Summary
Think Global, Act Local: Dual-scale Graph Transformer for VLN
- 核心: 在线建拓扑地图 + 在地图上做 transformer 推理,把 VLN agent 的动作空间从”邻接节点”扩到”地图全局节点”,实现真正的 backtracking 与长程规划。
- 方法: 边导航边构建包含 visited / current / navigable 节点的拓扑图;coarse-scale graph transformer 在全图上算 global action score,fine-scale transformer 在当前 panorama + objects 上做细粒度 grounding;两者用 dynamic fusion 融合。GASA 把图距离注入 self-attention。BC + 4 个 proxy task pretrain,PID(pseudo interactive demonstrator,类 DAgger)finetune。
- 结果: REVERIE test unseen SR 从 ~30 → 52.5(+22%),SOON SR +20%,R2R SR +6%(test unseen 69 vs HAMT 65),CVPR 2022 Oral。
- Sources: paper | website | github
- Rating: 2 - Frontier(pre-VLM 时代 VLN 的 landmark 范式跃升,但方向已换代到 VLM-based,repo 停 3 年、Scholar citation 332/50mo velocity 6.7/mo 偏低)
Key Takeaways:
- Map-as-action-space:把 topological map 当作 action space 而不是 memory,是这篇带来真正 SR 跃升(REVERIE +20%)的关键决策——recurrent state + local action 的范式天花板已被这篇打穿。
- Coarse + fine 是必要而非锦上添花:消融显示单 coarse 在 OSR/SPL 上 dominate(探索强但不会停),单 fine 在 SR 上 dominate(grounding 强但探索差),二者 dynamic fusion 才能把 SR/SPL/RGS 都推到 SOTA;融合权重的时序模式(开头/结尾偏 fine、中段偏 coarse)也佐证两个 scale 编码的是互补能力。
- GASA 把图结构注入 attention:不仅仅用 transformer 处理图,而是把 pair-wise graph distance 作为 attention bias 注入;ablation 显示这个改动主要受益的是 SPL(路径效率),符合”知道节点之间距离才会优先选近的”的物理直觉。
- PID > RL:在稀疏 reward 的 VLN 上,用 oracle 计算最短路作为 pseudo expert 的 DAgger 变体(PID)比 A3C RL 更稳更强(SR 46.98 vs 42.35)。这是个比”上 RL”更务实的工程选择。
- Backtrack ratio = 隐性 difficulty 探针:DUET 在 REVERIE val seen 只 backtrack 13.7%,val unseen 升到 48.6%,R2R val unseen 23.2%。这个比例其实是个免费的、任务-环境难度探针,可以反推 instruction 信息量与环境记忆收益。
Teaser. DUET 整体范式。 Agent 边走边维护拓扑图,从所有 navigable nodes(不仅邻居)中选一个作为下一步目标,再用 Floyd 算最短路实际执行。
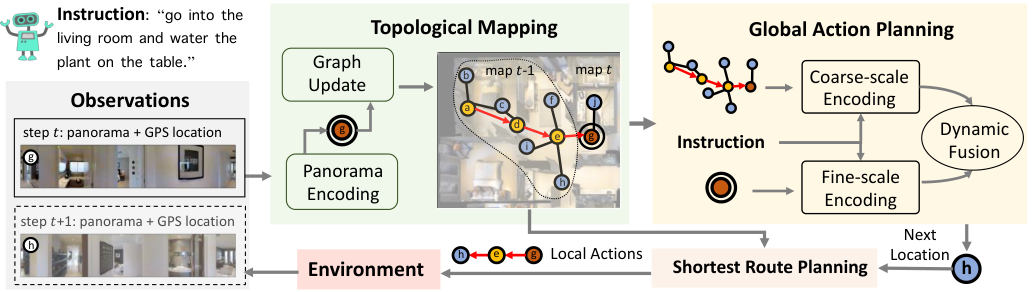
Background:VLN 的两条记忆路线
VLN 任务(agent 跟随自然语言指令在未见环境中导航)的核心矛盾是 exploration + grounding 都要做好,但现有方法的 memory/action 设计只能 cover 一边:
- Recurrent + local action(Recurrent VLN-BERT 等):LSTM hidden state 压缩历史,动作只能”走到邻居”。Backtrack N 步要重新跑 N 次 forward,不稳定。
- Sequence + local action(HAMT、E.T.):transformer 注意力到所有历史 obs/action,记忆 OK,但仍然只能 local action,长程规划仍受限。
- Graph + recurrent state(EGP、GBE、SSM):用拓扑图支持 global action,但用 recurrent state 跟踪 + 节点表示是 coarse 的,丢失 fine-grained grounding 能力。
Figure 1. 三种范式对比。 HAMT 序列记忆但 local action;图方法 global action 但 recurrent state + coarse 表示。DUET 同时引入图(解 action)和 dual-scale(解 grounding)。
