Summary
Understanding World or Predicting Future? A Comprehensive Survey of World Models
- 核心: 把 “world model” 这个被 LLM/Sora 浪潮重新激活的概念,按 “理解世界(implicit representation)” vs. “预测未来(future prediction)” 二分法做系统综述
- 方法: 沿这两条主轴梳理 MBRL/LLM-as-WM 与 video-WM/embodied-environment 两脉,再覆盖 game / embodied / urban / society 四大应用域
- 结果: 给出 categorization 框架、representative-paper 表格、benchmark 清单(VBench/PhysBench/WorldScore 等)和 6 类 open problems
- Sources: paper | github
- Rating: 2 - Frontier(覆盖面最广的 WM survey + benchmark cheatsheet,当前是 WM 方向有用的入口,但广而不深、且分类边界人为,不具奠基性)
Key Takeaways:
- 二元定义统一框架:作者把 “world model” 收敛为 “understand the dynamics of the world and compute the next state with certainty”——下面分裂成 implicit representation(latent dynamics for decision-making)和 future prediction(generative simulation)两条互补主轴,所有具体 system 都映射到这张图。
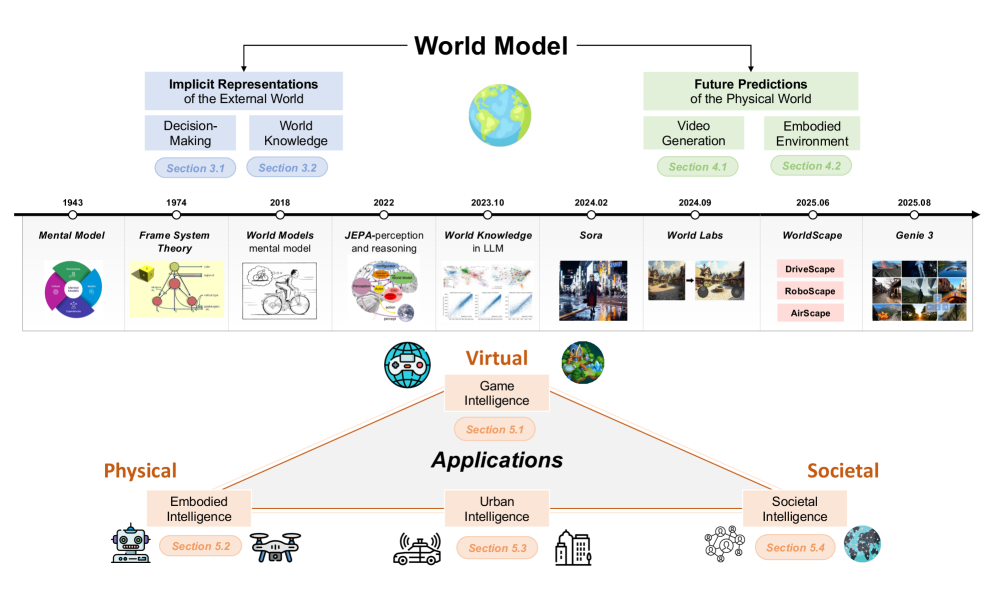
- 历史脉络(Sec 2.1/2.2):从 Craik (1943) / Johnson-Laird mental models → Minsky frames → Sutton-style MBRL → Ha & Schmidhuber 2018 重新引入 “world model” → Sora/Genie/Cosmos 把焦点推向 video-as-WM。这部分是这一版相比 v1 重写的核心贡献。
- 应用域结构化:Game (GameNGen, Genie)、Embodied/Robotics、Autonomous Driving (Vista, OccSora, Cosmos)、Social Simulacra 各自对应 “implicit vs. predictive” 的不同侧重,作者还给出 cloud-side(数据引擎/RL env/policy evaluator)vs. edge-side(agent brain,例如 V-JEPA 2 latent MPC)的功能切分。
- Benchmark 清单值得收藏:Sec 6.3 Table 8 列了 VBench / VBench-2.0 / WorldScore / PhysBench / Physics-IQ / VideoPhy / WorldSimBench 等十余个评测,覆盖 video-centric simulation、physical/spatial reasoning、embodied decision,是查 “怎么评一个 WM” 时的入口。
- Open problems:(1) physical rules & counterfactual simulation(Sora 的物理失败 → Genesis/PhysGen 等 hybrid physics)、(2) benchmarks、(3) sim-to-real、(4) simulation efficiency、(5) ethical & safety——比单纯列方向更有信息量的是它把 “为什么 data-driven 还不够” 的论据连了起来。
Teaser. Survey 的总框架与 timeline,把 implicit representation 与 future prediction 两条线、以及它们映射到 application domains 的方式合在一张图。
1. 定义与分类(Sec 2)
1.1 历史脉络
作者把 world model 演化分成三个阶段:
