Summary
GEN-0: Embodied Foundation Models That Scale with Physical Interaction
- 核心: Generalist AI 公开他们的第一代 embodied foundation model GEN-0,宣称在 270K 小时真实操作数据上观察到 robotics 领域的 scaling laws,并出现 7B 处的”intelligence threshold”相变。
- 方法: Decoder-only 架构 + “Harmonic Reasoning”(异步连续时间的 sensing/acting token 流,避免 System1/System2 分离或 inference-time guidance);270K 小时真实人类操作数据预训练,10K 小时/周新增;多模型尺寸(1B/6B/7B/10B+)扫描。
- 结果: 1B 模型在大数据下出现 ossification;6B 受益但有限;7B+ 解锁迁移;real-robot 上 5.6h post-training 即可见效,full pretrain + 550h post-train 个别任务达 99% 成功率。
- Sources: website
- Rating: 3 - Foundation(首次把 “robotics 是否存在 scaling laws” 推到有可测形式的实证层面,ossification 临界 size / pretrain→post-train power law / reverse-KL 区分 SFT-vs-RL 数据这三个观察是后续 data-centric VLA 研究必须对照的参考点。)
Key Takeaways:
- 首次在 robotics 观察到 ossification 相变:1B 模型在大量预训练数据下反而无法吸收新信息(model weights 失去可塑性),需要 ≥7B 才能突破——比 LLM 中观察到的 ossification 临界 size(O(10M))大两个数量级,作者用 Moravec’s Paradox 解读。
- Robotics 出现 power-law scaling:在 fixed downstream finetune budget 下,validation error 关于预训练数据量 D 满足 ,跨 16 个任务集一致——可定量回答”还需多少 pretraining data 达到目标 error”。
- Harmonic Reasoning:连续时间的异步 sensing/acting token 流,让单一大模型在物理时钟下”边想边动”,绕过 π0/Helix 等 dual-system 设计与 Real-Time Chunking 这类 inference-time trick。
- Data engine 是真护城河:270K 小时的 in-house manipulation 数据 + 10K 小时/周增长 + 全球数据采集网络,远超公开 robotics 数据集,是文中 scaling 结论成立的物质基础。
- Data 质量 > 数据量:8 种 pretraining 数据混合的 ablation 显示,prediction error 与 reverse-KL 共低的混合更适合 SFT,prediction error 高但 reverse-KL 低的混合更适合 post-training RL(多模分布有利于探索)。
