Summary
Large Language Model-Brained GUI Agents: A Survey
- 核心: 系统综述 LLM-brained GUI agent 的演化、组件、框架、数据、模型、benchmark 与应用,并以 8 个 RQ 为主线给出”从零搭建”的 cookbook
- 方法: 按 perception → prompt → inference → action → memory → advanced enhancements 拆解 agent 架构;横向跨 web / mobile / desktop / cross-platform 四类平台对比 framework / data / LAM / benchmark
- 结果: 形成一份持续维护(v8, 2025-05)的 taxonomy 与文献清单,配 searchable 网页与 GitHub 仓库
- Sources: paper | website | github
- Rating: 2 - Frontier(GUI agent 领域最全面的 living cookbook-style survey,是当前入门与文献定位的重要参考;但批判性弱、数据层面 meta-analysis 缺失、尚未成为必引奠基工作,不到 Foundation 档)
Key Takeaways:
- 8 个 RQ 的 cookbook 视角:作者把 GUI agent 拆成 perception / prompt / inference / action / memory 五段标准流水线,每段都给 design choice 与代表工作,是新人系统入门的好脚手架。
- 平台维度比技术维度更主导分类:framework / data / model / benchmark 四章都按 web / mobile / desktop / cross-platform 切,反映 GUI 领域的”碎片化”是首要矛盾——跨平台统一接口和统一动作空间是当前最大的工程瓶颈。
- 方向分流:(a)Pure-vision 路线(OmniParser、UGround、AGUVIS)追求消除对 a11y tree 的依赖;(b)Multi-agent + self-reflection(UFO、Reflexion)追求长程鲁棒;(c)RL 路线(DigiRL、DistRL、UI-R1、GUI-R1)开始把 GUI 任务正式视为 MDP。
- 挑战清单偏 system 而非 modeling:privacy、latency、safety、human-agent shared control、personalization、scalability——大多需要”系统级”协议(permission、rollback、virtual desktop、native API exposure),而不只是更大模型。
- survey 本身是 living document:v1 → v8 跨度半年,配 searchable site 与持续更新的 GitHub paper list;适合作为 GUI agent 文献入口的 index 而非定型 reference。
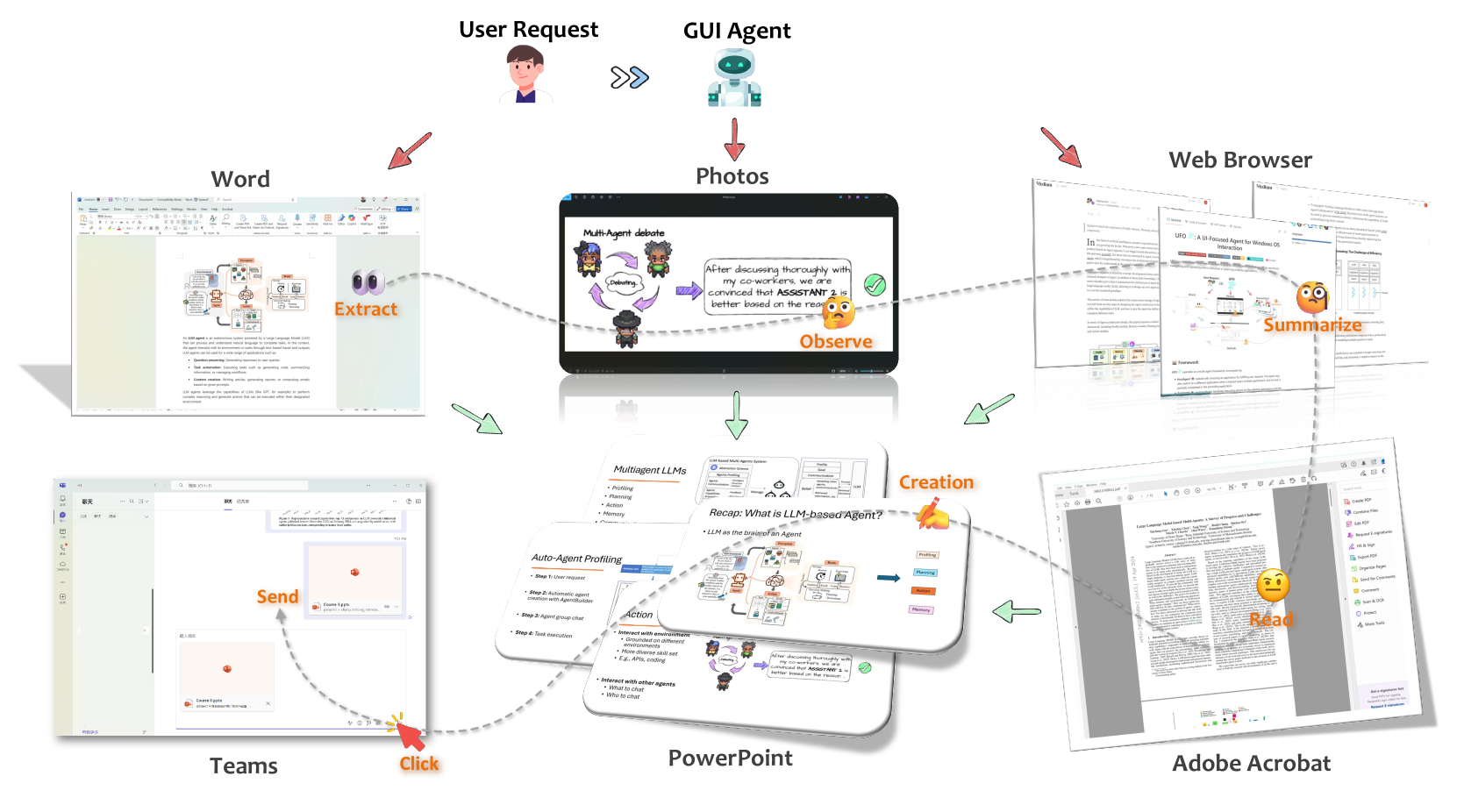
Teaser. Figure 1 — LLM-powered GUI agent 的高层概念:用户用一句自然语言串起 Word / Photos / Browser / Acrobat / PowerPoint / Teams 多个应用,agent 在 GUI 层面跨应用编排执行。
Section 4: Evolution & RQ 框架
