Summary
SpatialVLM: Endowing Vision-Language Models with Spatial Reasoning Capabilities
- 核心: VLM 缺空间推理不是架构问题,是数据问题——用 off-the-shelf vision experts 把 10M 互联网图像自动 lift 成 metric 3D,合成 2B 条空间 VQA,cotrain 后 VLM 能定性定量地推理 3D 空间关系
- 方法: 数据合成 pipeline = CLIP filter → region caption (FlexCap) + segmentation + ZoeDepth metric depth → 3D point cloud + canonicalize 到 geodetic 坐标 → 38 类问题模板 × 20 question + 10 answer 模板 → 2B QA pairs;以 PaLM 2-E (PaLM-E with PaLM 2-S backbone) 为底座 cotrain,spatial token 占 5%
- 结果: qualitative VQA 75.2% (vs GPT-4V 68.0%, LLaVA-1.5 71.3%);quantitative 99% 输出有效数字 + 37.2% 落在 [0.5×, 2×] 区间;不损 OKVQA / VQAv2 通用 VQA;可作机器人 dense reward annotator
- Sources: paper | website | github
- Rating: 3 - Foundation(把”VLM 空间推理”重新 framing 为数据问题,催生了一整条 internet-scale 3D 监督合成的后续工作线)
Key Takeaways:
- “Data, not architecture”: VLM 在空间推理上的失败可以靠注入合成 3D 空间数据修复,不需要改架构、不需要专门的 3D encoder
- 2D → 3D 自动 lift pipeline: 用 detection + caption + segmentation + monocular metric depth + 坐标系 canonicalize,把任意单张 2D 图变成可被几何规则查询的 metric point cloud,是 internet-scale 3D 监督的关键
- Quantitative answer 是 unlock 应用的关键: 有 metric 估计能力后,VLM 直接变成 robotics 的 dense reward annotator,并能跟 LLM 协作做 chain-of-thought 空间推理(“3 物体是否构成等边三角形”)
- 对噪声鲁棒: 合成 quantitative 答案噪声很大(因为 monocular depth 有偏),但 ablation(Gaussian noise std 0/0.1/0.2/0.3)表明 VLM 仍能学到 generalizable 的空间常识
- ViT 解冻有效: contrastive 预训练的 ViT 是 lossy 的——做 fine-grained distance estimation 必须解冻 ViT([90, 110]% 区间从 5.6% → 8.4%)
Teaser. SpatialVLM 与 GPT-4V 在空间问答上的对比示意。 模型能从 2D 图直接给出 metric 距离估计,而 GPT-4V 经常拒绝回答或 hallucinate。

Motivation
人类的空间推理是 effortless 的——估距离、判前后、看大小都是直接感知,不需要显式 chain-of-thought。但 SOTA VLM(包括 GPT-4V)在这类任务上系统性失败。作者的核心 hypothesis:
这不是架构限制,而是训练数据的限制。互联网 image-caption pair 里几乎没有 metric 3D 信息(caption 不会说 “杯子离碗 23 cm”)。
这把问题从 “如何设计更好的 3D-aware 架构” 转成了 “如何在 internet scale 上拿到 3D 监督”——后者更 scalable。
这是个典型的 first-principles move——把架构归因转成数据归因,再用 expert vision models 把缺失的监督信号补上。如果 hypothesis 正确,这条路天然 scale。
Method
数据合成 pipeline
Figure 2. 数据合成 pipeline 5 步法:CLIP filter → 物体级标注 → 2D→3D lift → 歧义消解 → 模板化 QA 生成。
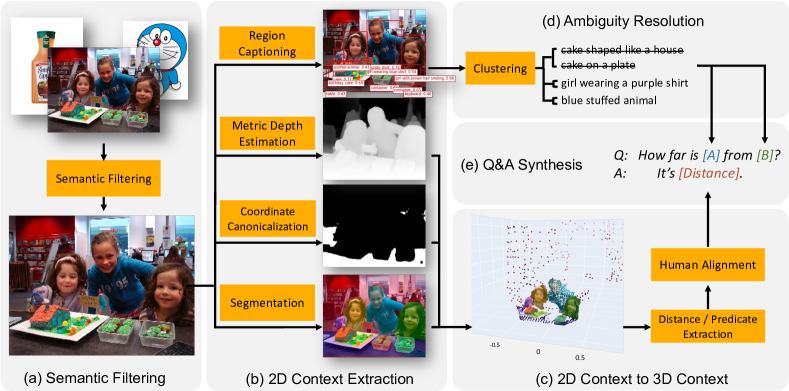
Step (a) Semantic Filtering. 用 CLIP 分类器筛掉单物体 / 无场景的图(比如电商商品图、屏幕截图),只留 scene-level 照片。
Step (b) Object-centric Context Extraction. 跑 region proposal + region captioning (FlexCap) + semantic segmentation,对每个物体得到 pixel cluster + 自然语言描述。
Step (c) Lifting 2D → 3D. 这是整个 pipeline 的关键:
- 用 ZoeDepth 做 monocular metric depth estimation(注意:是 metric scale,不是 relative depth)
- Lift 像素到 3D point cloud
