Summary
What Matters in Building Vision-Language-Action Models for Generalist Robots
- 核心: 一篇 VLA 设计空间的大型 empirical study —— 在 8 个 VLM backbone × 4 类 VLA 结构 × 多种训练目标/数据策略上跑了 600+ 实验,给出”哪种 backbone、什么结构、何时引入 cross-embodiment 数据”的工程性结论
- 方法: 提出 RoboVLMs 统一框架,把任意 VLM 转成四类 VLA(One-Step-Disc/Cont、Interleaved-Cont、Policy-Head-Cont),在 CALVIN / SimplerEnv / 真实 Kinova Gen3 上做 controlled comparison
- 结果: KosMos / PaliGemma + policy-head + 连续动作 + 完整 chunk 执行 = best recipe;CALVIN ABC→D 上 Avg.Len. 4.25/5(前 SOTA GR-1 为 3.06),real-robot 20 任务上对 unseen 设置鲁棒,并出现训练数据中没有的 self-correction 行为
- Sources: paper | website | github
- Rating: 2 - Frontier(VLA 设计空间第一份大规模 controlled study,taxonomy + recipe 有 reference 价值;但 16 个月后 cc=96 / ic=6(6.3% 低继承)低于 Foundation 档奠基工作的典型社区采纳度)
Key Takeaways:
- VLM pretraining 是 VLA 性能的真正源头:KosMos / PaliGemma(pretrain 数据规模大)显著优于 LLaVA / Flamingo / Qwen-VL / MoonDream / UForm,证明”vision-language alignment 质量 → 操作性能”是底层因果链
- 结构上 policy-head + 连续动作压倒性最优:在所有 backbone 上 Policy-Head-Cont > Interleaved-Cont > One-Step-Cont >> One-Step-Disc,且在 ABC→D zero-shot 和 data-scaling 实验中都是最 robust 的
- 完整 chunk 执行 > first-action 执行 > ensemble:long-horizon 多模态动作下,每步重新推理会破坏轨迹一致性,跌幅最大可超 1.5 个任务
- Flow Matching ≈ MSE+BCE:在 PaliGemma 上 diffusion 比确定性 loss 仅有边际优势(< 0.1 Avg.Len.),diffusion 的额外复杂度未带来匹配收益
- Cross-embodiment 不是 free lunch:单纯 OXE co-train 不如 in-domain finetune;只有 “OXE co-train → in-domain post-train” 两阶段对高频任务(pick & place)有帮助,对低频技能反而掉点;few-shot OOD 场景下 pretrain 才显出价值(CALVIN +17.2%)
Teaser. 论文研究的三个核心维度:how (problem formulation, history/action 设计) / which (backbone) / when (cross-embodiment 数据)。
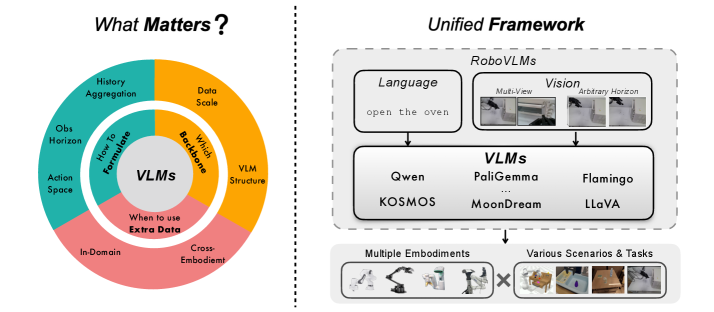
Problem & Motivation
把 VLA 当成 “VLM + 一些 action 适配层” 的做法已经成主流,但这条路径上几乎所有设计选择都缺乏 controlled comparison:
- Backbone 各自为战(RT-2 用 PaLI-X,OpenVLA 用 LLaVA,π0 用 PaliGemma,Octo / GR-1 用自训 transformer),没人公平对比过
- Action 表示分散:discrete token vs. 连续 MLP vs. diffusion / flow-matching head
- History 是塞进 VLM context(interleaved)还是单步特征 + 外挂 policy head?
- OXE 这类 cross-embodiment 大数据到底应该 co-train、post-train 还是干脆别用?
