Summary
Diffusion Policy: Visuomotor Policy Learning via Action Diffusion
- 核心: 把 visuomotor behavior cloning 重新参数化为 action 空间上的 conditional DDPM——policy 不再一次性回归 action,而是 iterative denoising 一段 action sequence。
- 方法: Conditional DDPM 预测 action trajectory;visual observation 作为 condition 而不是 joint 变量(encode-once);receding-horizon 执行(predict , execute );CNN (FiLM) 和 Transformer (cross-attn) 两种 noise-prediction backbone;DDIM 加速推理(训练 100 / 推理 10 步,~0.1s on 3080)。
- 结果: 跨 4 个 benchmark / 15 个 task,平均 success rate 相对 SOTA(LSTM-GMM、IBC、BET)提升 46.9%;真实机器人完成 Push-T、Mug Flipping、Sauce Pouring、以及 bimanual Egg Beater / Mat Unrolling / Shirt Folding。
- Sources: paper | website | github
- Rating: 3 - Foundation。该工作把 diffusion 作为 action 表示的范式落地,citation=2857 / influential=624 / 77.2 per month / 4k stars,是后续 VLA(π0、Octo 等)“flow/diffusion head” 的共同起点。
Key Takeaways:
- Action 空间上做 diffusion 的 why:behavior cloning 的核心痛点是 demonstration 的 multimodality(同一 state 多种合理 action)、high-dim action sequence、以及 high-precision。Explicit regression 会 mode-average,IBC 的 EBM 方案需要负采样、训练不稳。Diffusion 直接学 score 绕开归一化常数,天然 multimodal、天然支持 sequence,训练稳定。
- Visual conditioning 而非 joint modeling:相比 Diffuser(Janner et al. 2022a)把 state 和 action 放在 joint distribution 里去噪,本文只对 建模——visual encoder 每次 forward 只跑一次,不进入 步 denoising 循环,inference 可实时。
- Receding-horizon 是 sequence prediction 的 killer feature:预测 步、执行 步,比 single-step 更平滑、减轻 idle action(BC 老大难)、同时保留闭环响应。Ablation 显示 太小噪声大、太大反应慢。
- Position > velocity control:与 BC 主流相反。作者解释 velocity control 下 multimodality 被时间积分平均掉,而 position control 让 modes 保留在 action 上,刚好匹配 diffusion 的多峰表达能力;position control 的 compounding error 问题也因为 action-sequence receding-horizon 被缓解。
- Architecture 选择的经验规则:CNN (1D temporal + FiLM) 默认够用、鲁棒;Transformer 在 state-based + 高频动作变化任务上更强,但超参敏感。作者明确给出 “先试 CNN、不行再上 Transformer” 的建议——后续 Pi0 等工作反而用 Transformer + Flow Matching 成为主流。
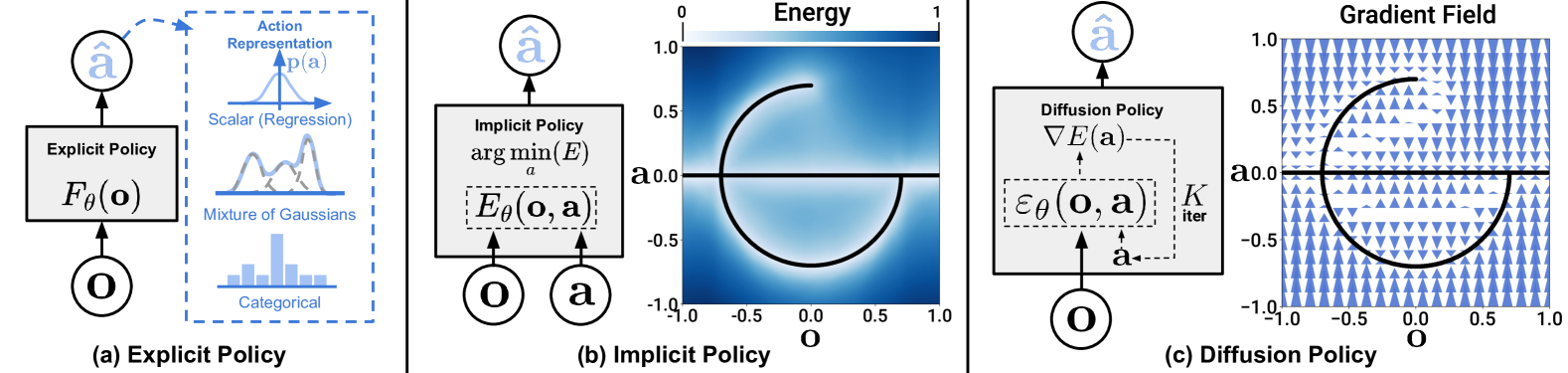
Teaser. Policy representation 的三种范式。 这张图是理解本文贡献的关键对比:(a) Explicit policy 直接回归 action(或用 GMM / 离散化 / mixture 来表达多峰);(b) Implicit policy(IBC)学一个 (obs, action) 的 energy,推理时优化;(c) Diffusion policy 通过 步 denoising 把 Gaussian 噪声 refine 成 action,这实际是在学 action score 的 gradient field。
Figure 1. Policy Representations 对比
