Summary
X-VLA: Soft-Prompted Transformer as Scalable Cross-Embodiment VLA
- 核心: 把 cross-embodiment heterogeneity 当作 multi-task prompt 学习问题——给每个数据源一组 learnable embeddings (soft prompts) 注入 transformer 早期,而非靠 per-embodiment action heads 在末端兜底
- 方法: 0.9B flow-matching VLA = Florence-Large 主视觉语言流 + 共享 wrist-view encoder + 单 transformer encoder backbone + 每数据源 soft prompt + EEF + Rotate6D 标准化动作 + 30-anchor intention abstraction
- 结果: 在 6 个 simulation benchmarks (Libero/Simpler/VLABench/RoboTwin-2.0/Calvin/NAVSIM) 中 5 个新 SOTA;Simpler-WidowX 95.8% 远超之前 71.9%;PEFT 仅调 1% (9M) 参数即可在 Libero/Simpler 上逼近全量 finetuned π0
- Sources: paper | website | github
- Rating: 3 - Foundation(cross-embodiment VLA 的 first-principles 重构:把 heterogeneity 从 output head 推到 input-side soft prompt;ICLR 2026 接收 + LeRobot 原生集成 + IROS 2025 AgiBot Challenge 冠军已成为方向必读)
Key Takeaways:
- Soft prompts > action heads:将 heterogeneity 处理推到 input 端而非 output 端,能在 early feature fusion 就让 backbone “知道自己在哪台机器上”,覆盖 camera 设置、视觉域、任务分布等被传统 per-embodiment action head 忽视的 heterogeneity 维度
- 学到的 prompt 不是 ID lookup:T-SNE 显示 prompts 形成与 hardware 一致的 clusters,但同一 Droid 数据下 left/right view 的两个 Franka prompt 互相 intermingled——说明 prompts 学到的是 hardware 语义而非 brute-force 数据源 ID
- Pretrained prompts 支持 zero-shot transfer 早期 boost:对 unseen WidowX,用 UR5 (另一 single-arm) 的 frozen pretrained prompt 初始化,早期收敛显著快于 random prompt,但最终因 domain gap 无法追平 adapted prompt——指向”prompt retrieval as cross-embodiment transfer”路线
- 0.9B 模型 + 290K episodes scaling 未饱和:在 model size、data diversity、data volume 三轴上 validation error 持续下降,且作者用 PT validation error 作为 AD success rate 的 proxy(Tab.1 验证两者强相关),把 VLA 评测从昂贵 rollout 解耦到 offline error
- Architecture 简化的胜利:去掉 DiT、用 vanilla transformer encoder + disentangled streams(fixed view/language 走 VLM, wrist view 走另一 backbone, proprio+action+time 走 lightweight linear early fusion),相比 dual-system DiT baseline 在 Simpler-WidowX 上 73.8% → 89.6%
Teaser. X-VLA 设计概览:每个数据源一组 learnable soft prompt embedding 注入 transformer,作为对 hardware 异构性的 early-stage 调制信号。
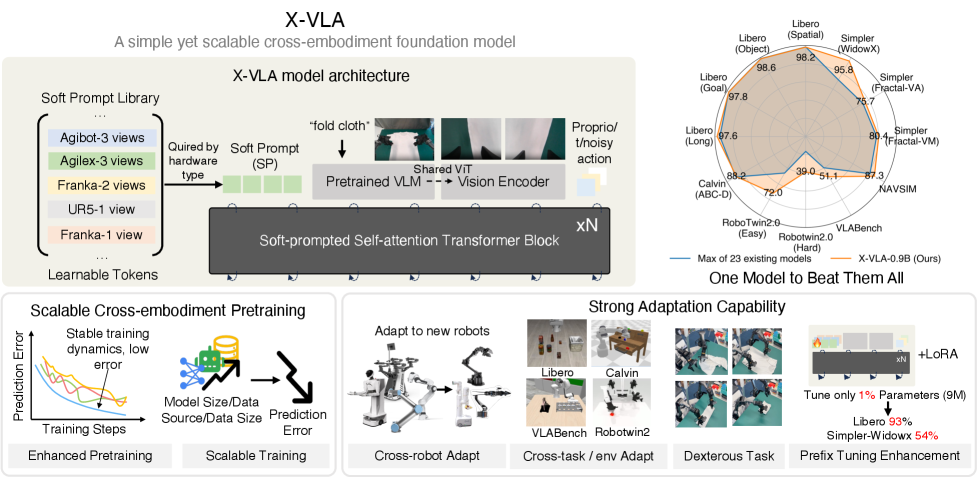
Background & Motivation
VLA 训练面对的 heterogeneity 不止 action space
