Summary
WindowsAgentArena: Evaluating Multi-Modal OS Agents at Scale
- 核心: 把 OSWorld 框架移植到真实 Windows 11 OS 上,构建 154 个跨应用任务的 agent benchmark,并通过 Azure 容器化 VM 实现”全 benchmark 20 分钟跑完”的并行评估
- 方法: Docker + QEMU/KVM 封装 Win11 VM;任务 JSON 包含 setup script + 自动化 reward function;同时发布 Navi agent,用 SoM (Set-of-Marks) 把 UIA accessibility tree、OCR、icon detector、Omniparser 多源信息叠加到截图上喂 VLM
- 结果: 最佳 Navi 配置 (UIA + Omniparser + GPT-4V-1106) 取得 19.5% 成功率,远低于人类 74.5%。Office / Windows Utils 几乎全 0%;Web Browser、Windows System 相对最好
- Sources: paper | website | github
- Rating: 2 - Frontier(Windows OS agent 评测的代表性 benchmark + 可 scale 的云端评估基础设施,被后续 OS agent 工作作为重要参考,但 154 任务规模和 zero-shot-only 结果限制其成为 de facto 标准)
Key Takeaways:
- OS-level benchmark 的价值在 task realism + scalable eval:跟 OSWorld 区别不在 OS 选择本身,而在用 Azure ML job 把每个 task 分发到独立 VM,把单机串行的”几天”压到 20 分钟。
- SoM 质量是 zero-shot VLM agent 性能的关键瓶颈:单纯像素 OCR/icon 检测 vs 加上 UIA accessibility tree,GPT-4V 的成功率从 12.5% 涨到 19.5%(相对提升 57%)。“看得懂屏幕” 比 “推理强” 更稀缺。
- Visual-language mis-alignment 是常见 failure mode:agent 文本说 “click 红色”,但选了 SoM ID 对应的黄色——VLM 训练分布里没有”上百个小标号的截图”这种数据。
- Generalist VLM 远未饱和:19.5% vs 74.5% human 的 gap,跟 OSWorld / AndroidWorld 的 gap 量级一致——说明 OS agent 的瓶颈不在 OS 选择,而在底层模型的 grounding 能力。
