Summary
Embodied-R1: Reinforced Embodied Reasoning for General Robotic Manipulation
- 核心: 把 “pointing” 系统化为 embodiment-agnostic 的中间表示,用 RFT 训一个 3B VLM 来弥合 “seeing-to-doing” 的 gap
- 方法: 定义四种 pointing 能力(REG/RRG/OFG/VTG),构造 Embodied-Points-200K,两阶段 GRPO 训练 + 多任务 reward library;下游接 motion planner 实现 zero-shot 控制
- 结果: 11 个 spatial/pointing benchmark 全 SOTA;SIMPLEREnv 56.2%;xArm 真机 8 任务 zero-shot 87.5%(比 RoboPoint/FSD 提升 60%+)
- Sources: paper | website | github
- Rating: 2 - Frontier(pointing-as-middle-representation + RFT 的 design 哲学扎实,真机 + 多 benchmark 证据完整且完全开源,ICLR 2026 接收;但 8 个月 26 cites / 4 influential (15.4%) + 138⭐ 尚未兑现 Foundation 级 de facto adoption)
Key Takeaways:
- Pointing 作为统一中间表示:把 affordance、target region、visual trace、object reference 全部统一到 image coordinates 上,绕开 VLA 端到端的 “动作空间不匹配” 问题,又避免 modular pipeline 的级联误差
- RFT 解决 “multi-solution dilemma”:embodied pointing 任务(如 “在空地放一个点”)有大量等价解,SFT 强迫拟合单一标签会过拟合,RFT 可以正向强化任意正确解,鼓励学到任务的真实约束
- 3B 打 13B:仅 3B 参数(基于 Qwen2.5-VL-3B-Instruct)在 spatial reasoning 上 rank 2.1,超过 FSD-13B、RoboBrain-7B、RoboPoint-13B
- 真机 + 视觉扰动鲁棒性:87.5% 真机成功率不是 cherry-pick——在背景+灯光+高度同时变化下仍保持 83% grasp 成功率
- 混合训练优于单任务:四个 pointing 能力 joint training 比单独训练在 Part-Afford / Where2Place / VABench-P 上都更高(共享坐标语义对齐先验)
Teaser. Embodied-R1 框架总览:3B VLM 通过 “pointing” 作为中间表示连接高层视觉理解与底层动作原语,在 11 个 benchmark、SIMPLEREnv 仿真和 xArm 真机上展示 zero-shot 泛化。
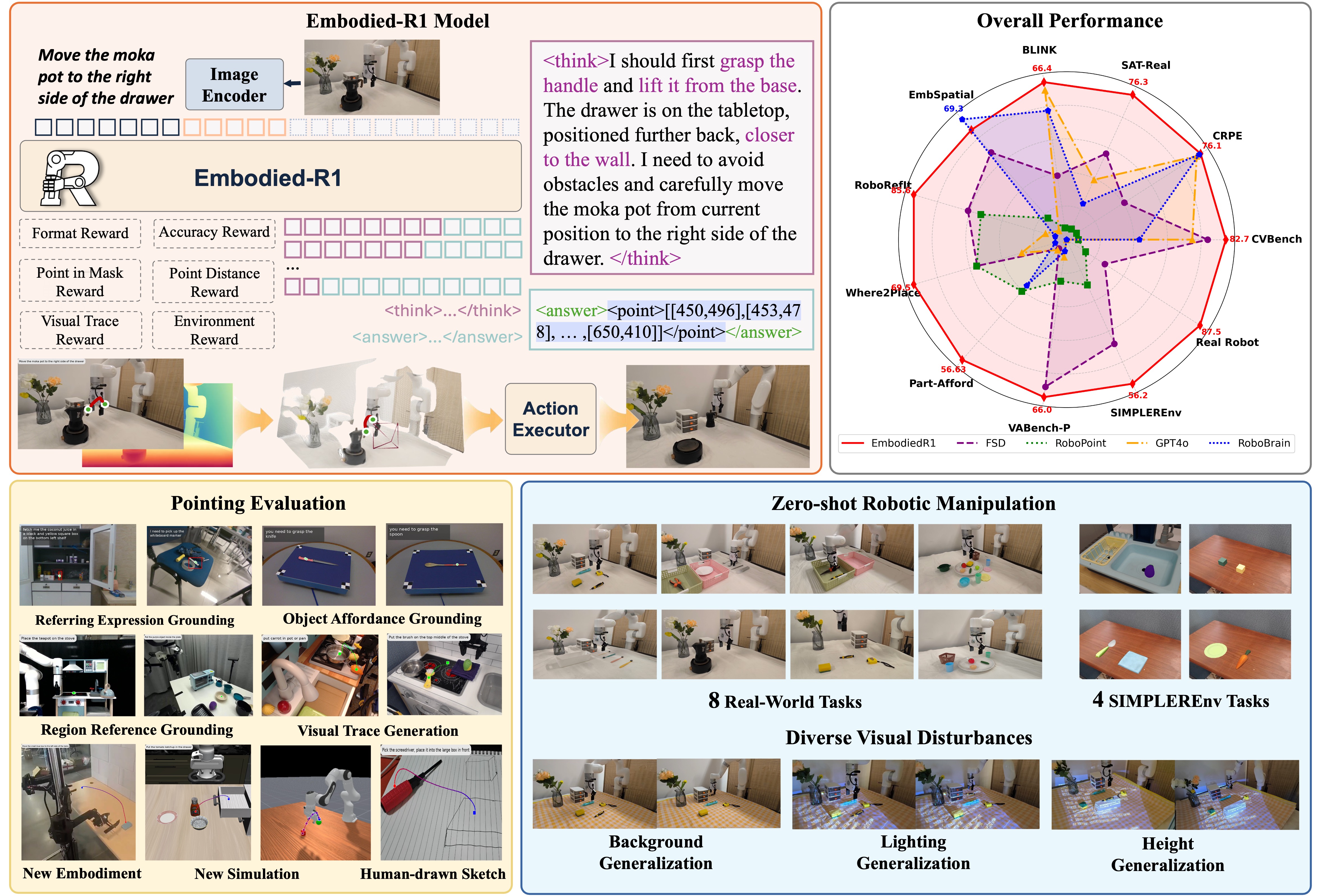
1. Motivation:Seeing-to-Doing Gap
VLA 模型擅长感知和模仿专家轨迹,但在新环境下操作能力急剧退化。作者把这个 “seeing-to-doing gap” 归因于两点:
- Data scarcity:embodied data 不足以把语言/视觉与物理动作充分 grounding
- Embodiment heterogeneity:robot morphology 差异大,跨形态知识迁移困难
现有方案的问题:
- End-to-end VLA(如 π0、OpenVLA):动作空间和预训练数据存在根本性 mismatch
- Modular pipeline(如 MOKA):多模型级联,误差累积
- 现有 pointing 方法:信号过于单一——只输出 affordance point 或 visual trace 或 target region 之一
- FSD 等 reasoning-anchored 方法:用 SFT 学固定 CoT 模板,限制了对新任务的泛化
作者的判断:用 “pointing” 作为统一的中间表示,配合 RFT 学 free-form reasoning,能同时解决数据稀缺(pointing 数据可从 web/sim/real 大规模获取)和 heterogeneity(image coordinate 与机器人形态无关)。