- Pre Deep Learning:可以追到 1960s Minsky 的 frame representation;RL 视角下早期 MBRL 用 tabular / 简单参数化函数学 transition model
(s, a) → s',做 planning / look-ahead。 - Model-based RL 重启:Ha & Schmidhuber (2018) 用 RNN 学 latent dynamics,把 “world model” 这个词重新带回主流,对应心理学的 mental model 理论(Craik 1943, Johnson-Laird 1983)。后续 Dreamer/PlaNet 系列把 latent imagination 推到 Atari/控制基准。
- Generative-AI Era:Sora、Genie 等大规模视频/可交互生成模型让 “WM 等价于 video predictor” 这种叙事流行;同时 V-JEPA 等 latent-prediction 路线主张 WM 不必落到像素。
1.2 二元 categorization
作者收敛到一句话本质:
the essential purpose of a world model is to understand the dynamics of the world and compute the next state with certainty (or with some guarantee), which empowers the model to extrapolate longer-horizon evolution and to support downstream decision-making and planning.
由此分两支:
- Implicit representation of the external world (Sec 3):把外部环境压缩为 latent dynamics,服务于 decision-making;包括 MBRL world model 和 LLM-as-WM 两条线。
- Future prediction of the external world (Sec 4):以生成模型直接合成未来观测,从 video generation(Sora 系列)发展到 embodied environment generation(indoor/outdoor/dynamic)。
Dr. Li 视角:这个二分法清晰但不互斥——V-JEPA 2 既是 latent 表征又能做 imagination MPC;Genie 既是 video generator 又给 RL 当 env。Survey 的真正价值不是在分类边界本身,而是把这两条线的同源性(都是 next-state predictor,只是在哪个抽象层)讲清楚。
2. Implicit Representation(Sec 3)
Figure 3 — Two schemes of utilizing world model in decision-making.
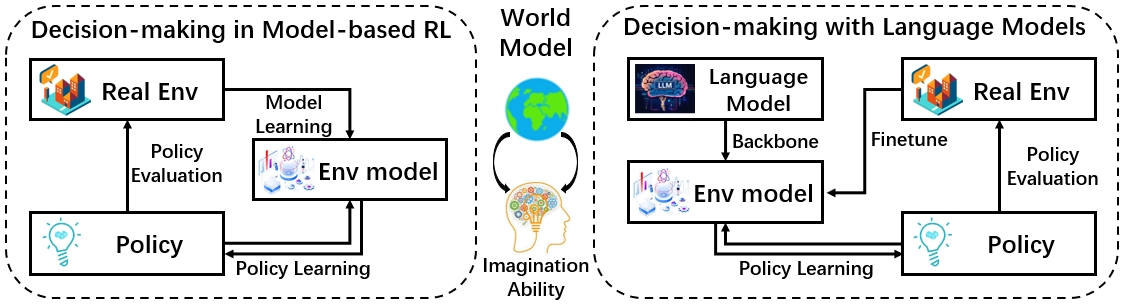
2.1 World Model in Model-based RL
经典 MBRL 把决策建模为 MDP (S, A, M, R, γ),world model 学 transition M 和 reward R。Survey 沿三条 axis 梳理:
- State representation:从 latent recurrent state(PlaNet/Dreamer 系列)到 transformer-based dynamics(IRIS/TWM)到 diffusion world model(DIAMOND)。
- 使用方式:(a) Dyna-style,用 model rollout 增广真实数据;(b) MPC / planning,用 model 做 short-horizon look-ahead;(c) actor-critic in imagination(Dreamer 风格)。
- 关键问题:长 horizon error accumulation、exploration-exploitation、model bias 如何不让 policy 过拟合到模型 hallucination。
2.2 LLM-as-World-Model
Figure 4 — World knowledge in LLMs for world model.
