Summary
Gemini Robotics: Bringing AI into the Physical World
- 核心: 基于 Gemini 2.0 的 VLA 双栈:Gemini Robotics-ER(embodied reasoning backbone)+ Gemini Robotics(cloud backbone + local decoder 的 VLA)
- 方法: 云端 backbone(<160ms)+ 本地 action decoder(端到端 ~250ms、50Hz);数千小时 ALOHA 2 数据 + web/code/multimodal mixture;generalist → specialization fine-tune pipeline
- 结果: ERQA 48.3 SOTA(CoT 54.8);20 任务 out-of-the-box 显著超 π0 re-implement 和 diffusion baseline;100 demo 内快速适配新任务;迁移到 bi-arm Franka(63% avg)和 Apollo humanoid
- Sources: paper | website | github
- Rating: 3 - Foundation(Google DeepMind 旗舰 VLA,cloud backbone + local decoder 范式与 ERQA benchmark 已成为后续 Gemini Robotics 1.5 / ER 1.6 与大量 VLA 工作的必引参考)
Key Takeaways:
- Cloud backbone + local decoder:把”大模型理解能力”与”实时控制闭环”解耦——backbone 出粗粒度 action chunk,本地 decoder 在 latency budget 内补齐细节,实现 50Hz 的高频响应。这是把云端大模型塞进真实机器人的一条实用路径。
- Embodied reasoning 作为 VLA 的地基:Gemini Robotics-ER 先在 pointing/trajectory/3D 等任务上 SOTA,再把这个 ER 蒸馏成 VLA backbone——这条”先建 reasoning,再建 action”的 stack 顺序在论文里被反复论证(Table 3/4 + 4.2 的 reasoning-enhanced 变体)。
- 三维泛化 + cross-embodiment:visual / instruction / action 三类分布外变化同时评测,外加 ALOHA 2 → bi-arm Franka → Apollo humanoid 的迁移,验证了 foundation model 范式可以在 embodiment 间转移 robustness。
- ERQA benchmark:填补了 VLM embodied reasoning 评测的缺口,400 题 multi-choice、7 个能力类别、28% 多图题——首次给出了能让 Gemini / GPT-4o / Claude 横向比较 embodied 理解能力的统一标尺。
Teaser. Gemini Robotics hero reel(website):多种机器人形态下的灵巧操作与长时序任务演示。
Introduction
Figure 1. Overview of the Gemini Robotics family of embodied AI models. Gemini 2.0 already exhibits capabilities relevant to robotics such as semantic safety understanding and long contexts. The robotics-specific training and the optional specialization processes enable the Gemini Robotics models to exhibit a variety of robotics-specific capabilities.
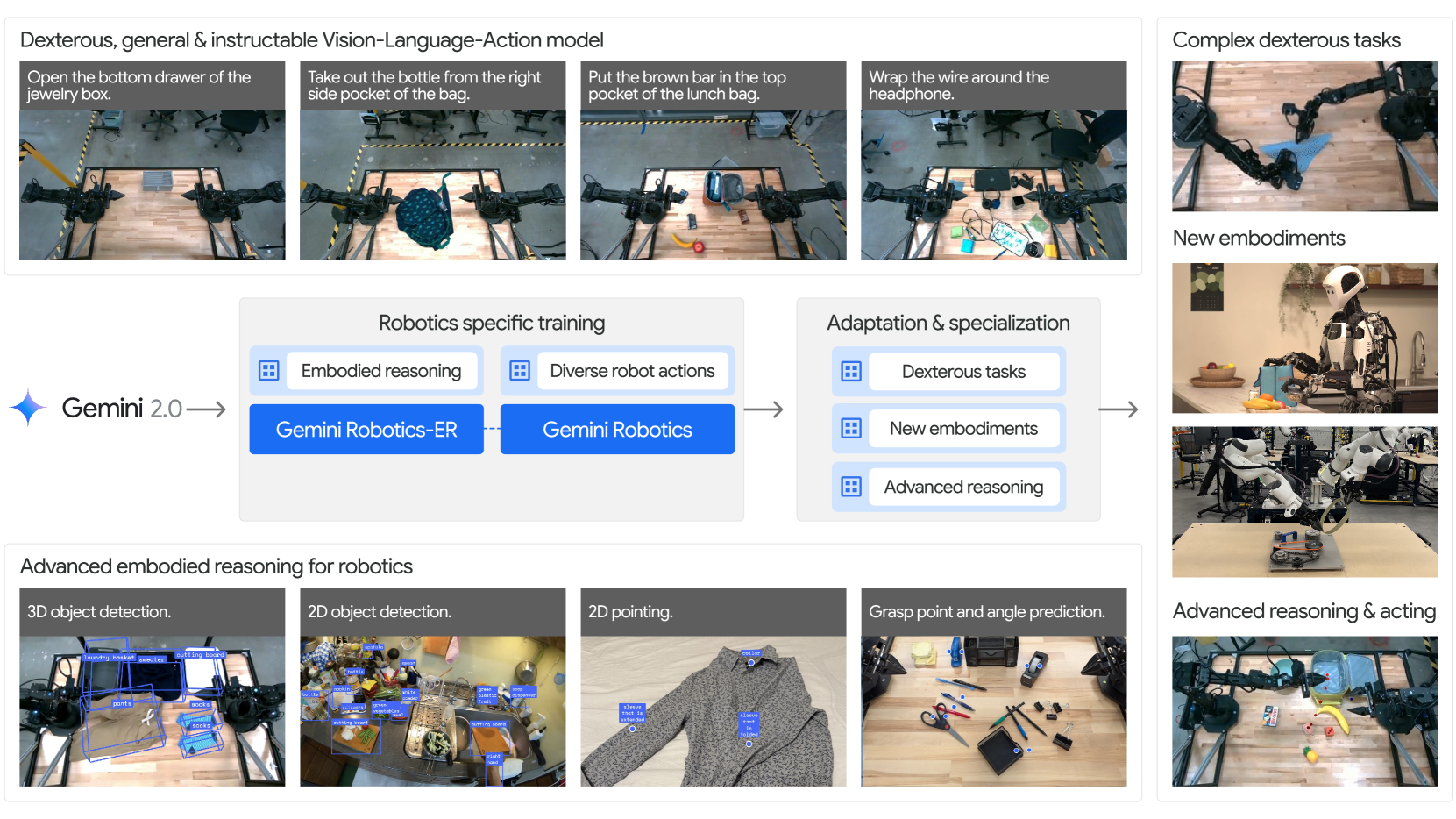
论文的论证主线分三段:(1) 在 Gemini 2.0 基础上训练 Gemini Robotics-ER,强化 embodied reasoning(Section 2);(2) 在 ER 的基础上训练 Gemini Robotics VLA,直接输出低层 action(Section 3);(3) 对 Gemini Robotics 进行专门化 / 快速适配 / 跨 embodiment 迁移,验证 generalist + specialist 范式(Section 4)。
Embodied Reasoning with Gemini 2.0
Figure 2. Gemini 2.0 excels at embodied reasoning capabilities — detecting objects and points in 2D, leveraging 2D pointing for grasping and trajectories, and corresponding points and detecting objects in 3D.

ERQA Benchmark
ERQA(Embodied Reasoning Question Answering)是本论文新提出的 embodied reasoning 评测集,400 道 multiple-choice VQA,覆盖 spatial reasoning、trajectory reasoning、action reasoning、state estimation、pointing、multi-view reasoning、task reasoning 七个类别。28% 的题目是多图——这些 multi-image correspondence 题是 benchmark 里最困难的部分。所有问题均由作者手工标注以保证质量,图像来源包括 OXE、UMI Data、MECCANO、HoloAssist、EGTEA Gaze+ 等数据集,或作者自行拍摄。Benchmark 代码已开源(见论文正文的 embodiedreasoning/ERQA 仓库引用)。
Figure 3. Example questions from the Embodied Reasoning Question Answering (ERQA) benchmark, with answers in bold.

Figure 4. ERQA question categories.
