Summary
AgentTrek: Agent Trajectory Synthesis via Guiding Replay with Web Tutorials
- 核心: 用互联网上的 GUI 教程做 “guided replay”,让 VLM agent 在真实浏览器里按教程一步步操作,自动合成 web agent 的 multi-step trajectory 训练数据
- 方法: 三阶段 pipeline——(1) FastText 分类器从 RedPajama 过滤教程;(2) GPT-4o 在 BrowserGym 中按教程引导执行,记录 screenshot/AXTree/DOM/action;(3) GPT-4o VLM evaluator 过滤无效轨迹。最终 Qwen2-VL/Qwen2.5 SFT
- 结果: 10,398 条 trajectory(127 网站,平均 12.1 步,每条 $0.55),Qwen2-VL-7B+AgentTrek 在 ScreenSpot Web 67.4 (vs 30.7 baseline),Mind2Web 全面超过 GPT-4 baseline
- Sources: paper | website | github
- Rating: 1 - Archived(+230% replay ablation 有清晰因果证据、ICLR 2025 Spotlight,但发表 16 个月后 cc=69 / gh 54⭐ stale、未被 OS-Atlas / UI-TARS 等 GUI agent 主线采纳,作为 tutorial-as-plan 的单点参考)
Key Takeaways:
- Tutorial-as-supervision: 把网上现成的”how-to”教程当成弱监督的轨迹脚手架——human 已经免费写好了 step-by-step 计划,剩下的只是让 agent 在真实环境里 grounding 执行,避开了纯 LLM self-instruct 在长 horizon 上的脆弱
- Guided replay vs unguided rollout: 同样 400 个任务,带教程的 effective trajectory 比例 52% vs 无教程 15.78%(+230%)。说明在当前 VLM 能力下,high-level goal 还远不够,detailed step 是数据合成成功率的瓶颈
- VLM evaluator 可用且成本低: GPT-4o 作 trajectory-level judge,acc 84%,成本仅占总 pipeline 的 1.4%(215/1k),是 cost-effective 的 quality filter
- Pure-vision + pyautogui unified action space,避开 HTML 跨站点格式不一致问题,token cost 从 4k/step → 1.2k/step (Qwen2-VL 720p)
Teaser. AgentTrek 三阶段 pipeline overview
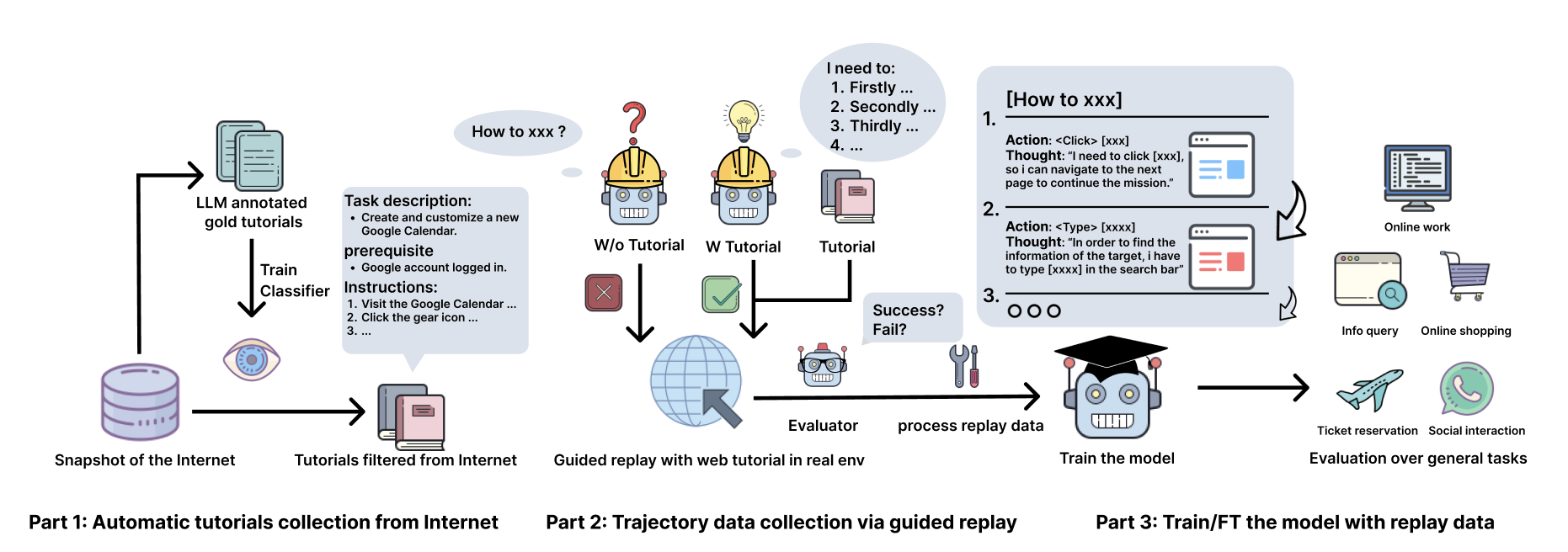
Pipeline 设计
整体目标:从互联网原始文本到训练好的 GUI agent,全自动闭环。三大阶段对应论文 Section 2.1 / 2.2 / 2.3。
Stage 1:从互联网自动收集教程
Figure 3. 教程过滤与分类 pipeline
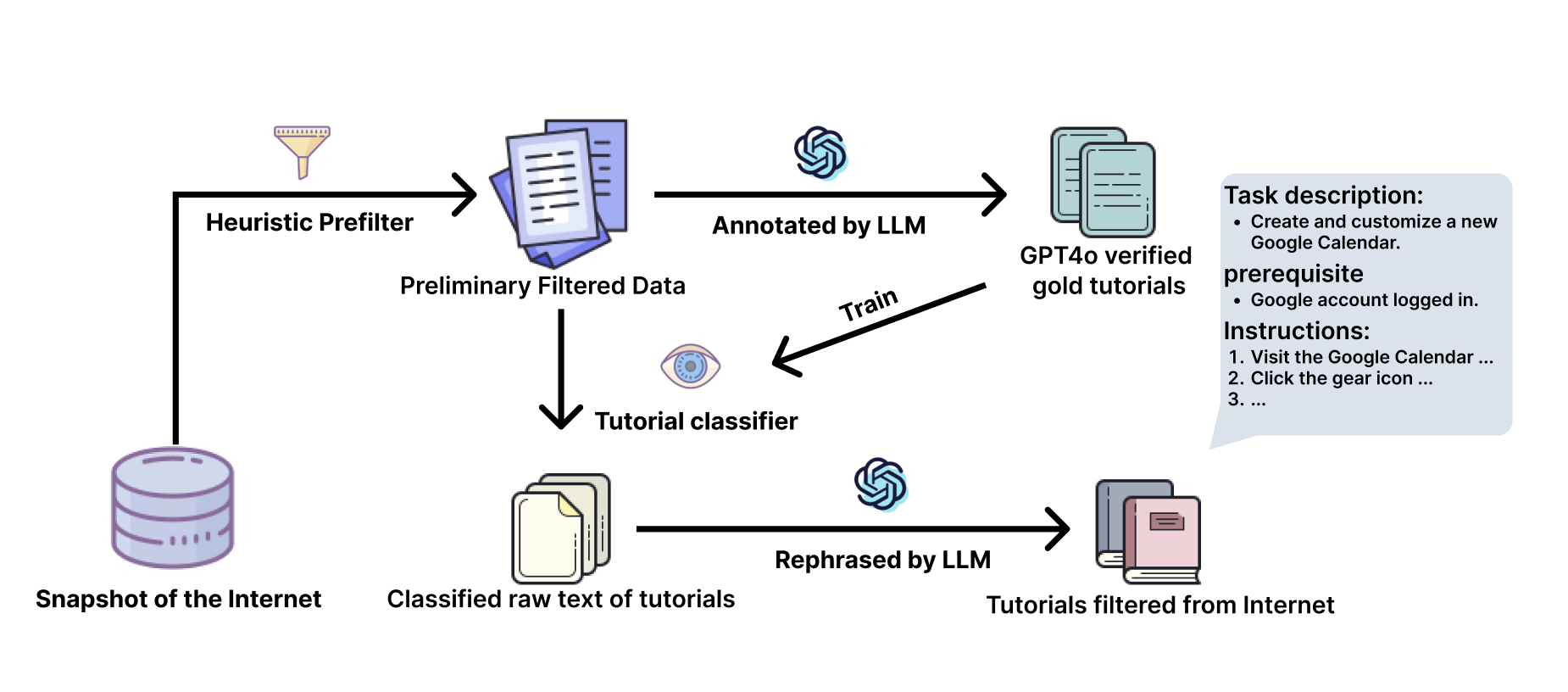
