Summary
SpatialEvo: Self-Evolving Spatial Intelligence via Deterministic Geometric Environments
- 核心: 把 3D 室内场景(dense point cloud + camera pose)当作一个 deterministic geometric oracle,用程序化几何运算替代 self-evolving 常见的 majority-vote pseudo-label,让 VLM 在 questioner / solver 双角色下通过 GRPO 自进化,拿到 zero-noise 的 reward。
- 方法: Deterministic Geometric Environment (DGE) 把 16 类 spatial reasoning task 编码成原子几何验证规则;单个 policy 参数共享地交替扮演 questioner(看多视角图生成 physically valid 的空间问题)和 solver(基于图像与问题作答、对齐 DGE 计算的 GT);task-adaptive scheduler 按历史准确率上调弱任务采样权重,形成 endogenous curriculum。
- 结果: 以 Qwen2.5-VL-3B/7B 为 backbone,在 9 个 benchmark 平均分取得 51.1 / 54.7,超过 SpatialLadder、SpaceR、ViLaSR、Spatial-SSRL;VSI-Bench 7B 达 46.1;MMStar/RealWorldQA 几乎不掉,证明空间专精不损伤通用能力。关键 ablation:用 majority-vote 替换 DGE ground truth 会让 VSI-Bench 从 46.1 崩到 18.8。
- Sources: paper | github
- Rating: 2 - Frontier(spatial reasoning 领域当前最前沿的 self-evolving RL 方案,DGE 这一 primitive 有方法论价值,但 scope 被静态室内 3D asset 和手工选定的 16 类 task 卡死,未到 foundation 量级)
Key Takeaways:
- Spatial reasoning 天然逃过 self-evolving 的 pseudo-label 陷阱:答案是几何的确定性函数,从 point cloud + camera pose 可程序化精确算出,不需要 model consensus 当 noisy proxy。
- DGE 是这篇的真 contribution:16 类任务的 atomic geometric validation + automatic GT synthesis pipeline(entity parsing → legality check → geometric toolkit 计算)把 ScanNet/ScanNet++/ARKitScenes 这类”静态”场景数据集变成 online interactive oracle。
- Ablation 把话说死:
w/o Physical Grounding是最大一刀(Avg ↓5.1,VSI-Bench 18.8),直接证明 deterministic feedback 是核心;其他 module(scheduler、observation reward)贡献都是 0.2–0.8 的小刀。 - Self-play 架构性的价值有限:w/o Questioner / w/o Solver 分别掉 1.6 / 3.2,远小于 physical grounding 那 5.1。真正的 heavy lifting 不是 self-play,而是”有个不会骗人的 oracle”。
- 局限非常明确:依赖 ScanNet 家族这类高保真静态室内 3D asset;outdoor / dynamic / sparse point cloud 场景直接失效——方法的 scalability 被 3D 重建数据的 availability 卡死。
Teaser. 三种训练范式的对比——Static Data Tuning(固定人工标注)、Consensus Self-Evolve(model voting 的 biased GT)、SpatialEvo(DGE 从 3D asset 精确计算 GT)。图里的 framing 很清晰,把”consensus 作为 proxy”挑出来当成主要攻击目标。
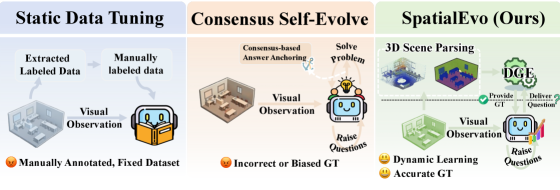
1. Motivation: 为什么 spatial reasoning 特别适合 self-evolving
Self-evolving 范式的常见玩法是:模型自己 propose 问题和答案,然后用 majority voting / self-consistency 聚合成 pseudo-label 反哺训练。这条路径在自然语言 / 通用视觉里 work,但有个结构性弱点——pseudo-label 继承了模型当前的 prediction bias,训练等于在强化自己的错误。
作者抓住了 3D spatial reasoning 的一个特殊属性:
Given a dense point cloud, calibrated camera poses, and a well-formed geometric question, the correct answer can be computed exactly and programmatically, with no appeal to any model’s judgment.