Teaser. GEN-0 模型在多种长程灵巧操作任务上的 demo 集锦。
Background:Why scaling laws for robotics
Robotics 领域过去主要靠 vision-language pretraining 转移语义泛化能力(如 PaLM-E 一脉),但缺少在机器人本域建立 scaling laws 的证据:模型/数据/算力增加是否带来可预测的能力增长?这一直是 LLM 范式的核心,也是 robotics 一直缺的部分。GEN-0 的核心 claim 是:在足够大的真实数据规模上,他们看到了和 LLM 类似的 scaling 行为,但临界模型规模显著高于 LLM——这指向 Moravec’s Paradox 的一种实证形式:人类觉得 effortless 的感知和灵巧操作,反而需要更多 compute。
Body 的核心论点按四块展开:(i) Intelligence threshold / ossification、(ii) Pretrain → post-train scaling laws、(iii) Data engine、(iv) Science of pretraining。
Surpassing the Intelligence Threshold
作者扫描 1B / 6B / 7B 三个模型尺寸,在一个完全 held-out(zero-shot)的长程下游任务上看 next-action validation prediction error 随 pretraining compute 的演化。结论:
- 1B:训练越久,validation error 反而上升或停滞——典型 ossification(模型权重无法吸收新信息)。
- 6B:受益于 pretraining,多任务能力开始显现。
- 7B+:可以”内化”大规模预训练数据,下游只需几千 step 的 post-training 就能迁移。
Figure 1. 不同模型尺寸在 held-out 下游任务上的 zero-shot prediction error 随 pretraining compute 演化。1B 出现明显早期 ossification,6B 与 7B 依次解锁吸收能力。x 轴对 GEN-0 7B 的 compute 归一化。
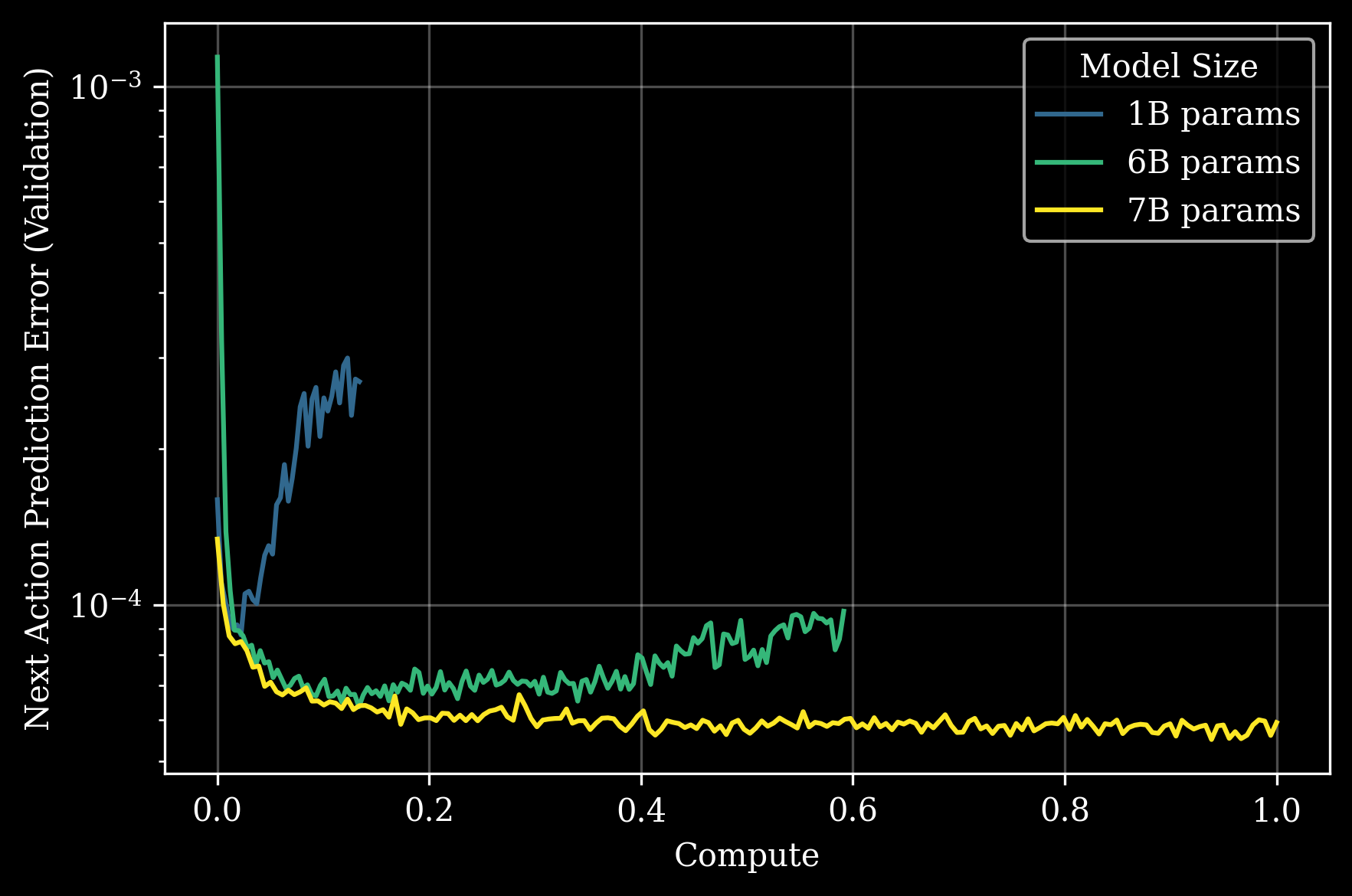
❓ 这里的 ossification 定义和 LLM 文献略有不同:原本指 pretrain→finetune 阶段的”被冻结”现象(Springer et al., 2025),作者在 footnote 8 也承认他们说的是纯预训练阶段 zero-shot 泛化能力的退化。这个换了语境的术语借用值得警惕——是同一现象还是只是命名相似?文中没有给出 weight-level 的诊断(比如 effective rank、gradient norm 等)证据,目前是行为层面的观察。
❓ 为什么阈值正好在 7B?是数据多样性的函数还是某种本征属性?文中没有给 6.5B / 7.5B 等更细的扫描。“phase transition” 是个强 claim,但只有 3 个 size 的 evidence 支持。
文章已说他们把模型 scale 到了 10B+,并观察到”越来越少 post-training”的 fast adaptation——但这部分没有给具体数字或图。
Scaling Laws for Robotics
