Summary
π*₀.₆: a VLA That Learns From Experience
- 核心: 通用 VLA 不能只靠 demonstration——得让它像人一样练习;本文给出 Recap 算法与 π*₀.₆ 模型,在真实部署中用 autonomous rollouts + 人类 correction + sparse reward 迭代自改进,espresso / laundry / box assembly 三个长程任务 throughput 翻倍、failure rate 减半。
- 方法: Recap = (1) episode-level sparse reward → (2) 训 distributional value function → (3) 把 advantage 的二值化 indicator “Advantage: positive/negative” 作为 text token 塞进 VLA prefix,训练时跑 advantage-conditioned SFT,推理时固定 positive(可选 CFG 放大)。绕过 flow-matching policy 做 PPO 的 likelihood / trust-region 难题。
- 结果: π*₀.₆ 能在真实家庭连续折 2 小时衣物、在咖啡店连续做 13 小时咖啡、在工厂拼装包装纸箱;除 diverse laundry 外所有任务成功率 ≥90%;VS. PPO / AWR 在同一批数据上显著领先;两轮迭代(autonomous-only)即可让 t-shirt 折叠吞吐翻倍。
- Sources: paper | website
- Rating: 2 - Frontier(flow-matching VLA + real-world RL 的前沿代表工作,advantage conditioning 是关键工程突破;但发表仅数月,尚需时间验证是否升格为 Foundation)
Key Takeaways:
- “RL is back” for VLAs:首次在通用 4B+ flow-matching VLA 上跑通 real-world RL 自改进闭环——此前 VLA RL 工作几乎全部局限在离散动作、小模型、或 toy task。
- Advantage conditioning 是对 flow matching 的”绕开式”解法:把 RL 问题编码为”多一个 text prefix 的 supervised learning”,与 Knowledge Insulation 的 stop-gradient 结构天然兼容,不用硬算 flow-matching 的 log-likelihood。
- Value function 的角色远不止 critic:670M 多任务 language-conditioned distributional VF(predict negative steps-to-success + 201 bins)既做 credit assignment,又能可视化出”什么时候robot犯错、什么时候progress”,这件事本身就是 alignment 工具。
- Coach + practice 的混合数据范式:human intervention 修大错(exploration),autonomous rollouts 打磨细节(speed/fluency),共用同一套 advantage-conditioned 目标——工程层面统一了异构数据源。
- 迭代即可,无需完美初始化:box assembly iteration 0 → iteration 2 throughput 翻倍,“offline RL + SFT” 只是起点而非终点。
Teaser. Recap 训出的 π*₀.₆ 能做三个真实长程任务:espresso、box assembly、diverse laundry

Problem & Motivation
“It’s amazing what you can learn if you’re not afraid to try.” — Robert Heinlein
Imitation learning 的天花板是 demonstration 数据的质量与覆盖——“at best, can only be as performant as the demonstration data”。而真实机器人与 LLM 不同:policy 在真实环境里跑会产生 compounding errors——小偏差把机器人带到训练分布之外,于是犯更大的错。这个问题 DAgger (Ross et al. 2011) 早已形式化,但在大模型 VLA 上给出可规模化的工程解法是空白。
