Summary
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
- 核心: NVIDIA 的开源人形机器人 VLA 基础模型——双系统架构(Eagle-2 VLM 作 System 2 + DiT flow-matching head 作 System 1),主打跨 embodiment 的数据金字塔 co-training。
- 方法: 在 “real robot + sim + neural trajectory + human video” 四类异构数据上联合预训练;action-less 数据用 latent-action codebook(VQ-VAE)和 IDM 打伪标;embodiment-specific MLP projector 吸收维度差异。
- 结果: 在 RoboCasa/DexMG/GR-1 sim benchmark 上显著超过 Diffusion Policy;真机 GR-1 humanoid 上,10% 数据的 GR00T N1 (42.6%) 已接近 full-data Diffusion Policy (46.4%)。
- Sources: paper | website | github
- Rating: 3 - Foundation(cross-embodiment humanoid VLA 的 de facto open baseline,“数据金字塔”+“neural trajectory as data engine” 是可复用的方法论 insight)
Key Takeaways:
- 数据金字塔 (Data Pyramid): 把训练数据按”数量-embodiment specificity”的 tradeoff 组织成三层:底层 human egocentric video(量最大,embodiment 最泛)、中层 sim + neural trajectory(量中)、顶层 real robot teleop(量最小但最贴下游)。方法论上比”把所有数据一锅炖”更清晰。
- Latent Action + IDM 双路伪标签: 无动作数据用 VQ-VAE 学 latent action codebook(类 LAPA),有真实 action 的数据上再训 IDM 打 pseudo-action。训练时把 latent-action 当成一个独立的 “LAPA embodiment”——不强求和真实 action 空间对齐。
- Neural Trajectory 数据增广: 用 fine-tuned image-to-video 模型把 88h 真机 teleop 扩到 827h(约 10x),配合 multimodal LLM 做 prompt 生成和质量过滤。这是公开 VLA 工作中最大规模的 “video-model-as-data-engine” 实验。
- 架构选择上的 delta vs π0: GR00T N1 用 cross-attention 耦合 VLM 和 DiT(解耦),π0 用 MoE 共享 transformer backbone(紧耦合)。GR00T 论证 cross-attention 的”灵活”更利于替换组件——但没直接 head-to-head,是 design choice 差异而非胜负。
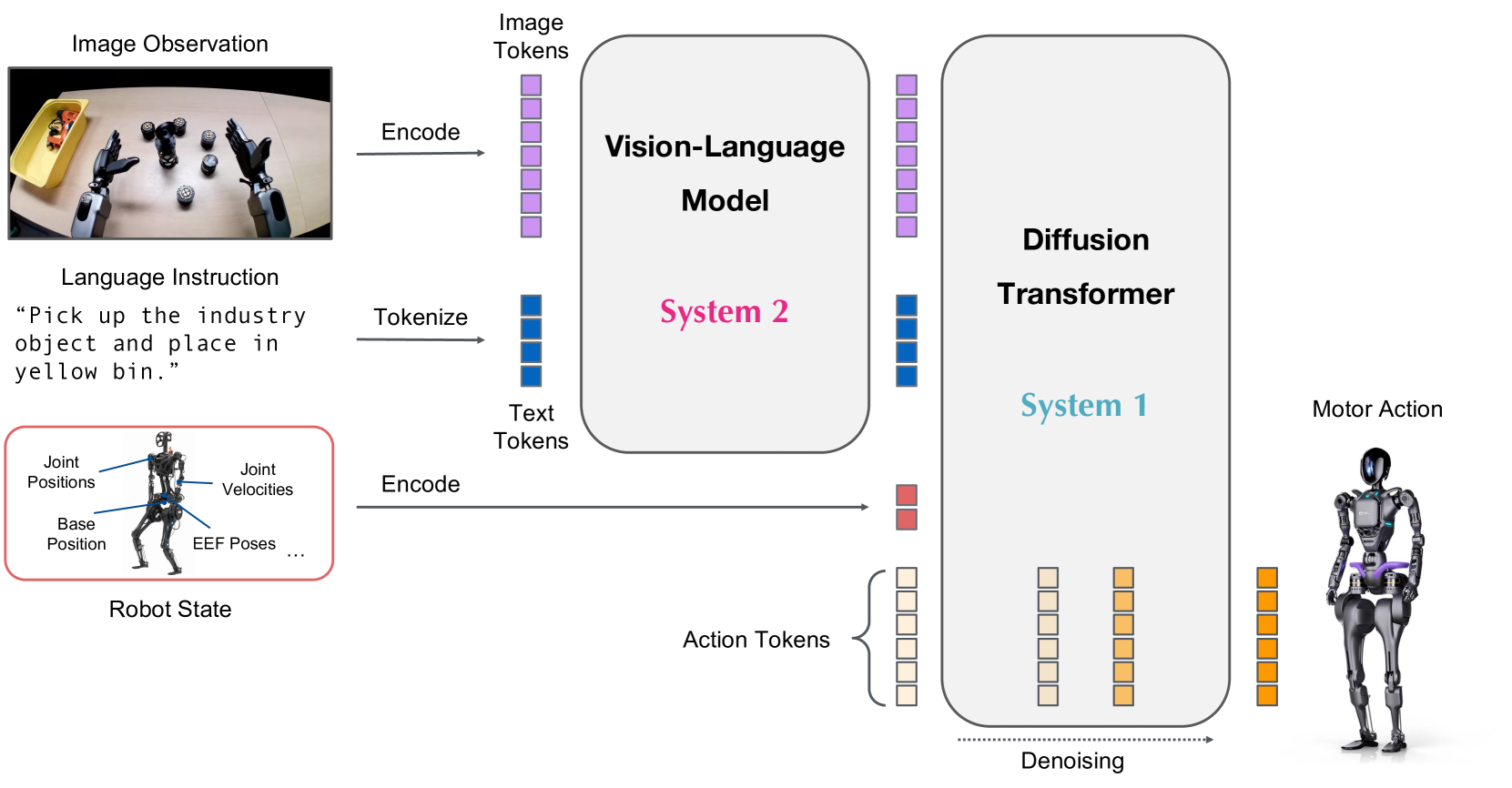