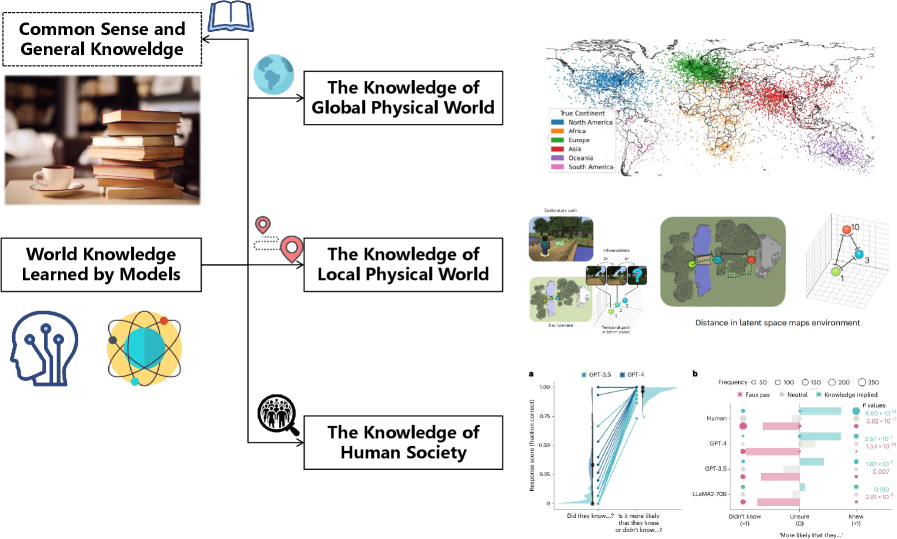
LLM 通过 large-scale pretraining 内化大量 commonsense / 物理 / 社会知识,被作者归为 “implicit world model” 的另一种实现形态。Sec 3.2 把 LLM 知识进一步分三层:
- Global physical world:地理、天文、物理常识等大尺度结构化知识。
- Local physical world:日常物体属性、affordance、因果链——和 embodied agent 关系最直接。
- Human society:社会规范、心智理论、role-play,是 social simulacra 的基础。
Dr. Li 视角:把 LLM 当 WM 是 framing 上方便,但严格说 LLM 缺 explicit dynamics——它会预测下一段叙事而非下一个物理状态。Survey 没有过分推销 “LLM = WM”,承认了它是 “world knowledge container” 这层定位,比一些 hype 更克制。
3. Future Prediction(Sec 4)
3.1 Video as World Model
围绕 Sora 这条主线讨论 video WM 的两个子问题:
- Towards Video World Models:从 next-frame prediction → 长序列、动作可控、多模态输入(text + traj)。Sora 被作为代表,关注其 spatial-temporal coherence 与 physical-law adherence。
- Capabilities:interactivity(GameNGen 的 20 fps 实时交互、Genie 的 latent action)、physical fidelity(VBench-2.0 / Physics-IQ 的诊断)、controllability(camera / action / text 条件)。
3.2 Embodied Environment
Figure 5 — Indoor / outdoor / dynamic embodied environments.
