Summary
OSWorld: Benchmarking Multimodal Agents for Open-Ended Tasks in Real Computer Environments
- 核心: 首个在真实 OS(Ubuntu/Windows/macOS)VM 上跑、可扩展、execution-based 评测的 computer-use agent benchmark
- 方法: 基于 VM 的可控环境 + 369 个真实任务 + 134 个例子级 execution-based eval scripts,每条任务由 9 位作者历时 ~1800 man-hours 标注
- 结果: 人类 72.36%,GPT-4 (a11y tree) 仅 12.24%,workflow(多 app)任务普遍 <7%;瓶颈在 GUI grounding 和 operational knowledge
- Sources: paper | website | github
- Rating: 3 - Foundation(computer-use 方向事实标准评测,后续主线工作 UI-TARS / Agent-S2 / OS-Atlas / ComputerRL 均以它为核心评测,护城河在 134 个 example-specific eval 与持续维护的 OSWorld-Verified)
Key Takeaways:
- 真实 OS + execution-based eval 是 computer-use 评测的正确组合:抛弃 action matching 后允许 agent 用任意路径达成目标,比静态 demonstration benchmark 更接近真实任务
- 134 个 example-specific eval functions 是 OSWorld 区别于前辈最重要的工程投入——比 WebArena (5)、VisualWebArena (6) 高一个数量级,是 “open-ended task” 能成立的前提
- 12.24% vs 72.36% 的巨大 gap 把 computer-use 从”看起来快解决”拉回”远未解决”,并明确指出两个具体瓶颈:GUI grounding(坐标精度)+ operational knowledge(domain 软件知识)
- a11y tree > screenshot-only:仅靠像素的 VLM 普遍 ~5%,加 a11y tree 可翻倍到 ~12%,说明当时 VLM 的 visual grounding 远不足以支撑端到端 agent
- Set-of-Mark (SoM) 在 desktop 反而下降:经典视觉理解任务上 work 的 SoM 在 OS 高分辨率、密集元素场景被噪声反噬,提示 web→desktop 迁移并非 trivial
Teaser. OSWorld 整体架构:VM 内运行真实 OS,agent 接收 screenshot + a11y tree,用 pyautogui 代码作为 action,task 完成后由 example-wise execution-based script 验证最终状态。
Problem & Motivation
现有 computer-use / digital agent benchmark 有三类硬伤:
- 缺可执行环境:GAIA、Mind2Web、WebLINX、AitW、PixelHelp 等只提供 demonstration 数据集,没有 controllable executable env,agent 只能预测下一步而无法真正交互探索
- 被锁在单一域:MiniWoB++、WebShop、WebArena、VisualWebArena 限定在 web 浏览器;AssistGUI、ScreenAgent 限定在桌面单 app;没有 cross-app workflow 的能力
- Action-matching 的评测有偏:用 “下一步动作是否匹配 ground truth” 评分会错误惩罚等价的替代解法
OSWorld 针对性地要求:真实 OS + 跨 app + open-domain 任务 + example-specific execution-based eval。
Method
环境基础设施
Figure 2. OSWorld 环境基础设施。基于 VM(VirtualBox/VMware/AWS/Azure 等),由 Coordinator 接收 config 文件 → Task Manager 初始化(下载文件、打开 app、调整窗口)→ agent 通过 keyboard/mouse code 与 Simulator 交互 → 任务结束后 post-process(保存文件、激活窗口)→ Getter 抓取最终状态 → Evaluator 跑 eval function 给出 reward。Headless 与多 VM 并行均支持。
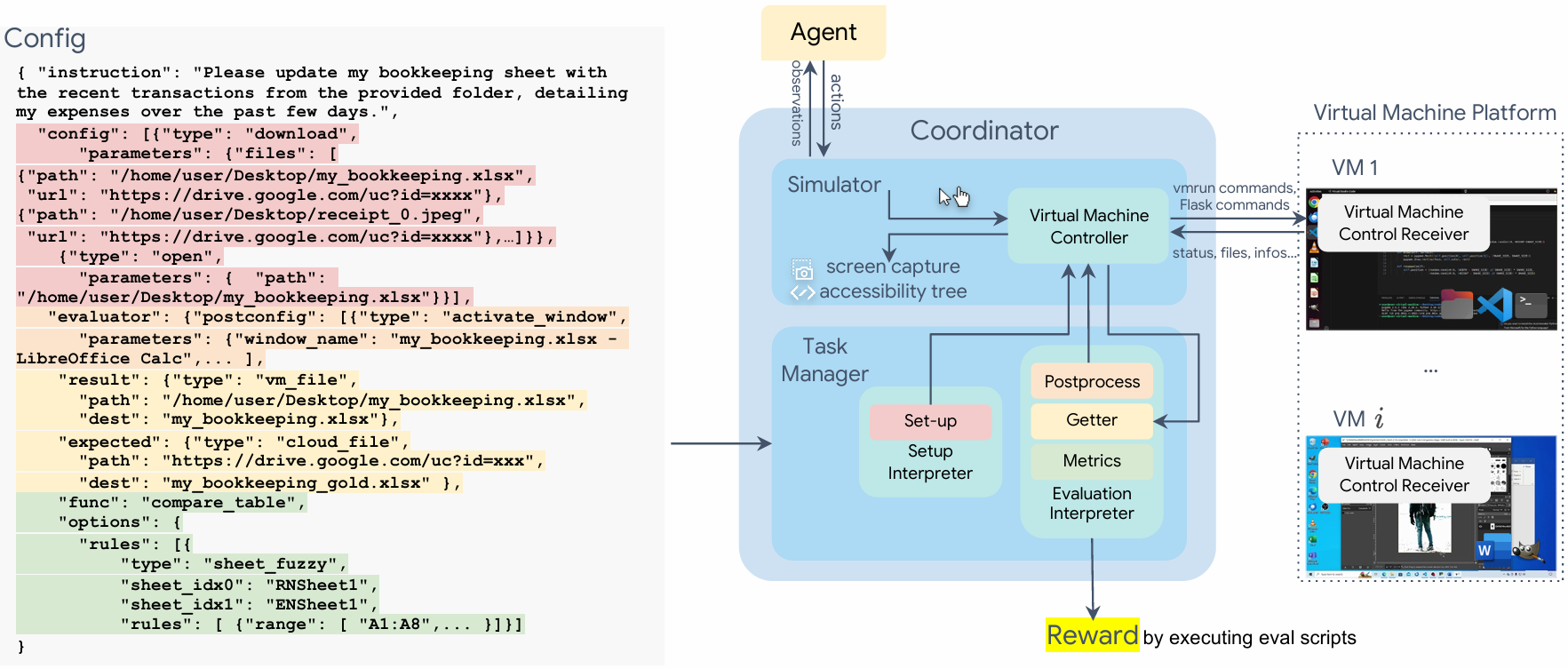
Task 形式化
