Summary
Robot-R1: Reinforcement Learning for Enhanced Embodied Reasoning in Robotics
- 核心: 用 RL(GRPO)训练 LVLM 通过显式 reasoning 预测 robot 下一个 keypoint state,把这个 next-state prediction 重新表述为多选题以缩小动作空间
- 方法: 三类 MCQA 任务(waypoint / current-state / movement prediction)+ 元数据条件输入 + DeepSeek-R1 风格的
<think>/<answer>格式 reward + GRPO 优化- 结果: Qwen2.5-VL-7B 在 Robot-R1 Bench 上低层控制 reasoning 超过 GPT-4o;EmbodiedBench Manipulation +31%;SpatialRGPT 量化 +40% / 质化 +60%;SFT baselines 在迁移任务上崩盘
- Sources: paper
- Rating: 2 - Frontier(R1 范式在 embodied reasoning 上的 early attempt,MCQA reformulation + SFT/RL 对比完整,但 no real-robot、no code、训练 task 少,后续 Embodied-R1 已部分超越)
Key Takeaways:
- MCQA reformulation 是关键:连续 keypoint 空间下做 RL exploration 困难,把它离散化为 4 选项 MCQA + rule-based exact-match reward,让 RL signal 变得可学;ablation 显示 open-ended L1 reward 在加入辅助任务后会崩
- Auxiliary tasks 提供 grounding:current-state 与 movement prediction 两个辅助 QA 改善 visual-state grounding,使主任务的 reasoning 有可信的中间表征
- RL 显著优于 SFT 的可迁移性:Direct/CoT SFT 在 EmbodiedBench 上跌到 0%(catastrophic forgetting),同样数据 RL 后还能涨;与 DeepSeek-R1 在 math 上的发现一致
- Robotic reasoning 反而越训越短:与 math/coding 中 reasoning chain 越来越长的趋势相反,Robot-R1 的 reasoning 随训练逐渐缩短并聚焦——一个有意思的 domain-specific observation
- 新 Bench 是 contribution 之一:Robot-R1 Bench (215 个开放式 QA, 4 类 reasoning, GPT-4o-as-judge, Pearson ≈ 0.9 与 human 一致除 planning)
Teaser. Robot-R1 framework 概览
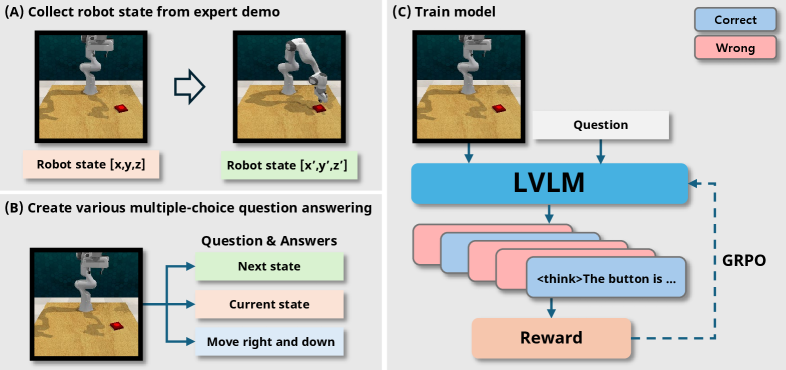
左:从 expert demonstrations 提取 (observation, state, keypoint);中:reformulate 成三类 MCQA(next state / current state / movement);右:GRPO 训练 LVLM 生成
<think>...</think><answer>...</answer>,answer 命中正确选项给 reward。
1. 问题背景
LVLM 用于机器人控制的 SFT 路线(用 embodied reasoning QA 做 fine-tuning)存在两个核心问题:
- 数据启发式构造:SFT 数据集里的 reasoning 范式是人工拍脑袋的,不一定真的对下一步 action 预测有用;语言描述也很难捕捉 low-level 控制需要的精确数值
- Catastrophic forgetting:SFT 对 input/output format 敏感,一旦在 OOD 上跑就崩,连 base model 已有的 conversational ability 都会丢
DeepSeek-R1 在 math/code 上展示了 RL 能 elicit reasoning 并显著优于 SFT 的泛化性,作者把这个范式搬到 embodied reasoning。
❓ DeepSeek-R1 用 verifiable reward (math 答案对错) 起作用的核心条件是 reward 可靠且 dense enough。本文用 MCQA 4 选 1 + exact match 也是 verifiable,但 reward 是 1/4 baseline 的 noisy signal,能否真的产生 generalizable reasoning 而非 shortcut?后面 ablation 部分回答了一些(auxiliary tasks 必要、open-ended L1 reward 不行)。
2. Method
2.1 Preliminaries
- Robot state: Franka Panda,7-D 向量 (xyz, rpy, gripper);为简化只用 (x, y, z) 作为
- GRPO:每个 query 采 个 response,组内归一化算 advantage ,目标函数:
其中 。
2.2 Data Generation
从 RLBench 的 expert demos 抽数据,关键设计是 metadata :
