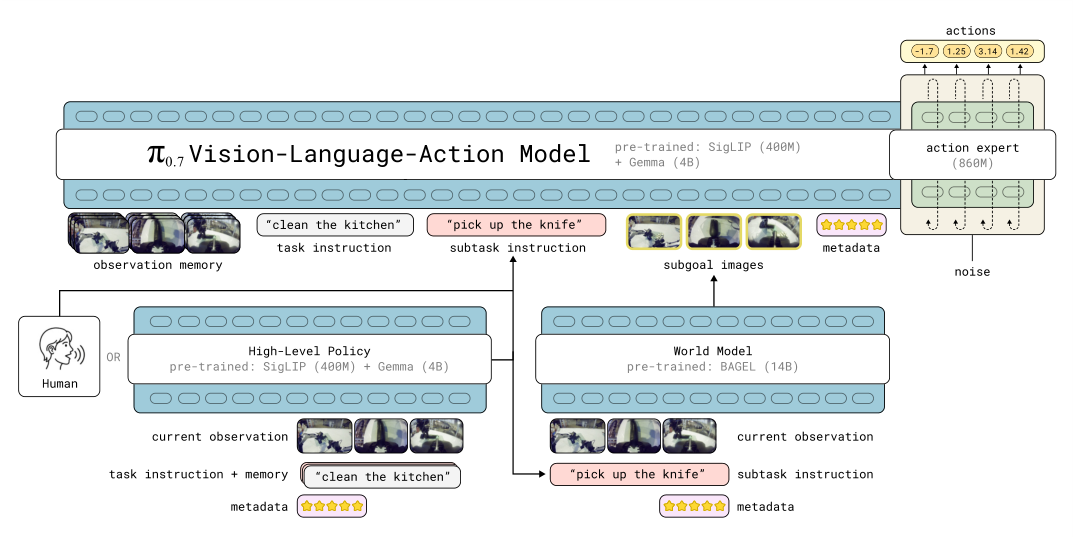
- Backbone:Gemma3 4B-parameter VLM(含 400M ViT vision encoder),从公开权重初始化。
- History encoder:沿用 MEM 的 video history encoder——对历史观察做时空压缩,无论历史帧数都输出固定 token 数。最多 4 路相机(前视、左右腕、可选后视)+ 6 帧历史,1 秒 stride。
- Action expert:860M transformer,flow matching 目标,固定输出 50 步 action chunk,bidirectional self-attention 且能 attend 到 backbone 激活;用 adaptive RMSNorm 注入 timestep。
- 训练目标:π0 的 flow matching + Knowledge Insulation (KI)——backbone 用 FAST 离散 token 监督,action expert 的梯度不回传到 backbone,避免 unstable continuous loss 污染 VLM 表示。
- 状态编码:与 π0.6 不同,π0.7 跟 MEM 一样把 proprioceptive state 用线性投影做 token 嵌入(不是离散文本 token);历史 state 与历史帧 dropout 联动。
- Real-time chunking (RTC):训练时模拟 0–12 timestep 的 inference delay(对应 50Hz 上最多 240ms 延迟)以保证生产部署时的动作平滑。
多模态 Prompt 设计
π0.7 的 prompt 包含 5 类组件,训练时各自独立 dropout,推理时可任意组合:
| 组件 | 训练 dropout 率 | 作用 |
|---|---|---|
| Task instruction | - | 总体目标(如 “clean the kitchen”) |
| Subtask | 30%(仅在有 subgoal 时) | 步骤级语言(“open the fridge door”),可由人或高层 policy 给 |
| Subgoal images | 75%(即只 25% 训练样本带) | 多视图近未来期望帧,由 world model 生成;本质是把任务降为 inverse dynamics |
| Episode metadata | 整体 15%、每项另 5% | speed bin(500 步粒度)、quality 1-5、mistake bool |
| Control mode | - | joint / ee 文本标识 |
示例 prompt:
<Multi-view observation> <Multi-view subgoals>
Task: peel vegetables. Subtask: pick up the peeler.
Speed: 8000. Quality: 5. Mistake: false. ControlMode: joint.
