Summary
Room-Across-Room (RxR): Multilingual VLN with Dense Spatiotemporal Grounding
- 核心: 一个比 R2R 大 10× 的多语言 VLN benchmark——126K 指令 × {en, hi, te},路径平均 14.9 m / 8 edges(vs R2R 的 9.4 m / 5 edges),每条指令都带 word-level 与 viewpoint-level pose trace 对齐,主评测指标从 SR/SPL 切到 nDTW/sDTW(path fidelity)。
- 方法: Two-level path sampling(room-graph → panorama-graph + greedy coverage)刻意打破 R2R 的”shortest path / 直线 prior”;Guide annotator 边走边说,annotation tool 同步记录 6-DoF pose 和 ASR-aligned 文本时间戳;Follower 听音频复现路径,pose trace 也保留作为额外训练信号。
- 结果: 多语言 RCM-style baseline 在 val-unseen 上 SR ≈ 22-23 / nDTW ≈ 38-40(人类 SR ≈ 90-97 / nDTW ≈ 78-82),头顶空间巨大;monolingual > multilingual > MT-cross-translation;Guide+Follower 路径联合训练全 metric 提升;R2R↔RxR transfer 失败但多任务训练在两个 dataset 上都最好。
- Sources: paper | website | github
- Rating: 3 - Foundation(VLN 子领域 de facto 第二大 benchmark,nDTW/sDTW 作为 path-fidelity 主指标的奠基,社区移植成的 RxR-CE 是 ETPNav / NaVid / NaVILA / StreamVLN / NavFoM / Efficient-VLN / PROSPECT 的标配评测)
Key Takeaways:
- Path biases 是 R2R 的隐藏作弊面: R2R 全是 start→goal 的最短路径且长度集中在 4-6 edges,agent 学到 “go straight” prior 就能拿到不平凡 SR。RxR 用 two-level sampling 显式破坏这个 prior(44.5% 路径非 shortest,平均比 shortest 长 27.4%,长度从 ~5 到 ~20 edges 高方差)。“random-heading-then-go-straight” baseline 在 R2R 上 SR=8.2、在 RxR 上只有 8.0 但 nDTW 从 28.3 跌到 16.3——长指令 + 弯路让 path-fidelity 类 metric 真正分得开。
- Pose trace = word-pixel level dense alignment: Guide 边在 simulator 里走边说话,tool 记录 6-DoF camera pose 时间戳;之后 annotator 自己转写音频,再用 ASR + DTW 把转写文本时间戳化。结果是一个**“每个词在哪个 viewpoint / 视角朝向被说出”** 的 ground truth, 可以投回 panorama 的 2D heatmap 或 3D semantic mesh。这是 R2R 完全没有的 supervisory signal——R2R 后续的 sub-instruction-to-viewpoint 对齐(如 FGR2R, Hong 2020)都是事后人工标的。
- nDTW/sDTW 是为 RxR 量身定的指标: SR 在长弯路 + 大方差长度下退化(agent 走错很远但终点恰好在 3m 内也算成功);SPL 用 path length 归一但只看终点。nDTW = 1 / mean DTW distance to ground-truth trajectory,sDTW = nDTW × SR,明确惩罚 fidelity 偏离。RxR 论文显式声明 “we focus primarily on NDTW and SDTW”——把社区注意力从 goal-reaching 拽向 instruction-following。
- Multilingual ≠ multilingual win: 把三种语言混训(experiment 4)反而比 monolingual(experiment 3)差(~3-7 SR/nDTW points),机器翻译的 cross-translation 反而再降一档(experiment 5)。这复现了 multilingual MT/ASR 里”高资源语言被稀释”的现象,但说明纯靠 scale + 翻译对 grounded language 学不到 transfer。
- Annotator 行为本身是数据: Fig. 5 显示 Guide / Follower 在每个 viewpoint 平均只观察 27% 的全景,远小于 一般 VLN agent 默认 attend 整个 panorama 的假设——这是为 visual attention supervision 提供 evidence-based prior 的依据,但论文自己实验(exp. 6)显示 supervise visual attention 给 mixed results(NDTW 涨、SR 跌),说明这个先验和 RL/SR 优化目标存在张力。
Teaser. RxR 把 annotator 的 virtual pose 与口述指令对齐到 Matterport mesh 上

Fig. 1 把一条 RxR 指令展示在 Matterport3D 室内 mesh 的鸟瞰里:彩色路径是 Guide 走过的 viewpoints,文本气泡里的词被着色对应到说出该词时 Guide 所在的 viewpoint 与朝向。这种”词→3D pose 对齐”是 RxR 区别于所有先前 VLN dataset 的核心 artifact。
1. Motivation:R2R 的四个 gap
