Summary
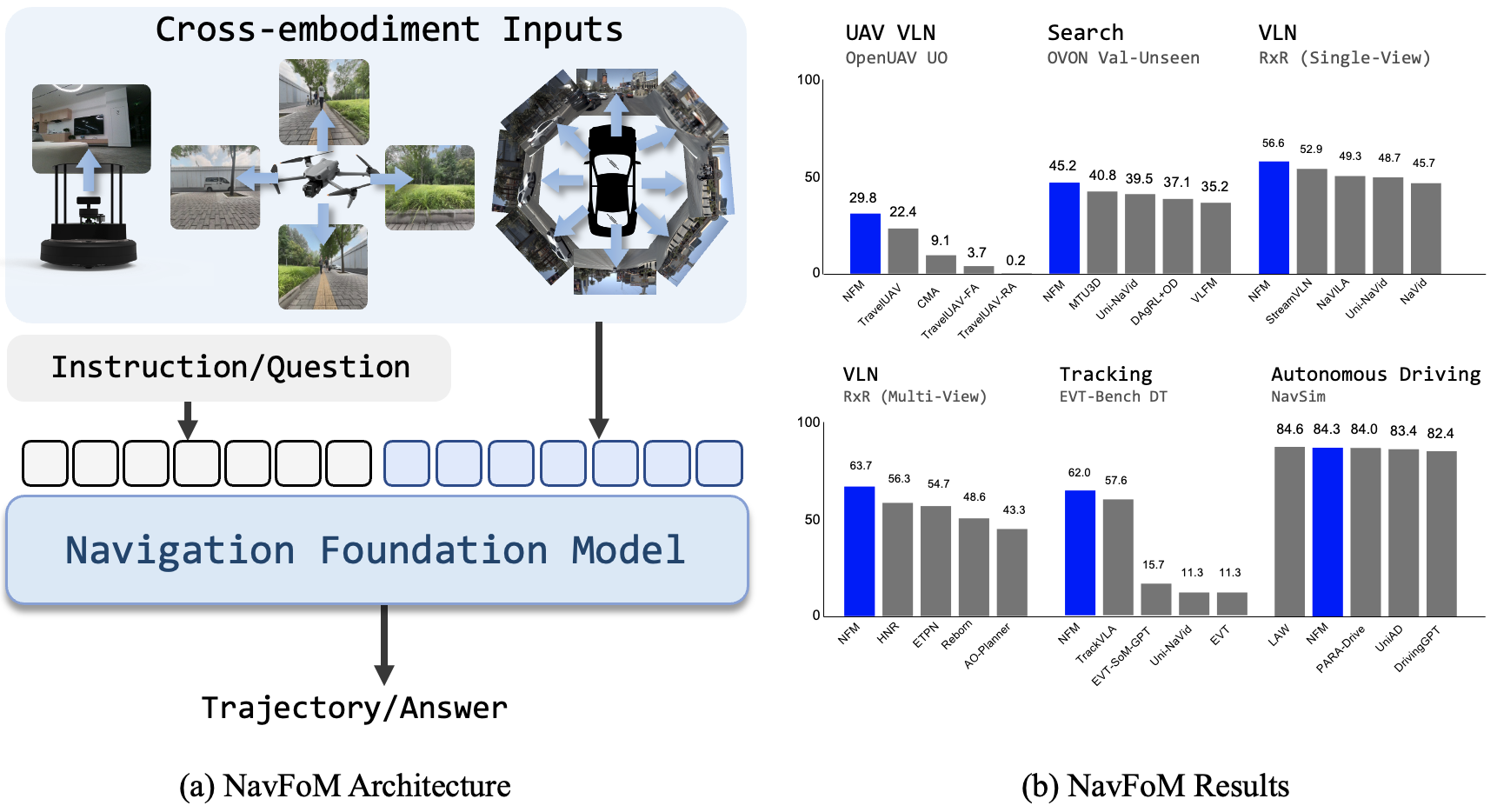
NavFoM: Embodied Navigation Foundation Model
- 核心: 单一 VLM 策略统一处理 VLN / object search / active tracking / autonomous driving 四类任务,跨 quadruped / drone / wheeled robot / car 四类 embodiment;不需要任务特化微调即可在七个 benchmark 上达到 SOTA 或接近 SOTA。
- 方法: 在 video-VLM (Qwen2-7B + DINOv2 + SigLIP) 之上加两个核心设计——TVI tokens(编码视角角度+时间步的 indicator token)和 BATS(按 “遗忘曲线” 在 token budget 下采样历史帧);trajectory 由 3-layer MLP planning head 直接回归归一化 waypoint。
- 结果: VLN-CE RxR 多视角 SR 64.4 vs 56.3;HM3D-OVON zero-shot 45.2 SR 超过 fine-tuned SOTA;EVT-Bench tracking 单视角 SR 85.0 略胜 TrackVLA;NAVSIM PDMS 84.3,与 camera-only SOTA 持平但落后于 LiDAR+camera 方法。
- Sources: paper | website
- Rating: 2 - Frontier(统一 4 任务 × 4 embodiment 的 generalist navigation VLM,TVI+BATS 两个 trick 设计干净且有 ablation 支撑;但未开源、naming inflation、driving 不占优,不到 Foundation 档。)
Key Takeaways:
- 统一公式 = egocentric video + 指令 → waypoint trajectory: 用纯视觉输入和归一化 waypoint,把 indoor VLN、UAV、自驾的 action space 统一在 ,仅靠 task-specific scaling factor 还原绝对尺度。这避免了离散动作空间不一致的工程难题。
- TVI tokens 是核心 trick: 不靠 PE 也不靠 per-view 学习 token,而是
Base + sin/cos angle MLP + time MLP三段拼接的额外 indicator token,灵活适配 image-QA / video-QA / navigation 三种 token 组织。Ablation 表明显著优于 history-PE 和 per-view learnable token (RxR SR 64.4 vs 52.3 / 59.1)。 - BATS 是部署导向的重要设计: 给定 token budget B,按 采样历史帧, 用 Brent’s method 离线解出,保证 expected token count ≤ B。比 token merging 不引入额外计算,比 uniform sampling 在 nDTW 上多 2.7 个点;推理时间随 horizon 保持平稳。