作者把这些维度全部参数化,在 RoboVLMs 框架内统一实现,跑大规模 ablation,目标是给”未来想做 VLA 的人”一份 design guidebook。
❓ “design guidebook” 的定位决定了这篇文章的价值不在新方法(RoboVLMs 本身没什么新东西),而在于 ablation 结论的可移植性——下文需要重点审视这些结论的 scope 边界。
Method:RoboVLMs 框架
VLA 结构分类
作者把已有的 VLA 按 “history 怎么聚合 × action 是否离散” 切成 4 类(图中 b 部分):
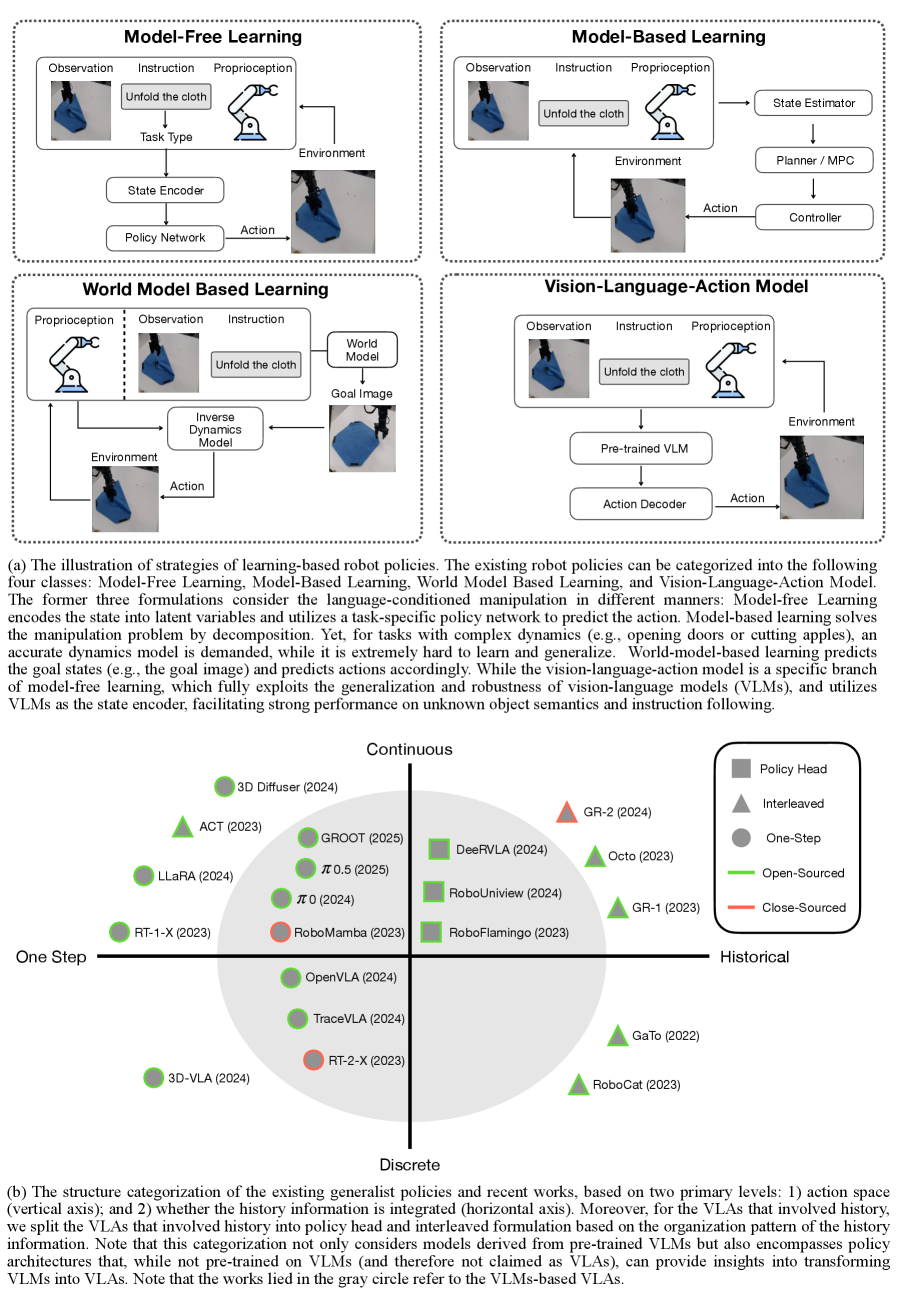
Figure 1. 学习型机器人策略的分类(左)和 VLA 结构变体(右)。 4 类 VLA 分别为 One-Step-Discrete(RT-2、OpenVLA 等)、One-Step-Continuous(ACT、π0 等)、Interleaved-Continuous(GR-1、Octo 等)、Policy-Head-Continuous(RoboFlamingo、RoboUniView 等)。
One-step 模型 —— 只用当前观测 预测未来 步动作:
变体一是连续动作(VLM 输出 [LRN] 学习 token,MLP 解码成动作向量);变体二是离散动作(直接 next-token prediction,每个动作维度被分桶)。
Interleaved-Continuous 模型 —— 输入 token 序列把 H 步历史观测和动作 token 交错:
VLM 一次性 fuse 整个序列,每个 [LRN] 都会被 MLP 解码成对应步的动作 chunk。GR-1 / Octo / GR-2 属于此类。注意只能配 decoder-only backbone。
Policy-Head-Continuous 模型 —— VLM 单步只产生 multi-modal 表征 [LRN]_t,把 H 步表征拼起来交给一个独立 policy head (RNN / Transformer / Diffusion)做 history fusion 和动作预测:
这种结构的好处是 VLM 主体只需做单步多模态对齐——它原本擅长的事——history 建模交给小型专用模块。
评测平台
- CALVIN:4 splits (A/B/C/D) × 34 个 table-top 操作任务,24K 人类示范;指标是 1~5 连续任务成功率与平均执行长度(Avg. Len.)
