Summary
EmbodiedBench
- 核心: 一个把 MLLM-as-embodied-agent 评测拆成 high/low-level × 6-capability 的细粒度 benchmark;24 个模型、4 个环境、1128 个任务全部用统一 vision-driven agent pipeline 跑过一遍
- 方法: 4 个环境(EB-ALFRED / EB-Habitat 高层;EB-Navigation / EB-Manipulation 低层)+ 6 个能力子集(Base / Common Sense / Complex Instruction / Spatial Awareness / Visual Appearance / Long Horizon);统一 planner pipeline(visual desc → reflection → reasoning → language plan → executable plan,输出 JSON,多步规划)
- 结果: 最强模型 GPT-4o 在 EB-Manipulation 平均仅 28.9%;high-level 任务上去掉 vision 几乎无影响(甚至更好),low-level 任务去 vision 掉 40–70%;long-horizon 是最难子集;InternVL3-78B 是开源最强、在低层上贴近 GPT-4o
- Sources: paper | website | github
- Rating: 2 - Frontier(ICML 2025 Oral、覆盖 24 模型 × 4 环境 × 6 能力的 fine-grained MLLM embodied agent benchmark,正被后续工作采纳为参考;但尚未成为 de facto 标准)
Key Takeaways:
- Action-level taxonomy 是关键:把 MLLM agent 评测按”动作粒度”分成 high-level(skill 级)和 low-level(XYZ+rpy 级)才能暴露当前 MLLM 的真实瓶颈——前者主要是文本任务,后者才真正考验 vision
- Vision 在 high-level 任务上几乎无用:GPT-4o (Lang) 在 EB-ALFRED / EB-Habitat 与有视觉的 GPT-4o 持平甚至略高(58.0 vs 56.3, 56.0 vs 59.0)。这是个对 “MLLM agent benchmark” 的根本性提醒——很多所谓 “MLLM agent” 评测其实可能不需要 vision
- Long-horizon 是最一致的 failure mode:跨 4 个环境、跨模型规模、跨开源/闭源都是 base→long 跌幅最大的 subset
- Low-level manipulation 很难解:即便加了 action discretization (100 bins for xyz, 120 for rpy) 和 YOLO detection box + index marker,GPT-4o 也只到 28.9%;planner error (44%) + perception error (33%) 是主因
- Multi-step / multi-view image 不 work:当前 MLLM 加历史帧或多视角反而掉点——这是个独立的 capability gap
Teaser. EmbodiedBench overview:4 环境 × 2 action level × 6 capability subsets

1. Motivation 与问题定位
现有 LLM-based embodied agent 评测(AgentBench、Lota-bench、Embodied Agent Interface)大多 text-only 或仅评 high-level planning;唯一覆盖 MLLM 的 VisualAgentBench 也只评 high-level,留下两个根本问题没回答:
- vision 在 embodied tasks 里到底起多大作用?
- MLLM 在 low-level navigation/manipulation 上的真实水平?