Teaser. GR00T N1 model overview: VLM (Eagle-2) 把 image+instruction 编成 token,DiT 对含噪 action chunk 做 flow-matching 去噪,通过 cross-attention 吃 VLM token、通过 embodiment-specific encoder/decoder 适配不同机器人。
1. Motivation: 为什么要数据金字塔
人形机器人缺 “Internet-scale” 数据。Cross-embodiment 的 Open X-Embodiment 试图把多机器人数据池化,但”sensor、DoF、control mode 差异太大,结果是一群 data islands 而非 coherent dataset”。
GR00T 的路线是承认 heterogeneity 并结构化地用它:
Figure 1. Data Pyramid。 自底向上:web/human video(量最大,embodiment specificity 最低)→ sim + neural trajectory(中层)→ real robot(顶层,最 grounded 但量最小)。

❓ 这个 pyramid 的纵向 “embodiment specificity” 轴和横向 “quantity” 轴是否正交?人类 egocentric 视频的 embodiment specificity 低,是因为它”不是机器人”,不是因为它泛。真正想要的是 “transferable prior strength”——论文没 tease 开这个概念。
2. Model Architecture
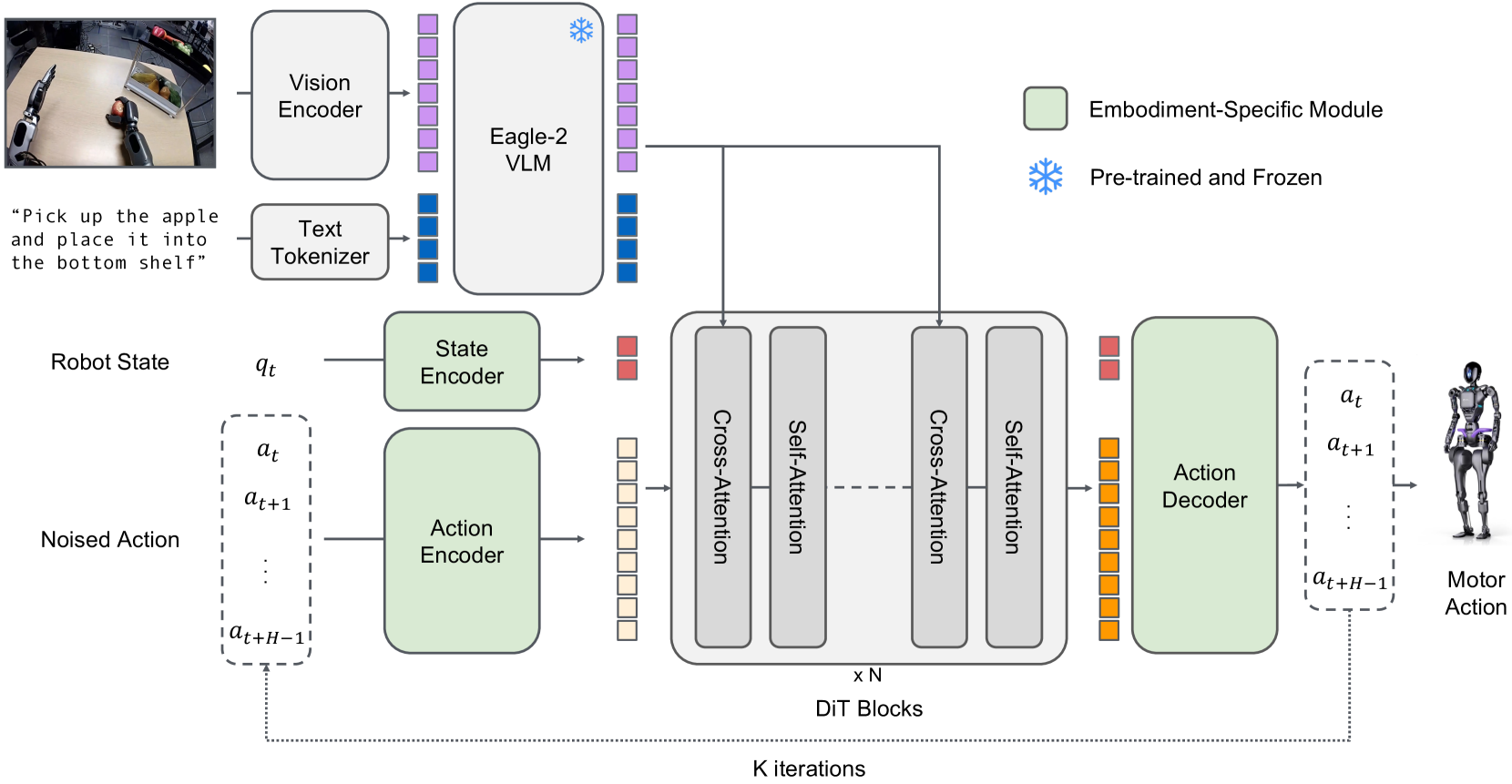
2.1 整体结构
System 2 (VLM, 10Hz): Eagle-2 VLM(SmolLM2 LLM + SigLIP-2 encoder),224×224 输入 + pixel shuffle 得 64 image tokens/frame。取 12th middle layer 的 LLM embedding 作为 condition——比 final layer 快且下游成功率更高。
System 1 (DiT, 120Hz): flow-matching DiT ,交替 self-attention(on noised action + state)+ cross-attention(on VLM tokens),类似 Flamingo/VIMA 结构。
Embodiment Adapter: 每个 embodiment 独立 MLP 作 state encoder / action encoder / action decoder,把变维度的 state/action 投到共享 hidden dim。Action encoder 还编码 flow-matching timestep 。
Figure 3. 架构图。
2.2 Flow Matching 训练目标
Action chunk ,。噪声 action ,, (和 π0 一致)。训练目标:
符号: = VLM tokens, = state embedding, 预测 denoising vector field 。
推理时从 开始做 步 forward Euler:
Inference latency: 2.2B 参数(1.34B 在 VLM),bf16 on L40 GPU,一次 16-step action chunk 63.9ms。