POMDP :
- :natural language instruction + screenshot + a11y tree(可选组合)
- :pyautogui Python code(
click(x,y)、hotkey(...)、write('text')等)+ 三个特殊动作WAIT/FAIL/DONE - ,仅在终止步基于 execution-based script 给出
三个关键设计决策
- VM-based:隔离 + snapshot 快速 reset;用 hybrid config 而非 per-example snapshot 避免 GB 级存储
- Example-specific eval:拒绝”一类任务一个 metric”;为每个 task 写 getter(取 cookie / 文件 / a11y tree / 云端 reference 等)+ evaluator(compare_table、check_a11y_tree、is_cookie_deleted 等)
- Real OS apps:Chrome、VLC、Thunderbird、VS Code、LibreOffice (Calc/Writer/Impress)、GIMP + 系统自带工具
Benchmark 构建
Table 3. OSWorld 关键统计。
| Statistic | Number |
|---|---|
| Total tasks (Ubuntu) | 369 (100%) |
| - Multi-App Workflow | 101 (27.4%) |
| - Single-App | 268 (72.6%) |
| - Integrated(来自 NL2Bash/Mind2Web/SheetCopilot/PPTC/GAIA) | 84 (22.8%) |
| - Infeasible(deprecated/hallucinated features) | 30 (8.1%) |
| Supp. tasks (Windows) | 43 |
| Initial States | 302 |
| Eval. Scripts | 134 |
标注成本:9 位 CS 学生(全部为 student authors)历时 3 个月,约 1800 man-hours(650h single-app + 750h workflow + 400h double-check),加上 400h 收集,相当于人均 ~225h。每个 example 的 eval script ~2 man-hours,setup config ~1 man-hour。每条任务由另外两位 author 当作 agent 实际跑一遍来质检。
任务来源:官方 tutorial、TikTok/YouTube tip 视频、WikiHow、Reddit/StackOverflow、Coursera/Udemy、个人 blog;并 brainstorm 跨 app workflow(这部分网上几乎找不到现成 example)。
Observation Space
- Screenshot:1920×1080,原始像素
- A11y tree:XML,经过过滤(按 tag / visibility / 文本存在性)+ 压缩为 tab-separated table,仅保留 tag/name/text/position/size。原始 a11y tree 经常超百万 token,过滤后 90th percentile ~6343 tokens
- 四种输入组合:
A11y tree only/Screenshot only/Screenshot + A11y tree/Set-of-Mark (SoM)
Action Space
Table 2. 动作空间示例(pyautogui 风格)。
| Function | Description |
|---|---|
moveTo(x, y) | Move mouse to coordinates |
click(x, y) | Click at coordinates |
write('text') | Type text at cursor |
press('enter') / hotkey('ctrl', 'c') | Key / hotkey |
scroll(±N) / dragTo(x, y) | Scroll / drag |
keyDown / keyUp | Modifier hold/release |
WAIT / FAIL / DONE | Special meta-actions |
选 pyautogui 而不是封装好的 web-style action(click element by id 之类)的关键理由:覆盖全部 human input(含 right-click、ctrl-click、drag、modifier hold),让 action space 不成为 capability 的天花板。
Key Results
主表:所有 baseline 远低于人类
