Summary
MolmoAct2: Action Reasoning Models for Real-world Deployment
- 核心: 一个端到端开放的 VLA 家族(数据 + tokenizer + backbone + 架构 + 推理变体),以「fully open + 多 embodiment out-of-the-box 部署」为目标对标 π0.5
- 方法: Molmo2-ER 具身推理 backbone → MolmoAct2-FAST 多 embodiment action tokenizer → 离散 AR 预训练 → DiT-style flow-matching action expert 通过逐层 KV cross-attention 而非 hidden-state 连接 backbone → MolmoAct2-Think 用 adaptive depth tokens(仅对变化 patch 重生成)维持几何 grounding 同时降延迟
- 结果: 13 个具身推理 benchmark 平均 63.8%(超 GPT-5、Gemini-ER 1.5 Thinking);DROID 实机 5 task 平均 87.1% vs π0.5-DROID 45.2%;YAM 8 实机任务 50.1%(runner-up +15%);LIBERO 97.2%(Think 98.1%);CUDA Graph 后 MolmoAct2 控制率 55.8 Hz
- Sources: paper | website | github
- Rating: 2 - Frontier(最新开放 VLA SOTA,超 π0.5;但发布 < 1 周,引用尚未沉淀,定型为 foundation 还需时间)
Key Takeaways:
- Per-layer KV conditioning > hidden-state conditioning:把 action expert 的每层 cross-attention 接到对应 VLM 层的 K/V(而非只读 final hidden state),LIBERO 上 +1.9 点。直觉是 expert 拿到的是和 VLM 自身一样的注意力状态而非压缩残差。
- Adaptive-depth reasoning:MolmoAct2-Think 把 MolmoAct 的 depth token CoT 改为「只对 RGB cosine 相似度 < 0.996 的 10×10 cell 重新预测」,几何推理延迟随场景变化量缩放,而非 100-token 常量。
- 数据是杠杆:MolmoAct2-BimanualYAM 720 小时——目前最大开放双臂数据;DROID 和 SO-100/101 用 Qwen3.5-VL 重标语言(unique label 比例 22% → 46%),这种「数据清洗 + 重标」可能是性能差距的隐藏推手。
- 「fully open」是核心叙事:相比 π0.5 仅放 weight、Gemini Robotics 完全闭源,MolmoAct2 同时放出模型、训练代码、完整数据、tokenizer 训练数据。这把它定位成研究基础设施而不是产品。
- Embodied-reasoning backbone 显著影响 action learning:仅换 backbone(Molmo2 → Molmo2-ER),LIBERO Long 6 点提升。VLA 性能不仅由 action head 决定,VLM 预训练对空间任务的特化同样关键。
Teaser. MolmoAct2 总览:左侧三类开放机器人数据(YAM/SO-100/101/DROID)训练 MolmoAct2(中),通过逐层 KV 连接连接 VLM backbone 和 action expert,部署到三类 embodiment 的 in-the-wild 任务(清理、洗碗、湿实验室、倒茶)。

1. Motivation:当前 VLA 哪儿不够 “deployable”
作者把现有 VLA 体系的不足整理为四条互相加强的问题:
- Frontier 闭源:Gemini Robotics、π 系列等仅放权重甚至完全闭源,数据/recipe 不公开
- 开放方案绑硬件:π0、π0.5 等开权重模型针对高成本平台,学术实验室难以复现
- Reasoning 太贵:MolmoAct 这类 reasoning-augmented policy 在生成几百个 depth token 后才能输出 action,破坏 closed-loop 控制