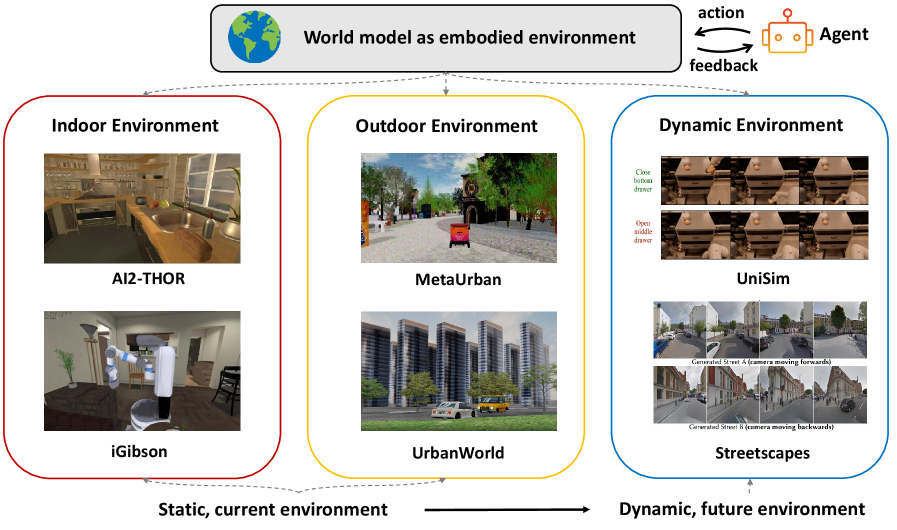
把 WM 当做 embodied env 时,分三层:
- Indoor:Habitat / AI2-THOR / ProcTHOR 类 simulator,强调任务多样性与物理逼真。
- Outdoor:CARLA、CityGen 风格驾驶/城市环境,依赖大规模 procedural generation。
- Dynamic:从 static scene 走向 generative 的 first-person dynamic environment(Genie 系、Cosmos 系),目标是给 embodied agent 提供 ever-changing feedback 而不是固定地图。
4. Application Domains(Sec 5)
4.1 Game Intelligence
强调三个能力维度:interactivity(GameNGen real-time)、generative content(Genie 用 latent action 推 platformer)、long-horizon stability。Survey 的 take 是 WM 把 game dev 从 “scripted assets” 推向 “generative engine”。
4.2 Embodied Intelligence
Figure S1 — Development of robotic world model.
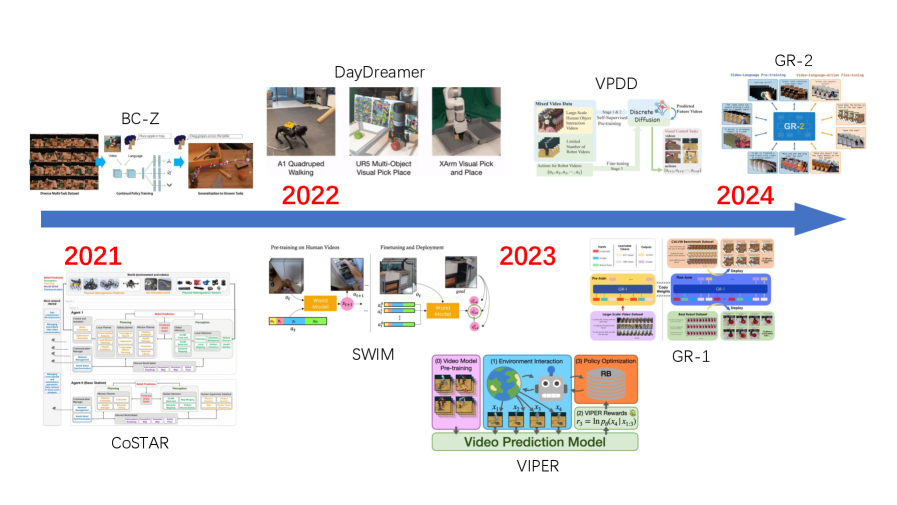
三类工作:
- Learning implicit representation:例如 RT-2 / OpenVLA / Pi0 这类 VLA 把视觉-动作映射当 implicit dynamics 学。
- Predicting future states:IRASim、UniSim、Cosmos 等做 action-conditioned video prediction,作为 robot data engine 或 policy evaluator。
- Sim-to-real:用 generative WM 缩短模拟到真实的 gap,配合 fine-grained sensory data 形成 self-reinforcing loop。
4.3 Urban Intelligence
Figure 6 — World model in autonomous driving.
