Summary
World Action Models are Zero-shot Policies (DreamZero)
- 核心: 用预训练 video diffusion 模型做 backbone 的 14B “World Action Model” (WAM),joint 预测未来视频和 action,用 video 作为 dense world representation 来弥补 VLA 在 motion-level 泛化上的不足。
- 方法: Autoregressive DiT (从 Wan2.1-I2V-14B 初始化) + 共享 timestep 的 flow-matching joint denoising + KV-cache + 单独的 action encoder/decoder;real-time 通过 CFG parallelism / DiT caching / NVFP4 量化 + DreamZero-Flash (decoupled video/action noise schedule) 实现 38× 加速→7Hz 闭环。
- 结果: 在 AgiBot G1 上 unseen-env+unseen-object 评测 task progress 62.2%(>2× 超过 best pretrained VLA 基线 27.4%);unseen tasks 39.5% vs 16.3%;20 min 视频 (no action) 即可做 robot-to-robot 迁移 (+17pp);30 分钟 play data 适配新机器人 YAM。
- Sources: paper | website | github
- Rating: 3 - Foundation(NVIDIA GEAR 旗舰 VLA / World Model 作品;把 video diffusion 作为 robot foundation model backbone 的路线样本,open-source + OOD 协议可信度高,很可能成为后续 video-centric robot foundation model 的必引 baseline)
Key Takeaways:
- Video as the missing prior for VLA: VLA 从 VLM 继承了 semantic prior 但缺 spatiotemporal/dynamics prior;joint video+action 预测把 action 学习从 dense state-action imitation 转成 inverse dynamics(在 predicted visual future 上反解 motor command),作者明确假设 “improving robotic capabilities reduces to improving video generation”。
- Diverse > Repetitive 的反直觉数据策略: 同样 500 小时 AgiBot 数据,diverse、长 horizon (avg 4.4 min, ~42 subtasks/episode) 数据比 task-focused repetitive 数据 task progress 33%→50%;这与 VLA 主流”每任务多次重复演示”的做法相反,作者认为这是 WAM 的特殊优势——video prior 已就绪,关键瓶颈是学 IDM,需要多样的 state-action 对应。
- WAM 显示出 model scaling 信号: 5B → 14B 把 task progress 从 21% → 50%;同等 5B/14B 的 VLA 在 diverse data 上都是 0%。这与 “VLA scaling 不必然改善 action prediction” 的经验形成对比,给 robot foundation model 的 scaling 提供了一个 video-centric 路线。
- Cross-embodiment 用 video-only 数据: 12 min 人类 egocentric 数据或 20 min YAM 机器人视频(仅 video objective,不需要 action label)即可让 unseen task 性能从 38.3% → 54-55%,给”用大规模人类视频喂机器人 foundation model”提供早期证据。
- Real-time 是被精心打磨出来的: 14B diffusion 默认 5.7s/chunk 完全不可用;通过 CFG 双 GPU 并行、DiT velocity caching (16→4 步)、torch.compile + CUDA Graphs、NVFP4 量化、最后用 Flash 单步去噪 (decoupled noise schedule, β-biased video timestep) 把延迟压到 150ms,配合 asynchronous inference 实现 7Hz 闭环。这是工程驱动 capability 的典型 case。
Teaser. Joint video + action 预测概览,展示 WAM 的四种能力:从 heterogeneous 数据有效学习、open-world 泛化、video-only 跨形态迁移、few-shot 新形态适配。
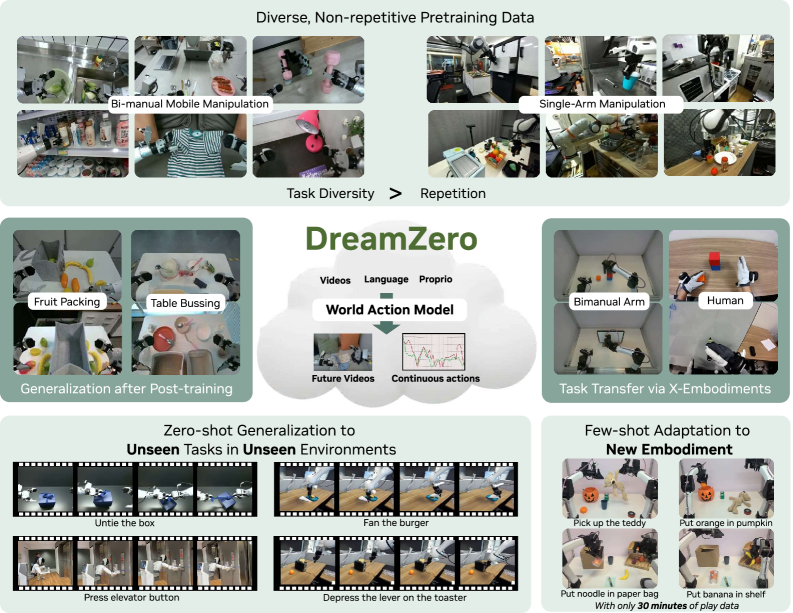
1. Motivation: 为什么需要 WAM
