Summary
Rethinking the Embodied Gap in Vision-and-Language Navigation
- 核心: 现有 VLN 模型在”理想伪运动 + 单一智能体”假设下训练,迁移到带物理控制器的多具身机器人时性能崩盘。VLN-PE 是第一个系统量化这一 embodied gap 的物理仿真平台与 benchmark。
- 方法: 基于 GRUTopia/Isaac Sim 搭建支持 humanoid (H1)/quadruped (Aliengo)/wheeled (Jetbot) 的物理 VLN 平台;评测 3 类 ego-centric pipeline——分类式 (Seq2Seq/CMA/NaVid)、扩散式 waypoint (新提出的 RDP)、map-based zero-shot LLM (改进 VLMaps);引入 GRU-VLN10 (合成场景) 与 3DGS-Lab-VLN 数据集,新增 Fall Rate / Stuck Rate 指标。
- 结果: VLN-CE → VLN-PE 零样本 SR 相对掉 34%;NaVid 在低光下 SR 掉 12%、在 3DGS 场景几乎完全失效 (5.81 SR);跨具身 co-training 让一个 6M 参数的 small baseline 在 R2R 上反超 7B 的 NaVid。
- Sources: paper | website | github
- Rating: 2 - Frontier(第一个系统量化 VLN embodied gap 的 physical benchmark,且已被 InternRobotics/InternNav 采纳为 navigation foundation model 的 cross-embodiment 训练数据源;尚未定型为 community 标准)
Key Takeaways:
- Pseudo-motion → physical 迁移代价巨大: 在 Habitat 上跑得好的 SoTA 直接搬到带 RL locomotion controller 的 H1 humanoid,SR 相对下降 34%(NaVid 从 ~40 掉到 22.42 on val-unseen);这把”VLN-CE 已经接近真实”这种叙事直接证伪。
- Camera height 是决定性变量: 把 CMA 的相机调到 1.8m (CMA-Height1.8) 就能恢复一部分零样本性能;quadruped (~0.5m) 视角让模型几近完全失效,说明现有 VLN 模型隐式 overfit 到 MP3D 默认 1.2-1.6m 视高。
- 多模态融合 ≠ 锦上添花,是抗光照退化的必需: 纯 RGB 的 NaVid 在低光 DL300 下 SR 掉 12.47,RGB+D 的 CMA/RDP 几乎不退;3DGS 渲染噪声让 NaVid 直接崩到 5.81 SR——MLLM 对像素级 perturbation 极其敏感。
