Summary
GenieReasoner: Unified Embodied VLM Reasoning with Robotic Action
- 核心: 提出 FACT(Flow-matching Action Tokenizer)将连续动作离散化为 token 序列,在统一自回归框架中联合优化 VLM 推理与精确动作执行
- 方法: VQ-encoder 将动作 chunk 压缩为离散 code,flow-matching decoder 从离散 code 重建高保真连续轨迹;三阶段训练(tokenizer → 联合预训练 → 后训练)
- 结果: ERIQ benchmark 平均 82.72%(vs. base 58.64%);真机实验在 language following 和 success rate 上均超越 π0.5(连续)和 π0-FAST(离散)baseline
- Sources: paper | website
- Rating: 2 - Frontier(来自 AgiBot 的新 VLA,unified reasoning+action 思路有代表性,但时间太新、代码未开源、ERIQ 未被社区采用,尚未到 Foundation)
Key Takeaways:
- ERIQ benchmark: 6K+ embodied QA pairs,覆盖空间感知、规划监控、错误检测恢复、人类意图理解四个维度,首次系统解耦 reasoning 评估与 action execution,验证了 reasoning 能力与 VLA 泛化性能的正相关
- FACT tokenizer: VQ-encoder + flow-matching decoder 的设计,在同等 code length 下重建误差比 FAST+ 低一个数量级,解决了离散化 token 精度不足的问题
- 统一优化的关键: 三阶段训练中保持 Embodied VQA co-training 是防止 reasoning 能力退化的关键,post-training 阶段去掉 VQA 数据会导致泛化显著下降
Teaser. GenieReasoner 系统概览
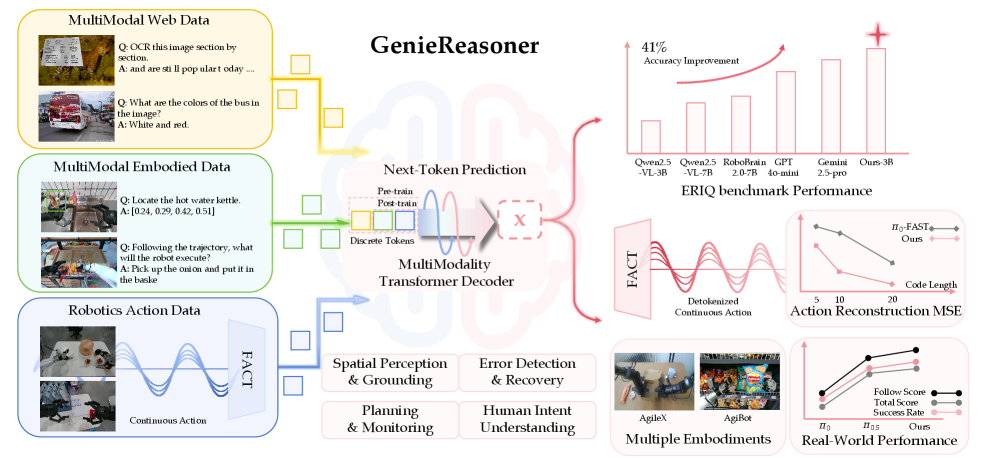
Introduction
核心问题:现有 VLA 模型面临 reasoning-precision trade-off——优化 reasoning 的模型动作精度下降,优化 execution precision 的模型泛化能力有限。
现有离散化方案的局限:
- Uniform binning(RT-2, OpenVLA):需要过多 token 才能达到精细控制精度
- VQ-VAE:编码紧凑但缺乏高精度控制
- FAST(BPE-based):变长编码导致解码不稳定
- Hybrid(π0):连续 action head 的梯度与离散 backbone 的优化目标冲突,损害 reasoning 性能
GenieReasoner 的核心 insight:用 VQ-VAE 做离散化(紧凑稳定),但把精细运动生成的负担转移给 flow-matching decoder,从而在 compact discrete space 做 planning,同时通过 ODE 积分恢复高保真连续轨迹。