Teaser. WindowsAgentArena 的整体框架与多任务覆盖范围。
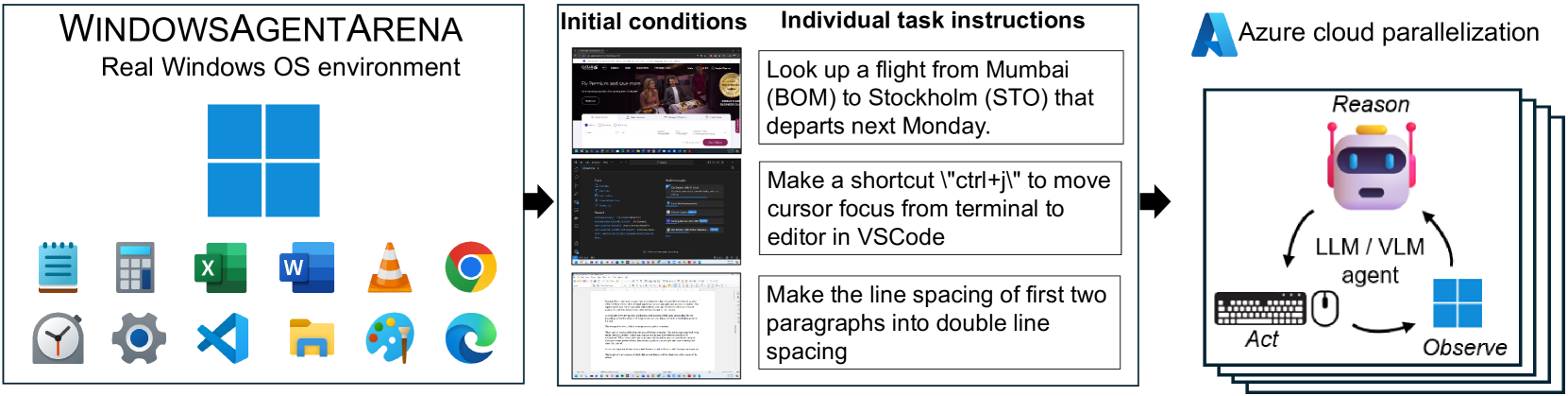
1. Motivation 与定位
现有 agent benchmark 有两个 pain point:
- Modality / domain 受限:text-only Q&A、web navigation、coding 各自为政,跟人类真实跨应用工作流脱节。
- 评估慢:multi-step 任务串行跑完一遍 benchmark 要 days。OS 不是物理仿真,没法”加速时钟”——多个进程异步运行,仿真速度等于 wall clock。
OSWorld 已经把”真实 OS”塞进 benchmark,但聚焦 Linux,且并行只能在单机内开多 VMware VM(受单机内存/CPU 限制,最多个位数)。Windows 占 73% 桌面市场份额却没人做。WindowsAgentArena (WAA) 的定位就是 Windows 版 OSWorld + Azure-native 并行。
❓ “Windows 占 73% 市场” 作为研究 motivation 有点弱——真正的技术 motivation 应该是 Windows 上有 UIA accessibility tree 这种结构化信号,跟 Linux/macOS 的 a11y stack 行为差异大。论文没强调这点。
2. 环境设计
2.1 任务形式化(POMDP)
标准的 POMDP 。Agent 在每一步看到 ,输出 ,直到 DONE/FAIL 或超过 。Reward 在终止时返回 [0,1]:binary 任务返 0/1,相似度任务返小数。
2.2 Observation Space
Agent 每步能看到:
- 任务指令 + clipboard 内容(文本直接拷,图像用 VLM 生成 caption)
- Foreground / background 窗口标题(pygetwindow 抓取)
- 当前屏幕截图(1440×900 RGB)+ 上一步截图
- UIA tree(pywinauto 抓取,不直接喂给 agent,而是用来生成 SoM 标记)
2.3 Action Space
两套并存:
- Free-form pyautogui / Python 代码执行:最大灵活性。
- Computer class wrapper:把 mouse / keyboard / clipboard / OS / window manager 封装成结构化函数。关键能力是
mouse.move_id(id)——直接按 SoM 标号交互,不用算绝对像素坐标,大幅降低 grounding 难度。
Table 1. Computer class actions.
| Group | Functions |
|---|---|