<Proprioception>
Figure 3. Prompt overview:同一个数据可以同时具备 subtask 文本、subgoal images、metadata 三类条件——这种冗余表示让模型学会任意子集都能用。例如 UR5e bimanual 折衬衫示例中,prompt 是 “subgoal image + metadata”。

World model(subgoal generator)
- 初始化:BAGEL [105],14B mixture-of-transformers,本身有图像理解+编辑+生成能力(同时含 ViT 7B + generation 7B)。
- 训练目标:标准 flow matching loss,输入是 subtask 文本 + 当前观测 + metadata,预测段末帧。
- 数据:高质量 subtask label 的机器人 episode + egocentric human video + 开源 image editing/video 数据;label 时序切分质量被指出”对 subgoal 质量影响最大”。
- inference 时延:14B 模型 + 近 10K token 序列,需要 4×H100 + tensor parallel + 8-bit 量化 + SageAttention,才能把 25 步 denoising 的 subgoal 生成压到 1.25 秒。π0.7 主体异步执行不阻塞。
Inference-time prompting
Algorithm 1
- 用 high-level policy 或人给出 subtask ℓ̂
- 用 world model 生成 subgoal g* (仅当 subtask 变或 4s timer 触发)
- C = {ℓ, ℓ̂, g*, m, c}
- VLA 输出 50 步 action chunk,执行 H̃ ∈ {15, 25} 步
- 默认 metadata:speed = task 数据的 15th percentile(即”快”),quality = 5,mistake = false。
- Classifier-free guidance:可对任一 prompt 组件做 CFG。论文用 metadata CFG(β=1.3–2.2)来”把模型推向高 quality 行为”。
训练数据混合
- 大量不同机器人平台的 demonstrations(static / mobile / single-arm / bimanual)
- autonomous evaluation rollouts——尤其是 π*0.6 RL 训练时收集的 episode,作为 distillation source(脚注 1:generalization 评测涉及的任务排除在外,避免数据泄漏)
- 失败 episode + 含错误的成功 episode
- 开源机器人数据集
- Egocentric human video
- web 多模态数据:object localization、attribute prediction、VQA、text-only、video captioning
❓ 论文一直强调”在 large + diverse 数据下定义’unseen’非常困难”——这其实削弱了 compositional generalization 的强 claim。论文自己在 Discussion 里诚实承认了这点。这也意味着 air fryer 这类”未训练”任务的迁移在多大程度上是真的”compose”vs “近邻 retrieve”,目前没法严谨界定。
Experimental Results
A. Out-of-the-box dexterity
Setup:复用 π*0.6 release 的 4 个高难度任务(laundry/espresso/box building)+ Robot Olympics 任务(PB sandwich、shirt inside-out、drive through door)+ 新增灵巧任务(zucchini slicing、peeling、trash bag replacement)。Baseline 是 task-specific RL specialist 或 SFT specialist。