作者把 GUI 自动化的演化划分为三波:(1) 早期 random / rule-based / script-based 自动化(AutoIt、Sikuli、Selenium);(2) ML/CV/NLP 引入后的 intelligent agent;(3) LLM-brained agent 的崛起,分别覆盖 web(SeeAct)、mobile(AppAgent)、computer(UFO)和 industry models。
特别讨论 GUI agent vs API-based agent:API-based 依赖应用主动 expose 接口,覆盖面有限;GUI agent 通过”通用人机界面”操作,non-intrusive,可以在没有 API 的遗留软件上运行。这是把 GUI 当作 universal action interface 的核心论据。
❓ 这种二分其实正在模糊:现在的 GUI agent 大多 hybrid(UI ops + native API + AI tools 混用,见 §5.5),单纯的 “pure GUI” agent 反而少。survey 把 hybrid 列为单独类目(Hybrid Agent、AutoWebGLM)是合理的。
Section 5: 组件与 Cookbook
5.1 Workflow
Figure 5. Architecture overview — User request → Environment perception → Prompt construction → LLM inference → Action execution → Memory update → loop。
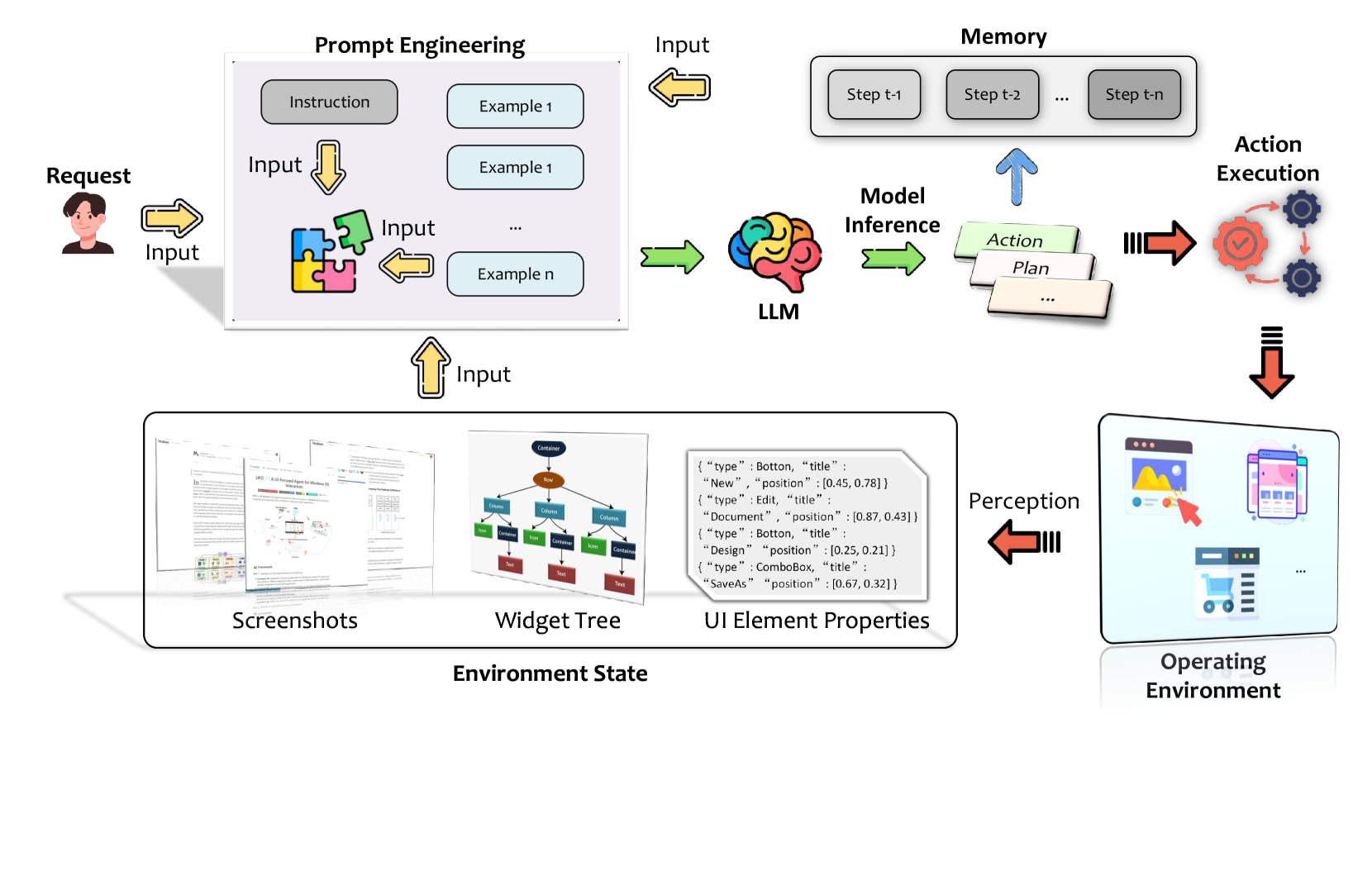
Table III. 平台特性对照
| 平台 | 主要挑战 | 动作空间 | 典型任务 |
|---|---|---|---|
| Mobile | 屏幕受限、触摸/手势、原生 vs 混合 app、a11y framework、权限 | tap/swipe/pinch、虚拟键盘、in-app navigation、硬件访问(摄像头、GPS) | 登录表单、消息/社交、地图、push/permission |
| Web | 动态布局、AJAX、HTML/DOM、跨浏览器差异 | click/hover/scroll、DOM 表单、链接导航、JS 事件 | 表单注册/结账、爬取、搜索筛选、多步导航 |
| Computer | OS-level 接口、多窗口、Win UI Automation、频繁更新 | 鼠标拖拽、键盘快捷键、菜单/工具栏、多窗口 | 文件管理、办公套件、安装卸载、跨应用工作流 |
5.2 Operating Environment
四类感知通道:
- GUI screenshots:捕获布局与图标信息;可叠加 Set-of-Mark(SoM)或 bounding box 标注降低 grounding 难度
- Widget trees:层次化结构(Win UI Automation、macOS Accessibility API、Android Accessibility API、HTML DOM),直接给出元素 type/role/label
- UI element properties:control type / label / position / bbox,用于精确定位
- Complementary CV:当 a11y 不可用或不全时用 OCR + SAM / DINO / OmniParser 兜底
Figure 7. VS Code 三种 screenshot 表征 — clean、SoM、bounding box 标注的对比。
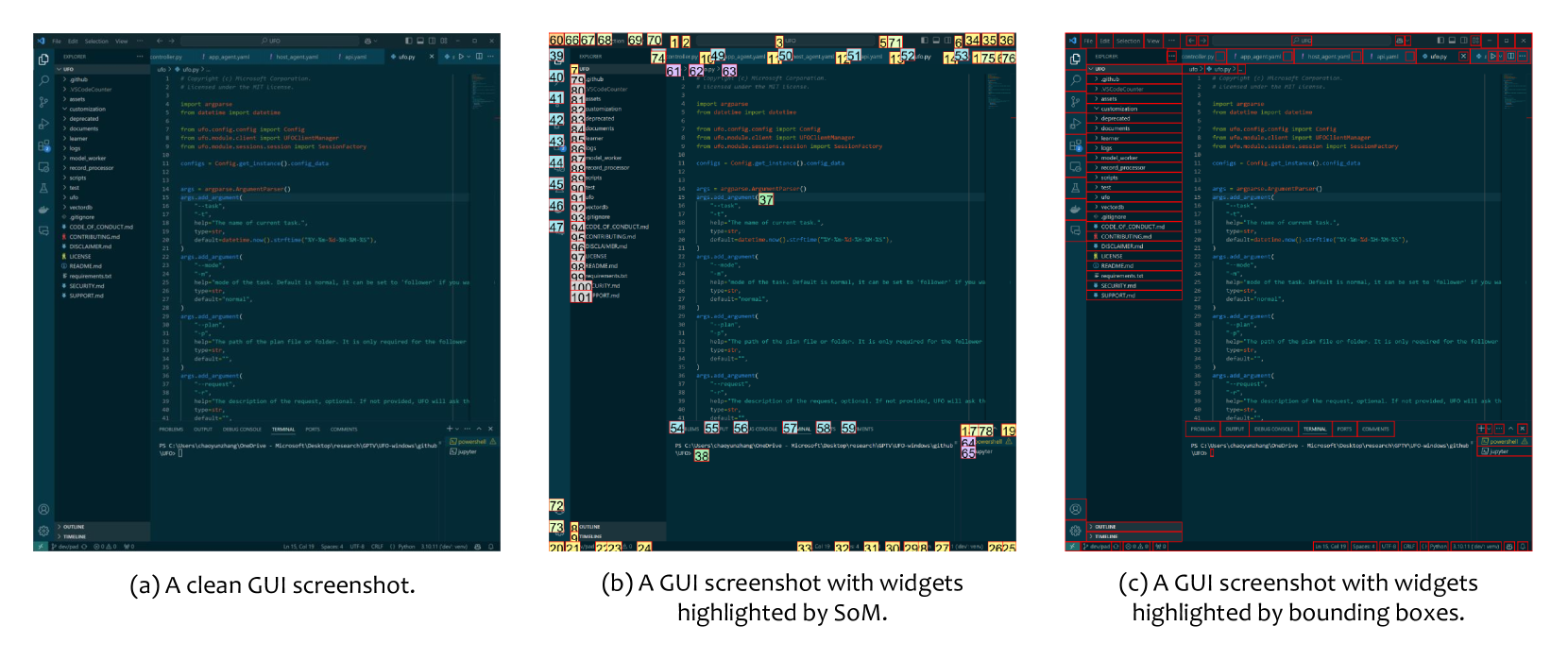
Figure 10. CV-based 解析 PowerPoint — 标准 a11y 抓不到的 thumbnail / canvas 元素,CV parser 能识别并推断 type/label。