Table 5. Baseline LLM/VLM agent 在 OSWorld 上的 success rate(max 15 steps,每条任务)。
| Inputs | Model | OS | Office | Daily | Profess. | Workflow | Overall |
|---|---|---|---|---|---|---|---|
| A11y tree | Mixtral-8x7B | 12.50 | 1.01 | 4.79 | 6.12 | 0.09 | 2.98 |
| A11y tree | Llama-3-70B | 4.17 | 1.87 | 2.71 | 0.00 | 0.93 | 1.61 |
| A11y tree | GPT-3.5 | 4.17 | 4.43 | 2.71 | 0.00 | 1.62 | 2.69 |
| A11y tree | GPT-4 | 20.83 | 3.58 | 25.64 | 26.53 | 2.97 | 12.24 |
| A11y tree | Gemini-Pro | 4.17 | 1.71 | 3.99 | 4.08 | 0.63 | 2.37 |
| A11y tree | Gemini-Pro-1.5 | 12.50 | 2.56 | 7.83 | 4.08 | 3.60 | 4.81 |
| A11y tree | Qwen-Max | 29.17 | 3.58 | 8.36 | 10.20 | 2.61 | 6.87 |
| A11y tree | GPT-4o | 20.83 | 6.99 | 16.81 | 16.33 | 7.56 | 11.36 |
| Screenshot | CogAgent | 4.17 | 0.85 | 2.71 | 0.00 | 0.00 | 1.11 |
| Screenshot | GPT-4V | 12.50 | 1.86 | 7.58 | 4.08 | 6.04 | 5.26 |
| Screenshot | Gemini-ProV | 8.33 | 3.58 | 6.55 | 16.33 | 2.08 | 5.80 |
| Screenshot | Claude-3-Opus | 4.17 | 1.87 | 2.71 | 2.04 | 2.61 | 2.42 |
| Screenshot+A11y | GPT-4V | 16.66 | 6.99 | 24.50 | 18.37 | 4.64 | 12.17 |
| Screenshot+A11y | GPT-4o | 41.67 | 6.16 | 12.33 | 14.29 | 7.46 | 11.21 |
| SoM | GPT-4V | 8.33 | 8.55 | 22.84 | 14.28 | 6.57 | 11.77 |
| SoM | Gemini-Pro-1.5 | 16.67 | 5.13 | 12.96 | 10.20 | 3.60 | 7.79 |
| SoM | Claude-3-Opus | 12.50 | 2.72 | 14.24 | 6.12 | 4.49 | 6.72 |
| Human | — | 75.00 | 71.79 | 70.51 | 73.47 | 73.27 | 72.36 |
五条主要 finding
- LLM/VLM 远未达到 digital agent 标准:最强 GPT-4 (a11y tree) 仅 12.24%,screenshot-only 的 VLM 普遍 5–6%。Claude-3 Opus 在通用 benchmark 上对标 GPT-4V,但在 OSWorld 上落后明显(仅 2.42% / 4.41%)
- Agent 的方差远大于人类:人类在五个子集上稳定在 70–75% 区间(<5% 波动);模型在 OS(CLI 友好)任务上能到 20–40%,到 Office(GUI 密集)跌至个位数,到 multi-app workflow 几乎全部 <7%
- A11y tree 是当前最有效的额外信号:加上 a11y tree 一般能让 success rate 翻倍。但效果因模型而异——Claude-3 在加 a11y tree 后从 2.42% 到 4.41%,远不如 GPT-4V 的提升
- SoM 在 desktop 不再是 free lunch:经典视觉理解任务上 work 的 SoM,在 OS 任务上对 GPT-4V 下降(11.77% vs S+A 的 12.17%)。作者推测原因:高分辨率 + 密集元素(spreadsheet 单元格)→ 噪声盖过 bbox 提示;且 SoM 无法支持需要精确坐标的细粒度操作
- Screenshot-only 是长期方向:当前性能最低(5.26%),但唯一不依赖 a11y tree(很多软件不支持、屏幕外设也拿不到、token 成本巨大)。是 generalize 到物理世界的必经路线
Ablation findings (§5)
Table 6. GPT-4V (SoM) 在不同任务子集的 SR。