核心挑战有三(来自 Intro §I 和 Related Work §II):
- Scalable RL for large VLAs:4B VLM backbone + 860M flow-matching action expert,policy gradient 类方法(PPO)要求可解析的 log-likelihood 和小步长 trust region,和 flow matching 不兼容。
- 异构数据整合:pre-training demonstrations、autonomous rollouts(好坏混杂)、human correction(不完美但针对痛点)——一套 loss 要吃得下。
- Sparse & noisy reward:实验中只给 episode-level success/failure 一个二值标签,中间过程没有 dense reward。
❓ 本文 framing 有一个隐含假设:失败模式可以通过 practice 消除。但真实世界里有些 failure 是来自 hardware / perception 的系统性 bug(比如抓取角度传感器漂移),这类 practice 再多也 RL 不出来。论文没有区分”可 RL 修复的 failure”和”结构性 failure”。
Related Work 的站位
论文在 Related Work 里把 VLA + RL 的前作分成了四类,定位自己为第四类:
| 类别 | 代表工作 | 本文的差异 |
|---|---|---|
| 直接 PPO fine-tune VLA | InteractivePostTraining, VLA-RL, piRL, SimpleVLA-RL | 前作用离散/Gaussian action,规模受限;本文用 端到端 flow-matching VLA |
| Residual policy / head fine-tune | ImprovingVLA, ConRFT 等 | 改 head 不改整体;本文 整个 VLA 端到端 offline RL |
| Value function + end-to-end | CORFT, GRAPE, VLA-C, SelfImprovingEFM | 前作用 Q-learning / DPO / PPO + REINFORCE;本文用 advantage conditioning 绕开 policy gradient |
| Return / advantage conditioning | Upside-Down RL, Decision Transformer, CFGRL | 前作针对 diffusion 或 offline RL 的小模型;本文 scale 到 generalist VLA + 真实长程 manipulation |
最接近的方法是 CFGRL (Frans et al. 2025)——它提出用 classifier-free guidance 做 diffusion policy 的 advantage conditioning;本文在此之上做了 VLA-scale + real-world + iterated offline RL 的工程化。
Method: Recap
Recap = RL with Experience and Corrections via Advantage-conditioned Policies
三步循环,可迭代 K 次:
- Data collection:跑当前 policy,每个 episode 拿 success/failure 标签,可选地让专家 teleoperator 在 agent 犯错时 intervene 提供 correction。
- Value function training:用所有累积数据训多任务 distributional VF 。
- Advantage-conditioned policy extraction:用 VF 算每个 的 advantage,二值化为 ,拼到 VLA 的 text prefix 里,做 SFT-style 训练。
Figure 3. VLA 与 value function 的交互结构:两边都从 VLM 初始化(VLA 是 4B Gemma 3,VF 是 670M Gemma 3),Knowledge Insulation 的 stop-gradient 保证 discrete text token 与 continuous action 互不干扰;advantage indicator 以 text 形式进入 prefix