3. 数据生成与 Co-training
3.1 Latent Actions (for action-less data)
VQ-VAE 编码器吃 对,输出 latent action ;解码器重建 。训练后只用 encoder 的 pre-quantized 连续 embedding 当 latent action label,配合 flow-matching loss 训练,作为一个独立的 “LAPA embodiment”。
Figure 4. Latent action 的 cross-embodiment 一致性。 检索同一 latent code 下的 对:8 个 embodiment(含人手)在 “右手左移” 和 “右手右移” 两个语义下对齐。

❓ “Latent action 跨 embodiment 对齐” 是结构性的还是检索出来的?Fig 4 是 cherry-picked retrieval,不能证明 codebook 的所有 code 都有 cross-embodiment 语义。Ablation 里没直接跑 “latent action 做 transfer” 的实验。
3.2 Neural Trajectories
Fine-tune image-to-video 模型在 3k 真机样本 / 100 epoch,生成 ~827h (10x 扩增)。Pipeline:
- 用 commercial MLLM 从 initial frame 检测物体 + 生成 “pick {obj} from {A} to {B}” 的物理可行组合
- 生成视频
- 用 MLLM-as-judge(喂 8 帧)过滤不符合 prompt 的视频 + re-caption
Cost: 3600 L40 GPU × 1.5 days ≈ 105k L40 GPU hours(约等于模型训练 cost 的 2 倍)。
Figure 5. Neural trajectory 示例——同一 initial frame 不同 prompt、object 替换、spilling 这类 sim 难做的液体任务。

3.3 Simulation Trajectories (DexMimicGen)
DexMimicGen 把少量 human demo 切成 object-centric 段 → 按物体位置变换 replay → 只保留成功的。GR00T 用它生成 540k pre-training + 780k total sim demos,~6500 hours,11 小时内搞定——人力等价 9 个月。
3.4 Training Details
预训练: 在所有数据上 flow-matching co-training。Language 部分 frozen,其他 finetune。1024 H100 × ~50k GPU-hours = GR00T-N1-2B 预训练成本。
Post-training: 针对单 embodiment finetune。额外探索 co-training with neural trajectory:1:1 ratio real:neural,neural 用 latent 或 IDM 伪标签。
4. Evaluation
4.1 Benchmarks
- RoboCasa Kitchen(24 tasks,Franka Panda,3000 demos/task,MimicGen 生成)