Environment feedback 三类:screenshot diff、UI structure change、function return / exception。这些信号是 self-reflection 与 RL reward 的基础。
5.3 Prompt Engineering
Prompt 六段式:User Request、Agent Instruction、Environment States(多版本截图)、Action Documents、Demonstrated Examples(ICL)、Complementary Information(RAG / memory)。
❓ 这个划分是经验综合,没有”必须六段”的硬性证据;多数开源 agent 实际 prompt 都更短,且 action document 常以 function-calling schema 注入而非自由文本。
5.4 Model Inference
分 planning / action inference / complementary outputs。Planning 强调 hierarchical(global subgoal + local step),可借助 CoT 与 plan caching。Action 通常以 function-call string 表示,便于直接转成 UI op / API call。
5.5 Actions Execution
三大类:
- UI Operations:鼠标/键盘/触摸/手势/语音/剪贴板(platform-specific toolkit:Pywinauto、Appium、Selenium 等)
- Native API Calls:shell command、application API(Office COM、Android/iOS SDK)、system API、Web API
- AI Tools:调 DALL·E / OpenAI APIs 做摘要、图像生成等”非 UI”操作
把 native API 与 AI tool 显式纳入 GUI agent 动作空间是务实的——否则 “pure GUI” 在长程任务上效率太低。问题转化为 何时该 fallback 到 API——目前还没有可学到的策略。
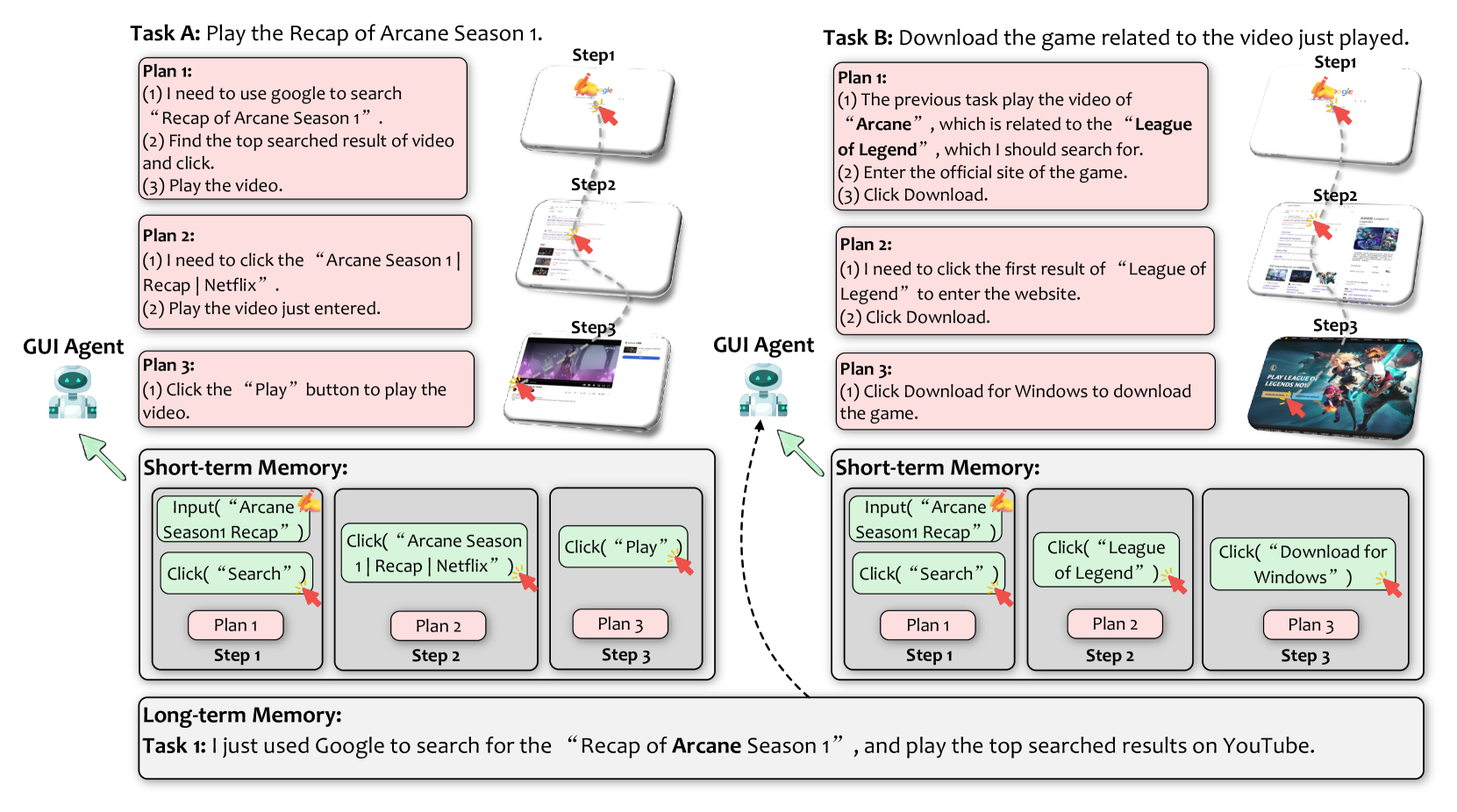
5.6 Memory
Figure 14. STM vs LTM — STM 装 action / plan / execution result / env state,存活在 context window;LTM 装 self-experience / self-guidance / external knowledge / task success metrics,落到 DB/disk,靠 RAG 检索。
LTM 是连接”单 episode agent” 与 “lifelong learning agent” 的关键,但 survey 也承认目前 LTM 大多停在 trajectory storage + naive retrieval,离真正的 self-improvement 还有距离。
5.7 Advanced Enhancements
五个增强方向(作者强调彼此不互斥,可叠加):
- CV-based GUI grounding:用 OmniParser / UGround / Aria-UI / SAM / DINO 直接从 screenshot 出 element 列表与 bbox。表 VII-IX 列了十余个 grounding 模型(OmniParser、UGround、Aria-UI、Iris、AGUVIS、SeeClick、ScreenSpot/-Pro 等)。