VLN 的标准 setup 自 R2R (Anderson 2018b) 起就被 4 个性质卡住,RxR 一一对应解决:
| 维度 | R2R | RxR | 解决方式 |
|---|---|---|---|
| 语言 | 单一英文 | en (US/IN) + hi + te | 三个 typologically diverse 语言独立采集,非翻译 |
| 规模 | 22K instr | 126K instr / 9.8M words | 14K paths × 3 instr × 3 lang |
| Grounding 粒度 | 段落级(与 viewpoint sequence 对齐) | 词级(与 6-DoF pose 时间戳对齐) | 边说边录音,ASR + DTW 时间戳化 |
| 路径分布 | shortest 4-6 edges | high-variance, 非最短 | Two-level room-graph sampling + greedy coverage |
| Demonstrations | 仅 Guide instruction | Guide + Follower pose trace | Follower 验证 + 数据增益 |
为什么 multilinguality 是关键?论文引 Munnich (2001), Haun (2011), Bender & Beller (2014) 论证不同语言对接触/支撑关系、reference frame(egocentric vs allocentric)、时态指代有不同编码方式——这些恰好是 navigation instruction 的核心要素。en/hi/te 三个语系(Indo-European Germanic / Indo-European Indo-Aryan / Dravidian)各异,把”VLN model 是否真在做语言 grounding”从 anglocentric 假设里解放出来。
❓ 但论文的 Table 3 已经显示,allocentric relation 比例在 hi (68%) / te (76%) / en-IN (92%) 都比 en-US (76%) 高,coreference 在 hi (40%) / en-US (64%) / te (76%) 也差异巨大——这究竟是语言的差异,还是annotator pool 习惯的差异?论文自己也承认 “not clear how much … can be attributed to language, dialect, annotator pools, or other factors”。这是个 confound,讨论 multilingual VLN 时要小心。
2. Two-Level Path Sampling
RxR 路径要满足 4 个 desiderata:(a) 长度高方差;(b) 允许 indirect approach;(c) 自然(不绕圈、不频繁折返);(d) 视点覆盖均匀。直接在 panorama graph 上随机采样很难同时满足,论文设计了两层采样。
Figure 2. Two-level path sampling: 先在 room graph 上采 simple path,再在每个 room 内取 panorama 最短路径
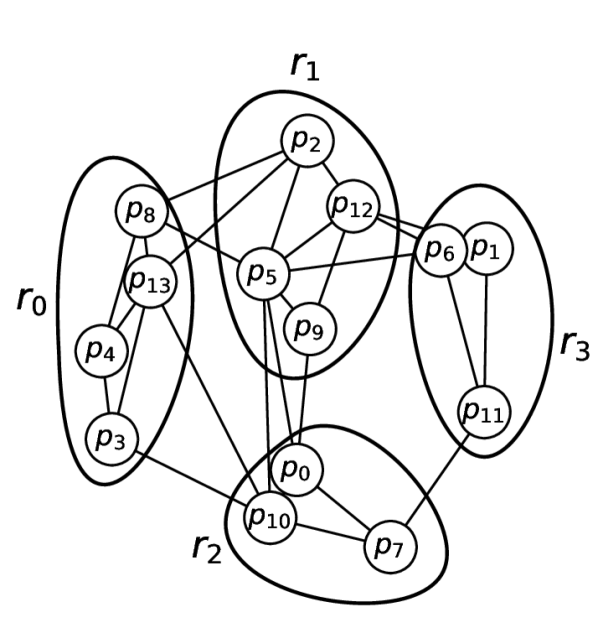
Preliminaries
- :panorama navigation graph,节点是 360° 全景图(约每 2.2 m 一个),90 个 indoor environments
- :MP3D 提供的 human-defined room 划分,每个 room 是 节点的非重叠子集
- :room graph,节点是每个 room 的连通分量, 之间有边当且仅当合并子图连通
Path Generation
枚举 上最多 5 个 rooms / 跨 2 个 building level 的所有 simple paths 。给定一个 room path:
- 在 (被 room path 限制的 panorama 子图)里
- 随机从 取 start ,从 取 goal
- panorama 路径 取 start→goal 在 里的最短路径
为什么这样设计:room 大小变化大(卧室 vs 客厅),room path 限制保证 naturalness(人倾向于按 room 描述:“穿过这扇雕花木门”),且最短路径在 room graph 而非 panorama graph 上算 → panorama graph 上的最终路径不一定是全局最短路径,自动满足 desideratum (b)。
Greedy Coverage Selection
从所有候选路径里,按
的最小值贪心挑选下一条加入数据集 。第一项 (直线距离 / 路径长度)偏小 → 偏好绕路;第二项是已选路径里 panorama 出现次数的均值 → 偏好覆盖低频 viewpoint。max path 40 m,每个 building 最多 500 paths。
Path Statistics
最终 16,522 paths:11,089 train / 1,232 val-seen / 1,517 val-unseen / 2,684 test,环境划分与 R2R 一致。
Figure 3. RxR vs R2R 路径分布对比
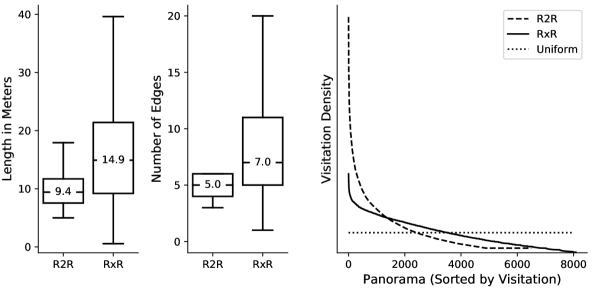
Fig. 3 同时展示三个对比:(1) 路径长度(米)的方差 RxR 远大于 R2R;(2) edges 数从 R2R 的 4-6 集中分布扩展到 RxR 的 4-20 长尾;(3) panorama 覆盖度更均匀(R2R 大量 viewpoint 从未被任何 path 覆盖)。
3. Data Collection
RxR 的 annotation tool 是论文真正的 engineering contribution,不只是采更多数据。
Guide Task
Guide 在 web-based MP3D simulator 里边走边口述指令(不像 R2R 是写)。Tool 同步记录:
- 6-DoF camera pose 时间序列(heading, elevation, position)
- 音频文件
- annotator 自己事后转写的高质量文本