- One-for-All cross-embodiment 可行: 用 humanoid+quadruped+wheeled 三类数据 co-train 单个 CMA,在所有具身上都达到 (或接近) 各自的最佳,且训练数据量越大收益越线性——给跨具身 navigation foundation model 提供了第一份 controlled evidence。
- Controller-in-the-loop 数据采集是 legged robot 的必需品: 训练数据 + 评测都用 RL controller 时性能最高且 FR/StR 最低;mismatch 时性能崩盘——意味着 legged VLN 不能简单复用 graph-based pseudo trajectories。
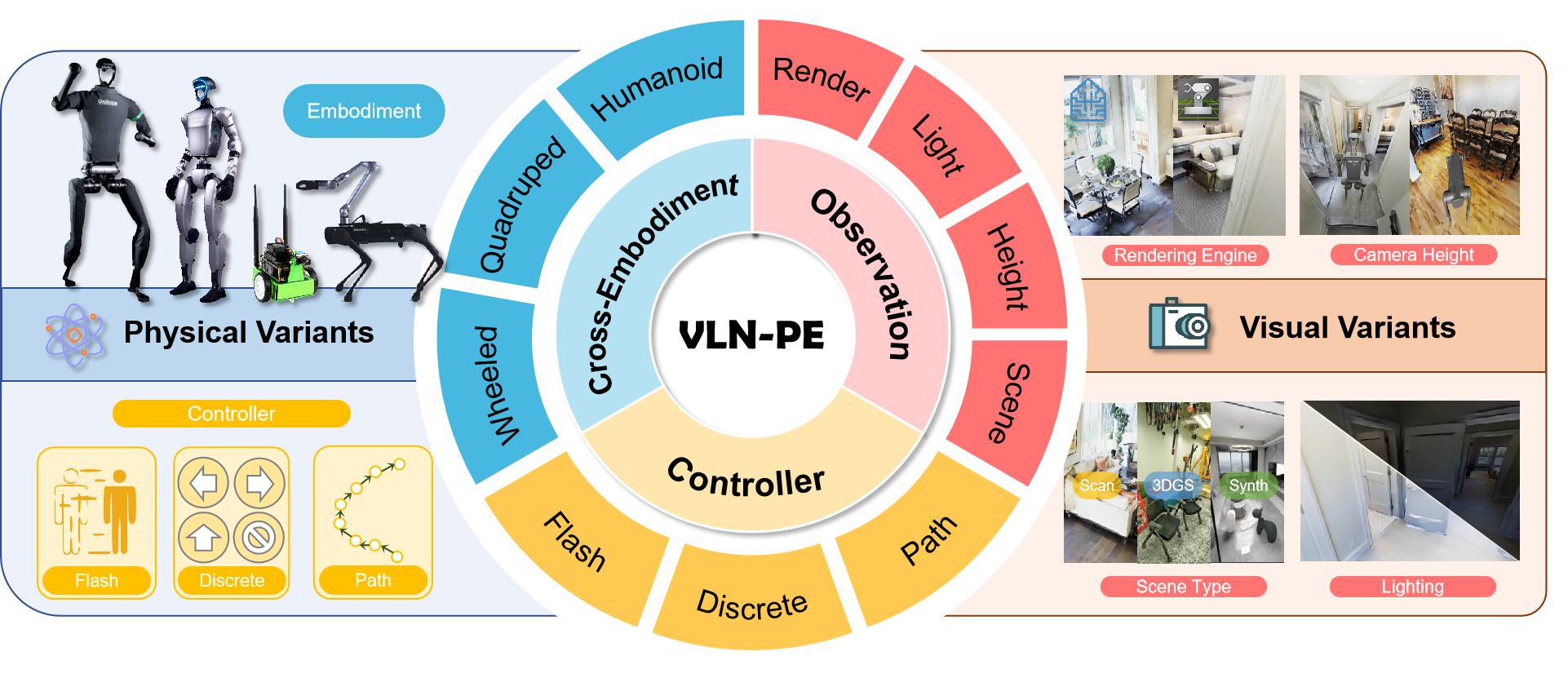
Teaser. VLN-PE 概览:覆盖 humanoid/quadruped/wheeled 三类机器人,集成 MP3D + GRU-VLN10 合成场景 + 3DGS 扫描场景,支持物理控制器与多种光照条件下的端到端评测。
VLN 演化与 embodied gap 的提出
VLN 从最初 MP3D 上节点跳跃式 navigation,演化到 VLN-CE 的连续动作 (Habitat),再到本文主张的 physical VLN。作者指出:当前所有 VLN-CE benchmark 都把 agent 当成理想 wheeled 或 point-based mover,忽略机器人本体的物理约束——视角高度差异、跌倒、卡死、运动误差。这导致一个具体的开放问题:“To what extent do physical embodiment constraints and visual environmental variations impact existing VLN methods?”——之前没有任何系统性研究回答过。
Figure 1. VLN 任务的 evolution——从离散节点到 VLN-CE 再到 VLN-PE 的物理仿真。

VLN-PE 平台设计
仿真基座与场景
- 基座: GRUTopia (NVIDIA Isaac Sim),提供 RL-based locomotion controller 作为 API,支持 Unitree H1/G1 (humanoid)、Aliengo (quadruped)、Jetbot (wheeled)。
- MP3D 移植: 90 个 MP3D 场景转 USD 格式,手工补洞(reconstruction error 导致地板裂缝会让 legged robot 卡死/跌入)。坐标对齐 VLN-CE 原始 annotation。Disk lighting 提供可调光强。
- 新增场景:
- GRU-VLN10: 10 个高质量合成 home scene (来自 GRScenes),弥补 MP3D 视觉多样性不足。
- 3DGS-Lab-VLN: 一个 3DGS 扫描的实验室场景,online rendering,用来测试模型对 3DGS 渲染 artifact 的鲁棒性。
❓ MP3D 补洞这步只在论文中一句带过——这种手工修复对 reproducibility 是隐患,原始 USD 转换 + 修复 patch 是否随代码发布?