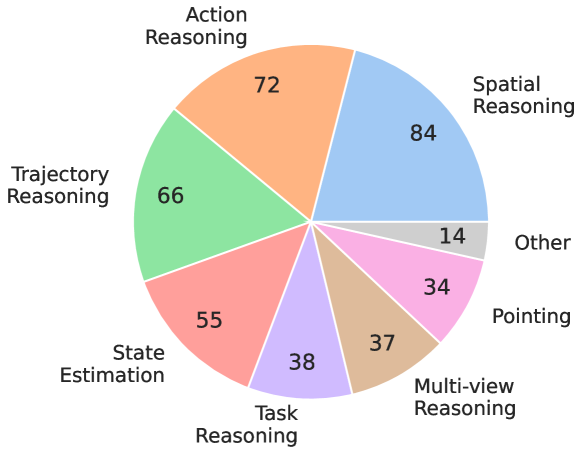
Table 1. Comparing VLMs on benchmarks that assess a wide range of embodied reasoning capabilities, including our new ERQA benchmark. Benchmarks are evaluated by accuracies of multiple-choice answers. Results obtained in Feb 2025.
| Benchmark | Gemini 1.5 Flash | Gemini 1.5 Pro | Gemini 2.0 Flash | Gemini 2.0 Pro Exp | GPT-4o-mini | GPT-4o | Claude 3.5 Sonnet |
|---|---|---|---|---|---|---|---|
| ERQA | 42.3 | 41.8 | 46.3 | 48.3 | 37.3 | 47.0 | 35.5 |
| RealworldQA (test) | 69.0 | 64.5 | 71.6 | 74.5 | 65.0 | 71.9 | 61.4 |
| BLINK (val) | 59.2 | 64.4 | 65.0 | 65.2 | 56.9 | 62.3 | 60.2 |
Insights: ERQA 是三个 benchmark 里最难的一档——即便是 Gemini 2.0 Pro Experimental 也只到 48.3%,远低于 RealworldQA 的 74.5%。Gemini 2.0 Flash(46.3%)与 GPT-4o(47.0%)几乎持平,Claude 3.5 Sonnet 只有 35.5%——说明 embodied reasoning 这一维度的 SOTA 差距远比传统 VQA 大。
Table 2. Performances on the ERQA benchmark with and without Chain-of-Thought (CoT) prompting.
| Prompt Variant | Gemini 2.0 Flash | Gemini 2.0 Pro Exp | GPT-4o-mini | GPT-4o | Claude 3.5 Sonnet |
|---|---|---|---|---|---|
| Without CoT | 46.3 | 48.3 | 37.3 | 47.0 | 35.5 |
| With CoT | 50.3 | 54.8 | 40.5 | 50.5 | 45.8 |
Insights: CoT 对所有模型都有明显提升——Gemini 2.0 Pro Exp 从 48.3 → 54.8(+6.5),Claude 3.5 Sonnet 收益最大(+10.3)。CoT 下 Gemini 2.0 Flash(50.3)已经超过了 Pro Experimental without CoT(48.3),说明 embodied reasoning 对 test-time compute 高度敏感。
Gemini 2.0’s Embodied Reasoning Capabilities
Gemini 2.0 / Gemini Robotics-ER 的 embodied reasoning 能力覆盖四个基本原语:
- Object Detection:open-world 2D bounding box,query 可以是显式(object name)也可以是隐式(category / attribute / affordance)。
- Pointing:从自然语言描述直接预测 2D point,支持显式实体(物体、部件)和隐式概念(where to grasp、where to place、free space、spatial relation)。
- Trajectory Prediction:基于 pointing 能力预测 2D motion trajectory,可以 grounded 在 physical motion 描述上。
- Grasp Prediction:Gemini Robotics-ER 新增能力,将 pointing 扩展到 top-down grasp 预测。
这些能力均为 open-vocabulary、无需针对特定物体训练。Gemini 2.0 还具备 3D 空间推理能力——跨多视角建立 2D point 对应,以及直接预测 open-vocabulary 3D bounding box。
Figure 6. 2D Detection examples with Gemini 2.0 Flash. Left: detect by object category. Middle: detect by spatial description. Right: detect by affordance.

Figure 7. Gemini 2.0 can predict 2D points from natural language queries.

Figure 8. Gemini 2.0 can predict 2D trajectories by first predicting start and end points.

Figure 9. Gemini Robotics-ER can predict top-down grasps by leveraging Gemini 2.0’s 2D pointing capability.

Figure 10. Gemini 2.0 can understand 3D scenes by correlating 2D points across different views.

Figure 11. Gemini 2.0 can directly predict open-vocabulary 3D object bounding boxes.
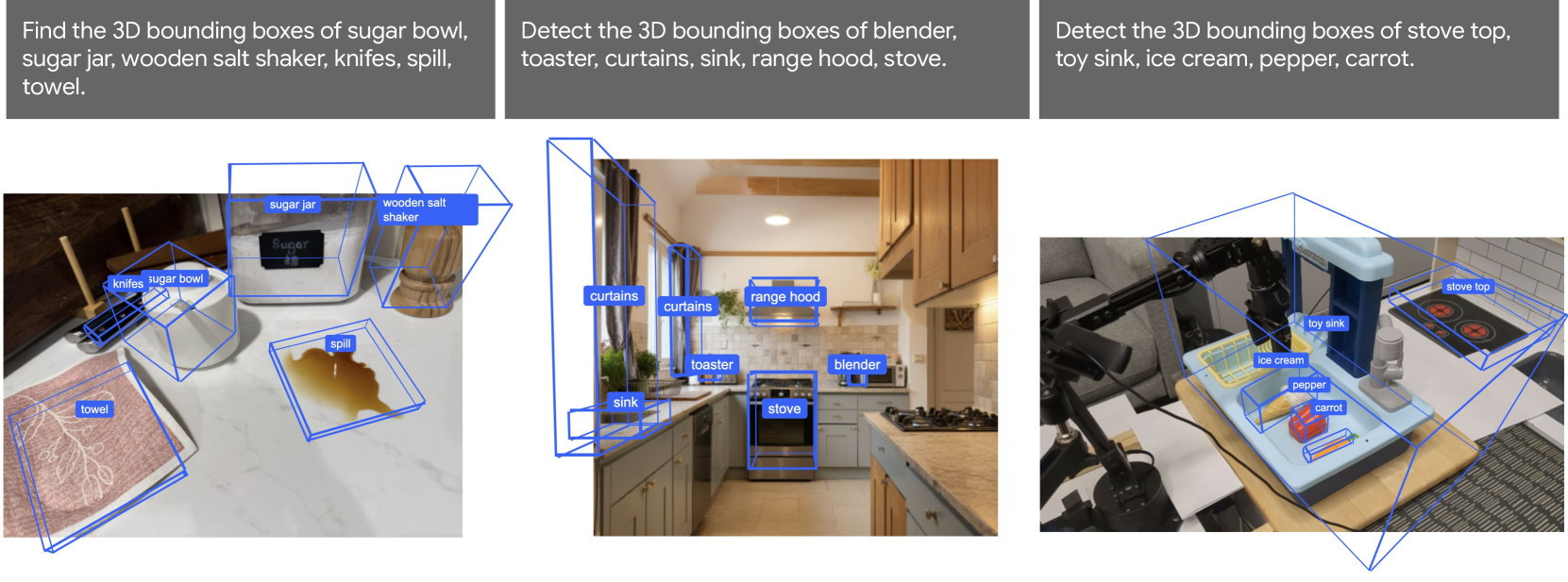
Table 3. 2D Pointing Benchmarks evaluating open-vocabulary pointing capabilities. Scores are accuracies (1 if predicted point is within the ground truth region mask, 0 otherwise).
| Benchmark | Gemini Robotics-ER | Gemini 2.0 Flash | Gemini 2.0 Pro Exp | GPT-4o-mini | GPT-4o | Claude 3.5 Sonnet | Molmo 7B-D | Molmo 72B |
|---|---|---|---|---|---|---|---|---|
| Paco-LVIS | 71.3 | 46.1 | 45.5 | 11.8 | 16.2 | 12.4 | 45.4 | 47.1 |
| Pixmo-Point | 49.5 | 25.8 | 20.9 | 5.9 | 5.0 | 7.2 | 14.7 | 12.5 |
| Where2Place | 45.0 | 33.8 | 38.8 | 13.8 | 20.6 | 16.2 | 45.0 | 63.8 |
Insights: Gemini Robotics-ER 的 targeted training 在 Paco-LVIS 和 Pixmo-Point 上把 base 模型的 pointing 精度几乎翻倍(46→71,26→50),说明 pointing 是可以被专门 fine-tune 的离散能力。在 Where2Place(affordance-level pointing)上仍被 Molmo 72B 反超(63.8 vs 45.0)——open-vocabulary 的 spatial placement 比物体 pointing 更困难。GPT-4o / Claude 在所有 pointing 任务上都显著落后,这反映出非 Google 系模型在这一维度缺乏针对性训练数据。
Table 4. Gemini Robotics-ER achieves a new state-of-the-art performance on the SUN-RGBD 3D object detection benchmark. ( ImVoxelNet performance measured on an easier set of 10 categories).*
| Benchmark | Gemini Robotics-ER | Gemini 2.0 Flash | Gemini 2.0 Pro Exp | ImVoxelNet | Implicit3D | Total3DU |
|---|---|---|---|---|---|---|
| SUN-RGBD AP@15 | 48.3 | 30.7 | 32.5 | 43.7* | 24.1 | 14.3 |
Insights: Gemini Robotics-ER 在 SUN-RGBD 3D detection 上达到 48.3 AP@15,不仅超过所有通用 VLM,也超过了传统专用 3D detection 模型 ImVoxelNet(43.7,且 ImVoxelNet 的数字还是在更简单的 10 类子集上测的)。这是论文里 reasoning 层面最硬的数字之一——一个 VLM 在专用 3D 任务上打败了专用模型。
Gemini 2.0 Enables Zero and Few-Shot Robot Control
作者用 Gemini Robotics-ER 的 embodied reasoning 直接驱动 ALOHA 2 双臂机器人,完全不使用任何 robot action 训练数据。两种模式:
Zero-shot via Code Generation:给模型一套 perception / control API(move gripper to pose、open / close gripper 等),让 Gemini 通过 code generation 产出控制逻辑。相比以往”多个模型拼接”的 pipeline,Gemini 用单一模型统合了 perception、state estimation、spatial reasoning、planning、control 所有环节。
Few-shot via In-Context Learning:把 observation + language instruction + 若干 trajectory 作为 in-context 示例喂给模型,让它在 prompt 内完成学习。
Figure 12. Overview of the perception and control APIs, and agentic orchestration during an episode. This system is used for zero-shot control.