文本和 pose 通过 Google Cloud ASR 输出 + DTW 对齐 → 得到 word-level timestamp,进而每个词关联到 Guide 当时的 6-DoF pose。这个流程灵感来自 Localized Narratives (Pont-Tuset 2020)——image captioning 里让 annotator 一边描述一边移动鼠标。
每语言 14K paths × 3 instr,其中 12.8K paths 在三种语言里共享(→ 跨语言对齐研究的天然 testbed),1.2K paths 各语言独有(→ 增加多样性)。Guide 任务平均 458 秒(60s 录音 + ~400s 转写)。
Follower Task
Annotator 听 Guide 的音频,在 simulator 里复现路径,可暂停 / 倒退 / 快进。完成后给 instruction 打分。Follower task 平均 132 秒。
质量控制流程:如果 Follower 没成功(终点 >3 m),换一个 Follower;再失败则重新生成 Guide+Follower 标注。最终保留三对里最成功的一个。这个 multi-pass 验证是 RxR human SR=93.9% 的关键。
Follower pose trace 也被记录——这给了第二条 grounding signal:同一条 instruction 下,人类听者怎么解读它,与 Guide 自己的 pose trace 对照。Fig. 4 给出 en-US 例子,Follower 路径稍长但 visual-textual alignment 模式与 Guide 类似。
Figure 4. Guide vs Follower 同一指令下的 pose trace 与全景图对齐

Dataset Statistics
Table 2. Per-language summary
| en-IN | en-US | en | hi | te | Total | |
|---|---|---|---|---|---|---|
| Instructions | 28010 | 13992 | 42002 | 42068 | 41999 | 126069 |
| Paths | 14005 | 13992 | 14005 | 14026 | 14003 | 16522 |
| Avg words | 87 | 129 | 101 | 76 | 56 | 78 |
| Avg WordPieces | 104 | 159 | 123 | 143 | 184 | 150 |
| Avg audio (s) | 64 | 80 | 69 | 53 | 58 | 60 |
平均 78 词 vs R2R 的 29 词,最长的 en-US 平均 129 词。用 wordpiece 衡量更公平(te 是黏着语,wordpiece 平均 184),不同语系拉到可比刻度。
语言学特征对比 (Table 3 摘要)
人工分析 25 paths 的 instruction,统计每种 phenomenon 在多少句子里出现 (%) 和平均出现次数 ():
| Phenomenon | R2R en | RxR en-US | 解读 |
|---|---|---|---|
| Reference (entity 提及) | 100% / 3.7 | 100% / 8.3 | RxR 长指令必然提更多 entity |
| Coreference | 32% / 0.5 | 64% / 5.3 | discourse coherence 远高 |
| Allocentric relation | 20% / 0.2 | 76% / 2.4 | ”桌子下方” 这种第三人称空间关系 |
| Egocentric relation | 80% / 1.2 | 60% / 2.3 | ”your left/right” 等同水平 |
| State verification | 8% / 0.1 | 84% / 3.1 | ”你应该在 balcony” 这种自检 |
| Temporal condition | 28% / 0.4 | 52% / 0.8 | ”until you see…” |
RxR 比 R2R 在 coreference / allocentric / state verification 三处量级跃升——这意味着光靠 R2R 训练的 model 对这些语言现象 underfit,难直接迁移到 RxR。这正是后面 Table 6 transfer learning 失败的语言学根源。
4. Evaluation Metrics
RxR 用 6 个 metrics:PL (path length), NE↓ (navigation error to goal), SR↑, SPL↑ (Anderson 2018a), nDTW↑, sDTW↑ (Ilharco 2019)。
为什么 RxR 必须用 nDTW/sDTW:
- SR / SPL 只看 goal 是否到达 / 路径效率,对走错弯路但凑巧到达不敏感。R2R shortest-path setting 下两者足够;RxR 路径绕行 27.4%,agent 完全可能”无视指令直奔终点”还拿满 SR。
- NDTW = ,其中 是 agent path 与 reference path 的 mean DTW distance, 是阈值(3 m)。它显式衡量 fidelity——绕远 / 抄近 / 错入 detour 都被 penalty。
- SDTW = NDTW × SR,结合 success 与 fidelity。是 RxR-CE leaderboard 的主排名指标。
Table 4. Simple baselines on val-unseen
| Setting | Dataset | PL | NE↓ | SR↑ | SPL↑ | SDTW↑ | NDTW↑ |
|---|---|---|---|---|---|---|---|
| Random walk | R2R | 10.4 | 9.5 | 5.1 | 3.6 | 3.8 | 27.6 |
| Random walk | RxR | 16.8 | 12.4 | 8.8 | 2.5 | 3.8 | 18.2 |
| Rand head + go straight | R2R | 9.7 | 9.9 | 8.2 | 7.2 | 6.6 | 28.3 |