| Task Subset | % of Total | SR (↑) |
|---|---|---|
| Easy (<60s 人类) | 28.72 | 16.78 |
| Medium (60–180s) | 40.11 | 13.12 |
| Hard (>180s) | 30.17 | 4.59 |
| Infeasible | 8.13 | 16.67 |
| Feasible | 91.87 | 13.34 |
| Single-App | 72.63 | 13.74 |
| Multi-App Workflow | 27.37 | 6.57 |
- 难度梯度:人类 84.91% / 81.08% / 49.57%(slight decline)vs agent 16.78% / 13.12% / 4.59%(cliff drop at >180s)
- Infeasible 检测:agent 在 infeasible 上反而略高(16.67%),但部分是 false positive——某些 setting 下 agent 倾向无脑输出
FAIL - 分辨率:screenshot-only 下分辨率↑→ SR↑(输出坐标必须对齐 1080P,低分辨率信息丢失);SoM 下 0.4× 下采样反而最优(适度降噪),0.2× 信息不够再下降
- Trajectory history:a11y tree (text) history 越长越有帮助;screenshot history 几乎不帮甚至有害——当前 VLM 对图像 history context 利用很差
- UI 布局 robustness:agent 对窗口位置/大小变化敏感,缺乏 layout invariance
❓ Tab. 5 中 GPT-4o 在
Screenshot + A11y tree设置下 OS 子集 41.67%,是全表最高单点。但 overall 反而不如 GPT-4 (12.24%),怀疑是 model 在某些 GUI 子集上 collapse;要看 App. C.5 的细分数据。
关联工作
基于
- WebArena WebArena: 启发 OSWorld 用真实可控环境 + execution-based eval,但限定在 4 个 web app 域;OSWorld 把这套思路升级到完整 OS
- VisualWebArena: SoM 设置直接沿用其方法
- VirtualBox / VMware / AWS: 底层 VM 基础设施
对比(非可执行 / 受限域 benchmark)
- GAIA、Mind2Web、WebLINX、PixelHelp、MetaGUI、AitW、OmniAct、ScreenAgent: demonstration dataset,无 executable env
- AgentBench、InterCode: multi-isolated / code env
- MiniWoB++、WebShop、WebArena、VisualWebArena、WorkArena: 限定 web
- WikiHow / AssistGUI: mobile / 单 desktop app
方法相关
- CogAgent CogAgent: 早期 GUI-aware VLM,作为 baseline 评测
- Set-of-Mark (SoM): 视觉 prompting 方法,本文实验显示在 desktop 上失效
- pyautogui: 选作 universal action space 的实现层
后续影响
- UI-TARS / UI-TARS-2 UI-TARS UI-TARS-2: 直接以 OSWorld 为核心评测;UI-TARS-72B 在 50 步限制下达 24.6%
- Agent-S2 Agent-S2、OS-Atlas OS-Atlas、ComputerRL ComputerRL、WindowsAgentArena WindowsAgentArena:均以 OSWorld 为基准或扩展
- GUI Agent Survey GUI Agent Survey、OS Agents Survey OS Agents Survey: 把 OSWorld 列为 evaluation 的事实标准
论文点评
Strengths
- 方法论上的范式转变:把 computer-use eval 从 “static demo + action matching” 推到 “real OS + execution-based”,这是 evaluation 上罕见的 paradigm 级别贡献。允许 agent 用任意路径达到同一终态,避免 OOD-correct 解法被错误判负
- 134 个 example-specific eval functions 是真正的护城河:相比 WebArena 的 5 个、VisualWebArena 的 6 个,OSWorld 的 eval function 数量高一个数量级。这是”open-ended task”能 scale 的基础设施投入,而非 marketing;后续 benchmark 想超越它,绕不开这层工程投入