我的看法:这两个问题的提法本身就有 taste。一个 MLLM agent benchmark 如果不能 ablate “去掉 vision 性能掉多少”,那它评的可能是 LLM agent 而不是 MLLM agent。这篇论文的最有价值发现就是把这件事量化了。
与同类 benchmark 的定位差异(Table 1):
| Benchmark | Action Level | Env | Tasks | Multimodal | Fine-grained | LLM/VLM Support |
|---|---|---|---|---|---|---|
| ALFWorld | High | 1 | 274 | × | × | × |
| Alfred | High | 1 | 3062 | ✓ | × | × |
| VLMbench | Low | 1 | 4760 | ✓ | × | × |
| Behavior-1K | High | 1 | 1000 | ✓ | × | × |
| AgentBench | High | 8 | 1091 | × | × | ✓ |
| Lota-bench | High | 2 | 308 | × | × | ✓ |
| VisualAgentBench | High | 5 | 746 | ✓ | × | ✓ |
| Embodied Agent Interface | High | 2 | 438 | × | ✓ | ✓ |
| VLABench | Low | 1 | 100 | ✓ | ✓ | ✓ |
| EmbodiedBench | High & Low | 4 | 1128 | ✓ | ✓ | ✓ |
唯一同时勾上 multimodal + fine-grained + 跨 action level 的 benchmark。
2. EmbodiedBench 设计
2.1 Action Level 形式化
- Low-level:直接可执行的 atomic command。机械臂 7-D 动作 ,或 “move forward 0.1 m” 这种 kinematic 映射明确的指令
- High-level:可分解为 low-level primitive 的 macro action 。例如 “find a HandTowel” 实际是 rotate→scan→move 的序列
这个区分本身没啥新意,但它逼出了一个有价值的实验设计:同一套 capability subsets 在两种 action level 下都跑一遍,才能看出 vision 的真正贡献。
Vision-driven agent 被建模为带 language instruction 的 POMDP ,每步基于 history 选 action。
2.2 四个环境
| Env | Source | Action Level | Tasks | Action Space |
|---|---|---|---|---|
| EB-ALFRED | ALFRED + AI2-THOR (基于 Lota-Bench) | High | 300 | 8 skill types × objects (动态 171–298 actions) |
| EB-Habitat | Language Rearrangement + Habitat 2.0 | High | 300 | 70 high-level skills(nav 限制到 receptacle) |
| EB-Navigation | AI2-THOR | Low | 300 | 8 atomic: move ±x/±y, rotate ±θ, tilt ±φ |
| EB-Manipulation | VLMBench + CoppeliaSim (Franka 7-DoF) | Low | 228 | 7-D 离散化(位置 100 bins、姿态 120 bins) |
关键工程选择:
- EB-ALFRED 修了 Lota-Bench 的 3 个 bug(不支持多实例、put-down 错放、指令质量差),把 7 个 ALFRED task type 都补全
- EB-Manipulation 做了两个非平凡 enhancement:
- Action space discretization:把连续 xyz 切成 100 bins、姿态切成 120 bins,让 MLLM 输出 integer
- YOLO detection box + index marker + 3D pose:把”精确 3D 定位”问题降为”指 index”问题
- EB-Navigation 仅给 validity feedback(无定位数据),符合真实机器人约束
2.3 六个 Capability-Oriented Subsets
| Subset | 评测能力 | 例子 |
|---|---|---|
| Base | 基础任务规划 | ”Put washed lettuce in the refrigerator” |
| Common Sense | 用常识间接指代物体 | ”a receptacle that can keep food fresh for several days” |