- Multi-Agent:specialization + collaboration(UFO 的 HostAgent + AppAgent、MMAC-Copilot 等)。
- Self-Reflection:ReAct 与 Reflexion 是两条主线——前者把反思嵌进每一步 reasoning,后者用语言形式 feedback 跨 episode 迭代。
- Self-Evolution:从 task trajectory 抽 demonstration / rule / new toolkit,回写到 LTM 与 fine-tuning 数据。
- Reinforcement Learning:把 GUI 任务建模为 MDP(state=screenshot+UI props, action=UI op/API, reward=task success/efficiency)。代表工作:DigiRL(offline→online RL on Android)、DistRL(异步分布式 RL fine-tune mobile agent)、UI-R1 / GUI-R1 / InfiGUI-R1(rule-based reward + o1-style 推理)。
Figure 18. MDP modeling for GUI task — state / action / reward 的具体定义示例。
❓ Self-evolution 与 RL 在概念上高度重叠——survey 把 self-evolution 分到 “trajectory + rule + toolkit” 三种 artefact,更偏 in-context;RL 则强调参数更新。但实际工作(如 UI-R1)已模糊这条界线。
Section 6: Frameworks(按平台)
按 web / mobile / computer / cross-platform 列代表 framework:
- Web:SeeAct、WebVoyager、Mind2Web、AutoWebGLM、Hybrid Agent
- Mobile:AppAgent、Mobile-Agent、AutoDroid
- Computer:UFO(Windows)、OS-Copilot、Cradle
- Cross-platform:AutoGLM、OSCAR
§6.5 Takeaways:(1) multi-agent 协同;(2) 多模态输入收益明显;(3) 动作空间扩展到 API + AI tool;(4) world model(WMA)+ search(best-first / MCTS, Search-Agent)开始进入决策层;(5) 跨平台框架兴起;(6) pure-vision agent 成为通用控制方向(AGUVIS),但 grounding 是瓶颈。
Section 7: Data
§7.1 Collection pipeline:Composition(task instruction、UI state、action trajectory、metadata)+ pipeline(human annotation、LLM-augmented synthesis、自动 record-replay)。各平台代表数据集:
- Web:Mind2Web、VisualWebArena task data
- Mobile:Android in the Wild (AITW)、AITZ、MobileViews
- Computer:ScreenAgent、UFO traces、ScreenAI
- Cross-platform:VisualAgentBench、GUI-World、xLAM unified format