- DexMimicGen Cross-Embodiment Suite(9 tasks,3 种 bimanual embodiment:Panda+parallel-jaw / Panda+dexterous / GR-1 humanoid,1000 demos/task)
- GR-1 Tabletop(24 tasks,GR-1 humanoid with Fourier dexterous hands,task 组合在 pre-training 中 unseen,1000 demos/task)
- 真机 GR-1:4 类任务(Pick-and-Place, Articulated, Industrial, Multi-Agent Coordination)
4.2 主表:Sim Benchmark(100 demos/task)
Table 2. Sim success rate average.
| RoboCasa | DexMG | GR-1 | Average | |
|---|---|---|---|---|
| BC Transformer | 26.3% | 53.9% | 16.1% | 26.4% |
| Diffusion Policy | 25.6% | 56.1% | 32.7% | 33.4% |
| GR00T-N1-2B | 32.1% | 66.5% | 50.0% | 45.0% |
GR-1 上优势最大(+17% over DP),是预期——pretrain 里有 GR-1 embodiment。
4.3 主表:真机 GR-1
Table 3. Real-world success rate.
| Pick-and-Place | Articulated | Industrial | Coordination | Average | |
|---|---|---|---|---|---|
| Diffusion Policy (10% Data) | 3.0% | 14.3% | 6.7% | 27.5% | 10.2% |
| Diffusion Policy (Full Data) | 36.0% | 38.6% | 61.0% | 62.5% | 46.4% |
| GR00T-N1-2B (10% Data) | 35.0% | 62.0% | 31.0% | 50.0% | 42.6% |
| GR00T-N1-2B (Full Data) | 82.0% | 70.9% | 70.0% | 82.5% | 76.8% |
关键数字:GR00T 10% 数据 ≈ DP 100% 数据(42.6 vs 46.4)。这是 pre-training prior 换 demo cost 的 ~10x 杠杆。
4.4 Zero-shot Pre-training 评估
两个任务(place on shelf with bimanual handover / place novel object into unseen container),pretrained checkpoint 直接跑:76.6% 和 73.3% success(各 15 trials)。说明 pretrain 学到了可泛化的 grasping + handover primitive。
4.5 Neural Trajectory Co-training Ablation
Figure 9. Neural trajectory for post-training (RoboCasa sim + real GR-1).