Figure 6. 单个 π0.7 vs 多个 task-specific specialists:第一行是与 π*0.6 RL specialist 比,第二行是与 SFT specialist 比。π0.7 全面匹配,且在 diverse laundry 和 box building 上 throughput 更高。
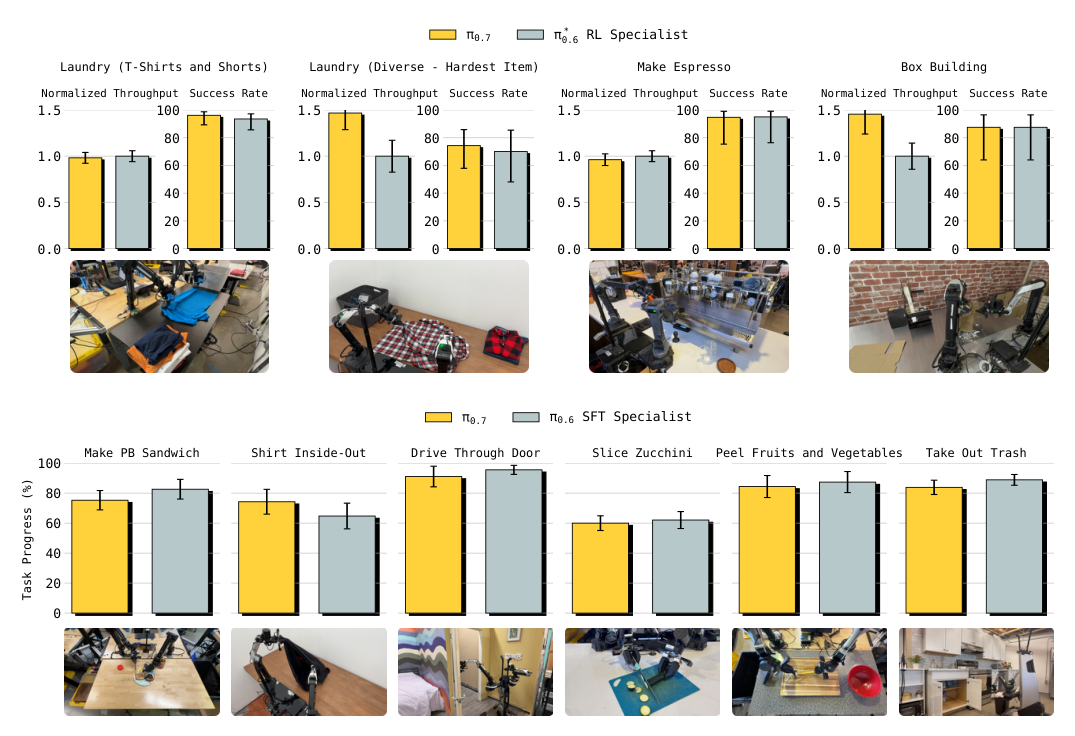
这个结果颠覆了”通才性能不如专才”的常识:通过 distillation + metadata steering,单一通才在所有 8 个 dexterous 任务上接平甚至超 RL/SFT 专家。throughput 优势可能反映了通才模型”见过更多类似 fold/grasp”的副作用。
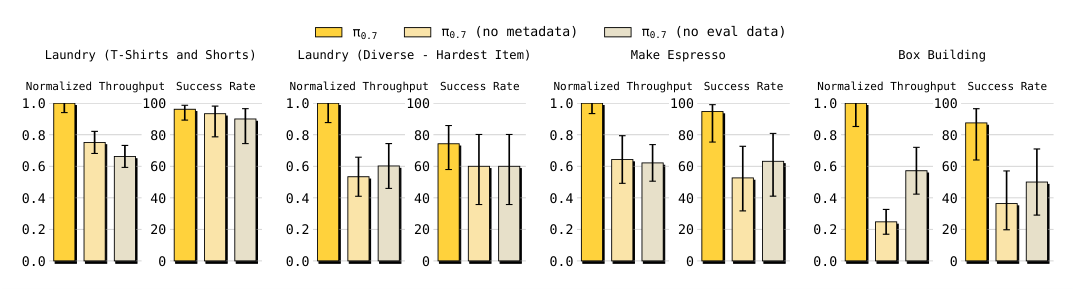
Figure 7. Ablation:metadata + eval data 都重要:去掉 metadata 或去掉 autonomous eval data 都显著掉性能(throughput 比 success rate 退步更大)。“eval data 含很多次优 rollout”——只有当 metadata 能区分质量时,把它们喂进去才不会污染模型。
B. Instruction following
Figure 9. 在 4 个未见厨房 + 2 个未见卧室上的 3-6 步指令跟随成功率:π0.7 全面超 π0.5 和 π0.6。这是直接对比此前 PI 自家的开放世界泛化模型——说明 prompt 多样化训练对”语言跟随”也是关键 lever,而不仅仅是”加大模型/数据”。

Figure 10. 复杂指代指令:标准指令(“pick up the spoon”)所有模型都能做;复杂指令(“pick up the object I would use to eat soup”、“pick up the fruit on the largest plate”)只有 π0.7 能跟住,加上 subgoal images(GC 变体)效果更好——把”语义解释”外包给了 world model 的 web-scale 先验。
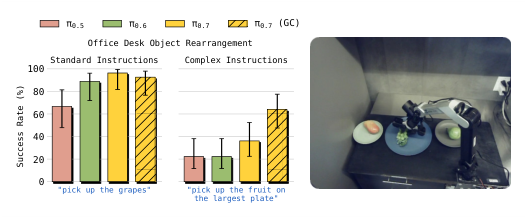
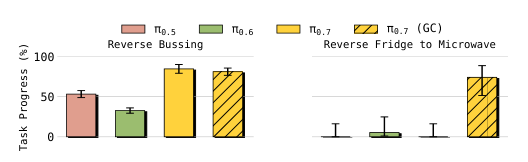
Figure 11. 反数据集偏置任务:训练数据里只有”trash → trash bin、dishes → bussing bin”,测试时反过来命令。强语言跟随才能压住数据偏置。“Reverse Fridge to Microwave” 上 GC 变体是关键——world model 能基于反向 instruction 生成正确 subgoal。
C. Cross-embodiment transfer
Figure 12. 跨形态迁移:从简单(Table Setting)到困难(Shirt Folding from static bimanual → UR5e)。π0.5 在大形态差距下崩溃,π0.7 仍能匹配 top-2% 人类 teleoperator 的 zero-shot 表现。subgoal images(GC)变体进一步提升——world model 能在”source 的腕部姿态”和”target 的手臂可达空间”之间做视觉类比。
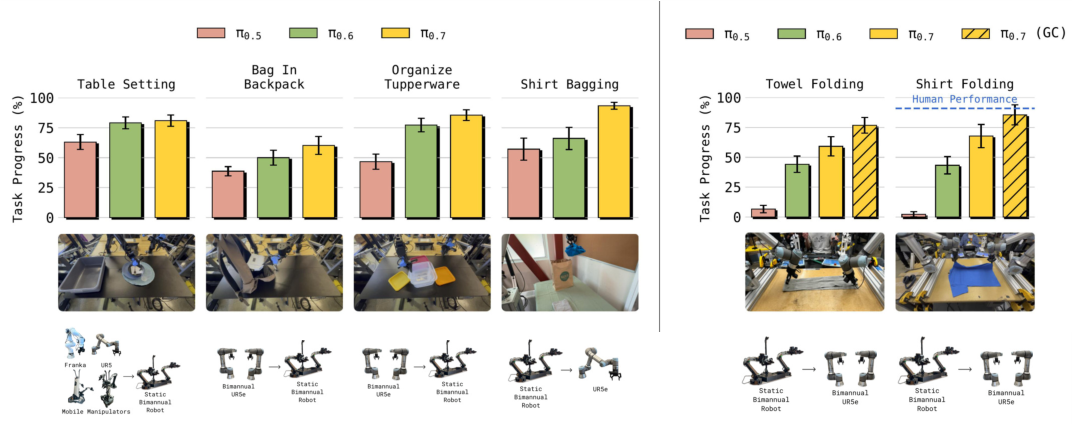
Human study(10 人 × 3 trial):top-2% experience operator(平均 375 小时)首次在 UR5e 上 fold shirt:90.9% task progress、80.6% success;π0.7 (GC):85.6% / 80%——基本持平。这是论文最强的”零样本迁移”证据,也直接给”用便宜灵巧臂收集数据→部署到工业臂”的产业 pipeline 背书。
D. Compositional task generalization