- VM 抽象选得正确:用 VM 而非 docker 容器或 web 沙盒 → 能跑真实 desktop app(LibreOffice、GIMP、VS Code),这是 web-only benchmark 永远做不到的;snapshot + hybrid config 也避免了 per-example GB 级存储的 scaling 问题
- 失败模式诊断细致:把”agent 不行”具体拆成 GUI grounding(坐标精度)+ operational knowledge(domain 软件知识)+ history modeling + UI layout robustness 四个独立短板,给后续工作明确的 attack surface。UI-TARS 的 perception 设计、OS-Atlas 的 grounding pretrain、computer-use specialized model 的 domain knowledge 注入,都对应到这里某个 finding
- Cross-OS 设计有前瞻性:在 2024-04 提交时多数 benchmark 还在卷 web,OSWorld 已经把 macOS / Windows 接入;2025-07 推出 OSWorld-Verified(AWS 支持,eval time → 1 hour)说明 infra 持续维护,没有沦为 abandonware
Weaknesses
- 任务规模 369 显得偏小:相比 Mind2Web (2350) / AitW (30k),OSWorld 一个量级以下。虽然 execution-based 路线决定了 per-task 标注成本极高(~5 man-hours/task),但小数量 + open-ended → 单个 task 的统计噪声会放大 leaderboard 上的小幅差距
- 初始 baseline 性能过低:当时所有 setting 下 overall <13%,30%+ 的 hard task 在 4.59%。这种 “floor effect” 让 ablation 信号被噪声淹没——例如 Tab. 6 中 infeasible 反而比 feasible 高 (16.67% vs 13.34%) 很可能是统计噪声而非真实信号
- 8 个 Google Drive 任务的网络依赖问题:2025-07 的更新承认 8 个任务由于 IP/网络 issue 无法稳定 init,必须手动 fix 或排除。说明”真实 web 服务”路线在长期可复现性上有不可避免的脆弱性,这在论文初版没有充分讨论
- VM-based 引入显著延迟:每步 action 经过 VM ↔ host 的 control receiver/coordinator 通信,使得 agent 与环境的交互频率远低于 native sandbox 或 web。这对 RL 训练(需百万级 rollout)的 throughput 是真实瓶颈,论文没有给数字
- 缺 multi-turn / error recovery 的系统评估:所有任务在 max 15 step 内单次完成或失败,没有评测 agent 在中途错误后的 self-correction、replanning 能力——这恰好是 long-horizon agent 的核心难点
- Set-of-Mark 失效原因停留在猜测:作者把 SoM 在 desktop 失效归因为”高分辨率 + 元素密集”,但没做 controlled ablation(例如固定分辨率比较 element density,或在低密度 desktop subset 上测 SoM)。这是一个值得追问的发现,可惜没深挖
可信评估
Artifact 可获取性
- 代码: 完整开源(环境 + benchmark + baseline agent 实现),github.com/xlang-ai/OSWorld 持续维护
- 模型权重: N/A(这是 benchmark 论文,不训练新模型)
- 训练细节: N/A
- 数据集: 369 Ubuntu tasks + 43 Windows supplementary tasks 全部公开,含 task config + eval script;verified trajectories 上传 HuggingFace(
xlangai/ubuntu_osworld_verified_trajs);8 个 Google Drive 任务受网络限制可选择手动配置或排除(“361-task” 版本官方允许)
Claim 可验证性
- ✅ Human 72.36% vs best model 12.24%:基于 9 位 author 在 max 15 step 限制下的实测,setup 在论文 §3.4 + App. 详述;后续社区在 OSWorld-Verified 上的复现结果(多家机构 cross-check)支持这一 gap 真实存在