Diffusion Policy Formulation
把 DDPM 搬到 action 空间
标准 DDPM 的 denoising 更新:
Equation 1. DDPM denoising step
符号说明: 初始噪声; 噪声预测网络; 是 的函数(noise schedule)。 含义:可以视作一次带噪的 gradient descent, 在预测一个 implicit energy 的 gradient 。
训练目标是 denoising score matching 的 :
Equation 2. DDPM training loss
两处关键改造
Diffusion 用于 visuomotor policy 需要两个修改:
- 把 从图像改成 action 序列 。
- 把 denoising 过程 condition 在 observation 上,建模的是 而不是 Diffuser 的 joint 。
由此得到 visuomotor diffusion update:
Equation 3. Conditional action diffusion
含义:把 observation 作为 condition 而不是 denoising 目标的一部分,换来两个好处——(i) vision encoder 只在每个 decision 跑一次, 步循环只跑 action 头,推理显著加速;(ii) vision encoder 可和 diffusion head 一起 end-to-end 训练。
Closed-loop action-sequence prediction
每个 decision:输入过去 步 observation,预测未来 步 action,执行其中 步后重新规划。 允许 warm-start 下一轮推理。这是 diffusion policy 和 single-step BC 最大的执行差异——既有 long-horizon consistency 又能对意外快速响应。
Figure 2. Diffusion Policy overview(CNN-FiLM 和 Transformer 两种 backbone)
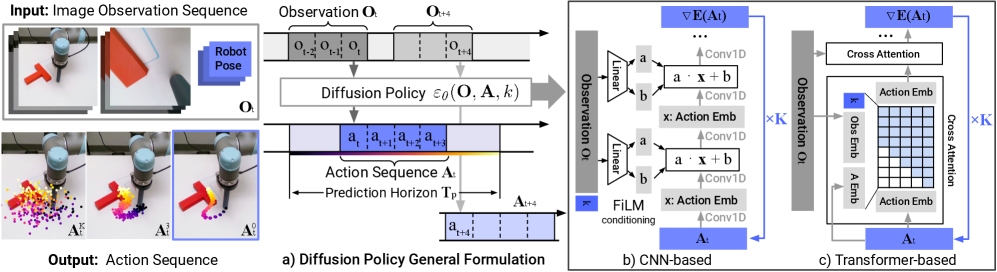
Key Design Decisions
Network Architecture
CNN-based:沿用 [Janner et al. 2022b] 的 1D temporal U-Net,用 FiLM 把 和 逐 channel 注入。作者发现 CNN 在大多数 task 上 out-of-the-box 好用,但在 velocity control / 高频 action 变化 时欠佳——temporal conv 的低频归纳偏置是一个 over-smoothing 源。
Transformer-based:借鉴 BET (Shafiullah et al. 2022) 的 minGPT 结构——noisy action token 作为 decoder input,diffusion step 的 sinusoidal embedding 作为第一 token,observation 作为 cross-attention 的 memory,causal mask 确保 只看自己和之前的 action token。state-based 任务和高频动作变化任务上更强,但对 LR、warmup 等超参敏感。
❓ Causal mask 对 action sequence 来说其实并不必要(action 之间不是自回归而是 joint denoising)。作者保留它大概率是 minGPT 架构的历史惯性——值得怀疑是不是个 free lunch 的简化空间。
推荐:先 CNN,效果不够再上 Transformer(+调参成本)。
Visual Encoder
ResNet-18 from scratch,两处改动:(1) global avg pool → spatial softmax(保留空间信息,来自 Robomimic 的经验),(2) BatchNorm → GroupNorm(BN 和 EMA 组合不稳定,这是 DDPM 常见细节)。每个 camera view 独立 encoder,每帧独立编码再 concat。
Noise Schedule
经验上 iDDPM 的 Square Cosine Schedule 最好。 作为 的函数决定了模型能捕获 action 信号的高频/低频成分的比例。
Inference 加速
训练 100 DDPM 步,推理用 DDIM 10 步,0.1s on 3080——这使实时闭环控制可行。作者在 Limitations 里点名期待 consistency models 进一步降推理步数。
Intriguing Properties
4.1 Multi-Modal Action Distributions
Push-T 任务里给定 state,end-effector 可以从左或右绕过障碍推 T 形物体。
Figure 3. 多峰对比:Diffusion Policy vs LSTM-GMM / IBC / BET
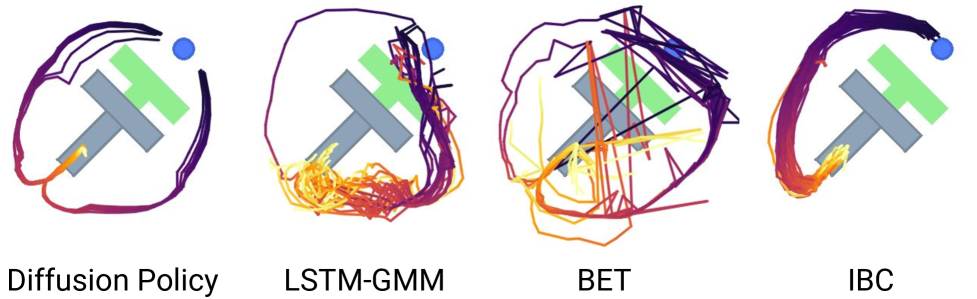