换言之,只要场景的 underlying geometry 在手,“哪个物体更近”、“相机旋转角度是多少”、“深度排序”这些都是纯几何 operator 的结果。这样 majority vote 就被甩掉了,model 不再是自己的 judge,而是由”物理世界”来判。这是整篇文章的 thesis。
❓ 但这个 “physics as judge” 的声明有个隐藏 scope:它只在有高质量 3D asset 的静态室内场景下成立。对 outdoor、动态物体、移动 camera,点云 sparse 或漂移,oracle 本身就变 noisy。作者在 Appendix A 其实承认了这一点(见 Limitations),但正文并未把这个 scope 限制讲得足够醒目——对不看 appendix 的读者容易被 “physics as impartial judge” 这种话术过度 generalize。
2. Method: SpatialEvo 框架
Figure 2. SpatialEvo 框架图——DGE 从 point cloud + camera pose 计算 zero-noise GT,Spatial-Grounded GRPO 驱动单一 VLM 在 Questioner / Solver 两个 role 之间交替优化。
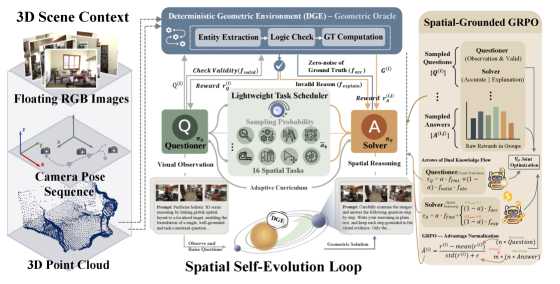
框架拆成两块:Deterministic Geometric Environment (DGE) + Spatial-Grounded Policy Co-Evolution。
2.1 Deterministic Geometric Environment (DGE)
DGE 是 self-evolution loop 里的 “Geometric Oracle”,把自然语言问题映射到 underlying 3D asset 上做客观 verification。它含两个子模块:
Task-specific Geometric Validation Rule Sets——为 16 类 spatial reasoning task 每类都预定义一组几何验证规则。每个 rule set 从三个维度约束 question validity:
- Premise consistency:问题中提到的 entity(frame index、object category、spatial region)必须在 asset 中存在且能唯一定位。
- Inferential solvability:问题的几何前提必须 unambiguously computable(例:metric task 要求参考物体 point cloud 密度达到最低阈值;orientation task 要求两帧间有足够 viewpoint disparity)。
- Geometric degeneracy filtering:过滤掉 physically unstable、highly ambiguous、low-training-value 的 edge case。
Automated Verification Pipeline 分三步:
- Stage 1 — Entity Parsing:用轻量 LLM 从 questioner 生成的自由文本里抽结构化 entity(frame idx / object category / spatial relation)。
- Stage 2 — Legality Verification:用对应 task 的 rule set 验。失败 → truncation + 给 questioner 负 reward。
- Stage 3 — Ground-Truth Synthesis:几何 toolkit 在全局坐标系做精确数值运算——刚体坐标变换、point-cloud bbox fitting 与拓扑分析、depth-map perspective projection、planar normal estimation。
16 task categories 按观察粒度分三组:
- Multi-image scene-level (6): object counting / size / absolute distance / relative distance / relative direction / room size。
- Single-image (3): single-view relative direction / camera-to-object distance / depth order object-object。
- Dual-image (7): camera-camera position / cam-obj position / cam-region position / camera motion / visibility comparison / cam-cam elevation / attribute measurement。