- Fine-tune 后成功率仍低:现实任务即便经过 task-specific 微调仍达不到生产可靠性
围绕这四条,MolmoAct2 沿 5 条轴改进 MolmoAct:(1) 更强的具身推理 VLM backbone (Molmo2-ER),(2) 3 个新机器人数据集,(3) 多 embodiment 开放 action tokenizer,(4) 新 VLA 架构(per-layer KV conditioning),(5) MolmoAct2-Think 的自适应深度推理。
2. Molmo2-ER:embodied-reasoning VLM Backbone
通用 VLM 缺少 metric distance、free space、cross-view tracking、scene geometry 等 robot policy 实际需要的技能。Molmo2-ER 在 Molmo2 基础上用 3.3M 样本做具身推理特化。
训练语料 6 大类(Table 1):
- Image embodied QA:SAT、RoboPoint-QA、RefSpatial、VST-P、VSI-590K——覆盖 static/dynamic、synthetic/real、single/multi-view
- Video embodied QA:SIMS-VSI、RoboVQA
- Pointing + detection:RoboPoint 700K 的 (x,y) target + 100K LVIS detection
- Multi-image / ego-exo:SenseNova-SI 500K + VST-P cross-view 200K
- Abstract reasoning:CLEVR、GRiD-3D(专门针对 object-intrinsic 方向)
Specialize-then-rehearse:
- Stage 1(20K 步):从 Molmo2-4B mid-train checkpoint 出发,纯具身数据 + 8% Tulu-3 text。快速把模型推到具身数据 manifold
- Stage 2(1.5K 步):和 Molmo2 原始 multimodal 数据 50/50 混合 rehearse,避免遗忘通用能力。
p=0.5是扫了 {0.3, 0.5, 0.7, 0.9} 后的 Pareto 最优
❓ Stage 2 只有 1.5K 步、和 Stage 1 比少 13×,但 sequence length 翻 4 倍。这种很短的 rehearse 是否真的恢复了 general capability?没看到 general benchmark 对比数据。
Table 3 主要结果:Molmo2-ER 在 13 个 ER benchmark 上 9 个领先,平均 63.8% > Gemini-ER 1.5 Thinking 61.3% / GPT-5 57.9%,比起点 Molmo2 提升 17 个点。这个 +17 是论文里数据-训练循环最大的一次跳跃。
| Model | RefSpatial | BLINK | CV-Bench | ERQA | VSI-Bench | Overall |
|---|---|---|---|---|---|---|
| GR-ER 1.5 Thinking | 48.5 | 84.3 | 54.8 | 78.4 | 45.8 | 61.3 |
| GPT-5 | 23.5 | 71.3 | 59.0 | 81.5 | 52.9 | 57.9 |
| Qwen3-VL-8B | 47.5 | 66.6 | 41.5 | 78.2 | 49.3 | 61.0 |
| Molmo2 | 76.9 | 50.8 | 46.3 | 67.0 | 26.1 | 46.8 |
| Molmo2-ER | 77.3 | 72.5 | 46.8 | 78.8 | 44.7 | 63.8 |
3. Robot Data
Figure 2. MolmoAct2 训练数据组合:YAM/SO-100-101/DROID 三个主要机器人数据集 + Open X-Embodiment 子集(BC-Z、Bridge-V2、Fractal)+ 多模态 web 数据 + 具身推理数据,前者负责动作,后者负责保持 VLM 能力。

