Summary
ComputerRL: Scaling End-to-End Online Reinforcement Learning for Computer Use Agents
- 核心: 用大规模分布式 online RL 训练 desktop computer-use agent,引入 API+GUI 混合动作空间和 Entropulse(RL/SFT 交替)来对抗 entropy collapse。
- 方法: API-GUI 动作范式(自动化 LLM workflow 生成应用 API) + 千级并行 Ubuntu VM 集群(qemu-in-docker + gRPC + AgentRL 异步 RL)+ Step-level GRPO + Entropulse 多阶段训练。
- 结果: AutoGLM-OS-9B(基于 GLM-4.1V-9B-Thinking)在 OSWorld 拿到 48.9%(从 BC 的 31.9% → RL2 的 45.8% 在 Qwen2.5-14B 上的消融),超过 OpenAI CUA o3 (42.9%)、UI-TARS-1.5 (42.5%)、Claude 4 Sonnet (30.7%)。
- Sources: paper | website | github
- Rating: 2 - Frontier(9B 开源模型在 OSWorld 超越 OpenAI CUA o3 / Claude 4 Sonnet,API-GUI + 千级并行 VM + Entropulse 是 desktop RL 落地的务实范式;但 API-GUI 依赖工程化的应用库、long-tail 泛化和 cross-OS 未验证,尚未到 de facto 标准)。
Key Takeaways:
- API-GUI 是主要 leverage point:在 GPT-4o 上做框架消融,纯 GUI 11.2% → API+GUI 26.2%(+134%),Office 域 6.2%→27.9%。这意味着相当一部分 OSWorld 上的 SOTA 提升来自工程化的 API 注入而非 RL 算法本身。
- Entropulse = 周期性 SFT 重置 entropy:RL 收敛后,挑选历史成功 rollout 做 SFT,恢复探索能力,再继续 RL。比 DAPO 提高 clip 阈值更有效(后者会减慢策略改进)。在 14B 上带来 +3.8%(41.5% → 45.8%)。
- 千级并行 VM 是 RL 落地 desktop 的真正瓶颈:基于 OSWorld 重构,用 qemu-in-docker + gRPC,使千级并行 Ubuntu VM 实例可行。这是 infrastructure 而非 algorithm 的贡献。
- 9B 模型超越闭源 SOTA:核心路径是 BC 冷启动(180k+ 正确步)→ Step-level GRPO → Entropulse → 第二轮 RL,这套配方迁移到 GLM-4-9B 和 GLM-4.1V-9B 都 work。
Teaser. ComputerRL 框架总览:API-GUI 动作范式 + 千级并行 Ubuntu VM + 全异步 RL。
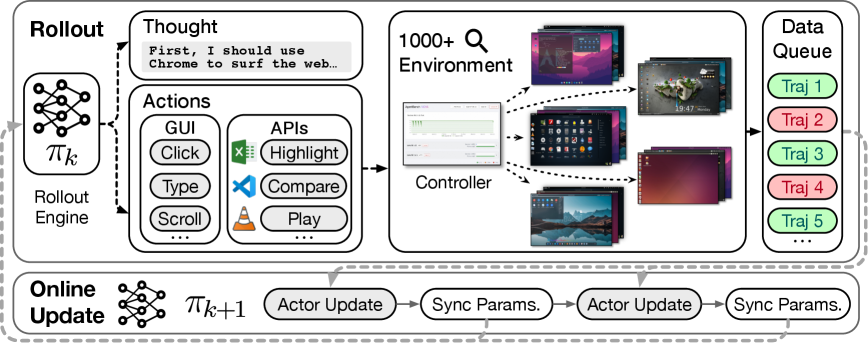
1. 动机:为什么 desktop agent 难做
三大障碍:
- GUI 是为人设计的:纯模拟点击/键盘对 agent 是低效且脆弱的范式。
- BC/distillation 不 scale:人工标注昂贵;蒸馏受限于教师模型上限;两者泛化和错误恢复能力都差。
- RL 在 desktop 上未真正 scale:环境慢、不稳定、收敛慢,加上 entropy collapse / KL 漂移这类已知病症。
ComputerRL 的回应方式分别是:(1) 引入 API 通道;(2) 千级并行 VM 解决数据通量;(3) Entropulse 解决长程训练 stagnation。
2. ComputerRL 框架
2.1 API-GUI 范式
❓ 这是论文最重要的工程 trick,但也是最容易被忽视的 confounder——后面的 SOTA 数字到底有多少来自 RL 算法、多少来自 API 工具集?消融部分给出了答案(见 §4.3)。
设计动机:纯 GUI 操作低效(要多步点击才能完成一个动作),纯 API 又有实现复杂度和安全限制。所以在 system prompt 里同时暴露 API 函数和 GUI 原语,agent 自行选择。
API 自动构建 workflow(Appendix A)三阶段:
- Requirement Analysis:用户给 task example,LLM 提取所需功能,与已有 API 对比补缺。约束 API 为 general-purpose,避免泛滥。
- API Implementation:用 Python 库(如 LibreOffice 的 UNO API)实现,加 error handling 和 logging。