- 固定参考点(如桌面中心)
- 3D 坐标系正方向
- 一个稳定存在物体(如 end-effector)的尺寸做 scale reference
没有 这种 grounding,LVLM 几乎无法把图像里的位置和数值 state 对上。三类 MCQA:
- Waypoint prediction: 给 和 4 个候选 state(其中一个是 ,其余 random distractor),选正确 next keypoint
- Current state prediction: 给 和 4 个候选 state,选
- Movement prediction: 给 和 4 个文字 movement option(“move up” / “slightly move backward” 等),选与 主方向匹配的
❓ Distractor 是从 valid state space “随机采样” 的,难度取决于采样分布。如果 distractor 太远(容易被排除),4 选 1 就退化成接近 visual-state grounding 任务而非真正的 spatial reasoning。论文未说明 distractor 难度控制,这可能是把 7B 模型推到 GPT-4o 之上的隐藏因素之一。
2.3 RL Training
DeepSeek-R1-Zero 风格:policy 输出 <think>...</think><answer>...</answer>,reward :
- : format 合规
- : rule-based exact-match 选项命中
训练用 EasyR1 框架,Qwen2.5-VL-7B-Instruct base,bs=128, 5 epochs, 5 samples/prompt, T=1.0, rollout bs=512, lr=1e-6。
2.4 Robot-R1 Bench
新 benchmark 设计动机:现有 VQA bench 不评估 robot-specific reasoning;现有 robotics bench 只看 task success 不评估 reasoning。
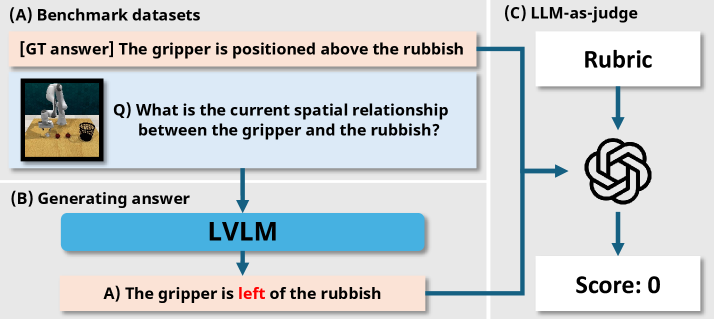
Bench 流程:人类专家围绕 demo 图像写问题与参考答案 → 被测 LVLM 看图答题 → GPT-4o 按 rubric 与参考答案打 [0,3] 分。
- 数据:RLBench 10 tasks × 5 frames = 50 images
- 题目:215 个开放式 QA,研究者手写 question + reference answer
- 4 类 reasoning: planning / high-level action / movement / spatial(前两为高层,后两为低层)
- 打分:GPT-4o-as-judge,按 rubric 给 [0, 3] 分
3. Experiments
3.1 训练数据
5 个 RLBench tasks(pick_up_cup, push_button, put_rubbish_in_bin, phone_on_base, take_lid_off_saucepan),每 task 50 demos,frame interval ,约 7.5K QA 跨三类任务。
3.2 Baselines
- Direct SFT: 直接 fit
- CoT SFT: 输入里塞一个手工 CoT 模板(planning → high-level action → movement → 输出)
3.3 Robot-R1 Bench 主结果
Table 1. Low-level control reasoning(Movement / Spatial)
| Model | Movement Avg | Spatial Avg |
|---|---|---|
| GPT-4o | 0.72 | 1.43 |
| Claude-3.7-Sonnet | 0.62 | 1.40 |
| Gemini-2.0-Flash | 0.46 | 1.49 |
| Qwen2.5-VL-7B-Ins | 0.58 | 1.40 |
| w/ Direct SFT | 0.06 | 0.06 |
| w/ CoT SFT | 0.70 | 0.29 |
| w/ Robot-R1 (Ours) | 0.76 | 1.51 |
7B Robot-R1 在低层控制 reasoning 上全面超过商业大模型;Direct SFT 几乎全崩;CoT SFT 在 movement 上勉强能跟,但 spatial 暴跌——说明 CoT SFT 学到的是 narrow pattern,无法迁移到训练 prompt 之外的 spatial task。
Table 2. High-level reasoning
| Model | Planning | High-level Action |
|---|---|---|
| GPT-4o | 1.96 | 2.02 |
| Qwen2.5-VL-7B-Ins | 1.66 | 1.04 |
| w/ Robot-R1 (Ours) | 1.44 | 1.30 |
Planning 反而略降——作者归因为训练目标只看 next keypoint 而非长程;High-level Action 涨了但仍不及 GPT-4o。
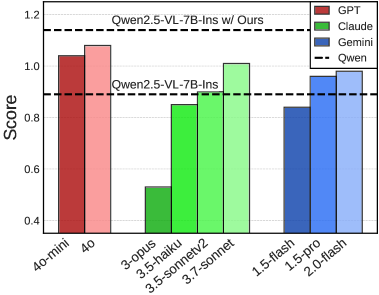
Figure 3 可视化:低层控制 reasoning 上 Robot-R1 系统性领先 commercial models。
3.4 EmbodiedBench Manipulation(迁移)