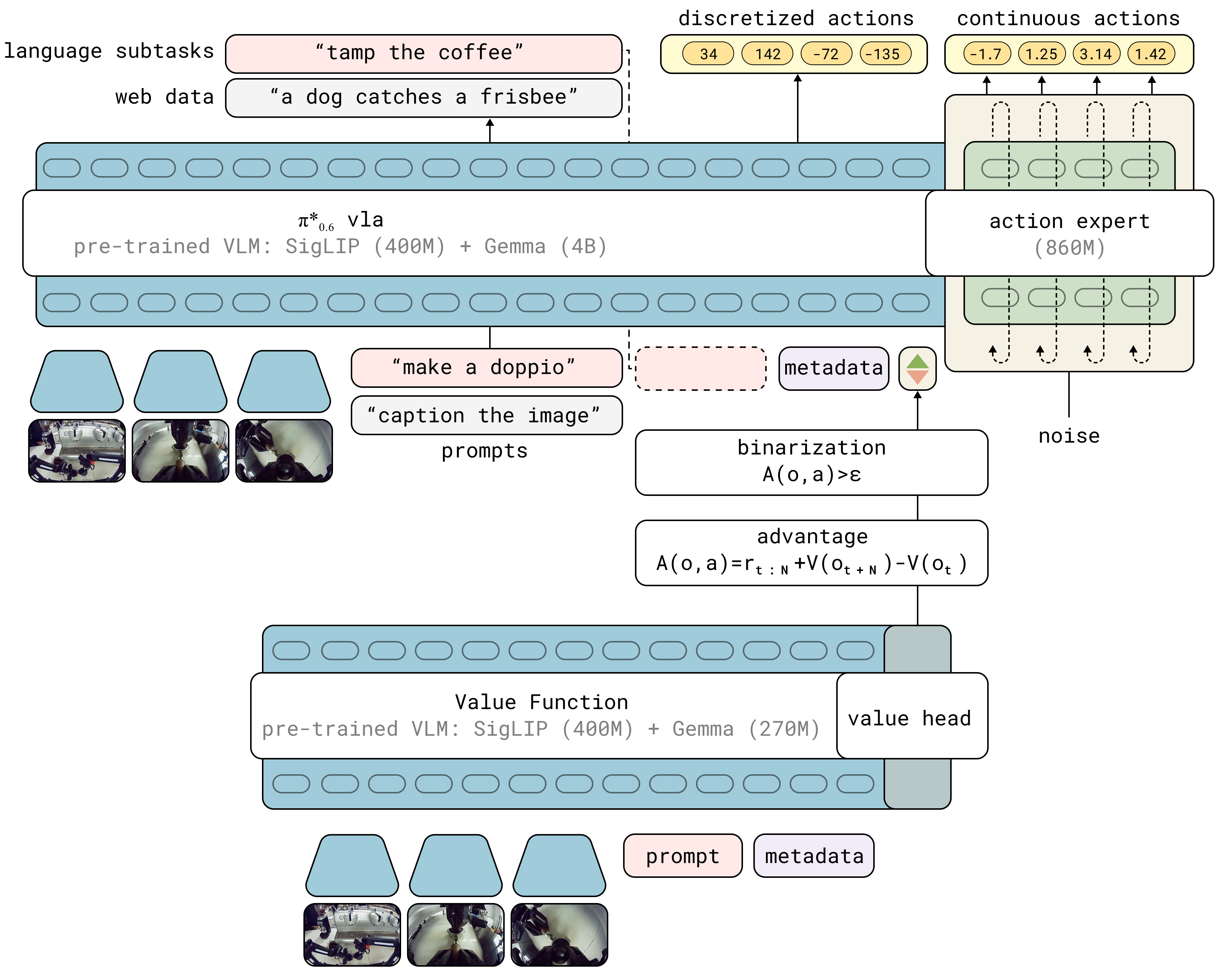
基础模型:π₀.₆ 的架构
来自 π₀.₆ 模型卡(这一信息在 paper 正文只匆匆带过):
- VLM backbone:SigLIP (400M) + π0.5 改用的 Gemma 3 4B,总 ~5B
- Action expert:860M 参数,和 backbone 层数相同
- 输入:最多 4 路 448×448 图像(base + 两腕 + 可选 backward for mobile),textual prompt + 可选 metadata,tokenized proprioception
- 输出:(a) discrete FAST tokens(VLM backbone 自己预测,做 Knowledge Insulation 的 co-train signal) (b) 50Hz continuous action chunks(action expert flow matching)
- 速度:5 denoising steps + 3 cameras → H100 上 63ms/chunk
- 相比 π0.5:更大 backbone(Gemma 3 vs PaliGemma)、更大 action expert、更丰富的 metadata 条件
- Knowledge Insulation:VLM backbone 正向 next-token prediction(包括 FAST action tokens 和 web 多模态 co-training),action expert 做 flow matching;action expert 的梯度不回传 backbone。这个设计是 advantage conditioning 能 plug-in 的关键——新增的 text token 自然地只影响 backbone 的 conditioning,不会打乱 flow matching。
Distributional Value Function
训练目标:预测”到任务成功还剩多少步”(distributional, 201 bins)。
Equation 1. Value function 的 cross-entropy 训练目标
符号说明: 是从 到 episode 结束的 empirical return 离散化到 个 bin; 是 language command。Reward 函数本身非常简单:每步 ,末步成功 、失败 (大负数),整体 normalize 到 。
关键工程选择:
- Multi-task language-conditioned:一个 VF 管所有任务,per-task 最大 episode 长度归一化
- Smaller backbone(670M vs 4B):保证 on-the-fly inference 在 VLA 训练时开销可控
- Web data co-training:防止 VF 过拟合
- Monte Carlo 估计而非 Bellman bootstrap:论文承认 off-policy Q-function 理论更好,但 on-policy MC “simple and highly reliable”
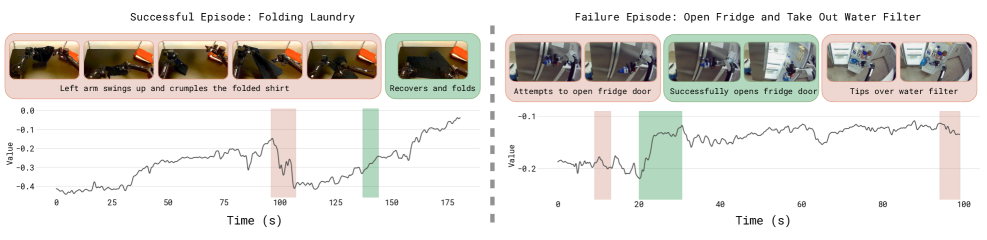
Figure 4. Value function 在两个 episode 上的可视化:successful folding 上 VF 稳步上升;一个 failed manipulation 上 VF 在犯错那一刻骤降(红色)。VF 能定位错误时刻——这本身就是很强的诊断工具
Advantage-Conditioned Policy Extraction
这是论文的 technical core,也是与 CFGRL 最贴近的部分。
Step 1: Regularized RL 的经典解
标准 regularized RL 解为 (AWR / MPO 家族)。
Step 2: 换成 improvement-probability 形式
论文用一个 less well-known 的结果:定义 ,其中 是”该 action 能 improve 的概率”,则 仍 guaranteed improvement。通过 Bayes rule 重写:
Equation 2. Improved policy 的 CFG-style 表达