❓ 这 16 类全是”可被几何运算完整定义”的子集——其实就是用 task 选择把 method 的优势最大化了。真正挑战 spatial reasoning 的任务(affordance、功能性推理、commonsense spatial understanding)不在其中。这是 methodology-driven 的 benchmark design,不是 capability-driven 的。
2.2 Spatial-Grounded Policy Co-Evolution
单一 policy 参数共享,通过 role-conditioned prompting 在 questioner / solver 之间切换。作者声称两角色互相强化:“solver 的 gradient 改善 questioner 的视觉感知;questioner 的 boundary exploration 深化 solver 的推理”。
Task-Adaptive Scheduler:对每个 task category 维护累计分 和样本数 ,用 pseudo-observation smoothing 估计 historical effective accuracy 。采样权重 与 负相关,引入最小 exploration weight 防止成熟 task 被完全驱逐。效果:自动把训练资源集中到 solver 当前弱项,形成 endogenous curriculum。
Questioner Reward:
- :来自 DGE 的几何 validity 分。
- :轻量 LLM judge 打分,评估 questioner 的文本 observation 是否有 global→local 的自然感知层次。
- 乘积 是 hard gating:两者同时满足才给正信号,防”格式合规但没空间理解”的伪有效问题。
Solver Reward:分 valid / invalid 两路。
- Valid question: 直接对齐 DGE 算出的 GT。
- Invalid question:DGE 返回 invalidation reason,solver 要显式分析原因,由 LLM judge 打分——把”坏问题”也转成学习信号。
GRPO Training:每个场景,scheduler 采 task type,questioner 生 个候选问题,形成一个 GRPO group 计算 questioner 的 advantage;去重后得 个 unique question 交给 solver;每个 unique question 采 个候选答案,形成 solver 的 个独立 GRPO group;advantage 组内标准化:
两端 gradient 在 single parameter set 上联合更新。
3. Experiments
Setup: DGE 从 ScanNet、ScanNet++、ARKitScenes 训练 split 构建,约 4K 源场景。Backbone: Qwen2.5-VL-3B/7B-Instruct。纯 online RL(GRPO),无 SFT 阶段。
Baselines:SpatialLadder / SpaceR-SFT / ViLaSR(静态标注或固定 reward 的 RL)、Spatial-SSRL(从 RGB 直接派生信号的 self-supervised RL)。
Benchmarks (9):VSI-Bench (主), EmbSpatial, ViewSpatial, RealWorldQA, V-STAR, SpatialViz, STARE, CoreCognition, MMStar。
3.1 Main Results (Table 1)
| Benchmark | 3B Base | 3B SpatialEvo | 7B Base | 7B SpatialEvo |
|---|---|---|---|---|
| VSI-Bench | 28.1 | 39.2 | 31.1 | 46.1 |
| RealWorldQA | 63.4 | 66.5 | 69.5 | 66.7 |
| EmbSpatial | 55.9 | 61.2 | 63.6 | 66.0 |
| SpatialViz | 24.2 | 25.4 | 27.0 | 28.6 |
| STARE | 33.1 | 36.9 | 41.8 | 41.3 |
| CoreCognition | 56.8 | 57.4 | 59.6 | 60.2 |
| ViewSpatial | 36.2 | 42.3 | 36.4 | 43.2 |
| V-STAR | 74.9 | 75.4 | 78.5 | 78.0 |
| MMStar | 54.6 | 55.2 | 61.6 | 62.5 |
| AVG | 47.5 | 51.1 | 52.1 | 54.7 |
- 两个 scale 的 AVG 都是最优。核心空间 task(VSI-Bench、EmbSpatial、ViewSpatial)提升显著。