2. 四种 Embodied Pointing 能力
所有能力都输出 image coordinates ,但语义不同:
| 能力 | 全称 | 任务 | 示例 |
|---|---|---|---|
| REG | Referring Expression Grounding | 从语言描述定位物体(点落在 segmentation mask 内) | “the red cup” |
| RRG | Region Referring Grounding | 从关系描述定位空间区域 | ”the space between objects” |
| OFG | Object Functional Grounding | 定位物体的功能部位(affordance) | “where to grasp this knife” |
| VTG | Visual Trace Generation | 输出有序点序列 表示操作轨迹 | object-centric manipulation trajectory |
Figure 2. 四种 embodied pointing 能力概览。

这个抽象的关键 insight:pointing 不是一种新的 “动作”,而是把 “什么物体 / 什么位置 / 什么部位 / 什么轨迹” 全部 collapse 到 2D 像素坐标上——任意机器人都能消费。
3. 数据集:Embodied-Points-200K
整个训练数据分三类:
General + Spatial Reasoning(Stage 1 用)
- Embodied-Spatial-84K:从 SAT 和 WhatsUp 聚合的空间感知数据,统一为 multiple-choice 格式(便于 verifiable reward)
- ViRL-subset-18K:从 ViRL 过滤的通用知识数据,对抗 catastrophic forgetting
Embodied Pointing(Stage 2 用,~200K):刻意采用 “question-verification” 而非 “question-answer” 结构,配合 RFT 解决 multi-solution dilemma。
| 子集 | 数据来源与构造 |
|---|---|
| REG | RefCOCO + RoboRefIt + RoboPoint。把 bbox 监督改为 “point-in-mask” 判定 |
| RRG | 自动 pipeline 处理 ~1M open-source embodied 数据,过滤后得 33K:抽取末帧物体位置 → 计算相对参考物的精确 placement region → 渲染回初始帧 |
| OFG | HandAL 数据集 + GPT-4o 生成功能性问题(如 “切菜时该握刀的哪部分”),40K |
| VTG | object-centric trace:GPT-4o 提物体 → self-supervised keypoint extractor + Grounded-SAM 找抓取点 → CoTracker3 跟踪 → 下采样为 8 个等距点 |
❓ “question-verification” vs “question-answer” 这个区分其实就是把 reward function 接在 verifier 上而非 ground-truth label 上——RFT 框架的标准做法,但作者把它包装成 “解决 multi-solution dilemma” 的核心 design。这个表述强调了语义层面的好处(鼓励 diverse correct answers),而非工程层面的便利。
4. 训练:两阶段 RFT + Multi-task Reward Library
4.1 两阶段 Curriculum
- Stage 1:Embodied-Spatial-84K + ViRL-subset-18K,建立空间推理基础
- Stage 2:Embodied-Points-200K 多任务混合训练四种 pointing 能力
优化算法:GRPO——对每个 prompt 采样多个候选回答,组内归一化算 advantage,clipped surrogate loss 优化。
4.2 Reward Function Library
为了让多任务训练时 simpler task 不主导优化,每个任务的总 reward 都被归一化到 。
