Summary
OpenCUA: Open Foundations for Computer-Use Agents
- 核心: 开源全栈 CUA 框架——标注工具 + 22.6K 桌面 trajectory 数据集 + reflective long CoT 训练 recipe
- 方法: AgentNet Tool 跨 OS 采集真实人类演示,三层 L1/L2/L3 CoT + reflector/generator/summarizer pipeline 合成反思推理,以 SFT 训练 Qwen2.5-VL/Kimi-VL 系列
- 结果: OpenCUA-72B 在 OSWorld-Verified 100-step 达 45.0%(开源 SOTA),ScreenSpot-Pro 60.8%,UI-Vision 37.3%(grounding SOTA)
- Sources: paper | website | github
- Rating: 3 - Foundation(开源 CUA 方向首个 end-to-end 开源全栈:标注工具 + 22.6K desktop trajectory + reflective CoT recipe + 多尺寸模型,已成为该领域 de facto baseline)
Key Takeaways:
- Reflective Long CoT 是 scaling agent 的关键: 仅在 state-action pair 上 SFT 几乎不 scale(4.4% on OSWorld);加入 reflector 合成的 reflection thought 后才解锁数据 scaling 收益(提升至 18.5%+)。错误标注不是噪声——只要识别得出,就能教模型 error recovery
- L2 reasoning 优于 L1/L3 inference: 反直觉地反驳 Aguvis 的 L1 best 结论。作者归因于自己的 L2 包含更多 planning + reflection;L3 (observation) 反而引入与任务无关的 visual element 干扰
- Cross-platform 数据有效: Win/Mac 数据明显改进 Ubuntu 测试性能(OSWorld 从 9.8% → 18.5%),反驳 OS-specific 训练的常识
- 开源生态贡献 > 算法新颖性: 真正价值在于 AgentNet Tool(首个 cross-OS 自然采集工具)+ AgentNet 数据集(首个 desktop trajectory-level 大规模数据集)+ 完整训练 recipe
Teaser. OpenCUA 框架四象限——左上 AgentNet Tool 跨 OS 采集,右上原始 demo 处理为带 reasoning 的 state-action trajectory,右下 AgentNet Dataset & Bench 提供任务和离线评测,左下训练得到的模型在真实环境中执行。
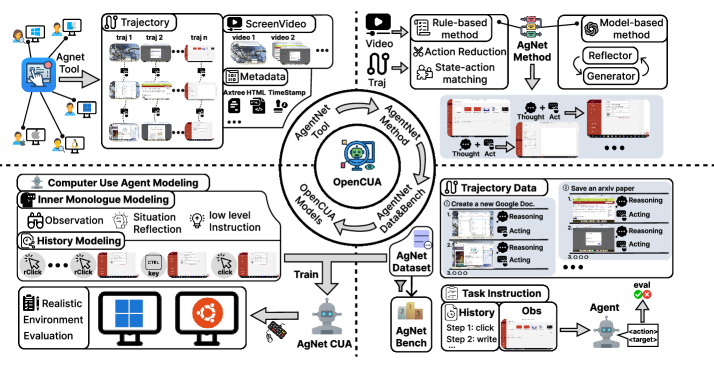
Problem & Motivation
Computer-use agent 的核心瓶颈是高质量训练数据的缺乏——现有数据集规模小、覆盖面窄(mobile/web 偏多,desktop 极少)、且缺少真实用户行为的复杂性。同时开源模型与闭源模型存在巨大差距:Claude Sonnet 4.5 在 OSWorld-Verified 达 61.4%,而开源模型如 UI-TARS-72B-DPO 仅 27.1%。现有方法的 reasoning 质量不足,缺乏 error recovery 能力。OpenCUA 旨在从数据基础设施、数据规模、训练方法三个层面系统性地解决这些问题。
Method
1. AgentNet Tool:跨 OS 标注基础设施
非侵入式后台运行的桌面端工具,支持 Windows / macOS / Ubuntu,采集三类信号:(1) 屏幕视频,(2) 鼠标和键盘信号,(3) accessibility tree。基于 DuckTrack、OpenAdapt(输入追踪)、OBS Studio(屏幕录制)、OSWorld 框架(Axtree 解析)构建。
关键设计选择:放宽”all correct trajectory”要求。前人工作要求所有 step 必须正确,但作者认为标注错误不全是坏事——只要识别得出,就能用来教模型 error detection 和 recovery。
2. AgentNet 数据集
Table 1. 12 类 PyAutoGUI 动作空间——纯视觉观察 + 跨 OS 通用动作。
| Human Action | Agent Action |