Figure 2. VLN-PE 架构图——研究者可无缝接入新机器人 / 新场景。

数据集
- R2R 适配: 因为 RL locomotion controller 处理楼梯不稳,作者过滤掉所有含楼梯的 episode,剩 train/val-seen/val-unseen = 8,679 / 658 / 1,347。
- GRU-VLN10: 441 / 111 / 1,287 episodes,3 个训练场景 + 7 个 unseen 测试场景。
- 3DGS-Lab-VLN: 160 train + 640 eval。
- 指令生成: 基于 modular LLM pipeline(action recognition + environment recognition + GPT-4 in-context description + 人工 refine)。
❓ 过滤楼梯 episode 让 SR 数字不再可直接和 VLN-CE 文献对比——一个公平的”VLN-CE on filtered split”baseline 应该单独报告。
指标:除经典 5 项外引入 FR/StR
- 标准: TL / NE / SR / OS / SPL
- 新增:
- Fall Rate (FR): roll > 15° 或 pitch > 35° 或 CoM-to-foot 高度低于 robot-specific 阈值
- Stuck Rate (StR): 50 步内 position 变化 < 0.2m 且 heading < 15°
这两个 metric 是 VLN-PE 的关键贡献之一——把”会不会摔 / 会不会卡”从 pure 动作级 success 中分离出来。
Locomotion Controllers (3 种)
- Flash Control: 瞬移到目标位置,无物理约束(模拟无 cross-embodiment 支持的旧平台)
- Move-by-Speed Control: RL policy 控制 legged robot 速度;wheeled 用 differential drive
- Move-along-Path Control: A* + PID,主要给 VLMaps 用
Baselines
3 类 pipeline,覆盖了 ego-centric VLN 主流方法:
- End-to-end single-step 分类: Seq2Seq、CMA (~36M params)、NaVid (7B, video MLLM)
- End-to-end multi-step 连续 waypoint: RDP (作者新提出的 Recurrent Diffusion Policy)
- Train-free map-based: 改进版 VLMaps + VLFM frontier exploration + room-level CLIP classifier
RDP: 第一个用于 VLN 的 diffusion policy
把 diffusion policy 从 manipulation/local navigation 推到 VLN,关键设计:
- RGB + instruction 用 LongCLIP 编码(标准 CLIP 77 token 限制不够),depth 用 ResNet50(与 CMA 一致)
- 历史信息用 GRU 维护——作者尝试过 NaVid-style 视频帧堆叠,但 diffusion loss 收敛过快导致严重 overfit
- Cross-attention 双向对齐 vision/language
- Stop prediction head: 一个独立 MLP 输出 0→1 的 stop progress,解决 diffusion model 不擅长基于语言决定何时停的问题
- 训练损失:
其中 λ=10。每次预测 8 个未来 waypoint,执行 4 步后重新规划。
Figure 3. RDP 框架图。

实验
Q1: VLN-CE 模型迁移到 VLN-PE 表现如何?