Embodied Reasoning and ERIQ Benchmark
ERIQ(Embodied Reasoning Intelligence Quotient):6,052 个 embodied QA pairs,采用标准 VQA 协议独立于 action execution 评估 embodied reasoning。
四个推理维度:
- Spatial Perception & Grounding: Scene Understanding、Task Grounding、Relative Position Grounding、Dualview Matching
- Planning & Monitoring: Sub-task Planning、Trajectory Analysis、Action Understanding、Success Detection
- Error Detection & Recovery: Mistake Existence / Classification / Recovery
- Human Intent Understanding: Human Intention Comprehension、Human-Robot Interaction
Figure 2. ERIQ benchmark 示例

Figure 3. ERIQ 15 个子任务分布

数据集覆盖 100+ 任务场景,跨 5 个领域(household 35%、restaurant 20%、supermarket 20%、industrial 15%、office 10%)。三种模态:Single Image(53%)、Sequential Images(26%)、Interleaved Image-Text(21%)。
相比已有 benchmark,ERIQ 是唯一在四个维度上全覆盖(●)的,且全部基于真实机器人数据、采用确定性 MC 评估协议。
GenieReasoner: Unified Discrete Low-level Policy Framework
System Architecture
Figure 4. GenieReasoner 系统架构
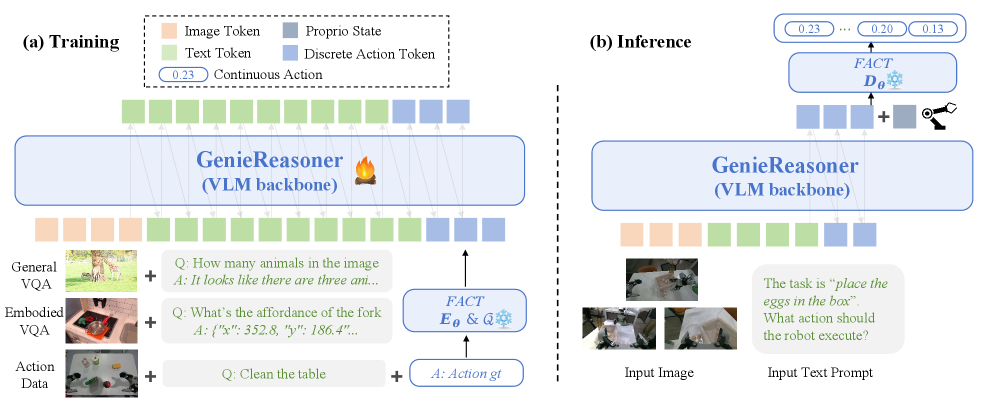
两阶段工作流:
- Training: 统一 pipeline 联合训练 VLM backbone,将连续动作 tokenize 为离散 latent space 中的 token,同时混合 General VQA 数据保持视觉语言能力
- Inference: VLM backbone 自回归生成离散 action code → FACT decoder 通过 flow matching 解码为连续控制信号
FACT: Flow-matching Action Tokenizer
Figure 5. FACT 架构
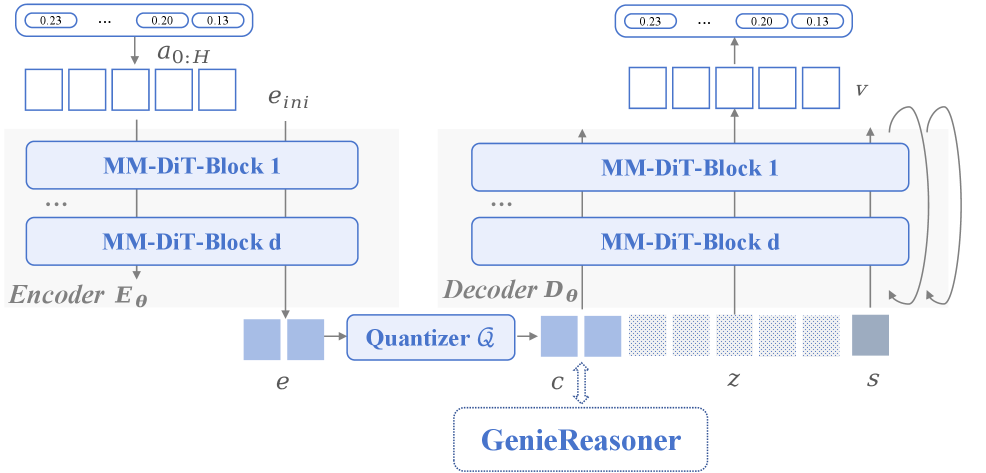