VLA 的标准训练范式:从 VLM 初始化,然后在 expert demonstration 上做 behavior cloning,预测 action chunk 。要做 generalist,必须在 个 heterogeneous 数据源 上联合训练,每个 来自一种 hardware 配置 。
但作者点明一个被普遍低估的问题:主流 VLA (π0、GR00T-N1、RDT) 处理 heterogeneity 的方式是给 action decoder 加 per-embodiment 的 projection head——这只在最末端动作生成阶段起作用,让早期的多模态推理对 embodiment 完全无感。这种 late-fusion 处理忽视了 camera 配置、视觉域、任务分布等其他 heterogeneity 维度。
四种处理 heterogeneity 的设计空间
作者把现有思路拉成 4 个候选方案做对比:
Figure 2. 四种 cross-embodiment heterogeneity 处理方法的对比
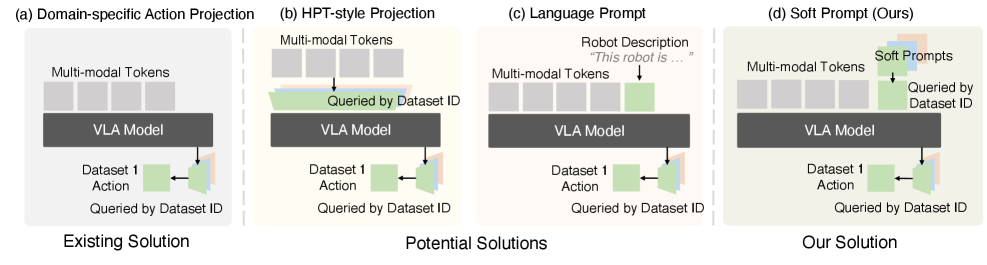
- (a) Domain-specific action projection:主流做法,per-embodiment 输出 head。问题:只影响输出,backbone 不感知 embodiment
- (b) HPT-style projection:在 observation 端加 domain-specific projection layer 把不同来源映射到共享空间。问题:扰动了预训练 VLM 的 feature distribution,训练不稳
- (c) Language prompt:把 hardware 配置写成自然语言描述喂给 VLM。问题:依赖手工 template,不可扩展
- (d) Soft prompt:每个数据源一组 learnable embedding ,end-to-end 优化。 不是预定义的,而是隐式学出来的
❓ 作者把 (a)/(b)/(c) 都和 (d) 单独对比,但实际系统里 action head 和 soft prompt 是可以并存的。Tab.1 的 ablation 也确实在最终 X-VLA 里保留了 action 端的处理。文中说 soft prompt “替代” action head 的程度其实有点暧昧。
Method: Heterogeneous Soft Prompt Learning + X-VLA 架构
Soft Prompt 的形式化
对每个数据源 ,引入一组 learnable embedding ,目标是隐式编码该数据源的 hardware 配置:
不预定义,而是通过 end-to-end flow-matching 训练隐式学出。Soft prompt 在 transformer 早期就注入,让 backbone 在 multimodal fusion 阶段就能 condition 在 embodiment 上。
Flow-matching policy
X-VLA 用 OT path 的 flow matching 学速度场 :
其中 ,。推理时用 Euler 方法迭代 。
X-VLA 架构:disentangled encoding + vanilla transformer stack
核心 design 是显式拆开高维 / 低维输入流,再让 vanilla transformer encoder 做 fusion——抛弃 DiT-style 复杂 decoder。
(1) 高维 observation stream:
- 主流:fixed-view 图像 + language instruction → Florence-Large VLM encoder(提供稳定的高层 task 推理上下文)
- 辅助流:wrist-view 等 auxiliary view → 共享 vision backbone(wrist 视角 noisy、变化快但对精细操作关键,与 language 解耦)
这是对 π0 等”全部塞 VLM”做法的反思——作者认为 wrist view 的语义和 fixed view 差太多,混在一起会污染 VLM 的视觉语言推理能力。
(2) 低维 proprioception–action stream:
- 把 (joint position / EEF pose) + (noisy action sample) + time embedding concat
- 通过 lightweight linear projection 升到高维 feature space,与高维流 early fusion
(3) Soft prompt 注入 在早期 fusion 阶段,引导 backbone embodiment-aware 推理。
训练 recipe:两阶段 adaptation 是关键
Phase I: Pretraining:backbone 和 soft prompts 联合优化 flow-matching loss。Custom LR:给 soft prompt 和 vision-language module 用更小的 LR,避免 catastrophic drift。