Figure 17. 短时程 compositional 任务零样本:模型能 out-of-box 做 french press 按压、scoop rice into rice cooker、wipe headphones、spin desk fan/gear set——这些没有专门的训练数据。π0.7 在 GC 与 non-GC 上接近,说明短时程任务里 language conditioning 已经够。
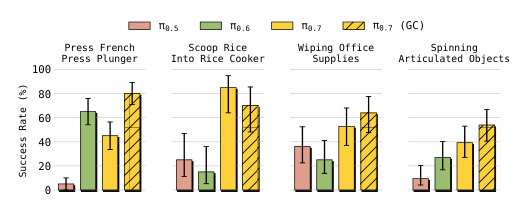
Figure 14. 用语言 coaching 教模型做新任务:人提供步骤级 instruction(“grasp the air fryer handle”→“open the air fryer with the left hand”→“pick up the sweet potato”→…),π0.7 跟着执行。

Figure 15. 长时程未见任务:air fryer 加载/卸载、bagel 烘烤——这些任务连 base 数据里都没有 action level demo。其它模型基本失败,π0.7 (GC) 才能跟得住 coaching。
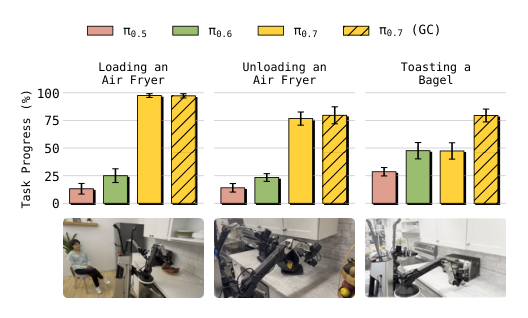
Figure 16. Coaching → autonomous 闭环:把 coaching episode 用来 fine-tune 一个 high-level policy(直接复用 π0.7 架构),让它自动生成同样的 subtask 序列;然后整个 pipeline 不需要任何 teleoperation 就能 autonomous 执行新任务。Autonomous 表现接近 coaching 时——证明 coaching 可以替代 teleop 数据采集这一步。
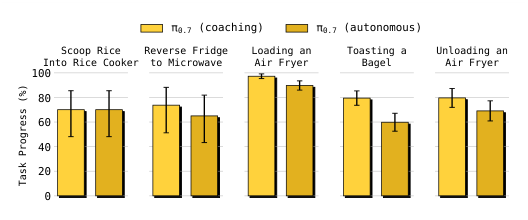
❓ 这条 pipeline 看起来非常 promising,但论文没说 coaching → autonomous 的 fine-tune 用了多少 episode,也没和 “直接收集 teleoperation 数据 fine-tune” 做相同样本量对比。如果 coaching 也需要几十次 trial 才稳,“省 teleoperation”的实际成本节省存疑。
E. Scaling 与数据多样性
Figure 18. 两个 scaling 实验:
- 左:fold laundry 任务,把数据按 quality+speed 分成 top 30%/50%/80%/all 四档。π0.7 (with metadata) 训练数据越多越强(即使大部分是 lower quality);π0.7 (no metadata) 反而随数据质量下降而崩。⇒ metadata 让模型把”加更多数据”和”加更高质量数据”解耦。
- 右:移除”task diversity 最高的 20%” vs 移除”随机 20%“。前者性能显著下降,说明 task-diverse 数据对短时程未见任务的泛化贡献最大。
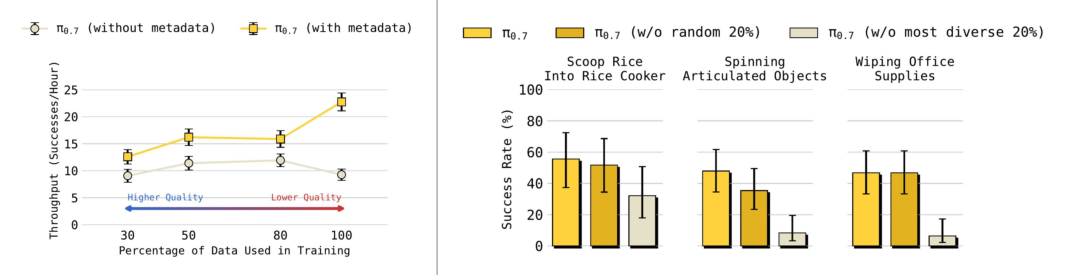
这个 scaling 实验是论文最有 information gain 的部分——直接量化了”prompt expansion 让 mixed-quality data 变成正资产”。但它只在 fold laundry 一个任务上做,跨任务的稳健性需要更多证据。
Limitations & Discussion
论文自己列出的 caveat:
- Unseen task 的成功率明显低于 in-distribution:seen task 常 90%+,unseen 任务或 unseen task-robot 组合在 60–80%。
- “Truly unseen” 几乎无法严格定义:训练集太大太杂,相似行为可能以不同 label 散落各处。论文承认这与 LLM 评测面临同样的难题,并主张”compositional generalization 本身就是 remix”。
- 未来方向:用语言 coaching 或 autonomous RL 在测试任务上做”高 steerability”的快速适应(i.e., 把 prompting 作为下游学习接口)。
