Summary
UI-TARS-2 Technical Report: Advancing GUI Agent with Multi-Turn Reinforcement Learning
- 核心: 在 UI-TARS-1.5 基础上,构建一套数据飞轮 + 多轮 RL + GUI/SDK 混合环境 + 沙箱基础设施的”全栈”训练方法,把单一 GUI 智能体扩展为可同时驾驭 GUI、终端、文件系统、游戏的统一计算机使用 agent。
- 方法: Seed-thinking-1.6 (532M ViT + 23B/230B MoE) → CT/SFT/RL 飞轮迭代;多轮 PPO + Decoupled-GAE + Length-Adaptive GAE + Value Pretraining + Clip-Higher;垂直 agent 通过参数插值合并。
- 结果: OSWorld 47.5、WindowsAgentArena 50.6、AndroidWorld 73.3、Online-Mind2Web 88.2;15 款游戏均一化得分 59.8(约人类 60%);带 SDK 时 SWE-Bench 68.7、TerminalBench 45.3。
- Sources: paper | github
- Rating: 2 - Frontier(当前 GUI agent SOTA 技术报告,全栈披露训练+infra 对业界参考价值高,但模型权重未开源、核心 claim 缺实证,尚未达到 foundation 层级)
Key Takeaways:
- Data Flywheel as the central scaling lever:CT/SFT/RL 三阶段不是一次性 pipeline,而是闭环——每轮 RL 模型都用 rejection sampling 生新轨迹,high-quality 轨迹被推到下一轮 SFT,low-quality 推回 CT,论文把”数据稀缺”这件事系统化解决,而不是依赖一次性大规模标注。
- Hybrid GUI environment 是 GUI agent 的真正可用形态:纯 GUI 操作做不了软件工程、终端管理这类任务。把 file system / terminal / MCP tool 与 screenshot+click 同构于一个 sandbox,BrowseComp-en 直接从 7.0 (GUI-only) 跃升到 29.6 (with SDK)。
- PPO + 多项稳定化技巧 > GRPO:在多轮 agent RL 里,作者明确报告 PPO 优于 GRPO(Figure 12),并把 VAPO/VC-PPO 的几项改造(Decoupled-GAE、Length-Adaptive GAE、Value Pretraining、Clip-Higher)系统集成。这与近期 reasoning-RL 圈普遍采用 GRPO 的潮流形成对照。
- Asynchronous + Streaming rollout 解决长尾问题:传统 batch rollout 要等最慢轨迹结束才能 train;UI-TARS-2 用动态 rollout pool,未完成轨迹保留到下一轮,避免长尾拖累训练吞吐——这与 Kimi-Researcher 思路一致。
- Parameter interpolation 合并垂直 agent:在 GUI-Browsing / GUI-General / Game / GUI-SDK 各自 RL 微调后,简单线性插值参数(共享 SFT 起点)即可合并能力,几乎不掉点;作为 hybrid RL 的廉价替代方案。
- GUI-RL 的反常熵动力学:与 reasoning-RL 训练时 entropy 单调下降不同,GUI/Game RL 训练中 entropy 反而上升,表明 agent 在持续扩展探索空间——视觉丰富的交互环境需要持续的策略多样性。
Teaser. UI-TARS-2 在真实任务中的轨迹示例——一个完整的 ReAct 循环(thought / action / observation)跨 GUI、终端、文件系统的演示。
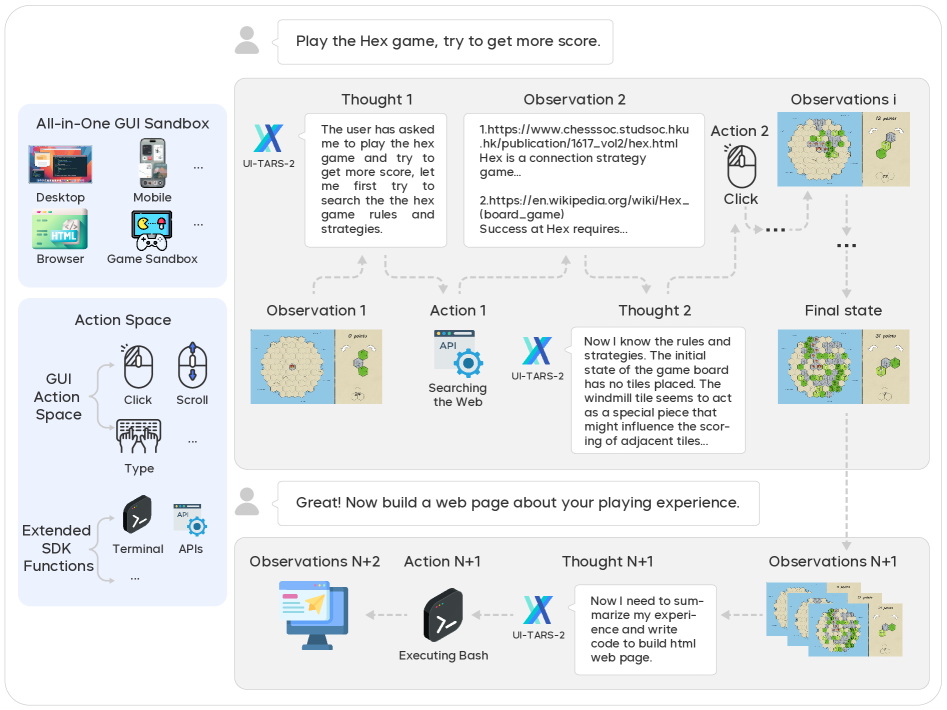
Figure 1: A demo trajectory of UI-TARS-2.