§7.6 Takeaways:scale & diversity / cross-platform / 自动数据采集 / 统一 data format(xLAM)是四大趋势。
Section 8: Models (LAMs)
把”为 GUI 优化的 LLM”统称为 Large Action Model (LAM)。foundation 端涵盖 closed (GPT-4V/o, Claude, Gemini) 与 open (Qwen-VL, LLaVA-NeXT, InternVL, Phi-3.5-V) 两路。
按平台列代表 LAM:
- Web LAM:WebLLaMA、AutoWebGLM、SeeClick
- Mobile LAM:CogAgent、MobileVLM、Iris
- Computer LAM:UFO 内置 LAM、OS-Atlas、ShowUI
- Cross-platform LAM:xLAM、UI-TARS、AGUVIS
§8.7 Takeaways:(1) 1B–7B 小模型支持端侧推理;(2) visual grounding 训练降低对 a11y 的依赖;(3) RL 桥接静态训练与动态环境;(4) 统一 function-calling 提升互操作性;(5) inference-time computing + o1-style reasoning(UI-R1/GUI-R1/InfiGUI-R1)开始进入 GUI 领域。
Section 9: Evaluation
§9.1-9.2 Metrics & measurements:step success rate、task success rate、efficiency(steps、time、token cost)、grounding accuracy(IoU、point-in-bbox)、completion under policy (CuP)。
§9.3 Platforms:browser sandbox(WebArena、VisualWebArena)、Android emulator + Docker(AndroidWorld、Mobile-Env)、Windows VM(OSWorld、WindowsAgentArena)。
§9.4-9.7 Benchmarks(按平台):
- Web:Mind2Web、WebArena、VisualWebArena、WebVoyager benchmark
- Mobile:AITW、AndroidWorld、A11yArena
- Computer:OSWorld、WindowsAgentArena、ScreenAgent
- Cross-platform:VisualAgentBench、GUI-World、CRAB
§9.8 Takeaways:从合成 → 交互式真实环境的趋势;跨平台 benchmark 但缺统一接口;多轮 / 对话化任务增多;scalability 仍靠人工;safety/privacy/compliance 维度开始被纳入评估。
Section 10: Applications
两大类落地:
- GUI Testing:general testing、text input generation、bug replay、verification
- Virtual Assistants:research(UFO, Cradle)、open-source(OpenAdapt, Open Interpreter)、production(Microsoft Copilot, Power Automate, Anthropic Computer Use, OpenAI Operator)
Section 11: 挑战与 Roadmap
八个开放问题(每个都强调 “GUI agent-specific,不是通用 LLM 问题”):