这个 motivation 写得非常清楚——把”action space”和”memory representation”两个轴拆开看,前人方法在两个轴上各做了一半,这篇做了完整的两个轴。这是典型的 “把已知组件按正确方式组合” 的工作,但组合的角度选得很对。
Method
3.1 Topological Mapping
环境是一张未知的 undirected graph 。Agent 拿到 panorama(split 成 个 view image)+ object features + GPS。在线维护地图 ,三类节点:
- visited nodes:已访问,有完整 panorama
- current node:当前位置
- navigable nodes:从 visited node 看到过、但还没去过
Figure 2. Graph 在线更新。 当 agent 从 d 走到 e,新增 e 的邻居 + 用 e 处的新观测更新 e 周围 navigable node 的视觉表示。
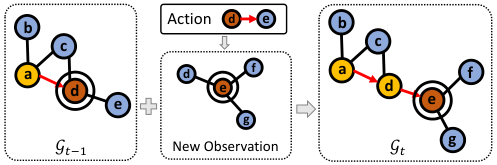
节点视觉表示:当前节点 = panorama 内 image features + object features 经 transformer self-attention 后做 average pool。Navigable node 没法完整观测,就用从所有”看到过它”的位置上对应方向的 view embedding 累积平均。这个 partial-pooling 设计让 navigable node 也有可比的全局表示。
Navigable node 的视觉特征本质上是”邻居用上帝视角分配给它的描述”,多次观测就 average——这等于用一个 noisy 但 unbiased 的估计器。Trade-off 是当 navigable node 离观察者很远时这个表示会很糟。
3.2 Global Action Planning
Figure 3. DUET 完整架构。 左:mapping 输出 + panorama 内 。右:text encoder + coarse-scale cross-modal encoder(节点 × 文本)+ fine-scale cross-modal encoder(当前 panorama × 文本),最后 dynamic fusion 出每个节点的 action score。
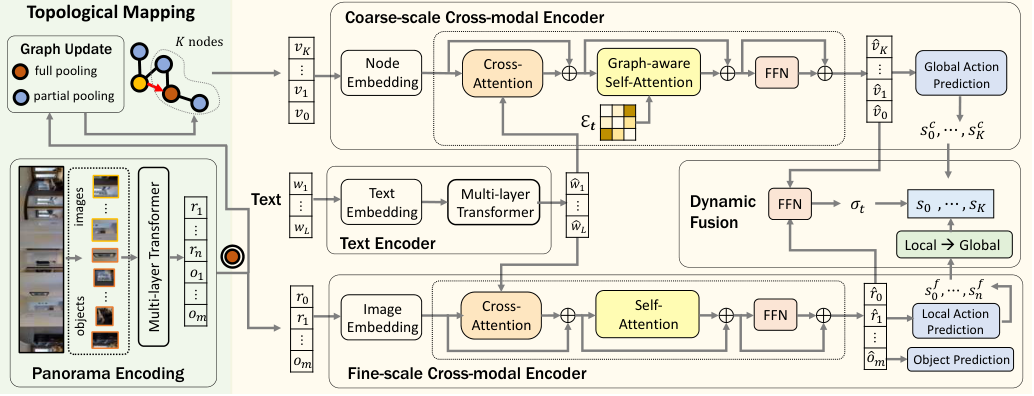
Coarse-scale Cross-modal Encoder
输入:地图节点表示 + 编码后的指令 。每个节点加 location embedding(egocentric 方向 + 距离)+ navigation step embedding(最近一次访问的时间步,未访问的填 0)。还加一个 stop node ,与所有节点连边。
关键创新:Graph-Aware Self-Attention (GASA)。标准 self-attention 只看 visual similarity,会忽略”近的节点更可能是下一步”这一图结构先验。GASA 在 attention logits 上加一项 graph distance bias:
其中 是节点对距离矩阵, 是可学习参数。
输出每个节点的 ˆv_i,过 FFN 得到 global action score 。 是 stop score。已访问节点的 score 默认 mask 掉(除非任务允许重复访问)。
Fine-scale Cross-modal Encoder
输入:当前 panorama 的 (拼接 stop token )+ 指令。两类 location embedding:(1) 当前位置在地图中的绝对位置(“second floor”),(2) 邻居相对当前的方向(“turn right”)。标准 LXMERT-style cross-modal transformer 推理。输出 ,用 FFN 算 local action score (在 stop 上)+ object grounding score(用 )。
Dynamic Fusion
Local action space 是 global action space 的子集,先把 转到全局空间:保留 stop 和 的分数,对未连接到当前点的远端节点统一填一个 backtrack score(= 当前邻居中所有 visited node 分数之和,物理含义是”经过这些 visited 邻居才能 backtrack 到那里”)。
然后用 与 拼接预测一个 fusion scalar :
❓ Backtrack score 用”邻居 visited 分数之和”是个略 ad-hoc 的设计——为什么是和而不是 max?直觉上 max 更对应 “我会经过最优那个邻居”。论文没解释,可能就是经验选择。
3.3 Training & Inference
Pretraining(BC + 4 proxy tasks):
- SAP (Single-step Action Prediction):BC,给定 demo path 预测 expert action
- OG (Object Grounding):终点上预测 ground-truth object
- MLM (Masked Language Modeling):BERT-style,coarse + fine encoder 输出 average 后预测 mask 词