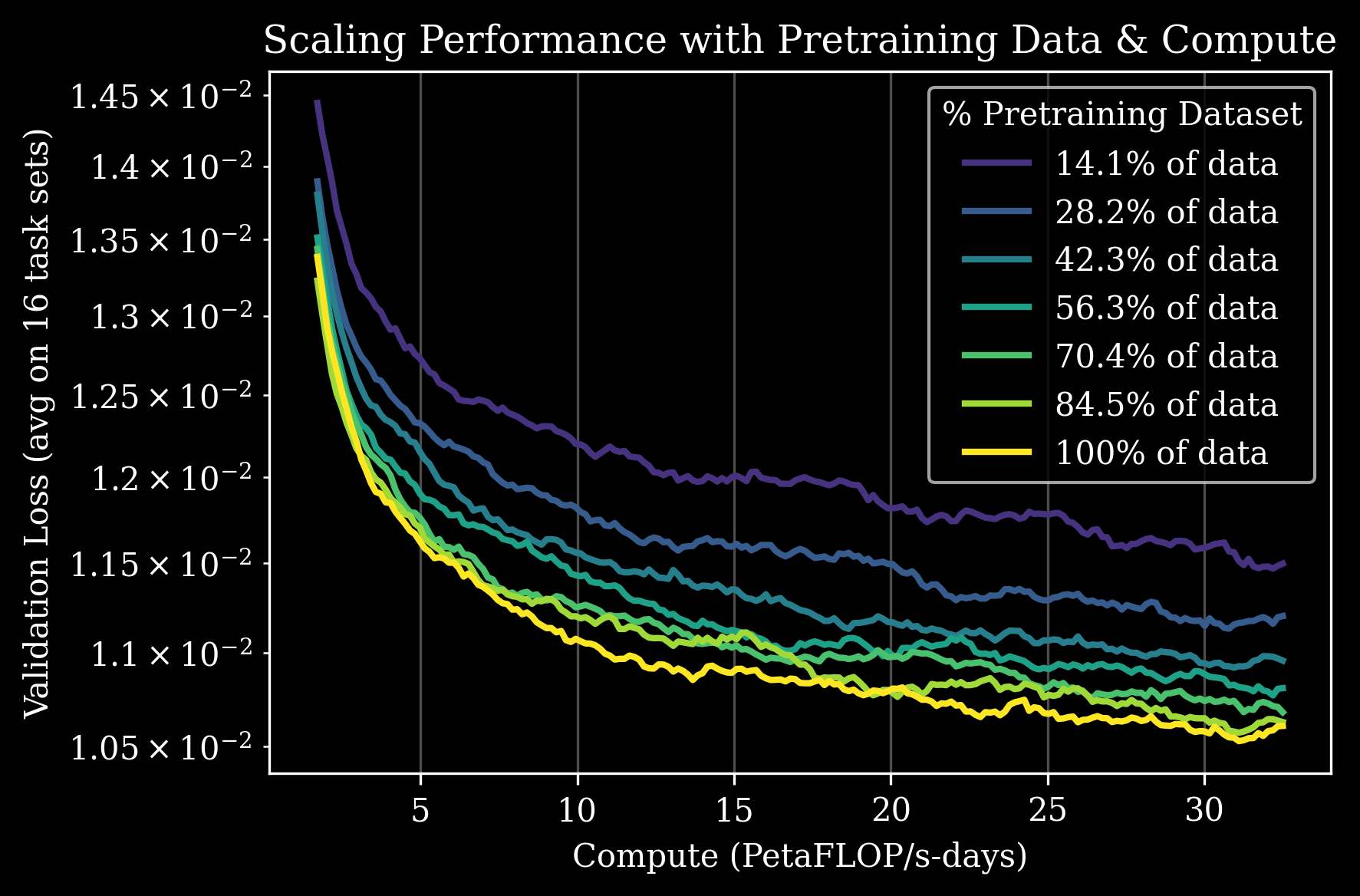
第二类 scaling law 关注:pretraining 收益是否能持续传到 post-training(finetune)。作者:
- 取一系列在不同子集大小预训练的 GEN-0 checkpoint。
- 对每个 checkpoint 用同样的 multi-task language-conditioned 数据做 post-training(一次 SFT 16 个任务集)。
- 评估每个任务集的 validation loss 与 next-action prediction error。
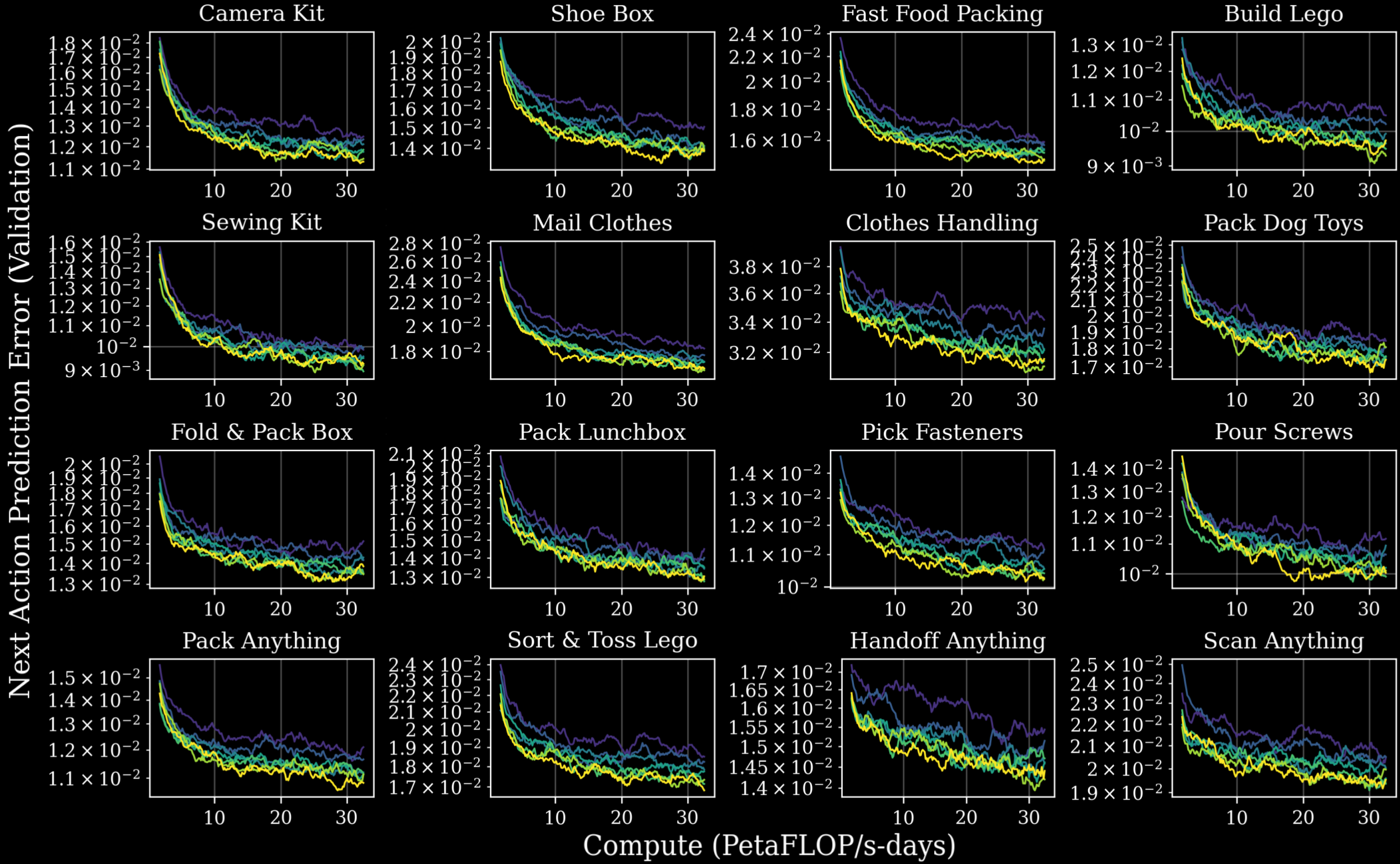
Figure 2. 16 个任务集上,pretraining 数据量越大(不同颜色),post-training 后的 multi-task validation loss(top)和 next-action prediction error(bottom 4×4 grid)越低。任务覆盖灵巧度(搭乐高)、行业 workflow(fast food packing)、泛化(”_ anything”)。
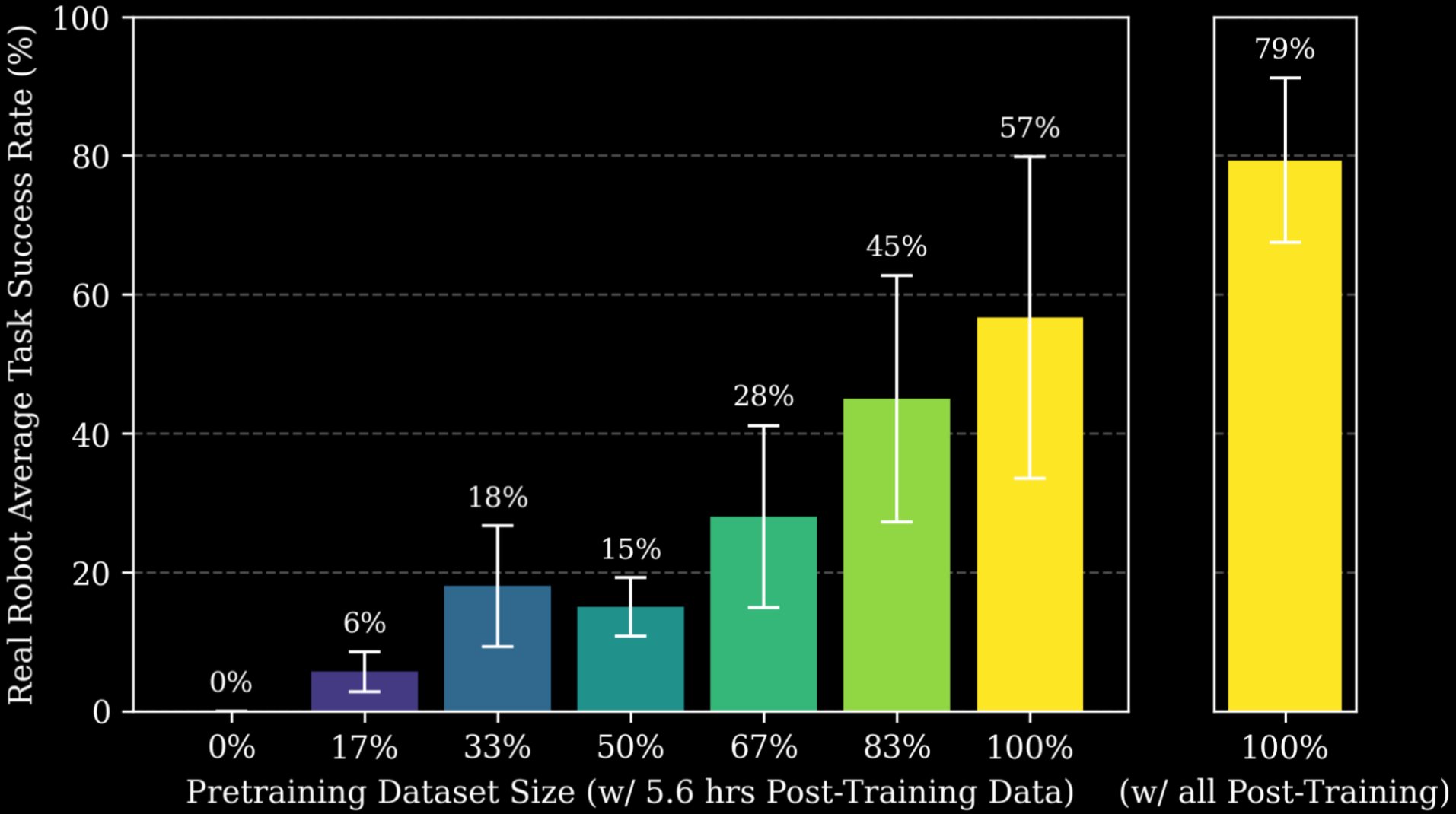
进一步在真实机器人上做 blind A/B 评估,验证 validation error 的改善能转化为成功率:
Figure 3. 真实机器人 closed-loop 评估。颜色表示不同 pretrain 规模的 checkpoint。左:仅 5.6 小时(1%)task-specific post-training 数据;右:full pretrain + 550+ 小时 task-specific 数据,最佳模型可达 99% 峰值成功率。注意 pretrain 数据与 post-train 数据由不同人在不同环境采集,确保无 overlap。
最后给出显式的 power-law 形式。给定固定的 finetune budget 与下游任务,预训练数据量 D 与 validation error 的关系:
Equation 1. Pretraining-data scaling law for downstream task error
符号说明: 是预训练数据集大小(以 action trajectories 数计), 是 task-specific 临界常数, 是 task-specific 指数。 含义:定量预测”达到给定 prediction error 需多少 pretraining data”,并与 post-training data 形成 trade-off。
Figure 4. 衣物处理(Clothes Handling:分拣、抚平、扣纽扣、挂衣)任务上的 scaling law 拟合。可外推到 1B action trajectories。
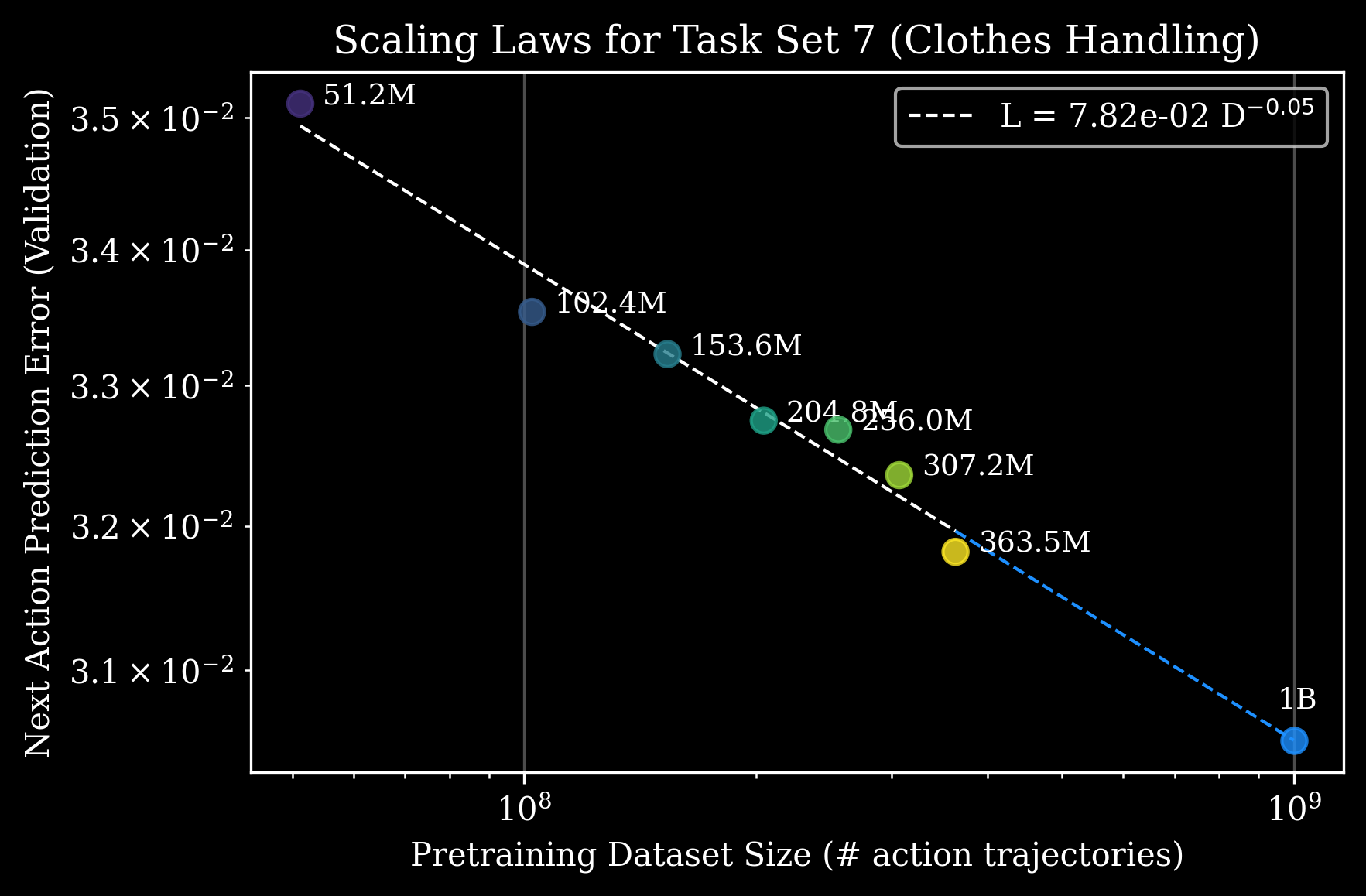
❓ Figure 2 和 Figure 4 用的 metric 都是 next-action prediction error / validation loss,不是真实机器人成功率。Figure 3 才是真机评估,但只显示离散柱状对比,没有拟合 power law。如果拿真机成功率拟合 power law,曲率与外推可信度可能完全不同——LLM 文献里 cross-entropy 与 downstream metric 的 scaling law 也有显著 mismatch(如 emergent abilities 之争)。这是论文论证链中最弱的一环。