- Privacy:sensitive screenshot/credential 必须经云端推理 → on-device inference + 模型压缩 + 联邦学习 + 差分隐私
- Latency / Resource:长程多步使延迟累积,端侧资源受限 → 蒸馏、量化、incremental inference、native API expose 减少 step 数
- Safety / Reliability:action 不可逆(误删文件、误转账) → action validation、formal verification、rollback、permission management、对抗鲁棒
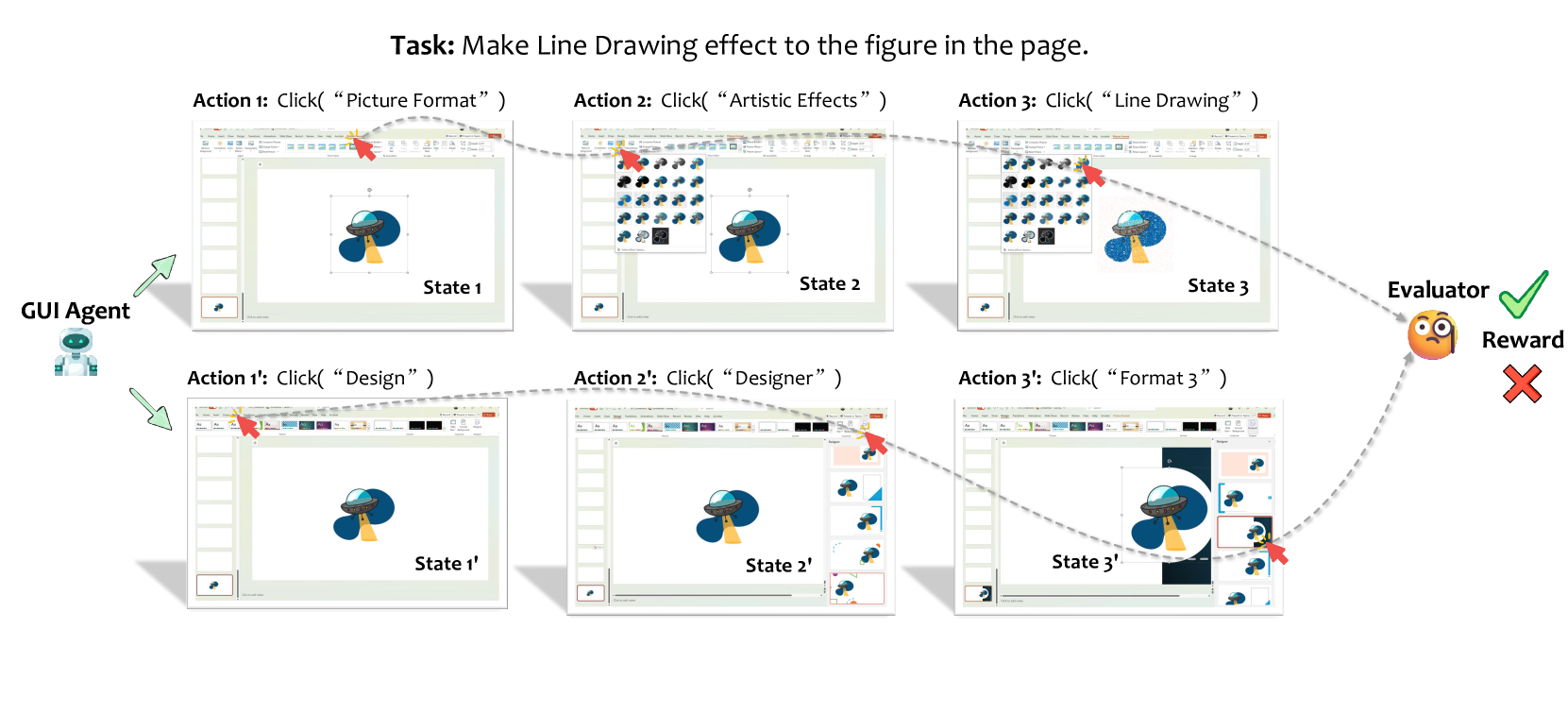
- Human-Agent Interaction:用户与 agent 共享同一 GUI,必然冲突 → clarification dialogue、human-in-the-loop、virtual desktop(UFO² 的 picture-in-picture)。Figure 32 展示了 UFO² 的 PIP 虚拟桌面:
- Customization & Personalization:编辑风格、命名习惯需要纵向学习 → user modeling、preference learning、on-device RLHF
- Ethics & Regulation:bias 在多应用链路上更难审计 → 审计日志、bias mitigation、regulatory framework
- Scalability & Generalization:UI 频繁变更(A/B 测试、版本升级)会击穿训练好的 agent → 大规模多样化数据 + transfer/meta-learning + RAG over docs
- §11.8 Summary:需要研究者、工业界、监管者、用户协同。
关联工作
同类 survey
- World Model Survey:另一类长综述,可对比 survey 写作风格——本作偏 cookbook/工程导向,World Model Survey 更偏理论/范式
- 其他 GUI agent / LLM agent survey(§2 引用):本作的差异化在 cookbook 视角与 desktop/Windows 第一手经验
核心组件相关
- Grounding: OmniParser、SeeClick、UGround、Aria-UI、ScreenSpot
- Set-of-Mark prompting: 通过视觉标注降低 LLM grounding 难度
- Self-Reflection: ReAct、Reflexion
- CoT planning: Chain-of-Thought
- RL for agent: DigiRL、DistRL;rule-based reward 后续被 UI-R1 / GUI-R1 / InfiGUI-R1 推进
代表性 GUI Agent
- Web: SeeAct, WebVoyager, Mind2Web, AutoWebGLM
- Mobile: AppAgent, Mobile-Agent, Android in the Wild data
- Desktop: UFO (作者团队)、OS-Copilot、Cradle
- Cross-platform: AGUVIS、UI-TARS、xLAM、VisualAgentBench
Foundation models
- 闭源:GPT-4V/o、Claude(含 Computer Use)、Gemini
- 开源:Qwen-VL、LLaVA-NeXT、InternVL、Phi-3.5-V
与 vault 已有方向的连接