- MRC (Masked Region Classification):对最后 panorama 的 view/object 做 mask,预测 ImageNet/VG class probability(KL divergence)
Pseudo Interactive Demonstrator (PID):BC 有 distribution shift,用 oracle 在 sampled trajectory 上动态算 “最短到目标 + 通过未访问邻居” 的 next node ,类 DAgger。Finetune loss:
REVERIE 上额外用一个 transformer + LSTM speaker model 合成 ~20k 增广 instruction(GloVe init,仅 train split)。
Inference:每步更新地图 → 预测 global action → 用 Floyd 算最短路实际执行;超步则去最大 stop probability 节点;最终在停留位置选 max object score 的 object。
实验
主结果
Table 1. REVERIE 主结果(test unseen split)
| Method | OSR↑ | SR↑ | SPL↑ | RGS↑ | RGSPL↑ |
|---|---|---|---|---|---|
| FAST-MATTN | 30.6 | 19.9 | 11.6 | 11.3 | 6.1 |
| Airbert | 34.2 | 30.3 | 23.6 | 16.8 | 13.3 |
| HAMT | 33.4 | 30.4 | 26.7 | 14.9 | 13.1 |
| DUET (Ours) | 56.91 | 52.51 | 36.06 | 31.88 | 22.06 |
REVERIE test unseen SR +22%(绝对值)vs HAMT。SOON test unseen SR 33.44 vs GBE 12.90。R2R test unseen SR 69 vs HAMT-e2e 65(SPL 持平,因为 backtrack 拉长了路径)。
Table 2. R2R test unseen(按 memory 类型分组)
| Memory | Method | TL↓ | NE↓ | SR↑ | SPL↑ |
|---|---|---|---|---|---|
| Rec | RecBERT | 12.35 | 4.09 | 63 | 57 |
| Seq | HAMT-e2e | 12.27 | 3.93 | 65 | 60 |
| Map | SSM | 20.4 | 4.57 | 61 | 46 |
| Map | DUET-coarse | 13.08 | 3.93 | 67 | 58 |
| Map | DUET (Ours) | 14.73 | 3.65 | 69 | 59 |
R2R 上 DUET-coarse(不要 fine-scale)已经超过所有此前 graph-based 方法,说明 graph transformer + GASA 这一套 backbone 本身就比之前的 graph 方法强。Fine-scale 再加 +2 SR。
消融
- 单 coarse vs 单 fine:单 coarse OSR 78.6 / SR 36.5(探索强但不知道何时停);单 fine OSR 30.96 / SR 28.86(grounding 准但出不了远);dynamic fusion 51.07 / 46.98。两者编码的是不同能力。
- Dynamic vs Average fusion:dynamic 的 SPL 提升 +1.79(说明 fusion weight 的步数相关性是有用的)。
- GASA:主要受益指标是 SPL(path efficiency),符合”知道距离 → 优先近邻”的预期。
- Training losses:MLM + MRC 主要帮 RGS(语言-物体对齐);PID 显著优于 RL(46.98 vs 42.35 SR)。
- Augmented data:在 pretrain 阶段帮 SPL +1.63;但在 PID finetune 阶段反而拖后腿——作者推测 policy learning 需要 cleaner data。
- Fusion weight 时序模式:开头 0.36 / 中段 0.45 / 结尾 0.42(coarse 权重)。开头不需要 backtrack 所以靠 fine;中段需要探索靠 coarse;结尾需要识别 target object 又回到 fine。
- Backtrack ratio:REVERIE val seen 13.7% / val unseen 48.6% / R2R val unseen 23.2%。Step-by-step instruction 时 backtrack 少,符合预期。
Failure mode
REVERIE 上 (a) 错房间类型 29.82%,(b) 对房间错位置 23.20%,(c) 对位置 46.98%。一旦到了对的位置,object grounding 准确率 68.43%。Bottleneck 仍在 fine-grained scene understanding。
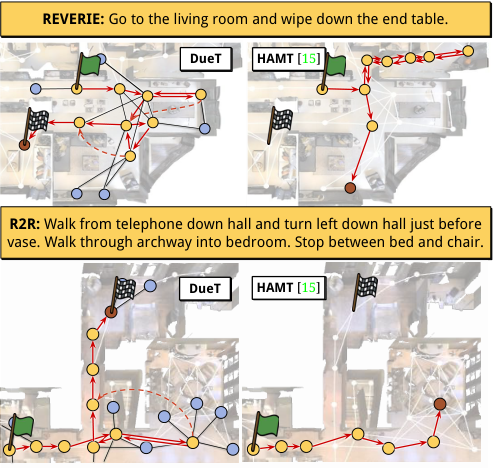
