Summary
OS-ATLAS: A Foundation Action Model for Generalist GUI Agents
- 核心: 把开源 VLM 训成一个跨平台 GUI 基础动作模型,主要靠堆 grounding 数据和统一 action space。
- 方法: 自建多平台(Win/macOS/Linux/Android/Web)grounding 数据合成工具,得到 13M 元素 / 2.3M 截图的 corpus,先 grounding pre-train(OS-Atlas-Base)再 multitask 动作 fine-tune;在 fine-tune 阶段用 unified action space(Basic + Custom)解决 click vs tap 这种命名冲突。
- 结果: ScreenSpot 上 7B 版本平均 82.47(standard)/ 85.14(GPT-4o planner),显著超 SeeClick / Qwen2-VL-7B / 同期 UGround-7B;OSWorld(grounding mode)从 SeeClick 9.21 提到 14.63;多个 mobile/web/desktop agent benchmark 上零样本 OOD 超 GPT-4o。
- Sources: paper | website | github
- Rating: 3 - Foundation(ICLR 2025 Spotlight;OS-Atlas-Base 与 ScreenSpot-V2 已成为 GUI grounding 方向的 de facto baseline 与数据源;cc=272 / ic=73(26.8% 高继承率)验证方法被深度复用)
Key Takeaways:
- GUI grounding 是数据问题:开源 VLM 在 GUI 上落后于 GPT-4o 主要因为没在 GUI 截图上充分预训练;scale 13M element grounding corpus 之后,7B 模型 ScreenSpot 拿到 82+。
- Cross-platform corpus 的工程价值:作者把 Web 用 FineWeb URL + 整页 1920×1080 切片爬,desktop/mobile 用 AndroidEnv / OSWorld + 物理机 + A11y tree(pyatspi/pywinauto/ApplicationServices)DFS/Random Walk 自动遍历——这套 infra 比方法本身更稀缺。
- Unified action space 是 OOD 的关键:fine-tune 时把 17 个动作类型压到 10 个(合并 tap/click、home/press_home、type/input 等),ablation 显示去掉 unified action 在所有平台都掉点。
- Web-only pre-training 不够 transfer:“不同 GUI 都遵循类似设计原则”这个直觉只对了一半——只用 web 数据预训 mobile/desktop grounding 仍掉点,desktop 数据有独立价值。
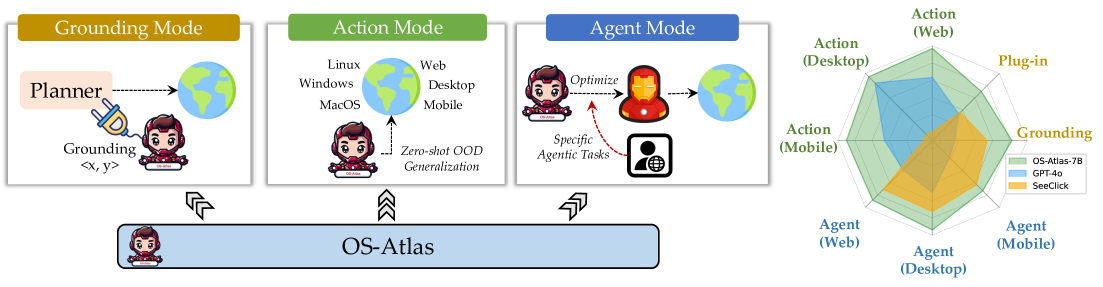
- 三种使用模式:Grounding mode(替换 GPT-4o agent 里的坐标预测模块)、Action mode(端到端零样本预测下一步动作)、Agent mode(在下游任务上 SFT);Grounding mode 配 GPT-4o 在 OSWorld 上表现最好。
Teaser. OS-Atlas 三种模式与整体性能对比。 左图展示 Grounding / Action / Agent 三种使用模式,右图是雷达图对比 OS-Atlas 与 GPT-4o、SeeClick、CogAgent 等在六个 benchmark 上的相对性能。