- ✅ 134 unique eval functions:可直接在 repo 中数 eval script
- ✅ A11y tree 翻倍 success rate:Tab. 5 多模型上一致体现,可独立复现
- ⚠️ “primarily struggling with GUI grounding and operational knowledge”:作为 main finding 的归因主要靠 §5.2/5.4 的定性 case study,缺乏量化的 error taxonomy 分布;“GUI grounding” 和 “operational knowledge” 也没有严格定义可测的边界
- ⚠️ SoM 在 desktop 反而下降的原因(高分辨率 + 元素密集):是合理推测但未做 controlled ablation 验证
- ⚠️ Infeasible task 检测能力 (16.67% vs 13.34%):作者自己承认部分是 agent 倾向输出
FAIL的 false positive,结论需要打折 - ❌ “first-of-its-kind scalable, real computer environment”:作为定位话术合理,但 “first” 这个 claim 严格说取决于如何定义边界(AssistGUI / ScreenAgent 也涉及 desktop,只是不跨 OS / 不 execution-based);这是 framing 而非可验证的技术 claim
Notes
- OSWorld 的真正贡献不在”第一个真实 OS env”,而在把 134 个 example-specific eval 当成基础设施投入——这是 open-ended task 评测可信的前提,也是后续 benchmark 难绕开的护城河
- 12.24% 这个数字非常重要:它把 “computer-use 看起来快解决” 拉回 “远未解决”,并明确指出两个具体的 attack surface(grounding + operational knowledge),后续工作的 RoI 高
- VM-based + per-step VM↔host 通信 → throughput 对 RL training 是 real bottleneck。后续的 ComputerRL、UI-TARS-2 都需要用各种工程 trick(并行 VM pool、frame skipping)来 amortize
- OSWorld-Verified (2025-07) 的存在说明 benchmark 维护与初版同样重要——8 个 Google Drive 任务的 fix、AWS 支持 (eval time → 1h)、verified leaderboard 是让 benchmark “活着” 的关键
- 一个值得思考的开放问题:当 agent 性能从 12% 提升到 50%+ 后,OSWorld 这类 “max 15 step / single attempt” 的评测设计是否仍能区分模型?是否需要专门的 long-horizon / error recovery / multi-session benchmark?
-
❓ 对照 OSWorld-Verified 的最新 leaderboard 数据,看 specialized model(如 UI-TARS)vs general model(如 Claude computer-use)vs agentic framework 三种 paradigm 各自的 ceiling,可能是判断 “computer-use 该往哪走” 的最直接证据
Rating
Metrics (as of 2026-04-24): citation=593, influential=99 (16.7%), velocity=24.30/mo; HF upvotes=52; github 2807⭐ / forks=447 / 90d commits=62 / pushed 6d ago
分数:3 - Foundation 理由:OSWorld 已是 computer-use / GUI agent 方向事实上的标准评测——后续主线工作(UI-TARS / UI-TARS-2、Agent-S2、OS-Atlas、ComputerRL、WindowsAgentArena)均以它为主评测或直接扩展,GUI Agent Survey / OS Agents Survey 也把它列为 de facto benchmark(见 Strengths-2/5 与「后续影响」列表)。相比 Frontier 档的 Benchmark 2(“有一定使用量、尚未定型”),OSWorld 已经跨过 adoption 门槛并被持续维护(OSWorld-Verified 2025-07);12.24% vs 72.36% 的 gap + 134 个 example-specific eval 的护城河使其短期内难被取代,因此计入 Foundation 而非 Frontier。