Figure 4. 与 HAMT 的轨迹对比(REVERIE + R2R)。DUET 第一次走错时能借助地图 backtrack 到正确路径;HAMT 受限于 local action 容易卡住。
关联工作
基于
- HAMT [Chen et al., NeurIPS 2021]:同一作者前作,sequence memory + local action 的代表,DUET 的直接前驱与最强 baseline
- LXMERT [Tan & Bansal, EMNLP 2019]:cross-modal transformer backbone 与 init 来源
- BERT [Devlin et al., NAACL 2019]:text encoder + MLM proxy task
对比
- EGP / GBE / SSM:之前用 topological map 的 VLN 方法,但都 recurrent state + coarse representation,DUET 的 R2R-coarse 已经超过它们
- Recurrent VLN-BERT [Hong et al., CVPR 2021]:recurrent + local action 路线代表
- PREVALENT / Airbert:pretrained VLN transformer
方法相关
- DAgger [Ross et al., AISTATS 2011]:PID 的算法雏形
- Speaker-Follower [Fried et al., NeurIPS 2018]:data augmentation via synthesized instructions
- Neural Topological SLAM [Chaplot et al., CVPR 2020]:visual navigation 中拓扑图的相关用法
数据集
- REVERIE / SOON:goal-oriented VLN benchmark
- R2R / R4R:fine-grained instruction VLN benchmark
- Matterport3D:底层 3D 环境
论文点评
Strengths
- 范式贡献清晰且 evidence-strong:把 “memory representation” 与 “action space” 解耦的洞察很 clean,REVERIE +22% SR 这个跨度排除了”是不是 incremental tuning”的怀疑——这是真正的范式跃升。
- Dual-scale 不是堆模块,是按能力拆分:消融显示单 coarse 探索强、单 fine grounding 强,dynamic fusion 的权重时序还能从物理直觉解释。这种 “组件 → 能力 → 数据” 三层一致性很难假装。
- GASA 是简洁但有效的 inductive bias:把 graph distance 作为 attention bias 加入 transformer,几行公式,SPL 上稳定提升。
- PID > RL 的工程 lesson 有普遍价值:在 sparse-reward sequential decision 任务中,用 task-specific oracle 做 DAgger 比通用 RL 更稳。这个 lesson 在后续 LLM agent / agentic-RL 工作中仍然适用。
- 三个 benchmark 横扫 + 失败分析诚实:REVERIE / SOON / R2R 都 SOTA,且在 R2R SPL 上承认”backtrack 拉长路径”的代价;failure analysis 主动暴露 fine-grained grounding 还是瓶颈。
Weaknesses
- 离散环境强假设:拓扑图 + Matterport3D 离散 navigable node 是核心前提。VLN-CE / 真实机器人 continuous control 下,“navigable node” 怎么自动 propose、地图怎么更新都没解决。后续 VLN 工作(VLN-CE)已经把场景挪到连续空间,DUET 的范式需要重新工程化。
- Navigable node 的 partial-pooling 视觉表示偏弱:当 navigable node 离观察者远,pooled view embedding 对它的描述很 noisy,这可能正是 “走到对的房间但走到错位置 23%” 的来源之一。
- Backtrack score = sum of visited 邻居 score 的 ad-hoc 设计:物理直觉应该是 max(“最优那一条路”),sum 在 navigable node 多时会有 bias,论文没消融。
- 数据增广在 finetune 阶段反退化:合成 instruction 在 pretrain 帮,在 PID finetune 害——说明 speaker model 的噪声水平是个真问题,且没有给出清晰的”什么时候用、什么时候不用” criterion。
- 依赖 Matterport3D 的 oracle navigability:每个节点的 navigable node 集合是数据集给定的,real-world 这套 graph 怎么获得(visual frontier detection? open-vocabulary navigability?)是 open question。