从 RedPajama (20.8B URLs) 起步,三层级联 filter 把 noise level 逐步压低:
- Prefilter (rule-based): 关键词匹配(
click,type,macOS,Windows)+ 长度 + URL format。在 180 正 / 105 负 ground truth 上 recall 92.69%。20.8B → 68.8M - LLM Labeler (GPT-4o-mini): 在 ground truth validation set 上 F1 ≈ 90%,作者声称在 lengthy text 中识别教程内容反而比 human 更准。用来给 FastText 打标
- FastText Classifier: ~90k LLM+human 标签的样本训练,二分类。结果 18.8M tutorial-like 文本
- Tag & Paraphrase (GPT-4o-mini): 标准化模板——Platform / Target / Task Description / Prerequisites / Step-by-step Instructions / Expected Outcome。$0.89/1k 条
Table 2. 三层 filter 性能对比
| Metric | Precision | Recall | F1 |
|---|---|---|---|
| Prefilter | 0.69 | 0.61 | 0.60 |
| LLM | 0.885 | 0.885 | 0.89 |
| FastText | 0.895 | 0.895 | 0.89 |
❓ Prefilter 的 92.69% recall 与表里 0.61 看似冲突,前者大概是早期 keyword-only 的指标,后者是综合判断后的结果。论文没明确解释。
Stage 2:Guided Replay 收集轨迹
Figure 5. Guided Replay & VLM Evaluator pipeline
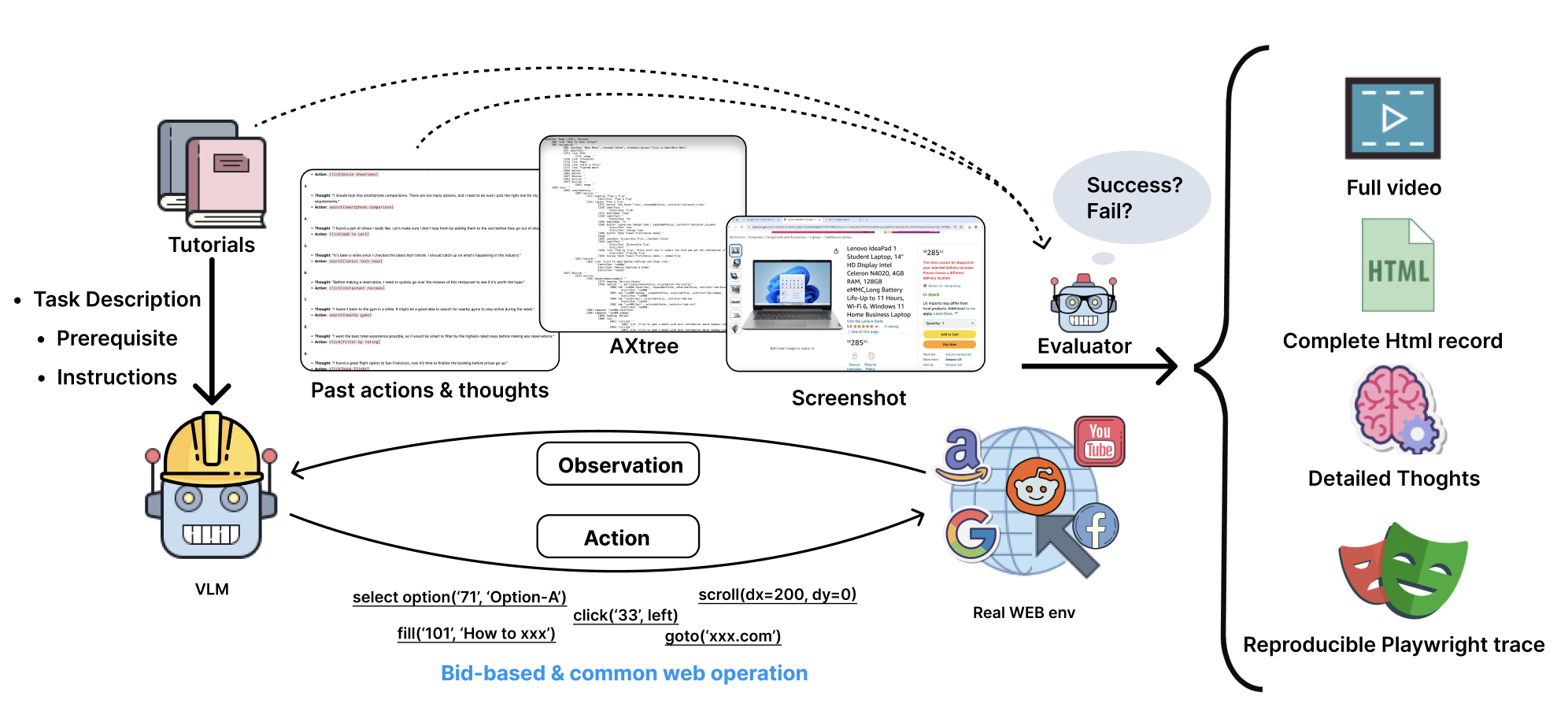
核心是把第一阶段产出的结构化教程喂给 BrowserGym 中的 VLM agent (GPT-4o-08-06),用 Playwright 在真实 Chromium 浏览器执行,同时记录:
- Trajectory data 组成:
- Task Information (platform, description, prerequisites, instructions, expected outcomes)
- Post-processed Textual Trajectory (task metadata + observations + intermediate reasoning + action sequence)
- Screenshots & Video Recordings
- Reproducible Native Trace (DOM snapshots, HTML, network flow, Playwright actions)
- Action space: Playwright
click / select_option / clear等,later mapped to pyautogui - Cost: 8,027 tokens/step, 86,114 tokens/task,1k tasks ≈ $215 (GPT-4o-08-06)