3.1 MolmoAct2-BimanualYAM Dataset(720 小时,最大开放双臂数据)
自制 bimanual YAM (Yet Another Manipulator) 平台,总成本 < $6000 USD。28 个真实任务(折衣服、解线缆、收拾餐桌、扫描杂货、装药等)。34.5k demo / 720 小时,2 个月采集,Cortex AI 协助。
Figure 3. YAM 数据采集平台:双 YAM 臂 + Intel RealSense D435(顶部俯视)+ D405(手腕)+ IKEA 桌,所有组件可购,整套 < $6000。

3.2 MolmoAct2-SO100/101 Dataset
从社区 1,222 个 LeRobot 数据集(377 用户贡献)筛选。4 阶段过滤:(i) 结构有效性、(ii) 移除 eval-style、(iii) license 检查、(iv) TOPReward quality gate——用 token probability 作 zero-shot reward 筛 episode 质量。最终 38k episodes / 19.8M frames / 184 小时。
3.3 MolmoAct2-DROID Dataset
利用 DROID 的扩展语言注释 + idle-frame 过滤,再 LLM 重标。最终 74,604 episodes / 17.8M frames。
3.4 Language re-annotation
发现的两个问题:(1) 大规模重复任务的语言 instruction 高度重复——Jang et al. 2022 中 39350 集只有 104 unique instructions(0.26%);(2) 众包数据有大量 lerobot_test、Test run 之类的占位符。
用 Qwen3.5-VL-27B 给 frame + 原 instruction → 生成新指令,并随机采样目标词数增加多样性。整体 unique label 比例 22% → 46%。
❓ Qwen3.5 → 这个版本号是 paper 写的,但 Qwen 当前 SOTA 是 Qwen3-VL(无 .5 中间版)。可能是笔误或内部 fork。
4. MolmoAct2 架构与训练
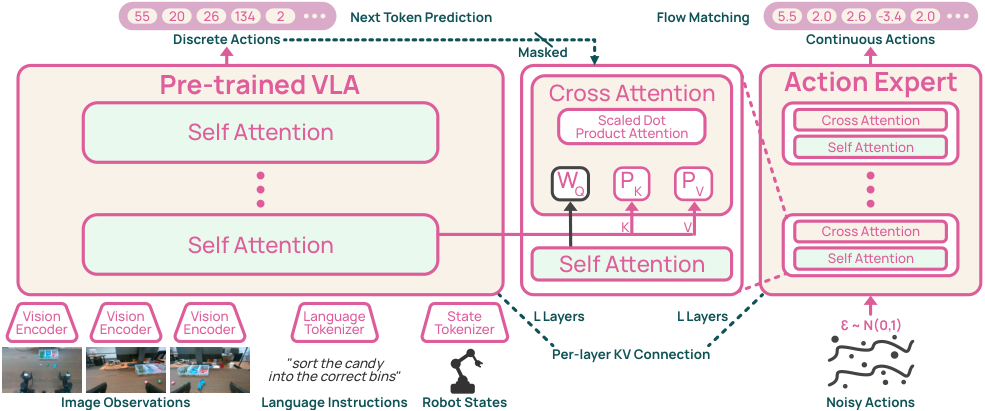
Figure 4. 架构总览:图像/语言/状态由 VLM backbone 处理,post-train 阶段额外接一个层数与 backbone 相同的 DiT-style action expert。每层 expert 的 cross-attention 用 backbone 对应层的 K/V(经线性投影对齐宽度),把 VLM 的逐层注意力状态注入到 continuous action 生成。Backbone 同时被 next-token loss 监督预测离散 action token,但目标 action span 在 expert 路径被 mask,避免 leakage。
三阶段 pipeline:
4.1 Pre-training:离散 AR VLA
从 Molmo2-ER 出发,把 robot trajectory 用 MolmoAct2-FAST tokenizer 离散化,统一在 next-token 目标下训练。
MolmoAct2-FAST Tokenizer:开放权重 + 开放数据版的 FAST tokenizer。在 1M action 序列(YAM/SO-100-101/DROID/BC-Z/Bridge/Fractal 6 embodiment 各 ~30%/3%)训练,频域变换 + 量化 + BPE,2048-token vocabulary,1 秒 32-D 连续动作压成短离散序列。所有 embodiment 统一 padding 到 32 维。
Pre-train:90% robot + 10% multimodal,YAM/SO-100/101/DROID 各 30%,BC-Z/Bridge/RT-1/MolmoAct Dataset 共 10%。200K steps,单 image crop,每 video 最多 8 frame,64 H100 / batch 128 / ~5,760 GPU 小时。Setup/control 用 special token wrapper:<setup_start>bimanual yam robotic arms in molmoact2<setup_end>,<control_start>absolute joint pose<control_end>。