|---|---|
| Click / Middle / Double / Triple Click | click(x, y, button) etc. |
| Mouse Move / Drag | moveTo(x, y) / dragTo(x, y) |
| Scroll | scroll(dx, dy) / hscroll(dx, dy) |
| Type / Press / Hotkey | write(text) / press(key) / hotkey(k1, k2) |
| Wait / Terminate | wait() / terminate(‘success’ or ‘failure’) |
数据规模:22,625 个 trajectory(12K Win + 5K macOS + 5K Ubuntu),分辨率 720p–4K,平均 18.6 步。覆盖 140+ 应用、190+ 网站。任务要求 >15 步;<5 步直接拒。
Table 2. AgentNet vs. 既有 GUI 数据集对比——首个同时具备 desktop / personalized env / human trajectory / video / long inner monologue 五项的 trajectory-level 数据集。
| Dataset | Tasks | Avg. Step | Env. | Human Traj. | Video | Inner Monologue |
|---|---|---|---|---|---|---|
| AndroidControl | 15283 | 5.5 | Mobile | ✓ | ✗ | Short |
| GUI Odyssey | 7735 | 15.3 | Mobile | ✓ | ✗ | ✗ |
| WonderBread | 598 | 8.4 | Web | ✓ | ✓ | ✗ |
| AgentTrek | 10398 | 12.1 | Web | ✗ | ✓ | Short |
| Mind2Web | 2350 | 7.3 | Web | ✓ | ✗ | ✗ |
| AgentNet | 22625 | 18.6 | Desktop | ✓ | ✓ | Long |
3. Data Processing Pipeline
Action Reduction:把高频原子信号压缩——mouse move 当 click 的前置;scroll 合并为单方向累计;连续 key press 合并为字符串;CTRL+C 之类抽象成 hotkey。
State-Action Matching:每个 action 对应一张 keyframe。关键 trick:mouse click 不能直接取 click 时刻的截图——鼠标已经悬停到目标,预测会变 trivial。改为回溯到鼠标 pre-movement 的最后一帧(视觉上 distinct 的最后状态),避免信息泄露。
4. Reflective Long CoT(核心创新)
三层结构化 CoT(受 Aguvis 启发但增强):
- L3 (Observation): 显著的视觉/文本元素描述
- L2 (Thought): 反思推理,分析 state transition、回忆之前 step、纠错、规划下一步
- L1 (Action): 简洁可执行动作
L3 → L2 → L1 mirrors perceptual-to-agentic decision flow。
Reflection Augmentation Pipeline:
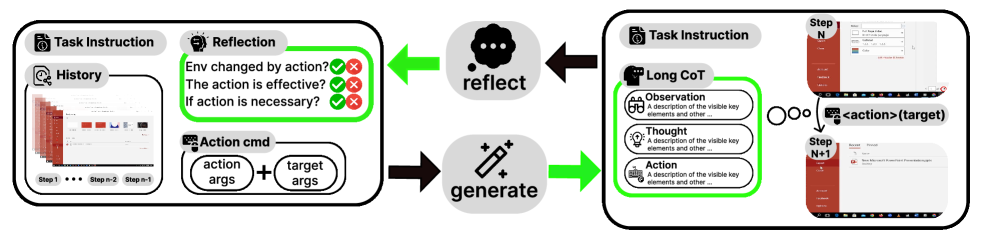
Figure 5. Reflective long CoT 合成 pipeline——三个组件迭代生成与验证 observation/thought/action。
- Reflector: 对比 action 前后截图,检查 action 代码与 CoT 的正确性。错误或冗余 step 给出原因并在训练时跳过;正确 step 解释 action 带来的状态差异
- Generator: 在完整 agent context(前序 reflection、action history、task goal、screenshots、action code)上生成结构化 CoT。Visual cue trick:在鼠标 action 坐标上画红点 + 嵌入 zoomed-in image patch(受 V* 启发)以辅助 grounding
- Summarizer: 把模糊的用户原始 goal 精炼为更精确的 task objective,并对 trajectory 打 alignment / efficiency / difficulty 分