Reward 库 :
- Format reward:,强制输出
<think>...</think>和<point>[[...]]</point>结构 - Accuracy reward:(用于 QA)
- Point-in-mask reward:(pointing 任务的 sparse reward)
- Point distance reward(dense auxiliary,加速学习):
其中 , 是 mask 的中心。
- Visual trace reward:先把 和 插值到相同点数,再算 RMSE 转 的 reward。
总 reward 为 ,权重归一化 。例:
这个设计本质是 task-conditioned reward shaping——不同任务用不同 weight 组合从同一个库里挑 reward。简洁,可复用。
5. 部署:两条 Action Pipeline
Embodied-R1 输出的 pointing 信号被两种下游 executor 消费:
- Affordance Points Branch (-P):用 RRG + OFG 预测 grasp 点和 place 点 → 喂给 CuRobo motion planner 生成无碰撞轨迹
- Visual Trace Branch (-V):用 VTG 输出 2D trace → 用 pinhole camera 模型 + 初始 depth 升到 3D → 在 SE(3) 空间插值为连续轨迹(与 FSD 类似)
整套架构允许 Embodied-R1 在任意 stage 起 reasoning,dynamic 地选择需要的 pointing 能力。
6. 实验
6.1 Spatial Reasoning(11 benchmarks)
Table 1. Spatial reasoning 性能对比(节选)。
| Model | CVBench Avg | CRPE Avg | SAT Real | BLINK Avg | EmbSp. Test | Rank |
|---|---|---|---|---|---|---|
| GPT-4o | 79.4 | 75.8 | 57.5 | 65.9 | 49.1 | - |
| FSD-13B | 80.9 | 70.2 | 63.3 | 60.5 | 63.3 | 4.6 |
| RoboBrain-7B | 74.2 | 76.0 | 52.2 | 64.6 | 69.3 | 4.4 |
| Qwen2.5VL-3B | 71.6 | 76.0 | 45.1 | 61.7 | 62.8 | 5.6 |
| Embodied-SFT | 82.1 | 73.3 | 65.5 | 66.3 | 63.1 | 3.7 |
| Embodied-R1 w/o CS | 81.5 | 75.2 | 73.9 | 64.1 | 65.4 | 3.4 |
| Embodied-R1 | 82.7 | 76.1 | 76.3 | 66.4 | 67.4 | 2.1 |
3B 打过 7B/13B,且 RFT vs SFT (Rank 2.1 vs 3.7)、有 CS vs 无 CS (3.4 vs 2.1) 都有可观差距,说明 RFT + 通用知识混入都关键。
6.2 Pointing 能力(4 benchmarks)
Table 2. Pointing 准确率(点落在目标区域的比例)。
| Model | RoboRefit | Where2Place | VABench-P | Part-Afford |
|---|---|---|---|---|
| GPT-4o | 15.28 | 29.06 | 9.30 | 10.15 |
| RoboPoint | 49.82 | 46.01 | 19.09 | 27.60 |
| FSD | 56.73 | 45.81 | 61.82 | 9.55 |
| Qwen2.5VL | 74.90 | 31.11 | 9.89 | 23.42 |
| Embodied-SFT | 83.85 | 41.25 | 50.46 | 40.20 |
| Embodied-R1 | 85.58 | 69.50 | 66.00 | 56.63 |
Table 3. VABench-V(visual trace 评估)。
| Model | RMSE ↓ | MAE ↓ | LLM Score ↑ |
|---|---|---|---|