1. 背景与开放问题
GUI agent 从 modular pipeline 走向 native end-to-end agent(UI-TARS、CogAgent、OS-Atlas、Aguvis)后,留下四个开放问题:
- 数据稀缺:与 reasoning/chat 不同,长 horizon GUI 轨迹(含完整 reasoning + action + obs + feedback)几乎无法从公网爬取。
- 可扩展的多轮 RL:sparse/delayed reward + 长 sequence credit assignment + 训练不稳定。
- 纯 GUI 操作的局限:很多真实工作流通过 file system / terminal 完成更自然。
- 环境的工程稳定性:rollout 必须 reproducible、fault-tolerant、能并发跑数百万 episode。
UI-TARS-2 用 Data Flywheel + 多轮 RL 框架 + Hybrid GUI Sandbox + Unified Sandbox Platform 四根支柱回应这四个问题。
2. 方法
2.1 Formulation:ReAct + 分层记忆
agent 在每个 timestep 走 ReAct 循环 :reasoning → action → observation。trajectory 长度 的轨迹:
记忆是分层的:
- Working Memory :保留最近 步原始信息(高保真)
- Episodic Memory :对历史 episode 的语义压缩摘要(保留 intention + outcome)
策略只 condition 于最近 步 + episodic summary:
action space 包含两类:GUI Actions(click/type/scroll,与 UI-TARS 一致;游戏复用同一组原语)和 Pre-defined SDK Functions(terminal commands、MCP tool calls)。
2.2 All-in-One Sandbox
核心是共享文件系统:GUI agent 可以浏览器下载文件,紧接在同一容器里用 shell 处理。
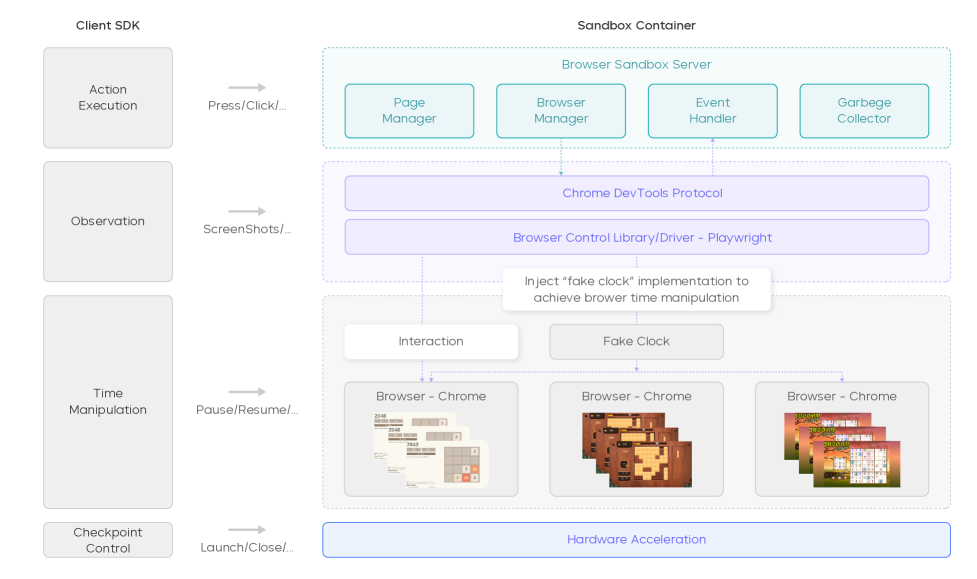
GUI Env (Cloud VM):基于数千实例的 VM 集群,跑 Windows / Ubuntu / Android,PyAutoGUI + ADB,VM Manager 支撑数千 QPS。session ID 维持 state 一致性,VNC/RTC 实时可视化,lease-based lifecycle 自动回收资源。集成 VS Code Remote / Jupyter / 终端预览,proxy URL 暴露 terminal 启动的 service 给 GUI 浏览。
Game Env (Hardware-Accelerated Browser Sandbox):HTML5/WebGL mini-game 必须在浏览器里跑。每容器多浏览器实例 + 弹性调度 + 自动崩溃恢复。GPU 加速截图 + 重写 Window timing API 实现 time acceleration / pause-at-startup(提升采样效率而不动 game logic)。
Figure 2. Browser sandbox (container) 架构
2.3 Data Flywheel
从 Seed1.6 起步,三阶段闭环:
- CT (Continual Pre-training):广覆盖知识,agent-specific 数据占比小
- SFT:高质量 task-specific instruction tuning,agent 数据占主体
- RL:在 verifiable interactive task 上 end-to-end 优化
每轮 iteration:当前 RL 模型 生成新轨迹 → 验证函数 打分 → 加入下轮 SFT 数据集, 加入下轮 CT 数据集。SFT 和 RL 比 CT 跑得更频繁。作者声称随迭代 单调上升,capability growth 加速。
Figure 3. Data Flywheel:模型 ↔ 数据共同演化
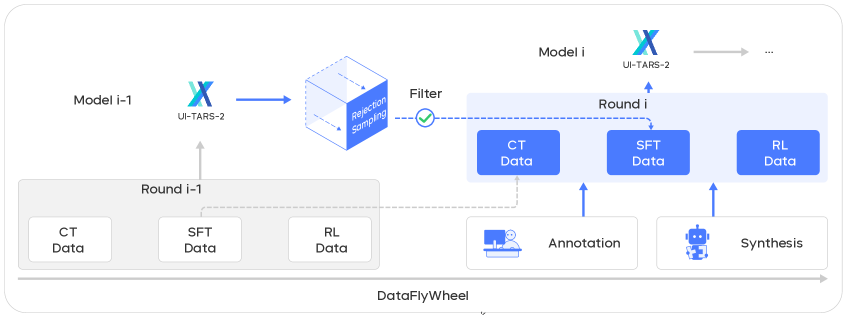
❓ 论文没给” 随 iteration 单调上升”的实证曲线,只用一句话定性陈述。这是飞轮成立的关键经验性 claim,缺图缺数据。