❓ “no overlap between pretraining and post-training datasets” 这个 protocol 很关键,但 overlap 的定义只在 collector 和环境层面排除——任务、技能、物体类别层面的隐性重叠如何控制?没有说明。
Robotics is No Longer Limited By Data
GEN-0 的真正”杀手级”卖点是数据规模:
- 270K 小时真实操作数据
- 1000+ 家庭、仓库、工作场所
- 全球 1000+ 数据采集设备和机器人
- 增长速度 10K 小时/周(且加速)
- 训练吞吐:每天可消化 6.85 年的真实操作经验
Figure 5. GEN-0 训练数据相比已知最大公开 robotics 数据集的对比(截至 2025-11)。
为支持这一规模,他们自建了硬件、dataloader、网络(包括”laying new dedicated Internet lines”)、O(10K) cores 的多模态数据处理流水线、数十 PB 的压缩存储,并复用前沿 video FM 的数据加载技术。
❓ 这是 closed-source 的”data moat”叙事——外界无法验证数据规模与多样性的真实结构。如果这些 claim 属实,单一公司的数据规模已超过整个公开 robotics 学术社区的总和,对开源研究的相对位置是结构性挑战。
Mapping the Universe of Manipulation
作者展示了一个内部数据探索工具,对预训练数据的语言标签 embedding 做 t-SNE,可以按文本检索附近区域的 trajectory:
Video 1. <1% 预训练数据的 t-SNE 可视化导航工具,演示按文本描述检索最近邻区域并随机采样视频。
Science of Pretraining
更有意思的是 ablation:他们与多个 data foundry 合作伙伴各自按不同 collection 方法(Class 1 = task-specific、Class 3 = do-anything、Class 2 = 中间)采集数据,比较各 mixture 在 10 个长程下游任务上的表现,分为 Dexterity / Applications / Generalization 三个维度。
衡量指标除了常规 prediction MSE,还引入了 reverse KL:
Equation 2. Reverse KL 的 Monte-Carlo 估计
符号说明: 是 policy 在 个采样 action 上构造的 unit-variance Gaussian 混合(mode-seeking 视角), 是以 ground-truth 为均值的 unit-variance Gaussian。 含义:reverse KL 偏好 mode-seeking,因此能捕捉 policy 是否分布性地”贴住”ground-truth 模式,而 forward KL 则偏好 mode-covering。这是 imitation learning 的 f-divergence 视角的延伸(Ke et al., 2020)。