Vision-driven agent benchmark,要求模型直接输出 7-D action 完成 manipulation。
| Model | Avg Success Rate |
|---|---|
| Qwen2.5-VL-7B-Ins | 8.92 |
| w/ Direct SFT | 0 |
| w/ CoT SFT | 0 |
| w/ Robot-R1 (Ours) | 11.68 |
SFT 直接归零(catastrophic forgetting + format mismatch);Robot-R1 在 base 类别上几乎翻倍(6.3 → 12.5),Visual 类别 11.1 → 16.7。绝对数值仍很低,但相对趋势对比清晰。
3.5 SpatialRGPT-Bench(OOD spatial reasoning)
| Model | Quant. Avg | Qual. Avg |
|---|---|---|
| Qwen2.5-VL-7B-Ins | 9.88 | 29.07 |
| w/ Direct SFT | 8.41 | 5.02 |
| w/ CoT SFT | 7.88 | 35.62 |
| w/ Robot-R1 (Ours) | 15.89 | 40.79 |
最有说服力的迁移:训练数据完全没有 SpatialRGPT 风格 QA,Robot-R1 仍能在 quant 涨 60%、qual 涨 40%;SFT 在 quant 上甚至比 base 还低。
3.6 Ablation
RL 算法:GRPO ≈ RLOO > REINFORCE++(后者 batch-level reward 归一化方差大,学习不稳)。
QA design(Table 9):
- Open-ended + L1 reward 单任务勉强可用,加 auxiliary 反而崩
- MCQA + 全部三类辅助任务最优(Movement 0.76 / Spatial 1.51 / High-level 1.30)
Reasoning length 演化:与 DeepSeek-R1 在 math 上 reasoning 越来越长的趋势相反——Robot-R1 reasoning 越训越短、越聚焦。作者解释:robotic decision 不需要长链 derivation,关键是把 spatial cue → action component 直接对上。
Bench 可信度:人 vs GPT-4o judge Pearson ≈ 0.9(除 planning ≈ 0.33,因为 planning 答案开放性大)。
关联工作
基于
- DeepSeek-R1: 本文直接借
<think>/<answer>格式 + RL with rule-based reward 的 paradigm - GRPO (DeepSeekMath): 核心优化算法
- ARM (Action Mode Repository): 用其 waypoint extraction 与 demonstration augmentation
- RLBench: 训练数据 + 部分评测环境
对比 / 同期
- 2502-EmbodiedBench: 本文用作迁移评测的 benchmark
- Embodied-R / Embodied-R1: 同期 / 后续 R1-style embodied reasoning 工作(grounding-as-action 等更彻底的 RL 形式)
方法相关
- Qwen2.5-VL-7B-Instruct: base model
- SpatialRGPT-Bench: 用作 OOD spatial reasoning 评测
- EasyR1: 训练框架
论文点评
Strengths
- Reformulation 很 clean:把 continuous next-state prediction → discrete MCQA,规避 RL 在大动作空间下 exploration 失败的问题,是简洁有效的工程化决策;这是从 DeepSeek-R1 借 paradigm 后做的关键 domain adaptation
- SFT vs RL 对比完整:Direct SFT / CoT SFT 两种 baseline + 三个 benchmark(in-distribution Robot-R1 Bench, manipulation transfer EmbodiedBench, OOD spatial SpatialRGPT),故事讲完整了——RL 不只是 in-domain 涨点,迁移性才是 SFT 的根本短板
- Reasoning length 反向演化的观察有价值:robotic reasoning 越训越短、越聚焦,与 math reasoning 的扩张相反,提示 reasoning chain 长度由任务结构决定而非训练范式决定
- Bench 验证有 human study:Pearson ≈ 0.9 给 GPT-4o-as-judge 一定可信度,且作者诚实指出 planning 题相关性低(0.33),不掩盖弱点
Weaknesses
- 训练 task 数量很小:5 个 RLBench tasks × 50 demos = 7.5K QA,规模上比 SimplerEnv / OXE 等差几个量级。Bench 也是 RLBench 内 10 tasks 50 frames,in-distribution 评估占主,泛化结论需要更多 task diversity 支撑
- No real-robot results:纯模拟环境(RLBench / EmbodiedBench Manipulation 也基于 RLBench)。SpatialRGPT 是 RGB QA 不是 robot control。声明的 “embodied reasoning for robot control” 在真机上是否成立完全没验