Table 1. R2R + Humanoid H1 + RL controller 上的全面对比 (节选关键行)。
| Idx | Method | Val-Unseen SR ↑ | FR ↓ | StR ↓ |
|---|---|---|---|---|
| 2 | Seq2Seq-Full (zero-shot) | 15.00 | 13.88 | 3.79 |
| 3 | CMA-Full (zero-shot) | 16.04 | 15.07 | 4.31 |
| 6 | NaVid 7B (zero-shot) | 22.42 | 8.61 | 0.45 |
| 7 | Seq2Seq (in-domain trained) | 15.89 | 19.67 | 3.71 |
| 8 | CMA (in-domain trained) | 18.78 | 18.63 | 3.12 |
| 9 | RDP (in-domain trained) | 21.98 | 18.75 | 4.58 |
| 11 | CMA+ (fine-tuned) | 23.31 | 18.63 | 4.83 |
| 12 | VLMaps* (zero-shot) | 20.00 | 23.00 | 0.00 |
关键发现:
- 三个 zero-shot 模型 SR 分别相对掉 ~10/16/18 个点;整体 34% 相对下降(abstract 数字)
- NaVid 因 MLLM world knowledge 表现出最低 FR/StR——但作者指出 70% episode 里 NaVid 在目标附近反复转 25+ 步才停,反映 MLLM 对精确 stop signal 仍弱
- 用 VLN-PE-collected 数据 fine-tune CMA(CMA+, 36M params)后 val-seen SR 28.72,反超 NaVid 7B 的 21.58——说明 SoTA 大模型严重 overfit Habitat 训练分布
- RDP from scratch 也超过 CMA from scratch——diffusion policy for VLN 是有前景的方向
Figure 4. Humanoid H1 上的 zero-shot 性能下降可视化。

Q2: Out-of-MP3D-domain (GRU-VLN10 + 3DGS-Lab-VLN)
Table 2. GRU-VLN10 评测——441 episode fine-tune 即可让 small model 反超 NaVid zero-shot。
| Method | Val-Unseen SR | SPL |
|---|---|---|
| NaVid (ZS) | 18.64 | 13.99 |
| CMA-CLIP w/o FT | 15.31 | 13.12 |
| CMA-CLIP | 22.46 | 17.93 |
| RDP w/o FT | 26.19 | 18.70 |
| RDP | 28.52 | 22.53 |
Table 3. 3DGS-Lab-VLN——NaVid 完全失效。
| Method | SR ↑ | SPL ↑ |
|---|---|---|
| NaVid (ZS) | 5.81 | 1.00 |
| CMA-CLIP | 24.88 | 17.43 |
| RDP | 30.63 | 22.69 |
3DGS rendering 引入人眼看不见但模型敏感的像素扰动 → RGB-only MLLM 直接失效。这是对 “vision foundation model 对 distribution shift 鲁棒” 这种叙事的直接打脸。
Q3: Physical Controller Engagement
Table 4. CMA from scratch,数据采集 / 评测 是否带 RL locomotion controller 的 2×2 实验。
| Collect w/ loco | Eval w/ loco | Val-Unseen SR | FR | StR |
|---|---|---|---|---|
| ✗ | ✗ | 21.31 | 0.00 | 0.00 |
| ✓ | ✗ | 15.90 | 0.00 | 0.00 |
| ✗ | ✓ | 13.51 | 25.69 | 4.75 |
| ✓ | ✓ | 18.78 | 18.63 | 3.12 |
核心结论:train-eval controller 一致时性能最高;mismatch 时显著掉分。controller-aware 数据收集对 legged robot 是 essential。
Q4: Cross-Embodiment Co-Training (One-for-All)
Table 5. CMA 在不同训练数据组合下的性能(val-unseen 节选)。
| Robot | Training Data | OS | SR | SPL |
|---|---|---|---|---|
| Humanoid | VLN-CE only | 19.82 | 16.04 | 14.63 |
| Humanoid | Humanoid only | 31.33 | 18.78 | 14.56 |
| Humanoid | All 3 robots | 31.70 | 19.30 | 16.97 |