4.2 Post-training:DiT-style action expert + per-layer KV conditioning
核心架构选择:expert 用 36 层 DiT,与 backbone 层数对齐。每个 expert block 计算:
其中 是把 VLM K/V 投影到 expert 注意力宽度的 adapter。Time embedding 给每个 residual branch 提供 DiT 风格的 shift/scale/gate。
Flow matching 训练:给定归一化 action chunk ,噪声 ,时间 :
expert 预测速度场 。每个样本采 K=4 个 (4.2 训练)或 K=8(4.3 fine-tune,GPU 内存允许)做 flow loss。
Knowledge insulation:VLM K/V 在送入 expert 前 detach,所以 只更新 expert + adapter,不反传到 VLM; 仍照常更新 VLM。
Post-train 配置:100K updates / batch 128 / 64 H100 / ~2,304 GPU 小时。Robot batch sequence 长 2100,VLM batch 4200(因为 expert 单独耗算力)。
4.3 Deployment
针对 4 个 embodiment 分别 fine-tune(YAM/DROID/SO-100/101/LIBERO),每个 1,1522,304 GPU 小时。Fine-tune 与 post-train 4 点差异:(1) robot-only,(2) K=8 flow samples,(3) 不用 knowledge insulation(实验中没有持续提升),(4) 仅 tune LM head + final norm。
Inference optimization:action chunk 内 VLM context 是 invariant 的,所以 cache 跨 flow step 的 cross-attention state;用 CUDA Graphs 捕获 fixed-shape flow loop,消除 kernel launch 开销。
5. MolmoAct2-Think:Adaptive Depth Reasoning
Figure 5. MolmoAct2-Think 总览:对每帧观测,模型先估出 10×10 depth grid(用 Depth Anything V2 + MolmoAct 的 depth VQ-VAE,128 codebook)。对每个 cell 比较当前帧与上一帧对应 32×32 RGB patch 的 cosine 相似度,<0.996 标记为更新;更新 cell 由 argmax 解码,未更新 cell 直接从 cache replay。然后 action expert 在「prompt + 填好的 depth prefix」KV 上做 cross-attention。
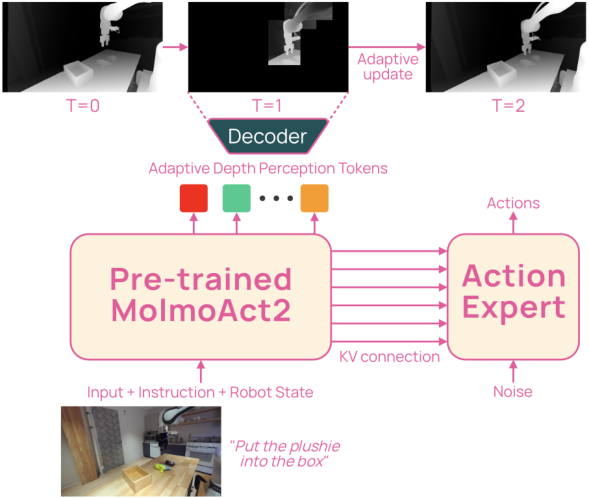
Depth 表示:每帧深度图量化成 10×10 grid,每位置一个 128-class learned depth code。共 100 token。
自适应核心:
只解码 的 cell,其他 replay cached value。代价随场景变化量缩放而非固定 100 token。
训练:post-train 阶段三种任务均匀采样:action / depth / depth-and-action。Fine-tune 阶段去掉 pure depth,注入 10% noise 模拟 inference-time 误差,加 per-layer depth gate(初始 bias = −4,使训练从「几乎不使用 depth」开始平滑过渡)。
❓ 0.996 这个阈值是怎么选的?论文没说扫参。0.99 vs 0.999 之间灵敏度可能差很多——0.999 太敏感导致大部分 cell 都重算,节省消失;0.99 太松可能漏掉 manipulation 的小幅 visual change。
6. Experiments
6.1 Out-of-the-box 部署
MolmoSpace(simulation, DROID setup, 4 类操作)