2.3.1 In-Situ CT Annotation
冷启动 CT 数据 = UI-TARS 全部数据 + 在线教程 + open-source agent traces。两个限制:(1) 公开数据极易耗尽,中文应用尤其稀缺;(2) 大多数据只有 procedural action 没有 cognitive reasoning。
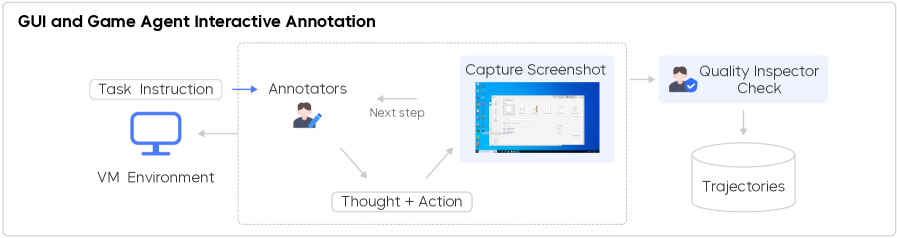
解决方案:annotator 电脑上直接安装 annotation tool,背景运行不打扰日常使用。采用 think-aloud protocol:annotator 一边操作一边语音说出思考,自动对齐到 UI 交互。两类标注员:expert(演示复杂任务)+ novice(用 trial-and-error 探索陌生任务,捕获 problem-solving 过程)。ASR + LLM 对语音 → 高质量 reasoning text,与 action 时间对齐。
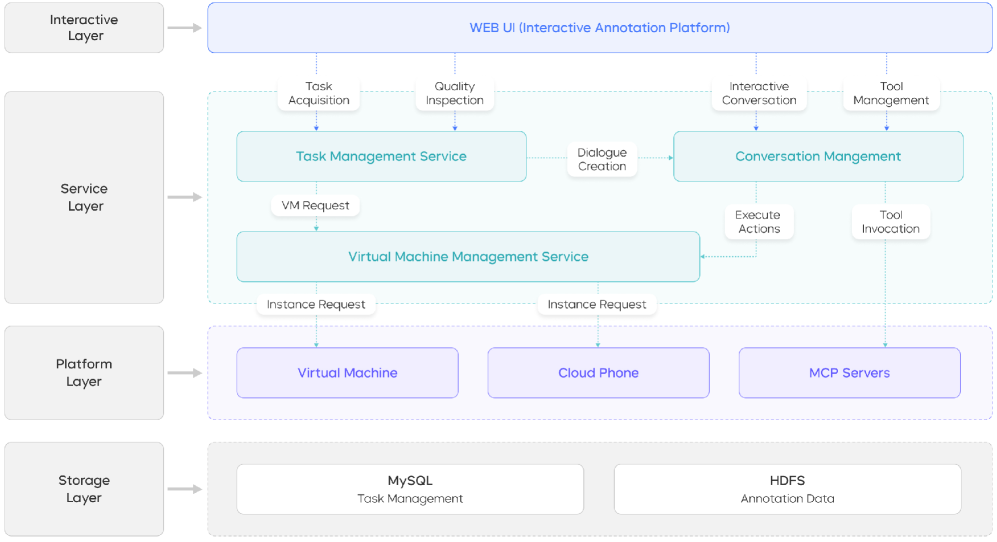
2.3.2 Interactive SFT Annotation
prior work 让 annotator 修改预收集轨迹是 off-policy 的,模型训出来在 rollout 时遇到自己的错误依然不会处理。UI-TARS-2 的方案:human-in-the-loop 在 live VM/browser sandbox 里标注:agent 提出 candidate action + reasoning trace,annotator 接受或 override。所有 supervision 严格 on-policy。
Figure 4. 四层 annotation platform(Interaction / Service / Platform / Storage)+ Figure 5. Interactive 工作流
2.4 Multi-turn RL
构建 RLVR (RL with Verifiable Rewards) 框架,覆盖 GUI-Browsing、GUI-General、Gameplay 三个代表场景。
2.4.1 Task Design
GUI-Browsing(类似 deep research,但只能看 screenshot 不能用 search API):
- Multi-Condition Obfuscation:从 Wikipedia 取实体 + 属性 → LLM 给 distinctiveness 打分 → 删掉高辨识度属性 + 改写其余属性增加抽象度,得到需要多 indirect constraint 推理的题。
- Multi-Hop Chain-Like:从某 entity 页面沿超链追溯链式实体,每一跳 obfuscate 描述构造子问题,最终拼成 multi-hop 综合题。
GUI-General:从公开网站集合中过滤 → VLM 提取 core functionalities → 合成单页面任务,覆盖 690 网站。
Gameplay:公开 HTML5/WebGL mini-game + LLM 合成 game code(暴露明确 state interface)。每个 game 配 JS verifier 查询 runtime variable(score / level / lives),统一 JSON schema 含 reward + termination flag。
2.4.2 Reward Design
- Deterministic verifiable(Game):function-based binary reward
- Reference-matched(GUI-Browsing):LLM-as-Judge
- Open-ended (GUI-General):用 UI-TARS-2 自己作为 generative ORM (Outcome Reward Model),输入完整 text history + 最后 5 张 screenshot,输出 scalar score。通过 targeted annotation + single-turn RL 增强 ORM 能力。
2.4.3 Asynchronous Stateful Rollout
Figure 6. 多轮 RL 训练基础设施
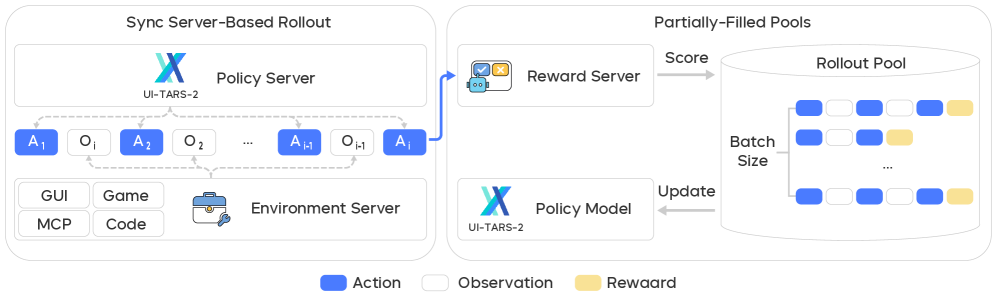