合成器使用 claude-3-7-sonnet-20250219。
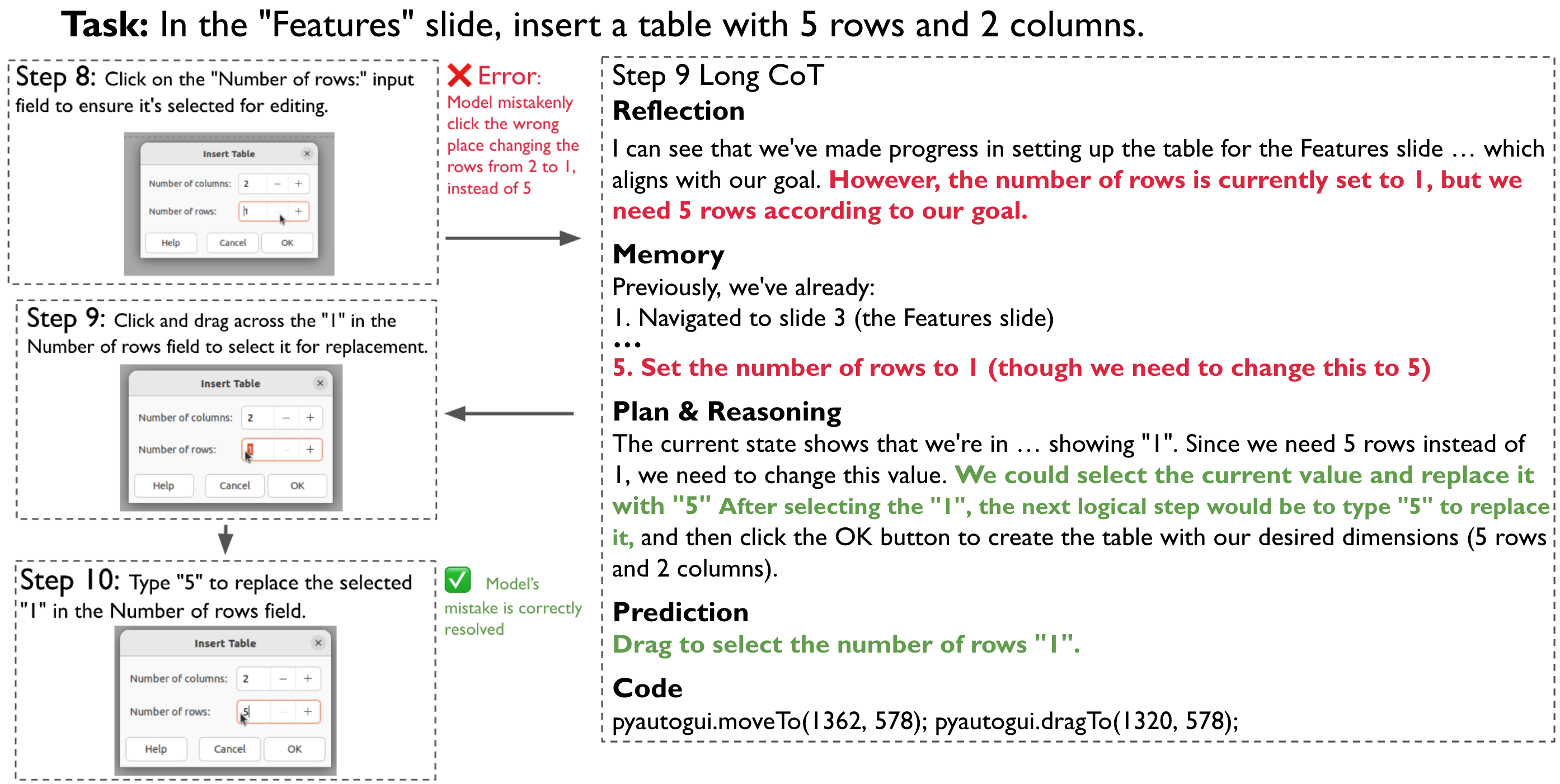
Figure 6. Reflective Long CoT 示例——模型在 thought 中显式包含 reflection / memory / plan / prediction 四个组件,能识别上一步错误并在后续 step 修正。
❓ Reflector 用 Claude 3.7 Sonnet 来判 action 是否”正确”——但 reflector 自己的 false positive/negative rate 多少?没看到数据。如果 reflector 误判率高,等于把噪声重新引入训练集
5. Context Encoding
- Textual history: 对话式格式,使用 L1 CoT(更 token-efficient,允许更长的 history window)。inner monologue 包含 memory 组件以补偿早期 step 缺乏 rich CoT
- Visual history: 默认 3 张截图——比 1 张提升 52%,但 5 张相比 3 张只有 marginal gain 且增加 3K tokens
- Test-time reasoning format: 训练时混合 L1/L2/L3,inference 时用 L2(含 planning + reflection)
6. Training Data Mixture
- CoT mixture: L1 + L2 + L3 三层都训,理由是各自承载互补信息(L1 直连 action,L2 含 planning,L3 含 perception)
- Domain mixture: grounding(ShowUI / UGround / 189K AXTree-parsed bbox)+ planning(Win/Mac + Ubuntu trajectory)+ general SFT(Kimi 团队的指令跟随、数学、long-context、OCR、VQA)。比例如 70% CUA + 30% general(Stage 2 only),或 45% planning + 20% grounding + rest general(Stage 2 of staged training)
- 三种训练策略:
- Stage 2 only: 资源受限场景,把通用 VLM 转成 specialized CUA(用于 OpenCUA-Qwen2-7B、OpenCUA-A3B)
- Stage 1 + Stage 2: 先在 grounding + general 数据上 pretrain(Stage 1 用 35B–250B token),再在 trajectory + general + grounding 上 finetune(Stage 2 用 16B–60B token)。OpenCUA-32B、OpenCUA-72B 用此策略
- Joint training: 全 mixture 端到端训 200B token,跨域平衡。OpenCUA-7B 用此策略,达 27.3% on OSWorld online
OpenCUA-72B 额外使用 8K 由 o3 + Jedi 在 Ubuntu 环境中 rollout 的 trajectory。
Experiments
Online Agent Evaluation: OSWorld-Verified
Table 3. OSWorld-Verified 主结果——OpenCUA-72B 45.0% 为开源 SOTA,与 Claude 4 Sonnet (41.5%) 持平,但仍落后 Claude Sonnet 4.5 (61.4%) 16.4 个点。
| Model | 15 Steps | 50 Steps | 100 Steps |
|---|---|---|---|
| Proprietary | |||
| OpenAI CUA | 26.0 | 31.3 | 31.4 |
| Seed1.5-VL | 27.9 | – | 34.1 |
| Claude 4 Sonnet | 31.2 | 43.9 | 41.5 |
| Claude Sonnet 4.5 | – | – | 61.4 |
| Open-Source | |||
| Qwen2.5-VL-72B-Instruct | 4.4 | – | 5.0 |
| Kimi-VL-A3B | 9.7 | – | 10.3 |
| UI-TARS-72B-DPO | 24.0 | 25.8 | 27.1 |