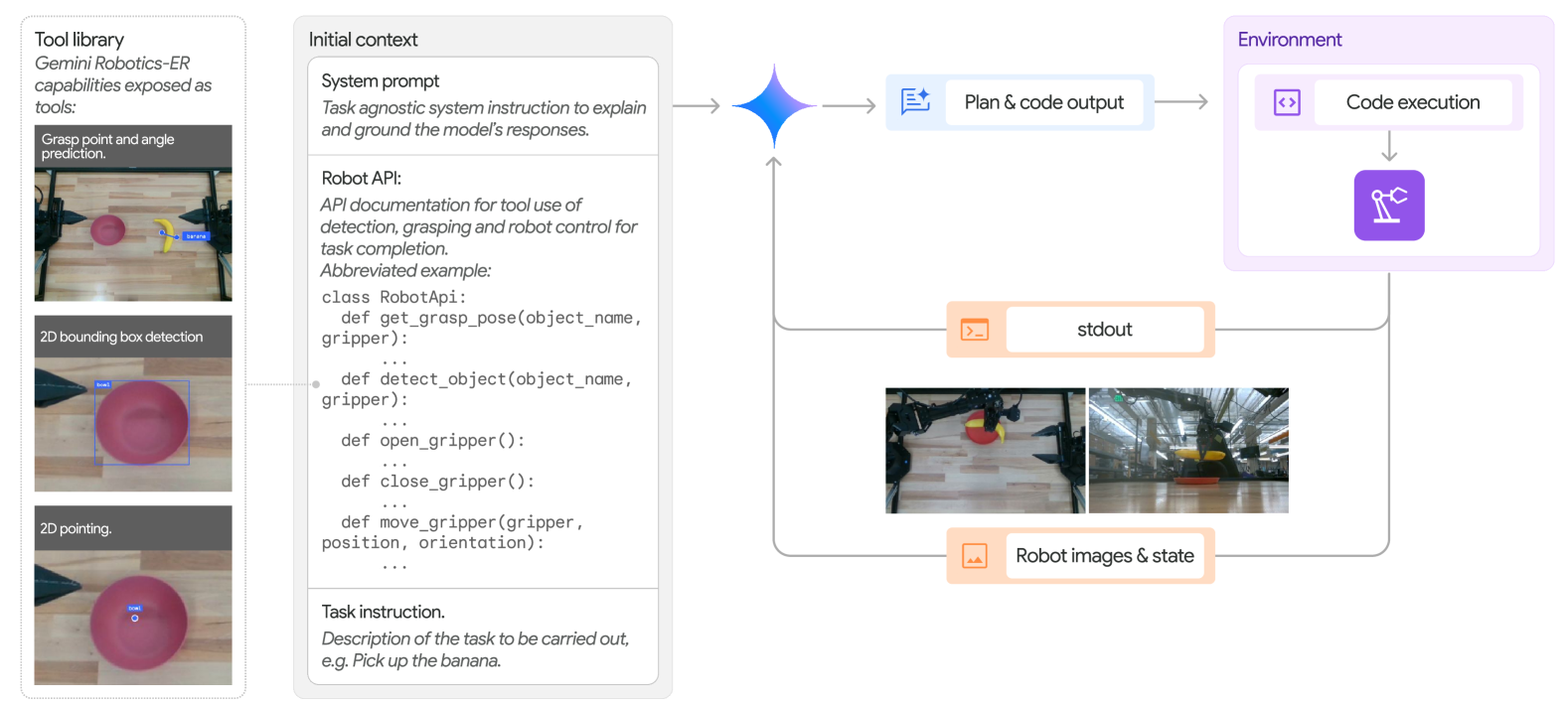
Figure 13. Overview of few-shot in-context learning pipeline. Gemini can receive observations, language instructions and trajectories in the prompt.
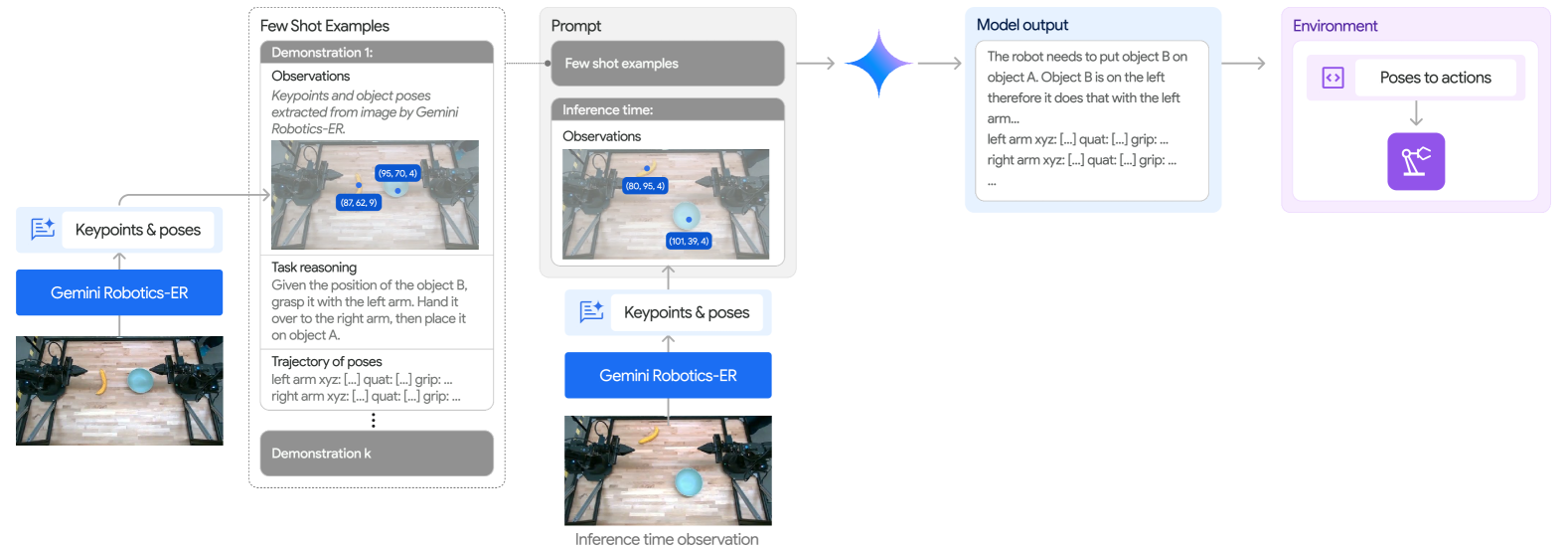
Table 5. Success rates on the ALOHA 2 Sim Task suite. Reported numbers are the average success rate over 50 trials with random initial conditions.
| Model | Context | Avg. | Banana Lift | Banana in Bowl | Mug on Plate | Bowl on Rack | Banana Handover | Fruit Bowl | Pack Toy |
|---|---|---|---|---|---|---|---|---|---|
| Gemini 2.0 Flash | Zero-shot | 27 | 34 | 54 | 46 | 24 | 26 | 4 | 0 |
| Gemini Robotics-ER | Zero-shot | 53 | 86 | 84 | 72 | 60 | 54 | 16 | 0 |
| Gemini 2.0 Flash | ICL | 51 | 94 | 90 | 36 | 16 | 94 | 0 | 26 |
| Gemini Robotics-ER | ICL | 65 | 96 | 96 | 74 | 36 | 96 | 4 | 54 |
Insights: Gemini Robotics-ER 相比 Gemini 2.0 Flash 在 zero-shot 下几乎翻倍(27 → 53)——这是作者强调”better embodied understanding 直接翻译成更好的 control”的核心证据。ICL 在两个模型上都显著提升(Flash 27→51、ER 53→65),但 Pack Toy 这类多步任务即便 ER + ICL 也只有 54%,zero-shot code generation 甚至 0%。Fruit Bowl 更惨——所有配置 ≤16%。说明 zero-shot 能力仍有明显上限,在 multi-step / contact-rich 任务上特别吃紧。
Table 6. Real world success rates of Gemini Robotics-ER on ALOHA 2 tasks.