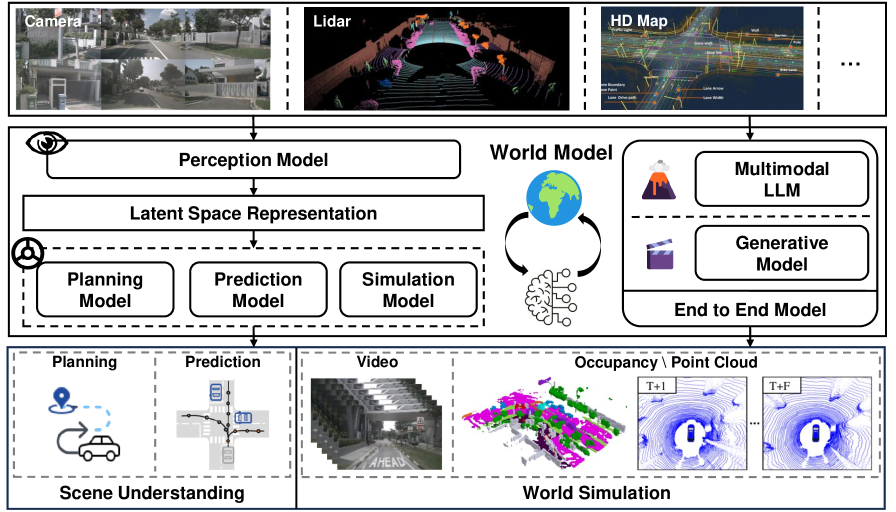
驾驶 pipeline 拆 perception / prediction / planning / control,对应 “implicit representation” 的 BEV/occupancy 学习与 “future prediction” 的端到端 driving simulator。代表工作:OccSora、Vista、Cosmos-Drive 系。还顺带覆盖 autonomous logistics 与 urban analytics。
4.4 Societal Intelligence
Figure S2 — World model and social simulacra.
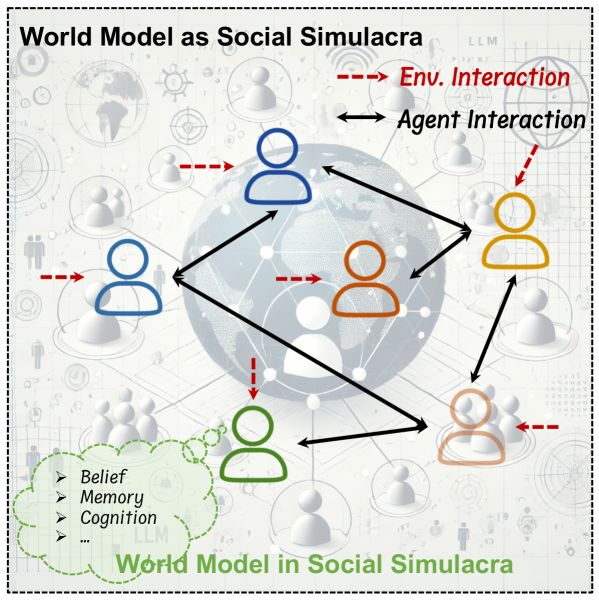
LLM-driven social simulacra(Park 2023 generative agents 是奠基)有两面:(a) simulacra 本身是 explicit WM,mirror real society;(b) agent 内部演化出 implicit WM 来推断他人行为。
4.5 Functions of World Models
最有信息量的一节切分:
- Cloud-side WM:video generator 当数据引擎、RL env、policy evaluator——主要服务 train-time。
- Edge-side WM:latent space WM 给 agent 当 brain,做 on-device MPC(V-JEPA 2 例子),不需要 pixel-level 生成。
Dr. Li 视角:cloud / edge 这条切分比 implicit / predictive 更落地。它隐含一个判断:高保真像素生成不应该是 robot brain 的 inner loop,能力分工 (data factory vs. controller) 才是合理工程边界——这一点和近期 V-JEPA 2 / 1X World Model 的实践方向一致。
5. Open Problems(Sec 6)
| # | Topic | 核心论点 |
|---|---|---|
| 6.1 | Physical rules & counterfactual | 纯数据驱动的 Sora 仍有 gravity/fluid/thermal 失败;Genesis、PhysGen、physics-informed diffusion 三条 hybrid 路线兴起 |
| 6.3 | Benchmarks | 见下表 |
| 6.4 | Sim-to-real | 多模态/3D/多任务能力 + self-reinforcing loop |
| 6.5 | Simulation efficiency | fps/cost 是 drone、autonomous driving 等 RL 场景的硬约束 |
| 6.6 | Ethics & safety | data privacy(GDPR)、unsafe scenario synthesis、deepfake accountability |
Table 8(节选) — Representative WM benchmarks.
