Summary
ETP-R1: Evolving Topological Planning with Reinforcement Fine-tuning for VLN-CE
- 核心: 把 “scaling data + RFT” 范式首次系统性地搬到 graph-based VLN-CE 上,用 closed-loop GRPO 替代 LVLM 路线的 open-loop RFT
- 方法: Gemini API 重新标注 Prevalent 形成大规模高质量预训练集 + R2R/RxR 联合预训练 + 三阶段(offline pretrain → online DAgger SFT → online GRPO RFT)
- 结果: VLN-CE Test Unseen SR 64 / SPL 54(+6 / +3 over G3D-LF);RxR-CE Val Unseen 全指标 SOTA
- Sources: paper | github
- Rating: 2 - Frontier(graph-based VLN-CE 上首次 closed-loop GRPO,R2R/RxR-CE 新 SOTA,但方法多为组合创新,作为 baseline 价值高于 foundation)
Key Takeaways:
- Graph-based VLN 才是 VLN-CE 上 RFT 的天然底座: waypoint 级 high-level action space 等价于 RL 的 token,使 closed-loop, multi-turn GRPO 直接可用;LVLM-based 方法(如 VLN-R1)受限于 offline 训练,RFT 实际是 single-turn open-loop。
- Speaker model 的瓶颈不在数量而在多样性 + hallucination: 用 Gemini 2.0 Flash 配合 trajectory segmentation prompt 重新标注 Prevalent,平均长度 31→48 词;ablation 显示同等数据量下 Gemini-aug 比原 Prevalent 在 SAP 准确率上高得多(MLM 反而略低,因为 in-domain)。
- 预训练分数与最终 online 表现强正相关:作者用这个相关性把架构 ablation 从昂贵的 online eval 偷换成廉价的 pretraining score,但也暴露了模型 data-hungry 的本质——架构改动收益(~0.5-0.85%)远小于数据 scaling(~6.5%)。
- GRPO on VLN 的关键工程发现: dropout(包括 sampling 阶段和 frozen layer)必须开;temperature scaling 反而有害;strict on-policy(μ=1)最好。这些 finding 与 LLM-RL 社区的常识有出入,值得记入 GRPO 的应用 playbook。
- R2R/RxR 联合预训练给跨任务泛化加分: 加入 RxR 数据后 R2R 性能再涨 1.16%,但远不如继续加同任务数据(6.55%)——cross-task transfer 存在但边际有限。
Teaser. ETP-R1 与 LVLM-based、传统 graph-based 方法的 pipeline 对比

Background:为什么 graph-based VLN 值得重做一遍
VLN-CE 任务在 Habitat 中要求 agent 给定语言指令、在连续环境中以 4 个 motor action(前进 0.25m / 左右转 15° / STOP)完成导航,每步获得 12 张 RGBD 全景图。当前两条主流路线各有死结:
- LVLM-based(StreamVLN、VLN-R1):token 输入冗余(重叠视图导致 token 线性增长)、缺少全景预训练所以只用 forward-facing 单视图、被迫用低层 motor action space 学长程导航。
- Graph-based(ETPNav、BEVBert、HNR、G3D-LF):online 用 waypoint predictor 构建拓扑图,agent 只决定下一个 waypoint,低层执行交给 deterministic controller。结构简洁但没有充分利用大规模数据和 RFT 范式。
ETP-R1 的论点是:graph-based 的 high-level discrete action space 才是 RFT 的天然适配——一个 episode 就是一个 prompt,一条轨迹就是一个 answer,每个 waypoint 决策就是一个 token,outcome reward 可以直接施加到完整 episode。这与 LVLM-based 方法只能在单轮 token 输出上做 open-loop RFT 形成对比。
❓ 论文反复强调 “graph-based + waypoint-based action space 与 GRPO 天然契合”,但 ETPNav 那一系工作并没有提出 RFT,而 RL 在 VLN-CE 上历史上确实少见(论文也提到 Krantz 2021 用 RL 训 waypoint predictor 效果有限)。如果这个 framing 真这么自然,为什么过去没人做?我倾向于:closed-loop online RL 在 VLN-CE 上工程门槛很高(每个 episode 要在 Habitat 里跑完才有 reward),ETPNav 系作者没有 RL infra 经验,而 LVLM 圈最近才把 RFT 模板传播开。这是 timing 问题不是 inevitability。