三个关键 design:
- Asynchronous Inference with Server-Based Rollout:把 policy inference 封装成异步 server,解耦 agent interaction handler 与 inference 执行
- Streaming Training with Partially-Filled Rollout Pools:动态 rollout pool,达到最小 batch 即开始 update,未完成轨迹留到下一轮(与 Kimi-Researcher 一致)
- Stateful Agent Environment Integration:跨多次 tool invocation 保持 execution state
2.4.4 RL Training Algorithm
PPO 目标:
四项关键加强(来自 VAPO / VC-PPO / DAPO):
- Reward Shaping:以 final outcome 正确性为主,必要时 format reward + length penalty
- Decoupled GAE:policy 和 value function 用不同 ( vs ),缓解长序列下的 critic value decay
- Length-Adaptive GAE:,,按序列长度动态调 bias-variance
- Value Pretraining:在固定 SFT policy 下用 GAE(, MC return) 离线训 value model 到收敛,再做 RL initialization
- Clip Higher:解耦 和 ,提升 增大对 low-prob action 的探索空间
2.5 Vertical Agent Merging via Parameter Interpolation
直接 joint RL 多域困难(action/state 空间、horizon、rollout 复杂度差异大)。利用同 SFT 起点的模型在参数空间近似线性 mode-connected,独立训各 vertical agent 后线性插值:
。复合任务上 merged model 几乎与各域最优 specialized model 持平。
3. 实验
3.1 Setup
- Backbone: Seed-thinking-1.6 init,532M ViT + 23B active / 230B total MoE LLM
- GUI benchmarks: OSWorld (369 tasks)、WindowsAgentArena (150+)、TerminalBench (75/80)、SWE-Bench、AndroidWorld (116)、Online-Mind2Web (300, 136 sites)、BrowseComp-en/zh
- Game benchmarks: 自家 15 Games Collection (in-domain) + LMGame-Bench (OOD, 6 经典)
- Baselines: Claude 4 (Sonnet/Opus)、OpenAI o3、OpenAI CUA-o3、UI-TARS / UI-TARS-1.5、Gemini-2.5 Pro、Claude 3.7
3.2 GUI Main Results
Table 1. GUI 主结果(† 表示 GUI-SDK 扩展 action space)
| Model | OSWorld | WAA | TB | SB | AndroidWorld | Online-Mind2web | BC-zh | BC-en |
|---|---|---|---|---|---|---|---|---|
| Claude-4-Sonnet | 43.9 | - | 39.2 | 72.7 | - | - | 22.5 | 14.7 |
| Claude-4-Opus | - | - | 43.2 | 72.5 | - | - | 37.4 | 18.8 |
| OpenAI o3 | ✗ | ✗ | 30.2 | 69.1 | ✗ | ✗ | - | 49.7 |
| OpenAI CUA-o3 | 42.9 | - | ✗ | ✗ | 52.5 | 71.0 | - | - |
| UI-TARS | 24.6 | - | ✗ | ✗ | 44.6 | - | ✗ | ✗ |
| UI-TARS-1.5 | 42.5 | 42.1 | ✗ | ✗ | 64.2 | 75.8 | ✗ | ✗ |