| Model | Pick | Pick & Place | Open | Close | Avg |
|---|---|---|---|---|---|
| π0-DROID | 16.2 | 12.5 | 11.0 | 53.1 | 23.2 |
| π0.5-DROID | 36.4 | 13.6 | 22.7 | 65.1 | 34.5 |
| MolmoAct2-DROID | 43.7 | 26.7 | 9.5 | 70.8 | 37.7 |
Pick & Place 大幅领先(+13.1 vs π0.5),但 Open 反而比 π0.5 差 13 点。作者承认 articulated object interaction 是改进方向。
Real-world DROID setup(OOD:相机随机、新物体、新场景,15 trials/task)
| Model | apple_on_plate | pipette_in_tray | red_cube_in_tape_roll | knife_in_box | objects_in_bowl | Avg |
|---|---|---|---|---|---|---|
| π0.5-DROID | 66.7 | 33.3 | 53.3 | 26.7 | 46.2 | 45.2 |
| MolmoBot | 86.7 | 53.3 | 33.3 | 40.0 | 28.6 | 48.4 |
| MolmoAct2-DROID | 100.0 | 86.7 | 93.3 | 93.3 | 62.0 | 87.1 |
实机 +38.7 比起 simulation +3.2 反差巨大。论文给的解释是 OOD(随机相机 + 新物体 + 新场景)放大了 backbone 与数据质量的优势。
SO-100/101:MolmoAct2-SO100/101 56.7% vs π0-SO100/101 45.3%(fine-tuned by authors)vs SmolVLA 2.3%。
6.2 Fine-tuning to new tasks
LIBERO(4 suites 平均)
| Model | Spatial | Object | Goal | Long | Avg |
|---|---|---|---|---|---|
| OpenVLA | 84.7 | 88.4 | 79.2 | 53.7 | 76.5 |
| π0 | 96.8 | 98.8 | 95.8 | 85.2 | 94.2 |
| MolmoAct-7B-D | 87.0 | 95.4 | 87.6 | 77.2 | 86.6 |
| GR00T N1.7 | 97.7 | 97.5 | 98.5 | 94.4 | 97.0 |
| π0.5 | 98.8 | 98.2 | 98.0 | 92.4 | 96.9 |
| MolmoAct2 | 98.8 | 100.0 | 97.8 | 93.2 | 97.2 |
| MolmoAct2-Think | 99.8 | 99.8 | 98.5 | 95.4 | 98.1 |
LIBERO 已近饱和(MolmoAct2 97.2 vs π0.5 96.9),Think 在最难的 Long 上多 2.2 点最有说服力——加 depth 的边际收益在低 headroom 套件上消失,在高 headroom 套件上保留,符合 “non-incidental gain” 的论证。
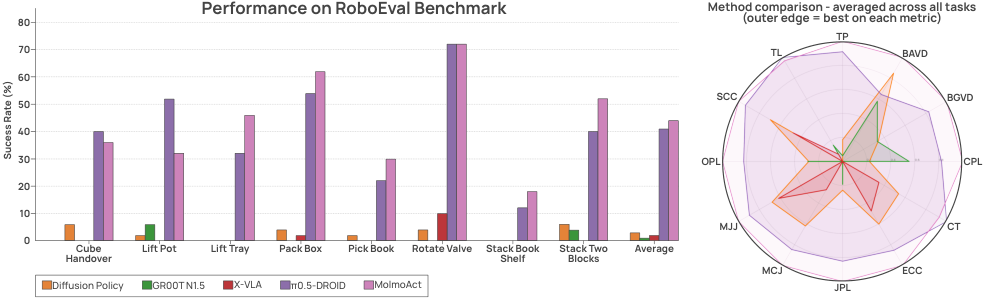
RoboEval:MolmoAct2 44.3% > π0.5 40.5%(次优)3.8 点。
Figure 6. RoboEval 基准上 8 任务的成功率(左)和行为/轨迹质量雷达图(右):MolmoAct2 不仅在 task success 上 dominate,在 completion time、joint path length、jerk、self-collision 等部署相关指标上也全面领先——这是论文为 “deployment readiness” 提供的最有力证据,因为成功率高但轨迹差的 policy 在生产里仍不能用。
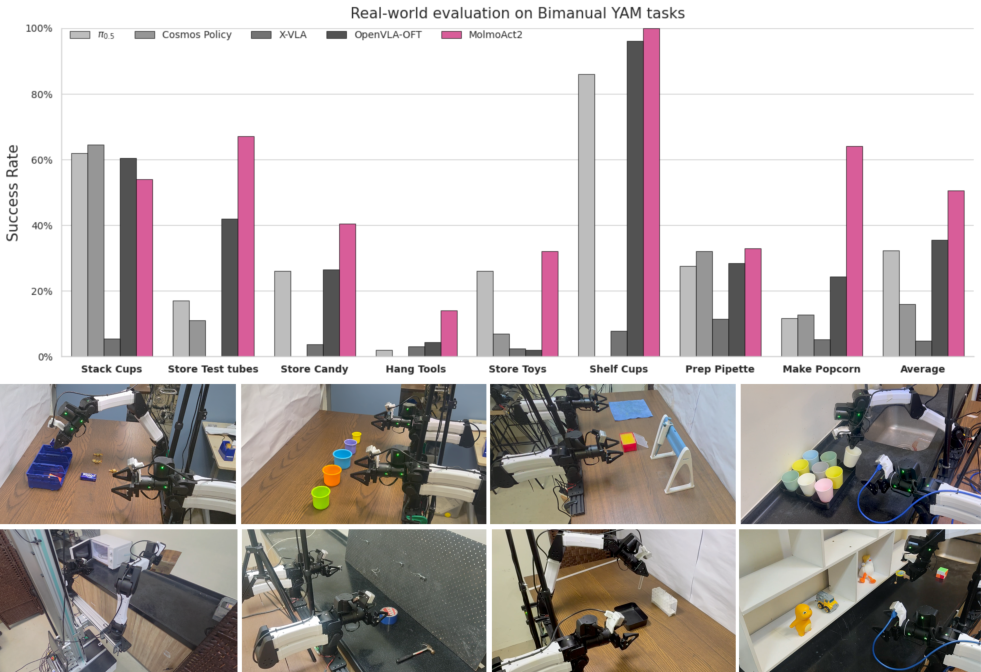
6.3 Real-world bimanual YAM(最关键的部署测试)