| Qwen3-VL | – | – | 38.1 |
| OpenCUA-7B (Ours) | 24.3 | 28.1 | 26.6 |
| OpenCUA-32B (Ours) | 29.7 | 34.1 | 34.8 |
| OpenCUA-72B (Ours) | 39.0 | 44.9 | 45.0 |
Key observations:
- OpenCUA 方法对多种架构和 size 都 work(Kimi-VL-A3B、Qwen2-VL-7B、Qwen2.5-VL-7B/32B/72B)
- step budget 从 15 → 50 收益大,50 → 100 收益小——大多数 task 不需要超过 50 步,且模型不擅长识别自己的错误和决定何时 stop
- Pass@n 头空间巨大:OpenCUA-72B Pass@1 = 45.0%,Pass@3 = 53.2%——意味着 post-training / re-ranking / multi-agent 还有很大空间
GUI Grounding
Table 5. GUI grounding——OpenCUA-72B 在 ScreenSpot-Pro (60.8%) 和 UI-Vision (37.3%) 上 SOTA。
| Model | OSWorld-G | Screenspot-Pro | Screenspot-V2 | UI-Vision |
|---|---|---|---|---|
| Qwen2.5-VL-7B | 31.4 | 27.6 | 88.8 | 0.85 |
| Qwen2.5-VL-32B | 46.5 | 39.4 | 87.0 | – |
| UI-TARS-72B | 57.1 | 38.1 | 90.3 | 25.5 |
| OpenCUA-7B | 55.3 | 50.0 | 92.3 | 29.7 |
| OpenCUA-32B | 59.6 | 55.3 | 93.4 | 33.3 |
| OpenCUA-72B | 59.2 | 60.8 | 92.9 | 37.3 |
关键观察:grounding 必要但不充分——Qwen2.5-VL-32B 在 OSWorld-G/ScreenSpot-V2 与 OpenCUA 接近,但 OSWorld 完整任务上完败(5.0% vs 34.8%)。high-level planning + reflective reasoning 才是 task completion 的瓶颈。
Offline Evaluation: AgentNetBench
Table 4. AgentNetBench——OpenCUA-32B 79.1% avg SR 超过 OpenAI CUA (73.1%)。但需注意 OpenCUA 在自家 distribution 上有优势。
| Model | Coord. SR | Content SR | Func. SR | Avg. SR |
|---|---|---|---|---|
| Qwen2.5-VL-72B | 67.2 | 52.6 | 50.5 | 67.0 |
| OpenAI CUA | 71.7 | 57.3 | 80.0 | 73.1 |
| OpenCUA-7B | 79.0 | 62.0 | 44.3 | 75.2 |
| OpenCUA-32B | 81.9 | 66.1 | 55.7 | 79.1 |
❓ Func. SR (terminate) OpenAI CUA 80% 而 OpenCUA-32B 仅 55.7%——termination judgment 是 OpenCUA 的明显短板,与论文 error study 中”termination misjudgment”作为主要错误类别一致
Data Scaling
- Cross-domain transfer 有效:7K Ubuntu → 7K Ubuntu + 14K Win/Mac,OSWorld 从 9.8% → 18.5%,反驳 OS-specific 数据是必要的
- In-domain scaling:Ubuntu 3K → 10K avg 提升 72%;Win/Mac 3K → 14K 提升 125%。两条 curve 都没有看到饱和
Analysis 关键 Ablation
Reflective Long CoT 是 driver
Table 6. CoT 设计 ablation(OpenCUA-Qwen2-7B on OSWorld)。
| Ablation | Variant | SR (%) |
|---|---|---|
| CoT Mixture | L2 only | 13.1 |