当 时 ——只需同时建模条件和无条件分布,采样时条件取 即可,这就是 classifier-free guidance 的经典套路。
Step 3: Binary advantage indicator
把 设为 advantage 超过阈值的 delta:。阈值 per-task 调整(pre-train 用 30% percentile、fine-tune 用 ~40%、laundry 收紧到 10%)。在 prefix 里注入 “Advantage: positive” / “Advantage: negative”。
Step 4: 训练目标
Equation 3. 最终 policy 训练 loss(文字 negation 形式)
同时建模带/不带 indicator 的两种 log-likelihood。Continuous action 部分用 flow matching ELBO(Appendix A-C)代替真实 log-likelihood。实际实现上,论文随机 30% dropout advantage indicator 而非通过 调权——效果等价,且方便推理时做 CFG( 等价于在 gradient space 做 guidance,Appendix A-E 详推)。
Human correction 处理:所有 human intervention 的 action 强制 ,假设专家总是提供 “improving” action。这个近似在实践中 work 得不错,因为专家只在明显错误时介入。
❓ 30% dropout 这个超参看起来是工程味的魔法数字;论文没报 ablation。
❓ 强制 human correction 的 假设专家永远 improve。但如果专家的 style 和 VLA 的 “optimal style” 不一致(比如专家 prefer 慢而稳、VLA 想学快),这会引入 bias。
算法 1:完整流程
Input: multi-task demo dataset D_demo
# Pre-training (offline RL on demos)
V_pre ← train on D_demo via Eq.1
π_pre ← train on D_demo via Eq.3 with V_pre
# Per-task specialist
D_ℓ ← task demos
V_ℓ^0, π_ℓ^0 ← fine-tune from V_pre, π_pre on D_ℓ
# Iterative improvement
for k = 1 to K:
Collect rollouts with π_ℓ^(k-1), add to D_ℓ
V_ℓ^k ← fine-tune from V_pre on D_ℓ
π_ℓ^k ← fine-tune from π_pre on D_ℓ
注意一个细节:每轮迭代都从 π_pre(而非上一轮)fine-tune,防止 drift over iterations。
Experiments
任务与平台
Figure 6. 三大任务:laundry(3 个变体)、box assembly、espresso making

平台:双 6-DoF 臂 + parallel gripper,base + 两 wrist 相机,50Hz joint position control(静态 bimanual;pre-training 覆盖多种 robot)。
任务 success 定义:
| 任务 | 变体 | 成功判据 | 时限 |
|---|---|---|---|
| Laundry | T-shirts & shorts | 折好放右上角 | 200s |
| Laundry | diverse (11 种衣物) | 目标件折好堆叠 | 500s |
| Laundry | targeted failure removal | T-shirt 折好且衣领朝上 | 200s |
| Cafe | double espresso | 取 portafilter → 研磨 → tamp → 插机器 → 取杯 → 萃取 → 出杯 | 200s |
| Box assembly | — | 平板纸箱 → 组装 → 贴标 → 放置 | 600s |
Baselines
- π0.5 pre-trained:无 RL
- π₀.₆ pre-trained(supervised):有新 backbone 无 advantage conditioning
- π*₀.₆ RL pre-trained:offline RL pre-training,加了 indicator