- 通过水平面(floor / table top)segmentation + 坐标变换,把 camera frame canonicalize 到 geodetic frame(z 轴对齐重力)
❓ Canonicalize 到 geodetic frame 是关键设计——没有这一步,“上方/下方/前后” 在 camera tilt 下会乱掉。但这一步对 outdoor / 倾斜场景的可靠性如何?论文没细说。
Step (d) Ambiguity Resolution. 同类物体多个时(“两个 cake”),caption 会指代不清。两个设计:
- 用 FlexCap 而非固定类别 detector,sample 1-6 词的可变长 caption(“cake shaped like a house”),细粒度区分
- 后处理算法 augment / reject ambiguous caption
Step (e) QA 生成. 基于 object caption 和 3D bbox/point cloud,用 38 类问题(每类 ~20 个 question 模板 + ~10 个 answer 模板)合成 QA。两类问题:
- Qualitative: “Which is more to the left?” / “Is A bigger than B in width?”
- Quantitative: “How far is A from B?” / “How much to the left is A compared to B?”(带数字+单位)
最终:10M 图像,2B QA pairs,qualitative/quantitative 各占 50%。
Figure 3. 合成数据样例。 一张图配多个模板生成的 QA pair,覆盖距离/方位/elevation/尺寸等 spatial concept(蓝色高亮)。

Learning
Direct Spatial Reasoning. 沿用 PaLM-E 的架构和训练流程,把 backbone 换成 PaLM 2-S(更小)。在 PaLM-E 原训练 mix 上加 spatial VQA,spatial 占 5% token。
Chain-of-Thought Spatial Reasoning. 合成数据只覆盖 “direct” 的简单空间问题。复杂问题(如”三个物体是否构成等边三角形”)通过让 GPT-4 / text-davinci-003 调用 SpatialVLM 做多步分解:LLM 不能看图但能看问题,SpatialVLM 不能看问题但能看图,两者通过自然语言交互(类似 Socratic Models)。
Figure 4. CoT Spatial Reasoning 示例。 LLM 把 “三个物体是否构成等边三角形” 分解为多次距离查询,再聚合判断。

Experiments
Spatial VQA benchmark
作者自建 benchmark:人工标注 WebLI 子集上 331 个 qualitative + 215 个 quantitative VQA。
Table 1. Qualitative spatial VQA accuracy(binary predicate)。SpatialVLM 75.2% 显著领先所有 baseline,包括 GPT-4V 和 LLaVA-1.5。
| Method | GPT-4V | LLaVA-1.5 | InstructBLIP | PaLI | PaLM-E | PaLM 2-E | Ours |
|---|---|---|---|---|---|---|---|
| Accuracy | 68.0% | 71.3% | 60.4% | 60.7% | 50.2% | 50.4% | 75.2% |
有意思的细节:LLaVA-1.5 是 baseline 第二名,作者推测因为它训练用了 bbox + caption 做 visual instruction tuning——也间接支持 “数据决定空间能力” 的假设。但 LLaVA 强在 2D 关系,弱在 3D。
Table 2. Quantitative spatial VQA。SpatialVLM 几乎总能给数字答案 (99.0%),且 37.2% 在 ground truth 的 [0.5×, 2×] 范围。
| GPT-4V | LLaVA-1.5 | InstructBLIP | PaLI | PaLM-E | PaLM 2-E | Ours | |
|---|---|---|---|---|---|---|---|
| Output numbers % | 1.0% | 20.9% | 26.0% | 52.0% | 83.2% | 88.8% | 99.0% |
| In range [50, 200]% | 0.0% | 13.0% | 7.9% | 5.3% | 23.7% | 33.9% | 37.2% |
GPT-4V 几乎总是拒答距离问题(“I’m sorry, but I cannot provide an exact distance…“)——典型的 RLHF safety bias。
Cotraining 不损通用 VQA
Table 3. 加入 spatial 数据没有 hurt 通用 VQA,反而 VQA-v2 +2.4%。
| General VQA | OKVQA | VQA v2 |
|---|---|---|
| PaLM 2-E w/o cotraining | 61.4% | 76.6% |
| Ours | 61.0 (-0.4) % | 79.0 (+2.4) % |
作者诠释:VLM 在 spatial-reasoning-邻近的任务分布上是 underfit 的,所以加 spatial 数据”白拿”。
Frozen vs Unfrozen ViT
Table 4. ViT 解冻对 fine-grained distance estimation 帮助显著。