| CoT Mixture | Mixture-CoT (L1+L2+L3) | 18.5 |
| Reflective Long CoT | Short-CoT (Aguvis 风格) | 11.5 |
| Reflective Long CoT | Advanced-CoT (本工作) | 15.3 |
| Test-time Format | L1 inference | 16.9 |
| Test-time Format | L2 inference | 18.5 |
| Test-time Format | L3 inference | 17.6 |
三个明确发现:
- Reflective long CoT 比短 CoT +3.8 pts(11.5 → 15.3),归因于 error correction
- 训练时混合 CoT 比只用 L2 高 +5.4 pts(13.1 → 18.5)——三层互补
- L2 inference 最佳——反驳 Aguvis 的 L1 best 结论。L3 退化是因为 description 引入与 next action 无关的 visual element
鲁棒性堪忧
即便 temperature=0 deterministic decoding,OpenCUA-Qwen2-7B 在 OSWorld 上 Pass@16 (38.6%) vs Pass@1 (20.1%) 有 18.5% 绝对差距。变异来源:
- agent 在不同 run 选不同方案(Ctrl+Shift+T vs 菜单导航)
- 微小遗漏或多余动作(忘点 Save / 多点一下)
- 环境动态:CAPTCHA、机器抖动、网络延迟
评价:这是这篇工作未充分讨论的隐忧——agent 的 task success 高度依赖 environment 的偶然性,而不是策略的 robust 推理
Visual / Textual History Trade-off
Figure 10: 1 → 3 张截图收益巨大;3 → 5 张 marginal。文本侧 L1 (Action) 历史比 L2 (Thought) 历史好——L2 history 引入幻觉且降低训练效率。Default: L1 CoT history + 3 images。
General Text Data 有正向作用
35% general text data(来自 Kimi 团队的指令跟随、数学、long-context)即便与 GUI 完全无关,依然轻微提升 agent 性能。作者归因于 generalization 和 instruction understanding 改进。
关联工作
基于
- OSWorld:评测 benchmark 与 Axtree parsing 框架直接复用,AgentNet 严格不重叠 OSWorld task 防止 leakage
- Aguvis:CoT 三层结构(L1/L2/L3)的祖宗;OpenCUA 的 L2 reasoning + 反思训练是对 Aguvis 的关键扩展
- ActRe:CoT 合成 pipeline 的另一个前置工作
对比
- UI-TARS-72B-DPO:当前开源 CUA 主要 baseline,27.1% vs OpenCUA-72B 45.0%
- OpenAI CUA / Claude 4 Sonnet / Claude Sonnet 4.5:闭源对比,gap 仍在 16+ 个点
- Qwen2.5-VL-72B-Instruct: 同 base model 对照,5.0% → 45.0% 验证 SFT 增益
- AgentTrek:来自同一团队 XLANG Lab 的前序工作,专注 web agent 数据合成;OpenCUA 是 desktop trajectory 的更大规模版本
方法相关
- ShowUI / UGround:grounding 训练数据来源
- Kimi-VL:base model 之一 + general SFT 数据来源
- V* (zoomed-in patch):visual cue 设计借鉴
- DuckTrack / OpenAdapt / OBS Studio:AgentNet Tool 的底层依赖
- o3 + Jedi:OpenCUA-72B Stage 2 用于 rollout 8K Ubuntu trajectory
论文点评
Strengths
- 系统性工程贡献无懈可击:从标注工具 → 数据集 → 模型 → 评测 benchmark 全部开源,是这个方向当下少有的 reproducible end-to-end work。降低了入场门槛,能催化整个开源 CUA 社区