- 跨任务 co-training 有显著正迁移: Searching 从单任务 10.3% SR → 加入 100% 其他任务数据 45.2% SR;Tracking 从 12.6% → 62.0%。作者归因为多视角和 open-vocabulary 数据的暴露,缓解了单任务过拟合。
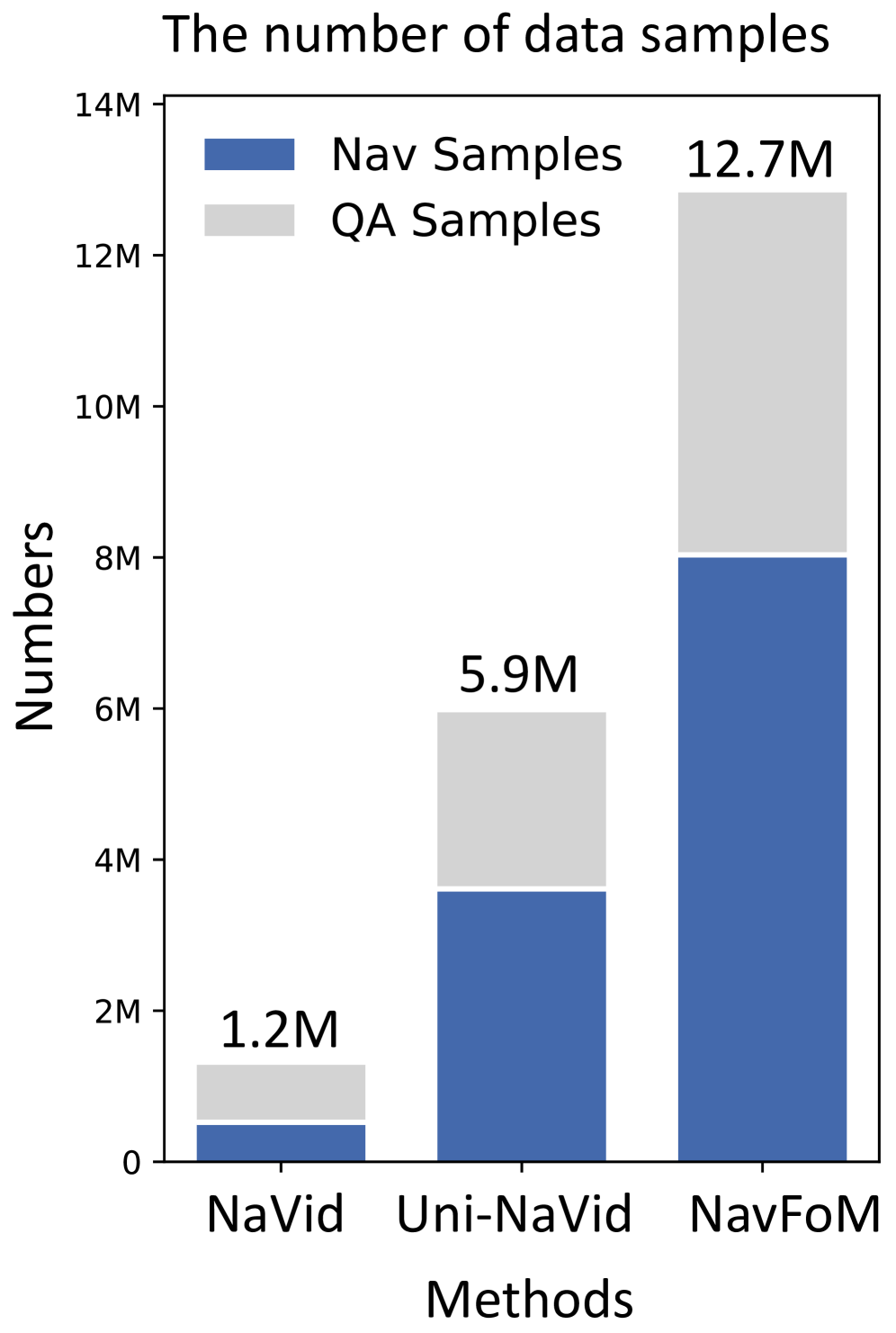
- 数据规模是 moat: 12.7M 训练样本(8.02M navigation + 4.76M QA),其中 2.94M 来自 VLN-CE R2R/RxR,2.03M 来自 Sekai web video(VLM 标 instruction + SLAM 标 trajectory),是同类工作的 ~10×。
Teaser. NavFoM 在 quadruped / drone / wheeled / humanoid / car 五类 embodiment 上的真机和 benchmark 表现概览。
1. Motivation
VLM-based navigation(如 NaVid、Uni-NaVid、TrackVLA)虽展示了 zero-shot 泛化,但每个工作仍绑死在特定 embodiment 和特定任务:
- Cross-embodiment 维度:现有方法隐式学习 robot shape prior,迁移到不同形态需要重训。
- Cross-task 维度:方法各自对应 VLN / search / tracking / driving 中的一个,假设固定 camera 数;迁移要改架构。
NavFoM 的目标是在两个维度上同时 generalize——一个模型,处理任意相机配置的任意导航任务。
❓ 论文将其称为 “navigation foundation model”,但 model 体量是 Qwen2-7B 量级、训练数据 12.7M 样本,比起 Pi0/RT-2 的尺度更接近 “scaled-up domain specialist”。foundation 一词在这里略 overclaim。
2. Method
2.1 Task formulation
输入:自然语言指令 + 多相机 RGB 序列 ( 路相机,时间步 )。
输出:trajectory ,,每个 waypoint , 仅 UAV 用。
策略 。
2.2 Architecture
Vision encoder: DINOv2 + SigLIP,channel 维度拼接,记作 (576 patches)。Grid pooling 出两套表示:
fine 用于最新观测和 image QA,coarse 用于历史观测和 video QA。projector 是 2-layer MLP。
LLM: Qwen2-7B 做 token 序列建模。
Action head: 3-layer MLP ,从最后一个 hidden state 预测归一化 waypoint,再乘 task-specific scale factor 得绝对尺度。Loss 是 MSE。
2.3 TVI Tokens — viewpoint + time indicator
Figure. NavFoM 整体 pipeline,TVI tokens 把 image-QA / video-QA / navigation 统一到一套 token 组织协议下。