Encoder + Quantization:
- MM-DiT backbone,patch size = 1
- 使用 zero-initialized queries 与动作特征交互,编码为连续 latent
- Lookup-free bitwise quantization:
Flow-Matching Decoder:
- 学习 Rectified Flow 的速度场,沿直线路径从高斯噪声传输到数据分布
Equation. Rectified Flow 插值
Equation. Flow-matching loss
符号说明: 是噪声样本, 是目标动作 chunk, 是量化后的离散 code, 是 flow 时间步。
Inference:从高斯噪声 出发,通过数值 ODE 积分恢复连续动作:
Experiments
Implementation Details
三阶段训练 recipe:
- Stage 1: 训练 FACT tokenizer(独立于 VLM)
- Stage 2: 端到端联合预训练——混合 General VQA + Embodied VQA + tokenized action 数据
- Stage 3: 任务特定后训练,保持 Embodied VQA + action 数据 co-training 防止灾难性遗忘
训练数据:
- General VQA: Cambrian-10M, LLaVA-OneVision, Describe Anything, CogVLM-SFT-311K, BLIP3-Grounding-50M
- Embodied VQA: NVIDIA Cosmos-Reason, ShareRobot, Robo2VLM, EmbSpatial-SFT, ManipulationVQA-60K
- Embodied action: AgiBot World 平台数据 + ARX/AgileX 多形态数据 + 开源操作数据集
Embodied Reasoning Capabilities
Table. ERIQ Benchmark 核心结果(Ours-3B vs. baselines)
| Model | ERIQ Avg | Act. Und. | Dualview | Success | Subtask | Intention |
|---|---|---|---|---|---|---|
| Qwen2.5-VL-3B | 58.64 | 65.50 | 37.53 | 52.75 | 55.67 | 86.22 |
| Qwen2.5-VL-7B | 66.69 | 76.83 | 50.56 | 62.62 | 60.67 | 73.78 |
| Gemini-2.5-pro | 80.55 | 89.83 | 89.89 | 67.37 | 76.67 | 91.11 |
| GPT-4o-mini | 77.61 | 84.67 | 93.48 | 71.63 | 65.17 | 89.78 |
| Ours-3B | 82.72 | 96.67 | 68.54 | 85.25 | 90.50 | 96.44 |