Figure 7. 8 个真实环境任务:从制备移液器(湿实验室)、整理玩具、堆杯子、做爆米花到挂工具——跨实验室、住宅、咖啡厅、化学/生物实验室的真实场景。MolmoAct2 fine-tune 后平均成功率 50.1%,比 runner-up(OpenVLA-OFT,35%)高 15 点。
6.4 Robustness(OOD perturbations on YAM)
| Model | Spatial Var | Lighting | Language | Distractor | Overall |
|---|---|---|---|---|---|
| π0.5 | 15.00 | 33.70 | 26.15 | 33.20 | 27.01 |
| Cosmos Policy | 8.75 | 17.50 | 5.00 | 13.75 | 11.25 |
| OpenVLA-OFT | 13.75 | 46.25 | 51.25 | 48.30 | 39.89 |
| MolmoAct2-Think | 26.25 | 62.05 | 60.35 | 54.10 | 50.69 |
每类 perturbation 都领先;最弱的是 Spatial Variance(26.25%),fine-grained 空间泛化仍是瓶颈。
6.5 关键消融
Backbone 消融(仅离散 action,LIBERO Long):Molmo2 → Molmo2-ER 提升 6 点(77.6 → 83.6)。证明 backbone 特化收益直接传到 action prediction。
Conditioning source(LIBERO Avg):
- Hidden-state conditioning:94.0%
- Per-head per-layer KV:94.8%
- Per-layer KV(最终方案):95.9%
差距主要出现在 Object/Goal/Long 上,证实「每层 attention state」比「单 residual stream 压缩」信号更丰富。
Flow samples K:K=1 → 94.15%, K=8 → 95.90%。更密的 flow 监督普遍更好。
Fine-tune 设计:discrete co-training 关闭、knowledge insulation 关闭、full FT,是最终配方(97.20%)。只调 action expert 掉到 93.05%,说明 backbone 必须可塑。
Depth-aware FT:noise injection + depth gate 一起开比都关高 0.45 点(98.10 vs 97.65),最大提升在 Goal(+1.8)。
6.6 Inference speed
Figure 8. CUDA Graph + reusable cache 后的控制频率:MolmoAct2 从 23.02 Hz → 27.39 Hz(缓存)→ 55.79 Hz(CUDA Graph),整体 2.42× 加速。MolmoAct2-Think 8.04 → 9.72 → 12.71 Hz,1.58× 提升——adaptive depth 的可变长度解码不适合 graph capture,所以收益较小。

Discrete action 路径(VLM 自回归 decode 整个 chunk)只有 14.17 Hz,比 continuous expert 慢 3.94×,所以默认部署用 continuous path。
关联工作
基于
- MolmoAct (Lee et al. 2025, arXiv:2508.07917):直系前作,相同实验室。MolmoAct2 沿 5 条轴改进(backbone/data/tokenizer/architecture/adaptive reasoning)
- Molmo2:通用 VLM backbone,Molmo2-ER 在此基础上加 3.3M 具身推理样本特化
- FAST tokenizer (Pertsch et al. 2025):MolmoAct2-FAST 直接采用其频域 + BPE 量化方案,关键差异是放出训练数据
- π0:flow-matching action expert 范式的开山之作,MolmoAct2 复用 flow matching 但换成 per-layer KV 连接
- Knowledge insulation (Driess et al. 2025):post-training 阶段沿用此 trick 隔离 VLM 与 flow loss 的梯度