- DomainMap: CUA:本 survey 是 CUA domain map 的天然 reference,可作为 entry point
- 与 World Model Survey 平行——两者都是”先 cookbook 再 roadmap”风格
论文点评
Strengths
- 覆盖全面、组织清晰:8 个 RQ 串起从历史到挑战的整条 pipeline,平台 × 维度二维切分让读者能横向对比。表格密度高(abbreviation、environment toolkits、actions、memory、grounding model 等),实用价值强。
- 作者背景的 implicit advantage:作者团队来自 Microsoft(UFO 团队),对 desktop/Windows GUI agent 的细节、UI Automation API、Office/COM 接口有第一手经验,这是别的 survey 难以触及的 angle。
- Living document:从 v1 (2024-11) 到 v8 (2025-05) 持续更新,配 searchable site + GitHub paper list,把 survey 当 maintained taxonomy 而不是一次性发表,符合 GUI agent 这种快速演化领域的需求。
- 明确把 GUI agent 与 API agent 区分:给出”non-intrusive、universal”的论据,澄清了为什么 vision-based path 仍有价值(即便 API 路径短期效率更高)。
- Roadmap 部分务实:privacy / safety / shared control / personalization 这些”系统层”挑战常被纯 modeling 视角的 survey 忽略,本作把它们抬到与 modeling 同等地位。
Weaknesses
- 批判性弱:典型 survey 通病——大量”X works are introduced”句式,缺乏对方法间 trade-off 的尖锐对比。例如 pure-vision vs hybrid (vision+a11y) 在哪类任务上差距最大、grounding model 的真实 ceiling 在哪、self-reflection 是否真的 generalize,都没有给出 evidence-based 判断。
- 数据驱动的 meta-analysis 缺失:没有跨 benchmark 把同一 agent 的成功率拉成统一表,读者难以快速判断 SOTA。grounding 章节列了十余个模型却没给统一 ScreenSpot 上的对比数。
- 平台维度切分过重,方法维度被打散:同一种方法(如 RL、self-reflection)在 web/mobile/desktop 章节里反复出现,分散讨论削弱了对方法本质的洞察。可考虑加一个”方法 × 平台”矩阵图。
- 概念边界模糊:self-evolution / lifelong learning / RL / continual fine-tune 之间的区分写得含糊;LAM 与”普通 fine-tuned VLM” 的边界也没有严格定义——任何在 GUI 数据上 SFT 的 VLM 都被收为 LAM。
- 更新速度仍跟不上:v8 (2025-05) 已不能覆盖 2025 下半年到 2026 的 RL agent 浪潮(如更近期的 Qwen3-VL agentic-RL、UI-TARS 后续、GLM-4.5V agent 等),现在再读需要自己补 delta。
可信评估
Artifact 可获取性
- 代码: 仓库为综述本身的 paper list 与 searchable site 代码(非 agent 实现);不涉及”训练/推理”
- 模型权重: 不适用
- 训练细节: 不适用