| Context | Avg. | Banana Handover | Fold Dress | Wiping |
|---|---|---|---|---|
| Zero-shot | 25 | 30 | 0 | 44 |
| ICL | 65 | 70 | 56 | 67 |
Insights: 真实 ALOHA 2 上,Fold Dress zero-shot 是 0%——deformable object 对 code generation 的 geometric 描述能力提出了过高要求。ICL 把平均值从 25% 拉到 65%,尤其 Fold Dress 从 0 拉到 56%,说明示例轨迹对 deformable manipulation 的价值远大于对 rigid 任务的价值。注意 Banana Handover 的 sim-to-real gap:Table 5 sim ICL 96% vs Table 6 real ICL 70%——真实物理接触比仿真难很多。
Robot Actions with Gemini Robotics
Gemini Robotics: Model and Data
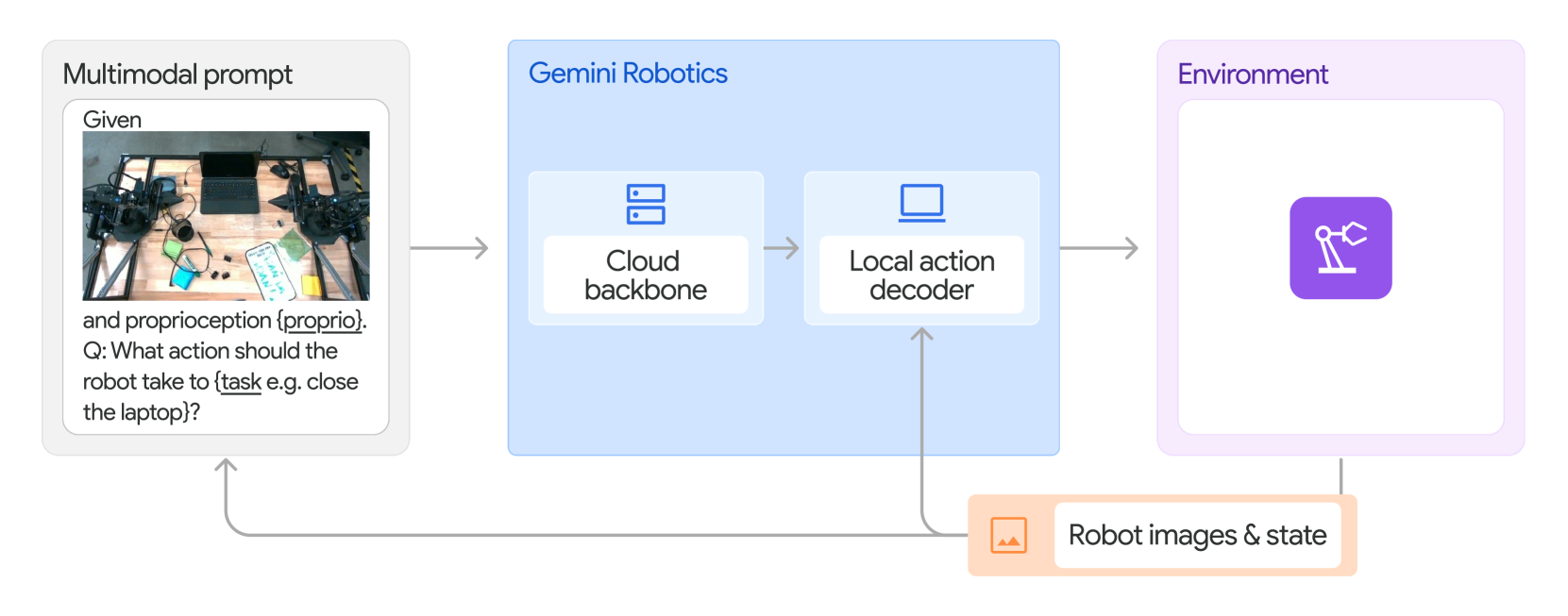
架构:Gemini Robotics 由两部分组成:
- Gemini Robotics backbone(云端):Gemini Robotics-ER 的蒸馏版本,query-to-response latency 从秒级优化到 <160ms。
- Gemini Robotics decoder(本地):运行在机器人自身算力上的 action decoder,负责补偿 backbone 的延迟。
端到端 latency 约 250ms,配合 action chunk(一次预测多步 action)达到 50Hz 的有效控制频率。作者明确指出,backbone + local decoder 的组合既保留了大模型的泛化能力,又产出 smooth / reactive 的运动——这是论文方法层面最核心的工程 trick。
Figure 14. Overview of the architecture, input and output of the Gemini Robotics model. Gemini Robotics is a derivative of Gemini fine-tuned to predict robot actions.
数据:作者在 ALOHA 2 robot fleet 上采集了 数千小时 真实世界 expert 遥操作数据,历时 12 个月,覆盖数千个 diverse task,跨越不同 manipulation skill、object、task 难度、episode 时长和灵巧度。训练 mixture 里还混入了 non-action 数据——web documents、code、multi-modal content(image / audio / video),以及 embodied reasoning 和 VQA 数据——作者认为这种 mixture 对 understanding、reasoning 和跨任务泛化都有帮助。
Baselines:两个 SOTA 对照组。
- π0 re-implement:作者自行复现的开源 π0,在其多样化数据 mixture 上训练;实测比原作发布的 checkpoint 更强,因此作为主要 VLA baseline。
- Multi-task diffusion policy:受 ALOHA Unleashed 启发但改为 task-conditioned 的多任务扩散策略 baseline。
两个 baseline 均用完全相同的训练数据 mixture 训练至收敛,且都跑在本地 RTX 4090 上,而 Gemini Robotics 主要跑在云端。
Gemini Robotics can solve diverse dexterous manipulation tasks out of the box
从 20 个 diverse 任务中采样,覆盖 laundry、kitchen、cluttered desk 等日常场景,所有任务均 out-of-the-box 评测,无 task-specific fine-tune、无额外 prompt。
Figure 15. A robot’s movement in example tasks: “open the eyeglasses case”, “pour pulses”, “unfasten file folder”, “wrap headphone wire”.

Figure 16. Gemini Robotics can solve a wide variety of tasks out of the box. Gemini Robotics significantly outperforms the baselines.
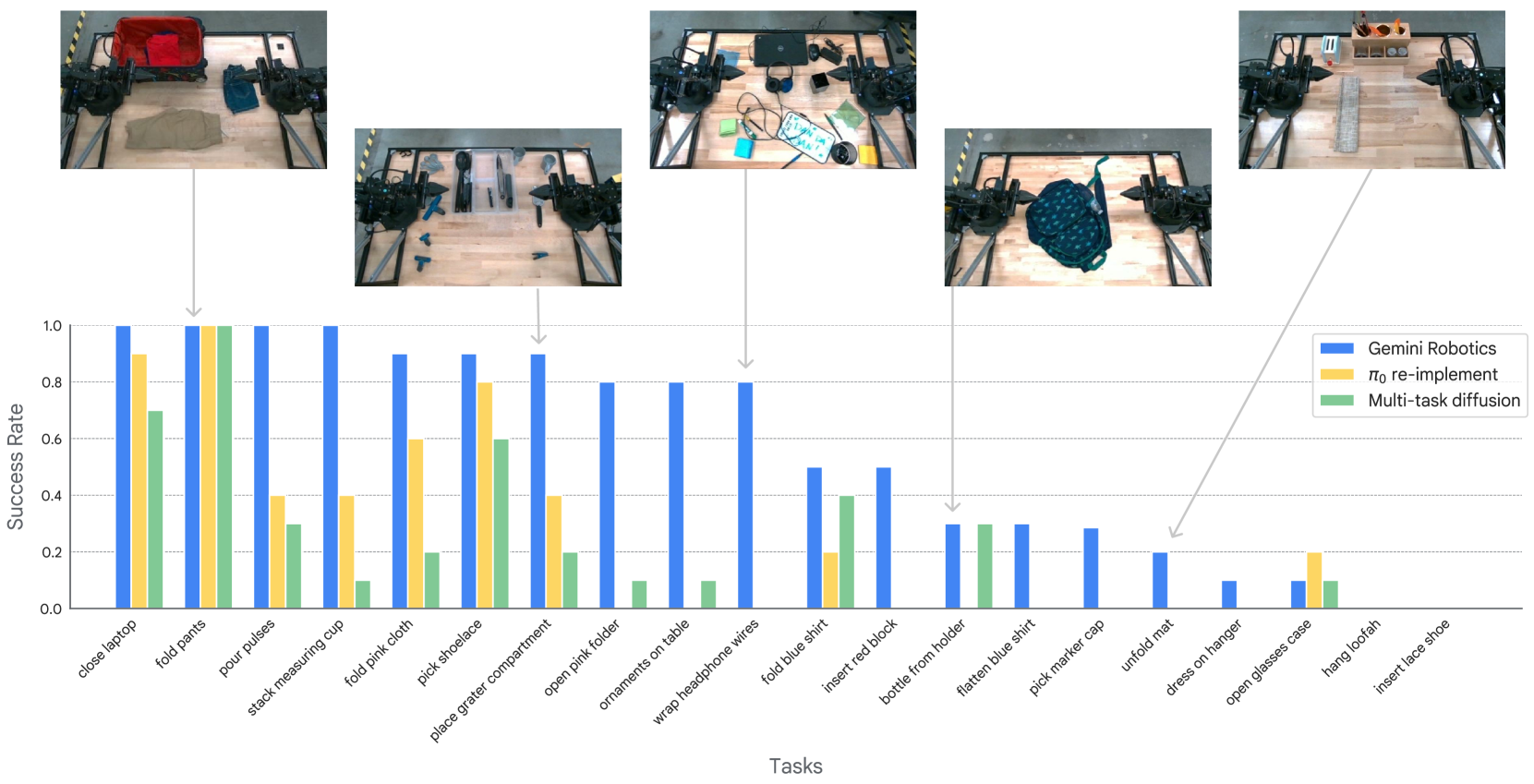
Gemini Robotics can closely follow language instructions
25 条 fine-grained language instruction × 5 scene(含训练场景 + unseen object / receptacle 场景)。评测聚焦于”必须被精确遵守的命令”(“Place the blue clip to the right of the yellow sticky notes”),而非开放式任务(“clean the table”)。
Figure 17. Gemini Robotics can precisely follow novel language instructions in cluttered scenes never seen during training.