| Complex Instruction | 长 context(含无关信息)下抽取意图 | 加一段背景描述包裹核心指令 |
| Spatial Awareness | 用相对位置指代物体 | ”the cabinet under the sink against the wall” |
| Visual Appearance | 用视觉属性指代物体 | ”a knife in a blue container” |
| Long Horizon | 步数 >15 的任务 | ”pick up knife, slice apple, put knife in bowl, heat…” |
❓ Spatial Awareness 在 EB-Navigation 缺失、Long Horizon 在 EB-Manipulation 缺失,作者归因为 “design challenges”。这其实暴露了 capability 与 environment 的耦合——Spatial 在 navigation 里和 base 难以区分(每个导航任务本身就是 spatial),Long-horizon 在 15-step 上限的 manipulation 里塞不下。要小心解读这种 grid 不规则导致的 cross-env 比较。
数据收集:EB-ALFRED / EB-Manipulation 用人工 + GPT-4o augmentation;EB-Habitat 复用 Language Rearrangement 子集;EB-Navigation 全 Python 程序生成。
2.4 统一 Vision-Driven Agent Pipeline
Figure 2. EmbodiedBench 的 vision-driven agent pipeline。

输入:language instruction + 当前帧(或 sliding window 的多帧)+ in-context demos + interaction history + task-specific info(high-level 任务给 valid skill set;EB-Manipulation 给 action format + detection box + 3D coords)。
Planner 每步五段输出(JSON 结构):
- textual description of current visual input
- reflection on past actions + env feedback
- reasoning about goal
- language plan
- executable plan in required format
关键设计:multi-step planning(一次输出多个 action)而不是 prior work 的 one-action-per-timestep。优点:(1) 与 ICL examples 对齐;(2) 减少冗余规划——尤其在 low-level 任务里单 action 视觉变化小,省 API 调用。Planner 失败或动作 invalid 就 restart from latest state。
这个 multi-step 选择是合理的。EB-Manipulation 上 GPT-4o 的 avg planner steps = 2.6 而 env steps = 12.9,相当于减了近 80% 的 LLM call——对评测大量 proprietary models 是 cost-saving 的工程决策。但也意味着 planner 对自己的”批量预测”长度有信心,这本身可能 bias 评测——某些模型可能因为不敢输出长动作链而被低估。
3. 核心实验结果
24 个模型:8 proprietary(GPT-4o, GPT-4o-mini, Claude-3.5/3.7-Sonnet, Gemini-1.5-Pro/Flash, Gemini-2.0-Flash, Qwen-VL-Max)+ 16 open-source(InternVL2.5/3, Qwen2/2.5-VL, Llama-3.2-Vision, Gemma-3, Ovis2, 7B–90B 规模)。统一温度 0、max tokens 2048、resolution 500×500、max env steps 30/20/15。
3.1 High-Level Tasks(EB-ALFRED + EB-Habitat)
Table 2. Task success rate, EB-ALFRED 和 EB-Habitat 各 6 子集(Lang = 去掉 vision input)。
| Model | ALFRED Avg | ALFRED Long | Habitat Avg | Habitat Long |
|---|---|---|---|---|
| Claude-3.7-Sonnet | 67.7 | 70 | 58.7 | 46 |
| Claude-3.5-Sonnet | 64.0 | 52 | 68.0 | 58 |
| Gemini-1.5-Pro | 62.3 | 58 | 56.3 | 52 |
| GPT-4o | 56.3 | 54 | 59.0 | 64 |