1. Motivation
作者把 open-source VLM-based GUI agent 落后于 GPT-4o 的原因归结为两点:
- 缺 GUI 截图预训练数据:现有 corpus 偏 web 和 mobile,desktop 几乎空白;且大多不开源或规模小。
- Action 命名冲突:mobile 的
tap和 desktop 的click逻辑等价但命名不同;这种异构性在多源数据 multitask 训练时拖累泛化。
❓ 第一点很容易被 trivial 化为 “数据不够”;但作者实际证据是 “scaling data 持续涨点”(Figure 3)+ “web-only 不能 transfer”(Figure 4)。这两条加起来才把”缺数据”具体化为”缺 cross-platform 数据”。
2. Method
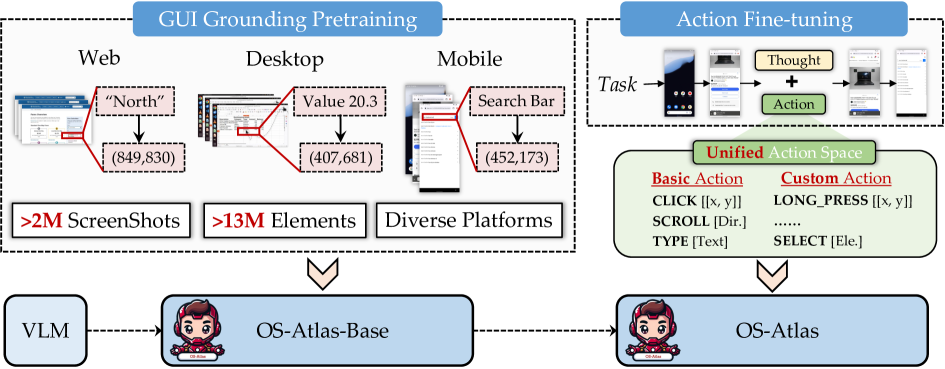
2.1 训练流程
两阶段:
- GUI Grounding Pre-training:输入
<screenshot, referring expression / instruction, coordinate>三元组,输出 element 坐标(point 或 bbox,归一化到 0-1000)。得到 OS-Atlas-Base。 - Action Fine-tuning:输入
<screenshot, task instruction, action history>,输出<thoughts, action type, action parameters>。得到 OS-Atlas。
Backbone 用两套:InternVL-2-4B(AnyRes 切 patch)和 Qwen2-VL-7B(任意分辨率→动态 visual token 数)。
Figure 2. Overall training pipeline.
2.2 Grounding 数据收集
Table 1. 数据规模对比。
| Dataset | Web | Mobile | Desktop | Open Source | Elements |
|---|---|---|---|---|---|
| SeeClick | 270K | 94K | - | ✓ | 3.3M |
| Ferret-UI | - | 124K | - | ✗ | <1M |
| GUICourse | 73K | 9K | - | ✓ | 10.7M |
| CogAgent | 400K | - | - | ✗ | 70M |
| OS-Atlas | 1.9M | 285K | 54K | ✓ | 13.58M |
Web:从 FineWeb(CommonCrawl 衍生)取 URL,爬 4M 页;不同于 SeeClick 只取上半屏,OS-Atlas 渲染整页再切 1920×1080,提升多样性。从 HTML 提取可点击元素(buttons / scrollbars / search bars / hyperlinks / 带 title 的 SVG)+ 坐标。规则过滤后剩 1.6M 截图 / 7.7M 元素,单页元素上限 10。
Desktop & Mobile:
| 平台 | 环境 | A11y API |
|---|---|---|
| Android | AndroidEnv | - |
| Linux | OSWorld | pyatspi |
| Windows | 物理机 | pywinauto |
| macOS | 物理机 | ApplicationServices |
模拟人机交互用 DFS + Random Walk 两种 exploration 策略遍历状态空间。