| UI-TARS-2 | 47.5 | 50.6 | 45.3 † | 68.7 † | 73.3 | 88.2 | 32.1 (50.5 †) | 7.0 (29.6 †) |
关键观察:
- 全面超越 UI-TARS-1.5(OSWorld +5、WAA +8.5、AndroidWorld +9.1、Online-Mind2Web +12.4)
- GUI-SDK 的杠杆效应:BrowseComp-en 从 7.0 (GUI-only) 跳到 29.6 (+SDK),BrowseComp-zh 从 32.1 → 50.5。SWE-Bench 68.7 接近 Claude-4-Opus 的 72.5。
- OOD 泛化:浏览器为主的 RL 数据训出来的模型,在 OSWorld 提升 10.5 (43.0→47.5)、AndroidWorld 提升 8.7 (64.6→73.3),说明 task-specific RL 诱导出可迁移技能。
3.3 Game Main Results
Table 2. 15 Games Collection(人类=100 归一化,节选)
| Game | Human | UI-TARS-2-SFT | UI-TARS-2-RL | OpenAI CUA | Claude Computer Use |
|---|---|---|---|---|---|
| 2048 | 1024.31 | 968.00 | 932.40 | 911.21 | 800.00 |
| Infinity-Loop | 6.58 | 1.60 | 6.10 | 3.30 | 1.90 |
| Shapes | 5.42 | 4.60 | 5.90 | 0.90 | 0.24 |
| Snake-solver | 3.92 | 2.10 | 3.00 | 0.23 | 0.20 |
| Tiles-master | 3.75 | 3.20 | 3.10 | 1.47 | 1.56 |
| Wood-blocks-3d | 4646.00 | 1900.00 | 2908.00 | 1814.00 | 1632.00 |
| Mean Normalized | 100.00 | 44.27 | 59.77 | 24.73 | 21.61 |
UI-TARS-2-RL 比 OpenAI CUA / Claude CU 高 +35 / +38 点。Shapes 甚至超人类(108.9)。
LMGame-Bench (OOD) 上 UI-TARS-2 与 o3 / Gemini-2.5 Pro 同台竞争(2048: 117.1 vs o3 128.2;Candy Crush: 163.2 仅次 Gemini 177.3,超 o3 106;Super Mario Bros: 1783 vs o3 1955)。Tetris 和 Sokoban 较弱,反映极长 horizon planning 的局限。
3.4 详细分析
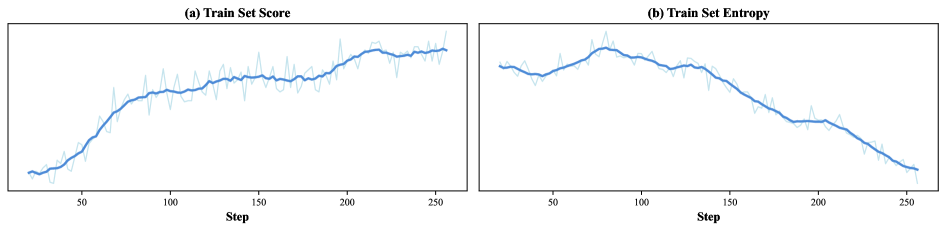
Reward 与 Entropy 动力学
Figure 7. RL 训练 reward 上升趋势(GUI-Browsing / GUI-General / Game)
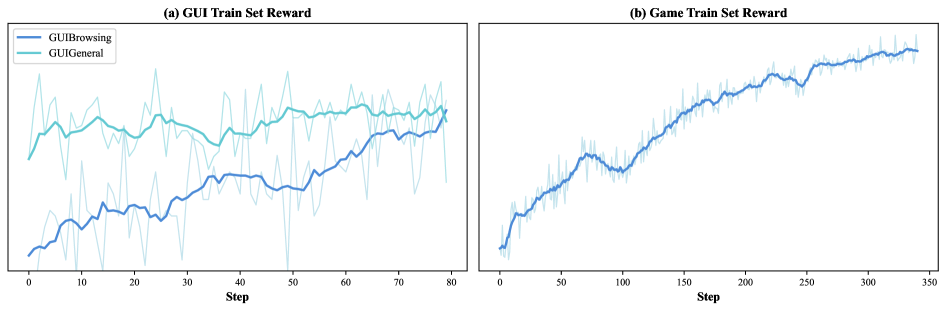
Figure 8. Entropy 动力学——与 reasoning RL 单调下降相反,GUI/Game RL 中 entropy 上升,agent 持续扩张探索空间。
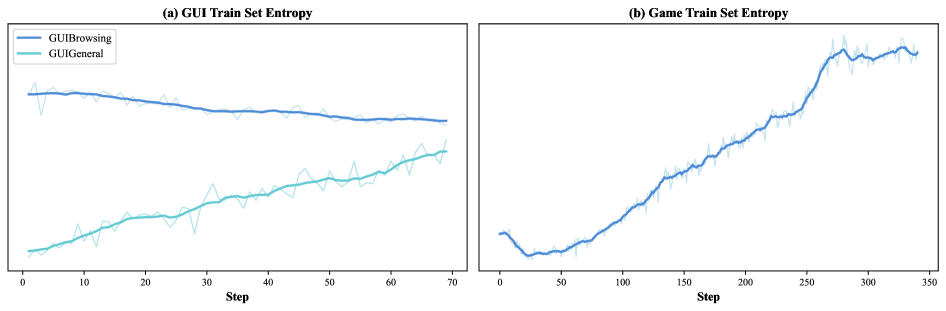
❓ “Entropy 上升 = 持续探索”是合理 narrative,但反过来也可能是 reward landscape 不够 sharp 导致策略难以集中。论文没给 entropy 与 task success 的相关性分析。
VLM-as-Verifier 的可行性
ORM 在 300 条人工标注的 GUI agent trace 上 F1 = 83.8(二分类)。误判主要是 false positive,但作者论证:“即便最终结果错,agent 中间也有许多正确步骤,正确部分的 reward 累加超过错误部分”——所以 imperfect ORM 仍可用。
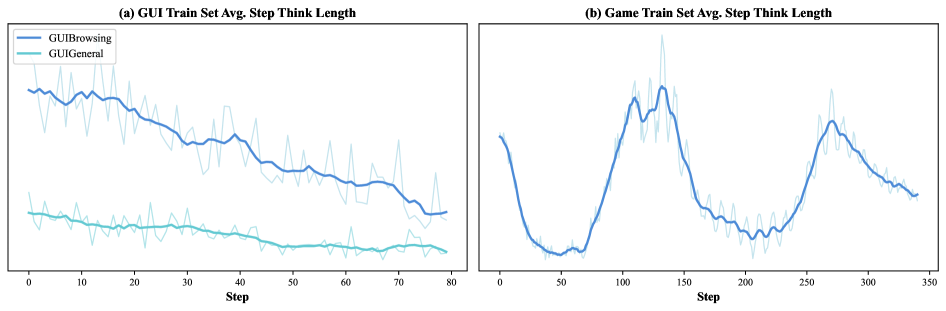
Average Think Length 趋势