VLA(如 GR00T、π₀、π₀.₅)从 VLM 继承到的是 semantic prior——能识别 “Taylor Swift” 是哪张照片,从而做”move coke can to Taylor Swift”。但当任务变成”untie the shoelace”——一个训练分布里没有的 motion 时,VLA 就垮了。作者的诊断:VLM prior 知道 what to do,但不知道 how actions should be executed with precise spatial awareness。
WAM (World Action Model) 的核心赌注:视频本身是 dense world representation。从 Wan2.1-I2V 这样的 image-to-video diffusion model 初始化,模型已经从 web-scale video 学到了物理动力学;机器人微调阶段只需要补两件事:(1) 学会预测 robot embodiment 的视频,(2) 学会从生成的视频反解出对应 action。后者本质是 inverse dynamics,比 VLA 的 direct policy learning 在 sample efficiency 上有先天优势。
❓ “improving robotic capabilities reduces to improving video generation” 是个很强的 claim。它在 high-precision (sub-cm) 任务上能成立吗?文中也承认这是 limitation——video token 在 mm 精度上信息密度不够。
2. Method
2.1 Problem Formulation
DreamZero 联合预测视频 和动作 ,给定语言指令 、本体状态 、历史观察 。joint 分布的关键分解:
虽然在数学上是 video prediction × inverse dynamics 的乘积,作者坚持单模型 end-to-end 训练而非两阶段 pipeline——理由是 deep integration 带来更好的 video-action alignment(实证发现 DreamZero 的失败 case 多半是 video 预测错而 action faithfully execute 该错的 video)。
2.2 Model Architecture
Figure 4. DreamZero 架构。 Visual context 走 VAE,language 走 text encoder,proprioceptive state 走 state encoder;autoregressive DiT backbone 用 flow matching 联合预测未来 video frame 和 action;training 时各 chunk 在 noisy latent 上 denoise(条件于干净的历史 chunk),inference 时执行完一个 action chunk 后把 ground-truth observation 换回 KV cache 中对应位置,避免误差累积。
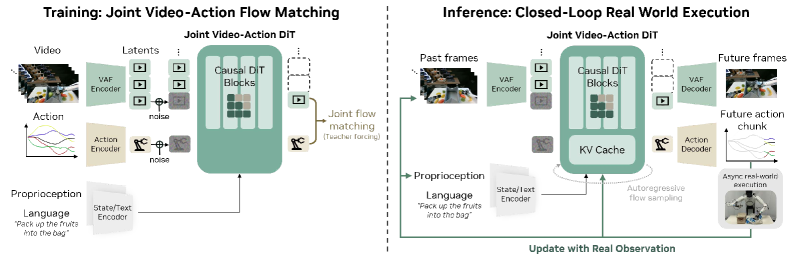
关键设计:
- Backbone 选择 Wan2.1-I2V-14B-480P——14B image-to-video diffusion,update 全部 DiT block + state/action encoder/decoder,冻结 text encoder、image encoder、VAE(保留 video prior)。
- Autoregressive over chunks: 与 bidirectional diffusion 相比,AR 有三个好处——(1) KV cache 加速,(2) 可以利用 visual history,(3) 不强制做 frame subsampling,保持 native FPS,让 video 帧和 action 时间戳精准对齐。文中只对 video modality 用 AR,action 不 AR 以避免 closed-loop action prediction 的误差传播。
- Multi-view 融合:直接拼成单个大 frame,不改 backbone(一个非常实用的工程妥协)。
2.3 Training Objective: Shared-timestep Flow Matching
每个 chunk 共享一个 timestep (不同 chunk 独立采样),这点和近期一些 WAM 把 video/action timestep 完全独立的做法不同——作者声称共享 timestep 在训练初期 converge 更快。Noisy latent 是 clean / Gaussian 噪声的线性插值:
模型预测 joint velocity,loss 是标准的 flow-matching 形式(teacher forcing:当前 chunk 在 noisy 状态下被 denoise,条件是干净的历史 chunk):
其中 。
2.4 Real-time Execution: 把 5.7s 压到 150ms
Naive inference: 14B DiT × 16 denoising steps × 串行 = 5.7 秒/chunk,完全不能用。作者堆叠了从 system 到 model 的优化:
| Layer | Optimization | 作用 |
|---|---|---|
| Async | Asynchronous closed-loop execution | Inference 与 action 执行并行,约束变成”在当前 chunk 用完前算出下一个” (~200ms 目标) |
| System | CFG parallelism (双 GPU 跑 cond/uncond) | -47% per-step latency |
| System | DiT caching (velocity cosine sim 高时复用) | 16→4 effective DiT steps |
| Implementation | torch.compile + CUDA Graphs | 消除 CPU overhead |
| Implementation | NVFP4 量化 (Blackwell),QKV/Softmax 保 FP8 | 进一步加速 |
| Implementation | cuDNN attention + GPU-side scheduler | 消除 CPU-GPU 同步 stall |
| Model | DreamZero-Flash: decoupled video/action noise schedule | 4→1 denoising step |
Table 1. 累积加速。 各项优化在 H100 / GB200 上的 cumulative speedup。
| Optimization | H100 | GB200 |
|---|---|---|
| Baseline | 1× | 1.1× |
| + CFG Parallelism | 1.9× | 1.8× |
| + DiT Caching | 5.5× | 5.4× |
| + Torch Compile + CUDA Graphs | 8.9× | 10.9× |
| + Kernel & Scheduler Opts. | 9.6× | 14.8× |
| + Quantization (NVFP4) | — | 16.6× |
| + DreamZero-Flash | — | 38× |
2.5 DreamZero-Flash: Decoupled Noise Schedule
直接减 denoising step 会让 action 质量崩——因为 action 预测被 noisy video 条件污染。Flash 的 insight:inference 时 action 应该被 denoise 到干净,但 video 还可能很 noisy——所以 training 时也制造这个分布。
Figure 5. Decoupled noise schedules。 标准 DreamZero 让 video 和 action 共享 uniform noise;Flash 把 video timestep 偏向 high-noise 端,用 ,,使 (大部分时候 video 很 noisy),同时 action 仍然 uniform。这样 model 学会”在 noisy video 条件下预测 clean action”,正好匹配 single-step inference。
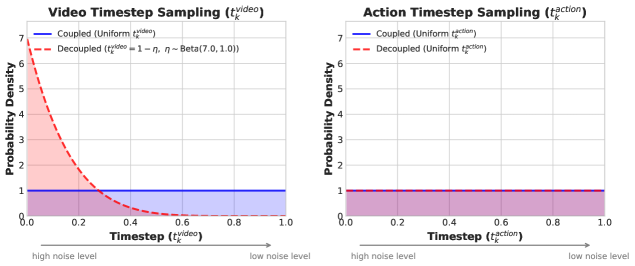
外加 action chunk smoothing:上采样 2× → Savitzky-Golay 滤波 → 下采样回原分辨率,去掉高频噪声。
3. Experimental Setup
- Embodiments: AgiBot G1 (mobile bimanual)、Franka single-arm (DROID);cross-embodiment 实验用 YAM bimanual 和 human egocentric。
- 数据: AgiBot 自采 ~500 小时 teleop,跨 22 unique env (homes/restaurants/supermarkets/coffee shops/offices),平均每 episode 4.4 min、~42 subtasks;Franka 用 DROID 公开数据。
- Baselines: GR00T N1.6、π₀.₅,每个都做 from-scratch 和 from-pretrained 两版(pretrained 的有 thousands of hours cross-embodiment robot data 加成)。compute 通过匹配 batch size + gradient steps 对齐。
- 训练: 100K steps, global batch size 128,update 全部 DiT block + state/action encoder/decoder,过滤 idle action,default 用 relative joint position。
- Eval default: unseen environment + unseen object——pretraining 和 eval 在不同地理位置采集,所有 benchmark 都是 OOD 测试。任务粒度按 (motion × object type) 定义,folding shirt → folding socks 算 unseen。
4. Results
Q1. WAMs 真的能从 diverse, non-repetitive 数据中更好地学吗?