Instruction Grounding (IG) 数据:用 GPT-4o 标注现有轨迹数据集(Mind2Web / AMEX / AITZ),结合 Set-of-Mark prompting 让 GPT-4o 看清被操作元素。再加 AndroidControl + Wave-UI 的现成 IG 数据。
2.3 Unified Action Space
Basic actions(跨平台标准化):click、type、scroll。
Custom actions(用户/平台特定):例如 open_app、drag。Custom action 是支持 OOD 的关键——允许用户在推理时声明新动作。
量化收益:动作类型从 17 → 10,消除
tap/click、press_home/home、type/input等冲突。
3. Experiments
3.1 Grounding(ScreenSpot)
Table 2. ScreenSpot grounding accuracy. 关键行:
| Planner | Model | Mobile-Text | Mobile-Icon | Desktop-Text | Desktop-Icon | Web-Text | Web-Icon | Avg |
|---|---|---|---|---|---|---|---|---|
| - | SeeClick | 78.0 | 52.0 | 72.2 | 30.0 | 55.7 | 32.5 | 53.4 |
| - | Qwen2-VL-7B | 61.3 | 39.3 | 52.0 | 45.0 | 33.0 | 21.8 | 42.9 |
| - | UGround-7B | 82.8 | 60.3 | 82.5 | 63.6 | 80.4 | 70.4 | 73.3 |
| - | OS-Atlas-Base-4B | 85.7 | 58.5 | 72.2 | 45.7 | 82.6 | 63.1 | 70.1 |
| - | OS-Atlas-Base-7B | 93.0 | 72.9 | 91.8 | 62.9 | 90.9 | 74.3 | 82.5 |
| GPT-4o | OS-Atlas-Base-7B | 93.8 | 79.9 | 90.2 | 66.4 | 92.6 | 79.1 | 85.1 |
OS-Atlas-Base-7B 在不带 planner 的 standard setting 下就超过了带 GPT-4o planner 的 UGround-7B(82.5 vs 81.4)。
ScreenSpot 还被作者重新审计——发现约 11.32% annotation 错误,重发为 ScreenSpot-V2。
Figure 3. Data scaling 效果。 Grounding accuracy 和 IoU 都随数据量持续涨;IoU 在 web 域(~10M elements)涨势最明显,accuracy 涨势相对弱(因为 acc 不能捕获细粒度误差)。
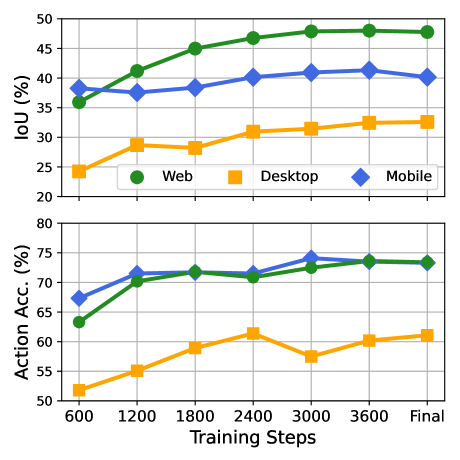
❓ “accuracy 还能往上推” 与 “需要更难 benchmark” 是同一个事实的两面——84% 的 ScreenSpot 离饱和不远,下一步评估应该看 IoU 或 ScreenSpot-Pro 类难数据。
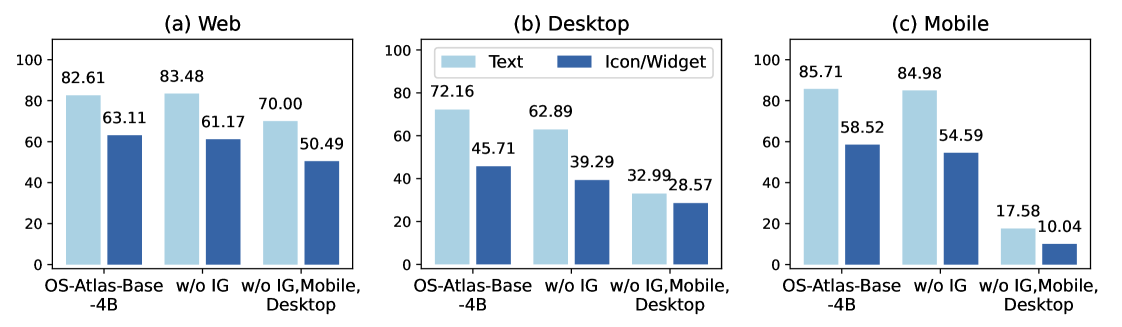
Figure 4. Pre-training 数据消融。 去掉 IG、再去掉 mobile/desktop(只剩 web)。结论:(1) REG 数据已足够强;(2) Web-only 不能泛化到 desktop/mobile,desktop+mobile 数据不可或缺。
3.2 Grounding Mode 应用:OSWorld
把 GPT-4o agent 里的坐标预测换成 OS-Atlas-Base:
Table 3. OSWorld success rate (%).