| [50, 200]% | [66.7, 150]% | [90, 110]% | |
|---|---|---|---|
| Frozen ViT | 34.9% | 9.3% | 5.6% |
| Unfrozen ViT | 37.2 (+2.3) % | 10.7 (+1.4) % | 8.4 (+2.8) % |
粗粒度差不多,越细粒度([90, 110]% 严格区间)gap 越大。Hypothesis:contrastive 预训练的 ViT 在 fine-grained spatial info 上是 lossy 的。
Noise robustness
Table 5. 在 quantitative answer 上加 Gaussian 噪声,VLM 性能基本不变。
| Gaussian std | 0 | 0.1 | 0.2 | 0.3 |
|---|---|---|---|---|
| MSE (m) | 0.046 | 0.053 | 0.039 | 0.048 |
| [50, 200]% | 59.0% | 55.8% | 61.1% | 61.1% |
这个结果有点反直觉但 robust——VLM 学到的是 distribution-level 的 spatial commonsense,对单点噪声不敏感。同时也意味着:花更多力气提升 pipeline 精度,边际收益不大。
机器人应用
Figure 5. Gripper 接近 coke can 时,SpatialVLM 给出单调递减的距离估计。 验证了它能作为机器人任务的 dense reward。

Figure 6. SpatialVLM 作 dense reward annotator。 对 “pick orange tea bottle” 任务,用 “What is the distance between gripper and bottle” 的回答作为 cost function,散点图显示 reward 在物理空间里的分布合理。

关联工作
基于
- PaLM-E:直接复用其架构和训练流程,仅替换 backbone 为 PaLM 2-S。整个 SpatialVLM 在 system view 上就是 “PaLM-E + spatial data mix”
- ZoeDepth:metric monocular depth estimator,是 lift pipeline 的核心组件
- FlexCap:variable-length object captioning,是 ambiguity resolution 的关键
- CLIP:scene-level image filtering 和 caption similarity 聚类
对比
- GPT-4V / PaLI / InstructBLIP / LLaVA-1.5:所有空间 VQA benchmark 上的 baseline,都在通用 image-caption mix 上训练,未注入 spatial 监督
- PaLM 2-E(vanilla):架构相同、训练流程相同、只是没有 spatial 数据——是验证 “data is enough” 的关键 control
方法相关
- Socratic Models / LLM as coordinator:CoT spatial reasoning 部分用 LLM 协调 VLM 的范式来源
- Scene graph 类 spatial reasoning(VG, GQA 等):传统做法是显式构造 scene graph 再 pathfinding,SpatialVLM 把这种 spatial structure 隐式编码进 VLM 权重
- VLM as reward / success detector:SpatialVLM 是这条线里第一个能给 metric dense reward 的
论文点评
Strengths
- 问题归因清晰且可验证:把 “VLM 不会空间推理” 归因到数据缺失,并用 cotrain ablation(PaLM 2-E vanilla vs +spatial data)直接验证。这是教科书级的 hypothesis-experiment loop。
- Pipeline 简洁可 scale:5 步全部用 off-the-shelf expert,没有任何需要训练的中间组件。10M 图像 → 2B QA 能跑出来本身就是工程上的 statement。
- 关键设计 well-justified:FlexCap 替代固定类别 detector(解决歧义)、坐标 canonicalize(解决 camera tilt)、spatial token 5% 比例(不损通用能力)——每个都有具体动机。
- Robotics 应用 unlock 得自然:metric distance 估计 → dense reward,比 binary success detector 信息量大得多。这是 spatial reasoning 的”杀手级”下游。
- Noise robustness 实验诚实:明确说自己 quantitative 答案噪声大(因为 monocular depth 有偏),并且证明这不影响最终性能——避免了 overclaim pipeline 精度。
Weaknesses
- Benchmark 是自建的:546 个人工标注的 WebLI 问题,规模偏小且标注本身有噪声(作者承认 annotator 间 agreement 不保证)。GPT-4V 的对比也是 Nov 2023 版本的 snapshot,公平性存疑。
- 没开源:无代码、无模型、无数据。第三方 VQASynth 是 community 复现,作者未参与。对学术社区的实际可复现性几乎为零。