| Rand head + go straight | RxR | 15.1 | 13.5 | 8.0 | 3.4 | 3.9 | 16.3 |
| GT first step + straight | R2R | 9.5 | 6.2 | 27.2 | 25.7 | 23.6 | 52.6 |
| GT first step + straight | RxR | 15.3 | 11.4 | 13.7 | 7.5 | 8.3 | 25.9 |
“给对第一步然后直走”在 R2R 拿 SR=27.2 / NDTW=52.6(接近半数 R2R 路径就是直线到目标),在 RxR 跌到 SR=13.7 / NDTW=25.9。这组 baseline 直接证明 R2R 的 shortest-path bias 给了 dumb agent 多大便宜,也说明 RxR 在结构上拒绝了这种 free lunch。
5. Baselines & Experiments
Agent 架构
类 RCM (Wang 2019) 的 LSTM decoder + dot-product attention,但因 RxR 指令长(平均 78 词),把 bidirectional LSTM instruction encoder 换成更并行的 CNN encoder(1D conv + ReLU + residual)。Word embedding 来自预训练 multilingual BERT(同一个 BERT cover 所有三种语言)。
视觉 encoder:EfficientNet-B4,预训练用 Conceptual Captions image-text dual encoder 而非 ImageNet classification——论文报这给”noticeable improvements”,与 VLN survey 里 “in-domain VL pre-training > 通用 ImageNet” 的结论一致。
主要实验结论
Table 5. Monolingual vs multilingual on val-unseen
| Exp | Method | G | F | X | NE↓ (en/hi/te) | SR↑ (en/hi/te) | NDTW↑ (en/hi/te) |
|---|---|---|---|---|---|---|---|
| (1) | Mono | ✓ | 10.1/9.7/9.4 | 25.6/24.8/28.0 | 41.3/38.8/43.7 | ||
| (2) | Mono | ✓ | 10.3/9.2/9.5 | 23.9/28.0/27.0 | 37.0/45.9/43.9 | ||
| (3) | Mono | ✓ | ✓ | 9.8/9.2/9.1 | 26.1/29.6/29.8 | 42.4/45.5/45.6 | |
| (4) | Multi | ✓ | ✓ | 11.0/10.9/11.0 | 22.2/23.0/23.1 | 38.6/39.2/38.8 | |
| (5) | Multi | ✓ | ✓ | ✓ | 11.5/11.4/11.4 | 20.0/18.7/20.3 | 36.3/36.0/36.7 |
| (6) | Multi* | ✓ | ✓ | 11.0/10.7/10.7 | 21.9/22.6/23.2 | 38.6/39.9/39.7 | |
| (H) | Human | 1.3/0.6/0.8 | 90.4/96.8/94.7 | 77.7/82.2/79.2 |
(G = Guide path / F = Follower path / X = MT cross-translation; Multi* = + visual attention supervision from pose traces)
四个核心观察:
- Guide + Follower 联合训练 (3) 全面超过单独 (1) 或 (2):Follower path 提供了”同一指令下的不同有效路径”,data augmentation 效果稳。
- Monolingual (3) > Multilingual (4) ~ 3-7 points across metrics: 多语言混训稀释了高资源语言,复现 MT/ASR 经典现象。
- 加 MT cross-translation (5) 进一步降: 翻译噪声 + 大多数 Guide path 已被三种语言原生覆盖 → 翻译对增量信息少,反而引入分布噪声。
- Visual attention supervision (6) mixed: NDTW 略涨(38.6→38.6/39.9/39.7)但 SR 略跌——supervision 把 agent 的 attention 推向”人类实际看的部分”,这是更 faithful 的信号但与 RL reward (NDTW + NE) 不完全对齐,揭示 SR-driven 训练目标和 fidelity-driven 数据信号的张力。
Table 6. Multitask R2R + RxR
| Exp | R2R train | RxR train | R2R SR | en SR | hi SR | te SR |
|---|---|---|---|---|---|---|
| (7) R2R only | ✓ | 36.5 | 14.5 | 9.6 | 9.7 | |
| (4) RxR only | ✓ | 19.2 | 22.2 | 23.0 | 23.1 | |
| (8) Both | ✓ | ✓ | 37.8 | 22.5 | 23.6 | 23.1 |
Multitask (8) 在两个 dataset 上都最好,但 transfer (R2R→RxR 或 RxR→R2R) 比 in-domain 差很多——RxR 长指令 + 弯路 + 多语言对 R2R agent out-of-domain,反向 R2R agent 在 RxR 上无法 exploit shortest-path bias。这是支持 “RxR 才是真正测试 grounded language understanding 的 benchmark” 的关键证据。