Table 1. 不同 pretraining 数据混合(partner × class)在 10 个下游任务集(按 Dexterity / Applications / Generalization 分组)上的 finetune 后 prediction error 和 reverse KL(数值越小越好)。
| Partner & Class (Pred Err) | Dexterity | Applications | Generalization |
|---|---|---|---|
| Partner A Class 1 | 0.00307682 | 0.00334155 | 0.00308992 |
| Partner A Class 2 | 0.00306196 | 0.00333253 | 0.00306503 |
| Partner A Class 3 | 0.00305728 | 0.00331309 | 0.00305888 |
| Partner A Class 2 + 3 | 0.00315980 | 0.00341899 | 0.00315661 |
| Partner B Class 1 | 0.00302728 | 0.00330365 | 0.00304627 |
| Partner B Class 2 Objs | 0.00314415 | 0.00341147 | 0.00315975 |
| Partner B Class 2 Skills | 0.00301995 | 0.00329235 | 0.00305292 |
| Partner C Class 3 | 0.00306247 | 0.00332128 | 0.00307944 |
| Partner & Class (Rev KL) | Dexterity | Applications | Generalization |
|---|---|---|---|
| Partner A Class 1 | 0.00200585 | 0.00258898 | 0.00198088 |
| Partner A Class 2 | 0.00188744 | 0.00244642 | 0.00193866 |
| Partner A Class 3 | 0.00198332 | 0.00246089 | 0.00190205 |
| Partner A Class 2 + 3 | 0.00184110 | 0.00228588 | 0.00185473 |
| Partner B Class 1 | 0.00189286 | 0.00246051 | 0.00192307 |
| Partner B Class 2 Objs | 0.00184719 | 0.00233209 | 0.00186721 |
| Partner B Class 2 Skills | 0.00182561 | 0.00242293 | 0.00190308 |
| Partner C Class 3 | 0.00192134 | 0.00236901 | 0.00190956 |
经验观察:
- 低 pred err + 低 reverse KL → 适合 SFT post-training(model 既精确又分布贴近 ground-truth 模式)
- 高 pred err + 低 reverse KL → 分布更 multimodal,适合 post-training RL(多模分布留出探索空间)