| GPT-4o (Lang) | 58.0 | 54 | 56.0 | 36 |
| GPT-4o-mini | 24.0 | 0 | 32.7 | 14 |
| GPT-4o-mini (Lang) | 31.3 | 14 | 36.7 | 14 |
| InternVL3-78B | 39.0 | 36 | 55.0 | 40 |
| Qwen2.5-VL-72B-Ins | 39.7 | 34 | 37.7 | 18 |
| Llama-3.2-90B-Vision | 32.0 | 16 | 40.3 | 14 |
关键观察:
- GPT-4o (Lang) 比 GPT-4o vision 还好(58.0 vs 56.3 on ALFRED;56.0 vs 59.0 on Habitat 接近持平)。GPT-4o-mini (Lang) 同样如此(31.3 vs 24.0 on ALFRED)。这说明 ALFRED-style high-level 任务的瓶颈在 reasoning/planning,不在 vision
- Claude-3.7 和 Claude-3.5 互有胜负;3.7 强 ALFRED、3.5 强 Habitat
- 开源最强 InternVL3-78B(Habitat 55.0)已逼近部分 proprietary
3.2 Low-Level Tasks(EB-Navigation + EB-Manipulation)
Table 3. Task success rate, EB-Navigation 5 子集、EB-Manipulation 5 子集。
| Model | Nav Avg | Nav Long | Man Avg | Man Spatial |
|---|---|---|---|---|
| GPT-4o | 57.7 | 55.0 | 28.9 | 25.0 |
| Claude-3.7-Sonnet | 45.0 | 26.7 | 28.5 | 20.8 |
| Claude-3.5-Sonnet | 44.7 | 26.7 | 25.4 | 22.9 |
| Gemini-1.5-Pro | 24.3 | 20.0 | 21.1 | 35.4 |
| GPT-4o (Lang) | 17.4 | 0.0 | 16.2 | 14.6 |
| GPT-4o-mini (Lang) | 8.3 | 0.0 | 6.6 | 14.6 |
| InternVL3-78B | 53.7 | 31.7 | 26.3 | 31.3 |
| Ovis2-34B | 45.7 | 11.7 | 26.8 | 31.3 |
| Qwen2.5-VL-72B-Ins | 40.0 | 33.3 | 16.2 | 18.8 |
关键观察(与 high-level 形成强烈反差):
- GPT-4o → GPT-4o (Lang):EB-Navigation 从 57.7 掉到 17.4(−40.3 pt),long-horizon 从 55.0 → 0.0。EB-Manipulation 从 28.9 掉到 16.2(−12.7 pt)
- vision input 对 low-level 任务是 critical——这是 high-level 和 low-level 评测最重要的分水岭
- Open-source InternVL3-78B(53.7 / 26.3)已追平 GPT-4o 在 navigation/manipulation 上的水平。low-level 是开源 catching up 最快的方向
- EB-Manipulation 整体仍很差:最好 28.9% 平均成功率,绝大多数模型 <20%
3.3 Fine-grained Cross-Subset 观察
- 不同模型擅长不同 subset:Claude-3.5 整体强于 GPT-4o on Habitat (68 vs 59),但 long-horizon 上 GPT-4o (64) > Claude-3.5 (58)。Claude-3.5 在 EB-Manipulation complex/visual 子集分别比 GPT-4o 高 14.6/5.6 pt,但其他 capability 上落后。aggregate score 隐藏了 capability-level 的真实差异——这是 fine-grained eval 的核心价值
- Long-Horizon 是最一致的瓶颈:每个环境下都是 base→long 跌幅最大。Claude-3.5 on Habitat: base 96 → long 58(−38 pt);GPT-4o on Habitat: base 86 → long 64(−22 pt)
4. Ablation Studies
4.1 Language-Centric Ablations on EB-ALFRED
Figure 4. Language-centric ablations.

- 去掉 environment feedback:GPT-4o 掉 10 pt,Claude-3.5 掉 8 pt
- In-context examples 数量:默认 10 shots,降到 0-shot 成功率掉到 ~40%