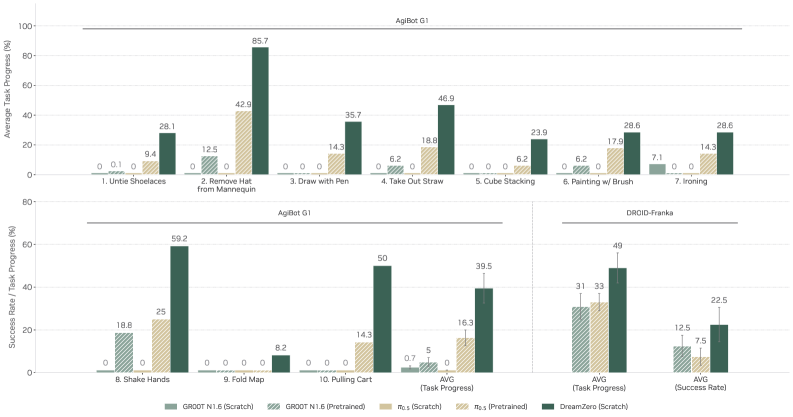
Figure 8. Seen task evaluation。 在 pretraining 任务集上做 zero-shot env + unseen object 评测,DreamZero 大幅领先所有 VLA baseline,from-scratch VLA 几乎全 0。
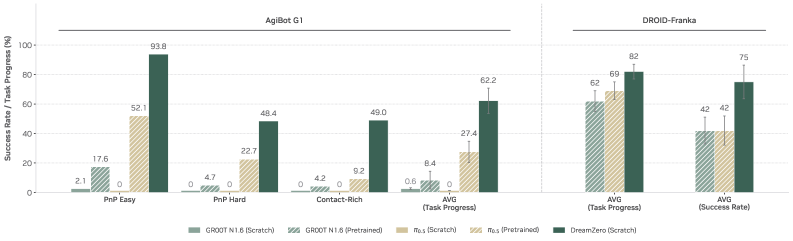
AgiBot G1 上 from-scratch VLA 在所有类别都接近 0 task progress;DreamZero 62.2% vs best pretrained VLA 27.4%(>2×)。DROID-Franka 上同样的 pattern——只在 DROID 上训练的 DreamZero 击败用多 embodiment 数据预训练的 baseline。
定性观察:多数 DreamZero 失败来自 video 生成错误而非 action 抽取——policy 忠实执行 video predicted 的轨迹(即使是次优行为)。这是 “improving video → improving robot” 的实证支撑。
Q2. 能 zero-shot 泛化到完全没见过的任务吗?
Figure 9. Zero-shot generalization to unseen tasks。 10 个完全不在训练分布的任务(untie shoelaces、ironing、painting、shake hands 等),DreamZero AgiBot 平均 39.5% (vs pretrained VLA 16.3%);DROID-Franka 上 49% task progress / 22.5% success rate (vs π₀.₅ 33%/7.5%)。
观察到 pretrained VLA 经常”reach toward objects and attempt grasping regardless of the instruction”——overfit 到了 dominant 的 pick-and-place 行为。
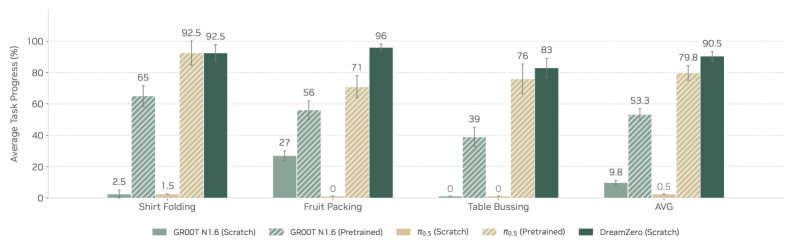
Q3. Post-training 后还能保留泛化吗?