| Model | Avg |
|---|---|
| GPT-4o + SoM | 4.59 |
| GPT-4o (vanilla) | 5.03 |
| GPT-4o + SeeClick | 9.21 |
| GPT-4o + OS-Atlas-Base-4B | 11.65 |
| GPT-4o + OS-Atlas-Base-7B | 14.63 |
| Human | 72.36 |
14.63 vs Human 72.36 的差距说明 grounding 不是 OSWorld 的全部瓶颈——planner / long-horizon / error recovery 都有问题。OS-Atlas 的贡献限定在 grounding 这一环。
3.3 Agent Tasks(Action / Agent Mode)
Action fine-tuning 只用 AMEX (mobile) + AITZ (mobile) + Mind2Web (web) 三个数据集,留 5 个 benchmark 做 OOD 测试:AndroidControl、GUI-Odyssey(mobile);GUI-Act-Web、OmniAct-Web(web);OmniAct-Desktop(desktop,纯 OOD,训练完全没见过 desktop agent 数据)。
Table 4. Web & Desktop(关键 SR 列):
| Model | GUI-Act-Web SR | OmniAct-Web SR | OmniAct-Desktop SR |
|---|---|---|---|
| Zero-shot | |||
| GPT-4o | 41.84 | 34.06 | 50.67 |
| OS-Atlas-7B | 57.02 | 59.15 | 56.73 |
| SFT | |||
| Qwen2-VL-7B | 82.27 | 78.58 | 91.77 |
| OS-Atlas-7B | 82.70 | 93.56 | 94.05 |
Table 5. Mobile(关键 SR 列):
| Model | AndroidControl-Low SR | AndroidControl-High SR | GUI-Odyssey SR |
|---|---|---|---|
| Zero-shot | |||
| GPT-4o | 28.39 | 21.17 | 5.36 |
| OS-Atlas-7B | 50.94 | 29.83 | 26.96 |
| SFT | |||
| Qwen2-VL-7B | 82.56 | 69.72 | 60.23 |
| OS-Atlas-7B | 85.22 | 71.17 | 61.98 |
OS-Atlas-7B 在 6 个 OOD benchmark 上全部超过 GPT-4o;SFT setting 下也比从原始 Qwen2-VL/InternVL-2 fine-tune 更强,验证 OS-Atlas-Base 作为 foundation 的价值。
3.4 Ablation:Pre-training + Unified Action
Figure 5. Zero-shot OOD 上的 ablation。 去掉 pre-training(直接从原 VLM SFT)和去掉 unified action space 都掉点;desktop/web 受影响最大(这两个域 fine-tune 数据少甚至没有)。
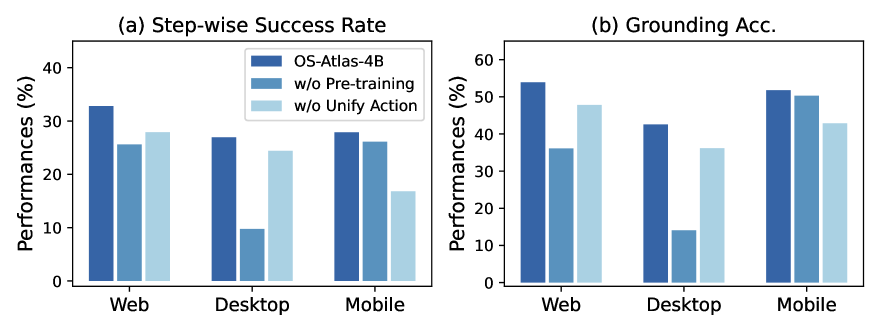
3.5 OS-Atlas-Pro
把所有 7 个 agent 数据集都用上做 multitask SFT(不再保留 OOD)。
Figure 6. OS-Atlas-Pro 平均 SR。
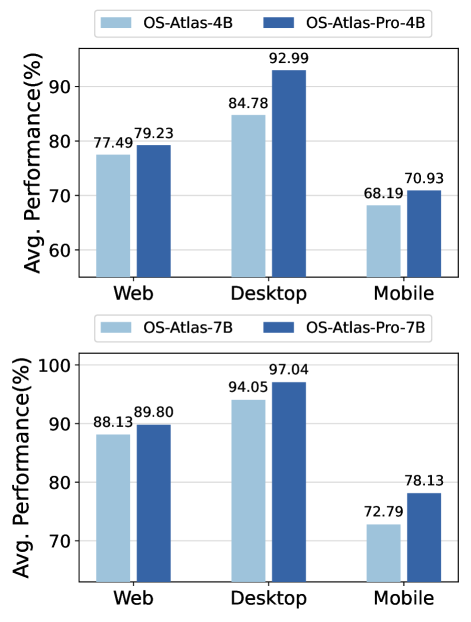
4. Demos
Video 1. VSCode:Hide __pycache__。
Video 2. Chrome:放大字号。
Video 3. Android:通过 Simple Messenger 发短信。
关联工作
基于
- InternVL-2-4B / Qwen2-VL-7B:两个 backbone VLM。
- AndroidEnv / OSWorld:分别提供 Android 和 Linux 模拟环境。
- FineWeb:CommonCrawl 衍生的 URL 来源。
- Set-of-Mark prompting:让 GPT-4o 标注 IG 数据时定位元素。
对比
- SeeClick (Cheng et al.):早期 GUI grounding 模型,OS-Atlas 在 ScreenSpot/OSWorld 多项指标上对位完胜。
- UGround-7B(concurrent work):同期 web-scaling grounding 模型;OS-Atlas 在 standard setting 下平均 +9.2 个点。