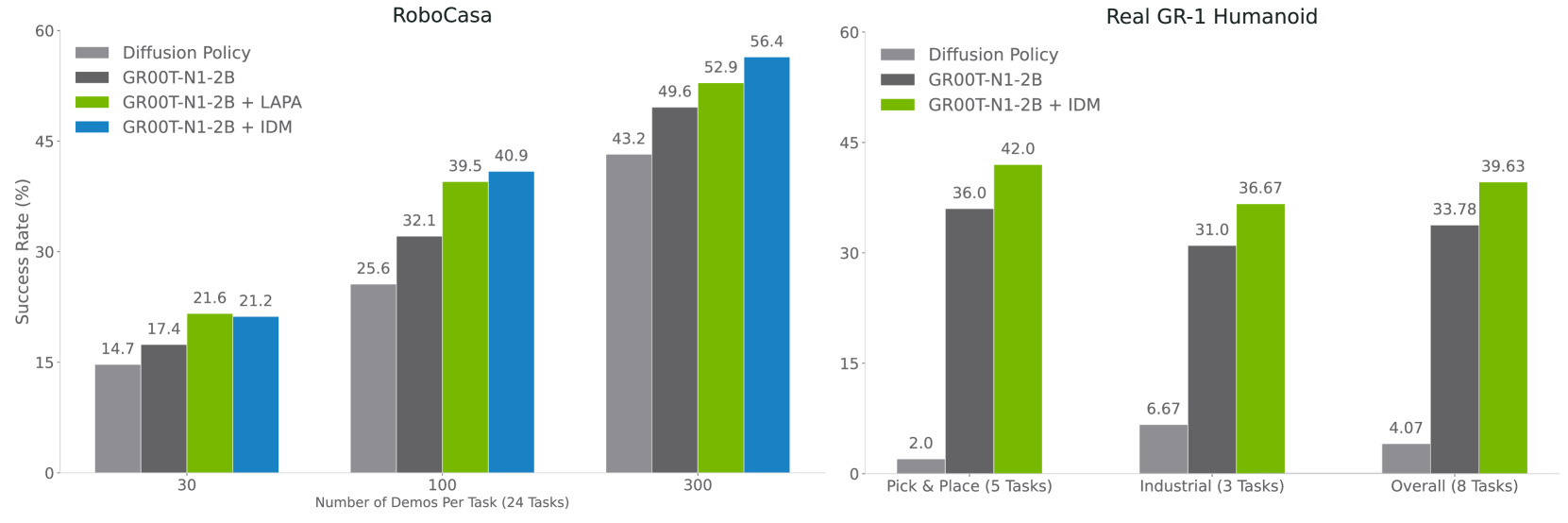
- RoboCasa: +4.2% / +8.8% / +6.8% 在 30 / 100 / 300 demos 设定下。
- 真机 Pick-and-Place + Industrial: +5.8% 平均提升。
- LAPA vs IDM 对比:低数据(30)时 LAPA 略胜,数据多(100/300)时 IDM 优势扩大——符合直觉(更多数据让 IDM 学得更准)。
4.6 Qualitative Observation
一个有意思的 pretrain > posttrain 的 regression 案例:“Pick up red apple, place in basket”,苹果放在左手左边。Pretrained checkpoint 会用左手抓、右手接、右手放(bimanual handover);post-trained checkpoint 失败——因为所有 post-train 数据都是右手单手任务,模型丢失了 handover 能力。
这是 catastrophic forgetting 的一个具体例子,也是 embodied 模型 post-training 的结构性挑战:下游数据分布越窄,越容易 erase pretrain 学到的 primitive。
5. Limitations(我的延伸)
- 短 horizon tabletop only:long-horizon loco-manipulation 完全没碰。
- Neural trajectory 的 cost:10x 数据扩增的 compute cost(105k L40 GPU-hours)和真机 teleop 的 cost 哪个更划算?论文没算 ROI。
- Dexterous hand 任务多数 sim/teleop:真机 benchmark 主要是 pick-and-place 类,没涉及 precise insertion、deformable、contact-rich。
- VLM 部分 frozen language:VLM 的 language 头全程 frozen,没有 co-train language 部分。这样 VLM 对 robot-specific instruction 的适配是否够?