computer.mouse | move_id(id), move_abs(x,y), single_click(), double_click(), right_click(), scroll(direction) |
computer.keyboard | write(text), press(key) |
computer.clipboard | copy_text(text), copy_image(image), paste() |
computer.os | open_program(program) |
computer.window_manager | switch_to_application(window) |
2.4 Reward:Execution-based
跟 OSWorld 一样用后处理脚本判断完成:读系统/app settings、对比文件内容、或动态调用 web API 验证。关键是不要求 agent 复刻人类轨迹,只看终态——这给 agent 解题的自由度。
3. 任务 Curation
154 个任务,覆盖典型 Windows 用户工作流:
- Office: LibreOffice Calc / Writer
- Web Browser: Microsoft Edge, Google Chrome
- Windows System: File Explorer, Settings
- Coding: VS Code
- Media & Video: VLC Player
- Windows Utils: Notepad, Clock, Paint
任务来源:约 2/3 从 OSWorld Linux 任务移植(改文件路径、把 bash 改成 PowerShell、Edge/Chrome 反向代理改造、修订 evaluator 函数);剩余 1/3 从零创建覆盖 Windows-specific 应用。
任务定义:每个任务一份 JSON:
- 自然语言指令(“Make the line spacing of first two paragraphs into double line spacing”)
- Setup script(下载文件、打开应用)
- Evaluator 元数据 + Python 比对脚本
人类基线:74.5% 成功率,最高 Windows Utilities 91.7%,最低 VLC Player 42.8%(VLC 的 UI 本身对人都不友好)。
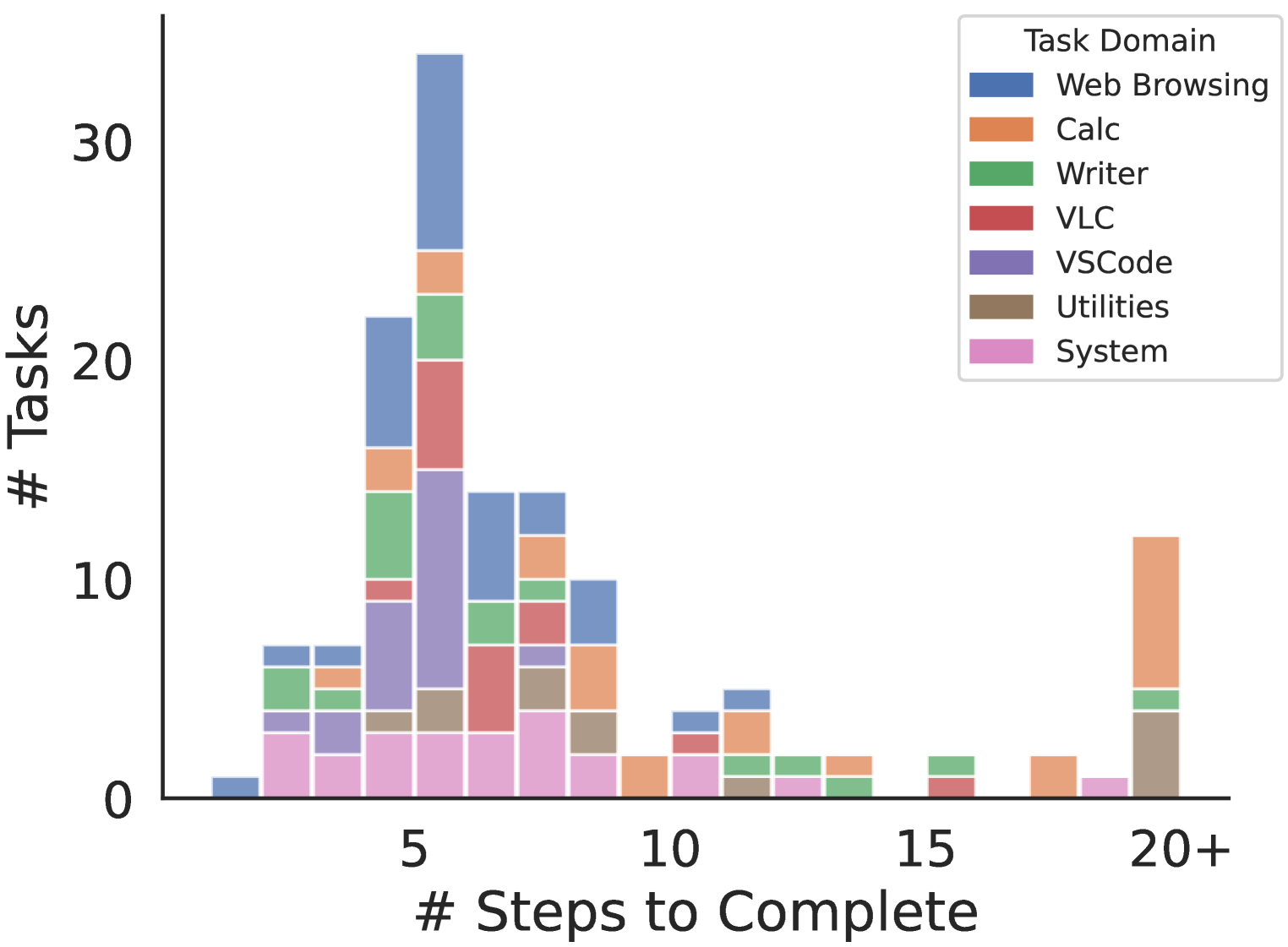
4. Deployment Infrastructure
WAA 真正的工程贡献在这。
架构:
- 外层:Docker container(windowsarena/winarena)
- 内层:QEMU + KVM 跑 Windows 11 VM(adapted from dockur/windows)