- CogAgent (Hong et al.):早期 GUI VLM,70M element 但闭源。
- Fuyu / GPT-4V:分别作为 baseline 和被 omit 的对照。
方法相关
- Mind2Web / AMEX / AITZ / AndroidControl / GUI-Odyssey / OmniAct / GUI-Act-Web:fine-tuning 与评测的 agent benchmark 套件。
- Ferret-UI / GUICourse:相关 GUI grounding corpus。
论文点评
Strengths
- 数据 infra 是真壁垒:跨 5 平台的合成工具链(FineWeb 爬 + AndroidEnv + OSWorld + 物理 Win/Mac + A11y tree DFS/Random Walk)+ 全部开源,是论文的核心贡献。13M elements / 2.3M screenshots 量级 + desktop 数据填了空白。
- ScreenSpot-V2 是社区贡献:审计出 11.32% 标注错误并发布修正版,比单纯刷分更有价值。
- Unified action space 设计简洁有效:Basic + Custom 两层结构既保持跨平台一致性又支持扩展,ablation 数据扎实(17→10 action types,性能稳定提升)。
- OOD 泛化证据强:OmniAct-Desktop 训练完全没见过 desktop agent 数据,零样本 SR 56.73 超 GPT-4o (50.67) ——证明 grounding pre-training 提供的视觉-动作先验是可迁移的。
- 对位评估清楚:Grounding mode(在 OSWorld 替换 GPT-4o 的 grounding 模块)和 Action mode(端到端预测)分别评测,避免把两件事混在一起报数。
Weaknesses
- Action fine-tuning 数据多样性窄:只用 3 个数据集(2 mobile + 1 web),desktop 完全没见过。“OOD 强”的 narrative 一部分是因为 ID 数据本就稀少。
- 没和 GPT-4o 在 grounding 上正面对位:作者主动 omit 了 GPT-4V/GPT-4o 在 ScreenSpot 上的数(理由是”well-studied 且表现差”);用纯专有数据对 SeeClick/UGround/Qwen2-VL 比较,省了一个常被问的对位。
- ScreenSpot accuracy 接近饱和:7B 模型 mobile-text 93%、desktop-text 91%,剩下空间小;论文自己也承认需要更难的 benchmark。
- OSWorld SR 14.63 离实用还远:OS-Atlas 只解决 grounding 一环,long-horizon planning / error recovery / 状态记忆都没碰;对”开源替代 GPT-4o”的定位有点 over-promised。
- 方法上没有 architectural novelty:本质是 VLM + 大规模 GUI grounding SFT;故事是”data infrastructure first”。这没问题,但限制了方法论意义上的引用价值——后续工作引用主要是为用数据/模型,而非 borrow 方法。
- Custom action 的 OOD claim 缺定量:论文强调 custom actions 支持”unseen actions defined by users”,但没单独 ablate 这一点,证据偏 anecdotal。
可信评估
Artifact 可获取性
- 代码: Inference + 部分训练(GitHub 仓库提供 Base-4B/7B 的 inference 脚本;training pipeline 部分开源)。
- 模型权重: OS-Atlas-Base-4B、OS-Atlas-Base-7B、OS-Atlas-Pro-4B、OS-Atlas-Pro-7B 全在 HuggingFace 发布。
- 训练细节: Appendix F 给出主要超参(per-backbone 学习率、batch size、训练 step 数),数据配比有概要描述但未完全披露每个 source 的精确比例。
- 数据集: OS-Atlas-data 全开源(HuggingFace),ScreenSpot-V2 单独发布;desktop 数据收集 infra 在 GitHub。
Claim 可验证性
- ✅ ScreenSpot SOTA:Table 2 有完整 per-platform per-modality 数;HF 模型可复现。
- ✅ OOD agent 超 GPT-4o:Table 4/5 涵盖 6 个 benchmark,SR 显著优势;OmniAct-Desktop 是真 OOD(未见 desktop agent 数据)。