- LSTM-GMM(Robomimic)和 IBC(Implicit BC)偏向单一 mode;
- BET 捕获多 mode 但缺乏 temporal consistency,rollout 中频繁 mode switching 导致失败;
- Diffusion Policy 每次 rollout commit 到一个 mode(归功于 sequence prediction)但不同 rollout 覆盖不同 mode。
多峰性的两个来源:随机初始化( 决定落入哪个 basin)+ Langevin dynamics 的随机扰动(允许 basin 间迁移)。
4.2 Synergy with Position Control
反直觉的发现——BC 主流是 velocity control,作者 empirically 发现 position control 显著更好。解释:
- Velocity control 通过时间积分平均掉 action 的多峰性,让单时刻看到的分布更单峰——这对普通 explicit policy 有利,但白白浪费了 Diffusion Policy 的多峰建模能力。
- Position control 下 compounding error 更严重,但 action-sequence + receding-horizon 正好缓解这一点。
这条 insight 本身非常值得后续工作 revisit——它揭示了 “policy 的表达能力” 和 “action 空间选择” 的耦合。
4.3 Action-Sequence Prediction 的好处
- 缓解 BC 的 idle action 问题(demo 中的暂停会被单步 BC 学成 “停下不动”)。
- 让 temporal consistency 内生于 prediction horizon 里,不需要额外 smoothing。
- 的 ablation:太小(单步)噪声大、太大反应迟钝,sweet spot 约 8 步。
4.4 Training Stability
和 IBC 对比的核心优势。IBC 的 InfoNCE loss 需要负采样估计 partition function,梯度偏差随负样本分布漂移。Diffusion 的 score matching 是 proper loss,不需要负采样。作者的训练曲线显示 Diffusion Policy 的 loss 和 success rate 同步、单调。
4.5 Connections to Control Theory(扩展版新增)
把 denoising 过程视作一个 optimization——Diffusion Policy 在推理阶段本质上是在 action score field 上做 Langevin sampling 去求 modal action。作者把这和 sampling-based MPC、cross-entropy method 的类比讲清楚。
Evaluation
5.1 Benchmarks
- Robomimic(Mandlekar et al. 2021):5 task × PH/MH 数据,9 个变体,state 和 image 两种 observation。
- Push-T(IBC, Florence et al. 2021):2D planar pushing,多峰性极强。
- Block Pushing / Franka Kitchen(BET, Shafiullah et al. 2022):multi-goal task, mode coverage 指标。
- 总共 15 tasks。
5.2 Baselines
LSTM-GMM(Robomimic SOTA)、IBC(implicit policy representative)、BET(clustering + offset)。
5.3 Key Findings
跨 15 tasks 平均 success rate 相对 SOTA 绝对提升 46.9%。最显著的提升发生在高精度、多峰、长 horizon 任务上(Tool Hang、Transport、Push-T)。
❓ “46.9%” 这个 headline 数是对每个 task 的相对或绝对提升平均?作者在 Appendix B.2 明确是 “(ours − baseline) / baseline 再跨 task 平均”,因此对 baseline 低的 task 权重天然大——不算 cherry-pick 但要这样读。
5.4 Ablation (扩展版新增)
- Architecture variants:CNN-based 和 Transformer-based 的 trade-off 系统化。
- Pretraining/Finetuning:ImageNet-pretrained encoder 并不总是更好(端到端训练在 image domain 上也能收敛到合理 feature)——这和后来 VLA 普遍用 pretrained vision backbone 的做法形成对比。
Realworld Evaluation
6. Single-arm tasks