| Humanoid | VLN-CE + 3 bots | 34.08 | 26.87 | 23.54 |
| Quadruped | VLN-CE only | 7.84 | 4.73 | 3.80 |
| Quadruped | Quadruped only | 32.37 | 17.00 | 13.40 |
| Quadruped | VLN-CE + 3 bots | 29.62 | 23.83 | 20.75 |
| Wheeled | VLN-CE only | 13.75 | 11.02 | 10.80 |
| Wheeled | VLN-CE + 3 bots | 22.71 | 20.02 | 19.38 |
- Quadruped (~0.5m camera) 直接 zero-shot 几乎完全失败 (SR 4.73)
- 跨具身 co-training 在所有 3 类机器人上都给出最佳结果——multi-view learning + 数据量提升的双重收益
- 这是 VLA / cross-embodiment foundation model 在 navigation 场景的第一份 controlled evidence,比 manipulation 上的 cross-embodiment 工作 (RT-X 等) 更直接对应实际硬件部署
Figure 5. NaVid 在不同机器人平台上的性能差异。

Q5: Lighting Conditions
Table 6. NaVid 单 RGB 受光照影响远大于 RGB+D 的 CMA/RDP。
| Method | Light | Val-Unseen SR | SPL |
|---|---|---|---|
| NaVid | DL5000 | 22.42 | 18.58 |
| NaVid | DL300 | 9.95 | 9.01 |
| NaVid | CL | 11.17 | 9.34 |
| CMA | DL5000 | 18.78 | 14.56 |
| CMA | DL300 | 17.37 | 15.34 |
| RDP | DL5000 | 21.98 | 16.44 |
| RDP | DL300 | 22.27 | 17.15 |
Figure 6. 不同光照条件下的环境对比。

Sim-to-Real 验证 (Appendix B)
Unitree Go2 + Intel RealSense D455,14 个室内 episode:
| Method | Fine-tuned on VLN-PE | OS ↑ | SR ↑ |
|---|---|---|---|
| CMA (Full) | ✗ | 14.29 | 7.14 |
| CMA | ✓ | 57.14 | 28.57 |
VLN-PE fine-tune 在真实 Unitree Go2 上把 SR 从 7.14 提到 28.57——给”sim2real via physically realistic sim”提供了正向证据。但 14 episode 样本量很小,需要更大规模验证。
关联工作
基于
- GRUTopia (Wang et al., 2024): VLN-PE 的仿真基座,提供 Isaac Sim + RL controller 集成
- VLN-CE (Krantz et al., 2020): continuous VLN benchmark 的前身,本文证明其物理 idealization 不充分
- VLMaps: train-free map-based baseline,本文做了 frontier exploration + room-level classifier 的改进
- NaVid: 7B video MLLM baseline,本文揭示其在物理设置下的局限
对比
- NaVILA: 同样针对 legged robot 的 VLA,但走的是 VLM + locomotion 双系统路线,与 VLN-PE 的 ego-centric 单系统评测可互补
- VLNav / VLN-R1 / StreamVLN / LH-VLN: 同期 VLN 工作;VLN-PE 提供的 cross-embodiment + physical controller benchmark 可作为它们的 stress test
- EfficientVLN: 后续 VLN 效率优化工作,可在 VLN-PE 上重新评测
方法相关
- Diffusion Policy (Chi et al., 2023): RDP 的方法基础,本文是 diffusion policy 在 VLN 的首次系统应用
- NavDP (Cai et al., 2025): 同样把 diffusion policy + sim-to-real 用在 navigation,但聚焦 point-goal 而非 language-conditioned
- InternVLA-N1 / InternData-N1 (2025): 本文成果已被纳入 InternRobotics 的 navigation foundation model pipeline,VLN-PE 是其 cross-embodiment 训练数据来源之一
论文点评
Strengths