- Test Case Generation:自动生成测试用例,验证 (1) 无 runtime error,(2) 参数下结果正确。失败则 LLM 自我修正。
最终 API 数量(Appendix B Table 5):
| Application | Number of APIs |
|---|---|
| Code | 12 |
| Chrome | 11 |
| LibreOffice Calc | 27 |
| LibreOffice Impress | 22 |
| LibreOffice Writer | 19 |
| VLC | 12 |
| Total | 103 |
GUI 原语动作空间(Appendix B Table 4):open_app, click, type, drag_and_drop, scroll, switch_window, hotkey, quote, wait, exit,共 10 个。
观测:用 pyatspi(Python Accessibility Toolkit SPI)抽 a11y tree,元素表示为 tag text position(x,y) size(w,h)。多模态版本去掉 a11y tree,改用 1080p 截图缩放到 1280×720。
2.2 千级并行 Ubuntu 环境
基于 OSWorld 重构,针对四大痛点:
- 资源/稳定性:原始 VM 在高并发下 CPU 占用爆炸、易冻死。
- 网络瓶颈:高负载下连接失败、IP 丢失。
- 缺少分布式:OSWorld 不支持多节点 cluster。
解法:
- Standardized API:通过 AgentBench 接口解耦环境与计算后端。
- Lightweight VM:qemu-in-docker,瘦身镜像。
- gRPC cluster:CPU 节点串成集群,集中资源调度。
- Web monitoring:实时可视化 env / agent / 资源状态。
声称支持千级并发——这是这篇文章的核心 infra 贡献,也是其他人想复现 RL 训练的最大门槛。
2.3 全异步 RL Framework
基于自家 AgentRL 框架。核心设计:
- Resource Partitioning:rollout 与 trainer 物理隔离,trainer 从 replay engine streaming 取数据。
- Dynamic Batch Sizing:trainer 用变长 batch,减少 idle。
- Modular Component Isolation:actor / reference / critic 独立资源,PyTorch distributed groups + NCCL 共享参数。
- Off-policy Bias Mitigation:限制 replay buffer 大小,每次 update 后同步轨迹,让 trajectory 接近最新 policy。
❓ 这部分讲得很笼统,没有给出 throughput / GPU 利用率的具体数字(只说 “high average power consumption per GPU”),可信度打折。
3. ComputerRL 训练流程
三阶段总览(Figure 4):
- BC 冷启动:用通用 LLM 收集轨迹做 SFT
- RL Phase 1:Step-level GRPO + verifiable rule-based reward
- Entropulse:用历史成功 rollout 做 SFT 恢复 entropy,然后 RL Phase 2
3.1 Behavior Cloning 冷启动
任务:8k tasks(人工初始 + 增强),每个任务有对应的 evaluation function(rule-based)。
轨迹收集 pipeline(核心是用 model pool 解决 single-model 数据同质化):
- Initial Sampling:闭源 LLM 多次采样每个任务,记录轨迹和 eval 结果。
- Outcome Stratification:按准确率分三档:Fully Solved (acc=100%)、Partially Solved (0<acc<100%)、Unsolved (acc=0%)。
- Stratified Augmentation:
- Partially solved → 用初始轨迹 SFT backbone,再用 SFT model 重新采样以扩展覆盖。
- Unsolved → 维护 high-performing model pool,每个 action 随机选一个模型决定。利用模型间互补性。
最终保留 180k+ 正确步,做 SFT。
❓ 第三步的 random per-action model selection 有点 hack——本质是用 ensemble 多样性碰运气,trajectory 内部一致性可能很差。但能把零样本搞出来就够了。
3.2 Step-Level GRPO