关联工作
基于
- π0: flow-matching VLA + action chunking 的祖父架构
- π0.5: 引入 high-level subtask prediction 与 heterogeneous co-training,π0.7 复用其 subtask 设计
- π*0.6: 上一代基础 VLA 架构 + RL fine-tuned specialist;π0.7 直接 distill 其 evaluation rollout
- MEM: 历史视频编码器与状态 token 化;π0.7 把 MEM 作为基础模块引入
对比
- π0 / π0.5 / π*0.6: 主要 baseline,跨 instruction following / cross-embodiment / dexterity 三条线
- Hi Robot: 高层语言策略思路与 π0.7 的 high-level policy + low-level action 框架同源
- RL/SFT task-specific specialists:用作 “通才能否匹配专才” 的金标准
方法相关
- BAGEL [105]: subgoal world model 的 init;提供 web-scale 图像编辑/生成先验
- Gemma3 [106]: VLM backbone init
- SuSIE [93]: image-edit-as-subgoal-policy 的祖先;π0.7 的 subgoal 概念延续自此
- FAST tokens [104]: backbone 的离散 action 监督,配合 KI 训练
- Knowledge Insulation (KI) [103]: backbone 不接受 action expert 梯度的训练 recipe
- RTC [107, 108]: 训练时模拟 inference delay 的 action chunking 技术
- Classifier-free guidance [109]: prompt 组件 dropout 后用于 quality steering
- DROID [open dataset]: 训练数据的一部分;blog 中举例 air fryer 任务最近邻数据来自 DROID Franka
论文点评
Strengths
- 方法论 framing 漂亮:把 “prompt expansion = 让数据集隐变量显式化”这一抽象 insight,落到 metadata + subgoal + subtask 三类具体条件上,并给出统一的 dropout/CFG 训练-推理接口。这套机制可以直接被其他 VLA 工作借用。
- 数据策略极其务实:明确接受 failure rollout、autonomous data、跨 embodiment 数据作为正资产,并通过 metadata 标注解决质量混淆问题。这是”VLA 数据工程”的一个明确进步——不再寄望于”高质量 demonstration 才能用”。
- Cross-embodiment 与 RL specialist 蒸馏两条线都拿到强结果:UR5e laundry 持平 top-2% 人类 teleoperator;espresso/laundry/box 通才匹配甚至超 RL specialist。两个结果各自都改变了对应方向的”期望基线”。
- Scaling 消融直接量化 metadata 价值:mixed-quality data 在 no-metadata 模型下越多越差,加 metadata 后 monotonically improves。这是为”prompt expansion”提供机制级证据的关键实验,非常清晰。
- Coaching→autonomous 闭环给”教机器人做新任务”提供了不依赖 teleoperation 的新原语,连接了语言指令跟随和数据扩增。
Weaknesses
- “Compositional generalization” claim 的强度被论文自己稀释:作者诚实地承认”训练集太大无法严格定义 unseen”。这意味着 air fryer / bagel toasting 等结果到底是 compose 还是近邻 retrieve,无法严格切分。这个核心 claim 缺乏 controlled novelty 实验。