- Push-T:对扰动和视觉干扰鲁棒。
- Mug Flipping:接近运动学极限的 6-DoF 平滑轨迹。
- Sauce Pouring & Spreading:流体操作、周期性动作。
7. Bimanual tasks(扩展版新增)
- Egg Beater、Mat Unrolling、Shirt Folding:验证双臂协调和柔性物体操作。这些任务证明 diffusion policy 能 scale 到更高维 action(双臂 × 6DoF + gripper),和后来 Mobile ALOHA 的双臂 BC 形成互补。
关联工作
基于
- DDPM (Ho et al. 2020):action 扩散的数学骨架。
- Diffuser (Janner et al. 2022a):state+action joint diffusion 做 planning——本文明确地把它简化为 action-only + obs-as-condition,这是推理加速和端到端训练的关键区别。
- iDDPM (Nichol & Dhariwal 2021):Square Cosine noise schedule。
- Robomimic (Mandlekar et al. 2021):benchmark + LSTM-GMM baseline + spatial softmax 视觉技巧。
对比
- IBC (Florence et al. 2021):implicit policy 用 EBM,训练不稳——Diffusion Policy 在 representation expressiveness 上继承 IBC 但解决训练稳定性。
- BET (Shafiullah et al. 2022):clustering + offset 的多峰 BC,temporal consistency 差。
- LSTM-GMM(Robomimic):explicit mixture, mode 有限。
方法相关 / 后续
- Octo:generalist manipulation policy,diffusion head 作为 action decoder 的范式本质上继承 Diffusion Policy。
- π0 / π0.5 / π0.7:把 diffusion 换成 Flow Matching,但 “VLM backbone + 生成式 action head + action chunking” 的总架构与 Diffusion Policy 一脉相承。
- OpenVLA-OFT、SmolVLA:同样沿用 action-chunk diffusion/flow 路线。
- RoboVLMs:把 VLM backbone 接 diffusion action head 的系统化对比。
- Consistency Policy / DDIM-Policy:针对 diffusion policy 推理延迟的后续加速工作。
- DP3、Diffusion Transformer Policy:3D 输入和更大模型尺度的扩展。
论文点评
Strengths
- 问题表述正确:把 BC 的核心 pain point(multimodality、sequence、stability)与 policy representation 的选择一一对应地分析,随后用一个数学上干净的 diffusion 公式同时解决三者。这是典型的 “important question, simple method”。
- 工程关键决定讲得清楚且 ablation 充分:receding-horizon、position vs velocity、CNN vs Transformer、visual encoder 细节、DDIM 加速——每一条都有对应实验。后人可以几乎 “查表” 选超参。
- benchmark 覆盖广:15 tasks × sim+real × single/bimanual × 刚性/流体,把 “该方法适用边界” 划得足够清楚,让社区有信心采用。
- Reproducibility 高:代码、数据、超参、环境都公开,repo 4k+ stars 反映在被广泛用作 baseline。
- 影响深远:2857 citations / 624 influential(22% 比例,远高于 ~10% 典型值)说明方法被 substantively 继承,而不是只被引用为 landmark。
Weaknesses
- 推理延迟仍是 bottleneck:0.1s @ DDIM 10 steps 对 contact-rich 高频控制仍慢,Limitations 自己也点名了——后续 consistency / flow matching 路线正是冲着这个去的。
- “46.9%” 的算法(相对提升跨 task 平均)对低 baseline task 权重大,单看 headline 会高估;不过作者在 Appendix 披露得很透明,不算 misreport。
- Architecture 建议偏经验:CNN vs Transformer 的 trade-off 主要靠实验观察,缺乏理论解释(temporal conv 低频 bias 的 Tancik 2020 引用是 hint 但不是证明)。