Phase II: Two-step adaptation(部署到新 hardware ):
- Prompt warm-up:固定 backbone,只训新引入的 ,让它先学到把 frozen embodiment-agnostic feature project 到新 embodiment 的方向
- Joint policy adaptation:解冻 backbone,joint finetune
这个 two-step 类比 LLM→VLM 的适配套路(先调 connector / projector,再 joint train),把 prompt 视作 hardware-side 的 connector。
Data processing
- Aligned action representation:所有数据源都标准化成 EEF Cartesian xyz + Rotate6D 旋转 + binary gripper(Rotate6D 解决 Euler/quaternion 的 discontinuity)。XYZ/旋转用 MSE,gripper 用 BCE
- Intention abstraction:不预测 per-step action,而是用 30 个 anchor point 概括未来 4 秒的轨迹意图——避免 low-level noise 干扰高层 grounding
- Balanced sampling:跨 domain + 同 domain 内跨 trajectory 都 shuffle,对抗 dominant domain 的 distributional bias
Experimental Results
Ablation:每一步设计都正向贡献
Table 1. X-VLA 设计的 ablation path(PT validation error / AD success rate on Simpler-WidowX)
| 阶段 | 改动 | Val Error (PT) | Acc (AD) |
|---|---|---|---|
| Baseline (Florence-base + DiT-base, no PT) | — | — | 4.1 |
| Pretraining technique | + Custom LR (no PT) | — | 39.6 (+35.5) |
| + Heterogeneous PT | 0.11 | 25.0 (-14.6) | |
| Data processing | + Action alignment + Intention abstraction + Balanced sampling | 0.077 (-0.033) | 50.0 (+25.0) |
| Architecture | + Replace DiT with Transformer encoder | 0.071 (-0.006) | 47.9 (-2.1) |
| + Encoding pipeline (disentangled streams) | 0.053 (-0.018) | 64.6 (+16.7) | |
| + Soft prompt | 0.041 (-0.012) | 73.8 (+9.2) | |
| + Scaling up to 0.9B | 0.032 (-0.009) | 89.6 (+15.8) | |
| Finetuning | + Two-step adaptation | 0.032 | 95.8 (+6.2) |
两个值得 highlight 的观察:
- Naive heterogeneous PT 先掉点(39.6 → 25.0),后面靠 data + arch + soft prompt 才把性能拽回来——说明 heterogeneity 真的是个需要刻意处理的问题,不是 free lunch
- PT val error 和 AD acc 强单调相关——作者把这个相关性当成 evaluation cost 优化的关键:用 offline val error 替代昂贵的 rollout adaptation 评测
Scaling 行为
Figure 5. X-VLA 沿 model capacity / data diversity / data volume 三轴的 scaling
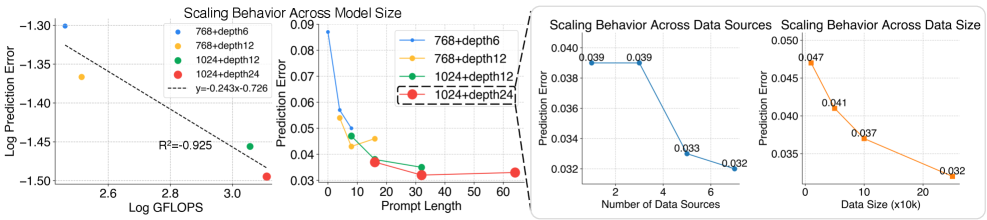
在最大配置 X-VLA-0.9B(hidden 1024, 24 layers, 290K episodes from 7 sources)下未见饱和。
Adaptation: 6 benchmarks, 5 SOTA
Table 2. 与 generalist VLA baselines 在 simulation benchmark 上的对比(节选关键行)
| Methods | Size | Simpler-VM | Simpler-VA | Simpler-WidowX | LIBERO Avg | Calvin ABC→D | RoboTwin-2.0 Easy/Hard | VLABench Avg.PS | NAVSIM PDMS |