VLM Evaluator (GPT-4o): 输入 task description + action history + 每步 inner thought,做 trajectory-level pass/fail judgment,并定位 earliest failure point。在 1,081 人工 review 的 558-sample 验证集上 84.0% accuracy;作者观察到 evaluator 比 human 更严格。
Figure 6. Guided replay 实例(agent 查找返修政策)
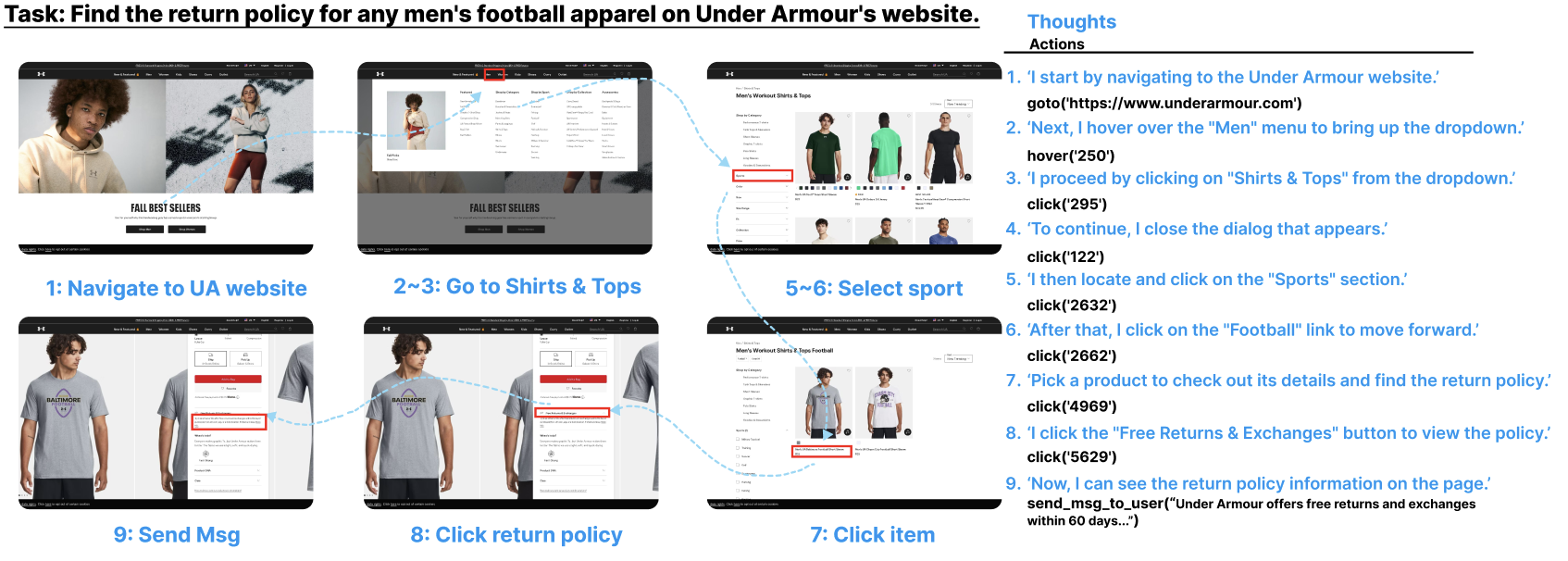
Table 4. Cost breakdown
| Phase | Cost/1k ($) | Model |
|---|---|---|
| T&P | 0.89 | gpt-4o-mini |
| Replay | 215.36 | gpt-4o |
| Eval | 3.10 | gpt-4o |
| Total | 219.35 | – |
考虑 44.4% replay 成功率 → 每条 effective trajectory $0.551。
Stage 3:训练 Pure-Vision Web Agent
设计取舍:完全抛弃 HTML/AXTree 输入,only screenshot + pyautogui action:
- 理由:HTML 跨站点不统一;HTML token 成本高 (~4k/step);视觉表示更接近 human 认知;Qwen2-VL 720p 仅 1.2k tokens/image
- Backbone: Qwen2-VL(NaViT encoder + 2D-RoPE,支持 dynamic resolution)
- Action: 标准 pyautogui + pluggable action system 处理
select_option这类 Playwright-specific 动作 - Training: 单阶段 SFT,10k vision trajectories(vision agent);6k text trajectories(text agent,输入 AXTree+Playwright actions)
实验结果
Text-based agent on WebArena
Table 5. WebArena task success rate
| Model | WebArena |
|---|---|
| GPT-4o | 13.10 |
| GPT-4 | 14.41 |
| Synatra-CodeLlama-7B | 6.28 |
| AutoWebGLM (OOD SFT) | 8.50 |
| AutoWebGLM (In-domain RFT) | 18.20 |
| Qwen2.5-7B-Instruct w/ AgentTrek | 10.46 |
| Qwen2.5-32B-Instruct w/ AgentTrek | 16.26 |
WebArena 是 OOD(self-hosted 网站,AgentTrek 训练集没见过)。32B 模型 16.26 超过 GPT-4o 但仍低于 In-domain RFT 的 AutoWebGLM。
Vision-based agent on ScreenSpot Web
Table 6. ScreenSpot Web grounding
| Model | Text | Icon/Widget | Average |
|---|---|---|---|