- π*₀.₆ offline RL + SFT:上一个 + per-task demo fine-tune
- π*₀.₆ (Ours):加 on-robot experience 的完整 Recap
- AWR:同数据,policy gradient 的 advantage weighted regression
- PPO:同数据,单步 diffusion likelihood + SPO-style trust region
Main Results
Figure 7 (left) / Figure 8 (left). T-shirt & shorts laundry 上各阶段的 throughput 与 success rate:从 π0.5 到最终 π*₀.₆,throughput 单调上升,success rate 早就饱和在 95%+,gain 主要在速度
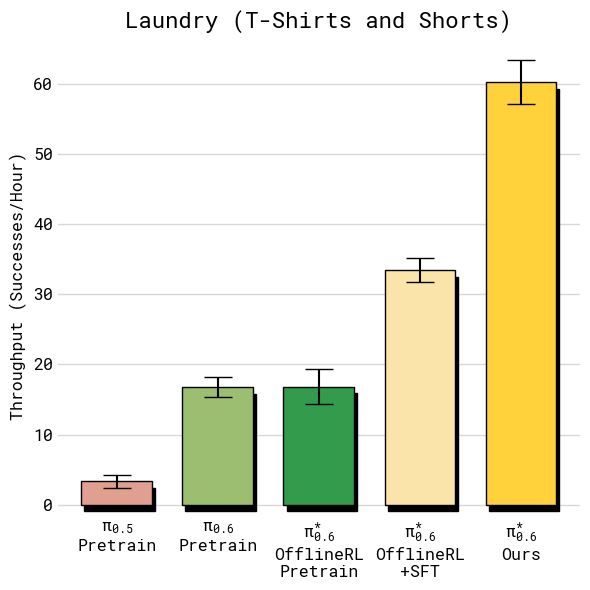
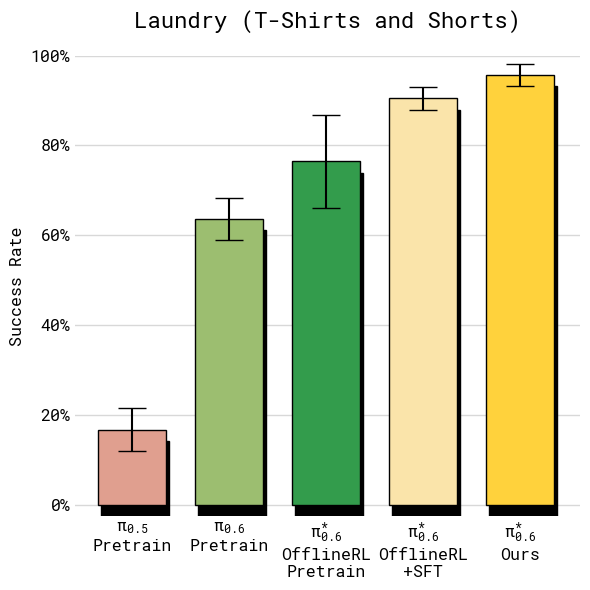
聚合数据:
| 任务 | Throughput 提升(Recap vs. 最强非 Recap baseline) | 最终 Success Rate |
|---|---|---|
| Laundry T-shirts/shorts | ~50% | >95% |
| Laundry diverse | >2× | |
| Espresso double shot | >2× | >90% |
| Box assembly | ~2× | ~90% per substage |
实际部署:
- 13 小时连续做 espresso(5:30am–11:30pm,不同 drinks)
- 新家中折 50 种衣物、连续 2+ 小时不中断
- 工厂组装 59 个巧克力包装盒
Iterative Improvement
Pure-autonomous t-shirt task(无 human correction)+ box assembly:
- T-shirt:iteration 1 就把 success 拉到 >90%;iteration 2 主要拿 throughput(+50%)。
- Box assembly:iteration 2 才看到 2× throughput——长程任务需要更多数据才收敛。
Recap vs. PPO vs. AWR(ablation on extraction method)
Figure 11. 同一批数据下,Recap 的 advantage conditioning 远胜 AWR / PPO;PPO 必须用 η=0.01 的极小 trust region 才稳定,代价是性能低
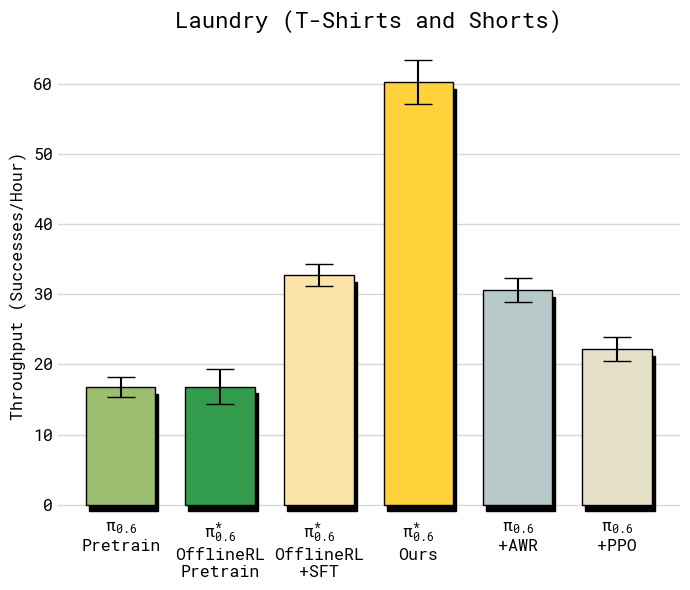
- PPO:flow matching 的 unbounded diffusion head 难以约束 trust region。加 SPO-style 定义 + 极小 η 才稳,但性能垫底。
- AWR:成功率 ok,但 policy 偏保守(filtered imitation 的副作用),速度慢、throughput 低。
- Recap:两个指标都领先——把 RL 问题降维成 SFT + CFG 是对 flow-matching policy 的关键工程解。
Targeted Failure Removal
Figure 12. 取 T-shirt 任务的严格变体(衣领必须朝上),用 1200 条 pure-autonomous rollouts + 两轮 Recap,success rate 从 baseline 的~30% 冲到 97%
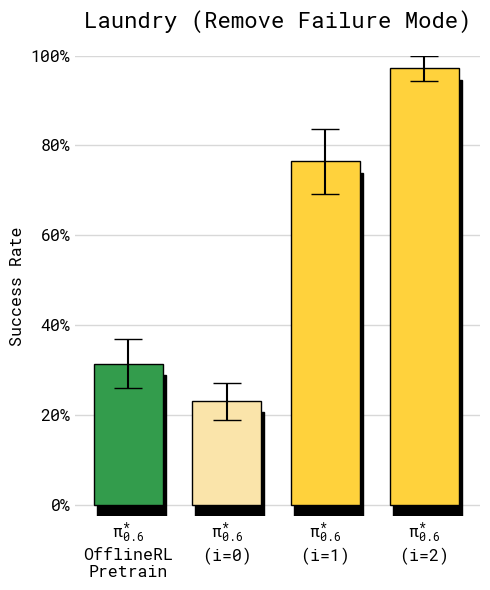
这个结果展示了 Recap 的 surgical 能力:不用人类干预,只靠 RL 就能消除一个 specific failure mode。对大规模部署来说这意义重大——“工厂发现了新的 failure → 收集 autonomous rollouts → 再训一轮”是一条可执行的运维流水线。
关键超参速查(Appendix A-F)
- Advantage lookahead:post-training ,pre-training (episode-final)
- Advantage dropout:30%
- Advantage threshold :pre-train 30% percentile / post-train ~40% / t-shirt laundry 10%