- Distractor 难度未控制:MCQA 的 distractor 是 “随机采样” 自 valid state space,没有 hard negative mining 或难度分层。可能模型学到的是 “排除明显不合理的 state” 而非细粒度 spatial reasoning
- EmbodiedBench 绝对成功率仍很低(11.68%),相对涨幅大但远未到可用水平;与商业模型(Claude-3.5-Haiku 13.6%)比甚至略低
- Reward 设计简单到可能过拟合:format reward + exact-match answer reward,没有任何 process reward 或 partial credit。RL 实际上只是把 4 选 1 多选题 verifiable reward 做到位——能否真的 elicit reasoning 而非 answer guessing 仍存疑
- 与 Embodied-R1 (2508.13998) 的关系未讨论:后续工作(同名 R1 范式)已用 grounding-as-action 做更彻底的 RL embodied reasoning,本文作为 early attempt 提示的方向已被 follow-up 部分超越
可信评估
Artifact 可获取性
- 代码: 未开源(论文未提供 github,作者主页也无项目页链接)
- 模型权重: 未发布
- 训练细节: 仅高层描述(base model, bs, lr, GRPO 超参提到但训练步数、distractor 采样细节、reward shape 完整定义未充分披露)
- 数据集: Robot-R1 Bench 215 题未说明是否发布;训练数据基于公开 RLBench 可重建
Claim 可验证性
- ✅ Robot-R1 在 Robot-R1 Bench 上 outperform SFT 与 GPT-4o:表 2/3 数值清晰,bench 题虽未公开但同源评测下相对比较可信
- ✅ GRPO ≈ RLOO > REINFORCE++:表 7 ablation 直接,与社区共识一致
- ✅ Reasoning length 越训越短:定性 + appendix 例子支持,可信
- ⚠️ EmbodiedBench Manipulation +31%:相对涨幅大但绝对仍低(11.68%),且 SFT baselines 全 0 让对比看起来夸张;与 Claude-3.5-Haiku 对比仅持平
- ⚠️ SpatialRGPT 上 Robot-R1 大幅超过 SFT:SFT baselines 在 quant 上比 base 还低,说明 SFT 在 OOD 上确实垮,但这部分对比不能直接换算成 “Robot-R1 spatial reasoning 强”——只能说 RL 没破坏 base 能力且小有增益
- ⚠️ “7B 超越 GPT-4o”:仅在 Robot-R1 Bench 的低层控制子集上成立,high-level reasoning 仍输 GPT-4o;标题级 claim 容易被读者过度泛化
- ❌ 无明显 marketing 话术
Notes
- 这篇是 NeurIPS 2025 接收,定位是 “把 R1 范式搬进 embodied reasoning” 的早期工作。核心贡献不是某个 SOTA 数字而是 MCQA reformulation 让 RL 在 robot keypoint 预测上能跑起来 这个 design pattern。
- 后续 Embodied-R1 等工作把类似思路推得更远(直接做 grounding/trajectory 而非 MCQA),本文更适合作为 “为什么 SFT 在 embodied reasoning 上不行 + 怎么把 R1 范式适配到 robotics” 的 reference。
- Reasoning length 越训越短的现象值得追踪——若在更多 robotic RL 工作中复现,可能说明 reasoning chain 长度是任务”决定推理深度上限”的产物,而非训练能放大的 capacity。
- 没有真机、没有 code、训练 task 很少、distractor 设计不严——单看作 building block 不够格,作为 indexed reference 合适。
Rating
Metrics (as of 2026-04-24): citation=17, influential=1 (5.9%), velocity=1.57/mo; HF upvotes=29; github=N/A (无代码仓库)
分数:2 - Frontier 理由:R1-paradigm 在 embodied reasoning 上的早期代表工作(NeurIPS 2025 接收),Strengths 里的 MCQA reformulation + 完整 SFT/RL 对比 是当前 embodied-RL 前沿需要比较的 baseline 之一,且提出了 Robot-R1 Bench 这个针对 robot reasoning 的评测设计。不够 3 是因为:no real-robot、no code、训练 task 仅 5 个(见 Weaknesses 1-2),且 Embodied-R1 等后续工作已用 grounding-as-action 推得更远(见 Weakness 6),本身不具备 foundation 级的奠基性或社区 de facto 地位。不降到 1 是因为作为 “R1 范式如何适配 robotics” 的 design pattern reference 仍在方向前沿被引用。