- Prompt 组件的贡献度未做 leave-one-out:论文做了 metadata 和 eval data 的 ablation,但 subgoal images / subtask 文本 / control mode 各自的边际贡献没系统量化。subgoal images(“GC”)有时关键、有时无差异,缺少机制性解释。
- Coaching pipeline 缺少成本核算:coaching episode 数量、fine-tune 高层 policy 所需数据量、与”直接 teleoperation 收集等量数据”的成本对比都没披露——决定了这个原语在实际工程中能否替代 teleop。
- World model 推理代价巨大:4×H100 + 8-bit 量化 + custom attention 才能把 1.25s subgoal 生成压下来。在很多场景里 GC 变体是核心收益来源,这意味着部署成本被这个 14B 副模型主导。论文未讨论是否能蒸馏到更小的 subgoal generator。
- 基线偏弱:比较对象主要是 PI 自家的 π0.5 / π0.6 / π*0.6,缺少与其它强 baseline(Gemini Robotics、Gemini Robotics 1.5、GR00T N1 等)的横评,部分原因可能是闭源/平台不同,但 cross-embodiment / instruction following 这类抽象能力本可以共比。
- Metadata 设计的 scalability 存疑:speed/quality/mistake 这三个维度由人工标注;论文没讨论如何在更大数据上自动获得高质量 metadata,也没讨论 metadata schema 在新任务/新数据源上是否需要重新设计。
可信评估
Artifact 可获取性
- 代码: 未开源(PI 的 openpi 仓库截至本笔记日期只放出 π0/π0-FAST/π0.5)
- 模型权重: 未发布
- 训练细节: 高层架构 + 关键超参(dropout 概率、CFG β 区间、history stride、denoising step、行 50 token、inference latency 38–127ms)已披露;但训练 token 数、各数据源配比、训练步数未公开
- 数据集: 私有;只透露包含开源数据如 Octo 的 mix(DROID 提到一次作为相关数据源举例)
Claim 可验证性
- ✅ 单 π0.7 模型在 8 个 dexterous 任务上匹配/超过 task-specific RL/SFT specialists:图 6 给了 success rate + normalized throughput 双指标,且与 π*0.6 论文的 baseline 直接对应
- ✅ UR5e laundry zero-shot transfer 与 top-2% 人类 teleoperator 持平:人体 study 设计严谨(10 人 × 3 trial、首次尝试、无 warmup),数字可比
- ✅ Mixed-quality scaling 现象(Figure 18 left):方法上有 controlled ablation(同一任务、四档质量),结论清晰
- ⚠️ “Compositional generalization” 在 air fryer / bagel 等长时程任务上的成立:论文自承”unseen 难定义”;coaching 时人提供 step-by-step 语言相当于把组合负担分散给人;autonomous policy 是从 coaching 数据 fine-tune 得到,不算严格意义上的 zero-shot
- ⚠️ subgoal-image (GC) 的边际收益跨任务不一致:在 reverse-bias 和 cross-embodiment 上明显有用,在 short-horizon 新任务上几乎无差异——论文没给出”何时 GC 必要”的判据