作者得到两个观察:(1) strong steerability 来自 “high-quality diverse data + 强 VL backbone” 的组合——Gemini Robotics 和 π0 re-implement 都超过了 diffusion baseline,说明强语言编码器是必要的;(2) 在 cluttered novel scene + fine-grained 描述(“Place the toothpaste in the bottom compartment of the caddy”)上,Gemini Robotics 比两个 baseline 都更有效——而 π0 re-implement 虽然能正确接近训练时见过的物体,但在解释描述性语言属性(“top black container”、“blue clip”)和处理 unseen 物体时会失败。
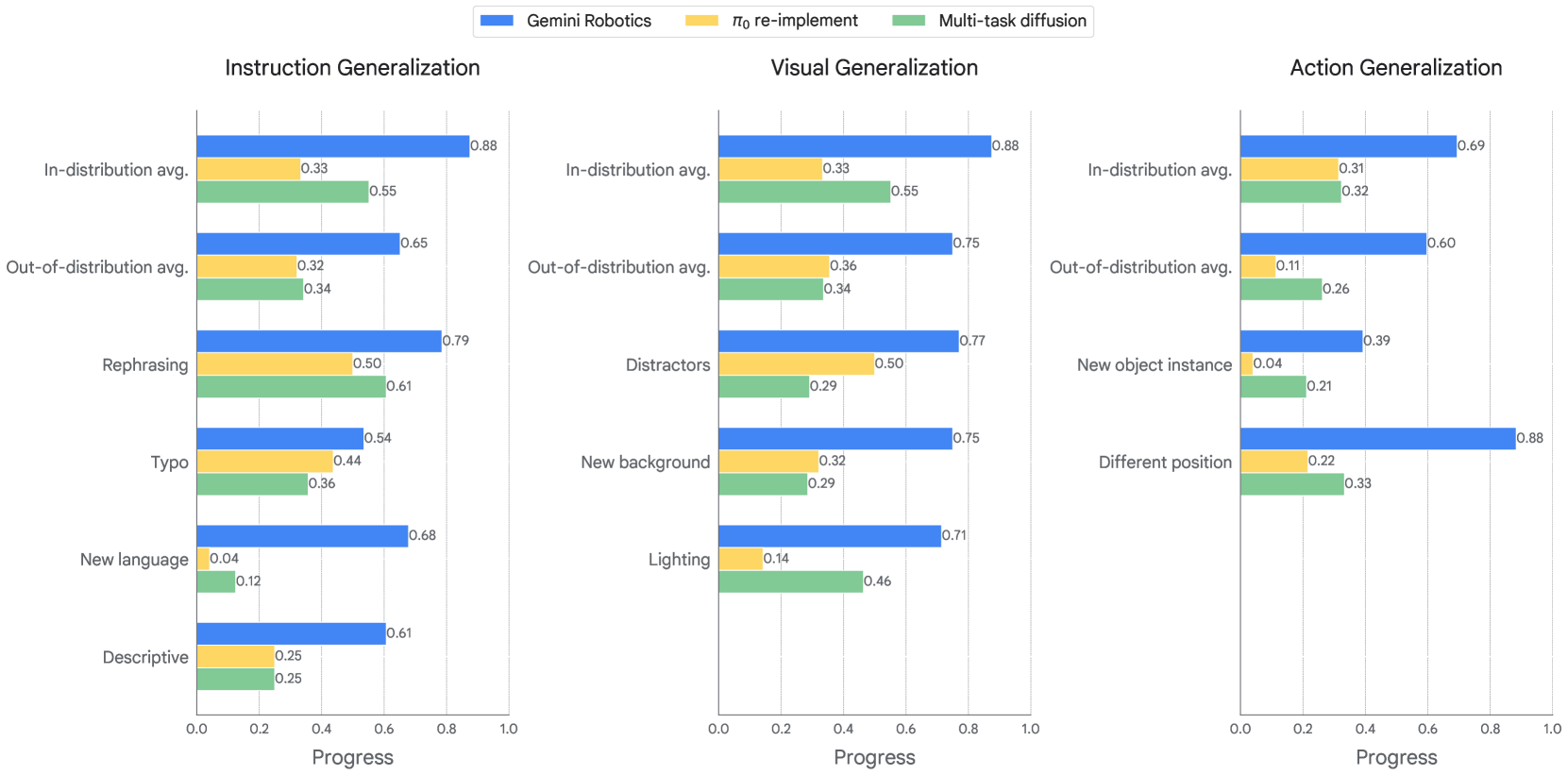
Gemini Robotics brings Gemini’s generalization to the physical world
作者在三个 generalization 轴上系统评估:
- Visual generalization:不影响所需 action 的视觉变化——背景、光照、干扰物、纹理。
- Instruction generalization:自然语言的等价性和不变性——paraphrasing、typos、不同语言、不同细节层级的描述。
- Action generalization:适配学到的运动或合成新运动——初始条件(物体位置)和物体实例(形状、物理属性)。
Figure 18. Example tasks for measuring visual generalization.

Figure 19. Example tasks for measuring instruction generalization.

Figure 20. Example tasks for measuring action generalization.
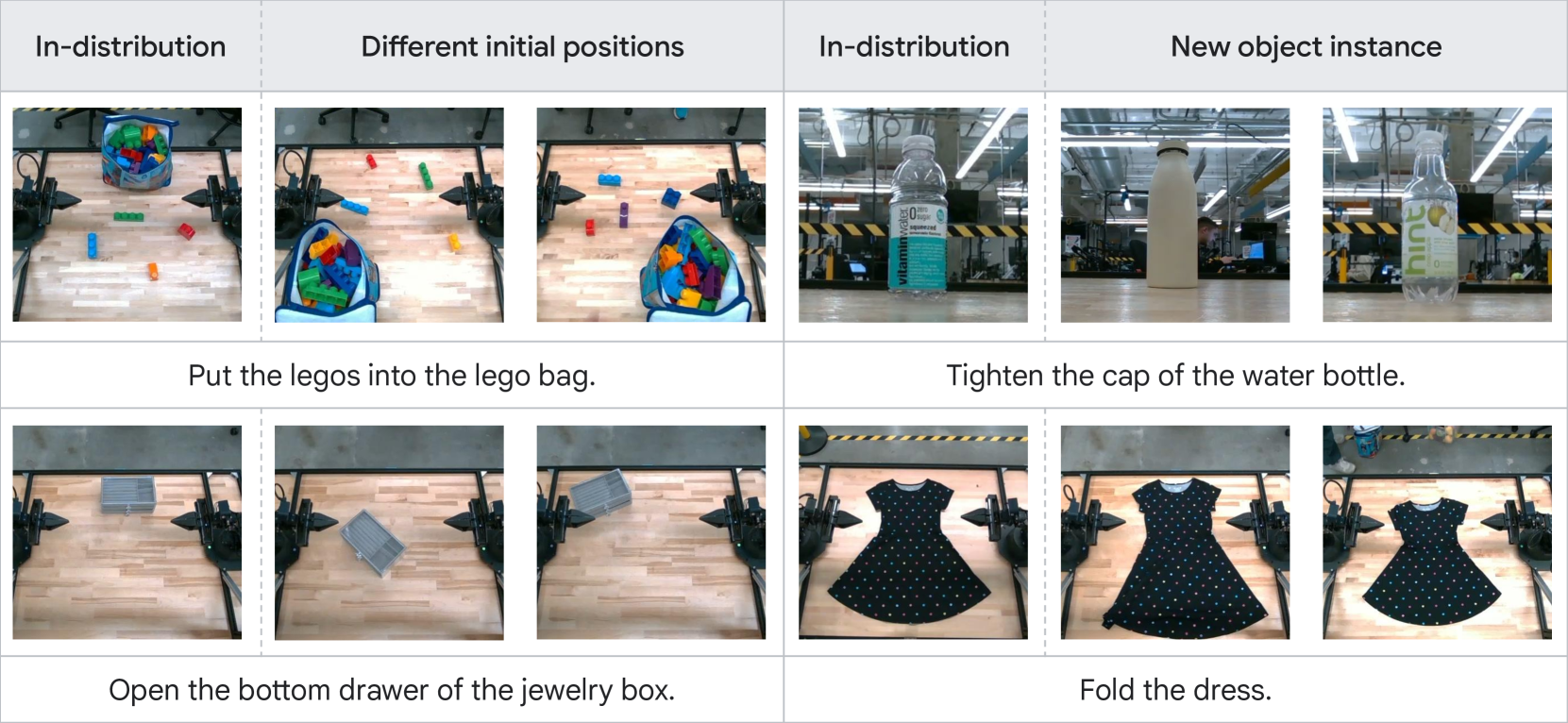
Figure 21. Breakdown of Gemini Robotics generalization capabilities. Gemini Robotics consistently outperforms the baselines and handles all three types of variations.