- Reflective CoT 设计精巧且有 ablation 支撑:reflector / generator / summarizer 三段式 pipeline,明确解决”标注错误”这个看似负面的因素,实际转化为 error recovery 能力。+3.8 pts 的 ablation gap 是 clean evidence
- Data scaling law 实证:双 OS 维度的 scaling curve(Ubuntu in-domain + Win/Mac cross-domain)都没饱和,意味着继续 scaling 数据仍有空间。这种 evidence-driven 的方向性判断比单纯刷 SOTA 更有 insight
- 诚实地报告 robustness 问题:明确指出 deterministic decoding 下 18.5% 的 Pass@1 vs Pass@16 差距,没有掩盖。section 5 的 variance 来源分析很有价值
- L2 vs L1 inference 的反直觉发现 + 解释:反驳 Aguvis 的结论并给出 hypothesis(L2 质量更高所以更有用),并通过 case study 验证 L3 退化的原因(无关 element 干扰)
Weaknesses
- 与 Claude Sonnet 4.5 仍有 16.4 pts 差距,且 gap 来源没有归因:是 base model 能力(Qwen2.5-VL vs Claude)、是数据规模、还是 RL 缺失?没有对照实验。读者无法判断 next step 应该 invest 在哪
- Reflector 自身可信度未验证:用 Claude 3.7 Sonnet 当 reflector 判定 action 正确性,但 reflector 的 precision/recall 没有测。如果 reflector 误判率高,相当于把噪声以”反思”的形式重新注入训练集
- Robustness 问题严重但没有解决方案:Pass@1 vs Pass@16 18.5% 的差距说明策略对 spurious factor 极敏感。这不是 future work 一句话能搪塞的,是部署的 blocking issue
- Long-horizon 任务收益递减是真问题:50 → 100 step budget 几乎没提升,说明 18.6 步平均长度的训练数据不足以泛化到真正长 horizon 场景。论文的 18.6 步本身在真实办公场景(如完整 ETL 流程、多文档协调)下可能偏短
- Privacy concern 仅在 Appendix 提及:采集真实用户桌面操作的伦理 / GDPR / 数据 leakage 问题需要更深入讨论。这对开源社区采用本工作的方法有实际影响
- CoT 合成成本不透明:Claude 3.7 Sonnet 合成 22K trajectory × 18.6 step 的 CoT 是非平凡 API 开销,没披露具体成本。这影响后人是否能复现 / scale
可信评估
Artifact 可获取性
- 代码: inference + training(Github 仓库提供完整训练 code,vLLM 已支持 7B/32B/72B 推理)
- 模型权重: OpenCUA-7B、OpenCUA-32B、OpenCUA-72B(基于 Qwen2.5-VL)+ OpenCUA-A3B(基于 Kimi-VL)+ OpenCUA-Qwen2-7B(基于 Qwen2-VL)已发布
- 训练细节: 三阶段策略均报告了 batch size / LR / token budget / GPU 数 / 训练步数;但 Stage 1 的 “general SFT data from Kimi Team” 配比未完全披露,属仅高层描述
- 数据集: AgentNet 22.6K trajectory 开源;AgentNetTool 单独 repo 开源;AgentNetBench 100 task 离线评测开源;OSWorld-Verified 公开评估通过 OSWorld 团队 AWS 设施
Claim 可验证性
- ✅ OSWorld-Verified 45.0% (100-step):3 次运行平均,由 OSWorld 团队在 AWS 上独立评估,Pass@1 报告了 ±std
- ✅ Reflective long CoT +3.8 pts ablation:明确控制变量(同 base model + 同 data + 同 step),数字直接可验证
- ✅ Data scaling 趋势:cross-domain 与 in-domain 双维度 curve 完整,3 个数据点足够支撑趋势