|---|---|---|---|---|---|---|---|---|---|
| π0 | 3B | 58.8 | 56.8 | 27.8 | 94.1 | — | 46.4 / 16.4 | 37.8 | — |
| π0+FAST | 3B | 61.9 | 60.5 | 39.5 | 85.5 | — | — | 34.1 | — |
| GR00T-N1 | 3B | 45.0 | 48.4 | — | 93.9 | — | — | 39.7 | — |
| OpenVLA-OFT | 7B | 63.0 | 54.3 | 31.3 | 97.1 | — | — | — | — |
| MemoryVLA | 7B | 77.7 | 72.7 | 71.9 | 96.7 | — | — | — | — |
| UniVLA | 9B | — | — | 69.8 | 95.4 | 4.41 | — | — | 81.7 |
| Max of existing SOTA | — | 78.0 | 72.7 | 71.9 | 97.1 | 4.53 | 46.4 / 16.4 | 39.7 | 81.7 |
| X-VLA (Ours) | 0.9B | 80.4 | 75.7 | 95.8 | 98.1 | 4.43 | 70.0 / 39.0 | 51.1 | 87.3 |
X-VLA-0.9B 在 8 列里 7 列 SOTA(仅 Calvin 略低于 FLOWER 4.53)。Simpler-WidowX 上 95.8% vs. 71.9% 的 24 个百分点跃升尤其反常识——单凭 architecture / soft prompt 解释不完,可能跟 Simpler-WidowX 是 PT 数据里就有的 embodiment 强相关。
PEFT:1% 参数逼近 π0
LoRA 仅调 9M 参数(1% of 0.9B),在 Libero 上 93%、Simpler-WidowX 上 54%——逼近 π0 (3B 全量) 的 94.2% / 55.7%。作者强调”300x fewer parameters”,但这里比较的是 LoRA tunable params (9M) vs. π0 full params (3B),不是 active inference params。
⚠️ 这种”少调参 ≈ 全调参”的 PEFT claim 通常只在 PT 数据/hardware 接近的 distribution shift 下成立。X-VLA 的 PT 不含 WidowX,但 LoRA 还能 work——这是 backbone embodiment-agnostic 的真正证据,比 frozen backbone 实验更有说服力。
Soft Prompt 学到了什么:T-SNE 可视化
Figure 8. T-SNE visualization of soft prompts on 7 data sources
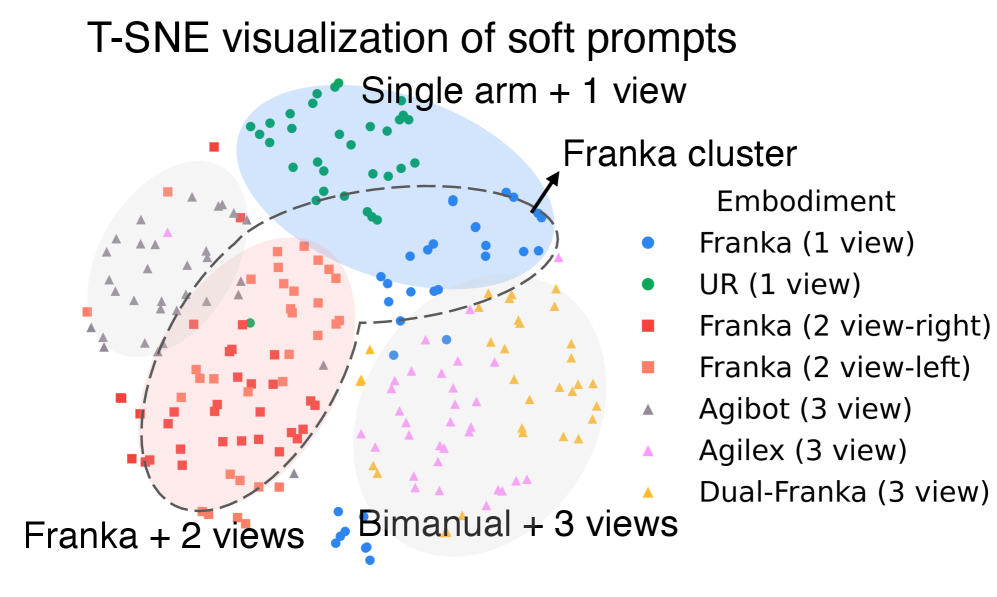
Soft prompt 形成 well-structured cluster,每簇对应一个 hardware 配置——但 Droid 里两个 Franka 的 left/right view 设置 prompt 互相 intermingled(它们只在 designated main view 上有差异)。这暗示 prompt 不是退化成 dataset ID lookup,而是真在编码 hardware 语义。
Cross-embodiment transfer 实验:用 PEFT 在 unseen WidowX 上对比三种 prompt 初始化:
- (1) random + frozen
- (2) UR5 (另一 single-arm) pretrained + frozen
- (3) two-step adapted
(3) 最终最高,(2) 早期收敛快但被 domain gap 卡住,(1) 全程最差。作者把这个观察 framed 为 “prompt retrieval as cross-embodiment transfer” 的 promising route——如果 PT 涵盖足够多 hardware,新 embodiment 可以通过检索最近 prompt 实现 zero/few-shot。
Real-world 与 dexterous cloth folding
Figure 7. Real-World Evaluation Results:3 个真实平台 + bi-manual cloth folding (Soft-Fold 数据集 1200 trajectories)。

X-VLA-0.9B 在 cloth folding 上达到 ~100% 成功率、33 folds/hour,与闭源 π0-folding 持平;公平对比下 finetuned π0-base 和 from-scratch ACT 均无法 match。