把 GRPO 推广到 step-level:每个任务采 G 条轨迹,第 i 条有 步 action。所有 step 跨轨迹共同 group 起来计算 advantage。
Equation. Step-Level GRPO objective
Reward Design:rule-based verifier 给整条轨迹打 binary 成功/失败;成功轨迹的每个正确格式的 step 都给 reward 1,否则 0。不沿 Bellman 反向传播——每个 (prompt, response) 视为独立训练样本,reward 直接来自 trajectory 结果。
❓ “treats each prompt-response pair as an independent training instance” + “rewards based on the final trajectory outcome” 听上去有点矛盾。读起来像是:成功轨迹的所有 well-formatted step 都拿 1,失败的全 0。这比真正的 trajectory return 更粗糙,但因为是 group-normalize 的 advantage,加上 step 数归一化,应该能稳定。
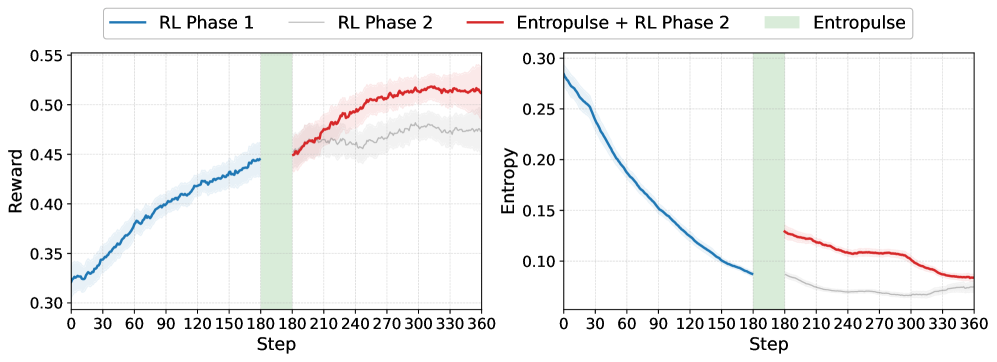
3.3 Entropulse:抗 entropy collapse 的多阶段训练
观察的病症:RL 跑几百步后 reward 平台、entropy 持续下降、KL 漂移升高。
已有方案的缺陷:DAPO 抬高 clipping 阈值能缓解 entropy 下降,但严重拖慢 policy improvement。
Entropulse 配方:
- RL 训练时聚合所有成功 rollout 轨迹(来自不同训练步、不同 policy)。
- 每任务随机挑选若干条成功轨迹,构造新的 SFT 数据集。优点:质量高(都成功)、多样(来自不同 policy)、无需新 rollout。
- 用这个 SFT set 训练一轮 → policy entropy 回升,evaluation 性能基本不变。
- 在抬高的 entropy 上做 RL Phase 2,进一步突破。
Figure 5. RL 训练曲线:红线(带 Entropulse)vs 灰线(仅 reset reference model)。Entropulse 把 entropy 拉回去,并允许 RL Phase 2 继续提升。
4. 实验
4.1 OSWorld 主结果
Table 1. AutoGLM-OS vs SOTA on OSWorld / OSWorld-Verified
| Agent Model | Params | OSWorld | OSWorld-Verified |
|---|---|---|---|
| Proprietary | |||
| Claude 3.7 Sonnet | - | 28.0 | 35.8 |
| Claude 4.0 Sonnet | - | 30.7 | 43.9 |
| Agent S2 w/ Claude-3.7 | - | 34.5 | - |
| OpenAI CUA 4o | - | 38.1 | 31.3 |
| Agent S2 w/ Gemini-2.5-Pro | - | 41.4 | 45.8 |
| UI-TARS-1.5 | - | 42.5 | - |
| OpenAI CUA o3 | - | 42.9 | - |
| Open | |||
| Qwen2.5-VL-72B | 72B | 8.8 | 5.0 |
| UI-TARS-72B-DPO | 72B | 24.6 | 27.1 |
| UI-TARS-1.5-7B | 7B | 26.9 | 27.4 |
| UI-TARS-7B-1.5 + ARPO | 7B | 29.9 | - |
| ComputerRL (ours) | |||
| w/ GLM-4-9B-0414 | 9B | 48.1 ± 1.0 | 47.3 |
| w/ GLM-4.1V-9B-Thinking | 9B | 48.9 ± 0.5 | 48.0 |
声称用 API-GUI 后完成任务的步数最多只需最强 baseline 的 1/3。
4.2 OfficeWorld(自建 benchmark)
180 tasks,来自 SpreadsheetBench + PPTC + 自研 Writer 任务,整合到 OSWorld 框架。
Table 2. OfficeWorld 结果
| Agent Model | Word | Excel | PPT | Average |
|---|---|---|---|---|
| DeepSeek-V3.1 | 6.7 | 35.0 | 21.7 | 21.1 |
| Claude 4.0 Sonnet | 18.3 | 35.0 | 20.0 | 24.4 |