- SimplerEnv:real-to-sim 复刻 Google Robot 与 Bridge V2 任务
- Real Robot Benchmark:7-DoF Kinova Gen3 + Robotiq 2F-85,70K+ 人类轨迹,105 任务;评测 20 任务 × 5 setting(Simple + Novel Description + Unseen Distractor + Unseen Target + Unseen Background)
关键实验与发现
Finding 1:VLM pretraining 决定 VLA 上限
Question 2: 哪种 VLM backbone 适合 VLA?
作者评测了 8 个 backbone:Flamingo 系列(encoder-decoder)+ LLaVA / Qwen-VL / MoonDream / UForm / PaliGemma / KosMos(decoder-only)。结论:
Finding 2: VLAs benefit from sufficient vision-language pre-training on larger vision-language datasets of VLMs backbone.
KosMos 和 PaliGemma 显著领先,且优势随任务复杂度放大。 作者把这个归因到”大规模 VL pretraining 让 visual–linguistic 表征更对齐,下游策略只需学操作技能本身”。这与 π0 选择 PaliGemma 的工程直觉一致。
❓ 这里其实没有完全 disentangle 模型规模 vs. 数据规模 vs. 架构差异。Qwen-VL 和 LLaVA 的 pretrain 数据也不算小,输了多半因为 visual encoder / fusion 设计而非数据量。论文给出的”data scale → performance”叙事过于干净。
Finding 3:结构选择——Policy Head + 连续动作压倒性最优
Table I (节选). CALVIN ABCD 上不同 backbone × 结构的连续 5 任务成功率(Avg. Len.)。
| Backbone | Structure | Action | 1 | 2 | 3 | 4 | 5 | Avg. Len. |
|---|---|---|---|---|---|---|---|---|
| LLaVA | One-Step | Disc. | 0.81 | 0.48 | 0.28 | 0.18 | 0.10 | 1.85 |
| LLaVA | One-Step | Cont. | 0.79 | 0.59 | 0.42 | 0.33 | 0.24 | 2.37 |
| LLaVA | Interleaved | Cont. | 0.89 | 0.65 | 0.44 | 0.28 | 0.18 | 2.44 |
| LLaVA | Policy-Head | Cont. | 0.87 | 0.68 | 0.51 | 0.38 | 0.28 | 2.71 |
| Flamingo | Policy-Head | Cont. | 0.96 | 0.90 | 0.82 | 0.74 | 0.66 | 4.09 |
| KosMos | One-Step | Disc. | 0.42 | 0.10 | 0.02 | 0.01 | 0.00 | 0.55 |
| KosMos | One-Step | Cont. | 0.94 | 0.87 | 0.81 | 0.77 | 0.70 | 4.09 |
| KosMos | Interleaved | Cont. | 0.99 | 0.92 | 0.82 | 0.74 | 0.66 | 4.12 |
| KosMos | Policy-Head | Cont. | 0.97 | 0.93 | 0.90 | 0.87 | 0.83 | 4.49 |
| PaliGemma | Policy-Head | Cont. | 0.98 | 0.93 | 0.89 | 0.84 | 0.78 | 4.42 |
三条 takeaway:
- 连续动作 > 离散动作:单帧设定下连续动作显著更好,越长 horizon 差距越大——离散动作的 indexing 误差会沿 horizon 放大
- 历史观测 > 单步观测:所有 backbone 上 history-based 都比 one-step 更好
- Policy-Head 历史融合 > Interleaved 历史融合:作者的解释是 policy head 把 history fusion 任务从 VLM 主体里剥离,VLM 可以保留它原本的 vision-language fusion 能力;而且 interleaved 的 memory/FLOP 开销大得多
❓ 这条 “policy head 比 interleaved 更好” 的结论很值得对比 π0 / π0.5 那条 “把 action 塞进 VLM context 才能利用 VL 表征” 的路线——两者等于在押注相反方向。看起来当 backbone 已经过 VL 充分对齐后(如 KosMos / PaliGemma),把 policy 学习从 backbone 里隔离反而保护了表征。这是一个值得深挖的 mechanism question。