| GPT-4o | 12.2 | 7.8 | 10.1 |
| Qwen2-VL-7B | 35.2 | 25.7 | 30.7 |
| SeeClick | 55.7 | 32.5 | 44.7 |
| CogAgent | 70.4 | 28.6 | 50.7 |
| GPT-4 + OmniParser | 81.3 | 51.0 | 67.0 |
| Qwen2-VL-7B w/ AgentTrek | 81.7 | 51.5 | 67.4 |
7B model fine-tuned on AgentTrek 把 baseline 翻一倍多,跟 GPT-4+OmniParser 持平。
Vision-based agent on Multimodal-Mind2Web
Table 7. Mind2Web cross-task / cross-website / cross-domain (Step SR & Op.F1)
| Model | CT Step SR | CT Op.F1 | CW Step SR | CW Op.F1 | CD Step SR | CD Op.F1 |
|---|---|---|---|---|---|---|
| GPT-4 (H+I) | 40.2 | 73.4 | 32.4 | 67.8 | 36.8 | 69.3 |
| Qwen2-VL + AT | 40.9 | 84.9 | 35.1 | 82.8 | 42.1 | 84.1 |
| Qwen2-VL + M2W | 50.9 | 89.5 | 44.9 | 83.9 | 47.7 | 86.8 |
| Qwen2-VL + AT+M2W | 55.7 | 88.9 | 51.4 | 88.1 | 52.6 | 87.5 |
AT 单独已超 GPT-4;AT + M2W 联合训练给出最佳——说明 AgentTrek 与 in-domain Mind2Web 数据互补,不冗余。
关键 Ablation:Tutorial 的作用
400 任务,replay 两次:
- 不带 tutorial(仅 high-level goal):63 effective (15.78%)
- 带 step-by-step tutorial:208 effective (52.0%)
- +230% effective rate
Insight: 当前 VLM 在 long-horizon 任务上的瓶颈不是 grounding,而是 planning coverage——它知道按钮在哪儿,但不知道下一步该按哪个。Tutorial 把 plan 外包给 human-written text,是当下最 cost-effective 的解。
数据规模与多样性
- RedPajama → 18.8M filtered → 23,430 prepared tutorials → 10,398 successful trajectories
- 127 网站,11 个 distinct categories
- 平均 12.1 steps/trajectory(同表对比:WebLINX 18.8, Mind2Web 7.3)
Figure 7. Dataset domain diversity

❓ “127 websites” 听起来不少,但相对 web 全貌仍很窄。论文没说 category 分布是否长尾、多少网站只贡献了 1-2 条 trajectory。这会影响 OOD generalization 的判断。
关联工作
基于