Soft-Fold 数据集承诺开源(高质量 cloth folding 数据极稀缺,1200 episodes 用 DAgger-style 收集 + 两阶段拆分 [smooth → fold])——单这个 dataset 就值得追踪。
关联工作
基于
- π0 (Black et al. 2024): X-VLA 的主要 baseline 和 architecture 灵感来源(dual-system VLM + DiT decoder),X-VLA 简化为 single-system + Transformer encoder
- π0.5: 同系列 follow-up,X-VLA 用 LoRA 9M 参数 claim 逼近 π0 全量
- Florence-Large (Xiao et al. 2023): 主视觉语言 backbone
- Flow Matching (Lipman et al. 2023): action generation 的核心 loss formulation
对比
- OpenVLA / OpenVLA-OFT: 7B autoregressive VLA baseline,X-VLA 0.9B 在 Libero / Simpler 全面超越
- GR00T-N1: NVIDIA 3B humanoid VLA,per-embodiment action head 的代表
- RDT (1B): per-embodiment action head 的 bi-manual VLA baseline
- SmolVLA (2B): 类似 efficiency-oriented 路线,X-VLA 0.9B 在 Libero 上 98.1 vs. 88.8
- Octo (0.1B): cross-embodiment generalist 早期工作,X-VLA 在所有 benchmark 上数十点领先
- π0+FAST: action tokenizer 路线对比,X-VLA 用 flow matching 而非离散 token
- HPT: 把 observation 用 per-domain projection 映射到共享空间,被 X-VLA 在 Sec.3 (b) 列为对比并指出 instability
方法相关
- Prompt Tuning (Lester et al. 2021): soft prompt 的原始来源,X-VLA 把它从 NLP frozen-LM adaptation 移植到 multi-task heterogeneous robot pretraining
- Meta-learning / Multi-task learning:作者明确 framed soft prompt 学习为 task-feature 抽取问题
- Rotate6D (Zhou et al. 2019): 旋转表示,被用于消除 Euler/quaternion 不连续性
- DAgger: cloth-folding 数据采集策略(每 100 episodes 训练 ACT、找 failure mode、靶向补数据)
- LoRA: PEFT 实现
论文点评
Strengths
- Problem framing 清晰:把”VLA 处理 heterogeneity 只盯 action head”这个 unspoken convention 摆出来,并系统地拉出 4 个候选方案做对照(Fig. 2 的 (a)-(d))。这是真正的 first-principles 贡献——让人意识到 heterogeneity 是 multi-task / meta-learning 问题而不是 output projection 问题
- Soft prompt 的可解释性证据扎实:T-SNE 上 Droid 同源 Franka prompt 的 intermingling 是反 brute-force ID 假设的强证据,比单看 cluster 漂亮要 informative 得多
- Cross-embodiment transfer 实验有 ablation 风范:random vs. nearest pretrained vs. adapted 三组比较把 “prompt 学到 hardware 语义”的 claim 推到了可操作层面(prompt retrieval for unseen embodiment),不只是修辞
- PEFT 1% 参数逼近 π0 全量——这是 backbone 真正学到 embodiment-agnostic 表征的关键证据,比 zero-shot 失败/成功更难造假
- 架构简化对的方向:用 vanilla transformer encoder 替 DiT、disentangle high/low-dim stream、early fusion——0.9B 就打过 7B 的 OpenVLA-OFT 和 9B UniVLA,参数效率说明白了
- Open source 完整:code、weights、Soft-Fold 数据集、ICLR 2026 接收 + LeRobot 集成 + IROS 2025 AgiBot Challenge 冠军——可复现 + 社区采用