Finding 3.1:泛化与数据效率上 Policy-Head 也最稳
在 CALVIN ABC→D 的 zero-shot 设定下,KosMos + Policy-Head 的性能 drop 最小;在 0.1× / 1× / 5× ABCD 数据 scaling 实验中也是 KosMos + Policy-Head 在小数据下衰减最慢。结合上一表 → policy head 不仅是 in-distribution 最优,在 generalization & data efficiency 上也是 dominant。
Finding 3.2:训练目标——Flow Matching ≈ MSE+BCE
Table II(a) 结论摘要(PaliGemma + One-Step-Continuous):
| Training Split | Objective | Exec | Avg. Len. |
|---|---|---|---|
| ABC | Flow Matching | Chunk | 3.68 |
| ABC | MSE+BCE | Chunk | 3.57 |
| ABCD | Flow Matching | Chunk | 4.09 |
| ABCD | MSE+BCE | Chunk | 4.04 |
差距在 0.05~0.11 区间,作者直接给出 Finding:
Finding 3.3: For One-Step-Continuous formulation, Diffusion loss and MSE loss could achieve a similar performance. For inference-time aggregation strategy, it is important to keep execution consistency, particularly for long-horizon tasks and multimodal actions.
执行策略上对比更显著:Chunk > Ensemble > First。Chunk 在 ABC 上 3.68,First 跌到 2.45——单步重推会破坏多模态轨迹一致性。这条与 OpenVLA-OFT 等用 chunk execution 的趋势吻合。
Finding 3.3:MoE 提升泛化但不提升 in-distribution
Table II(b):在 PaliGemma 上加 MoE(即 π0 的 dual-expert 设置)在 ABC→D 训练分割下能提 +0.16 Avg.Len.(3.84 vs 3.68),但在 ABCD 满数据下反而掉点(3.84 vs 4.10)。
Finding 3.4: Introducing the Mix-of-Expert structure can improve the generalization of VLAs, while it can not boost the performance in seen scenarios.
这是个有意思的现象——MoE 的 expert 分离可能保护了 VLM 原生表征不被 action loss 污染,所以在 OOD 场景才有用;但 in-distribution 时这种”保护”反而限制了 capacity 利用。
Finding 4:Cross-embodiment 数据需要 post-train,不是 co-train
作者比较三种使用 OXE 的方式:Co-train(一阶段混训)/ Post-train(先 OXE+in-domain co-train,再 in-domain 单独 fine-tune)/ Finetune(不用 OXE)。
In-domain (OXE 内任务):
- Co-training 几乎没增益:OXE Co-train ≈ RT-Partial Finetune;增加同 robot 的 task-agnostic 数据(RT Finetune)反而比加 cross-embodiment 数据更有效
- Post-train 只在高频任务上赢:Bridge 上 50% (post) vs 44% (finetune);Google Robot 上只在 pick coke can 上赢(OXE 里 pick & place 占比大),其它任务掉点
- Domain 内数据是真正的关键:哪怕 task-agnostic,同 embodiment 数据也比 cross-embodiment 数据更有效
OOD (CALVIN, 不在 OXE 中) few-shot:
- Pretrain 显著有用:单视角 +17.2%(单任务执行率)/ +0.25 Avg. Len.
Finding 4: Extra in-domain data, even from different tasks, shows beneficial, and an extra large-scale cross-embodiment co-training before the post-training stage further improves high-frequency tasks as well as few-shot performance.