Figure 9. 思考长度变化——GUI 任务中 step-level think length 持续下降,与”复杂推理”预期相反。作者解释:GUI 任务通过环境交互推进,对的 action 直接拿到 reward,无需冗长 deliberation。Game 中呈周期性(难度递增→升、熟悉后→降),与 curriculum 难度阶梯吻合。
环境交互轮数
Figure 10. (a) 交互轮数与 reward 关系;(b) Value pretraining 的影响
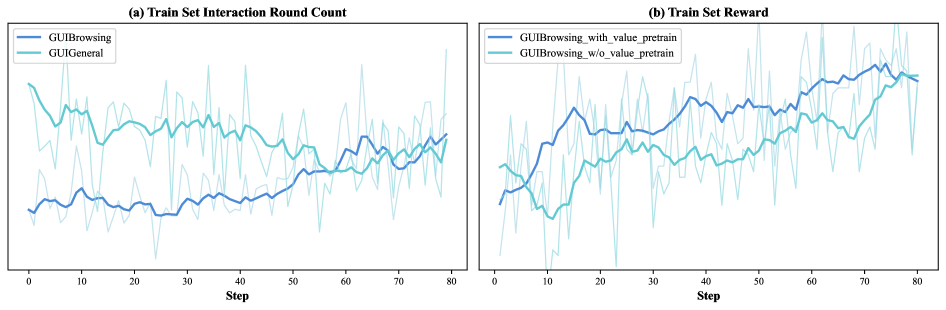
GUI-General 的 reward 上升伴随完成步数下降——RL 内化任务知识,减少不必要探索。Value pretraining 让 reward 在整个训练过程持续更高。
Inference-time Scaling
Figure 11. OSWorld + Game 的推理时步数预算扩展
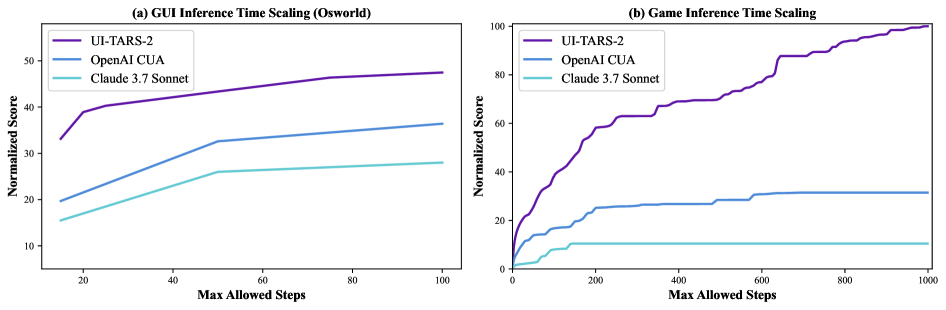
step budget 增大时 UI-TARS-2 几乎单调阶梯式上升,baselines 很快 plateau。即便 RL 训练奖励了”少步完成”,inference time 仍能利用更大预算解锁更多 subgoal。
PPO vs GRPO
Figure 12. PPO 在 GUI-Browsing/General 上 reward 更高、波动更小。
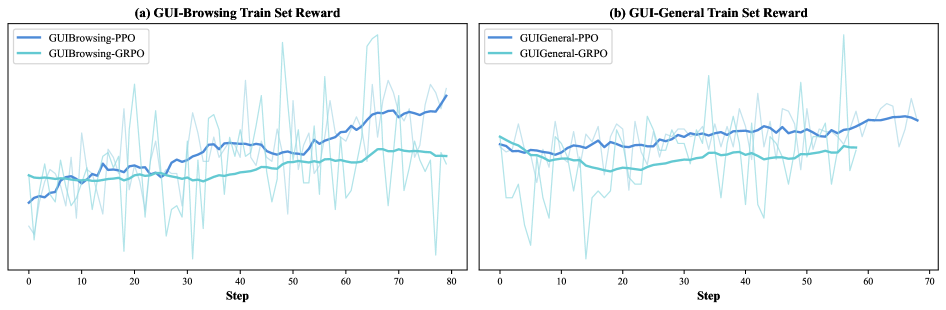
这与 reasoning-RL 圈普遍偏爱 GRPO(DeepSeek-R1 系列)形成对照。可能与 multi-turn agent rollout 中 critic 的价值更大相关——纯 reasoning 任务里,单 step、token-level credit 简单,critic 边际收益低;agent 任务里 long-horizon credit assignment 显然受益于 well-trained value function。
Figure 13. 各 game 训练 reward:很多 game 接近或达到人类@100-step 参考;Free-the-key、Yarn-untangle 等”零起点”游戏被训上来,证明真正提升 game-reasoning 能力。Gem-11、Hex-frvr 出现 plateau,说明 backbone 推理上限。
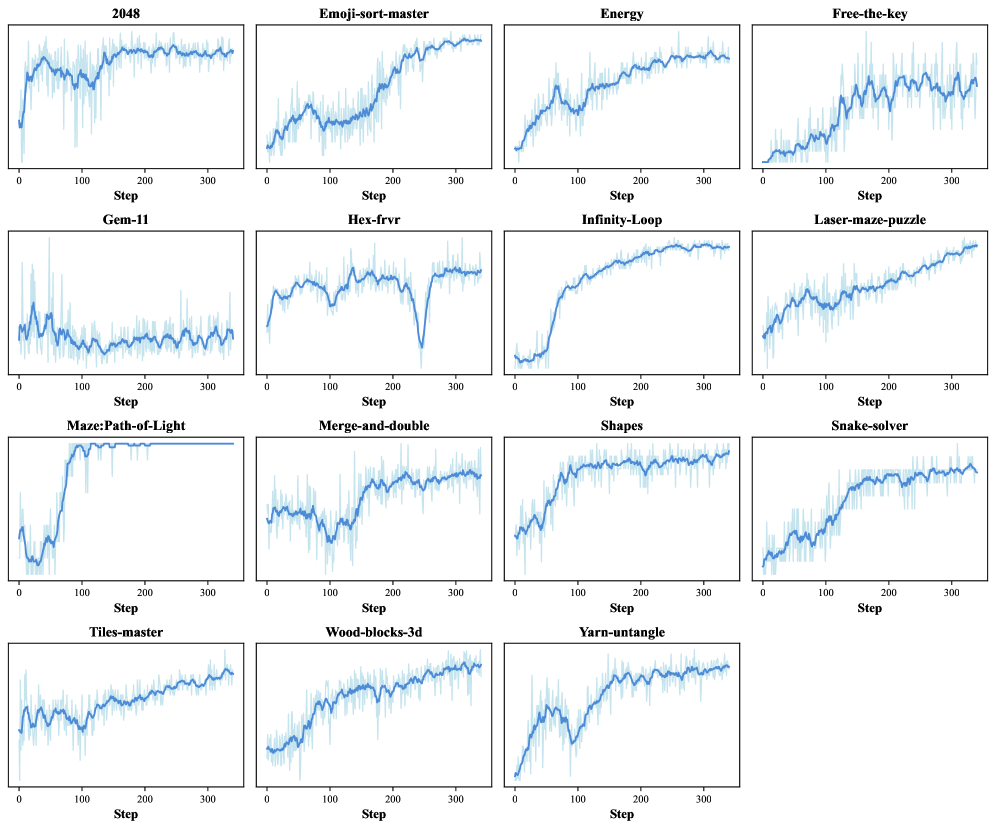
Figure 14. GUI-SDK RL 训练动力学:score 上升、entropy 下降。
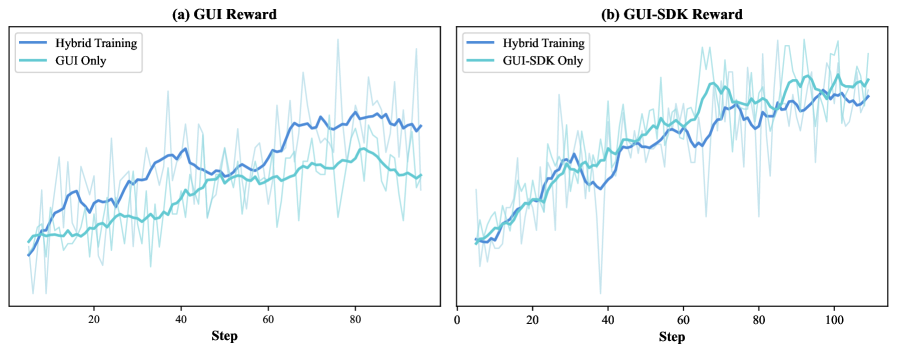
Hybrid Agent RL(vs Parameter Interpolation)
GUI-only / GUI-SDK 双 interface 同时训练,每 interface 数据减半,但 hybrid 模型在纯 GUI 任务上仍超过 GUI-only baseline——更强 interface 的知识可迁移到受限 interface。共享 value model 提高 explained variance。Hybrid 训练成本更高但 transfer 更直接,与 parameter interpolation 形成 efficiency-vs-transfer 取舍。
Figure 15. Hybrid training reward 对比
W4A8 Quantization
权重 4-bit、激活 8-bit。token 生成 29.6 → 47 tokens/s,单轮交互延迟 4.0s → 2.5s。OSWorld 47.5 → 44.4,仅小幅下降。
关联工作
基于
- UI-TARS: 直接前作,承接其 GUI action 原语、UI grounding 数据、native agent formulation
- VAPO / VC-PPO: Decoupled-GAE、Length-Adaptive GAE、Value Pretraining 全部来自这两篇
- DAPO: Clip Higher 来自 DAPO
对比
- OpenAI CUA-o3 / Claude 4 (Computer Use): 主要 baseline
- Kimi-Researcher: streaming rollout pool 与 partially-filled batch 的设计同源