Method
整体框架

复用 ETPNav 的 topological mapping 与 low-level controller,三个核心创新分别落在:(1) 数据标注(Sec III-A)、(2) cross-modal planning network(Sec III-B)、(3) 三阶段训练范式(Sec III-C)。
Gemini-based Instruction Annotation
针对 Prevalent 数据集(1M 合成轨迹,原 speaker model 标注)做 re-annotation,目标是降 hallucination、提升 linguistic diversity:
- 视觉输入:每个 viewpoint 横向拼接 left/front/right 三张 90° FOV monocular 图(避开 LVLM 不擅长的全景),用红色箭头叠加指示去往下个 viewpoint 的方向。
- Heading 对齐:viewpoint 的朝向 = 从 到达的方向; 用 episode 起始 heading。Edge case: 第一步往后退则重定向,prepend “Turn around”; 箭头出 view 直接丢弃(约 2% 轨迹)。
- Trajectory segmentation prompt:把轨迹随机切成 1/2/3 段,每个 split scheme 让 Gemini 对每段写两条描述,单次 API call 拿 6 条不同 granularity 的 instruction。故意不给 R2R few-shot examples 以免限制 Gemini 的语言风格,只约束每段描述 10-25 词。

最终 Prevalent_Gemini_Aug 平均指令长度从 31 词增至 48 词。
Model Architecture
0.5B 参数的 cross-modal planner,由 text encoder + node encoder + DPFT + 两个 task head 组成:
Text Encoder
BERT-style RoBERTa(12 层)。在 word + position + type embedding 之外引入 task embedding:R2R=1, RxR=2, Gemini-aug=3,让模型在联合预训练时区分语言风格。
Node Encoder
每个图节点的 12 RGBD 观测分别过 ViT-B/32 (CLIP, RGB) 和 ResNet-50 (DDPPO point-goal, depth),加上 view angle embedding 后过 panorama Transformer (2 层) 融合全景。访问过的节点 token 是 12 视角输出的平均;未访问节点直接继承父节点对应视角的 feature。再加 step / position / task embedding。STOP action 单独占一个 token。
DPFT (Dual-Phase Fusion Transformer)
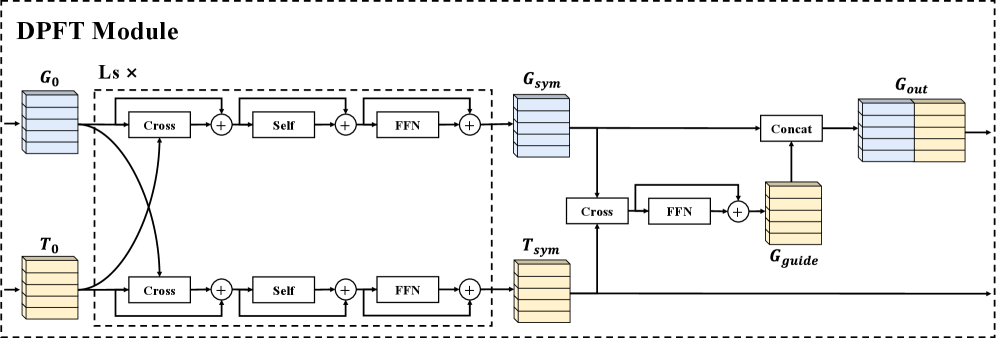
两阶段融合:
- Symmetric Cross-Modal Fusion ( 层):双向 cross-attention(与 LXMERT 不同的是两个方向不共享权重作为 scaling 策略)+ self-attention + FFN,得到 。
- Text-Guided Graph Refinement:graph 单向 query text 抽出 language guidance,concat 回原 graph feature:
Task Heads
两个 FFN:SAP 给每个候选节点打分(推理时取 argmax),MLM 用于预训练时预测 masked token 分布。
❓ DPFT 的设计相对直接,提升不大(ablation 表 II 显示去掉 Text-Guided 模块只掉 0.85% 总分)。这与作者自承的 “data-hungry” 属性一致——模型容量已经远小于数据信号能驱动的范围,架构 tweak 的边际收益自然小。
三阶段训练
Stage 1: Offline Joint Pretraining
5 个数据集联合:Prevalent (1M) + Prevalent_Gemini_Aug (1M) + RxR-Marky (1M) + R2R_train (14K) + RxR_train (80K)。两个 auxiliary task:SAP 与 MLM,1:1。Best checkpoint 按 R2R+RxR val_unseen 上 SAP+MLM 之和挑。
Stage 2: Online SFT (DAgger)
针对每个任务单独微调。每步以概率 follow expert action(global planner 给的 optimal node), sample 自己的 policy。VLN-CE 按 SR+SPL 选 ckpt,RxR-CE 按 nDTW+SDTW。
Stage 3: Online RFT (GRPO)
数据划分:90% 给 SFT,剩 10% 留给 RFT。只 fine-tune DPFT + SAP head,其他 freeze。