❓ 这条结论严格来说只能 generalize 到 “OXE 已覆盖的任务分布 + KosMos backbone + policy-head 结构”。后续 π0 / π0.5 / π0.7 的成功表明大规模 cross-embodiment 在更大模型与更长训练下仍能持续 scale,这里的 600 GPU·h 量级实验很可能尚未达到 cross-embodiment 数据真正发挥作用的 capacity 区间。把 “in-domain > cross-embodiment” 当成普适结论会误导。
真实机器人结果
最优配置(KosMos + Policy Head, 简称 KosMos P.H.)部署在 7-DoF Kinova Gen3 上,对 20 任务 × 5 setting 评测,与 Octo-Base / OpenVLA 对比。
主要观察:
- 所有 setting(Simple / Novel Description / Unseen Distractor / Unseen Target / Unseen Background)都赢,Unseen Background 上优势最大
- Emergent self-correction:当末端执行器位置错误时,KosMos P.H. 能识别并修正未来轨迹完成任务,而 baseline 不会——这个能力在训练数据里不存在
下方是 SimplerEnv 上的 rollout 示例:
Video. SimplerEnv WidowX + Bridge 任务 rollout 示例。
Video. 真实机器人 Unseen Distractor 设置下的 open drawer 任务。
关联工作
基于
- VLM backbones:KosMos、PaliGemma、OpenFlamingo、LLaVA、Qwen-VL、MoonDream、UForm(被作为 backbone 直接 fine-tune)
- CALVIN / SimplerEnv / OXE benchmark 与数据集
对比 / 复刻框架
- One-Step-Discrete 类:RT-2、OpenVLA、3D-VLA、LAPA、Embodied-CoT、RT-1
- One-Step-Continuous 类:ACT、BC-Z、MVP、R3M、VIMA、3D Diffuser、RoboMamba、π0
- Interleaved-Continuous 类:GR-1、GR-2、Octo
- Policy-Head-Continuous 类:RoboFlamingo、RoboUniView、DeeR-VLA
后续 / 相关方向
- OpenVLA-OFT:把本文 “chunk execution + 连续动作” 等结论应用到 OpenVLA 上做改进,与本文结论高度一致
- π0.5 / π0.7:在更大规模上验证 cross-embodiment 数据的 scaling,提供了与本文 Finding 4 的对照证据
- MiMo-Embodied:另一条 reasoning + action 的 VLA 路线,可作为方法多样性的对照
论文点评
Strengths
- 覆盖度罕见:8 backbone × 4 结构 × 多种训练目标 / 数据策略 / 执行模式 × 3 个评测平台,单一论文 600+ 实验在 VLA 领域确实是最大规模 controlled comparison
- 同时 sim + real 验证:CALVIN / SimplerEnv 加 Kinova 真实平台,避免了”只在 CALVIN 拿 SOTA”的常见 overclaim
- 开源完整:代码 + 模型权重 + 真机数据集(ByteDance Robot Benchmark, 8K+ 轨迹)+ 训练 recipe 全开
- 分类框架清晰:把现有 VLA 切成 4 类的 taxonomy 已经成为后续工作(如 OpenVLA-OFT)的标准 reference 框架
- 写作把 question / finding 显式 anchor 出来:每个 sub-section 都用 callout box 把”问什么 / 答什么”标清楚,使得这篇文章作为 reference 时非常好查
Weaknesses
- Scope 不算 generalist:所有 task 都是 table-top 短 horizon 操作,找不到 mobile manipulation / dexterous / 长时序任务。“Generalist policy” 的标题与实测 scope 不完全匹配
- 数据规模偏小:每个 ablation 5 epoch、CALVIN 量级数据,得出的 “in-domain > cross-embodiment” 结论很可能只在小 scale 成立,与 π0 / π0.7 的大规模 cross-embodiment scaling 结论冲突
- Backbone 评测没 disentangle 模型规模:8 个 VLM 的参数量、pretrain 数据量、视觉 encoder 都不同,单纯归因到”VL pretrain 数据规模”过于干净
- Policy-Head vs Interleaved 的 mechanism 解释偏轻:只说 “policy head 保护了 VLM 原生 fusion 能力”,但没有 attention map / probing 等证据。这条结论与 π 系列把 action 塞 context 的趋势相反,机制层面值得更深入分析
- Real-robot 评测样本少:每 setting 3 rollout,对小数差距的统计意义薄弱,self-correction 之类的 emergent 现象观察是定性的
- 方法本身没新意:RoboVLMs 是 framework 而非新方法。论文价值是 empirical insight,不是 modeling contribution
可信评估
Artifact 可获取性