- WebArena: 用作 text agent evaluation benchmark;BrowserGym 也基于 WebArena 框架
- RedPajama: tutorial 提取的原始 web corpus
- Qwen2-VL: vision agent 的 backbone,NaViT encoder + 2D-RoPE 支持高分辨率截图
- FastText: 教程二分类 classifier
- Playwright: 浏览器自动化 + trace recording 工具
对比
- SeeClick: 之前的 web grounding 工作;AgentTrek 在 ScreenSpot Web 上超过它(67.4 vs 44.7)
- CogAgent: 大规模 GUI VLM;AgentTrek 7B SFT 持平 18B CogAgent
- GPT-4 + OmniParser: 训练-free pipeline,AgentTrek SFT 后达到同水平
- AutoWebGLM: in-domain RFT WebArena 18.20,AgentTrek 32B OOD 16.26
- Mind2Web / WebLINX / RUSS / ScreenAgent / GUIAct: Table 1 的 dataset 对比对象
方法相关
- Tutorial-as-supervision: 利用 human-written procedural text 作弱监督,与 instruction tuning / chain-of-thought 同源
- VLM-as-Judge: GPT-4o trajectory evaluator 与 LLM-as-judge 文献相关
- Guided rollout / replay: 与 imitation learning 中 expert demonstration replay 思想一致,但 expert 是 text tutorial 而非动作
论文点评
Strengths
- 问题定位清晰且重要:GUI agent 的 trajectory data scarcity 是真实瓶颈,而 web tutorial 这一 supervision 来源被低估了——把 “how-to 文章” 这类人类已经付出 cognitive effort 写好的过程性知识直接利用,相比 self-instruct 的 LLM 凭空想象,是更可靠的 plan source
- 三层级联 filter 设计务实:rule → LLM (GPT-4o-mini) → FastText 的瀑布,把 expensive model 用在数据少处、cheap model 用在 data scale 处。Cost engineering 做得到位
- Cost number 公开且 itemized(Table 4),方便后续工作复用预算估计;$0.55/trajectory 对比 human annotation 数十美元有数量级优势
- +230% replay success rate 是有说服力的 ablation——证明了 tutorial 不是装饰而是核心,pipeline 的因果链清晰
- AT + M2W 互补结果好:训练数据非冗余,说明 AgentTrek 拓展了 Mind2Web 未覆盖的区域
Weaknesses
- WebArena 16.26% 并不强:32B 模型仍输给 in-domain RFT 的 AutoWebGLM (18.20),且远低于人类水平。说明 synthetic data 在最终 capability ceiling 上还有 gap,单靠 trajectory diversity 不够