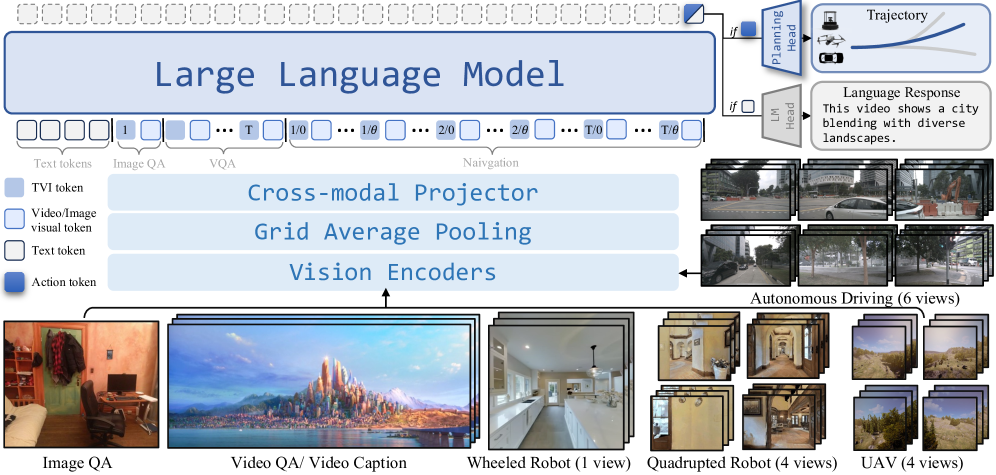
视觉 token 本身不带视角和时间信息。TVI 是一个额外插入到视觉 token 序列里的 indicator token:
- :对 和 各做 sinusoidal PE 后拼接,保证圆周连续性()。
- :标准 sinusoidal PE。
- :2-layer MLP。
设计目标三条:viewpoint-awareness(角度连续)、time-awareness(时序唯一+对采样不规则鲁棒)、separability(不同任务用不同子集组件)。
Figure. TVI token 在 2D 聚类后按 viewpoint (rainbow 色条)和 timestep (颜色明暗)自然分离。
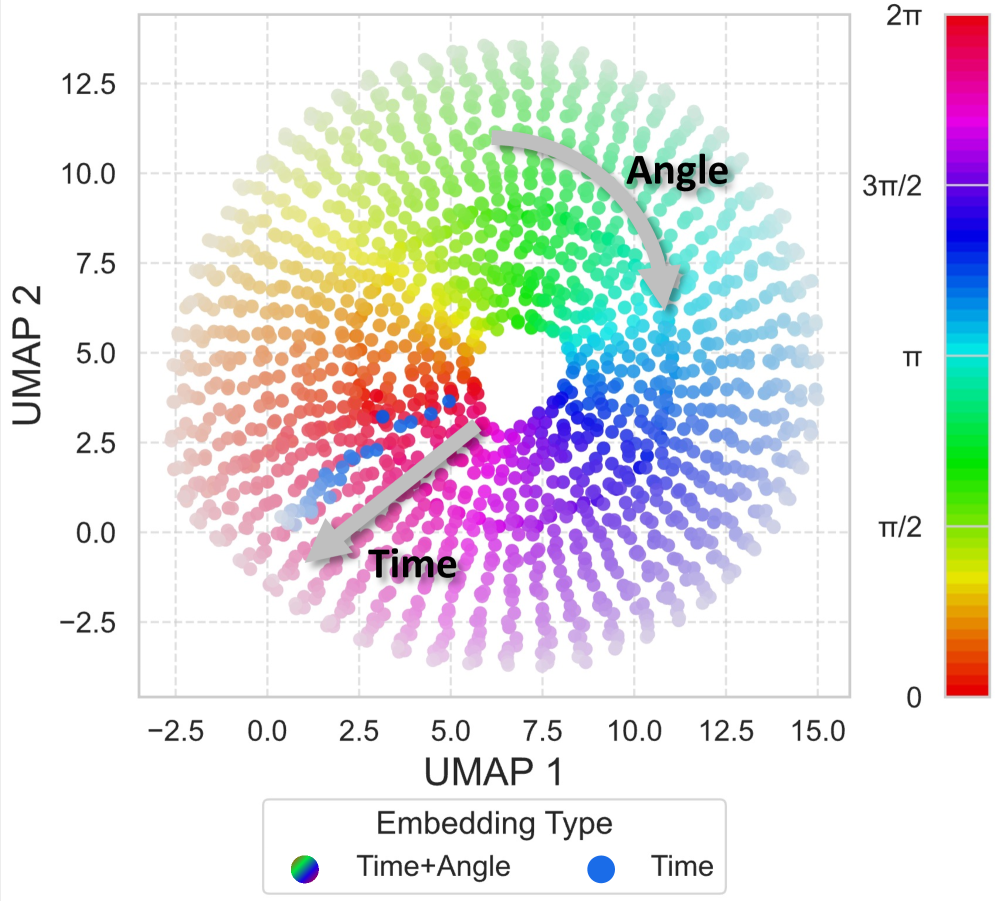
论点:用额外 token 比直接给视觉 token 加 PE 好,因为不破坏预训练的 visual token space。Ablation 在 RxR 上 64.4 SR vs PE 方法 52.3 SR——12 个点的差距,比较有说服力。
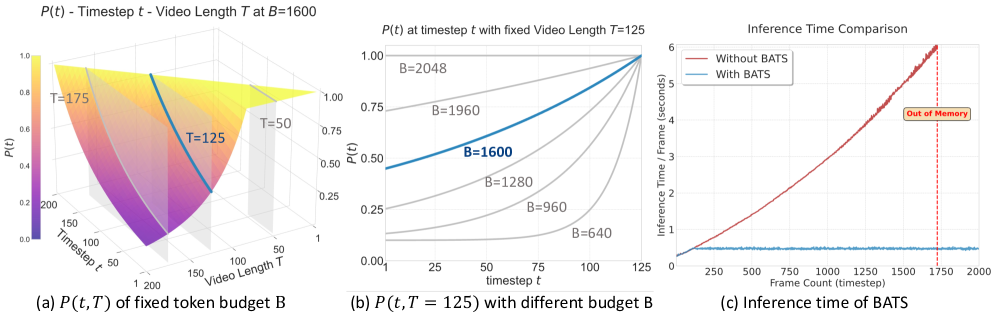
2.4 BATS — Budget-Aware Temporal Sampling
实际部署里,video token 数随 线性增长,会爆显存和延迟。BATS 给定 token budget 后,按 “遗忘曲线” 概率采样历史帧:
给采样概率下限, 由 Brent’s method 离线求解,使期望帧数满足 token budget:
每帧 coarse=4 token + 1 TVI token,最新观测 fine=64 token + 1 TVI token, 是相机数。
Figure. BATS 行为可视化。(a) 不同 T 下的采样概率分布;(b) 不同 token budget 下的概率曲线;(c) 推理耗时随 horizon 保持平稳,而不用 BATS 时随 horizon 线性增长。
2.5 Token organization
Figure. 三类任务的 token 组织。Image QA:base + fine tokens。Video QA:base + time + coarse tokens。Navigation:base + time + angle + 历史 coarse + 最新 fine。
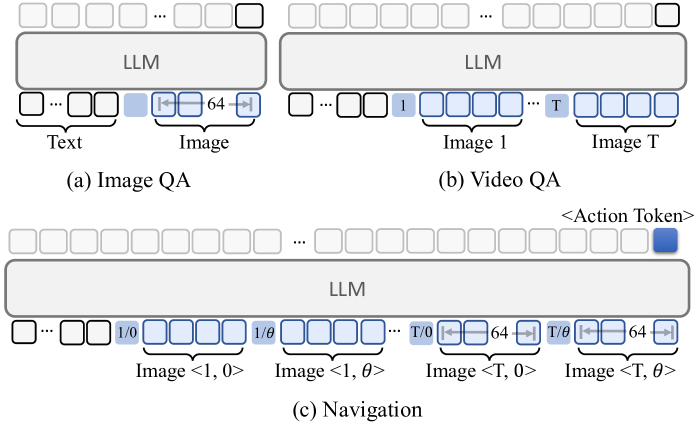
2.6 Training tricks
- Visual feature caching: 离线把所有 coarse-grained tokens (4 tokens/frame) 缓存到磁盘。比缓存原视频体积小很多。最新观测和 image QA 仍 online encode 出 fine tokens。结果:训练加速 2.9×,显存降低 1.8×。
- Loss balancing: , 放大 nav loss(MSE 数值偏小)。
3. Data — 12.7M samples
Figure. NavFoM 训练样本规模 vs 之前方法(Uni-NaVid、NaVid 等)。