结合 vision-removal 几乎无影响的事实,这进一步说明 high-level 任务的信号量主要在 textual prompt(feedback + ICL examples)里。high-level embodied benchmark 设计如果 textual scaffolding 太重,等于在评 LLM 的 text-prompted planning 能力。
4.2 Visual-Centric Ablations on EB-Manipulation
Figure 5. Visual-centric ablations on EB-Manipulation。(a) camera resolution, (b) detection boxes, (c) multi-step images, (d) visual ICL。
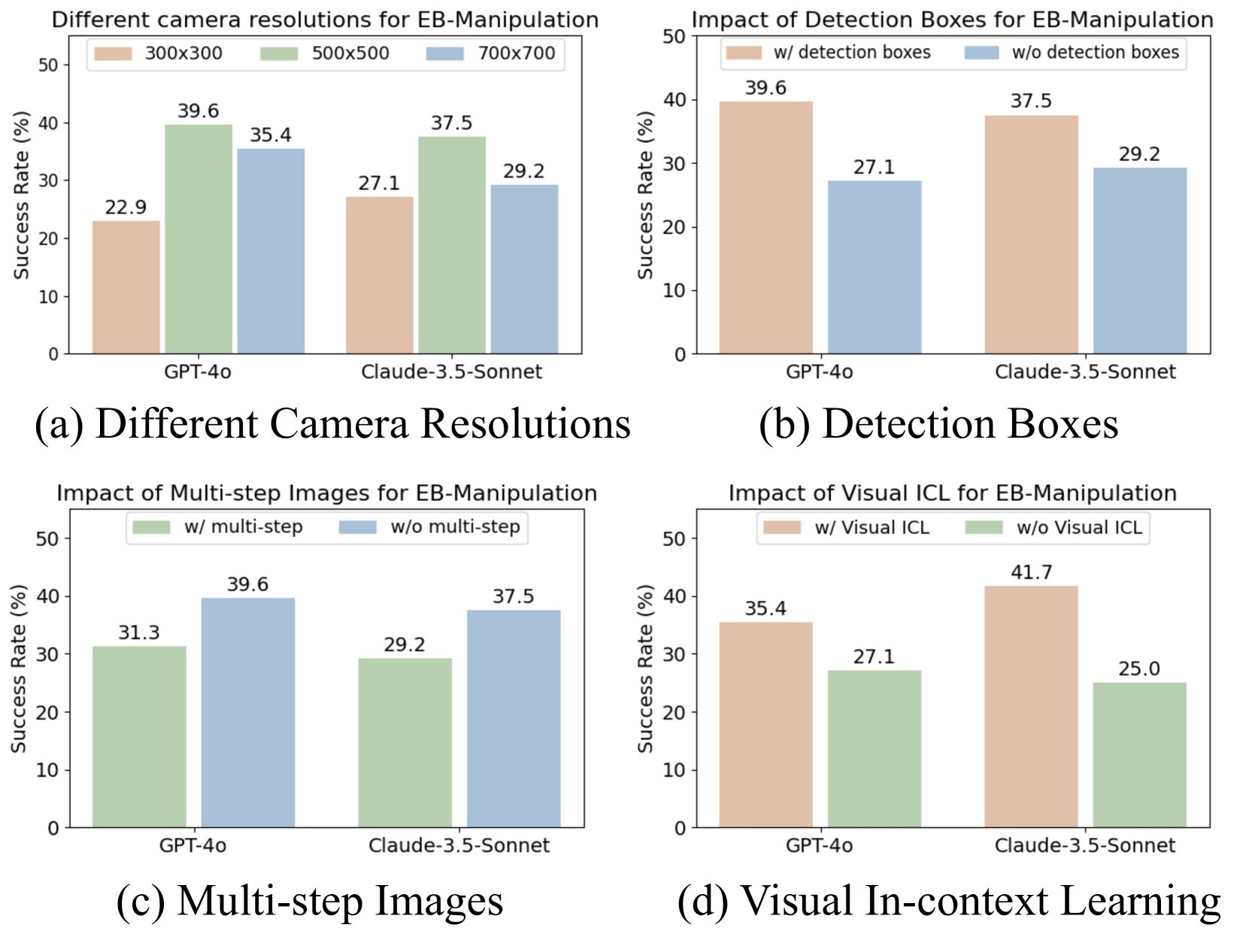
- (a) Resolution:mid-range 500×500 最好;300×300 缺细节、700×700 反而更差(增加无关 token,分散注意力)
- (b) Detection boxes:去掉 detection box,GPT-4o 39.6 → 27.1(−12.5 pt),Claude-3.5 37.5 → 29.2(−8.3 pt)。说明现阶段 MLLM 还没强到能裸眼 grounding 3D 物体位置
- (c) Multi-step image:加历史 2 帧反而掉点。MLLM 难以正确建模”我之前在哪、现在在哪”的时序关系
- (d) Visual ICL:把图像也加入 in-context examples,Claude-3.5 涨 16.7 pt(虽然 N=2 vs 默认 text ICL N=10 的对比有 confound,方向性结论仍可信)
EB-Navigation 的 detection box 反例(Table 9):multi-box 反而 hurts(GPT-4o:no-box 61.7、one-box 68.3、multi-box 53.3)。多 box 在导航场景遮挡了关键视觉路径线索。结论:visual augmentation 必须 task-tailored,无脑加不一定 work。
4.3 Multi-View Images
front-view + top-down (Nav) 或 front-view + wrist-view (Man) 的双视角输入 — GPT-4o 整体掉点。说明现阶段 MLLM 多视角 fusion 能力不足。
5. Error Analysis(GPT-4o 110 个失败 episode)
Figure 6. Error analysis on GPT-4o failures across EB-ALFRED 和 EB-Manipulation。

| 环境 | Planning | Reasoning | Perception |
|---|---|---|---|
| EB-ALFRED (high-level) | 55% | 41% | 4% |
| EB-Manipulation (low-level) | 44% | — | 33% |
- EB-ALFRED:planning errors 主导,其中 missing steps (23%) 和 invalid actions (22%) 最多;reflection errors (17%) 表明 GPT-4o 经常没意识到自己之前规划失误;wrong termination (13%) 是过早判断任务完成
- EB-Manipulation:perception errors 显著上升到 33%(即便有 detection box 标注),其中 wrong recognition (22%) 最多——对 GPT-4o 来说,“看见 box” 不等于 “看懂 box 里是什么颜色/形状”
这是个有信息量的 finding。perception error 在低层任务上的占比说明:当前 MLLM 即便配上 grounding scaffold(detection box),底层 visual recognition 仍是 manipulation 失败的主因。这给 VLA 训练数据组成、low-level vision encoder 的预训练目标提供了直接证据。
项目主页放出的 EB-Manipulation 与 EB-Navigation 成功 rollout 示例(GPT-4o 驱动):
关联工作
基于
- ALFRED + AI2-THOR:EB-ALFRED / EB-Navigation 都基于 AI2-THOR 模拟器
- Lota-Bench:EB-ALFRED 直接基于其 8 高层 skill 实现,并修了三个 bug
- Language Rearrangement (Habitat 2.0):EB-Habitat 来源
- VLMBench (CoppeliaSim + Franka):EB-Manipulation 扩展
对比
- AgentBench / Lota-Bench / Embodied Agent Interface:text-only 或不支持 multimodal,本工作补全 MLLM 评测