Reward:
gSPL 关键 trick:用 ground-truth path length 替代 SPL 中的 shortest path length。RxR 的 reference path 经常故意非最短,用 SPL 会激励 agent 走捷径违反指令;gSPL 才能正确鼓励 “高效但忠于指令” 的路径。
Group trajectories 算 advantage(z-score 标准化),分配给该轨迹所有 high-level step;KL weight ,clip ,update iter 。
Experiment
Main Results
Table I. VLN-CE 和 RxR-CE 主结果
| Method | R2R Val NE↓ | R2R Val SR↑ | R2R Val SPL↑ | R2R Test NE↓ | R2R Test SR↑ | R2R Test SPL↑ | RxR Val nDTW↑ | RxR Val SDTW↑ |
|---|---|---|---|---|---|---|---|---|
| ETPNav | 4.71 | 57 | 49 | 5.12 | 55 | 48 | 61.90 | 45.33 |
| HNR | 4.42 | 61 | 51 | 4.81 | 58 | 50 | 63.56 | 47.24 |
| G3D-LF | 4.53 | 61 | 52 | 4.78 | 58 | 51 | - | - |
| Ours-DAgger | 4.11 | 63 | 54 | - | - | - | 63.78 | 48.53 |
| Ours-GRPO | 3.94 | 65 | 56 | 4.19 | 64 | 54 | 65.31 | 50.41 |
观察:
- 仅 SFT (Ours-DAgger) 在 VLN-CE Val Unseen 已经超过所有 baseline,说明强基础模型 + 高质量数据已经吃掉了大部分增益。
- GRPO 在 SFT 之上再涨 ~2 SR / 2 SPL,幅度最显著的是 R2R Test Unseen(+6 SR over G3D-LF)——更强的 generalization 提升暗示 RFT 在缓解分布偏移。
Ablations
数据组成
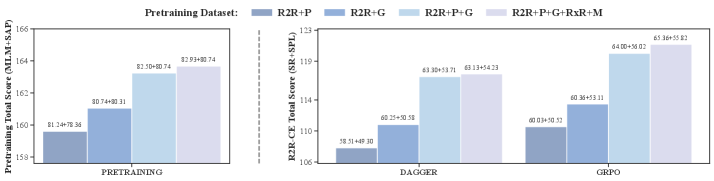
- R2R+G vs R2R+P:换成 Gemini 标注,pretrain +1.45%, online +3%。Gemini 数据 MLM 略低(in-domain bias)但 SAP 显著更高,说明 hallucination 真的在毒害 action policy 学习。
- R2R+P+G vs R2R+G:再叠 1M 原 Prevalent,pretrain +2.19%, online +6.55%。VLN 还在 data-hungry 阶段。
- R2R+P+G+RxR+M vs R2R+P+G:加 RxR 相关数据,R2R 性能再 +1.16%。Cross-task transfer 存在但边际较小。
架构组件 (Table II)
| 变体 | MLM | SAP | Total |
|---|---|---|---|
| Full Model | 82.93 | 80.74 | 163.67 |
| - Text-Guided | 83.10 | 79.72 | 162.82 |
| - Task Emb | 82.21 | 80.87 | 163.08 |
去掉 Text-Guided Refinement 掉 0.85%,去掉 task embedding 掉 0.59%。
GRPO 配置 (Table III)
| 变体 | SR | SPL | Total |
|---|---|---|---|
| Ours-GRPO | 65.36 | 55.82 | 121.18 |
| - Sample Dropout | 63.78 | 55.10 | 118.88 |
| - Frozen Dropout | 64.17 | 54.96 | 119.13 |
| + Temperature Scaling (T=2→1) | 63.46 | 53.80 | 117.26 |
| + Multi-Epoch Update (μ=2) | 64.76 | 54.25 | 119.01 |
最有意思的发现:
- Dropout 必须开(包括 sampling 和 frozen 层),关掉掉 ~2%。作者归因于 dropout 引入 stochasticity,避免 well-trained 模型的 policy collapse 到 local minimum。
- Temperature scaling 反而有害:作者推测温度让 logits 更平,模型反而强化 confidence 而非学新知识。
- Strict on-policy (μ=1) 最好:每个 batch 只更一次。多更一次也掉 ~2%。
❓ Dropout-as-exploration 的解释听起来合理,但 GRPO 标准做法里很少强调 dropout 的作用,常见 wisdom 是 sampling temperature 控制 diversity。这里 temperature scaling 失败可能是 hyperparameter tuning 问题(T=2→1 的 schedule 选得不好),不能简单结论 “temperature 不行 dropout 行”。值得在自己 RL 项目里复现验证。