Figure 10. Post-training results。 在 shirt folding / fruit packing / table bussing 三个 downstream task 上 fine-tune,仍然保留对 unseen env 的鲁棒性,DreamZero 与最强 pretrained VLA baseline 持平或超越(特别是 fruit packing 显著领先),不需要 cross-embodiment pretraining 加持。
Q4. Cross-embodiment transfer (video-only)
Figure 11. Cross-embodiment transfer。 9 个 unseen task,72 条 multi-view 演示(YAM 20 min / human 12 min),与 pretraining 数据 1:1 mix co-train 10K steps;只用 video objective,没有 action label。

Table 2. Cross-embodiment transfer 结果。
| Method | Task Progress |
|---|---|
| DreamZero | 38.3% ± 7.6% |
| DreamZero + Human2Robot Transfer | 54.3% ± 10.4% |
| DreamZero + Robot2Robot Transfer | 55.4% ± 9.5% |
robot-to-robot 提升最大(embodiment gap 小);human-to-robot 相当(虽然 morphology gap 大、视角是 egocentric)。这条路打开了用人类视频喂机器人 foundation model的可能。
Q5. Few-shot adaptation 到全新机器人
Figure 12. Few-shot embodiment adaptation。 AgiBot G1 预训练的 DreamZero 用 55 条轨迹 / ~30 分钟的 YAM play data 适配到 YAM 机器人(也是 bimanual parallel gripper)。即使数据极少,仍然保留强 language following,能泛化到训练时没见过的物体(pumpkins、teddy bears、cup noodles、paper bags)。
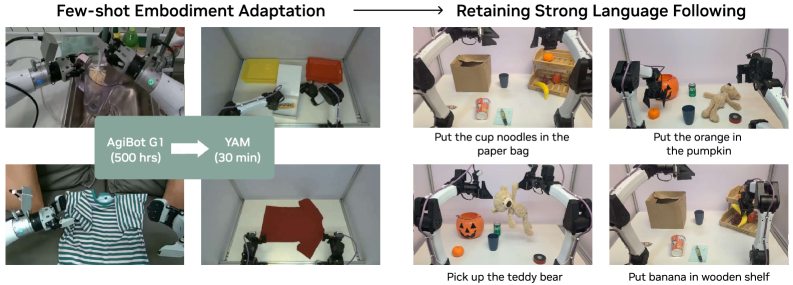
作者归因于两点:(1) AgiBot 与 YAM 视觉相似(都是双臂平行夹爪),(2) 更根本地,“learning an implicit IDM from predicted videos may be inherently more sample-efficient than direct policy learning”。
❓ Embodiment gap 更大的(如 humanoid 五指手 vs bimanual gripper)会怎样?文中只测了同 morphology family。
Q6. DreamZero-Flash 在更少 denoising step 上是否保留性能?