| GPT-4.1 | 21.7 | 25.0 | 28.3 | 25.0 |
| OpenAI o3 | 23.3 | 36.7 | 41.7 | 33.9 |
| ComputerRL w/ GLM-4-9B | 21.7 | 58.3 | 43.3 | 41.1 |
| ComputerRL w/ GLM-4.1V-9B | 30.0 | 58.3 | 41.7 | 43.3 |
❓ 注意:所有 baseline 都用 “same framework (with tools)” 测——也就是说 baseline 也用了 API-GUI,所以这里的差距更纯粹反映 RL 训练的效果。但同时这个 benchmark 是作者自建,task 数据可能与训练分布更接近。
4.3 Ablation(核心信息量)
Table 3. 框架与训练消融(OSWorld 五域)
| Method | OS | Office | Daily | Professional | Workflow | Avg. |
|---|---|---|---|---|---|---|
| Framework Ablation (w/ GPT-4o) | ||||||
| GUI Only | 41.7 | 6.2 | 12.3 | 14.3 | 7.5 | 11.2 |
| API-GUI | 52.6 | 27.9 | 25.7 | 41.6 | 10.8 | 26.2 |
| Training Ablation (Qwen2.5-14B) | ||||||
| Untrained | 20.8 | 17.2 | 19.7 | 22.9 | 3.3 | 15.2 |
| + BC | 54.2 | 35.0 | 37.2 | 45.8 | 10.8 | 31.9 |
| + RL Phase 1 | 83.3 | 46.1 | 45.1 | 56.3 | 16.1 | 42.0 |
| + Entropulse | 75.0 | 42.3 | 50.6 | 52.1 | 18.9 | 41.5 |
| + RL Phase 2 | 83.3 | 46.2 | 46.7 | 60.4 | 27.2 | 45.8 |
关键读数:
- API-GUI 单独贡献 +15 points(11.2 → 26.2)on GPT-4o
- BC → RL1 贡献 +10.1 points(31.9 → 42.0)
- Entropulse → RL2 再贡献 +3.8 points(41.5 → 45.8)
- Workflow 域提升最大(10.8% → 27.2%),其他域已接近天花板
所以:API-GUI 的工程贡献 >> RL 算法本身的边际贡献。读者应该把这篇当作 “怎么搭建一个能把 desktop RL scale 起来的 stack”,而不是 “一个新的 RL 算法”。
4.4 Error 分析
四类错误:visual perception、multi-app coordination、operational illusions(agent 以为做了某事但其实没成功)、其他。具体百分比见 Figure 6。
关联工作
基于
- OSWorld: benchmark + 环境基础,ComputerRL 重构其 VM 层做大规模并行。
- DeepSeekMath / GRPO: 把 GRPO 推广到 step-level,用于 agent RL。
- AgentRL framework: 异步 RL 训练框架,本文用其做 desktop agent 训练。
- AgentBench: 环境接口标准化,用其 API 解耦 env 和 backend。
对比
- UI-TARS / UI-TARS-2: 纯 GUI screenshot-based 范式,本文 API-GUI 的对照面。
- OpenAI CUA (o3 / 4o): 闭源 SOTA computer-use agent,本文宣称超越。
- Claude 4 Sonnet (computer use): 闭源 baseline,OSWorld 30.7%。
- Agent S2: hierarchical reasoning + 外部 grounder 的对照范式。
- OS-Atlas: foundational GUI action model。
- CogAgent: 早期多模态 GUI 理解的代表。
方法相关
- DAPO: 通过抬高 clip threshold 抗 entropy collapse 的对照方法,本文 Entropulse 是替代方案。
- ARPO: 在 UI-TARS-7B 上 +RL 的工作,UI-TARS-7B-1.5 + ARPO = 29.9% on OSWorld。
- ZeroGUI: VLM 自动生成任务和 reward 估计。
- Verl / AReaL: 异步 RL framework 的相关工作。
- Windows Agent Arena: Windows 上 150+ 任务的 desktop benchmark,本文未在该 benchmark 测试。