- 数据集: 不适用;但 survey 内列出的 Mind2Web / AITW / VisualAgentBench / OSWorld 等数据集均开源(详见 §7、§9)
Claim 可验证性
- ✅ “GUI agent 已在 web/mobile/desktop 多平台出现成熟 framework”:每个 framework 都给了引用与 link,可逐项验证
- ✅ “OmniParser 显著提升 GPT-4V 屏幕理解”:可在 OmniParser 论文与 ScreenSpot benchmark 上独立复现
- ⚠️ “1B-7B 小模型已可端侧推理”:依赖具体硬件;survey 未给出统一 latency 数据
- ⚠️ “Multi-agent 显著优于 single-agent”:举的都是 anecdotal example(UFO、MMAC-Copilot),缺 controlled ablation
- ⚠️ “Self-evolution 让 agent 持续改进”:所引工作多为短期实验,长期 lifelong 收益未被严格验证
- ✅ 整体无明显 marketing 话术(survey 体裁 claim 较保守);本节 无 ❌
Notes
- 使用建议:作为 GUI agent 文献的 入口 index,不要当 reference 死读。需要找特定 framework / benchmark / dataset 时再回查具体表格。
- 后续要补的 delta(survey v8 之后):UI-TARS 后续版本、GLM-4.5V agent、Qwen3-VL agentic-RL、Anthropic 与 OpenAI 的 computer-use 在更新版本上的能力曲线。
- 可借鉴的写作结构:8 RQ 串联 + 平台 × 维度二维表格 + cookbook + roadmap 的组织方式,对未来如果要写 VLA 或 spatial-intelligence 的 survey 是好的模板。
- 可挖掘的研究 gap:(1) “何时 fallback 到 API” 的可学策略;(2) self-evolution 与 RL 的统一框架;(3) 跨平台统一 action space / interface protocol;(4) GUI 版本漂移的 robust adaptation——所有这些都符合 survey roadmap 的走向,且有 measurable benchmark 切入点。
Rating
Metrics (as of 2026-04-24): citation=156, influential=5 (3.2%), velocity=9.23/mo; HF upvotes=30; github 229⭐ / forks=15 / 90d commits=0 / pushed 305d ago · stale
分数:2 - Frontier 理由:本作是当前 GUI agent 领域覆盖最全、结构最完整的 cookbook-style living survey(v1→v8,配 searchable site + GitHub paper list),在 Strengths 中体现为 “8 RQ pipeline + 平台 × 维度二维切分 + Microsoft/UFO 团队的 desktop 第一手经验”,足以作为方向入门 index 和文献定位重要参考,因此高于 Archived。但 Weaknesses 指出其批判性弱、数据层 meta-analysis 缺失、方法维度被平台切分打散,且 v8 后的 2025H2–2026 RL agent 浪潮未覆盖,并未像 ImageNet/DROID 级工作那样成为方向必引奠基,所以不到 Foundation——停在 Frontier 档是更准确的定位。