Specializing and Adapting Gemini Robotics for Dexterity, Reasoning, and New Embodiments
这一节把 generalist Gemini Robotics 推向四个极限方向:(1) 用 fine-tune 让它解决远超 generalist 能力的长时序高灵巧任务;(2) 通过 embodied reasoning 增强 generalization;(3) 快速适配新任务;(4) 快速适配新 embodiment。前两个是”能力上限”探索,后两个是”部署可行性”验证。
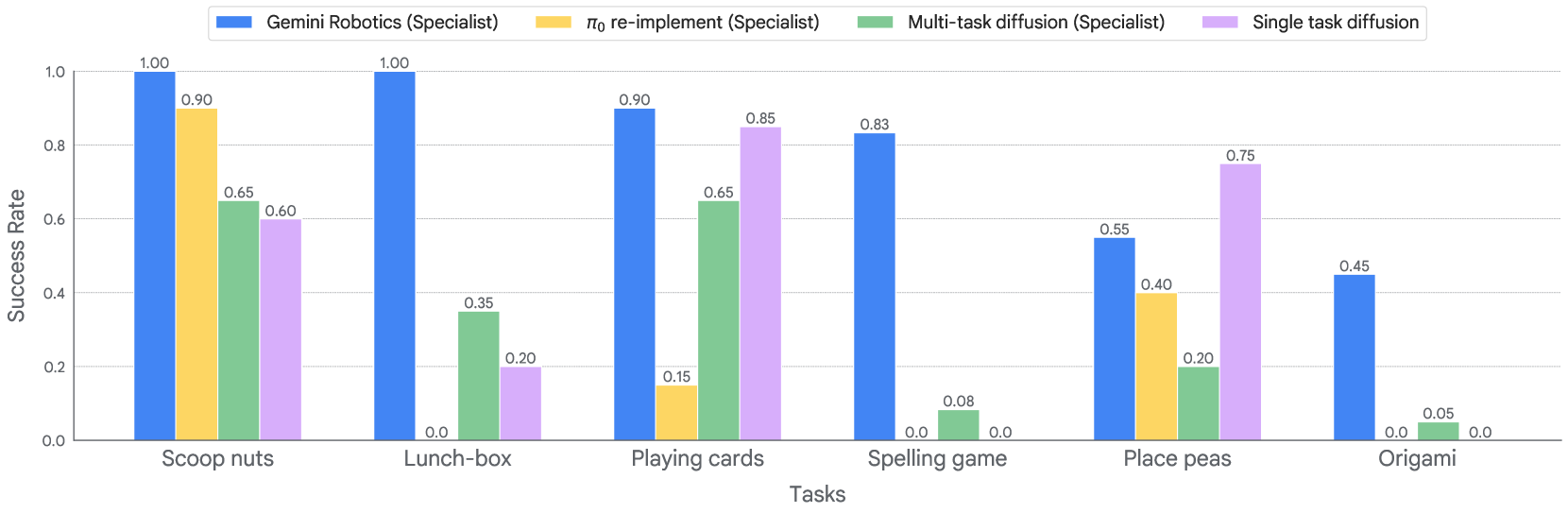
Long-horizon dexterity
用少量高质量数据 fine-tune,让模型专门化解决六个长时序高灵巧任务:
- Make an origami fox:四次精确折叠,每次需要对齐、弯折、捏紧、压痕;纸层越叠越厚,任何小误差都会导致不可恢复的失败。
- Pack a lunch-box:把面包插入塑料袋窄缝、拉链封口、转移葡萄到容器、盖盖、整包放入午餐袋、最后拉链——多处需要双臂精确协同。
- Spelling board game:人放置/画出字母,机器人识别并拼出单词。
- Play a game of cards、origami + salad add-ons 等。
Figure 22. Gemini Robotics successfully accomplishes long-horizon dexterous tasks on ALOHA: “make an origami fox”, “pack a lunch-box”, “spelling board game”, “play a game of cards”, “add snap peas to salad with tongs”, “add nuts to salad”.

Figure 23. Performance on new, dexterous and long-horizon tasks after specialization. Gemini Robotics is the only model that can consistently solve the extremely challenging long-horizon tasks.
Enhanced reasoning and generalization
这一节尝试回答一个开放问题:VLA 把 action prediction 塞进 VLM 之后,有没有保留住上游 reasoning 能力?作者用一个重新标注的 action dataset——把 trajectory 理解/生成(Section 2.2 里的 reasoning intermediate)与 low-level action 桥接——fine-tune 出一个 reasoning-enhanced 变体。本地 action decoder 被扩展成能把这些 reasoning intermediate 转换为连续低层 action。
评测集特别设计为同时包含 visual + instruction + action 三重分布偏移——也就是作者主张这些是”真正考验 reasoning”的组合。
Figure 24. Performance on real-world robot tasks that require embodied reasoning. After fine-tuning on a re-labeled action dataset that bridges action prediction with embodied reasoning, the reasoning-enhanced variant substantially outperforms the vanilla Gemini Robotics.
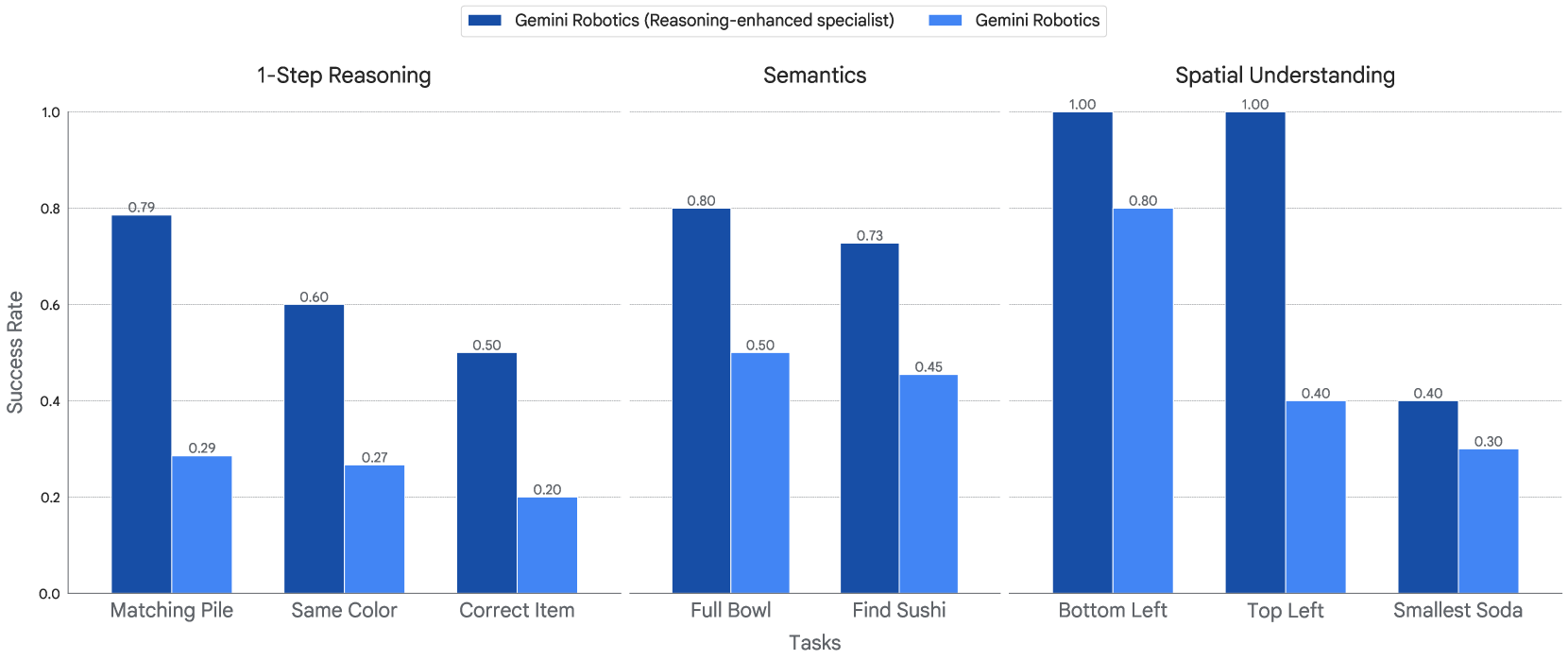
Figure 25. Visualizations of predicted trajectories utilized as part of the reasoning-enhanced Gemini Robotics model’s internal chain of thought.