- 通用能力(MMStar、RealWorldQA)几乎不退化;对比 SpatialLadder 在 MMStar 从 54.6 掉到 45.8,在 V-STAR 从 74.9 崩到 36.7——说明很多同类方法是”以牺牲通用能力为代价换空间指标”。
- 一个 caveat:3B 设置下 VSI-Bench 被 SpatialLadder (45.7) 反超(SpatialEvo 39.2)。作者后面在 5.1 说因为 task coverage 不同,controlled 比较下 SpatialEvo 反而更强——但正文 Table 1 里被反超这一点没醒目标出,读者容易忽略。
3.2 Ablations (Table 2, 7B)
| Variant | AVG | ΔAvg |
|---|---|---|
| SpatialEvo (Full) | 54.7 | – |
| w/o Questioner | 53.1 | ↓1.6 |
| w/o Solver | 51.5 | ↓3.2 |
| w/o Physical Grounding | 49.6 | ↓5.1 |
| w/o Adaptive Scheduler | 54.4 | ↓0.3 |
| w/o Validity Reward | 53.9 | ↓0.8 |
| w/o Observation Reward | 54.5 | ↓0.2 |
| w/o Explanation Reward | 54.3 | ↓0.4 |
关键发现:
- w/o Physical Grounding(用 majority vote 替代 DGE GT)= 最大一刀,VSI-Bench 从 46.1 崩到 18.8。这是整篇文章的 core claim 的 smoking gun。
- Self-play 架构本身 (w/o Questioner / w/o Solver) 贡献 1.6–3.2,比 physical grounding 小 2–3×。真正的 heavy lifting 是 DGE oracle,不是 self-play。
- Adaptive scheduler 只给 0.3 的 avg 提升——Table 1 主结果 scheduler 的贡献并不像作者叙事里那么关键;但在 Table 4 的 iterative self-evolution 下能看到 scheduler 防止 stagnation 的效果(见下节)。
3.3 Online vs Static (Table 3, 3B, VSI-Bench)
在 narrower task scope(6 core task)下对齐 SpatialLadder (26K) / SpaceR (151K) / Spatial-SSRL (81K):
- SpatialEvo Online RL: AVG 46.3(优于 SpatialLadder RL 的 40.1)
- SpatialEvo Offline Data + SFT: 43.9(优于 SpatialLadder SFT 43.7、SpaceR 36.3、SSRL 28.1)
- online > offline SFT 同数据:43.9 vs 46.3,差 2.4 个点——作者归因于 online 能”实时对齐 solver 的 cognitive frontier”做 adaptive hard-sample mining,静态数据做不到。
3.4 Curriculum Emergence (Figure 3, Table 4)
Figure 3. Training dynamics——(左) Questioner Validity Reward 快速升到接近 1.0;(中) Solver Accuracy 稳步上升、Invalid Ratio 同步下降;(右) Adaptive Scheduler 让难任务(Rel. Dir. 21.8%、Rel. Dist. 18.7%)采样权重超过 uniform 的 16.7%,简单任务(Room Area 12.5%、Obj. Size 13.4%)被下调。
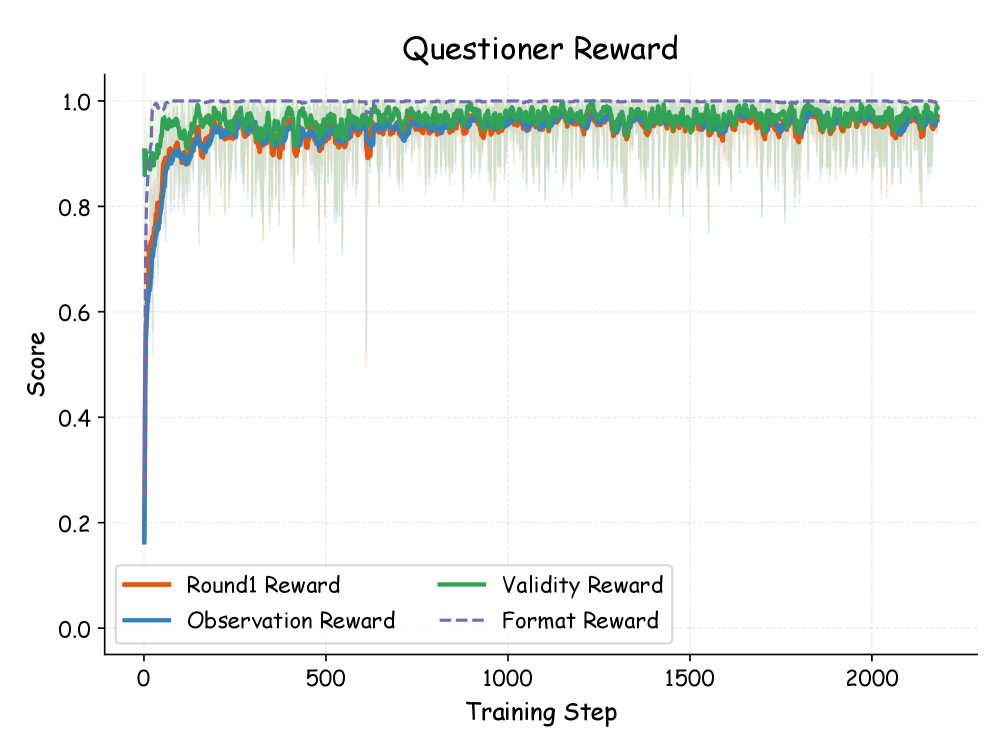
Table 4 的发现值得关注:
- w/o scheduler 的 4 iter 轨迹:44.2 → 44.5 → 43.7 → 43.4(stagnation + decline)。
- w/ scheduler:44.2 → 45.0 → 45.1 → 46.1(monotonic improvement)。
- 也就是说 scheduler 在长程迭代中的价值远大于单轮(单轮只 0.3,但多轮累积 ~2.7)。这才是 scheduler 真正的作用。
4. Limitations (Appendix A)
作者自述三点局限——都是关键的、对论文 scope 有实质影响的:
- Dependency on high-fidelity 3D assets:需要 ScanNet 级别的高质量 indoor point cloud + calibrated camera pose + 完整场景覆盖。outdoor / dynamic scene 直接不适用——点云 sparse、scale 变化复杂、物体移动都会破坏 geometric consistency。
- Sensitivity to entity parsing quality:DGE Stage 1 依赖 LLM 做自由文本 → 结构化 entity。问题含 ambiguous reference 或 underspecified target 时,parsing 错误会传递到后续验证和计算。Deterministic geometry 没法 compensate for parsing failure。
- Sensitivity to point cloud quality:重建 artifact、点云 sparsity、occlusion 会降低 bbox fitting、depth estimation 这类 operator 的精度,对 continuous-valued task(absolute distance、object size)影响最大。虽然 reward 端引入了相对误差 tolerance band,但上限被数据质量卡死。
关联工作
基于
- SpatialVLM:把 2D → metric 3D point cloud 做 spatial VQA 数据合成的奠基工作;SpatialEvo 把其”离线批量生成”升级为”online 动态生成 + 几何 verification”。
- GRPO (DeepSeek-Math):RL 训练骨架,group-relative advantage 标准化。
对比
- SpatialLadder:静态 RL(固定标注+GRPO),同类最强 baseline;SpatialEvo 声称 distribution 能随 solver 能力动态迁移。
- SpaceR-SFT / ViLaSR:静态 RL 或 SFT,牺牲通用能力换空间指标。
- Spatial-SSRL:self-supervised RL,直接从 RGB 派生信号,无需几何 GT;SpatialEvo 用 DGE geometric GT 在平均分上胜出。
- VisPlay / EvolMM / V-Zero / Vision-Zero / MM-Zero:multimodal self-play / self-evolving;仍依赖 model consensus,SpatialEvo 把 consensus 换成 deterministic geometric oracle。
方法相关
- OpenSpatial:同期 spatial intelligence data engine,路线是 principled offline data 生成,不走 online self-evolution——可以作为”离线 DGE-like pipeline”的对照。
- ScanNet / ScanNet++ / ARKitScenes:3D 场景数据源;DGE 的 GT 合成完全建立在这些 dense reconstruction 上。
- VSI-Bench:主要评测基准,32-frame 多视角 spatial reasoning。
论文点评
Strengths
- 问题 framing 抓得极准:self-evolving 的 pseudo-label bias 在 spatial reasoning 这个 domain 正好有解(几何 GT 可算),这一点不是堆方法,是 observation-driven 的 insight。
w/o Physical Grounding那一刀(VSI-Bench 46.1 → 18.8)把 thesis 证得干干净净。 - 工程上做得硬:16 类 task 的 atomic validation rule + 全自动 pipeline + 从三个主流 3D dataset 构建 4K 场景 online oracle——不是 proof-of-concept,是能 run 起来的 system。代码 + 3B/7B 两个 checkpoint + SpatialEvo-160K offline dataset 全开源。
- 通用能力保持得体面:MMStar / RealWorldQA 几乎不掉,和 SpatialLadder 崩 MMStar (54.6→45.8)、ViLaSR 崩 V-STAR (78.5→35.6) 形成鲜明对比。说明 DGE 的 reward signal 足够”干净”,不会把 VLM 带偏到 narrow distribution。
- Table 4 的 iterative curriculum 证据有说服力:单轮 scheduler 只给 0.3,但 4 iter 累计 2.7,且 w/o scheduler 会 stagnate。这个 long-horizon evidence 比单轮 ablation 更能证明 adaptive curriculum 的价值。