- ARPO / Mobile-GUI-R1: 早期 RL-based GUI agent 的代表
方法相关
- ReAct: thought-action-observation 循环的来源
- RLVR (RL with Verifiable Rewards): RL 训练信号的范式来源
- SWE-agent / OpenHands: 软件工程 agent 框架的对照
- LMGame-Bench: OOD game evaluation 来源
- GUI Agent Survey: GUI agent 整体 landscape 参考
- OpenCUA: 同期开源 computer-use agent 工作
论文点评
Strengths
- System-level engineering completeness:论文不是单一技术贡献,而是一整套 production-grade 的 stack(VM cluster + browser sandbox + 数据飞轮 + 异步 streaming RL + ORM + 参数插值 merge)。这种”全栈披露”对工业界复现 GUI agent 是稀缺资源。
- Hybrid environment 是真问题真解法:把 file system + terminal 与 GUI 同构在同一 sandbox 是对”GUI-only 不够用”的诚实回应,BrowseComp 的数字差(7.0→29.6)让论点说话。
- 训练动力学的细致剖析:entropy 反向、think length 下降、PPO vs GRPO、value pretraining 对 reward curve 的影响——这些经验观察对从业者有 real signal。
- Inference-time scaling on agent tasks:阶梯式上升曲线 + 与 baseline plateau 的对比,是 agent RL 研究里少见的清晰证据,比单纯报 benchmark 数字更有说服力。
- 数据飞轮的概念清晰:把 RFT 输出按 quality 分流 SFT/CT 是简单但易被忽略的操作,理论上能消除”数据浪费”。
Weaknesses
- 关键 claim 缺实证支撑:飞轮的核心假设( 单调上升)没有曲线;ORM “false positive 不致命” 的论述只有定性解释,没量化分析;entropy 上升 = exploration 这一 narrative 也没用 task success 相关性证实。
- Backbone advantage 与方法贡献不可分:从 Seed-thinking-1.6(532M ViT + 23B/230B MoE)起步,能力提升中有多少来自飞轮+RL,多少来自更强的 init?没有 ablation 把方法贡献单独剥出来。
- 作者列表与 institute 不透明:技术报告署名 “ByteDance Seed”,contributions 在最后一节扁平铺开但没有 lead author 划定。复现/讨论时缺锚点。
- 没有开源 UI-TARS-2 模型权重:截至 readme,只有 UI-TARS / UI-TARS-1.5 系列权重;UI-TARS-2 是 close-weight technical report。所有 RL infra、sandbox code 也未开源——claim 完全不可独立验证。
- OOD 泛化样本量小:Online-Mind2Web 上的 SFT→RL gap (83.7→88.2) 看起来不大,OSWorld 43.0→47.5 也只 4.5 点。“strong OOD generalization” 的措辞偏强。
- Game benchmark 的实际意义存疑:很多 mini-game (Tile-master、Infinity-Loop、Shapes) 是低 horizon、规则明确的浏览器小游戏。用作 GUI agent 的 long-horizon control 测试床,与 OSWorld 这类工作流任务对智能体的要求差异巨大;用 mean normalized score 加权会被低 horizon、规则简单的 game 主导。
- PPO > GRPO 缺乏深入分析:只有一张 figure,没解释为什么。是 critic 在 multi-turn 中更重要,还是 GRPO 的 group-baseline 在多轮 sparse reward 下噪声大?