Unimodal ablation (Table 7): vision-only SR=7.8 vs language-only SR=16-18 vs full SR=22-23——语言占主要信息。原因:即使没视觉,“turn left” / “go upstairs” 在 navigation graph 拓扑里仍部分可解(限定了候选 viewpoint)。这也是 RCM-style baseline 的局限——视觉信号在长指令下没充分利用。
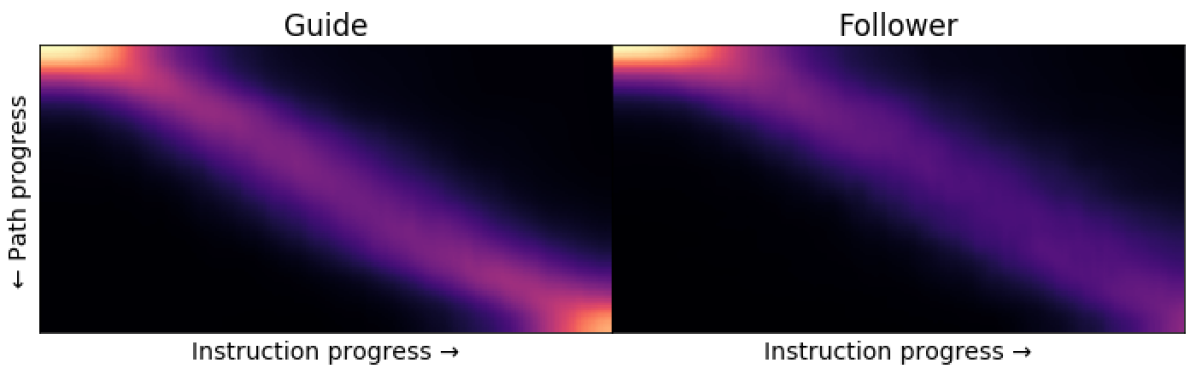
Pose trace 的 attention 统计 (Fig. 5): Guide / Follower 在第一个 viewpoint 平均观察 43% / 44% 的 panorama,后续 viewpoint 只看 27% / 28%。远低于 标准 VLN agent 默认 attend 整张 panorama 的假设。这是论文留给后续工作的重要 evidence——agent 应该学会选择性观察,而不是 panorama-wide attention。
Figure 5. 上:Instruction progress vs path progress 对齐;下:Guide/Follower 在 panorama 上的注视 heatmap(centered on initial perspective)
Test split
Test 分 test-standard / test-challenge 两个 split, 长期保留作为 leaderboard 评测,对应 RxR-Habitat Challenge(CVPR 2022 起)。
6. RxR-CE:社区移植到连续环境
⚠️ 这部分不在本论文里,但理解 RxR 在 2026 年的影响必须提到。
原 RxR 仍在 panorama navigation graph 上(discrete VLN),与 R2R 同 setup。社区(VLN-CE 框架, Krantz 2020)将 RxR 路径移植到 Habitat 连续环境:每个 panorama → 3D Matterport mesh 上的位置;动作变为 FORWARD 0.25 m / TURN 15° / STOP 的 low-level control。
RxR-CE 关键设定(与 VLN-CE 不同):
- Chassis radius 0.18 m(VLN-CE 是 0.10 m)—— agent 体型更大,更容易卡墙
- Sliding forbidden —— 撞墙后不能贴墙滑行(VLN-CE 允许)
- Path 平均 14.9 m(VLN-CE 9.89 m)—— 长程导航 + 障碍避让难度叠加
这三个性质让 RxR-CE 成为所有现代 VLN-CE 方法的核心试金石。ETPNav 用 Tryout 解决 sliding-forbidden deadlock 在 RxR-CE 上拿 51.21 SR / 41.30 SDTW (test-unseen),比前任 CWP-RecBERT +26.36 SR / +22.25 SDTW,是 VLN-CE 史上最大单步跃升之一。后续:
| 方法 | RxR-CE val-unseen SR | 备注 |
|---|---|---|
| ETPNav | 54.79 | topological planner + Tryout |
| NaVid | ~45 | video-LLM, monocular RGB |
| NaVILA | ~50+ | dual-system VLA |
| StreamVLN | ~60+ | streaming video VLA |
| NavFoM | 64.4 | VLN foundation model |
| Efficient-VLN | 67.0 | efficient streaming VLA |
| PROSPECT | 60.3 | prospective planning |
nDTW/sDTW 在 RxR-CE 上的角色更重要:sliding-forbidden + 长指令 + 大底盘让 SR-only 优化容易陷入”绕一大圈到达”的解,nDTW penalty 把这类解过滤掉。RxR-CE leaderboard 排名以 nDTW(或 SDTW)为主。
关联工作
基于
- R2R (Anderson 2018b):VLN 起点 benchmark,RxR 是其 superset / 升级版,path 设计直接对标其 shortcoming
- Localized Narratives (Pont-Tuset 2020):image captioning 里 mouse-pointer + speech 的 dense alignment idea, RxR 把它升级到 3D 环境
- RCM (Wang 2019): baseline agent 架构来源
- Conceptual Captions (Sharma 2018) + EfficientNet (Tan & Le 2019): 视觉 encoder 预训练
- VALAN (Lansing 2019): 训练框架
- NDTW / SDTW (Ilharco 2019): metric 来源——RxR 把它从可选指标抬到主指标地位
- DTW for ASR-text alignment: Google Cloud Speech-to-Text + DTW 做 word-pose 对齐
对比
- R2R: 直接对照(Table 1, Table 4, Fig. 3)
- CVDN (Thomason 2019b): dialogue-based VLN, instruction 数量更小
- Touchdown (Chen 2019): outdoor VLN, 长指令但单语言
- REVERIE (Qi 2020): goal-oriented VLN with object grounding
- ALFRED (Shridhar 2020): 合成环境 + manipulation, 不是 photo-realistic
- R4R (Jain 2019): R2R 的 longer-paths 扩展, 仍单语言, RxR 更彻底
方法相关
- VLN-CE (Krantz 2020): 连续环境框架,RxR-CE 移植的基础设施