- VisualAgentBench:第一个 MLLM agent benchmark,但只 high-level;本工作扩到 low-level + capability subsets
- VLABench:focus 在 VLA 评测(端到端 policy),本工作 focus MLLM-as-planner(输出离散 action)
- EmbodiedEval(concurrent work):覆盖 nav + object interaction + social + QA,但无 low-level manipulation、规模仅 328
方法相关
- Action discretization:把连续 7-D action 离散到 integer bin —— 与 RT-2、OpenVLA 等 VLA 工作的 action tokenization 思路同源
- Visual marker / detection box prompting:用 YOLO + index marker 让 MLLM 输出”指 index”而非”输出 3D 坐标”——SoM (Set-of-Marks) 类技术的工程化应用
- 后续工作 ERA (2025-10):同组用 EmbodiedBench 数据集训了 reasoning + grounding 增强的 VLM-based embodied agent
论文点评
Strengths
- Coverage 真的全:4 个环境 × 24 个模型 × 6 个 capability subset × 多个 ablation 因子。这种规模的 benchmark 论文很少见有人愿意花成本去跑(proprietary API + 7B–90B 开源 local)
- Action-level taxonomy 是个 useful axis:清晰区分 high-level skill agent 和 low-level control agent 的评测,第一次量化了”vision 在 high-level 任务里其实可有可无”这件事
- Capability-oriented subsets 暴露了 aggregate 隐藏的差异:Claude-3.5 vs GPT-4o 在不同 subset 上互有胜负,这种 nuance 是单一 score 看不到的
- 多个工程决策非常负责:multi-step planning 节省 ~80% LLM call、action discretization 让 MLLM 输出 integer、detection box + index marker 把”3D 定位”降级为”指标号”——这些都是 reproducibility-friendly 的细节
- Negative result 也报:multi-step image 不 work、multi-view 不 work、navigation 上 multi-box 不 work——这些反结论比正向 SOTA 有信息量
Weaknesses
- 仍然是 simulation-only:作者自己也承认。AI2-THOR / Habitat / CoppeliaSim 与真实机器人的 perception/dynamics gap 不小,benchmark 上的相对排序未必转移到 real-world
- Capability subset 的”正交性”存疑:Common Sense 和 Complex Instruction 在某些任务里区分度不大(都是改写指令),缺少 cross-subset 的相关性分析
- Capability × env 的 grid 不规则:EB-Navigation 缺 Spatial、EB-Manipulation 缺 Long-Horizon,cross-env 的 capability 分数无法直接平均比较
- Pipeline 是固定的:所有模型用同一个 5-stage JSON planner pipeline。对某些模型(如 chain-of-thought 不擅长 JSON 的)可能不公平。Lack of “best-effort per-model prompt tuning” 限制了结果的 ceiling 解读
- 没有训练实验:纯 evaluation。EB-ALFRED / EB-Habitat 给出的 trajectory 数据集本可以用来 fine-tune 当 baseline——这部分 README 显示后续 (2025-06) 才补 trajectory dataset、(2025-10) 才有 ERA training recipe,主文未涉及
- Vision-removal 结论的 confound:去掉 vision 时高层任务”几乎无影响”——但 in-context examples 是 text 形式,可能补足了 vision 的信号。如果同时去 ICL examples,结论可能不同
可信评估
Artifact 可获取性
- 代码:开源(github.com/EmbodiedBench/EmbodiedBench),inference + evaluation