关联工作
基于
- Eagle-2 VLM: NVIDIA 自家 VLM,GR00T 的 System 2 backbone
- DexMimicGen: GR00T sim 数据的主要生成器
- π0: flow-matching VLA 先例(timestep schedule 直接沿用)
- LAPA: latent action codebook 思路的直接来源
- RoboCasa: sim benchmark 来源
对比
- Diffusion Policy: 作为主要 from-scratch baseline
- BC-Transformer (RoboMimic): 作为传统 BC baseline
方法相关
- π0: 同样 flow-matching,但用 MoE 共享 backbone;GR00T 用 cross-attention 解耦 → architecture design delta
- π0.5 / π0.7: 后续 PI 系列,同样拥抱 heterogeneous data co-training
- OpenVLA: 另一条 VLA 技术路线(discrete action tokenization)
- OpenVLA-OFT: OpenVLA 的 flow-matching 升级
- Open X-Embodiment: cross-embodiment 数据源
- Ego4D / Ego-Exo4D / EPIC-KITCHENS / HOI4D: human video 预训练来源
论文点评
Strengths
- 工程和开源完整度顶:模型权重、训练数据、sim benchmarks 全开源,Apache 2.0 / NVIDIA OML 许可;github 仓库持续维护(已迭代到 N1.7)。这是跨 embodiment VLA 领域少有的高质量 open artifact。
- 数据金字塔是个有用的 taxonomy:不是”又训一个大模型”,而是系统化地 articulate 了 “heterogeneous data co-training” 的结构——web video (base) / sim + neural traj (mid) / real robot (apex)。这个 mental model 可以被后续工作直接复用。
- Neural trajectory 的工程规模是公开最大的:827h 生成视频 + 3600 L40 GPU 的验证,说明”video generation as data engine” 已经从 toy demo 进入工业量级。后续 PI 系列也采用类似思路,印证方向。
- Ablation 对关键设计做了回答:middle-layer vs final-layer VLM embedding、 步去噪、LAPA vs IDM pseudo-action——都有具体比较,不是靠直觉断言。
Weaknesses
- 和 π0 没有直接 head-to-head:同期最强的 open VLA baseline 是 π0,但 GR00T 只对比 Diffusion Policy / BC Transformer。Cross-attention vs MoE 的架构差异没有实证定论。
- Pretrain eval 样本量过小:zero-shot pre-training 的两个任务各 15 trials,76.6% 和 73.3% 的置信区间非常宽,不足以 substantively claim “strong generalization”。
- Latent action cross-embodiment transfer 没有直接证据:Fig 4 是 cherry-picked retrieval,没做 “只用 human video 的 latent action 预训练 → 机器人 task 上的 transfer gain” 这种干净 ablation。
- Post-training catastrophic forgetting 被 narrative 为 “feature”:bimanual handover 丢失的 case 其实是严重的 regression,但论文只做 qualitative 展示,没量化、没给 mitigation。
- Neural trajectory 的 downside 模糊处理:附录 Fig 13 展示 multi-round generation、liquids 等 “hard simulation” 的能力,但明确说 “quantitative evaluation left for future work”——没证据证明这些是真能 transfer 到 policy 的。
可信评估
Artifact 可获取性
- 代码: inference + training 完整开源(github.com/NVIDIA/Isaac-GR00T),Apache 2.0。包含 finetuning、deployment(TensorRT)、server-client eval 全套 pipeline。
- 模型权重: GR00T-N1-2B base + LIBERO / DROID / SimplerEnv-Bridge / SimplerEnv-Fractal 多个 finetuned checkpoint,HuggingFace 可直接下载(~6GB)。N1.6/N1.7 后续版本也已发布。