❓ Table 1 数值差异极小(pred err 在 0.00302–0.00316,差不多 5% 的相对差距)。在 low-noise validation 下这种差距是否真的能 robustly 转化为 post-training 后的 task success 差距?文中并没有给真机评估佐证 Table 1 的排序——和 Figure 3 一样,最关键的 downstream 真实指标在最关键的 ablation 上缺席。
Demos
文章嵌入了多段 demo 视频,展示长程操作任务,例如组装相机包装:
Video 2. Build a camera kit (top view):把清洁布放进盒子、折入卡纸托盘、从塑料袋中取出相机、放入盒中、合上盖子(含小翻盖)、最后丢弃塑料袋。模型不维护任何显式 subtask 概念,整个长程任务在单一 harmonic reasoning 流中完成。
其他展示(手机打包、相机包装侧视/POV、乐高组装、紧固件拼接、盒装打包等)参见原文。
关联工作
基于
- PaLM-E:作者在开篇明确把 GEN-0 定位为”超越 vision-language pretraining 转移路径”的下一步。
- Kaplan & McCandlish (2021), Scaling Laws for Neural Language Models:本文 scaling law 形式 直接借自 LLM scaling law 文献。
- Hernandez et al. (2021), Scaling Laws for Transfer:pretraining → finetune scaling 的语境来源。
对比
- π0 / π0.5:同一时代的 generalist VLA。GEN-0 在文中没有直接 benchmark 对比,但 Harmonic Reasoning 的设计明确针对其 dual-system / inference-time chunking 路径。
- Figure Helix:作者点名”我们不需要 System1-System2 架构”。
- π0 团队的 Real-Time Action Chunking Flow Policies (Black et al., 2025):作者点名”我们不需要 inference-time guidance”。
- OpenVLA / Octo:作为开源 VLA 的对照,文中未提及,但显然是隐性对比对象。
方法相关
- Imitation learning as f-divergence minimization (Ke et al., 2020):reverse KL 作为 mode-seeking metric 的理论根据。
- Springer et al. (2025), Overtrained Language Models Are Harder to Fine-Tune:ossification 的 LLM 侧参考。
- Moravec’s Paradox:作者用以解读”为什么 robotics 的 intelligence threshold 比 LLM 大两个数量级”。
- 后续工作:GEN-1(2026-04,承接 GEN-0 走向 mastery)。
论文点评
Strengths
- 首次以工业规模数据 + 系统 size sweep 在 robotics 中报告 scaling laws——即使方法细节不公开,仅这一观察就有研究价值,是后续 community 必引的对照点。