- WebArena: web-only benchmark,本文 related work 中作为 limitation 案例提及。
论文点评
Strengths
- Infrastructure 贡献扎实:千级并行 Ubuntu VM 是 desktop RL 落地的真瓶颈,这套 qemu-in-docker + gRPC + AgentRL 异步训练 stack 是社区可以受益的工程基础。
- API-GUI 框架的 motivation 清晰:纯 GUI 是 human-centric 范式,对 agent 不友好;用 LLM 自动生成 application API 是合理的 augmentation。消融数字也支持这个 claim。
- Entropulse 是务实的 trick:用历史 successful rollout 做 SFT 来恢复 entropy,比 DAPO 这种 in-training 调 clip threshold 更直接。属于 RL workflow 层面的工程化设计,可复用。
- 9B 模型超越 OpenAI CUA o3 / Claude 4 Sonnet:在 OSWorld 上的数字若可复现,是开源模型在 desktop agent 任务上的强信号。
- 诚实的消融:明确显示 API-GUI 自身在 GPT-4o 上就有 +15 points,没有把所有功劳都归给 RL。
Weaknesses
- API-GUI 的 generalizability 存疑:当前只覆盖 6 个应用、103 个 API。新应用需要走一遍 LLM workflow + 人工兜底,长尾 application 上的可扩展性没被验证。这个 paradigm 本质上把 desktop 的世界 collapse 成了 “热门应用 + GUI fallback”,对真实的 long-tail desktop 任务可能脆弱。
- OfficeWorld 是自建 benchmark:作为 ComputerRL 训练数据来源(SpreadsheetBench + PPTC 是公开的)的近邻,可能存在 train-test 分布污染。论文没说训练任务和 OfficeWorld 之间的去重情况。
- Step-level GRPO 的 reward 设计粗糙:成功轨迹所有 well-formatted step 都拿 reward 1 — 这把”成功路径上的好动作”和”成功路径上恰好 well-formatted 但其实可有可无的动作”画上等号。在 multi-step task 中可能会强化一些冗余行为。
- 异步 RL 的细节缺失:除了几个 bullet point,没有 throughput 数字、GPU 利用率数据、rollout 与 update 之间的 lag 分析。这是工业级系统论文里最该量化的部分。
- 没有 cross-OS 评估:仅 Ubuntu。Windows、macOS 没碰,generalization claim 不完整。也没有真正的 cross-application 任务(比如要求 agent 自己组合从未见过的应用)。
- Entropulse 的 ablation 不彻底:Table 3 显示 Entropulse 单独 from RL1 反而轻微下降(42.0 → 41.5),价值要等到 RL2 才显现。但论文没对比 “RL1 → 直接 RL2(不 Entropulse)” vs “RL1 → Entropulse → RL2”,无法分辨提升来自 Entropulse 本身还是单纯多训了一阶段。Figure 5 的对比项是 “reset reference model”,不完全等价。
可信评估
Artifact 可获取性
- 代码:inference + 评估代码已开源(基于 OSWorld 改的 evaluation harness),训练代码未开源(只有 evaluation 的
run_autoglm.py系列)。 - 模型权重:已发布,ModelScope 上
shawliu9/computerrl-glm4-9b(text-only)和shawliu9/computerrl-glm4_1v-9b(多模态)。也可以zai-org/autoglm-os-9b。 - 训练细节:超参在 Appendix D(未读到详细数字,论文说 in appendix);BC 数据规模披露(180k+ steps、8k tasks),RL 数据配比未详细披露。
- 数据集:OSWorld 公开;OfficeWorld 部分公开(基于 SpreadsheetBench + PPTC + 自研 Writer 任务,README 给了 ModelScope cache 链接
shawliu9/OfficeWorld,但 Writer 任务的具体内容未单独说明)。
Claim 可验证性