Fast adaptation to new tasks
作者从前述 long-horizon 任务里抽出 8 个 short-horizon 子任务,改变 fine-tune 数据量,测试 Gemini Robotics generalist checkpoint 的快速适配能力。
Figure 26. Fast adaptation to new tasks with a limited number of demonstrations. Fine-tuning Gemini Robotics achieves over 70% success on 7 out of 8 tasks with at most 100 demonstrations, reaching 100% success on two tasks.
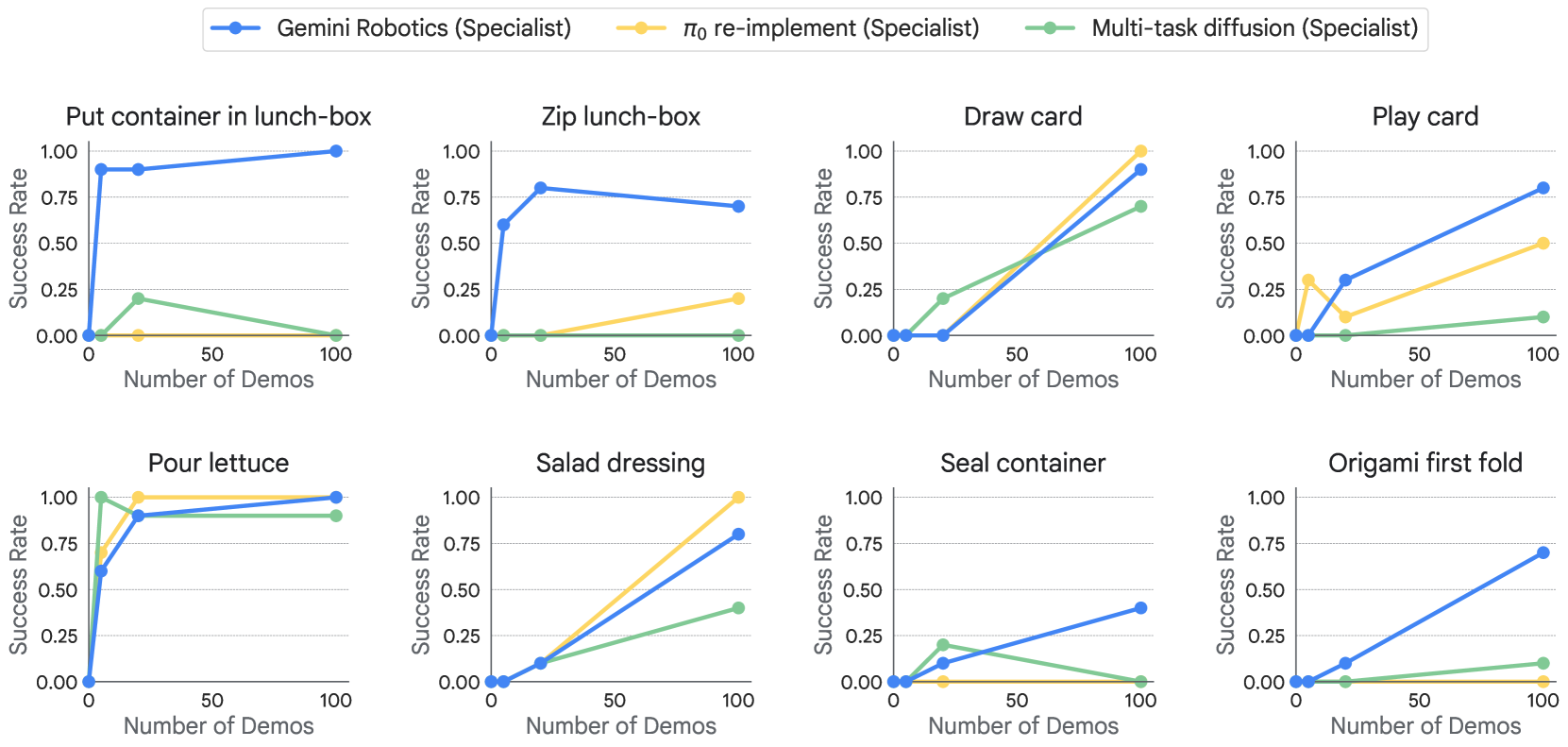
结果:仅 100 条 demonstration 就在 7/8 任务上拿到 >70% 成功率,其中 2 个任务达到 100%。在”困难任务”(origami first fold、lunch-box manipulation)上,即使 baseline 在简单任务上也不差,Gemini Robotics 的优势仍然显著——说明 foundation model 的 pre-training 在复杂任务上的 sample efficiency 收益更大。
Adaptation to new embodiments
作者把只在 ALOHA 2 上训练的 Gemini Robotics 迁移到两个新平台:
- Bi-arm Franka(平行夹爪):fine-tune 后可解决所有考察任务,平均成功率 63%。
- Apollo humanoid(Apptronik,五指灵巧手):初步实验成功,示例包括 pack a lunch bag。
Figure 27. The Gemini Robotics model can be fine-tuned to control different robots. Top: Apollo humanoid packs a lunch bag. Bottom: A bi-arm industrial robot assembles a rubber band around a pulley.

Figure 28. Breakdown of generalization metrics when the Gemini Robotics model is adapted to a new embodiment, the bi-arm Franka robot. It consistently outperforms the single-task diffusion baseline in visual and action generalization tests.
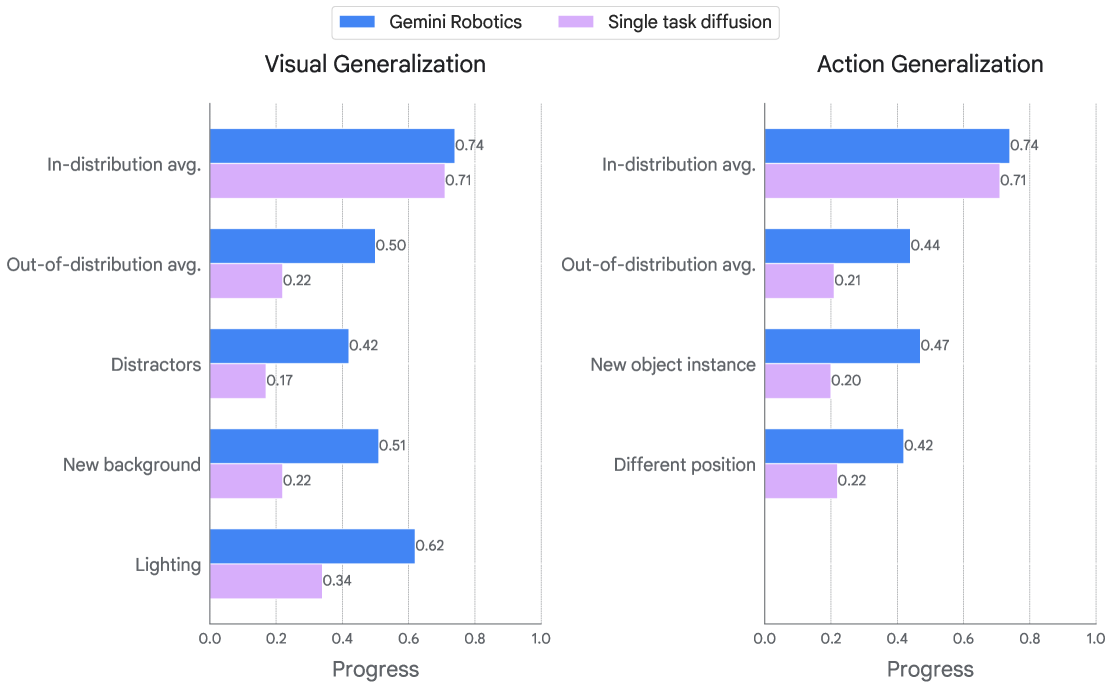
关键发现:in-distribution 成功率与 single-task diffusion policy 相当或略好,但在视觉扰动、初始条件扰动、物体形状变化上显著超过 baseline。这说明 Gemini Robotics 在跨 embodiment 迁移时把 robustness 和 generalization 能力也一并带了过去——这才是 foundation model 相比 per-task 模型的本质优势。
Responsible Development and Safety
作者把 safety 作为独立一节讨论,强调传统 robot safety 是多面向学科(hazard mitigation、human-robot interaction、physical constraints),而 robot foundation model 在”embodied 数字-物理混合”特性下需要额外考量。论文中使用 ASIMOV-Multimodal 场景对模型进行 semantic safety 评估:给一个 “robot chef” context,让模型判断”把沸腾液体倒进垃圾桶”这种指令是否 undesirable——模型正确识别为危险并拒绝执行。safety 工作由 Google DeepMind 的 Responsibility and Safety Council(RSC)和 Responsible Development and Innovation(ReDI)团队指导完成。
关联工作
基于
- Gemini 2.0:本模型的 VLM backbone 和 embodied reasoning 能力的起点
- ALOHA 2 硬件与 ALOHA Unleashed:数据采集平台与多任务 diffusion baseline 的灵感来源
对比
- π0:作为主要 VLA baseline,用作者自己的数据重训后作为”最强 VLA baseline”;论文 Section 3.3 / 3.4 / 4.3 反复与其对比
- Multi-task diffusion policy:task-conditioned diffusion baseline,覆盖”非 VLA 的 SOTA multi-task policy”比较维度
方法相关
- Embodied reasoning / pointing:与 Molmo、RoboPoint、SpatialVLM 等先前工作相关(ERQA 与 RealworldQA、BLINK 互补)
- Code generation for robot control:与 Code as Policies、VoxPoser、RoboCodeX 等 zero-shot 控制路径相关
- In-context learning for robot control:对应 VIMA、Diffusion-ICL 等少样本控制工作
论文点评
Strengths
- Cloud backbone + local decoder 的工程分解非常务实。把”大模型慢但强”和”实时控制快但弱”的矛盾用 action chunk + local decoder 化解,最终拿到 50Hz 有效控制频率——这是目前云端 VLA 方案里 latency 与能力之间最可信的一个平衡点。
- “先建 reasoning,再建 action”的 stack 顺序有证据支撑。Table 5 里 Gemini Robotics-ER 相比 Gemini 2.0 Flash 在 zero-shot control 上翻倍(27→53),Section 4.2 里 reasoning-enhanced 变体进一步提升 OOD 任务表现——两处数据共同支撑了”embodied reasoning 是 VLA 上限”的叙事。
- Cross-embodiment 迁移不仅看 in-distribution 成功率,还专门测 robustness。Figure 28 显示 Gemini Robotics 在 visual + action generalization 测试里显著超过 diffusion baseline——这比单看成功率更能证明 foundation model 迁移的是”泛化能力”而不只是任务知识。
- ERQA benchmark 填补真实空白。400 题、7 类别、28% 多图——embodied reasoning 此前缺乏能横向比较 Gemini / GPT-4o / Claude 的标准评测,ERQA 给社区提供了统一标尺。
- 数据规模 + 任务多样性在当前 VLA 文献里处于第一梯队。数千小时 × 12 个月 × 数千任务,加上 20 任务 out-of-the-box 评测和 85 任务 generalization 评测,实验覆盖面远超绝大多数 VLA 论文。
Weaknesses
- 极精细操作仍有天花板。论文正文没有详细展开 shoelace 类任务的结果,但 Figure 23 表明一些精细任务依然接近 0%——dexterous manipulation 的”最后一公里”还没突破。
- Sim-to-real gap 显著。Banana Handover 从 sim ICL 96%(Table 5)掉到 real ICL 70%(Table 6),Fold Dress sim-to-real 差距更大——部署到物理世界的可靠性仍是挑战。