Weaknesses
- Soft prompt 的可扩展性边界没探:每个数据源一组 prompt 在 7 个数据源时 work,但 OXE-scale (~1000 数据源) 下 prompt 数量爆炸。作者提到 “prompt retrieval” 但没真正实验 scale 到几十/几百个 source 的 case
- Simpler-WidowX 95.8% vs. 71.9% 的跃升缺乏 attribution:24 点提升不可能全归功于 soft prompt——可能跟 Florence VLM 选择、wrist-view 单独编码、intention abstraction 等的组合相关。Tab.1 的 ablation 显示 soft prompt 单独贡献 +9.2,scaling 贡献 +15.8——这两块加起来才是大头
- Custom LR 这种 stabilization trick 缺独立 ablation:被列为 “+Custom LR (w/o PT)” 一行带过,但实际可能是稳定异构训练的关键。这种隐性超参依赖很难复现
- 没有 OXE pretraining 对比:所有大型 generalist VLA (π0, GR00T-N1, OpenVLA) 都是在 OXE 上 pretrain 的,X-VLA 自选了 290K episodes from Droid+Robomind+Agibot。data mix 不同的话,Tab.2 的对比其实有点苹果 vs. 橘子
- Action representation 强假设:所有 embodiment 都映射到 EEF + Rotate6D + binary gripper,对于 mobile base、humanoid、multi-finger 等更复杂 morphology 不直接 work——文中没讨论 limitation
- Calvin 仍输给 FLOWER (1B, 4.53 vs. 4.43)——文中没解释为什么唯独 Calvin 没赢
可信评估
Artifact 可获取性
- 代码: inference + training,完整开源在 https://github.com/2toinf/X-VLA,并已 native 集成到 LeRobot
- 模型权重: X-VLA-0.9B checkpoint 在 HuggingFace https://huggingface.co/collections/2toINF/x-vla 公开
- 训练细节: 较完整——Appendix G (Pretraining Details) / H (Finetuning) / I (Preliminary Experiments) / J (Real-world Evaluation) / K (Baseline Training) 覆盖超参 + 数据配比;Soft-Fold 数据集采集协议 (Appendix F) 详细描述
- 数据集: 部分公开——Soft-Fold (1200 episodes cloth folding) 承诺开源 (https://huggingface.co/datasets/Facebear/XVLA-Soft-Fold);PT 数据 Droid / Robomind / Agibot 均为已公开数据集
Claim 可验证性
- ✅ 6 个 sim benchmark 上 5 个 SOTA:每个 benchmark 有标准评测协议,baseline 数值对应 Tab.2 引用,可独立复现
- ✅ PEFT 1% 参数(9M)在 Libero 93% / Simpler 54%:基于公开 benchmark + 开源 weight,可复现
- ✅ Soft prompt T-SNE 形成 hardware-aligned cluster:基于 PT checkpoint 直接可视化,可复现
- ✅ Cloth folding 33 folds/hour, ~100% success:实物实验 + 长视频证据 (120-min uncut on YouTube),相对硬证据
- ⚠️ “300× fewer parameters than π0”:比较的是 LoRA tunable params (9M) vs. π0 full params (3B)。inference 时 X-VLA 仍是 0.9B vs π0 3B,“3.3x” 才是 fair 比较。“300x” 是 marketing 修辞
- ⚠️ Simpler-WidowX 95.8% vs. 71.9% (+24 点):跃升幅度过大,部分可能来自 PT data 与 WidowX 的 distribution overlap,作者未做 leave-one-out PT 分析
- ⚠️ “comparable to π0-folding (closed-source)“:π0-folding 是闭源闭数据 baseline,所谓”comparable”基于作者复现 π0-base 的 finetuning 结果,这个复现本身的 fidelity 不可独立验证