- Ossification 这一现象在 robotics 中的首次报告有方法论意义:它说明在 high-data regime 下 robotics 的 model size “下限”远高于 LLM,对小规模 VLA 研究的 implications 是负面但重要的(“模型不够大就吸收不动”)。
- Reverse KL 区分 SFT-friendly vs RL-friendly 数据这一观察具有方法论 actionable 性,是少有的”data-centric ablation”产出可指导后续操作的 takeaway。
- Power-law 形式公开给后续研究留了 reproducibility 的接口——别人可以用自己的小规模数据验证拟合形式是否成立。
Weaknesses
- 零方法细节:架构(“decoder-only 多模态”以外)、token 化方案、Harmonic Reasoning 的具体训练 objective、loss、采样、连续时间机制——全部没说。“Harmonic Reasoning” 仍是 marketing term,不是可复现 method。
- 关键论点的 grounding 弱:
- 7B 相变只有 3 个 size 数据点支持。
- Power-law 拟合用的是 prediction error 而非 task success rate;二者在 LLM 文献中也有显著 gap。
- Table 1 ablation 没有真机 success rate 验证。
- Ossification 术语借用越界:作者自己在 footnote 8 承认与 LLM 文献定义不同,但仍沿用同一标签——容易在二手传播中被误读。
- Closed-source data + closed-source model:所有 claim 不可外部验证,这是一篇 corporate technical announcement 而非 paper。reader 必须降低 prior。
- 没有与同时期 open VLA(如 π0、OpenVLA、Octo、π0.5)做任何对比——这种 isolation 让”breakthrough” 的相对量级无法判断。
可信评估
Artifact 可获取性
- 代码: 未开源
- 模型权重: 未发布
- 训练细节: 未披露(仅 10K cores、PB 级压缩等基础设施性描述)
- 数据集: 私有(in-house,270K 小时)
Claim 可验证性
- ⚠️ “7B 处出现 phase transition”:仅 3 个 size 数据点(1B/6B/7B),术语借用 LLM 文献存在歧义;行为层面观察,无 weight-level 诊断。
- ⚠️ “power-law scaling for robotics”:metric 是 validation error 而非真机成功率;fit 在文中只展示一例(Clothes Handling)。
- ⚠️ “99% 峰值成功率”:未指明任务、评估场景、试验次数和置信区间。
- ⚠️ “data quality > volume”:Table 1 数值差极小(约 5%),缺乏真机 follow-up。
- ❌ “a new era of embodied foundation models” / “breakthrough fundamental capabilities”:营销 framing,不是技术 claim。
- ✅ “270K 小时数据规模 + 10K 小时/周”:可独立交叉验证(媒体已报道、视频展示数据采集流程),与公开 robotics 数据集的相对量级判断是 sound 的。