- Marky (Wang 2022a / Kamath 2023): instruction synthesizer, 在 RxR 上接近 human quality, 是 VLN survey §4.2 反复引用的代表
- HAMT (Chen 2021), DUET (Chen 2022): VLN history encoder / planner, 在 R2R 和 RxR 上都被用作 baseline
- FGR2R (Hong 2020): R2R 的 sub-instruction-to-viewpoint alignment, 是事后人工标注; RxR 的 word-pose alignment 是 collection-time by-product
后续/扩展
- RxR-Habitat Challenge (CVPR 2022 起): 把 RxR 作为 sliding-forbidden VLN-CE 的标准评测
- ETPNav: RxR-CE +26 SR breakthrough, 范式级跃升
- NaVid / NaVILA / StreamVLN / NavFoM / Efficient-VLN / PROSPECT: 新一代 VLA / streaming / foundation model,全部 report RxR-CE
- VLN-R1 / VLNVerse: RL 训练 / 多 benchmark 框架, RxR 是其评测标配
- ScaleVLN (Wang 2023): 因 RxR annotation 成本极高 (Guide 458s / Follower 132s = ~10 min/instruction), 推动了 synthetic instruction generation 路线,用 Marky-style speaker 在更大 path 池上自动生成指令补足 scale
- VLN-Foundation Survey: 把 RxR 列为 §3.2 Benchmark 的 multilingual + dense-grounding 代表
论文点评
Strengths
- Annotation tool 是真 contribution:从”写指令”切到”边走边说 + 同步 pose tracking + ASR + DTW 对齐”,整个 pipeline 让 word-level dense grounding 成为 collection-time by-product 而非事后标注。这种 annotation methodology 本身可迁移到任何”agent in environment”的 grounded language 数据集。
- Path 设计有 principled 反 bias 论证:Two-level room-graph sampling + greedy coverage 不是拍脑袋的设计,而是对应明确的 4 个 desiderata,并用 simple-baseline ablation (Table 4) 证明 R2R 的 dumb-agent free lunch 在 RxR 不存在。
- 指标转向 nDTW/sDTW:把社区注意力从 goal-reaching 拽到 path-fidelity,这是 long-instruction VLN 必须的转向。RxR-CE leaderboard 用 nDTW 排名是这个 framing 的胜利。
- 多语言不是 marketing:选 typologically diverse 的三种语言(Germanic / Indo-Aryan / Dravidian),不靠翻译,独立采集,且显式实验证明 multilingual joint 反而不如 monolingual——把 “multilingual VLN 的难点” 量化展示,而非简单宣称 “we support 3 languages”。
- Follower demonstration 提供两类 trace:Guide 是”指令生成者的视角”,Follower 是”指令解读者的视角”,两套 pose trace 为 grounded language pragmatics 研究 (speaker / listener model) 提供独有数据。
- 数据组织对跨语言研究友好:12.8K paths 在三种语言里共享 → 同一条路径的多语言指令对齐天然存在,是 cross-lingual VLN / parallel instruction 研究的 ready-made testbed。
- 作者组合权威:Google Research VLN 组(Anderson、Baldridge)+ Brown,作为 R2R 原作者的延续,承诺并实际发布了 leaderboard / annotation tool / 全部数据。
Weaknesses
- Baseline agent 太弱: RCM-style LSTM + dot-product attention 在 2020 已经不是 SOTA, 论文 SR=22 vs human 90+ 的巨大 gap 主要来自 agent 弱。一个更强 baseline (e.g. PREVALENT / VLN-BERT / HAMT 在 RxR 上的数字) 能让 dataset 难度的真实位置更清楚。后续 ETPNav (54.79 SR) 把 gap 缩到 ~40 points 才更准确——所以 “RxR 难” 部分被早期弱 baseline 夸大了。
- Cross-translation 实验设计有问题: 用 MT 翻译 en→hi/te 然后训练,但大部分 path 已有原生 hi/te 标注(12.8K shared),所以 MT 翻译相对原生 instruction 是低质增量,下降可预期。如果在未原生标注的 1.2K unique paths 上做 MT 增强对照,结论会更说服力。
- Dense grounding 的下游用法只 hint,没真正打通: Exp. 6 的 visual attention supervision 是”preliminary investigation”,结果 mixed 且论文也承认。RxR 最大的 unique signal(pose trace)在自家 baseline 里没发挥效力——这是个遗憾的 missed opportunity,留给社区做。但社区到 2026 也没大规模利用 dense grounding(NaVILA / StreamVLN 等都还是用 instruction → action 的端到端 supervision),说明这个数据资产至今未被充分挖掘。