关联工作
基于
- ETPNav: 直接复用其 topological mapping + low-level controller;ETP-R1 实质是 ETPNav 的 “scaling + RFT” 续作。
- Prevalent (Hao et al. 2020): 1M 合成 VLN 轨迹的来源数据集,被 ETP-R1 用 Gemini 重新标注。
- GRPO(DeepSeek-Math, Shao et al. 2024): RFT 算法骨架,原样使用 KL-regularized objective。
对比
- VLN-R1: 同样名字含 “R1”,同样做 VLN + RFT。但 VLN-R1 是 LVLM-based + offline + open-loop RFT;ETP-R1 是 graph-based + online + closed-loop。论文核心 framing 就是与 VLN-R1 类的 LVLM 路线划清界限。
- StreamVLN: LVLM-based VLN-CE 的另一代表,被作者作为 “token 冗余 + 单视图” 的反面教材引用。
- HNR / G3D-LF / BEVBert: 同样 graph-based 的前 SOTA,作为 main table 的对比 baseline。
方法相关
- LXMERT: DPFT 的 symmetric cross-modal fusion 借鉴自此,但改为 unshared weights 作为 scaling 策略。
- DAgger: Online SFT 阶段的 expert mixing 算法。
- ScaleVLN: 早期把 scaling-up data 思路引入 VLN 的工作,但仍在传统范式内;ETP-R1 把 scaling 与 RFT 都打通。
- RxR-Marky: 提供 RxR 风格大规模 instruction 标注,被纳入联合预训练。
论文点评
Strengths
- Framing 清晰且 actionable:把 graph-based VLN 重新定位为 “天然适合 closed-loop RFT” 的 substrate,与 LVLM 路线的 open-loop RFT 形成清楚对比。这个 framing 即便方法本身不算颠覆,也帮社区想清楚了为什么 graph-based 不该被 LVLM 浪潮淘汰。
- 数据 ablation 扎实:用 R2R+G vs R2R+P 的对照清楚证明了 hallucination 而非数据量是 speaker-based 标注的瓶颈,这是个可迁移到其他需要合成指令任务的 insight。
- GRPO 工程细节透明:dropout / temperature / on-policy 三组 ablation 给出了 RL 训练的 nontrivial 经验,且坦诚 reward 设计中 SPL→gSPL 的修正动机(避免 RxR 上的 shortcut hacking)。
- Stage decoupling 干净:offline pretrain 用 5 个数据集 → online SFT 各任务单独 → online RFT 只动 DPFT+SAP head,每一阶段的目标和约束都很清晰。
Weaknesses
- 新颖性主要靠组合:DPFT 是 LXMERT 的小改(unshared weights + 单向 refinement),三阶段范式是 NLP 圈成熟流程,GRPO 是直接用现成算法。真正的核心 contribution 是 “把这套搬到 graph-based VLN 并 work”——publishable 但论文没有揭示更深的 RL-on-VLN 一般性原理。
- GRPO 提升幅度并不惊人:R2R Val Unseen SR 63→65(+2),SPL 54→56(+2)。考虑到 RFT 阶段额外耗费的 compute 和数据 (10%),性价比不算极高。Test Unseen +6 才是真正的卖点,但作者没有深入分析为什么 GRPO 在 OOD 上提升更大。
- Reward 设计 ad-hoc:R2R reward 是三项加权和 (),权重是 hand-tuned,没有 sensitivity analysis。如果 reward shaping 需要任务特定调,方法的 generalize 性就打折。
- 比较对象缺一类:对比表没有列入纯 LVLM-based 的 VLN-R1 / StreamVLN 在 VLN-CE 的最新数字,无法看清 graph-based vs LVLM-based 在 2025 末的真实差距。考虑到论文 framing 主要在攻击 LVLM 路线,这个 omission 比较显眼。
- 架构 ablation 偷换 metric:用 pretraining score 替代 online performance 来 ablate 架构,理由是相关性强。但相关性强不等于线性映射——0.85% 的 pretrain 差距可能在 online 上是 0% 也可能是 3%,不能直接外推。
可信评估
Artifact 可获取性
- 代码: 已开源(https://github.com/Cepillar/ETP-R1,inference + training 都有,README 提供 setup 与 checkpoint 下载)