对比 / 主要 baseline
- π0.5:当前最强开权重 VLA,real-world DROID 上 MolmoAct2 比它 +41.9 点。MolmoAct2 把 “fully open” 推得更激进
- N1.5:另一开放 VLA,LIBERO 上接近持平,但实机评估缺席
- X-VLA:作为 cross-embodiment 对照,在 RoboEval / robustness 上明显落后
- OpenVLA-OFT:实机部署 runner-up,但 YAM 任务低 MolmoAct2 15 点
- Cosmos Policy (Kim et al. 2026):world-model based policy,robustness 测试中最差
- SmolVLA:低成本 baseline,SO-100/101 上 MolmoAct2 +54.4 点
- Diffusion Policy:RoboEval 上经典对照
方法相关
- per-layer KV conditioning:和 final-layer hidden-state conditioning(GR00T、VLA-Adapter)的对比是论文最重要的架构 claim
- adaptive depth reasoning:和 PEEK(mask RGB conditioning on visual tracing)思路相反——PEEK 替换观测、MolmoAct2-Think 增量更新中间表示
- TOPReward (Chen et al. 2026):用 token probability 做 zero-shot reward 筛数据质量,论文中用于 SO-100/101 过滤
- DROID (Khazatsky et al. 2024):上游 Franka 数据集
- LIBERO / RoboEval:sim benchmark
- Depth Anything V2:depth 估计 backbone
- Gemini Robotics 1.5 / Gemini Robotics ER 1.6:作为闭源 frontier 对照(embodied reasoning bench)
论文点评
Strengths
- System-level paper 的范本:不是只发模型,而是 backbone + tokenizer + 数据 + 架构 + 推理变体 + 推理优化 + 7 个 benchmark 一整套打包。每一项都不是革命性的,但组合起来构成了目前最完整的开放 VLA 栈
- Real-world DROID 实验严苛且结果非常强:随机相机、新物体、新场景的设置下还能 87.1% 平均成功率,比 π0.5 高 41.9 点——比 simulation 上 +3.2 的反差差不多大。这种 OOD 优势比 LIBERO 上 +0.3 更有信息量
- Per-layer KV conditioning 的消融做得干净:和 hidden-state / per-head per-layer 三档对比同条件,差距来自分层 vs 残差流是稳的,这是少数能让我相信架构创新 “确实在工作” 的 VLA 论文之一
- 「Fully open」的承诺真在执行:模型权重、训练代码、数据、tokenizer 训练数据都公开。GitHub repo 已 222 stars / 1 周更新,HF 270 upvotes(发布 7 天内的水平算很高)
- Trajectory quality 评估:除成功率外评估 completion time、jerk、self-collision 等——这是 VLA 评估里少见的「deployment readiness」视角
Weaknesses
- Adaptive depth 的节省没有 quantified:MolmoAct2-Think 只比 MolmoAct2 慢 4×,但论文没给出 “实际场景中 depth cell 的平均更新比例”。如果场景变化大(动态环境、移动相机),adaptive 退化为 dense,节省消失。0.996 阈值的 sensitivity 也没扫
- Articulated object 是短板:MolmoSpace Open 任务上 9.5% 比 π0.5 的 22.7 低一半多。论文承认但没分析为什么——是数据偏置、几何推理弱、还是 flow matching 在多模态分布上劣势?