| GPT-4o | 136.1 | 113.5 | 4.4 |
| RoboBrain | 121.6 | 103.8 | 4.5 |
| FSD | 78.3 | 63.4 | 6.2 |
| Embodied-SFT | 109.4 | 65.2 | 6.2 |
| Embodied-R1 | 77.8 | 45.0 | 7.3 |
Embodied-R1 vs Embodied-SFT 的差距(VABench-V MAE 45 vs 65)尤其大,说明 trace 这类 multi-solution 任务上 RFT 的优势最显著。
6.3 SIMPLEREnv 仿真(WidowX)
Table 4. SIMPLEREnv 4 任务平均成功率。
| 类别 | Model | Avg |
|---|---|---|
| End-to-end VLA | Octo | 26.7 |
| End-to-end VLA | π₀ | 27.1 |
| End-to-end VLA | π₀-fast | 48.3 |
| End-to-end VLA | OpenVLA | 5.2 |
| End-to-end VLA | OpenVLA-OFT | 41.8 |
| End-to-end VLA | ThinkAct | 43.8 |
| End-to-end VLA | Magma | 35.4 |
| Modular | MOKA | 33.3 |
| Modular | Sofar | 53.8 |
| Affordance | RoboPoint | 17.7 |
| Affordance | FSD | 40.6 |
| Pointing + Planner | Embodied-R1 | 56.2 |
6.4 真机:xArm 6,8 个 OOD 任务
零样本部署到第三人称 RealSense L515(640×480)。
Table 5. 真机成功率(节选)。
| Model | Avg Success |
|---|---|
| MOKA | 9.2% |
| RoboPoint | 12.5% |
| FSD | 25.0% |
| Embodied-R1-P | 83.3% |
| Embodied-R1-V | 87.5% |
V branch(visual trace)略优于 P branch(affordance points),作者归因于 trace 的 annotation 更精确。
Figure 5. 真机任务 + 视觉扰动 + OOD 泛化 demo(左:真机操作 snapshots;中:背景/灯光扰动鲁棒性;右:sim/新形态/手绘场景的 VTG zero-shot)。

Video. Task 6 在背景+灯光+高度同时变化下的执行过程(最严苛扰动条件下仍能完成)。
6.5 视觉扰动鲁棒性
Table 7. Embodied-R1 在视觉扰动下的成功率。
| Disturbance | Grasp (%) | Succ. (%) |
|---|---|---|
| Original | 100 | 100 |
| Background Change | 100 | 100 |
| BC + Light Change | 83 | 83 |
| BC + LC + Height Change | 83 | 83 |
背景换不掉,光+高度变化也只掉到 83%。
6.6 关键 Ablation
Table 6. SFT vs RL × Think vs No-Think(在 RRG benchmark 上)。
| RL | Think | Where2Place | VABench-P |
|---|---|---|---|
| ✓ | ✓ | 65.50 | 65.39 |
| ✓ | ✗ | 63.00 | 60.50 |
| ✗ | ✓ | 41.25 | 47.67 |
| ✗ | ✗ | 36.85 | 50.46 |
RL 比 Think 重要得多:在 Where2Place 上 RL 带来 +20+ 分,加 Think 仅再 +2.5 分;SFT 上加 Think 反而几乎没用。这表明 RFT 才是 OOD 泛化的主因,而非 chain-of-thought 本身。
Table 8. 多任务混合训练 vs 单任务训练。
| Benchmark | Mixed | Unmixed |
|---|---|---|
| Part-Afford | 56.63 | 51.25 |