- ⚠️ AgentNetBench 79.1% 超过 OpenAI CUA 73.1%:OpenCUA 在自家 distribution 测试集上有 domain alignment 优势,作者也明确承认(“relatively higher due to alignment of the domain”)。比较意义有限
- ⚠️ “Cross-platform 有效泛化”:OSWorld 9.8% → 18.5% 数字真实,但 OSWorld 主要是 Ubuntu,Win/Mac 数据带来的提升是否会在 Win-only benchmark 上同样成立?没有完整的 2x2 验证
- ⚠️ “Reflective CoT 提升来自 error correction”:归因来自 case study,没有定量证据(如 error recovery rate 对比)
- ⚠️ OpenCUA-7B “27.3% on OSWorld Online Evaluation Platform”:与 Table 3 的 26.6% 不一致,且 “Online Evaluation Platform” 与 “OSWorld-Verified” 是否同一 benchmark 文中描述不清
Notes
- Reflection augmentation 的思路可推广到其他 agent 领域——embodied agent / robot manipulation 的 error recovery 同样是核心挑战。值得探究是否存在 modality-agnostic 的 reflective training recipe
- 关键开放问题:data scaling 的天花板在哪里?Ubuntu 10K → 100K 是否还会线性提升?是否存在 data quality > data quantity 的 inflection point?
- AgentNetBench 作为 offline evaluation 的设计值得关注——给社区提供了 cheap 的 development 反馈环。但 100 task 规模太小,与 online benchmark 的 correlation 在 long-tail case 上可能崩
- 与 Claude Sonnet 4.5 的 16 pts gap:值得做的拆解实验是 (a) 把 OpenCUA 训练数据喂给更强 base(比如 Llama 4 / GPT-OSS)看 ceiling 提升多少;(b) 把 OpenCUA SFT checkpoint 加 RL(OSWorld 自验证 reward)看能否 close gap
- Reflective CoT 用 Claude 3.7 Sonnet 合成的成本和质量上限是真正的 bottleneck。后续工作方向:能否用 self-bootstrap(agent 自己合成 reflection)替代 teacher distillation?
-
❓ AgentNet 数据的隐私机制具体是什么?匿名化的颗粒度(仅去除 PII 还是 redact 截图中的敏感内容)会显著影响下游可用性
Rating
Metrics (as of 2026-04-24): citation=63, influential=12 (19.0%), velocity=7.50/mo; HF upvotes=33; github 740⭐ / forks=97 / 90d commits=1 / pushed 78d ago
分数:3 - Foundation 理由:OpenCUA 是开源 CUA 方向首个真正 end-to-end 的 foundation work——AgentNet Tool(首个 cross-OS 采集工具)+ 22.6K desktop trajectory(首个 desktop 大规模 trajectory 数据集)+ reflective long CoT recipe + 7B/32B/72B 多尺寸模型同时开源,直接把开源 SOTA 从 UI-TARS-72B-DPO 的 27.1% 拉到 45.0%(Strengths #1 所述)。外部信号印证 Foundation 而非 Frontier:NeurIPS 2025 Spotlight、vLLM 于 2026-01 官方支持 7B/32B/72B 全系列、被后续开源 CUA 工作作为 baseline 采用;数据集 + 工具 + recipe 这一组合的”社区基础设施”属性使其难以被单篇 SOTA 刷掉。降档为 Frontier 的唯一理由会是与 Claude Sonnet 4.5 的 16 pts gap(Weaknesses #1),但在开源子方向里 OpenCUA 已是必读必引。