Summary
Robotic World Model: A Neural Network Simulator for Robust Policy Optimization in Robotics
- 核心: 用 GRU + dual-autoregressive + 多步自监督训练,学一个低维 black-box dynamics model,使其在 100+ 步 autoregressive rollout 内仍稳定到足以撑起 PPO 的训练
- 方法: RWM (历史 horizon M、forecast horizon N、外层把预测喂回输入、内层 GRU 隐状态自回归更新;同时预测 contact 等 privileged 信号) + MBPO-PPO(PPO 在 imagined rollout 里更新策略,同时持续收集真实数据 fine-tune 模型)
- 结果: 在 6 类 manipulation/locomotion 任务里 autoregressive prediction error 低于 MLP/RSSM/Transformer baseline;ANYmal D 与 Unitree G1 上 zero-shot 部署成功,velocity tracking reward 与 250M-step PPO 持平 (0.90 vs 0.90),但 RWM pretraining 仅 6M state transitions
- Sources: paper | website | github
- Rating: 1 - Archived(legged MBRL + PPO 的单点工程参考,NeurIPS 2025 Workshop Outstanding Paper + 硬件证据,但 15 个月后 cc=29 / ic=2、作者 follow-up RWM-U 已替代核心 limitation,方向窄且未被社区广泛采纳)
Key Takeaways:
- 核心 bet:world model 不一定要 latent-space 或者 transformer——只要 autoregressive 训练时 horizon 给够、把自己的预测当输入,简单 GRU 就能撑住 100+ 步 rollout。和 Dreamer 系强调 latent + KL 正则的路线形成对照。
- Privileged head 是廉价 trick:除了观测,模型同时预测 contact / foot height 等仿真器才有的量。这给隐状态多了一个 grounding 的 supervision,作者归因为长程稳定的关键之一。
- PPO + learned model 的可行性证据:以往 MBRL 多用 SAC/short-horizon actor-critic,因为 PPO 需要长 trajectory 估 advantage,对 model error 极敏感。RWM 显示——只要 model 真稳,PPO 能在 imagination 里训出可上硬件的策略。
- Generalization 是 architecture-agnostic 的:作者明确说 RSSM 用同样的 autoregressive 训练也能达到接近性能;他们选 GRU 只是因为简单、显存友好。Transformer 反而被多步梯度爆显存劝退。
Teaser. RWM 在多机器人上的 imagination vs ground truth vs hardware deployment overview.

Video. NeurIPS 2025 workshop talk(Outstanding Paper)—— RWM + MBPO-PPO 的整体故事
1. Motivation:为什么需要又一个 world model
主流 robot policy 部署后就停止学习——这浪费了真实世界数据,也没办法应对 distribution drift。理想路径是用真实数据训一个 world model,然后让 policy 在 imagination 里继续学,避免在硬件上做危险探索。
但这条路上的一个 hard constraint 常被忽视:PPO 需要长 horizon 的 trajectory 来估 return / fit value。一旦 learned model 在 autoregressive rollout 里逐步漂移,PPO 就会 happily 优化一个幻觉世界。SAC、SHAC 那类 short-horizon / first-order 的方法对 model error 容忍度高,但 PPO 不行。
❓ 作者把”PPO 是 robot control 实际有效的 workhorse”作为出发点,但近年 SAC/DreamerV3 在很多 benchmark 已经追上甚至超过 PPO。这条 motivation 在 legged locomotion 这一窄域成立(PPO 在 Isaac Lab 上确实是 default),但放大到整个 robotics 不那么稳。
因此本文的具体问题不是 “学一个 world model”,而是 “学一个在 100+ autoregressive 步内仍可信,能让 PPO 不被骗的 world model”。
2. Approach
2.1 问题设定
POMDP ,policy 。World model 近似环境 dynamics,让 policy 在 imagination 里 rollout。常规三步循环:collect → train model → train policy in model。