Weaknesses
- “Self-evolving” 是营销标签,更准确的叫法是 “programmatically-verified online RL”:真正的自进化应该是 model 自己定义 reasoning objective,这里 16 类 task + geometric rule 全是人工定义的。questioner 的自由度只在具体 entity 和 phrasing 上,不在 task space 上。和 AlphaZero 那种意义上的 self-play 不是一个量级。
- Scope 被 3D asset availability 死死卡住:依赖 ScanNet 族静态室内场景。这个方法 fundamentally 不 generalize 到 outdoor / dynamic / embodied execution 场景——而 spatial reasoning 真正想落地的地方(robot manipulation、navigation、driving)恰恰大多是这类场景。作者 Appendix 承认了,但正文没强调。
- 对 SpatialVLM / SpatialRGPT / SpatialBot 的 delta 讲得不清楚:这些都是通过”生成大规模 spatial VQA 标注”提升能力。SpatialEvo 的 differentiator 理应是”在线动态分布 + 无需离线标注”,但 Section 5.1 的 controlled 对比只比了 SpatialLadder / SpaceR / SSRL,并没直接 ablate “如果用 DGE pipeline 离线生成 20K 数据做 SFT vs online RL”的 apple-to-apple——Table 3 里 SpatialEvo offline SFT 43.9 vs online RL 46.3 已经在做这件事,但只有 2.4 分差距,并不足以论证”online self-evolving 一定胜过离线批量生成+SFT”。如果 DGE 的 offline data generation 本身就足以 match,那 online RL 这一层的 necessity 就很弱。
- 16 类 task 是精心选择的 hand-designed subset:全是能被几何 operator 完整定义的(metric / topological / camera pose)。真正 hard 的 spatial reasoning(affordance、functional relation、commonsense 3D)被排除。在这个 subset 上 work 不等于在 spatial reasoning 全集上 work——benchmark 涵盖度是 method-shaped,不是 capability-shaped。
- Parsing 噪声的 residual risk 没量化:Stage 1 依赖轻量 LLM 抽 entity,失败时整个”deterministic”链条就破了。作者在 limitation 里提了一句,但没给出 parsing 成功率、parsing 错误对下游 reward 的 contamination rate 等指标。Deterministic 的 framing 实际上 conditional on parsing correctness。
- Invalid-question 的 explanation reward 由 LLM judge 打分:这部分又引回了”model as judge”的 noise,和开篇 thesis 的”彻底摆脱 model consensus”矛盾。实验上 w/o Explanation Reward 只掉 0.4,说明这条路径贡献边际,可以进一步简化。
- VSI-Bench 3B 被 SpatialLadder 反超没讲清:Table 1 里 3B 设置 SpatialEvo 39.2 vs SpatialLadder 45.7,这个缺口挺大。作者在 5.1 说是 task coverage 问题,但task coverage 恰恰是 DGE 可以扩展的事——如果对齐到同样 task 才能打平,那”DGE 的覆盖广度”就成了作者自己埋的坑,而不是 method 优势。
可信评估
Artifact 可获取性
- 代码: inference+training(GRPO 训练栈、DGE simulator、dataset pipeline 全开)。
- 模型权重: SpatialEvo-3B 和 SpatialEvo-7B(基于 Qwen2.5-VL-Instruct),均 HuggingFace 发布。
- 训练细节: 仅高层描述(Qwen2.5-VL backbone、纯 GRPO online RL、4K 场景来自 ScanNet/ScanNet++/ARKitScenes);完整超参与数据配比放在 Appendix C(未通读,标”仅超参”存疑,以 README 口径为准)。