- Annotator pool 与 dialect confound 未控制: en-US 和 en-IN 长度差 50% (129 vs 87 words), Hindi vs Telugu 在 coreference / sequencing 差异巨大——究竟是语言差异还是 annotator 习惯?没控制变量实验。
- “Multilingual ≠ multilingual win” 结论被过度解释: experiment 4 的多语言混训只是把三个 monolingual 数据简单拼接,没用 language adapter / language-conditioned encoder / curriculum 等多语言专门设计。结论应该是 “naive concatenation 不 work”,不是 “multilingual 训练根本不帮 VLN”。
- Telugu / Hindi annotator pool 显著小于英语: 论文未披露具体 annotator 人数, 但 Telugu 平均指令 56 词远短于 en-US 129 词暗示了 pool 训练程度差异。这影响 cross-lingual 比较的公平性。
- 没真正用上 follower confidence rating: Follower 完成后给 instruction clarity 与自己的 confidence 打分, 但论文实验里没有用这些 metadata(例如做 instruction quality scoring 任务 / curriculum)。又一个 unused signal。
- 静态环境: RxR 沿用 MP3D 的 90 个 indoor scenes, 没有 dynamic obstacle / household activity。在 2026 年看, 这是 “VLN 仍被锁在 90 MP3D scenes” 这一更大问题(VLNVerse Table 1 的核心 critique)的源头之一。
可信评估
Artifact 可获取性
- 代码:annotation tool / training code / RCM agent 实现 promise 但主仓库 google-research-datasets/RxR 只发布 dataset、Marky speaker (单独 sub-folder)、visualizations,没有 baseline RCM agent 训练代码。VALAN (Lansing 2019) 框架本身也未开源。这是个不便。
- 模型权重:未发布 baseline checkpoint
- 训练细节:高层描述完整(Adam, lr 1e-4, batch 32, 100K iter, 50% BC + 50% policy gradient, NDTW reward),但具体 hyperparam(CNN encoder 层数、attention head 数、reward 系数)部分缺失
- 数据集:完整发布——Guide/Follower instructions + pose traces + text features (mBERT) + MT translations,gzipped JSON Lines + numpy archive,CC-BY-4.0 许可,链接 https://github.com/google-research-datasets/RxR
Claim 可验证性
- ✅ RxR 比 R2R 大 10×、跨三种语言、有 dense word-pose alignment:dataset 公开可直接验证,Table 1/2 的统计数字可在 raw data 上重算
- ✅ RxR 路径破坏 R2R 的 shortest-path bias:Fig. 3 + Table 4 的 simple baseline 对比是 hard evidence——R2R 上 27.2 SR、RxR 上 13.7 SR 的 “GT first step + straight” 差异很难争议
- ✅ Multilingual joint training underperforms monolingual in this setup:Table 5 直接对比,统计上明显
- ⚠️ “Both languages contribute to performance” (Unimodal ablation):vision 贡献 SR ~5 points (22→17 from full→language-only), language 贡献 SR ~15 points——结论 OK 但视觉对长程 navigation 的真实贡献被弱 visual encoder 低估
- ⚠️ Visual attention supervision 给 NDTW 涨 / SR 跌的解释:论文归因为 “preliminary investigation”, 但 supervision loss 的具体实现细节(gating 是否 over-restrictive、loss weight)没扫,结论的鲁棒性不明
- ⚠️ “Human SR 93.9%” 作为 dataset 难度上限:这是 Follower task 的 multi-pass 后留下来的最佳 Follower SR——但 multi-pass 选择本身偏向了”被人能 follow 的 instruction”,RxR 实际难度对 random Follower 可能更低(论文未报 single-pass Follower SR)
- ❌ 没有过度营销话术——论文措辞克制,“only begun to explore” 等承认 limitation 的语气贯穿全文
Notes
- 这篇论文最被忽略的贡献是 annotation methodology:词-3D pose 时间戳化的 pipeline 完全可迁移——任何 “agent in environment + speech” 的数据集都能复用。我做 spatial intelligence / VLA 数据集时,“用 ASR + DTW 把 narrator 的话和 robot 视角 pose 对齐” 是个值得借鉴的 collection trick。