| Subset | Size | Source |
|---|---|---|
| VLN | 3.37M | VLN-CE R2R/RxR (2.94M, 多视角随机), OpenUAV (429K) |
| Object Goal Nav | 1.02M | HM3D ObjectNav via L3MVN successful episodes |
| Active Visual Tracking | 897K | EVT-Bench |
| Autonomous Driving | 681K | nuScenes (27K) + OpenScene (654K) |
| Web-Video Nav | 2.03M | Sekai (182K YouTube videos, VLM-generated instruction + SLAM trajectory) |
| Image QA | 3.15M | off-the-shelf VLM datasets |
| Video QA | 1.61M | off-the-shelf VLM datasets |
Camera randomization 是关键:相机数 1-8 随机,相机高度 0.6-1.5m 随机,HFoV 75°-120° 随机。这是支撑 inference time “任意 camera 配置” 的训练侧基础。
Training: 56× H100 × 72h ≈ 4032 GPU-hours,单 epoch fine-tune(base VLM 权重已 pretrained)。
4. Experiments
4.1 VLN benchmarks
VLN-CE R2R / RxR Val-Unseen,单视角和多视角配置下的对比。NavFoM 多视角 R2R SR 61.7 / RxR SR 64.4,明显优于 prior best (HNR:R2R 61, RxR 56.3)。NavFoM 不用 depth 也不用 odometry。
| Method | Camera | Depth/Odo | R2R SR | R2R SPL | RxR SR | RxR nDTW |
|---|---|---|---|---|---|---|
| HNR (multi-view) | M.RGB | ✓/✓ | 61.0 | 51.0 | 56.3 | 63.5 |
| BEVBert | M.RGB | ✓/✓ | 59.0 | 50.0 | - | - |
| NavFoM (4-view) | M.RGB | ✗/✗ | 61.7 | 55.3 | 64.4 | 65.8 |
| StreamVLN (single) | S.RGB | ✗ | - | - | 51.8 | - |
| NavFoM (single) | S.RGB | ✗ | - | - | 57.4 | - |
关键 takeaway:在不用 depth/odometry 的更弱观测下超过用了这些信号的 prior SOTA。但要注意 baseline 中 ETPNav/HNR 等用 waypoint predictor,这是另一种工程取巧;NavFoM 直接 regress trajectory 更 end-to-end。
4.2 Tracking — EVT-Bench