- 数据集: 开源。SpatialEvo-160K(由 DGE 离线生成的 QA)HuggingFace 上可拿;源 3D dataset 均为公开学术数据集。
Claim 可验证性
- ✅ DGE 消融后 VSI-Bench 从 46.1 崩到 18.8:Table 2 直接数值,grounding 在 paper 实验。
- ✅ MMStar/RealWorldQA 保持:Table 1 有数。
- ✅ Scheduler 在 4-iter 下防止 stagnation:Table 4 给出对照轨迹。
- ⚠️ “first framework to introduce self-evolving paradigm into 3D spatial reasoning”:相对 claim;VisPlay / EvolMM / V-Zero / MM-Zero 都在做 multimodal self-play,差异在”deterministic geometric GT”这一点。“first” 这个词 depending on 怎么定义 “3D spatial reasoning” 与 “self-evolving”,有一定 marketing 成分但不算虚假。
- ⚠️ Online self-evolution > static data training:Table 3 里 online RL 46.3 vs offline SFT(用 SpatialEvo 生成数据)43.9,差 2.4 点。“显著优于”这个定语略重——更准确的说法是”略优、且受益于动态 curriculum”。
- ⚠️ “zero-noise supervisory signal”:conditional on parsing success + point cloud fidelity;实际噪声量级作者自己在 limitation 里承认非零。说”low-noise”更准确。
- ❌ 无明显营销话术,整体 claim 克制。
Notes
- Implication for embodied AI:这篇方法的核心 primitive——“用 deterministic simulator 作为 online verifiable reward source”——其实和 robot manipulation 里的 sim-based RL 同构。区别是本文的 simulator 是”静态场景 + 几何规则”,manipulation 里是”动力学模拟器”。顺着这条路走,VLA 的在线 self-improvement 可以借鉴 DGE 的 thinking:不是让模型互相打分,而是让物理仿真器当 judge。值得跟进。
- 一个可 pivot 的方向:把 DGE 从 ScanNet static asset 延展到 Gaussian Splatting 重建的 dynamic scene,或 Omniverse / Isaac Sim 之类的 simulator。如果能把 oracle 的 scope 从”室内静态”拓到”动态仿真”,这个方法的天花板会高很多。
- 疑问:parsing failure rate 到底多高?作者没给。如果 parsing 失败率 >5%,“zero-noise”的 framing 就需要大打折扣。值得 reverse-engineer 他们的 SpatialEvo-160K 数据看一下 error distribution。
Rating
Metrics (as of 2026-04-24): citation=0, influential=0 (0%), velocity=0.00/mo; HF upvotes=62; github 66⭐ / forks=1 / 90d commits=3 / pushed 8d ago
分数:2 - Frontier
理由:DGE 这个 primitive(把 3D asset 当 deterministic oracle 替换 majority-vote pseudo-label)是 observation-driven 的真 insight,且 w/o Physical Grounding VSI-Bench 46.1→18.8 的 ablation 把 thesis 证得很干净,在 spatial reasoning 这一 field 是当前明确的 SOTA + must-compare baseline。但没到 Foundation 档——scope 被 ScanNet 族静态室内 3D asset 死死卡住(outdoor / dynamic / embodied execution 直接 not applicable,作者自承认),16 类 task 是 methodology-shaped 的手工精选子集而非 capability-shaped 的覆盖,且 online RL 相对 offline SFT (46.3 vs 43.9) 的 delta 只有 2.4 点,不足以论证”self-evolving 范式本身”的奠基性价值。