- 模型权重:N/A(本工作不训模型,纯评测)。后续 (2025-10) 发布的 ERA 是单独的 training recipe
- 训练细节:未说明(本工作不训模型)
- 数据集:开源(HuggingFace EmbodiedBench org),含 EB-ALFRED / EB-Manipulation 数据,以及多模型 trajectory 数据集(2025-06 释出)
Claim 可验证性
- ✅ 24 模型在 4 环境上的 success rate 表格:所有数据可由 codebase 复现,prompt 固定 temperature=0
- ✅ Vision removal 实验:GPT-4o (Lang) vs GPT-4o 的对比是 controlled,结论清晰
- ✅ Long-horizon 是最难子集:跨模型一致性强,证据充分
- ⚠️ “InternVL3-78B 接近 GPT-4o on low-level”:依赖 single-run;MLLM agent 评测的 variance 不小(虽 temperature=0 但环境 stochasticity 存在)。多 seed 验证未报
- ⚠️ Visual ICL +16.7 pt for Claude-3.5:N=2 visual ICL vs N=10 text ICL 的对比并非 apples-to-apples(数量不同),方向正确但 magnitude 可能 inflated
- ⚠️ “Detection box 在 navigation 里 hurts”:仅在 GPT-4o + Claude-3.5 上验证(Table 9),未跨开源模型确认
Notes
- 这篇是评测论文里态度比较诚实的一篇——不光报 SOTA 排名,还报了 vision-ablation、multi-step image fail、multi-view fail 这些”对 MLLM 不利”的结论。这种 negative result 友好的 benchmark 才有长期价值
- 对我个人最 useful 的两个 takeaway:(1) MLLM agent benchmark 必须 ablate vision,否则可能在评 LLM agent;(2) low-level manipulation 上 perception error 占 33%,detection box 也救不回来——意味着想做 MLLM-as-planner-for-manipulation 的方向,要么换更强的 visual encoder(DINOv2/SigLIP-2 量级),要么干脆走 end-to-end VLA
- 后续值得跟进:ERA (2510.12693) 是同组的 training recipe,用 EmbodiedBench 作为 training/eval 平台,可以看 fine-tuning 能把 28.9% manipulation 推到多少
- ❓ EB-Manipulation 的 28.9% ceiling 在哪?是 MLLM reasoning 不够还是 visual perception 不够?错误分析里 perception 33% + planning 44%,意味着即便 perception 完全修好,理论上限也只能到 ~70%——这个数字本身值得跟踪
- ❓ Multi-step image / multi-view 失败是 MLLM training data 问题(缺多帧/多视角理解数据)还是 model arch 问题(attention 在多 image 上分散)?这是后续工作可以拆开的
Rating
Metrics (as of 2026-04-24): citation=128, influential=11 (8.6%), velocity=8.95/mo; HF upvotes=35; github 293⭐ / forks=32 / 90d commits=11 / pushed 9d ago
分数:2 - Frontier 理由:ICML 2025 Oral、同时具备 multimodal + fine-grained + high/low-level 两种 action-level 覆盖的唯一 embodied MLLM benchmark(见”与同类 benchmark 的定位差异”表),且有 24 模型 × 4 环境的规模证据。其 fine-grained capability subsets 和 vision-ablation 协议已被后续 ERA 等工作作为训练/评测平台采纳,但尚未达到 ImageNet / DROID 级的 de facto 标准(社区里 VLMBench、EmbodiedEval 等竞争者并存),仍处 Frontier 而非 Foundation;同时 simulation-only、grid 不规则等 Weaknesses 限制了它升档的证据强度。2026-04 复核:citation=128 / velocity=8.95/mo、influential 比例 8.6%(接近典型 ~10%)、github 仍在维护(90d 11 commits、pushed 9d)且 HF 35 upvotes,表明社区采纳仍在积累但尚未进入 Foundation 级必引行列,维持 Frontier。