2.2 Self-supervised Autoregressive Training(核心)
输入是 步历史观测-动作对,预测下一步观测分布:
预测 步以后的观测,把自己的预测当作输入:
同样的 autoregressive 过程也用来预测 privileged 信号 (contact 等)。优化目标是 forecast horizon 内 N 步的加权多步预测误差:
Equation. RWM 多步训练 loss
符号说明: forecast horizon, 时间衰减因子,/ 观测和 privileged 信号的预测误差。
含义:和 teacher-forcing(始终用 ground truth observation 当输入,等价于 )相比,autoregressive training 强迫模型在训练时就见到自己产生的 distribution,缩小 train-test mismatch。Teacher-forcing 的并行性更好,但代价是部署时一旦小偏差就漂走。
2.3 Dual-autoregressive 架构
RWM 用 GRU + MLP head 输出下一步观测的高斯分布参数。Dual 体现在:
- Inner autoregression:在 context horizon 内,每过一步历史,GRU 隐状态自回归更新一次。
- Outer autoregression:在 forecast horizon 内,把预测的观测喂回网络,作为下一步的输入。
❓ 这个 “dual” 概念有点 marketing——inner 部分其实就是 GRU 本来的 sequence processing,把它命名成 “inner autoregression” 是把 RNN 的标配重新包装。真正新的是 outer autoregression 和多步 loss。
2.4 MBPO-PPO:在 RWM 里跑 PPO
Algorithm 1(伪代码 paraphrase):
初始化 、、replay buffer for iter = 1, 2, …: 用 与真环境交互,把 加进 用 按 Eq.2 的 autoregressive loss 更新 从 采初始观测,初始化 imagination agents 用 + rollout 步 imagination trajectories 用 PPO(或其它 RL)在 imagination 上更新 end for
实际策略更新里,imagination 中的动作来自 policy 本身:
Reward 从 imagined 观测 + privileged 信号算出。重点是作者敢把 imagination horizon 推到 100+ 步——这是 PPO 用来估 return 的标准长度,也是大多数 learned-model + PPO 组合崩掉的地方。
3. Experiments
3.1 Autoregressive 预测精度
ANYmal D 硬件采集数据,50Hz 控制, 训练。Rollout 远超训练 forecast horizon 后,预测仍贴近 ground truth。
Figure. Autoregressive trajectory prediction by RWM(与 ground truth 对比)
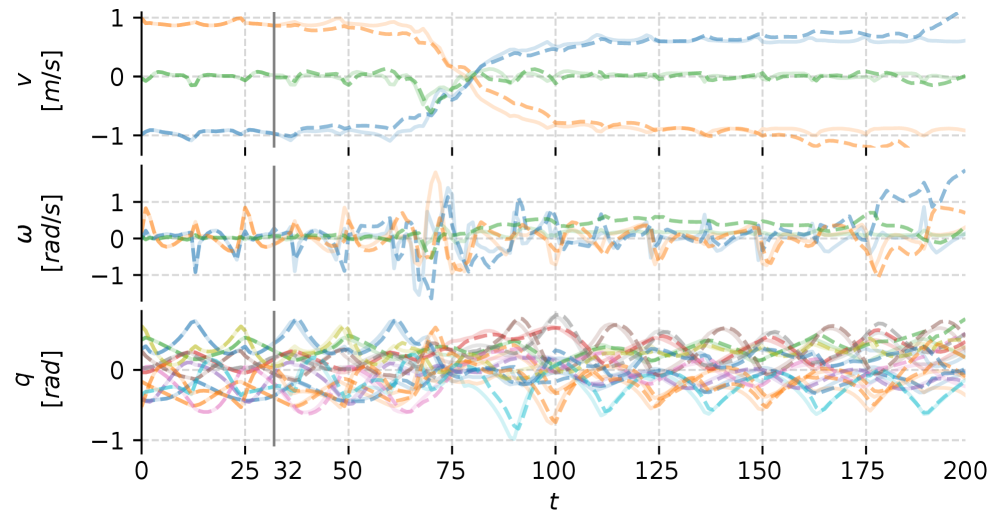
❓ 作者强调”超过训练 horizon 仍稳定”。但 ablation(appendix A.4.1)显示精度对 和 都敏感,要 careful tuning——所以并不是真的”训练短 horizon 就能 generalize 到长 horizon”,更像是 “训练 8 步已经够把 GRU 隐状态正则化得不至于发散”。
3.2 Robustness under noise
对观测和动作注高斯噪声,RWM 的 relative prediction error 增长显著低于 MLP baseline。归因于 dual-autoregressive 训练让模型在面对 OOD 输入时还能慢慢拉回 trajectory。
3.3 Cross-environment generality
跨 manipulation(Reach-UR10 / Reach-Franka / Lift-Cube-Franka / Open-Drawer-Franka / Repose-Cube-Allegro)+ locomotion(Unitree A1/Go1/Go2、ANYmal B/C/D、Spot、Cassie、H1、G1)共 10+ 个机器人 / 任务,对比 MLP / RSSM / Transformer。
Figure. RWM-AR 与 baseline 在多任务下的 autoregressive prediction error
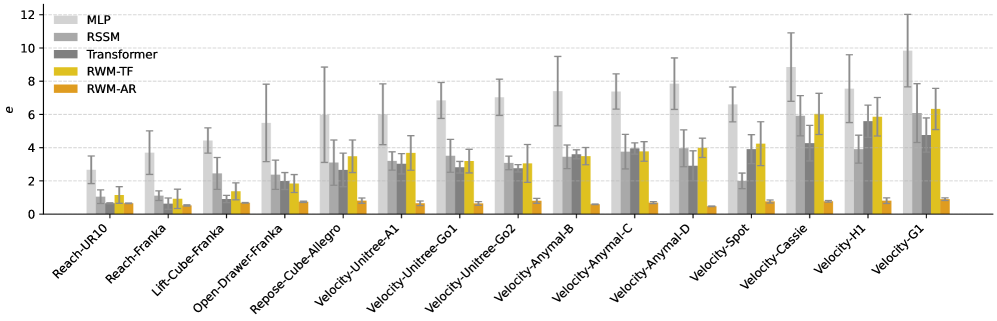
关键观察:
- RWM-AR 稳定最低 error——尤其是 legged velocity tracking 这种长程依赖强的任务。
- RWM-AR 显著优于 RWM-TF(teacher-forcing 版本)——印证多步 autoregressive 训练的必要性。
- RSSM + autoregressive 训练 ≈ RWM——架构其实没那么关键,autoregressive 训练才是 main contributor。GRU 胜在简单、显存便宜。