| Where2Place | 69.50 | 65.50 |
| VABench-P | 66.00 | 65.39 |
混合训练全面更好,说明四种 pointing 能力共享了底层的 “坐标-语义对齐” 表示。
关联工作
基于
- Qwen2.5-VL-3B-Instruct:backbone VLM
- GRPO (DeepSeek-Math):RFT 优化算法
- π0 / FSD:FSD 的 spatial reasoning + visual trace 思路启发了本文,Embodied-R1 用 RFT 替代 FSD 的 templated CoT SFT
对比
- End-to-end VLA:Octo, OpenVLA, OpenVLA-OFT, π0, π0-fast, ThinkAct, Magma — 论文核心 baseline,证明 pointing-based reasoning > end-to-end action prediction
- Modular / Affordance:MOKA, Sofar, RoboPoint, FSD — 同类型 pointing/region 方法
- RoboBrain / SpatialVLM:spatial reasoning VLM baseline
- Embodied-SFT:作者自己构造的同 backbone + 同数据 SFT 版本,用于 isolate RFT 贡献
方法相关
- Visual auxiliary signals:keypoints, affordance maps, bounding boxes, optical flow, visual trajectories — 作者把它们统一为 “pointing”
- CoTracker3 / Grounded-SAM / GPT-4o:VTG 数据生成 pipeline 的工具链
- CuRobo:motion planner,Affordance Points Branch 的下游 executor
- R1-style RFT 同期工作:Robot-R1, VLN-R1, ETP-R1, Embodied-R — 同 paradigm 在不同 embodied 任务上的应用
论文点评
Strengths
- Pointing 作为统一抽象的 design 选择有深度:不是简单地把 affordance/region/trace 拼起来,而是观察到它们都能用 image coordinate 表示,进而可以共享一个 reward library 和 backbone。这种 collapse 是 simple+scalable+generalizable 的好例子。
- RFT 解决 multi-solution dilemma 的论证清晰:Table 6 直接拆 RL vs Think 的贡献,证明 RFT 才是泛化主因,而非 CoT 这层包装。这是一个反直觉但重要的结果——很多 R1-style 工作把效果归因于 reasoning chain,这里说明 reward 才是真正起作用的东西。
- 真机评估扎实:8 个 OOD 任务 + 视觉扰动 + 长程/推理/接触三类复杂场景的 qualitative,都不是仿真里跑的 cherry-pick。87.5% vs FSD 25% 这个 gap 比 SIMPLEREnv 上的 56.2 vs 40.6 大得多,说明真机泛化是真的。
- 3B 参数 + 完全开源:模型权重、数据集、训练 + 推理脚本、benchmark 全开源,复现门槛低。
- 可组合性:Embodied-R1 输出的 point 可接 motion planner、impedance controller、Diffusion Policy 等任意下游 executor,证明了中间表示的解耦价值。
Weaknesses
- 依赖外部 motion planner / depth:-P branch 需要 CuRobo + 已知深度,-V branch 也要 pinhole camera + initial depth。“端到端 zero-shot” 的说法略 oversold——真正零样本的是 perception 部分,action 部分依然需要 calibrated camera 和 depth sensor。