- 模型权重: 仓库提供下载(具体 ckpt 名称见 README,含 VLN-CE 和 RxR-CE 两个最终模型)
- 训练细节: 较完整——给出了网络层数、隐藏维度、GRPO 超参 (μ=1, β=0.04, ε=0.2, G=8)、数据切分 (90/10)、reward 公式;但 SFT 的 expert probability 、optimizer / lr / batch size 未在正文披露
- 数据集: 公开(R2R / RxR / Prevalent / RxR-Marky 都是公开数据;Prevalent_Gemini_Aug 通过 Gemini API 重新标注,未明确说明是否会 release 这份标注数据——若不放出,复现需要自己花 API 成本重跑)
Claim 可验证性
- ✅ VLN-CE / RxR-CE 上的 SOTA 数字:标准 benchmark + 公开代码 + 公开数据,可独立验证。
- ✅ GRPO 配置 ablation(dropout 必要、temperature 有害、on-policy 最优):表 III 数字明确,开源代码可复现。
- ⚠️ “Closed-loop RFT 首次应用到 graph-based VLN”:这个 “first” 在 graph-based VLN 范畴内基本成立,但 RL on VLN-CE 早有 Krantz 2021,论文用 “graph-based VLN model” 限定后才严格成立——读者需注意 framing 的精细范围。
- ⚠️ “Gemini 数据降低 hallucination”:定性 figure 3 给了示例,但没有定量 hallucination 率测量(例如人工标注准确率),只能从 SAP 准确率间接推断。
- ⚠️ “DPFT 优于 LXMERT”:只与 ablation 中去掉 Text-Guided 的版本(即纯 symmetric fusion)对比,未与原始 LXMERT 直接对照,scaling 策略(unshared weights)的归因不严。
Notes
- 方法学价值:对正在做 VLA 或 navigation 的人,最值得借鉴的不是 DPFT 架构,而是三阶段训练范式 + GRPO 工程细节(dropout 必须开、strict on-policy)。这套范式可以平移到 manipulation 类任务,只要 high-level action space 离散且 episode reward 易计算。
- 对 LVLM-based VLN 的反思:ETP-R1 的成功 implicit 在质疑 “什么都用 LVLM” 的趋势——当任务有清晰的几何/拓扑结构时,专用表征 + 小模型 + RL 可能比硬塞进 LVLM 更高效。这与 LH-VLN 等长程 VLN 工作可以对照阅读,看 LVLM vs graph 的 trade-off。
- 疑问留待复现验证:dropout-as-exploration 的解释是否能 transfer 到其他 GRPO 任务?如果在 LLM RL 训练里也开高 dropout 是否同样收益?这是个值得在自己实验里验一刀的小 hypothesis。
- 数据 release 问题:Prevalent_Gemini_Aug 是这篇工作可复用价值最高的部分(1M 高质量 VLN 指令),但 README 暂未明确说会 release 标注数据本身。若不放出,复现 cost 会很高。
Rating
Metrics (as of 2026-04-24): citation=0, influential=0 (0%), velocity=0.00/mo; HF upvotes=0; github 25⭐ / forks=0 / 90d commits=0 / pushed 120d ago
分数:2 - Frontier 理由:graph-based VLN-CE 上首次系统化 closed-loop GRPO 的工作,在 VLN-CE / RxR-CE 双 benchmark 刷到新 SOTA(Test Unseen +6 SR over G3D-LF),按 framing 会被后续 graph-based VLN + RL 研究当作 baseline 引用,符合 Frontier 档定位。够不到 Foundation 的原因是:Strengths 里明确承认核心贡献是 “scaling + GRPO 的成熟组合搬到 graph-based VLN”——DPFT 是 LXMERT 小改、三阶段是 NLP 成熟流程、GRPO 直接用现成算法,没有范式级原创性;且论文仅 2025-12 arXiv preprint 未见引用和社区采纳信号。不落到 Archived 的原因是方法确实给 graph-based VLN 的 RFT 工程 playbook(dropout / 温度 / on-policy 三条 finding)和 Gemini-aug 数据 ablation 留下了可迁移 insight。2026-04 复核:发布 4 个月 citation=0/影响力=0、github 25⭐ 且近 90 天无提交,early signal 偏弱;按 <3 个月豁免的延伸(此处 4mo 边缘),绝对 citation 暂不足以降档,方法/framing 仍值得作为方向 baseline 参考,维持 Frontier。