- 第一个系统性把 embodied gap 量化的工作:把 “VLN-CE 已经够真实” 这种 community 假设直接证伪 (34% 相对 SR drop),并把 gap 拆解成 viewpoint height、controller、lighting、3DGS 噪声四个 actionable 维度。
- Cross-embodiment co-training 的 controlled experiment 漂亮:Table 5 的 4×3 grid 是这篇文章最有 reusable 价值的一组数据——在 navigation 场景下证明了 One-for-All 模型的可行性,且揭示了 “VLN-CE pseudo data + 3 robot real data” 的组合最优。
- 新增 FR / StR 指标:把 “成功 vs 摔倒/卡死” 解耦,对 legged robot navigation 是 sensible 且必要的。
- RDP 设计中”stop progress head”细节:诚实指出 diffusion 模型在 VLN 中的 stop signal 难题,并给出工程上的有效解。这种 negative observation + fix 的写法比纯卖方法更可信。
- Real-world 验证 (Appendix B):虽然只有 14 episode,但 7.14 → 28.57 的提升足以支撑 “sim-to-real via physically realistic sim” 的核心 claim。
Weaknesses
- Stair filtering 让 R2R 数字与文献不可直接对比:过滤完楼梯 episode,剩 1,347 val-unseen,所有 SR/SPL 数字与 VLN-CE 原始论文不在同一基准上——一个 “VLN-CE on filtered split” 的 reference 数字必须给出,否则 34% 相对下降的结论可能偏乐观/悲观。
- NaVid 是 zero-shot,CMA/RDP 是 in-domain trained,对比不公平:表 1 把 zero-shot 的 7B NaVid 和 fine-tuned 的 36M CMA+ 比 SR,得出 “small model 反超” 的结论——但前者无 VLN-PE 数据训练,后者有。NaVid 本身的训练代码不开源使作者无法 fair fine-tune NaVid,但应该明确标注这是 fairness limitation。
- MP3D 手工补洞缺失 reproducibility 细节:USD 转换 + hole patch 工作量大且对结果有影响,论文未说明 patch 是否发布。
- 3DGS 失效结论的归因不严:作者把 NaVid 在 3DGS-Lab-VLN 失败归因于 “3DGS rendering noise”,但只有一个场景的数据,且未做 controlled 对比 (e.g., 同场景非 3DGS 渲染 vs 3DGS 渲染)——可能还有场景布局、文化/室内类型 mismatch 等 confounding factor。
- RDP 作为新方法但 ablation 不足:GRU vs video stacking 只有定性描述 (“rapid convergence to small losses, severe overfitting”),没数字。stop head 的 ablation、λ=10 的扫描、8 waypoint / 4 step 频次的选择都缺。
- Locomotion controller 把 stair 排除掉是 fundamental limitation:现实部署不可能避开楼梯,这把 benchmark 的 ecological validity 削弱了一档。
- legged robot 的”摔倒/卡死”是 controller 的问题还是 policy 的问题,没有解耦:FR/StR 既受 high-level VLN policy 影响,也受 low-level RL controller 影响,论文用同一组 controller 对所有方法比较,但没有 ablation 说明 controller 本身的 baseline FR/StR (e.g., follow ground-truth waypoint 时的 FR)。
可信评估
Artifact 可获取性
- 代码: 开源(合并进 InternRobotics/InternNav,含 evaluation 与 training 代码;2025/11 还加了 distributed evaluation 把 full benchmark 从单卡降到 16 GPU 1.6h)
- 模型权重: 提到 InternRobotics/VLN-PE on Hugging Face;具体 checkpoint 列表未在论文正文给出
- 训练细节: 较完整——hardware (4× RTX 4090)、optimizer (AdamW, lr 1e-4)、batch size、训练时长 (CMA 1 day, RDP 2 days)、cosine schedule 都有
- 数据集: GRU-VLN10 + 3DGS-Lab-VLN 公开(论文提及 InternData-N1 包含 2.8k+ VLN-PE episodes,已整合进 LeRobot v2.1 格式)
Claim 可验证性