- 代码: inference + training 全开源(github.com/Robot-VLAs/RoboVLMs)
- 模型权重: 已发布 KosMos / PaliGemma / OpenFlamingo 等多个 backbone × VLA 结构组合的 checkpoint(README 中有 huggingface 链接)
- 训练细节: 完整——附录给出了超参、数据配比、训练步数、硬件配置;训练 recipe 在仓库
configs/下 - 数据集: 评测数据集(CALVIN、SimplerEnv、OXE)均已开源;自家 Real Robot Benchmark 已开源 8K+ 轨迹(ByteDance Robot Benchmark, 通过 gr2-manipulation.github.io 提供)
Claim 可验证性
- ✅ CALVIN ABCD 4.49 Avg.Len. SOTA:Table I 完整数据 + 开源 checkpoint + 公开 benchmark,可独立复现
- ✅ Policy-Head + Continuous 是最优结构组合:在多 backbone 上一致重现,趋势 robust,开源代码可复现
- ✅ 离散动作在长 horizon 任务上严重降级:表格数据极其显著(KosMos One-Step-Disc Avg.Len. 0.55 vs Cont 4.09),可信
- ⚠️ “VL pretraining 数据规模决定 VLA 性能”:归因不严,未控制模型规模 / 视觉 encoder 架构等混淆变量,更可能是综合因素
- ⚠️ “In-domain 数据比 cross-embodiment 数据更有效”:scope 受限于实验规模(KosMos + 短训练),与后续大规模 VLA(π 系列)的成功事实有 tension。作为”小规模 fine-tune 场景下的工程建议”成立,作为普适结论需谨慎
- ⚠️ “Emergent self-correction”:定性观察,无定量评估,无 ablation 证明这是 KosMos backbone 特有现象而非随机抽样偏差
- ⚠️ “MoE 提升泛化”:仅在 PaliGemma + ABC→D 设定下观察到 ~+0.16 Avg.Len.,样本面窄,且与 π0 dual-expert 设计的动机(action expert 隔离)逻辑不完全相同
- ❌ 无明显 marketing 话术(论文风格相对克制,主要 claim 都对应到具体实验数字)
Notes
- 这篇文章最大的价值是给 VLA 工程实践划了一条 default baseline:KosMos / PaliGemma + Policy-Head + 连续动作 + Chunk 执行。任何新方法没有 outperform 这个组合都很难 justify 复杂度
- “Policy head 保护了 VLM 原生 fusion 能力” 这个 hypothesis 值得系统验证——可以做 attention map 分析、对 VLM 表征做 probing、看 fine-tune 前后 VL 任务性能 retention。这是一个可以独立做成一篇 mechanism 论文的方向
- Finding 4 (in-domain > cross-embodiment) 与 π0 系列的事实成功有冲突——很可能是 capacity scale 的临界点问题:小模型 + 小数据下 cross-embodiment 是 noise,大模型 + 长训练下变成 signal。值得单独写一篇 “VLA cross-embodiment scaling law” 来澄清
- self-correction 的 emergent claim 应当在更大样本上重做评估;如果真的成立,这暗示 policy head + 大 backbone 组合可能在隐式学一个 closed-loop dynamics model,与 World Model 路线有连接
- 这篇适合作为 VLA related work / design choice 引用的 anchor 论文,但不要把它的实验结论当作 recipe ground-truth ——尤其是数据策略部分
Rating
Metrics (as of 2026-04-24): citation=96, influential=6 (6.3%), velocity=5.93/mo; HF upvotes=1; github 465⭐ / forks=21 / 90d commits=1 / pushed 10d ago
分数:2 - Frontier 理由:这是 VLA 领域第一份覆盖 8 backbone × 4 结构 × 多训练目标 / 数据策略的大规模 controlled study,其 4 类 taxonomy(One-Step-Disc/Cont、Interleaved-Cont、Policy-Head-Cont)已被 OpenVLA-OFT 等后续工作作为 reference 框架,“Policy-Head + 连续动作 + Chunk 执行” recipe 有 engineering reference 价值。2026-04 复核:发表 16 个月 cc=96 / ic=6(6.3%,远低于 Foundation 典型的 10%+ 继承率)/ velocity 5.93/mo,github 465⭐ active 但规模与 π0 / RT-2 这类 Foundation 档工作差一个量级——社区更多把它作为”有价值的 design space 参考”而非”方向必读必引的奠基工作”,且其 “in-domain > cross-embodiment” 的数据结论已被 π0 / π0.5 的大规模 scaling 事实反驳。改定 Frontier 更准确;不选 Archived 因为 taxonomy 仍被当前 VLA 工作持续引用作 reference。