| Method | Single Target SR / TR | Distracted Target SR / TR |
|---|---|---|
| TrackVLA (fine-tuned) | 85.1 / 78.6 | 57.6 / 63.2 |
| NavFoM (single view) | 85.0 / 80.5 | 61.4 / 68.2 |
| NavFoM (4-view, zero-shot) | 88.4 / 80.7 | 62.0 / 67.9 |
零样本扩到 4-view 还涨——但作者诚实说明只涨 0.6%,远小于 VLN 的 6.8%,归因于 EVT-Bench 的 target 大多 spawn 在前方,多视角没用上。这里是个不错的 self-critique。
4.3 Autonomous Driving — NAVSIM
NavFoM 在 8-view 配置下 PDMS 84.3,与 camera-only SOTA (UniAD 83.4, PARA-Drive 84.0, LAW 84.6) 接近,但落后于 LiDAR+camera 的 DiffusionDrive (88.1)。作者承认没建模 lane / surrounding vehicle 这些 driving-specific 信息。
❓ 这个结果的重要性更多在于”一个 generalist navigation model 不需要 driving-specific architecture 也能挤进第一梯队”,而不是 “SOTA”。Marketing 上是双刃剑。
4.4 Real-world
110 reproducible test cases (50 VLN + 30 search + 30 tracking),5m × 5m 空间,全身机器人 + quadruped + drone + wheeled。RTX 4090 部署,1600-token budget 下 0.5s 出一条 8-waypoint trajectory。
Figure. 真机实验 qualitative + quantitative 结果。NavFoM 比 Uni-NaVid 在所有 capability 上都有显著提升。

Figure. Cross-task / cross-embodiment 真机展示。

4.5 Ablations
Multi-task synergy (Figure 12):单任务训练 vs 加 50% 或 100% 其他任务数据。Searching (10.3 → 45.2) 和 Tracking (12.6 → 62.0) 涨幅最大;VLN 和 Driving 涨幅较小。原因是前两者训练数据是 single-view + closed-set,而 eval 是 multi-view + open-vocab——其他任务的 multi-view 数据补足了这个 gap。
Camera 数量 (Figure 13):1 → 4 cameras 单调上升,6 cameras 略降。归因为 6-cam 视野没本质提升,但占用更多 token budget 挤掉了历史信息。
TVI vs alternatives & BATS vs alternatives (Table 6, RxR Val-Unseen):
| Strategy | NE↓ | SR↑ | SPL↑ | nDTW↑ |