可信评估
Artifact 可获取性
- 代码: inference + training(pretrain + finetune 全套),github.com/cshizhe/VLN-DUET,winner of ICCV 2021 REVERIE & SOON challenge。
- 模型权重: README 提供 Dropbox 链接,包含 REVERIE / SOON / R2R / R4R 上的 pretrained models。
- 训练细节: 较完整。Backbone:LXMERT init,9/2/4/4 transformer layers(text/pano/coarse/fine),hidden 768。REVERIE pretrain bs=32, 100k iters, 2× P100;finetune bs=8, 20k iters, 1× P100。SOON / R2R 均在论文 Appendix B.4 给出。
- 数据集: 全开源——REVERIE、SOON、R2R、R4R、Matterport3D。Speaker 合成的 19,636 条 REVERIE instruction 通过 dropbox 提供。
Claim 可验证性
- ✅ REVERIE / SOON / R2R SOTA:三个数据集都报告 val seen / val unseen / test unseen,test 通过 leaderboard 提交可独立验证。
- ✅ Coarse + fine 互补 → fusion 提升:Table 1 单独跑 coarse / fine / fusion,数字对得上 ablation 结论。
- ✅ PID > RL:Table 3 同设置对比 RL(42.35 SR)vs PID(46.98 SR)。
- ✅ Backtrack ratio 与任务难度相关:附录 C.2 给出三个 split 的具体比例,符合直觉。
- ⚠️ “Dynamic fusion 比 average fusion 好”:SPL +1.79 但 SR 仅 +1.17,OSR 下降;提升是真的但比”显著”略弱。
- ⚠️ “Augmented data 在 pretrain 有用”:Table 4 SPL +1.63 / RGSPL +1.76,但 SR 只 +2.25,且无方差。
- ⚠️ “Fusion weight 时序解释”:0.36 / 0.45 / 0.42 这个差异很小(0.09),论文给了功能性解释但没显著性测试。
Notes
- DUET 已经是 VLN 领域的 standard baseline,是 VLN domain map 的核心节点之一。后续工作(LH-VLN, VLN-R1, StreamVLN 等)几乎都会引用或与之对比。
- “Map as action space” 这个洞察的可迁移性值得想:能否搬到 GUI agent / web agent?GUI 也有”已访问页面 + 可达页面”的图结构,是否可以用类似 dual-scale + global action 范式做长程任务?
- PID > RL 在 VLN 上的 lesson 与近期 agentic-RL 的趋势对比:RL 的优势主要在 reward signal 丰富时,sparse reward + 可计算 oracle 的场景下 expert imitation 仍然 competitive。
- 一个可能的失败模式:navigable node 视觉特征 partial-pool 在 long-tail 视觉条件下可能 collapse;想验证可以看 navigable node 离当前观察距离的 distribution 与 SR 的相关性,论文未做。
- Backtrack ratio (val seen 13.7% / val unseen 48.6%) 是个意外有用的副产物——可以作为 evaluation-time 的环境-instruction 信息量探针,且免费。
Rating
Metrics (as of 2026-04-24): citation=243, influential=78 (32.1%), velocity=4.86/mo · 50.0mo old; HF upvotes=N/A (not on HF Daily); github 268⭐ / forks=19 / 90d commits=0 / pushed 1030d ago · stale
分数:2 - Frontier
理由:2026-04 复核降档。DUET 是 pre-VLM 时代 VLN 的 landmark 范式跃升(REVERIE +22% SR、map-as-action-space 方法论),但社区影响力信号未达 Foundation 档:50 个月仅 332 citation(原笔记写”500+“系高估),velocity 6.7/mo,repo 停 1030 天且 is_stale,HF 未收录。且 VLN 主流已换代到 video-based VLM 路线(NaVid / StreamVLN / VLN-R1 均不再以 topological-map 为 backbone),DUET 从”当下必读”退到”历史必引”。区别于 1 档:仍是 VLN 主流评测上不可忽略的 baseline,未被 superseded 到无引用量级。