- ✅ AutoGLM-OS-9B 在 OSWorld 48.9%:模型权重 + 评估代码 + 公开 benchmark,可第三方复现。
- ✅ API-GUI 框架 ablation (+15 pts on GPT-4o):用公开 GPT-4o + 公开 OSWorld + 公开 API code 应可复现。
- ⚠️ 千级并行 VM:“thousands of parallel environments” 没有给具体数字(500? 2000?),也没给 VM 启动延迟、稳定性 MTBF 之类的硬指标。Web monitoring 截图也没放。
- ⚠️ API-GUI 让 step 数减到最强 baseline 的 1/3:没有给具体 step 数对比表,只是文字 claim。
- ⚠️ Entropulse 比 DAPO clip 阈值方法更好:Figure 5 的 baseline 是 “reset reference model”,不是 DAPO,对比不直接。
- ❌ 无明显的 marketing 修辞。
Notes
- 真正的 takeaway 不是 “RL 在 computer-use 上 work”——是 “如果你想让 RL 在 desktop 上 work,你需要的不是更聪明的算法,是 (a) 一个能跑千级并发的 infra、(b) 一套丰富的 API 工具集、(c) 一种避免 entropy collapse 的训练 schedule”。这与 LLM agent RL 的整体趋势一致:bottleneck 在 environment / data scaling,不在算法。
- API-GUI 范式值得追:长期来看,纯 GUI screenshot agent 是否是 computer-use 的终极形态是个开放问题。给 agent 暴露一组结构化 API(哪怕是 LLM 自动生成的)可能是更务实的路线。但需要回答:API 集合如何随长尾应用持续生长?API 调用与 GUI 操作的 routing 决策能否泛化到没见过的 API?
- 与 UI-TARS-2 的对比值得做:UI-TARS-2 是 pure-GUI screenshot-only 的代表,ComputerRL 是 API+GUI hybrid 的代表,两者在 OSWorld 上的数字、推理时延、长尾应用上的 robustness 应有显著差异。
- Entropulse 的本质:把 RL 收敛后的成功 rollout 当 “high-quality offline data” 重新做 SFT,使 policy 重新铺开,再接 RL。这与 self-improvement / iterative RL+SFT 的思路一致(如 STaR、ReST)。是否能进一步用 reject sampling + DPO 替代 SFT,可能是延伸方向。
- Step-level GRPO 是否真有必要?GRPO 的 group-relative advantage 在 trajectory level 也能做。把 step 跨轨迹 group 起来归一化,理论上的好处是 fine-grained credit assignment,但论文没消融 trajectory-level vs step-level GRPO,无法判断必要性。
- 想进一步追:(1) GLM-4.1V-9B-Thinking 在多模态 GUI 上比 GLM-4-9B 仅 +0.8 pts,说明视觉信号对当前 task 边际不大?还是 a11y tree 已经太强?(2) “operational illusions” 这一类错误的具体例子,对设计 verifier 很有启发。
Rating
Metrics (as of 2026-04-24): citation=19, influential=4 (21.1%), velocity=2.35/mo; HF upvotes=3; github 27⭐ / forks=6 / 90d commits=0 / pushed 168d ago
分数:2 - Frontier 理由:9B 开源模型在 OSWorld 取得 48.9%,在笔记主结果表中明确超越 OpenAI CUA o3 (42.9%)、UI-TARS-1.5 (42.5%)、Claude 4 Sonnet (30.7%),是当前 desktop computer-use agent 的强 baseline,模型权重与评估代码已开源(AutoGLM-OS-9B、computerrl-glm4_1v-9b),值得作为主要对比项。够不到 Foundation 的原因在 Weaknesses 已列:API-GUI 仅覆盖 6 应用 103 API,long-tail 泛化和 cross-OS 未验证,训练代码未开源,异步 RL 细节缺失——尚未成为方向的 de facto 标准,更接近 “当前 SOTA + 重要范式代表”。高于 Archived 因为它不是 incremental 工作,而是给 desktop RL 提出了一套可被后续工作继承的 stack。