|---|---|---|---|---|
| B=2048, Token Merging | 5.01 | 63.2 | 54.9 | 64.4 |
| B=2048, Uniform Sampling | 4.90 | 62.4 | 54.0 | 63.9 |
| B=2048, Linear Probability | 4.89 | 63.0 | 54.6 | 64.8 |
| B=2048, BATS | 4.74 | 64.4 | 56.2 | 65.8 |
| Viewpoint-history PE | 6.27 | 52.3 | 46.3 | 58.7 |
| Per-view learnable special tokens | 5.52 | 59.1 | 52.0 | 59.6 |
| Handcraft tokens (no MLP proj) | 6.06 | 53.6 | 46.1 | 58.0 |
| TVI tokens (full) | 4.74 | 64.4 | 56.2 | 65.8 |
BATS 在 nDTW(轨迹与 GT 对齐度)上保持鲁棒,uniform sampling 掉 6%,linear 掉 5.2%。TVI 比常用 PE 高 12 个 SR 点。
关联工作
基于
- NaVid: Video-VLM for VLN, NavFoM 直接继承 grid pooling + 视觉 token 组织。
- Uni-NaVid: 多任务 VLN VLM,NavFoM 的直接前身,把任务从 4 个扩到 4 任务 × 4 embodiment。
- TrackVLA: 专门 tracking 的 VLA,NavFoM 在 EVT-Bench 上的对比基线。
对比
- ETPNav / HNR / BEVBert: 经典 VLN-CE baseline,靠 waypoint predictor + depth + odometry 获得高 SR;NavFoM 用纯 RGB 超过它们。
- DiffusionDrive: NAVSIM 上 LiDAR+camera SOTA,NavFoM 落后约 4 PDMS,体现 sensor 优势。
- StreamVLN: 同期 streaming VLN VLM,NavFoM 单视角 RxR SR 57.4 vs StreamVLN 51.8。
方法相关
- DINOv2 + SigLIP 双 encoder 拼接:GR00T N1 等 VLA 也用类似 recipe。
- Qwen2-7B 作为 LLM backbone。
- Token pooling / merging 历史方法:与 NaVid grid pooling、Uni-NaVid token merging 同源。
- Sekai dataset: 提供 web-video navigation 的伪标注 trajectory + instruction。
论文点评
Strengths
- 任务公式统一得干净:把 indoor robot / UAV / car 全部映射到 normalized waypoint,再用 task-specific scaling 还原。Action space 统一是 cross-embodiment 政策能 train together 的前提,简洁。