Table 3. DreamZero-Flash evaluation。 Table bussing 任务上不同 denoising step 的对比。
| Method | Steps | Task Progress | Inference | Speedup |
|---|---|---|---|---|
| DreamZero | 4 | 83% ± 6.1% | 350ms | 1× |
| DreamZero | 1 | 52% ± 10.2% | 150ms | 2.33× |
| DreamZero-Flash | 1 | 74% ± 10.1% | 150ms | 2.33× |
Flash 在单步推理下保留 4-step baseline 大部分性能(仅落后 9pp),证明 decoupled noise schedule 是更好的速度-精度权衡。
Ablations
Table 4. Model 与 data ablation。 都在 PnP Easy 上评测。
| Architecture | Size | Data | Task Progress |
|---|---|---|---|
| DreamZero (AR) | 14B | Repetitive | 33% ± 4.2% |
| DreamZero (AR) | 14B | Diverse | 50% ± 6.3% |
| DreamZero (AR) | 5B | Diverse | 21% ± 4.2% |
| DreamZero (AR) | 14B | Diverse | 50% ± 6.3% |
| VLA | 5B | Diverse | 0% ± 0.0% |
| VLA | 14B | Diverse | 0% ± 0.0% |
| DreamZero (BD) | 14B | Diverse | 50% ± 14.4% |
| DreamZero (AR) | 14B | Diverse | 50% ± 6.3% |
三个发现:(1) Diverse data > Repetitive data(同等小时数);(2) WAM 显示出 model scaling 信号 (5B → 14B: +29pp),而 VLA 扩到 14B 仍是 0%;(3) AR 与 BD 在 task progress 上类似,但 AR motion 更平滑(backprop through 整个序列)且 KV cache 推理快 3-4×。
5. Discussion
作者自己列出的 limitation 与 future work:
- WAM scaling laws 未明: model size / data size / compute 三者最优配比未知;预期与 LLM/VLA scaling law 不同。
- In-the-wild human video 还没真正用上: 当前只 12 min in-lab egocentric。下一步是把 EgoExo / Ego4D 这种规模的人类视频喂进来。
- Inference 仍贵: 7Hz 在 2× GB200 上跑出来;VLA 在消费级 GPU 上 20Hz+。如果未来小 video backbone 也有强泛化,WAM 可能成为 edge 设备上的 System 1。
- Long-horizon: 目前 visual memory 只 6 秒。需要 System 2 planner 或更长 context 的 WAM。
- High-precision tasks (sub-cm): WAM 偏 breadth,亚毫米精度任务可能仍需 dense demonstration;但 [54] 给出了一些 WAM 在精密装配上的正面信号。
- Embodiment design: 高 DOF 需要更多 play data 学 implicit IDM;但人形机器人能从人类视频继承 prior,可能反而更高效。
关联工作
基于
- π₀ / π₀.₅: 主要 VLA baseline,从 pretrained VLM 初始化。π₀.₅ 是文中 “from-pretrained” 强 baseline。
- GR00T N1 (作者用 N1.6): 另一条 VLA baseline;DreamZero 的 action module 设计也参考了 GR00T 的 DiT-based action head。
- Wan2.1-I2V-14B-480P: 14B image-to-video diffusion backbone,DreamZero 的初始化。
对比
- V-JEPA 2: latent-space world model 路线,pixel-free。Appendix A 专门对比:JEPA 在 abstract latent 空间预测,需要 goal-conditioned planning/search;WAM 直接在 pixel 空间联合出 video+action。
- Dreamer 系列: 经典 latent dynamics model + model-based RL;与 WAM 的差异在于 web-scale video pretraining 是否可继承。
- PointWorld: 3D point cloud world model,文中提到作为另一种 world model 替代方案。
方法相关
- Joint video-action models: UniSim、HMA 等更早的 joint world+action 工作;DreamZero 的差异是从 pretrained video diffusion 启动 + AR 架构 + diverse data 思路。
- Genie / Genie Reasoner: 同样从 video 出发的 world model 路线;Genie 偏 controllable video generation,DreamZero 偏 robot policy。
- World Model Survey / Robotic World Model: 综述背景,可定位 WAM 在 world model 谱系中的位置。
- Flow Matching: training objective;shared timestep 与近期 Flash variant 是关键调整。
- DROID: Franka 上 pretraining 数据来源。
- Octo: 早期 cross-embodiment transformer policy,对比的是不同的跨形态范式。
论文点评
Strengths