Insights: 3B 模型在 ERIQ 平均分上超越所有 open-source 7B+ 模型和 GPT-4o-mini,仅次于/持平 Gemini-2.5-pro。Action Understanding(96.67%)和 Human Intention(96.44%)极高。Dualview Matching 相比 base 提升 31%,但仍低于 GPT-4o-mini 和 Gemini。
Figure 6. 跨平台 zero-shot 推理能力展示

Ablation on FACT Tokenizer
Figure 7. FACT vs FAST+ 重建误差对比
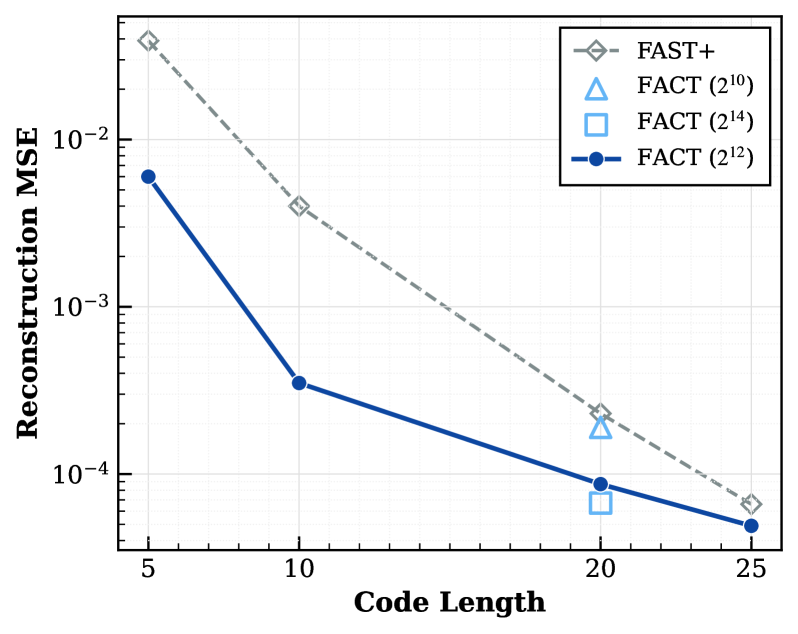
FACT 在相同 code length 下重建误差比 FAST+ 低约一个数量级。最终配置: 词表 + code length 20,在重建保真度和预测难度之间取得最优平衡。
Ablation of different training recipes
Table. 训练策略消融(GenieSim 模拟环境)
| Exp | Pre-train (Gen.VQA + Emb.VQA + Action) | ERIQ | Post-train VQA | Success (Target/Spatial/Color) |
|---|---|---|---|---|
| #0 | 无 | 58.64 | 无 | 0.05 / 0.00 / 0.06 |
| #1 | Gen.VQA + Emb.VQA | 82.72 | 无 | 0.04 / 0.00 / 0.03 |
| #2 | Action only | 0.00 | 无 | 0.12 / 0.20 / 0.07 |
| #3 | 全部 | 80.39 | 无 | 0.18 / 0.05 / 0.14 |
| #4 | 全部 | 80.39 | 有 | 0.25 / 0.35 / 0.22 |
Insights:
- Exp #1 vs #0:Embodied VQA 预训练将 ERIQ 从 58.64 提升到 82.72,但没有 action alignment 则 success rate 接近 0
- Exp #2:纯 action 预训练破坏了 reasoning 能力(ERIQ=0),但获得了基本执行能力
- Exp #4 vs #3:后训练阶段保留 Embodied VQA co-training 是关键,success rate 全面提升(如 Spatial 从 0.05 到 0.35)
Real-World Evaluation
Figure 8. 真机 language following 评估
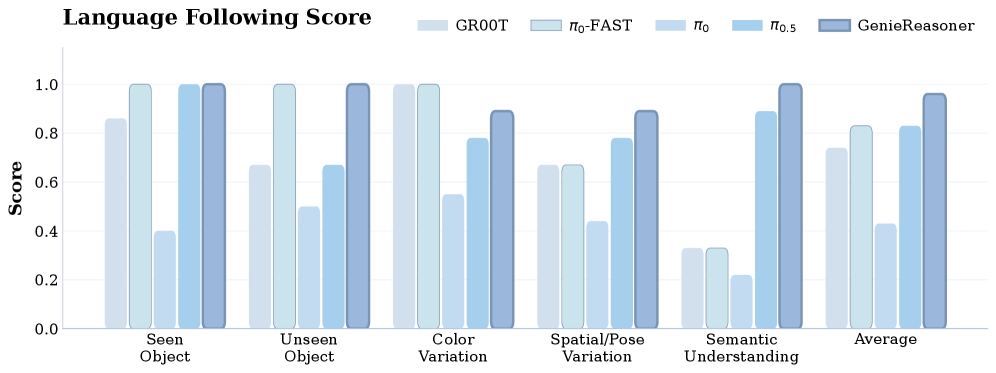
Figure 9. 真机 task success rates
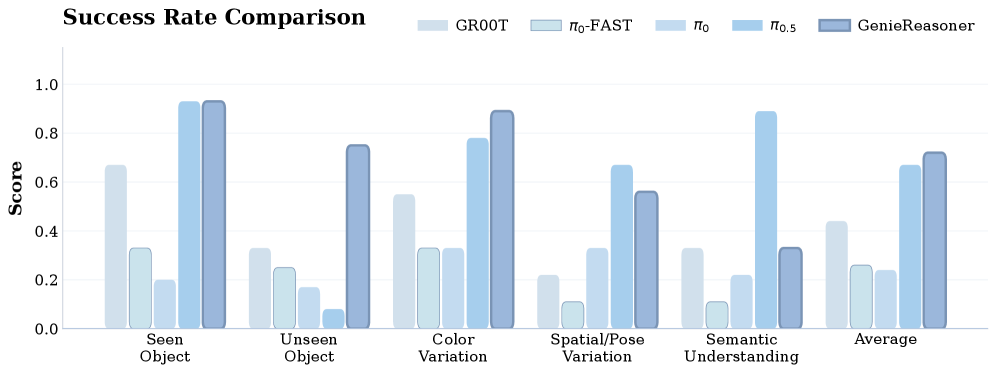
Figure 10. 真机综合性能对比
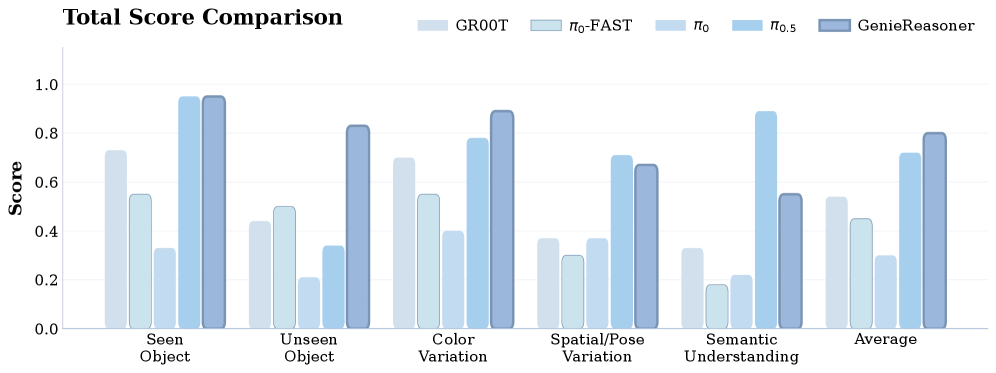