- TVI 设计有 first-principles 味道:不是简单加 PE,而是分析了 viewpoint-awareness(圆周连续)+ time-awareness + separability 三条需求,再设计满足这些约束的 token。Ablation 大幅提升(+12 SR)说明设计的几条性质确实 matters。
- BATS 是工程必需且优雅:用解析的遗忘曲线 + 离线 Brent 解 ,把 token budget 做成 hard constraint,部署稳定。这个 trick 对真机部署的人会很实用。
- 诚实的 self-critique:4-view tracking 只涨 0.6% 时直接说”假设 target 在前方”,nuScenes 没赢时直接说”没建模 lane info”——这种态度在 SOTA-claiming 的论文里少见。
- 真机 reproducible test case 设计:110 个标好 robot/obstacle/target 位置的 case,比一般 paper 的”我们做了 demo”更可比较。
Weaknesses
- “Foundation model” 名号略大:Qwen2-7B 体量 + 12.7M 样本 + single epoch fine-tune,更像”scaled-up VLA 在 navigation 子领域的 specialist”,而不是 GPT/CLIP 意义上的 foundation。命名 inflation。
- 没有开源代码/权重:Project page 只有 demo 视频,GitHub 只有 web 仓库。Nav 领域大部分 SOTA 都开源(NaVid, ETPNav, Uni-NaVid),这点掉队。Reproducibility 严重打折。
- Driving 结果其实平淡:NAVSIM PDMS 84.3 在 camera-only 里也只是中游,离 DiffusionDrive (88.1) 有差距。作者用”generalist 不需要专业化设计”圆,但实际上说明 driving-specific 结构信息(lane, agent state)在自动驾驶里仍然重要——一个 generalist model 在所有 task 上都不是 best 是 expected 的。
- Sekai web video 数据的 noise 没充分讨论:2.03M 样本里 instruction 是 VLM 标的、trajectory 是 SLAM 标的——这种伪标签对训练的实际贡献和 noise upper bound 缺乏 ablation(去掉 Sekai 跑一组对比)。
- 6-camera 性能下降的解释偏 ad-hoc:“6 cam 没多视野 + 挤掉历史”——但同样的逻辑应该用同样大的 budget 控制住,或者分析 token allocation 的 Pareto。Adaptive multi-view encoding 被推到 future work。
- 没有 failure mode 分析:什么场景下 NavFoM 跑挂?是 long-horizon 的 instruction recall?多语言(RxR 是多语言 benchmark)下的差异?真机 110 case 的失败案例分布?