- π0 baseline 使用作者自己的数据重训,优势归因困难。作者在 Section C.2 承认 re-implement 版本比原作开源 checkpoint 更强,但这样一来 Gemini Robotics 相对 π0 的 gap 同时混入了”架构差异”和”训练 recipe 差异”两个变量,读者无法判断究竟是哪个带来提升。
- Zero-shot code generation 在多步任务上仍有明显瓶颈。Table 5 的 Pack Toy 任务 zero-shot 为 0%,Fruit Bowl 在所有 configuration 下均 ≤16%——论文叙事强调 zero-shot 能力,但数据显示 zero-shot 仍是选择性可用。
- Cross-embodiment 覆盖仍然初步。bi-arm Franka 63% 和 Apollo 的”初步实验成功”之间有巨大的颗粒度差异,Apollo 上没有与 Franka 对等的成功率数字——humanoid 部分更像是 demo,不是严格评测。
- 权重和数据未公开,Trusted Tester 门槛高。官方 Safari SDK(
google-deepmind/gemini-robotics-sdk)虽然开源了完整的 checkpoint 访问 / serving / fine-tune 工具链,但所有 checkpoint 的实际下载仍被 Gemini Robotics Trusted Tester Program 限制——普通社区研究者既拿不到权重也拿不到训练数据,独立验证与社区扩展仍严重受限。
可信评估
Artifact 可获取性
- 代码: 部分开源。官方 Safari SDK(
google-deepmind/gemini-robotics-sdk,PyPI 可装safari_sdk)提供完整的 checkpoint 访问、模型 serving、真机/仿真评估、数据上传、fine-tune、checkpoint 下载工具链,以及一个包含 Aloha embodiment 的 agent framework(对接 Gemini Live API)。flywheel CLI 暴露train/serve/list/data_stats/download/upload_data命令。ERQA benchmark 单独开源(github.com/embodiedreasoning/ERQA) - 模型权重: checkpoint 不开放给一般公众——必须加入 Gemini Robotics Trusted Tester Program 才能通过 SDK 访问;SDK v2.4.1 起额外支持 Gemini Robotics On Device 模型。没有任何可直接下载的权重
- 训练细节: 仅高层描述(“thousands of hours of teleoperated data over 12 months”、“mixture of web + code + multi-modal + embodied reasoning + VQA data”),无具体 recipe、超参或 data ratio
- 数据集: 私有(ALOHA 2 遥操作数据未开源);ERQA 的图像来源开源(OXE、UMI Data、MECCANO、HoloAssist、EGTEA Gaze+)
Claim 可验证性
- ✅ Gemini Robotics-ER 在 ERQA、Paco-LVIS、Pixmo-Point、SUN-RGBD 上的 SOTA 数字:Table 1/3/4 提供完整 benchmark 对比,ERQA 开源,结果原则上可以第三方复现
- ✅ Sim ALOHA 2 zero-shot/ICL 控制成功率:Table 5 有具体数字、50 trial 统计
- ⚠️ “端到端 250ms、50Hz 有效控制”:无法独立验证——取决于未公开的 local decoder 和 backbone 蒸馏细节
- ⚠️ “Out-of-the-box 20 任务显著优于 π0 re-implement 和 diffusion baseline”:Figure 16 是柱状图,正文无完整数字表;且 π0 baseline 是作者自己复现的版本,不是原作 checkpoint
- ⚠️ “Origami fox 等 long-horizon 任务的成功率”:Figure 23 是可视化 breakdown,正文没有给出精确的数字表
- ⚠️ Cross-embodiment bi-arm Franka 63%:有数字但没有 trial 数,且具体任务分解在附录 D.4
- ❌ “bridges the gap between passive perception and active embodied interaction”:营销级叙事,无法用单一实验验证
Notes
- Cloud backbone + local decoder 是把大模型塞进真实机器人的一个可复用范式。延迟预算的拆分方式(backbone <160ms + local decoder 补偿)是工程上最值得迁移的部分
- “先建 ER 再蒸馏成 VLA” 的 stack 顺序在本论文和后续 Gemini Robotics 1.5 / ER 1.6 系列中都得到延续——验证了”embodied reasoning 是 VLA 能力上限”的假设
- ERQA 作为 benchmark 的设计很克制——7 个类别、400 题、28% 多图,不追求规模而追求 coverage。这种规模适合作为 evaluation 而非 training set
- 与 π0 的对比需要谨慎解读:π0 re-implement 训练在作者自己的数据 mixture 上,理论上比原作开源 checkpoint 更强,但也不能说”公平对比了两个架构”——更准确的说法是”在 Google 的数据 mixture 上,Gemini Robotics 架构优于 π0 架构”
- Cross-embodiment 的迁移部分是本论文最 exciting 也最不完整的一段——bi-arm Franka 有清晰数字,Apollo humanoid 只有 demo,距离”foundation model 真正跨 embodiment”还有一大段
Rating
Metrics (as of 2026-04-24): citation=0, influential=0 (0%), velocity=0.00/mo; HF upvotes=31; github 576⭐ / forks=51 / 90d commits=4 / pushed 10d ago
分数:3 - Foundation 理由:Google DeepMind 旗舰 VLA,笔记 Strengths 列出的”cloud backbone + local decoder”工程范式、“先建 ER 再蒸馏成 VLA”的 stack 顺序、以及 ERQA benchmark 三项贡献已在笔记 Notes 中被记录为后续 Gemini Robotics 1.5 / ER 1.6 系列的延续基础;外部信号上这是 Google 系 embodied AI 一整条产品线的起点,被 generalist robot policy 与 embodied reasoning 两个方向的主要后续工作作为必引 reference。相比 2 - Frontier(仅限当前 SOTA / 必比 baseline),它的影响力已经外溢到”范式参考”层面;但相比 3 的纯 dataset/benchmark 型 foundation(如 DROID),这里的 Foundation 价值更多来自方法范式与产品级 demo 而非开放 artifact——weights 与数据至今被 Trusted Tester Program 限制,这压低了 reproducibility 价值,但不改变其在方向脉络里的必读地位。2026-04 复核:S2 检索显示 citation=0 / influential=0 属数据异常(arxiv 2503.20020 发布 13mo 但 S2 未完整 index),实际领域影响力以 github 576⭐ + HF 31 upvotes + 持续 push(4 commits / 90d, pushed 10d)+ Gemini Robotics 1.5 / ER 1.6 系列明确延续为佐证,维持 Foundation。