五个测试设置:Seen Object、Unseen Object、Color Variation、Spatial/Pose Variation、Semantic Understanding。
关键发现:
- π0-FAST(离散):language following 高但 success rate 低——量化精度不足导致抓取失败
- π0.5 / GR00T(连续):执行能力强但频繁走向错误目标——action head 与 VLM 表示断开
- GenieReasoner: 同时保持了离散模型的指令跟随准确性和连续模型的执行精度
Figure 11. 真机复杂任务展示

跨平台验证:AgiBot G1 人形 + ARX AC-One 机械臂,涵盖 OOD 物体操作、长 horizon 语义任务、可变形物体操作。
关联工作
基于
- Qwen2.5-VL-3B: VLM backbone
- AgiBot World: 大规模 embodied demonstration 数据平台
- Rectified Flow / Flow Matching: FACT decoder 的生成框架
- Lookup-free Quantization (MAGVIT-v2): bitwise quantization 方法
- MM-DiT: FACT encoder/decoder 的 backbone 架构
对比
- π0 / π0.5: 连续 action head baseline(flow matching / diffusion-based)
- π0-FAST: 离散 action tokenization baseline(BPE-based)
- GR00T: 连续 action baseline
- OpenVLA: uniform binning 离散化 baseline
方法相关
- ECoT (Embodied Chain-of-Thought): reasoning 集成到 VLA 的先驱
- VQ-VLA: learned quantization VLA
- Diffusion Policy: diffusion-based action generation
- ERQA (Gemini Robotics): embodied reasoning benchmark
论文点评
Strengths
- 问题分析精准: 将 VLA 的 reasoning-precision trade-off 分析得很清楚——离散方案精度不够,连续方案梯度冲突损害 reasoning。FACT 用 flow matching 做 decoder 是一个 clean 的解法
- ERIQ benchmark 设计合理: 解耦 reasoning 和 execution 评估,证明了 reasoning 能力是泛化的前置条件。四维 15 子任务覆盖全面,且全部基于真实机器人数据
- 消融实验有说服力: 训练策略消融清晰展示了每个组件的贡献,特别是 post-training 阶段保留 VQA 数据的重要性
- 真机实验全面: 对比了连续和离散两类 baseline,跨多平台(AgiBot G1、ARX),测试了 OOD 泛化