- Transformer 不 work:多步 autoregressive 反传梯度对显存压力大,不实用。
这是论文最 honest 的一段——明确承认 architecture 不是核心 contribution,autoregressive 训练才是。这种诚实让 contribution 更可信,但也削弱了 “Robotic World Model” 作为一个独立 model 名字的份量。
3.4 Hardware transfer
MBPO-PPO 训出的 velocity tracking 策略 zero-shot 部署到 ANYmal D 与 Unitree G1。对比 SHAC(first-order gradient through model)和 DreamerV3(latent-space + actor-critic):
- SHAC:first-order gradient 在 contact discontinuity 上数值差,policy 崩,无法部署。
- DreamerV3:planning horizon 短,长程依赖处理弱,partial converge。
- MBPO-PPO:predicted reward 起初由 policy 利用模型 error 而 overshoot ground truth,但训练推进后两者收敛对齐。
Figure. Model error 与 policy reward 在 ANYmal D / G1 上的训练曲线(MBPO-PPO vs SHAC vs DreamerV3)
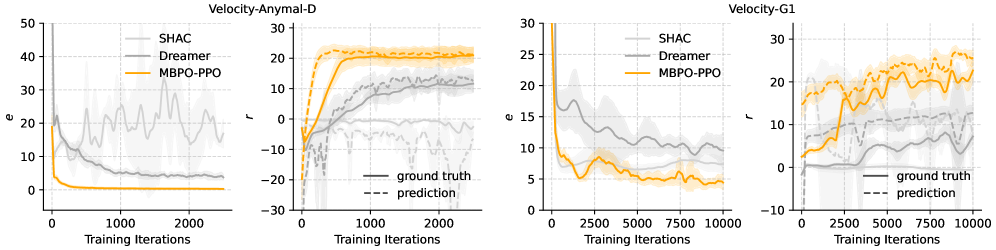
Video. Hardware deployment + robustness(impacts、terrain disturbance)
3.5 与 model-free PPO 的代价对比
Table. RWM + MBPO-PPO vs 高保真 simulator 上跑的 PPO
| Method | RWM pretraining | MBPO-PPO | PPO |
|---|---|---|---|
| state transitions | 6M | 250M | |
| total training time | 50 min | 5 min | 10 min |
| step inference time | 1 ms | 1 ms | |
| real tracking reward |
读法:在 reward 上打平 model-free PPO,且 state transition 总数从 250M 降到 6M(约 40× 节省);但 wall-clock 上 RWM pretraining 50min 反而比 model-free PPO 10min 慢——节省的是”必须在真实环境采的 transition 数”,不是 sim 里的 wall-clock。
❓ 这张表有点 misleading:作者在 limitation section 才承认 “well-tuned model-free PPO 在 high-fidelity simulator 上还是更强”。这里 reward 打平是因为对比的 PPO 也只是 baseline 配置,并非 SOTA tuning。读者很容易误以为 “RWM 已经追上 model-free”。
4. Limitations(作者承认 + 我的补充)
作者承认:
- 仍弱于 well-tuned model-free PPO + 高保真 simulator——MBRL 的优势在”无法获得高保真 sim”的场景,而 legged locomotion 恰恰是 high-fidelity sim 已经很成熟的领域。
- World model 是 simulation 数据 pretraining 的,不是 from scratch。Online 学习仍易被 policy exploit。
- 真硬件 online 学习还无法做:实验中策略 exploit model error 平均会撞 20+ 次,硬件不能承受;privileged 信号(contact)硬件不一定可测;缺 reset / recovery policy。
我的补充:
- 评估 task 都聚焦 velocity tracking,没有更复杂的 manipulation policy(虽然预测精度评估了 manipulation 环境)——所以 “MBPO-PPO 上硬件 work” 的 claim 仅在 locomotion 里 grounded。
- “GRU 比 transformer 好” 的结论很受限于 forecast horizon 8 + 显存预算的设定。如果换 H100、用 gradient checkpointing 做长 horizon transformer,结论可能反转。
- 论文里 “100+ autoregressive steps with PPO” 的数字看似 impressive,但相对 PPO trajectory 长度(典型 1000+),仍偏短。Dreamer 之所以用 short imagination + value bootstrapping 也是为了避开这个长 horizon 不稳定问题,本文是用模型质量去硬扛——这条路是否 scale 到更复杂任务待验证。
5. 后续工作
紧密相关的 follow-up,作者团队自己做的:
- Uncertainty-Aware RWM (RWM-U) [arXiv 2504.16680]:用 ensemble 估计 uncertainty,用 MOPO-PPO 在 offline 设置下训 policy(不再需要新交互)。这正面回应了本文 limitation 中”policy 易 exploit model error”的痛点。
关联工作
基于
- Dyna (Sutton 1991):model-based + model-free 混合的 ancestor,“在 imagination 里更新 policy” 的思想源头。
- MBPO (Janner et al. 2019):本文 MBPO-PPO 的直接前身,用 model-based imagination + model-free SAC。本文把 SAC 换成 PPO,并把 imagination horizon 推到 100+ 步。
- PETS (Chua et al. 2018):probabilistic ensemble dynamics model,给 RWM 的 stochastic 输出 head 提供了思路。
对比
- DreamerV3 (Hafner et al.):latent-space dynamics + actor-critic,short imagination horizon。本文实验中作为 hardware transfer baseline,partial converge。
- TD-MPC / TD-MPC2 (Hansen et al.):model + planning。作者引用为 latent-space MBRL 代表,未直接对比 hardware。
- SHAC (Xu et al. 2022):first-order gradient through dynamics model;本文显示 SHAC 在 contact-rich locomotion 上崩,无法部署。
- RSSM (Hafner et al. 2019):Dreamer 系的 latent recurrent state-space model。本文承认用 autoregressive training 时 RSSM ≈ RWM。
方法相关
- Decision Transformer / Trajectory Transformer (Chen et al. 2021):作为 transformer-based dynamics 的 baseline,本文显示 transformer 对多步 autoregressive 训练显存不友好。
- DayDreamer (Wu et al. 2023):Dreamer 系在真实机器人上的延伸,思路上接近本文 “world model 撑起 hardware transfer”,但只到 short-horizon。
- World Model Survey:对 world model 整体 landscape 的系统综述。
- World Model Domain Map:vault 内的整体 mental model。
- Uncertainty-Aware RWM (RWM-U) [arXiv 2504.16680]:作者团队后续工作,offline 设置 + uncertainty-aware 的 ensemble,对应本文 limitation 里 “online learning hard” 的 follow-up。
论文点评
Strengths
- 诚实的 ablation:明确承认 RSSM + autoregressive training ≈ RWM,把 contribution 从 architecture 移到了 training scheme。在 world model 论文普遍 oversell architecture 的氛围里很难得。
- Long-horizon PPO + learned model 的真硬件证据:以往 MBRL + PPO 几乎不被认为可行,本文用 ANYmal D + G1 hardware 给出反例。
- Privileged head 这个细节有用:让模型预测 contact 等 sim 才有的量,是 cheap 的 supervision 增益,可移植到其它 world model 工作。
- 简单可复现:GRU + MLP head 的组合不需要重型基础设施,开源代码(Isaac Lab extension)也已经发布。
Weaknesses
- Generalization 评估窄:MBPO-PPO 只在 velocity tracking 上做了硬件验证。Manipulation 评估只到 prediction error,没接 policy → hardware。
- “100+ autoregressive steps” 不够 impressive:相对 PPO 标准 trajectory 长度仍偏短;且 forecast horizon 的训练设定决定了”超出训练 horizon” 也只是 量级。
- “Dual-autoregressive” 命名带 marketing 成分:inner 部分本质是 GRU 默认行为。真正 novel 的只是 outer feedback + 多步 loss。
- 数据效率对比有 spin:Table 1 的 “6M vs 250M state transitions” 容易让读者以为打平了 model-free SOTA,但作者在 limitation 自己说 well-tuned PPO 仍胜。
可信评估
Artifact 可获取性