- 训练细节: 超参(pre-train / post-train table 6 in appendix)+ 数据配比 + 训练步数 + GPU hours(50k H100-hours pretrain)+ infra(NVIDIA OSMO + Ray)完整披露。
- 数据集: 开源部分 = PhysicalAI-Robotics-GR00T-X-Embodiment-Sim(HF datasets)+ 所有公开数据集(Open X-Embodiment、Ego4D、AgiBot-Alpha 等)。内部 GR-1 teleop 数据集未公开,是最大的 gap。
Claim 可验证性
- ✅ Sim benchmark 上超过 Diffusion Policy / BC Transformer:Table 2/4 有详细 per-task 数字,协议(100 trial、max of last 5 ckpt)明确,可复现。
- ✅ 10% data data efficiency:Table 3/5 per-task 数字清楚,4 类任务 consistent advantage。
- ✅ Inference 63.9ms on L40 for 16-step chunk:工程数字,github 里有脚本可直接测。
- ⚠️ “Pretraining 使模型 zero-shot 具备 bimanual handover”:只 15 trials,统计量不够;且和 post-train 模型的对比是 anecdotal(Fig 11)。
- ⚠️ “Latent action space is cross-embodiment consistent”:Fig 4 retrieval 是 qualitative 证据,没有定量实验(如 latent code 的 embodiment-invariance 分析)。
- ⚠️ “Neural trajectory co-training 一致带来 gain”:数字(+4~+9%)确实正向,但没控制 compute budget——同样的 compute 用来训练更多步数 vs 训练 neural trajectory 哪个更好?没比。
- ❌ “Open foundation model for generalist humanoid robots”:标题 claim。实际上任务范围局限在短 horizon tabletop,没有 locomotion、long-horizon,“generalist humanoid” 是 marketing overclaim。
Notes
- 与 PI 系列的定位差异:PI 系列更强调连续迭代(π0 → π0.5 → π0.7),架构上是 MoE backbone;GR00T 更强调 NVIDIA 生态闭环(Isaac sim / Cosmos video model / OSMO compute)。两者技术思想收敛(heterogeneous data + flow-matching + action chunking),工程路径分叉。
- 值得跟进的线索:
- Latent action 跨 embodiment transferability 的严格测量(GR00T 论证不充分)
- Neural trajectory compute ROI 分析——何时”合成数据 > 真机数据采集”
- VLM frozen 的代价——在 long-horizon、language-heavy 任务上 VLM co-train 是否必要
- 实验启示:如果我要做 cross-embodiment VLA,GR00T N1 的 repo 可以作为 codebase 起点;但如果做 efficient VLA / small model,可能更应该看 SmolVLA。
Rating
Metrics (as of 2026-04-24): citation=649, influential=106 (16.3%), velocity=49.17/mo; HF upvotes=7; github 6820⭐ / forks=1152 / 90d commits=43 / pushed 0d ago
分数:3 - Foundation 理由:cross-embodiment humanoid VLA 方向的 de facto open baseline——Strengths 里提到模型权重/数据/sim benchmark 全开源,github 持续迭代至 N1.7,后续 PI 系列(π0.5/π0.7)也收敛到同类 heterogeneous data co-training 思路。“数据金字塔” 与 “neural trajectory as data engine” 作为方法论 taxonomy 可被后续工作直接复用,不是单纯的 +SOTA 论文。不降到 2 是因为它已超出”前沿参考”的定位,成为领域必引的奠基工作;不升到更高因为 Weaknesses 里的 overclaim(“generalist humanoid”局限在短 horizon tabletop)和 π0 无 head-to-head 是明确短板。2026-04 复核:citation=649 / velocity=49.17/mo(方向内顶级)、influential 比例 16.3%(高于典型 10%)+ 6820⭐ + 今日 push 的活跃仓库,全部数字强化 Foundation 判定。