- 「Embodied reasoning + action 的因果链」缺直接证据:Molmo2-ER 比 Molmo2 强 17 个 ER 点 → LIBERO Long 强 6 个点,但 Molmo2-ER vs Qwen3-VL-8B 在 ER bench 平均差距不大(63.8 vs 61.0),如果用 Qwen3-VL backbone 训练 MolmoAct2 性能差多少?没做这个关键 ablation
- 训练成本未充分披露:Total 估算 ~10k+ GPU 小时(pretrain 5760 + posttrain 2304 + 4×fine-tune),相对于 frontier 是少的,但仍是大多数学术组无法复现的体量
- Bimanual YAM 实机评估只有 50 trials/task:考虑到这是 paper 最重的部署 claim,trial 数仍偏少,置信区间未给
可信评估
Artifact 可获取性
- 代码:训练 / fine-tune / 部署代码标注 “coming soon”——README 已发布但训练代码尚未公开。当前为 inference-only(基于已开放的 LeRobot fork)
- 模型权重:MolmoAct2, MolmoAct2-Think, MolmoAct2-Pretrain, Molmo2-ER(base)+ 4 个 finetuned (DROID, BimanualYAM, SO100_101, LIBERO, Think-LIBERO)全部开放
- 训练细节:完整披露 GPU 小时数、batch size、LR、step 数、数据配比;data pipeline、knowledge insulation、flow K 等都有 ablation 支撑
- 数据集:MolmoAct2-BimanualYAM、Molmo2-ER datasets、MolmoAct2 robotics datasets 全部在 HF 开放(LeRobot v3.0 格式)
Claim 可验证性
- ✅ Molmo2-ER 在 13 ER bench 上 9 个领先、平均 63.8%:标准 benchmark,开放权重,可独立验证
- ✅ LIBERO 97.2% / 98.1%:标准 sim benchmark,开放 checkpoint
- ⚠️ DROID 实机 87.1%:5 个任务 × 15 trials = 75 次评估,OOD 设置中相机随机初始化的具体协议在 appendix。物理实验结果原则上不可独立复现(依赖具体相机姿态/光照),但作者声明评估协议遵循 baseline 原始论文
- ⚠️ Per-layer KV conditioning > hidden-state +1.9 点:消融做得严谨,但同条件下 hidden-state baseline 用了同样的训练步数和 LR,没说明 hidden-state 需不需要不同优化器配置
- ⚠️ “Largest open bimanual dataset”:720 小时 / 34.5k demo 的体量是真的,但和 AIST bimanual、Aloha 等 dataset 的对比数据未给
- ❌ “Out-of-the-box deployment”:DROID/SO-100 实验仍是「fine-tune on DROID/SO-100 数据 → 部署到 OOD 任务」,不是 zero-shot from pretrained model。“out-of-the-box” 在这里是相对 task-specific fine-tune 而言,不是 zero-shot
Notes
- 论文的核心叙事是 “deployment ready open VLA”,最关键的差异化在 real-world bimanual YAM 部分。如果以后做相关研究,YAM 数据应该是必看的(720 小时是很大的杠杆)
- Per-layer KV conditioning 这个设计可能被其他 VLA 工作快速 adopt,因为消融干净 + 实现简单
- MolmoAct2-Think 的 adaptive depth 思路启发:CoT 不需要 dense step-by-step,可以是 “改变了什么就思考什么”。这个思路推广到其他 reasoning 也许有空间(如 video understanding 里的 temporal adaptive thinking)
- 这个工作的某种意义是把 π0 / π0.5 的方法 democratize 给学术社区,类似 OpenVLA 之于 RT-2
- 长期看,要看:(1)
is_stale检查后 90 天内 commits 数能否稳定,(2) influential citation 占比的演化,(3) bimanual 任务的 follow-up 数量
Rating
Metrics (as of 2026-05-11): citation=0, influential=0 (N/A%), velocity=0.0/mo; HF upvotes=270; github 222⭐ / forks=10 / 90d commits=1 / pushed 2d ago
分数:2 - Frontier
理由:MolmoAct2 是 2026 年中开放 VLA 的当前 SOTA:比 π0.5 强、比 GR00T 强、in-the-wild bimanual real-world 50% 是开放模型里没人达到过的成绩,研究兴趣方向(VLA / cross-embodiment)核心相关。Per-layer KV conditioning 和 adaptive-depth reasoning 也是有清晰消融支撑的方法贡献。但发布刚 7 天,citation 尚未沉淀,社区是否会把它视为 foundation(像 OpenVLA 之于早期开源 VLA)还需要 3-6 个月观察——能否取代 π0.5 成为默认 baseline 是关键判据。github 222⭐ / HF 270 upvotes 是健康的 early signal,但不足以直接升 3。如果它在 6 个月后仍是开放 VLA 的默认对比对象,应当升为 Foundation。