- 任务集偏 pick-and-place:8 个真机任务都是 tabletop pick/move/place,没有涉及双手协作、铰接物体、动态环境等更难的 manipulation。Long-horizon 部分依赖 Gemini-2.5-Pro 做 high-level planning,本文模型不直接 hold 这部分能力。
- Reward weight 是 hand-crafted:每个任务的 都是手调的(如 RRG 的 0.1/0.2/0.7),论文没有讨论这些权重对结果的敏感性。多任务 reward shaping 的 generalization 受限于这种 manual tuning。
- VTG 数据生成 pipeline 噪声大:作者自己承认 “using multiple pre-trained vision models in the process inevitably introduces noise”,过滤策略也只是 “rule-based + manually annotated test set iterative refinement”,dataset quality 难以严格保证。
- 闭环控制能力未验证:本文 pointing 是 open-loop——预测一次 trace 后 follow,没有 reactive replanning。Contact-rich 任务依赖 impedance controller / Diffusion Policy 兜底。
- 与 ThinkAct / Sofar 的对比不充分:Table 4 把 ThinkAct(43.8)和 Sofar(53.8)列出来了,但没讨论 Embodied-R1(56.2)相对它们的具体优势来自哪里——是 dataset、是 reward design、还是 RFT vs SFT?
可信评估
Artifact 可获取性
- 代码: inference + training(GitHub 提供 inference_example.py,stage_1/stage_2 训练脚本,eval 脚本)
- 模型权重:
IffYuan/Embodied-R1-3B-v1(HuggingFace) - 训练细节: 仅高层描述(论文有 algorithm 和 reward weight 例子,详细超参在 appendix B/C;GitHub 提供 config_stage1/2.yaml)
- 数据集: 开源(
IffYuan/Embodied-R1-Dataset、IffYuan/VABench-P、IffYuan/vabench-v都已发布)
Claim 可验证性
- ✅ 3B 模型在 11 spatial/pointing benchmark SOTA:Table 1-3 直接对比,rank 2.1,数字可独立复现(模型 + 数据全开源)
- ✅ SIMPLEREnv 56.2% / 真机 87.5%:Table 4-5 + 项目页 8 个任务视频 demo 完整公开
- ✅ RFT 比 SFT 显著好:Table 6 同组数据对照,论证清晰
- ✅ 混合训练优于单任务:Table 8 ablation 直接验证
- ⚠️ “62% improvement over strong baselines”:相对值算法(87.5 - 25.0 = 62.5)成立,但 baseline FSD 的 25% 本身在这些 OOD 任务上偏低;与 Sofar(53.8% on SIMPLEREnv)的真机对比缺失
- ⚠️ “Embodied-agnostic”:作者只在 xArm 6 + WidowX 两种臂上测过,cross-embodiment 论断需要更多机型验证(虽然 pointing 抽象本身确实形态无关)
- ⚠️ “Robust against visual disturbances”:只测了 1 个任务(Task 6)的扰动,不能推广到所有任务的鲁棒性
- ⚠️ VTG 数据质量:rule-based filtering + iterative refinement 这种构造方式难以严格 audit;数据集开源但 filtering 标准未完全披露
Notes
- 核心 takeaway:这篇是 RFT 在 embodied AI 上目前最 convincing 的应用之一。之前的 R1-style embodied work 大多停在 simulation 或单任务,本文是少数同时做了 11 benchmark + SIMPLEREnv + 真机 + 视觉扰动的工作。