- ✅ VLN-CE → VLN-PE 34% SR 相对下降:Table 1 表格直接支撑(CMA-Full 16.04 → CMA from scratch 18.78,但 zero-shot transfer 主线对比可见)
- ✅ Cross-embodiment co-training 优于单具身训练:Table 5 4×3 grid 完整数据
- ✅ NaVid 在低光下显著退化、CMA/RDP 稳定:Table 6 数字对比清晰
- ✅ VLN-PE fine-tune 在真实 Go2 上 7.14 → 28.57 SR:Table 7 + Fig 11,但 N=14 episode
- ⚠️ “NaVid 几乎完全失败 in 3DGS” (5.81 SR):归因到 “3DGS rendering noise” 缺乏 controlled experiment——可能也有场景类型 distribution shift 影响
- ⚠️ “6M params small baseline 反超 7B SoTA”:NaVid 是 zero-shot 而 CMA-CLIP 是 fine-tuned,对比不在同一 protocol 下
- ⚠️ “VLN models tend to overfit specific simulation platforms”:基于 1 篇论文的 1 类实验得出的高层 claim,需要更多模型 + 更多平台才能 generalize
Notes
- 可借鉴的 benchmark 设计原则:把 “成功率” 和 “物理可行性” (FR/StR) 解耦,是 evaluation methodology 上值得复用的 pattern——manipulation/VLA benchmark 也应该报告 “task success” vs “safe execution”。
- 对 VLA 的启示:Table 5 cross-embodiment co-training 的 monotonic 收益给 “navigation foundation model is feasible” 提供了 controlled evidence,比 manipulation 域的 RT-X 类工作更干净——manipulation 因为 task 本身的多样性,cross-embodiment 增益常被 task 异质性混淆。
- 3DGS rendering 对 RGB-only MLLM 的影响:如果 sim-to-real 走 3DGS 路线,需要在训练时显式注入 3DGS-style perturbation 做 augmentation——这是个具体的 actionable insight。
- 关于 “small model 反超 SoTA 大模型”:要谨慎解读。fine-tune 36M model 在 in-domain 数据上 vs zero-shot 7B 模型——这只能说 7B 的 NaVid 没在 VLN-PE 数据上训练,不能说 small model 本质上更强。但确实揭示 MLLM 不是万能的——在物理 deploy 场景下,data distribution match 比 model scale 更重要。
- 可能的后续 idea: 把 VLN-PE 的 controller-aware 评测协议扩展到 manipulation——构造一个把 high-level policy 和 low-level controller 解耦的评测,量化 manipulation 类 VLA 的 controller-induced gap。
- 作者后续动向: 论文成果已并入 InternNav/InternVLA-N1 navigation foundation model pipeline,GitHub 维护活跃 (v0.3.0 released 2026/01),是 navigation 方向值得跟踪的 codebase。
Rating
Metrics (as of 2026-04-24): citation=15, influential=0 (0.0%), velocity=1.63/mo; HF upvotes=2; github 826⭐ / forks=111 / 90d commits=10 / pushed 45d ago
分数:2 - Frontier 理由:作为 physical VLN benchmark,这是第一个系统量化 embodied gap 的工作(Strengths 1),把 “VLN-CE 已够真实” 这一 community 叙事直接证伪,且引入的 FR/StR 指标与 cross-embodiment co-training 协议具备 reusable 价值(Strengths 2-3)。达不到 3 - Foundation 的原因:benchmark 尚未成为 VLN 方向的 de facto 标准(同期 VLN-R1/StreamVLN 等仍主要在 VLN-CE 评测),且 stair filtering、3DGS 单场景等 weakness 削弱了 ecological validity;高于 1 - Archived 的原因:成果已被 InternRobotics/InternNav 吸纳为 navigation foundation model 的 cross-embodiment 训练数据源,是 physical VLN 方向的重要参考。