- ⚠️ Instruction-following 显著超 π0.5/π0.6 (Figure 9):absolute 数值(success rate)没标注,只是相对柱图;评测的 14 个 scenario 是 PI 自选,可能有 selection bias
- ❌ “Step-change in generalization”(blog 用语):营销话术;paper 自身用 “early signs” / “initial demonstrations” 这种 hedging,更稳
Notes
- Prompt expansion as a unifying mechanism for VLA:本文最值得借鉴的不是某个具体模块,而是”把 prompt 当 latent variable 显式化”的训练哲学。其它 VLA 项目都可以问自己:“数据集里有哪些隐变量影响 action 分布?哪些可以做成 prompt 标签?” 这是一个可复用的方法论。
- Subgoal generator 与 SnapFlow / video-as-policy 路线的关系:π0.7 是”world model 给 subgoal、VLA 走 action”的两阶段架构;视频生成派(dreamer-like / video-policy)是端到端的。两条路在工程实现 / latency / data efficiency 上各有 trade-off,值得继续追踪。
- Cross-embodiment “策略发现” 需要单独研究:UR5e vs static bimanual 上的策略差异(vertical vs tilted grasp)是 emergent 的,但论文只是定性观察。如何 controlled 地诱导这种 emergent strategy switch,是 cross-embodiment 方向的下一个有意思的子问题。
- Metadata 自动化是工程瓶颈:speed/quality/mistake 当前靠人工。如果有方法用自训练或 verifier 自动给 metadata(类似 RL 中的 reward model),整套 prompt expansion 就能 scale 到更大数据。这可能是下一篇 PI 论文的方向。
- 可参考的 idea hooks:
- 在自己的 VLA 工作里,是否能用 GAN/diffusion 生成 “synthetic subgoal” 来扩充小规模 demo?
- metadata schema 能否扩展到 “energy”、“smoothness”、“safety”,把行为质量从单维 scalar 变多维?
- coaching → autonomous pipeline 是否能用于 OOD recovery(错了之后被人语言修正,再 fine-tune 高层 policy)?
Rating
Metrics (as of 2026-04-24): citation=N/A (non-arxiv release), influential=N/A, velocity=N/A; HF upvotes=N/A; github=N/A (无代码仓库)
分数:3 - Foundation 理由:π0.7 是 PI VLA 系列(π0 → π0.5 → π*0.6 → π0.7)的下一代基础模型,方法论贡献(“prompt expansion as unifying mechanism for heterogeneous data”)和实证结果(单个通才匹配/超过 RL specialist;UR5e zero-shot laundry 持平 top-2% 人类 teleoperator)都处在方向级的位置,符合 Strength 1/3 和 Scaling ablation 的论断。相比 2(Frontier,仅是当前 SOTA baseline),它提出的 metadata + subgoal + dropout/CFG 训练接口具备被其它 VLA 工作借用的范式价值——这是 Foundation 区别于 Frontier 的关键。短期 citation 尚未累积、代码未开源是减分项,但基于方法论原创性与 PI 在 VLA 方向的一贯影响力,判定为 Foundation 而非 Frontier。