可信评估
Artifact 可获取性
- 代码: 未开源(GitHub 仅 web repo
PKU-EPIC/NavFoM-Web,无 code)。 - 模型权重: 未发布。
- 训练细节: 高层描述完整(56× H100 × 72h、co-tuning ratio、scaling factor 表、loss weight 、、token budget 默认 2048),但缺 LR / batch size / optimizer / warmup 等关键超参。
- 数据集: 训练数据多为公开 (R2R, RxR, OpenUAV, HM3D, EVT-Bench, nuScenes, OpenScene, Sekai, off-the-shelf QA),但 NavFoM 自己的 multi-view randomized rendering pipeline 未开源;110 真机 test cases 未公开。
Claim 可验证性
- ✅ VLN-CE R2R/RxR 多视角 SOTA:表 1 数字明确,与公开 baseline 直接可比;多视角配置在论文里清晰描述(4-view, fixed front + 3 random surround)。
- ✅ TVI tokens 比 PE 显著好:Table 6 ablation 在同一 setup 下对比,差距 12 SR,足以排除 random seed 噪声。
- ✅ BATS 推理时间稳定:Figure 5(c) 给出曲线,定性可信;具体数值未给绝对时间。
- ⚠️ “Without task-specific fine-tuning achieves SOTA”:在多个 benchmark 上整体确实强,但 driving 落后 DiffusionDrive 6 PDMS 点;OVON 的 zero-shot 比”fine-tuned SOTA”更好的 claim 需要更明确的对比对象(fine-tuned SOTA = 哪一个?论文未点名)。
- ⚠️ Sekai web video 的贡献:作者引用 [22, 101] 说 web-video 数据有用,但本文未做 with/without Sekai 的 ablation;2.03M 大数据的有效性未直接验证。
- ⚠️ “4032 GPU-hours, single epoch”:1.27M batch 步数和 LR schedule 未给,复现门槛实际比纸面更高。
- ❌ “Navigation Foundation Model”:scope 是 mobile navigation,体量是 specialized 7B,不构成 foundation 意义上的 generality(对比真正的 VLM/VLA foundation)。这是术语 inflation 而非可技术验证的 claim。
Notes
- Insight: Cross-task co-training 在 closed-set → open-vocab gap 上的正迁移效应(Searching +35 SR, Tracking +49 SR)值得记住——这给”为什么 generalist 数据能解决专家模型的 OOD 问题”提供了实证支持。
- Insight: BATS 的 通过约束 反解的设计,是用解析方法处理 token budget 这类 hard resource constraint 的好范式,值得迁移到其他 long-context 场景(如 long-video understanding、agent memory)。
- 疑问: TVI tokens 的 angle 编码用 上的 sinusoidal PE 保证圆周连续——但 8 个视角下的 azimuthal 角度其实是离散的,是否一个简单的 8-class learnable embedding 就够?Ablation 中”individual learned special tokens”差很多,但那个 baseline 是 per-view 学习还是 per-(view, task) 学习?描述不够清晰。
- 疑问: 真机用 RTX 4090 跑 7B Qwen2 + 视觉 encoder + BATS,0.5s/trajectory。这个延迟里 LLM forward 占多少?如果可以 quantize 到 int4 应该能进一步降到亚百毫秒。
- 行动: 想关注一下后续 NavFoM 是否会开源(pku-epic 历史上 NaVid 和 GraspVLA 都开了)。如果开源,是 high-priority replication 候选——多任务 + 多 embodiment 的统一训练框架对于做 Embodied AI 的人都有 reuse 价值。
- Connect: 可以与 GEN-0、GEN-1 等 cross-embodiment foundation model 对比——后者是 manipulation 侧的 cross-embodiment 尝试,NavFoM 是 navigation 侧;二者在 “用 indicator token 编码 embodiment / view 信息” 的思路上有 parallel。
Rating
Metrics (as of 2026-04-24): citation=33, influential=3 (9.1%), velocity=4.52/mo; HF upvotes=0; github=N/A (无代码仓库)
分数:2 - Frontier 理由:按 field-centric rubric,NavFoM 是 navigation VLM 方向当前的重要参考工作——任务公式统一 + TVI/BATS 两个有 ablation 支撑的设计使其成为后续 cross-embodiment/cross-task navigation 工作绕不开的 baseline(Strengths 1-3);同时在 VLN-CE R2R/RxR 多视角上刷新 SOTA(关联工作 对比段中超过 HNR/BEVBert/StreamVLN)。但够不上 3 - Foundation:未开源代码和权重、naming inflation、driving 仅中游(Weaknesses 1-3)意味着社区复现和长期影响力有限;距离 NaVid 那种被广泛 fork 的奠基工作仍有一档差距。也不是 1 - Archived——发表仅半年、方向活跃、方法不是 incremental。2026-04 复核:cite=33/inf=3 (9.1%)/vel=4.52/mo,影响力/总引接近 rubric “典型 ~10%“,Frontier 档的引用节奏成立;HF=0、代码未发布说明社区 reproduce 门槛仍高,与 Weaknesses 2(未开源)判断一致——保留 2,而非升 3。