- ✅ Grounding pre-training 在 fine-tune 阶段有正向贡献:Figure 5 ablation 直接对比 w/ vs w/o pre-training。
- ⚠️ “largest open-source cross-platform GUI grounding corpus”:13.58M elements 确实大,但 CogAgent 报的 70M elements(虽然非开源)量级更大;“open-source 中最大”是真的,去掉限定词就 over-claim。
- ⚠️ Unified action space 是 OOD 关键:ablation 显示 unified action 有用,但贡献来源没拆开(去 unified ≠ 去某个具体 conflict);degree of effect 与具体 dataset mix 强相关。
- ⚠️ “open-source alternative to GPT-4o”:Grounding 上 OS-Atlas-Base 可能成立;端到端 agent 在 OSWorld 仍 14.63 vs Human 72.36,这一标语在 grounding 之外的场景被 over-extend。
- ❌ “first LAM specifically designed for GUI agents”:这句在 Related Work 里出现,但 SeeClick / CogAgent / Ferret-UI 都可视为先驱;属于营销性 framing。
Notes
- Reading angle:作为”ICLR 2025 GUI 基础模型代表作”读,更看重的是数据 infra 和评估清晰度而非方法创新——这也是后续 GUI-Reflection / Aguvis / CogAgent-2 等工作的基线/数据来源。
- 复用价值:(a) ScreenSpot-V2 + 13M corpus 是高质量公共资源;(b) Unified action space 设计可作为后续 multi-source agent 训练的默认配方;(c) Grounding mode(外接 planner)的 modular 评估值得借鉴。
- 可挑战的方向:(1) 用 RL 而非 SFT 做 action fine-tuning 是否能进一步打破 SR 上限?(2) Custom action 的 zero-shot 扩展能力缺定量评估,可单独设计 benchmark;(3) OSWorld SR 14.63 的瓶颈是否真在 grounding?换更强 grounding 模型(e.g., Aguvis、UI-TARS)后还能再涨多少,是判断 grounding 是否饱和的好信号。
- ❓ Web 数据用 1920×1080 整页切片——这个分辨率对 mobile/desktop 真实截图分布是否 biased?没看到 cross-resolution 评估。
- ❓ A11y tree 在 macOS 上质量普遍较差(很多 app 不暴露完整 tree),论文没讨论这对 macOS 数据质量的影响;54K desktop 截图里 macOS 占比未知。
Rating
Metrics (as of 2026-04-24): citation=272, influential=73 (26.8%), velocity=15.28/mo; HF upvotes=49; github 443⭐ / forks=30 / 90d commits=0 / pushed 368d ago · stale
分数:3 - Foundation 理由:ICLR 2025 Spotlight,OS-Atlas-Base-7B 与 ScreenSpot-V2 已成为后续 GUI agent 工作(UIPro、OS-Sentinel、MGA 等)的标准 baseline / 数据源;开源权重 + 13M 跨平台 corpus 填补了 desktop 的数据空白,复用价值高(对应 Strengths 1-2 与 Notes 的”复用价值”)。Weaknesses 5 指出方法本质是大规模 grounding SFT、缺 architectural novelty;但 rubric 中 benchmark/dataset 类工作”已成为方向的 de facto 标准评测或基础数据”即可到 Foundation 档。2026-04 复核:cc=272 / ic=73(26.8% 远高于典型 ~10%,说明技术被实质继承)/ velocity 15.28/mo,社区影响力符合 Foundation 门槛;ScreenSpot-V2 已被 UI-TARS 等后续主流工作作为标准 grounding 评测——相邻档不选 Frontier,因为它不只是”最近 SOTA 之一”而是已定型为方向入口级资源;github stale 只反映原 repo 维护节奏,不削弱 benchmark/corpus 的奠基属性。