Notes
这篇把 robotics 是否存在 scaling laws 这个 vibe-level 判断推到了有可测形式的实证层面。即使方法不公开、claim 不能完全验证,关于 ossification 临界 size、pretrain → post-train 的 power-law、和 reverse-KL 区分 SFT/RL 友好数据的三个观察,都是后续做 data-centric VLA 研究、思考 model-size 选择时必须考虑的对照点。它不是 method paper,但改变了”我应该建多大的 VLA、收多少数据才有意义”的判断框架。
对我自己研究的 implications:
- 任何 ≤3B 的 VLA 实验都要警惕 ossification——尤其当数据 diverse 时,“训练越久越差”可能不是 bug 而是结构性问题。
- 报告 VLA 方法时,应该把数据量与模型 size 的 trade-off 当作一阶变量而非 footnote。
- Reverse-KL 作为 imitation 数据集 selection 的 metric 值得在小规模复现上试一下:如果 SFT-friendly vs RL-friendly 的二分真的成立,对于”该用 BC 还是 RL”的问题就有了 data-side 的判据。
追问 / 待查:
- GEN-1 (2026-04) 的发布是否给出了 GEN-0 没说的方法细节?
- Harmonic Reasoning 与 streaming VLA 工作(如 StreamVLN)在思路上的异同?
- 7B 相变的 follow-up 复现尝试:开源社区有没有人在自己更小的数据规模上看到过类似 ossification?
Rating
Metrics (as of 2026-04-24): citation=N/A (non-arxiv release), influential=N/A, velocity=N/A; HF upvotes=N/A; github=N/A (无代码仓库)
分数:3 - Foundation 理由:本笔记 Strengths 已列出三项社区级别 implication——首次在 robotics 报告 scaling laws、首次报告 ossification 临界 size、Reverse-KL 区分 SFT/RL 友好数据——都是后续 data-centric VLA 研究无法绕过的对照点;关联工作段明确写出 GEN-1 已承接该 agenda,方向连续性成立。不是 2-Frontier,因为它不是某个任务的 SOTA baseline,而是改变了”模型 size / 数据量”这一阶 trade-off 的判断框架;不降为 1-Archived,是因为即便 closed-source,它仍是 “robotics scaling laws” 这一议题的首要引用节点。2026-04 复核:因是 Generalist AI blog 而非 arXiv,s2 无 citation 追踪;无 HF/github 可核对社区采纳——但 GEN-1 (2026-04) 已在 vault 内作为 follow-up 出现,且 robotics scaling laws 议题在过去 5 个月里确实是后续 VLA data-centric 讨论的常引节点;Foundation 档的判断主要落在 “议题锚点” 而非 cite 数上,metric 缺失不影响判断。