- 依赖 monocular metric depth 的硬伤:ZoeDepth 在 1-10m 范围内 reliable,超出就退化(Fig 11 印证)。整个系统的物理 scale 上限被这个组件锁死,且室外/远距场景泛化未验证。
- CoT 部分弱:用 text-davinci-003 协调 SpatialVLM 是 prompt engineering,没有训练一个 native 多步推理模型。这只是 demo 不是方法贡献。
- PaLM 2-E 是 in-house 模型:所有 baseline 比较都基于 Google 内部模型栈,无法在 open-source VLM (LLaVA / Qwen-VL 等) 上验证 “data is enough” 的 claim 是否普适。
- Geodetic canonicalize 假设场景里有水平面:对手持相机随手拍、戏剧化角度、室外开阔场景,floor / table top segmentation 可能失败。论文没分析 failure mode。
可信评估
Artifact 可获取性
- 代码: 未开源(官方);第三方 VQASynth 提供数据合成 pipeline 复现
- 模型权重: 未发布
- 训练细节: 仅高层描述(PaLM 2-S backbone,5% spatial token,110k+70k steps;mix 比例提到了 PaLM-E original mix 但具体配比未给)
- 数据集: 未发布(2B QA pairs 都没放出来)
Claim 可验证性
- ✅ “Cotraining 不 hurt 通用 VQA”:Table 3 的 PaLM 2-E 自身对照实验严格
- ✅ “Quantitative 输出格式有效率 99%“:明确的 metric,可重测
- ✅ “作 dense reward annotator 单调递减”:Figure 5/6 有具体 trajectory 验证
- ⚠️ “75.2% > GPT-4V 68.0%“:benchmark 自建、GPT-4V 是 2023.11 snapshot、人工评估有主观性,gap 可能高估
- ⚠️ “Noise std 0.3 也不影响”:Table 5 数字波动小,但只在 manipulation domain 测了,泛化到 internet 图像未验证
- ⚠️ “VLM 限制是数据不是架构”:在 PaLM 2-E 这一种架构上验证。也许更小或不同结构的 VLM 仍受架构限制
- 无明显营销话术 (无 ❌)
Notes
- 这篇论文的真正贡献是”问题 framing + scale”:方法上没有任何花哨的组件(pipeline 全是 off-the-shelf),但把 “把 internet 图像 lift 成 3D 监督” 当成 first-class 问题来 scale,最终推导出 robotics 应用。这是 important > publishable 的好例子。
- 后续工作的 implication:如果 “data is enough” 普适,那应该在所有 open VLM (Qwen-VL, InternVL, Gemma 等) 上注入这种数据,看是否同样 unlock 空间能力。VQASynth 让这件事变得可行——值得看 2604-OpenSpatial / 2603-HoliSpatial / 2604-SpatialEvo 是否做了
- Bottleneck 在 monocular depth:1-10m reliable,超出失效。要么换 stereo / multi-view,要么等 better foundation depth model(如 Depth Anything v2 之后)
- Robotics 用法启发:dense reward 的 “natural language queriable distance” 接口很优雅。但 inference cost 是问题——每个 reward step 都跑一次 VLM forward,对 RL training loop 太慢。也许只适合 reward labeling 而非 online 用
- CoT 部分潜力大:现在是 prompt-based,是否可以把 multi-step spatial reasoning 也 distill 成训练数据?这跟 “把 LLM agent 推理蒸馏回 base model” 是同一类问题
❓ 论文说”5% spatial token”,但 cotraining 时具体是按 step 比例还是按 token 比例 mix?以及,spatial 数据是 random sample 还是 curriculum?没说。
Rating
Metrics (as of 2026-04-24): citation=723, influential=58 (8.0%), velocity=26.78/mo; HF upvotes=29; github 559⭐ / forks=26 / 90d commits=0 / pushed 108d ago
分数:3 - Foundation 理由:本文把”VLM 空间推理”从架构归因重 frame 为数据归因,并用 off-the-shelf expert 搭出 internet-scale 3D 监督合成 pipeline——这个 framing 直接开启了 VQASynth、SpatialRGPT、SpatialBot 等一整条后续工作线(第三方 VQASynth 已成为社区复现的 de facto 工具)。相比 Frontier 档,它不只是”当前 SOTA 或重要 baseline”,而是一个方向的 agenda-setter,后续 spatial-reasoning VLM 基本都把它作为必引起点;Weakness 里未开源、benchmark 自建等问题不改变它的方向性地位。