- GPT-4o 作 evaluator 有 reward hacking 风险:训练数据由 GPT-4o 生成、又由 GPT-4o 筛选,相当于让老师自己判作业。84% acc 是在 558-sample human-validated set 上测的,但这个 set 的分布是否代表 full 23k 还是个问题
- 127 网站长尾问题未分析:diversity claim 缺少分布数据;如果 80% 轨迹来自 top-10 网站,generalization 实际更窄
- Pure-vision 选择缺 ablation:作者列了 token cost 等理由弃用 HTML,但没有同样规模下 vision-only vs vision+AXTree 的对照实验——HTML 真的是负担吗?还是只是为了简化系统设计
- Tutorial 来源偏 RedPajama 一个 snapshot,时效性 / 域覆盖未来如何 scale 不清楚
- README BrowserGym leaderboard 数 (AgentTrek-32b WebArena 22.40) 与论文 Table 5 (16.26) 不一致——可能是后续新版本,但论文里没解释这种差异
可信评估
Artifact 可获取性
- 代码: 开源(xlang-ai/AgentTrek),README 含 evaluation 脚本,但 Data Preparation / Training section 在 README 里标记 “cooking”
- 模型权重: AgentTrek-32B 已发布 (HF: xlangai/AgentTrek-1.0-32B);7B / 72B 标记 “cooking”
- 训练细节: 仅高层描述(backbone、单阶段 SFT、数据量),无超参 / batch size / learning rate / training steps
- 数据集: 部分公开(HF collection);数据合成 pipeline 代码未明确开源
Claim 可验证性
- ✅ VLM agent + tutorial guidance 显著提高 trajectory 合成成功率:400-task ablation, 52% vs 15.78%, gap 大且方向稳健
- ✅ AgentTrek + Mind2Web 联合训练在 Mind2Web 三 split 全部 SOTA:Table 7 数字明确
- ✅ ScreenSpot Web grounding 显著提升:30.7 → 67.4 同样 backbone (Qwen2-VL-7B)
- ⚠️ “$0.551/trajectory” cost claim:基于 44.4% replay success rate 折算,但 evaluator 84% acc 意味着实际 effective trajectory 还要再打折;真实 quality-adjusted cost 偏高
- ⚠️ “surpasses teacher GPT-4” claim (intro):在某些 benchmark 上 7B 学生超过 GPT-4o,但 GPT-4o 没在同 prompt format / action space 下评估过——比较不严格
- ⚠️ VLM evaluator 84% acc:自己生成自己评估的 confounding 没排除;human-validated set 的代表性未说明