Weaknesses
- ERIQ benchmark 未公开细节不足: 数据构建流程(人工标注 vs 自动生成)、标注者一致性、难度分布缺乏详细描述
- 真机实验缺少具体数字: Figure 8-10 以柱状图呈现,无法精确读取数值;rollout 数量和置信区间未报告
- FACT 的推理开销: Flow matching decoder 需要多步 ODE 积分,推理延迟未报告,对实时控制的影响不明
- Base model 较小: 仅在 Qwen2.5-VL-3B 上验证,scaling 到更大模型的效果未知
可信评估
Artifact 可获取性
- 代码: 未开源(project page 标注 Coming Soon)
- 模型权重: 未发布
- 训练细节: 仅高层描述(三阶段训练、数据来源列表),缺少具体超参、数据配比、训练步数
- 数据集: ERIQ benchmark 未开源;训练数据混合多个开源数据集 + AgiBot 私有数据
Claim 可验证性
- ✅ ERIQ benchmark 上的定量结果:提供了与多个 baseline 的详细对比表格
- ✅ FACT 重建误差优于 FAST+:Figure 7 提供了定量 MSE 对比
- ⚠️ 真机实验结果:仅以柱状图展示,无精确数值和统计显著性分析;rollout 数量未说明
- ⚠️ “ERIQ 预测下游成功率”:Exp #1 的高 ERIQ 分数 → Exp #4 的高 success rate 的因果链不够严格,confound 因素多
- ❌ 跨平台 zero-shot reasoning 仅以定性图展示(Figure 6),无独立量化评估
Notes
Rating
Metrics (as of 2026-04-24): citation=4, influential=0 (0.0%), velocity=1.05/mo; HF upvotes=1; github=N/A (无代码仓库)
分数:2 - Frontier 理由:论文提出的 FACT tokenizer + unified discrete 框架在 reasoning-precision trade-off 上给出一个 clean 的解法(见 Strengths #1),且来自 AgiBot 这样的主流 embodied AI 实验室,对比了 π0 / π0.5 / GR00T 等当前主要 VLA baseline,属于方向前沿代表工作。但距离 Foundation 差在:(1) 论文刚发布(2025-12),ERIQ benchmark 尚未被社区采用为标准评测;(2) 代码权重均未开源(见 Artifact 可获取性),复现与外部验证暂不可能;(3) scaling 仅在 3B 验证。不是 Archived,因为方法思路和 benchmark 设计都有代表性,值得作为 VLA + unified reasoning 方向的参考。2026-04 复核:3.8 月累计 4 citation / 影响力 0、HF=1、仍无代码释放,早期信号温和;处于 <3mo 豁免窗口刚过的边缘,按 early-signal 口径仍归 Frontier。