- CFG 推理 :moderate 1.5–2.5;过大会 push action 到 support 边界导致动作过激
- 数据量(correction + autonomous):t-shirt 300×4 robot / diverse laundry 450+287 / failure removal ~1000+658 / box 600+360 per iter / cafe 414+429
关联工作
基于
- π0: flow-matching VLA 的源头,本文继承其双 expert 架构
- π0.5: 直接前作,Knowledge Insulation 训练框架、语言-子任务预测高度沿用;π₀.₆ = π₀.₅ + 更大 backbone(Gemma 3 4B vs PaliGemma)+ 更丰富 metadata conditioning
- π0.7: 本文的后继(2026.04);π0.7 在 π*₀.₆ 基础上继续加 steerable generalist 能力
- Knowledge Insulation (Driess et al. 2025):stop-gradient action expert 是 advantage conditioning 能干净 plug-in 的前提
- CFGRL (Frans et al. 2025):diffusion policy 的 advantage conditioning 原始想法
对比
- PPO on diffusion/flow VLAs(DPPO, FPO, SPO):policy gradient 派,本文证明 trust region 在 flow VLA 上很难做,advantage conditioning 更优
- AWR(Peng et al. 2019):filtered imitation 的典型代表,下权 suboptimal data;本文用 advantage conditioning 保留所有数据
- Decision Transformer / RvS / Upside-Down RL:return-conditioning 的大家族,本文是其 VLA-scale 扩展
方法相关
- DAgger(Ross et al. 2011):compounding error 的经典分析;本文的 human-gated DAgger(HG-DAgger)沿用
- FAST action tokenizer(Pertsch et al. 2025):discrete action head 的基础
- Distributional RL(Bellemare et al. 2017):201-bin value head 的出处
- Calibrated Q-Learning / CORFT(Huang et al. 2025):最相关的 value-based VLA RL 前作,但用 Q-learning 且限 grasping task
论文点评
Strengths
- 真正的 real-world RL 闭环:13 小时 espresso、工厂 box assembly 不是 demo 视频而是真实 deployment,“toy task 做 RL” 的壁垒被跨过去了。
- Advantage conditioning 是工程上的关键 simplification:把 RL 问题编码成 “SFT + prefix text”,与 Knowledge Insulation 的 stop-gradient 天然兼容。Policy gradient 派在 flow matching 上不 tractable 的问题直接绕开。
- 异构数据的统一 framing:demo、autonomous、correction 三类数据在同一套 advantage conditioning 下训练,工程架构简单。
- Value function 设计可解释:distributional + negative steps-to-success + language-conditioned,既是 critic 又是诊断工具。
- Iterative loop 有效:两轮就能显著提升,说明 Recap 不是 one-shot 幸运。
- 失败模式定向消除(Fig 12):对工业部署极有价值的能力。
Weaknesses
- Autonomy 不完整:reward label、human intervention、episode reset 都还靠人;论文自己承认。这让”scale to 1000 hours of practice”还有很长路。