| Category | Benchmark | 关键维度 |
|---|---|---|
| Video simulation | WorldSimBench | 把人类偏好挂钩 action-level consistency |
| WorldScore | 3000 camera-spec 场景;controllability/quality/dynamics | |
| VBench / VBench-2.0 | 通用 T2V/V2V;后者强调 intrinsic faithfulness(physics, commonsense) | |
| T2V-CompBench | compositional T2V;attribute/action/relation binding | |
| Physical & spatial | PhysBench | 10k video-image-text triplet,VLM 物理 gap |
| Physics-IQ | 5 个物理域,law adherence vs. perceived realism | |
| T2VPhysBench | 12 条 first-principle laws 清单 | |
| VideoPhy | action-centric prompts,semantic + commonsense | |
| Spatial | Basic Spatial Abilities | 心理测量学的 5 类空间技能 |
❓ Survey 把 benchmark 整理成清单,但没有讨论 “用哪一个评 WM 才公平”——例如 VBench 偏向视觉 fidelity,会让 V-JEPA 这类 latent WM 看起来很差。这是个未来比较 paper 时容易被忽略的 confound。
关联工作
Survey 内引用的关键 building blocks
- Genie: latent-action 可交互 video WM,Sec 4.1/5.1 反复出现
- GameNGen: real-time neural game engine,作 interactivity 例证
- DIAMOND: diffusion world model,MBRL imagination 的代表
- Vista / OccSora: 驾驶 WM 的 implicit / generative 两端
- IRASim: action-conditioned video prediction for robotics
- Cosmos-Reason1: NVIDIA Cosmos 系列里的 reasoning 分支,对应 survey 提到的物理 WM 平台
- V-JEPA 2: latent-space WM 当 edge-side agent brain 的代表
- PaLM-E: LLM-as-WM 在 embodied 的早期实现
同类对比
- Robotic World Model (ETH): 单一 system 的 deep dive,与 survey 的 broad map 互补
- DomainMap: World Model: vault 里 WM 主题入口,可拿这篇 survey 的 categorization 更新
方法相关
论文点评
Strengths
- 唯一一篇把 implicit / predictive 两脉同时盖住的 WM survey:相比 Appendix A 列出的几篇(驾驶/视频/MLLM-only),它的覆盖范围确实更全,且把 LLM-as-WM 与 video-WM 放进同一框架。
- timeline + categorization 配图(Fig 1, 2):可直接当 mental map 用,对新人入坑或 related work 起手很方便。
- 应用域 + cloud/edge 功能切分(Sec 5.5):比 “WM 用在哪儿” 这种平铺更有结构,把 data-engine / RL-env / policy-evaluator / agent-brain 四种角色讲清楚。
- benchmark 表(Sec 6.3):少有 survey 会把 12+ 个评测列在一张表里并标 scope,是实际查询时的高复用资产。
- 持续更新:v1 (2024-11) → v4 (2025-12) 多次重写 Sec 2 / Sec 5,跟进 Sora、Genie、Cosmos、V-JEPA 2 等新工作;ACM Computing Surveys 录用版本。
Weaknesses
- Survey 的通病:广而不深。每个子方向的 “为什么 work / 在什么 condition 会 break” 几乎不展开,读者拿到的是一张地图而不是 mental model。例如 Sora 的 physical-law failure 只是被列出,不分析失败模式分布。