- Problem formulation 干净: “VLA 缺 spatiotemporal prior,video diffusion 正好补上” 这条 narrative 既清晰又有 first-principle 味道。把 joint video+action 显式分解成 video prediction × IDM,让人立刻理解为什么 video prior 是 action 学习的捷径。
- Diverse > Repetitive 的反直觉发现有 ablation 撑: 同 500 小时、控制 model 和 step 数,diverse 数据涨 17pp。这条结论如果 robust,会改变 robot data collection 的 best practice——不再需要每个 task 拍几百遍。
- Real-time 工程下了真功夫: 38× speedup 是 system + implementation + model 三层堆叠的结果,不是单点 trick。Table 1 把每层贡献清楚拆开,DreamZero-Flash 的 decoupled noise schedule 把 train-test mismatch 显式化的洞察很漂亮。
- Cross-embodiment 用 video-only 是潜在 breakthrough: 12 min 人类视频 → unseen task +16pp。如果这条路 scale up 到 Ego4D 规模,可能根本性改变 robot data 经济学。
- Eval 协议自带 OOD: 训练和评测在不同地理位置,default setting 就是 unseen env + unseen object。比”训测同 lab”诚实很多。
- 开源: 代码、checkpoint、PolaRiS sim 评测、RoboArena 真机评测都开放,reproducibility 远超平均水平。
Weaknesses
- “Improving robot = improving video” 是过强 claim: 高精度任务上 video token 的信息密度不够,作者自己承认,但 narrative 仍然把这个等式当 main thesis。需要专门设计实验测它在 mm 精度任务上能否 hold。
- Failure attribution 是单方面叙述: “失败来自 video 错而非 action 错” 这条 claim 没看到定量的 failure breakdown(多少比例是 video 错?多少比例是 IDM 错?)。
- Cross-embodiment 只测同 morphology family: AgiBot G1 → YAM 都是 bimanual parallel gripper。Human-to-robot 虽然 morphology gap 大,但 evaluation 任务是 pick-and-place 类,不太能区分是真学到了 action 还是 video prior 直接 cover 了。
- Compute 对齐有 caveat: “matching total batch size and gradient steps” 不等于 matching FLOPs(DreamZero 14B + video 生成 vs VLA 14B 直接出 action)。VLA baseline 是否在最优配置下、是否需要更多 step 或不同超参,文中没有完整 sensitivity 分析。
- 延迟仍偏高 + 硬件门槛: 7Hz 需要 2× GB200。对学术 / 中小公司来说几乎不可复现 real-time 性能。“smaller backbone 也能行” 是 future work,目前只是 hope。
- 没有 RL/online learning: 既然是 world model,自然问能否用 imagined rollout 做 model-based RL?文中完全没碰这条线。
- Ablation 在 50K steps × bs 32 / 仅 PnP Easy 上做,规模和最终 100K × bs 128 不一致;conclusions 在更难任务上是否成立有疑问。
可信评估
Artifact 可获取性
- 代码: inference + training(README 描述 “code to pretrain, fine-tune, and evaluate DreamZero and run sim & real-world evals”)。
- 模型权重:
GEAR-Dreams/DreamZero-DROID在 HuggingFace 已发布;AgiBot checkpoint 文中提到 “we open-source our model weights”,但 in-house AgiBot 数据延后发布。 - 训练细节: 较完整——backbone (Wan2.1-I2V-14B-480P)、step (100K)、global batch size (128)、frozen 模块 (text/image encoder + VAE)、action representation (relative joint position)、horizon (48 步 @ 30Hz) 均披露;Flash 的 Beta(7,1) 配置和详细 hyperparam 在 appendix 给出。
- 数据集: 部分公开。DROID 公开;AgiBot G1 自采 500h 数据”prior to release” 说法暗示后续会放但未给时间表;YAM/human 数据未承诺开源。
Claim 可验证性
- ✅ 2× over best pretrained VLA on AgiBot seen tasks: 62.2% vs 27.4%,80 rollouts × 4 robots,有 Figure 8 + appendix protocol 支撑。
- ✅ 38× inference speedup → 7Hz: Table 1 逐项分解,硬件、kernel、量化都列出;可在开源代码上独立验证。
- ✅ Flash single-step 保留 4-step 89% 性能: Table 3 给了均值和 standard error,可复现。
- ⚠️ “Most failures stem from video errors not action errors”: 没有定量 failure mode breakdown,是定性观察。
- ⚠️ Cross-embodiment 42% relative improvement: 计算方式