- Exploration 极其朴素:靠 policy stochasticity + human correction,没有 curiosity、没有 planned exploration。初始 policy 足够好时 OK,但如果任务是 genuinely novel(没有好 demo),RL 寸步难行。
- Offline RL 而非真正 online:batch collect → retrain → deploy,延迟 iteration。
- 超参巫术: 按 task 手调、dropout 30%、 和 CFG β 的关系也只给了定性描述——规模化时这套超参怎么自动化不清楚。
- 没有 scaling 曲线:data vs. performance、model size vs. performance 的系统性实验没做——读者无法判断”再收 10× 数据能到哪里”。
- Value function bootstrap 问题:MC 估计的 VF 在 iteration K 时反映的是 mixture policy 的 value,和 PPO 那种强 on-policy 假设不同;论文没 ablation 这件事对最终性能的影响。
可信评估
Artifact 可获取性
- 代码: 未开源(paper / blog / 模型卡均未提代码)
- 模型权重: 未发布 π*₀.₆ checkpoint;此前 π0 open source 过但 π₀.₆/π*₀.₆ 属于 PI 商用线
- 训练细节: 算法流程 + 关键超参在 Appendix A-F,但 compute budget、training steps、lr schedule、数据 mixing ratio 未完整披露
- 数据集: 私有 pre-training data;评估任务 demonstration 数量给出
Claim 可验证性
- ✅ Throughput 2×、failure rate 2× 降低:blog 视频证据充分(13h espresso / 工厂 box / 新家 laundry),可信
- ✅ Recap > PPO, AWR on same data:Fig 11 给了同数据 ablation
- ⚠️ “first time general-purpose RL recipe for VLAs succeeds”:前作(VLA-C, CORFT, SelfImprovingEFM 等)在 smaller-scale task 上也声称 success,具体”first general-purpose”是 fuzzy 定义
- ⚠️ Value function 的 credit assignment 可视化(Fig 4, 13):定性展示好看,但 VF 真的定位对了 causal credit 还是只定位了统计相关的 timestep,没有控制实验
- ⚠️ Iteration 收敛:只展示到 k=2,是否 saturates / collapses 未知
- ❌ 无明显 marketing overclaim
Notes
对自己研究方向的映射
VLN + VLA 统一视角:
- Advantage conditioning 是 model-agnostic 的——理论上可以统一 navigation head 和 manipulation head 的 RL 目标。Navigation 的 reward 更 dense(distance-to-goal),VF 训练可能比 manipulation 更容易。
- Knowledge Insulation 对 dual-head 架构至关重要:discrete navigation waypoint selection + continuous manipulation flow matching 可以 independent 训练——这正是 hierarchical VLA with dual action heads 需要的 decoupling。
- “Practice loop” 是 VLN 更应该做的事:navigation task 在 sim/real 都更容易 autonomous scale(reset 只要 teleport),比 manipulation 的 human reset 瓶颈低。Nav 可能是 Recap-style iteration 的更好第一验证场。
可迁移到 Video Understanding 研究的 insights:
- Distributional value head 做 progress prediction → video segmentation / temporal localization:给一段长视频,predict “距离事件发生还剩多少”。这和 event detection 的 framing 天然契合。
- Classifier-free guidance 做 advantage conditioning → video generation:给一段 noisy 视频生成,加上 “quality: high/low” prefix 做 CFG。
追问
❓ 为什么 binary indicator 比 continuous advantage 好?论文用 delta 分布近似,但没 ablation continuous advantage(比如 normalized to [0,1])会如何。直觉上 binary 是”更粗的 signal” — 为何更 work?可能和 flow matching 的 mode covering 特性有关:fine-grained 条件会让 flow 学歪。
❓ 放在 之后、actions 之前——这个 ordering 能不能让 预测本身也被 advantage 条件化?论文说只有 action likelihoods 被影响,但 causal attention 下 预测时看不到 ——OK 那就是 预测独立于 advantage。但这意味着subtask plan 不会因为 advantage 而改变,只有 low-level action 会。对 long-horizon 任务这是优点(高层 plan 稳定)还是缺点(高层 plan 错了就一路错)?
❓ 13 小时 espresso、2 小时 laundry 的成功率是怎么定义的?blog 里只说 “without interruption”——中间是否有 minor failures 被 recover?学术界的 success rate(严格 episode)和工业界的 “uptime” 是两个概念。
下一步如果我要 follow-up
- Recap on Navigation: 最容易验证的场景——R2R / HM3D 上用 distance-to-goal 训 VF,prefix 加 advantage indicator。一周工作量。
- Recap on VLN-VLA joint: 验证 navigation head 和 manipulation head 能否共用一个 multi-task VF,dual-advantage conditioning。
- Ablate binary vs continuous advantage: 补上 paper 缺的实验。
- Scaling curve: pre-train data / fine-tune data / model size 三条轴上跑 scaling,回答”Recap 的 sample efficiency 是多少”。
Rating
Metrics (as of 2026-04-24): citation=107, influential=13 (12.1%), velocity=20.58/mo; HF upvotes=1; github=N/A (无代码仓库)
分数:2 - Frontier 理由:按笔记 Strengths 第 1-2 点(首次在 4B+ flow-matching VLA 上跑通 real-world RL 闭环、advantage conditioning 绕开 flow matching 的 policy gradient 难题)和关联工作定位(与 CFGRL、CORFT 等同属 value-based VLA RL 前沿),这是该方向当前必须比较的 Baseline 与方法范式代表,符合 Frontier 定义;但发表仅数月(2025.11),citation 与社区采纳度尚未累积,且已有 π0.7 后继出现迭代,尚不足以锁定为 Foundation——本方向的脉络仍在快速演化,Foundation 档位留给能被时间验证的工作。2026-04 复核:5.2 月积累 107 citation / 13 influential (12.1%,典型 ~10% 偏高)、velocity 20.58/mo 属 VLA 方向前列,早期采纳信号明显;但 PI 无代码/权重释放、π*₀.₆ 还未被社区当 de facto baseline 广泛复用,仍在 Frontier 段位,尚不跨入 Foundation。