- Scale 未被充分探索:论文时代的 action diffusion 只到单机 / 单任务规模,没回答 “diffusion policy 能否作为 VLA 的 action head scale 到 cross-embodiment”——这个答案由后续的 Octo / π0 给出,本文只是埋下了种子。
- 对 suboptimal data 无能为力:作为 BC 的扩展,继承了 BC 的全部局限,作者诚实承认并指向 RL 扩展(Wang 2023, IDQL 等)。
可信评估
Artifact 可获取性
- 代码: inference + training 均开源(
real-stanford/diffusion_policy)。 - 模型权重: 提供多个 pretrained checkpoint(Push-T、Robomimic 各 variant)。
- 训练细节: 超参、数据配比、训练步数在 Appendix A.4 完整披露(batch size、LR schedule、EMA decay、augmentation)。
- 数据集: 开源(Robomimic、Push-T、BET benchmark 均公开;real-world demo 数据随论文发布)。
Claim 可验证性
- ✅ “平均提升 46.9%“:benchmark 开源,社区广泛复现;公式见 Appendix B.2。
- ✅ “stable training”:loss 曲线与多 seed 统计公开。
- ✅ “position control 优于 velocity control”:同 benchmark 内对照实验,结论被后续工作如 ACT、π0 的默认 action space 间接佐证。
- ⚠️ “46.9% headline 跨 benchmark”:相对提升的平均对低 baseline 的 task 偏重,更严谨的读法是看每 task 表;作者在 Appendix 披露了,不算 overclaim,但 headline 引用时要当心。
- ⚠️ “CNN 在大多数 task 足够好”:这是软性推荐,随 task 分布而变;后续 VLA 主流反而选 Transformer,说明 “大多数” 的样本分布有时代性。
Notes
- 本文是 action-space 生成式建模 的分水岭。它不仅是一个方法,更是重新定义了 “policy 是什么” ——从 的 regression/classification,变成 的 generative sampling。后续 Flow Matching 系(π0 等)、Consistency Policy、Discrete Diffusion for action 都是这个思路的变体。
- 一个有趣的反思:作者推荐 “先 CNN”,但社区最终主要走 Transformer——部分是因为 VLA 时代的 backbone 天然是 Transformer,一致性使然;部分是因为 scale 后 Transformer 的超参敏感性下降。方法推荐的时效性很短。
-
❓ 如果今天重做,用 Flow Matching 替换 DDPM + 直接从 pretrained VLM 出 feature 是否还需要 “visual conditioning as encode-once” 这个 trick?—— 推理加速层面是的,但训练效率上 VLM 重到无法 end-to-end,反而退回 frozen backbone 路线。架构最优解随 scale 变化。
Rating
Metrics (as of 2026-04-22): citation=2857, influential=624 (21.8%), velocity=77.2/mo; HF upvotes=6; github 4045⭐ / forks=744 / 90d commits=0 / pushed 484d ago · stale
分数:3 - Foundation 理由:Diffusion Policy 是 action generation 范式的奠基工作——citation 2857 / influential 624(21.8% 远高于 ~10% 典型,说明被实质性继承而非只是 landmark 引用);velocity 77.2/mo 在发表 3+ 年后仍保持活跃引用。后续几乎所有 “VLM backbone + 生成式 action head” 的 VLA 工作(Octo、π0、SmolVLA)都可以追溯到它定义的 “action chunk + diffusion/flow head + receding-horizon” 三件套。repo 虽已 stale(484d 未更新、90d commits=0),但这只反映原作者已 pivot(Cheng Chi 去了 Stanford),不削弱方法影响力——fork 744 和社区再实现说明代码仍是 de facto 参考。相对 2 档(Frontier),Foundation 档的核心证据是它已经成为方向必引必读的 representation paradigm,不是某个 SOTA 数字的占位。