- 二分类 categorization 过于干净:implicit vs. predictive 在 V-JEPA、Cosmos-Reason 等近期工作里其实交融,Survey 把它们硬塞进单一桶,分类边界稍微人为。
- 缺定量比较:除了 benchmark 表本身,全文几乎没列具体 number;同类 WM 方法谁强谁弱无法从 survey 直接判断。
- Open problems 部分偏 wishlist:六个方向(physics、benchmark、sim2real、efficiency、ethics)都成立,但没指出哪些有可操作的 hypothesis、哪些只是泛泛 desideratum。
- 作者 bias 明显偏 urban / society 应用(Tsinghua FIB lab 主线),urban intelligence/social simulacra 章节比 robotics WM 更详尽,但前者对 VLA / embodied 受众来说价值有限。
可信评估
Artifact 可获取性
- 代码: 非论文 artifact;GitHub 仓库
tsinghua-fib-lab/World-Model维护 representative paper 列表 + 链接,无 model code - 模型权重: 不适用(survey)
- 训练细节: 不适用
- 数据集: 不适用
Claim 可验证性
- ✅ 历史脉络(Minsky frame、Craik mental model、Ha & Schmidhuber 2018):可在引用文献回溯
- ✅ Sora / GameNGen / Genie / V-JEPA 2 / Cosmos 等具体能力描述:均可在原论文 cross-check
- ⚠️ “first comprehensive survey of world models” 的首创性 claim:Appendix A 自己列了几篇同期 survey,“first” 更像是对 categorization 框架而非 coverage 的主张
- ⚠️ Sec 6.1 关于 hybrid physics 路线 “promising” 的判断:基于少量代表作,缺乏跨方法的失败模式系统对照
- ⚠️ Application domain 选择(game / embodied / urban / society):作者给的 rationale 并未论证 “为何不是其他切法”,社会模拟权重偏高可能反映 lab 偏好
Notes
- Survey 的真正用法:当成 1) related-work 入口 + 2) benchmark cheatsheet + 3) timeline 索引。不要指望从这里学到 “为什么 X work”,要去读它指向的原文。
- 可以更新 WorldModel:把 Sec 5.5 的 cloud-side / edge-side 切分加进 domain map,比单纯的 “implicit vs. predictive” 更可操作。
- 值得追踪 v5+ 更新:从 update log 看作者在持续重写 Sec 2,未来若新增 “WM as agent memory” 或 “WM + RL” 章节会更有 buy。
- ❓ 一个 survey 没回答的关键 framing 问题:生成 video 的能力 = 拥有 world model 吗? Survey 同时把 Sora 和 V-JEPA 当 WM,但前者是 pixel-level 模仿器、后者是 latent dynamics learner——两者的 “wm-ness” 应不应该用同一把尺子衡量?这是 reading critically 时要打的星号。
Rating
Metrics (as of 2026-04-24): citation=134, influential=7 (5.2%), velocity=7.84/mo; HF upvotes=1; github 653⭐ / forks=32 / 90d commits=0 / pushed 157d ago
分数:2 - Frontier 理由:作为当前覆盖面最广的 WM survey(Strength 1、5:同时盖 implicit/predictive 两脉、ACM CSUR 录用、v4 持续追到 Cosmos/V-JEPA2),其 categorization、cloud/edge 切分和 benchmark cheatsheet(Strength 3、4)已是 WM 方向常被引的入口型资料。但它并不具备奠基地位——不提出新方法、不定义新评测、二分类 categorization 存在人为边界(Weakness 2),且 “广而不深”(Weakness 1)使其无法像 Dreamer / Ha-Schmidhuber 那样作为必读源头。因此落在 2(方向重要参考)而非 3(必读奠基)或 1(niche/过气)。