- ⚠️ “覆盖 12 categories / 127 websites” diversity claim:缺分布数据,可能长尾严重
Notes
- AgentTrek 的核心 insight 用一句话讲:“网上有海量人类写的教程,就是免费的 trajectory plan,agent 只需要做 grounding execution 就够了”——这种把 plan / execution 解耦、把 plan 外包给 web text 的思路,对 GUI agent 数据合成是个开放但被低估的方向
- 如果 plan 来自 text 是最 cost-effective 的,那么下一个问题就是:什么任务 / 域里 tutorial 不存在或不够好?这些 long-tail 是否需要 self-instruct + human verification 补齐?
- 与 OS-Atlas / UI-TARS / OpenCUA 这条 GUI VLM 主线相比,AgentTrek 更专注 data pipeline 而非 model scaling;可作为这条线上 “data layer” 的代表工作
-
❓ tutorial 教的往往是 “标准做法”,而真实 user 的需求经常不标准 / 个性化。AgentTrek trajectories 是否会让 agent 在面对 underspecified goal 时更脆弱(因为 training set 全是 well-specified plan)?这值得 ablation
- 时间维度:教程对网站 UI 改版敏感。今天合成的 trajectory 一年后可能 grounding 全失效——pipeline 需要 continuous re-collection,这是 cost 的隐藏部分
Rating
Metrics (as of 2026-04-24): citation=69, influential=4 (5.8%), velocity=4.21/mo; HF upvotes=30; github 54⭐ / forks=2 / 90d commits=0 / pushed 427d ago · stale
分数:1 - Archived 理由:AgentTrek 是 GUI agent trajectory synthesis 方向的单点 pipeline 参考——ICLR 2025 Spotlight、+230% replay ablation 因果清晰,开源模型/数据,有 tutorial-as-supervision 的 transferable insight。定位在 data layer 而非方法范式奠基,WebArena 16.26 仍被 in-domain RFT 超过,且 tutorial-as-plan 未被 OS-Atlas / UI-TARS / OpenCUA 这条主线广泛采纳。2026-04 复核:发表 16 个月 cc=69 / ic=4(5.8%,无深度继承)/ velocity 4.21/mo,github 54⭐ / pushed 427d 深度 stale——社区未把它作为 GUI agent 数据合成的代表性 baseline,属”为某个具体问题查的一次性参考”。相邻不选 Frontier,因为缺”当前 SOTA 或必比 baseline”的证据;不选更低档是 replay ablation 与 tutorial-as-plan 作为 data pipeline 的 framing 仍有 readable value。