- Critical Read 之一:长指令对现代 streaming VLA 的真正影响——RxR 平均 ~120 词意味着模型必须在 128-512 tokens 的 prompt 里塞下整段 instruction + 视频 history。对 StreamVLN 这类 streaming video LLM, instruction 占用的 context budget 直接挤压可保留的 frame history。RxR-CE 上 SR 从 ETPNav 的 54.79 涨到 Efficient-VLN 的 67.0 用了三年, 部分原因就是 streaming VLA 在 context-pressure 下需要更精细的 instruction-frame 调度。NaVILA 的 dual-system 设计(高频 vision-action / 低频 reasoning)某种程度上是回应这个 pressure 的。
- Critical Read 之二:Hindi/Telugu 在 2026 还有没有用? 实际上几乎所有 published RxR-CE leaderboard 工作都只在 English split 上 train/eval(ETPNav / NaVid / NaVILA 都是)。Hi/Te 数据成了未被使用的 idle resource。原因:(a) baseline 多用 mBERT/CLIP-text,本身英语强 hi/te 弱;(b) 评测以英语 SR 为主,没动力做 multilingual robustness。RxR multilingual 部分在工程实践上 underused,但作为 critique 工具仍有效——任何宣称 “language-agnostic VLN” 的论文都应该在 hi/te 上验证。这个 idle resource 在 LLM-time 可能被多语言 LLM (Gemma, Aya, Llama) 重新激活。
- Critical Read 之三:RxR 把 VLN 锁死在 MP3D 90 scenes 的代价——RxR 沿用了 MP3D 同一批 scenes,所以一切 RxR 上的”环境多样性问题”和 R2R 是同构的。VLNVerse Table 1 把这个 framing 出来:现代 VLN 的 environment generalization 上限被 MP3D 卡住, RxR 没解决这个 underlying issue, 只解决了 instruction 维度的 diversity。这是 RxR 的 ceiling——它扩展了 instruction space, 没扩展 environment space, 而后者在现实部署中可能更紧迫。
- 可借鉴 idea (跨 task):Two-level sampling (room-graph → panorama-graph + greedy coverage) 是个通用的 hierarchical sampling pattern——任何”在层级结构里采样代表性序列”问题都能用:robot manipulation 的 task → sub-task → primitive 序列、生物路径采样、code generation 的 file → function 序列。
- 可借鉴 finding:annotator 平均只观察 27% 的 panorama → 全 panorama attention 是一种 over-engineering,agent 应该学”何时看哪里”。这与现代 VLA 用 active perception (NaVILA dual-system 在 reasoning 时只看 keyframes) 的方向一致, 是 evidence-based 的设计 prior。
- 方向相关性:与我的 spatial intelligence / VLN 方向直接相关——RxR-CE 是 VLN-CE 的 de facto benchmark 之一,所有现代 method 都 report 它。理解 RxR 的 path desiderata + nDTW/sDTW metric 是评估任何 VLN paper 的前置条件。
Rating
Metrics (as of 2026-04-28): citation=492, influential=66 (13.4%), velocity=7.45/mo (66 months since publish); HF upvotes=N/A(HF Papers 上无对应条目); github 179⭐ / forks=14 / 90d commits=0 / pushed 1007d ago · stale (repo archived 2023-07)
分数:3 - Foundation
理由:作为 VLN 子领域的奠基级 benchmark/dataset 工作完全够 Foundation 标准。(a) 影响力指标硬:492 cite / 13.4% influential ratio 在 dataset 论文里是健康的(比 RT-2 的 6% 高),velocity 7.45/mo 在论文 5.5 年后仍稳定,说明被持续作为新 method 的标配评测引用而非历史 reference;(b) 范式级贡献:multilingual VLN、word-level dense grounding、nDTW/sDTW 作为 path-fidelity 主指标——三件事任何一件都足够 Frontier,三件合一构成 VLN 子领域的 de facto standard;(c) 生态构建:RxR-Habitat Challenge / RxR-CE 让所有现代 VLN-CE 工作(ETPNav / NaVid / NaVILA / StreamVLN / NavFoM / Efficient-VLN / PROSPECT)都必须 report RxR-CE,而 VLN-CE / RxR-CE 是 VLN-CE 仅有的两个公认 benchmark。Stale repo 不扣分——dataset 一旦发布就稳定使用,archived 状态符合 dataset 论文的生命周期(不是 method 库要持续维护)。不达”全 embodied AI 必读”档(如 ImageNet)只因 VLN 是 embodied AI 的子方向, 但在 VLN 内部它就是必读必引。