- ❌ “To the best of our knowledge, no prior model has reported such comprehensive evaluation”:这是范围性 marketing claim,不是技术 claim
Notes
- 核心 takeaway for VLA 设计:把 heterogeneity 处理推到 input 端是个 simple, scalable, generalizable 的方向。如果接受这个 framing,那么 per-embodiment action head(π0、GR00T-N1、RDT 都用)在未来工作里应该被 deprioritize
- 可挖的 follow-up:
- Prompt 数量 scaling:扩到 OXE-scale 100+ 数据源时,“per-source learnable prompt” 是否还 work?需不需要分层 prompt(embodiment-level + setup-level)?
- Prompt retrieval 协议:作者只做了 UR5→WidowX 的 nearest-prompt 实验,没设计真正的 retrieval mechanism。一个 follow-up 是 train 一个 small classifier 把 unseen hardware 的 metadata mapping 到 prompt space
- Prompt 的 compositionality:能不能把 “arm kinetics prompt” + “camera config prompt” 组合?现在的 prompt 是 hardware-monolithic 的
- 对我自己研究的影响:
- VLA + cross-embodiment 方向的 must-cite。tag 选
VLA(核心)+cross-embodiment(核心创新点)+flow-matching(action generation 方法) - Soft prompt 的 T-SNE 证据值得放进未来 cross-embodiment 工作的 introduction,作为 “input-side conditioning works” 的支撑
- VLA + cross-embodiment 方向的 must-cite。tag 选
- 疑问:
-
❓ Soft prompt 与 action head 是否真的互斥?文中 Tab.1 没单独对比 “soft prompt only” vs “soft prompt + action head”——可能两者并存才是最优
-
❓ Calvin 输给 FLOWER 的根本原因?是 long-horizon language conditioning 还是 PT data 不含 Calvin-style 任务?
-
❓ 0.9B 是不是 sweet spot?文中说 scaling 未饱和但没给 1.5B / 3B 实验——可能是算力限制,但这也意味着 “0.9B beats 7B” 的 claim 暂时只在这个具体配置下成立
-
Rating
Metrics (as of 2026-04-24): citation=66, influential=7 (10.6%), velocity=10.31/mo; HF upvotes=16; github 628⭐ / forks=53 / 90d commits=1 / pushed 10d ago
分数:3 - Foundation 理由:X-VLA 重写了 cross-embodiment VLA 的 problem framing——从 “action head 兜底异构性” 转为 “input-side soft prompt 作为 hardware-aware 早期调制”(Strengths #1),并用 T-SNE intermingling、UR5→WidowX prompt 迁移、PEFT 9M 参数逼近 π0 全量(Strengths 2-4)三组正交证据把 claim 推到可操作层面;外部信号上,ICLR 2026 接收 + LeRobot 原生集成 + IROS 2025 AgiBot Challenge 冠军 + 开源完整(Strengths #6)表明它正在成为 VLA 方向的 de facto baseline 和必读参考,而非止步于 “近期 SOTA”。相比 2 档,它不只是一个 SOTA 数字——而是以 first-principles 方式重构了一类问题的处理范式,后续 cross-embodiment 工作很难绕开它。2026-04 复核:6.4mo 发布,cite=66/vel=10.31/mo(与 UI-TARS-2 13.51/mo 同一 Foundation 级别区间)、inf=7 (10.6%) 贴 rubric 典型值、仓库 628⭐+近期 active(10d)——引用节奏与社区采纳信号都 consistent 于 Foundation 档,原判断成立。