可信评估
Artifact 可获取性
- 代码: 未开源(无 RL 训练代码、sandbox 代码、ORM 模型)
- 模型权重: UI-TARS-2 未发布;GitHub 现有 UI-TARS-7B/72B-SFT、UI-TARS-72B-DPO、UI-TARS-1.5-7B
- 训练细节: 仅高层描述(PPO + 几项加强、parameter interpolation、value pretraining),具体超参数(learning rate、batch size、 取值除 外、训练步数)均未披露
- 数据集: 私有(CT/SFT/RL 数据均来自 in-house annotation 与 in-house synthesis pipeline;GUI-General 690 网站列表未公开)
Claim 可验证性
- ✅ GUI benchmark 数字(OSWorld 47.5、Online-Mind2Web 88.2 等):标准 public benchmark,第三方可独立测(前提是有模型权重——目前没有)
- ✅ PPO 训练曲线 vs GRPO:figure 直接展示,定性可信
- ⚠️ “飞轮使数据质量与模型协同演化”:核心机制 claim,但 上升趋势无证据
- ⚠️ OOD generalization(OSWorld +10.5、AndroidWorld +8.7):单一对比(SFT vs SFT+RL),样本量小,未做 statistical test
- ⚠️ ORM F1 = 83.8 已足够支撑 RL:ORM 评估集是 in-house 300 trace,分布与训练 task 关系不明
- ⚠️ Entropy 上升 = exploration 持续扩张:narrative 合理但 alternative 解释(reward 不够 sharp)未排除
- ❌ “competitive with frontier proprietary models on LMGame-Bench”:在 Tetris (16.0 vs o3 31.0)、Sokoban (0.3 vs o3 2.0) 上明显落后,但论文用”strong/competitive”模糊描述
- ❌ “all-in-one general computer-use agent”:只在选定子集上测;macOS 没测、跨多 app 复杂工作流没系统评估
Notes
- 这篇技术报告的核心价值在 system / data flywheel 而非 RL algorithm。RL 那部分基本是对 VAPO/VC-PPO/DAPO 的工程整合,没有新算法。但工程整合本身在大规模 agent RL 上是稀缺贡献。
- PPO > GRPO 在 multi-turn agent RL 上值得认真追究——这与 reasoning-RL 圈的共识相反。Hypothesis:critic 的边际价值随 horizon 长度增加而上升,因为 advantage estimation 的 variance 在 long-horizon、sparse reward 下会爆炸。验证方法:在固定 backbone 上控制 horizon 变量,测 PPO/GRPO 在 short-horizon agent task 上的差距。
- Parameter interpolation 合并垂直 agent 在概念上简洁但实际可能是 ad-hoc——论文没说 怎么搜(grid? validation set?)。如果需要密集搜超参,“几乎不掉点”就有水分。
- 值得追问:data flywheel 在 cold-start 数据用尽之后能持续多少 iteration?任何 self-improvement loop 都有 distribution collapse 风险(model 生成的轨迹偏向 model 已会的 task),论文对此完全没讨论。
- Hybrid GUI+SDK 的 design 可能是这篇论文最有 long-term 价值的 take——把”computer use” 重新定义为”GUI + terminal + tools 的融合”而非纯 screen click,符合实际工作流,BrowseComp 的数字也说明 SDK 是真正的能力杠杆。
Rating
Metrics (as of 2026-04-24): citation=104, influential=9 (8.7%), velocity=13.51/mo; HF upvotes=127; github 10132⭐ / forks=738 / 90d commits=0 / pushed 87d ago
分数:2 - Frontier 理由:作为 2025-09 发布的 GUI agent 技术报告,UI-TARS-2 在 OSWorld / WindowsAgentArena / AndroidWorld / Online-Mind2Web 上刷新 SOTA(Strengths 1-2),加之 Hybrid GUI+SDK、data flywheel、multi-turn PPO 的全栈系统披露,属当前方向必 baseline 的前沿工作;但不达 Foundation 一档——模型权重与 RL/sandbox 代码均未开源(Weaknesses #4),核心机制 claim 缺乏实证(Weaknesses #1),且 UI-TARS 系列的”奠基”角色更多落在 UI-TARS-1 上,UI-TARS-2 尚未被后续工作大规模采纳为标准参考。2026-04 复核:cite=104/inf=9 (8.7%)/vel=13.51/mo、HF=127、仓库 10132⭐(repo 包含 UI-TARS 全系列,非 UI-TARS-2 专属)——引用与社区关注都处于 Foundation 量级的入口水平,但 influential/total ~8.7% 接近 RT-2 式”被当 landmark 频繁提及、实质继承弱”的形态(见 rubric 特例条);加上 UI-TARS-2 权重至今未单独发布,社区采纳度仍被 UI-TARS-1 截流——保留 2 符合 field-centric 判断;若 UI-TARS-3 出现且 UI-TARS-2 仍无独立 weight release 则降为 1 候选。