(54.3 - 38.3)/38.3 ≈ 42%,可验证;但样本量小(9 unseen tasks,每任务 8 demo),standard error ±10pp,区间相当宽。 - ⚠️ 30 分钟 play data 适配 YAM “retains zero-shot generalization”: Figure 12 给出定性视频,但未给与从头训练 YAM 的对照实验,“few-shot 而保留泛化” 缺乏 quantitative baseline。
- ⚠️ Diverse > Repetitive (33%→50%): 只在 PnP Easy 上测,且都是 50K steps × bs 32 的 ablation 配置;在 main result 配置上是否成立未验证。
- ⚠️ VLA from-scratch 在 14B/5B 都是 0%: 这个数字需要警惕——是否 VLA 的训练超参没充分调?from-scratch VLA 本身就是 atypical setup。
- ❌ “sets a new benchmark for data-efficient embodiment adaptation” (in introduction): marketing 表述,没有同类 baseline 对照(其他 30-min adaptation 工作的明确数字)。
Notes
- 个人最 surprised 的点: “Diverse > Repetitive” 这条 ablation 如果在更多 setting 下成立,会逆转主流”每 task 演示几百遍”的数据采集 SOP——这对工业界 data team 影响巨大。但论文只在 PnP Easy 上做了 ablation,需要更多复现。
- 方法层面的关键 design choice 排序(按对最终性能的贡献重要性主观估计):(1) 用大 video diffusion backbone 而非从头训,(2) joint 而非 pipeline 的 video+action prediction,(3) AR 而非 BD(主要给 inference 速度和平滑度),(4) Flash decoupled noise schedule(推理速度的关键 enabler)。
- 可能的下一步研究方向:
- 用 Ego4D 规模人类视频做 pretraining 第二阶段,看 cross-embodiment transfer 能 scale 多远。
- 设计能定量分离”video error” vs “IDM error”的 evaluation protocol——这是 WAM 这条 narrative 能否站住的关键。
- 把 WAM 的 imagined video rollout 当作 model-based RL 的 simulator,能不能学出超越 demonstration 的行为?
- 在 high-precision (sub-cm) task 上压力测试,看 video token 信息密度的 fundamental limit 在哪。
- 对自己 idea 库的更新:
- “video as dense world representation” 这条思路可以借鉴到 GUI agent / Computer-use agent——把 screen recording 作为 dense state representation,joint 预测 next screen + next action,可能比纯 screen→action 的 BC 更 sample-efficient。
- Decoupled noise schedule (Flash) 是个一般化的技巧——任何 joint diffusion 任务里如果一个 modality 在 inference 时需要更早 converge 到 clean,都可以用这个 trick。
- ❓ Yuke Zhu / Linxi Fan / Joel Jang 的署名意味着 NVIDIA GEAR team 的旗舰工作。GR00T N1.6 也是同 team,DreamZero 的定位看起来是 GR00T 之外的”video-centric robot foundation model”分支线。两条线未来会合流还是分叉?
Rating
Metrics (as of 2026-04-24): citation=33, influential=7 (21.2%), velocity=15.00/mo; HF upvotes=18; github 1750⭐ / forks=134 / 90d commits=68 / pushed 5d ago
分数:3 - Foundation 理由:这是 NVIDIA GEAR team(Yuke Zhu / Linxi Fan / Joel Jang 等)的旗舰工作,在 Embodied AI / VLA 方向把 “video diffusion as robot foundation model backbone” 这条路线做到了可用范式——joint video+action 显式分解为 video prediction × IDM、14B 上显示 model scaling 信号(5B→14B: +29pp,而同尺寸 VLA 仍 0%)、video-only cross-embodiment transfer (+16pp)、38× 推理加速到 7Hz 闭环,每一条都是对 VLA 主流范式(π₀ / GR00T)的正面挑战。Strengths 里写到的 open-source 程度(代码 + DROID checkpoint + sim & real-world eval)和 default OOD eval 协议(unseen env + unseen object)让可信度远高于同类 VLA 论文,很可能被后续 video-centric robot foundation model 作为必引对照。落不到 “2 - Frontier” 而是 “3 - Foundation” 的关键是:这不只是又一个 SOTA,而是把 “video 作为 robot foundation model 主体” 这条范式首次完整端到端跑通并公开的工作。降档风险只有 Weaknesses 里的定性归因和硬件门槛,但都是 follow-up 可处理的细节,不动摇方法论贡献。2026-04 复核:发表仅 2.2 月已累计 33 citation / 7 influential (21.2%,远高于 ~10% 典型值,说明方法被实质继承,接近 π0 19% 的形态) / velocity 15.00/mo / github 1750⭐ / HF=18 / 近 5 天仍在活跃维护——几乎所有 early signal 维度都显著高于同批 Frontier 作品(对比同日 DM0:4 citation / 938⭐ / HF=0),支撑 Foundation 档位。