- 代码:完整开源(leggedrobotics/robotic_world_model + 配套 rsl_rl_rwm);含 Isaac Lab extension、pretraining 与 finetune 脚本、可视化 imagination rollout 的 visualize.py。
- 模型权重:未说明(README 只描述训练流程,没给 pretrained checkpoint)。
- 训练细节:超参 + 架构 + reward 权重均在 appendix(Table S2-S7)完整列出;具体训练步数有给出(pretraining 6M transitions)。
- 数据集:不需要外部数据集——pretraining 数据是用 PPO 在 Isaac Lab 跑出来的 simulation rollouts,pipeline 完整开源。
Claim 可验证性
- ✅ “RWM 在 manipulation + locomotion 多任务下 autoregressive prediction error 最低”:Fig 4 + appendix 多个 setting 一致。
- ✅ “MBPO-PPO 训出的 policy zero-shot 上 ANYmal D / G1 跑 velocity tracking”:webpage 视频 + Figure 1 + appendix 描述。
- ⚠️ “100+ autoregressive 步仍稳定”:Fig 3a 视觉证据较弱(曲线对齐 OK,但没量化”什么 horizon model error 超过阈值”);ablation 也没明确”autoregressive 步数 vs error 上界”的关系。
- ⚠️ “数据效率显著优于 model-free PPO”:Table 1 reward 打平的 PPO 是 baseline 配置;作者在 limitation 自己承认 well-tuned model-free RL 仍更强。
- ⚠️ “Dual-autoregressive 是关键”:没有 single-autoregressive(只 outer 不 inner,或反之)的 ablation 把两个 component 拆开归因。
Notes
- “Architecture 不重要,training scheme 重要” 的结论值得记下来,作为读其它 world model 论文时的对照。下次看到 fancy architecture 没附 same-training-scheme baseline 时可以提问。
- Privileged head 这个 trick 可以借到自己的工作里:当真值能拿到的 supervision,不一定要全部进观测,可以做 auxiliary head。
- “PPO 需要长 horizon → learned model 必须长程稳定” 这个 framing 是有用的 mental model。下次设计 model-based pipeline 时,要先想清楚 downstream RL algorithm 的 horizon 需求,再决定 model evaluation 的 metric。
- 想继续深挖:RWM-U 的 uncertainty-aware extension(arXiv 2504.16680)解决了 policy exploit error 的问题,可能是更值得 building block 化的版本。
Rating
Metrics (as of 2026-04-24): citation=29, influential=2 (6.9%), velocity=1.91/mo; HF upvotes=0; github 593⭐ / forks=46 / 90d commits=2 / pushed 15d ago
分数:1 - Archived 理由:位于 legged MBRL + PPO 这条窄方向上——NeurIPS 2025 Embodied World Models Workshop Outstanding Paper,提供了以往被认为不可行的 “long-horizon PPO + learned model” 在 ANYmal D / G1 上的真硬件证据(Strengths 2),privileged head trick 与 “autoregressive training > architecture” 的 honest finding 仍有 transferable value。2026-04 复核:发表 15 个月 cc=29 / ic=2(6.9%)/ velocity 1.91/mo,github 593⭐ active 但规模偏小;作者自己承认 architecture 不是核心贡献,well-tuned model-free PPO 在 high-fidelity sim 上仍更强,且作者团队 follow-up RWM-U(arXiv 2504.16680)已替掉 “policy exploit model error” 的核心 limitation——符合 Archived 档 “被后续工作取代 / niche / 为某个具体问题查的一次性参考”的定位。不选更低档是因为 hardware transfer 证据与 autoregressive-training-matters-more-than-architecture 的结论仍可查;不选 Frontier 因为当前已不是 learned-dynamics + on-policy RL 方向的代表性必比工作。