- “Pointing as middle-layer abstraction” 这个设计哲学值得思考:它本质上是把 robotics 的 “perception → planning → control” 三层中的 perception 输出从 “scene understanding” 升级到 “task-relevant spatial query”。这个抽象层级比 SayCan 的 affordance grounding 更细,比 Code-as-Policies 更结构化。
- 可复用的 component:(a) reward library 设计模式( + task-specific weighted sum)可直接迁移到其他 multi-task RFT 训练;(b) “question-verification” 数据格式可作为构造 RFT 数据集的 template;(c) Embodied-Spatial-84K + ViRL-subset-18K 的 “spatial + general” 混合 curriculum 是对抗 catastrophic forgetting 的实用配方。
- 对 VLA 方向的影响:如果 pointing-as-middle-representation 这条路径继续 scale(比如扩展到 dexterous manipulation、bimanual),可能会挑战 “VLA 必须是 end-to-end action policy” 的主流叙事——pointing + planner 可能是更 sample-efficient + 更可解释的方案。但需要看在 contact-rich / dexterous 任务上能否保持优势。
-
❓ Embodied-R1 输出的 point 是 single-step 的(VTG 是 8 点轨迹),缺乏 closed-loop reactive 能力。如果接 closed-loop 控制(如每帧 re-query 一次 pointing),latency 会成为问题——3B VLM 的 inference 时间在真机循环中是否可接受?论文 appendix D 提到了 execution time 分析,需要确认。
- 方法 vs 问题的权衡:作者自己强调 “simple, scalable, generalizable”。Pointing 抽象确实简洁,RFT 训练也是成熟方法,但整套系统依赖外部 motion planner、depth sensor、相机标定,“零样本” 的边界其实是 perception 层面的零样本,不是整个系统的零样本。这是个对自己方法的诚实定位问题。
Rating
Metrics (as of 2026-04-24): citation=26, influential=4 (15.4%), velocity=3.21/mo; HF upvotes=18; github 138⭐ / forks=4 / 90d commits=3 / pushed 51d ago
分数:2 - Frontier 理由:把 “pointing” 确立为 embodiment-agnostic 的中间表示,并通过 Table 6 (RL vs Think) 清晰论证 RFT 才是 OOD 泛化主因——这是对 R1-style embodied work 的关键纠偏,属于方向级别的 design 贡献而非 +3% SOTA。证据链完整(11 benchmark SOTA + SIMPLEREnv 56.2% + xArm 真机 87.5% + 视觉扰动鲁棒性 + 完全开源权重/数据/代码),3B 参数 rank 2.1 打过 13B 的效率优势使其具备成为后续 pointing+RFT 路线 baseline 的潜力。2026-04 复核:发布 8.1 个月累积 26 cites / 4 influential(15.4% 属健康继承比例)、velocity 3.21/mo、仅 138⭐、HF 18 upvotes——这些数字仅能支撑 Frontier 档而非 Foundation,“方向级别 design 贡献”的定性判断尚未被 community adoption 验证(同期 SmolVLA 同月龄已 244 cites + 17.6% ic),因此从 3 - Foundation 下调至 2 - Frontier;相对 1 - Archived,ICLR 2026 接收 + 完全开源 artifact + 作为 “R1 范式 + pointing” 代表工作被同期 VLA-RL 研究引用,仍处前沿必比 baseline 位置。