- VM 内:Python Flask server,作为 client 进程和 OS 之间的桥梁——接收命令、在 VM 内执行、返回 observation
Local 部署:WSL 或 Ubuntu。把 OS image 和 code 通过 volume mount 进 container,避免每次 rebuild。
Cloud 部署:用 Azure Machine Learning jobs 拉起 N 个 compute instance,每个跑一个 task。Win11 snapshot 和日志存在 Azure Blob Store。任务平均分发到 worker,结束后聚合结果。
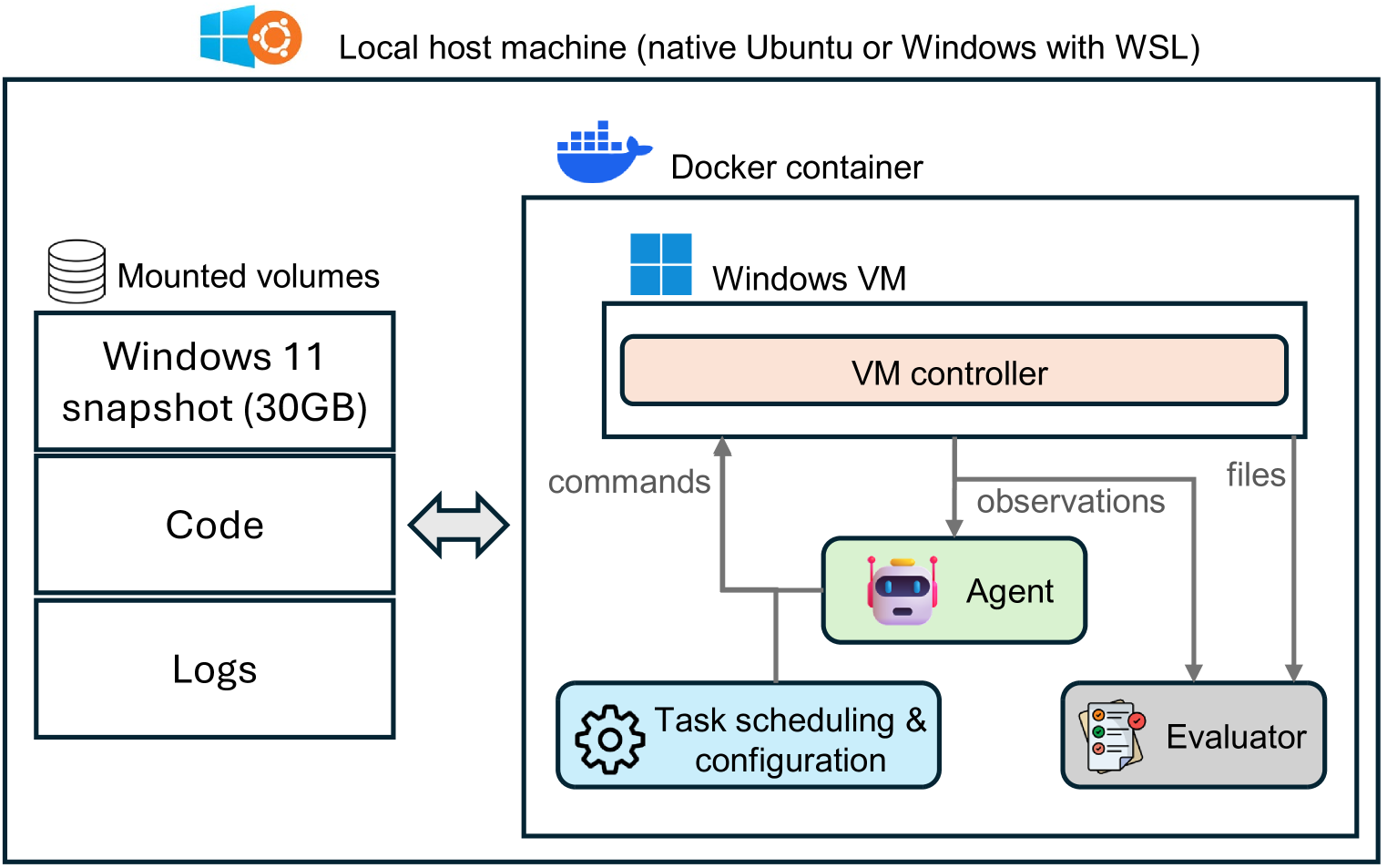
对比 OSWorld 的并行方式:OSWorld 在单机起多个 VMware VM——受单机资源限制;WAA 把 worker 数量上限抬到等于任务数。论文报告全 154 任务并行评估只需约 20 分钟(Appendix A.7)。
Security:Docker 隔离 + VM 端口不暴露公网,所有通信走本地。这对 OS agent 这类有 destructive action 能力的系统是必要的。
❓ 一个隐性成本:Win11 license 限制让 Microsoft 没法发预制 snapshot——用户得自己从 Microsoft 服务器拉 trial image,跑脚本配置。这降低复现性,且 trial 过期后任务初始状态会不会受影响没说。
5. Navi Agent 设计
5.1 输入处理
Navi 是 zero-shot prompted VLM agent,用 chain-of-thought prompting。每步喂给模型:
- 任务指令 + Computer class 描述 + action history + clipboard + memory block
- 当前截图(带 SoM 标注) + 上一步截图
SoM 来源 5 种,可组合:
- UIA tree parsing:从 Windows accessibility tree 抽可见元素
- DOM tree parsing:仅浏览器内
- OCR:proprietary(OneOCR)或 open(Tesseract)
- Icon / image detection:proprietary 或 Grounding DINO
- Omniparser:Microsoft 自家的多元素检测 + icon captioning 模型
输出格式:先回答几个屏幕理解 + 长程规划相关的问题,再输出下一步的 Python action 代码。
Figure. Set-of-Marks 标注示例(proprietary 像素模型版本):OCR 蓝色 / icon 绿色 / image 红色。
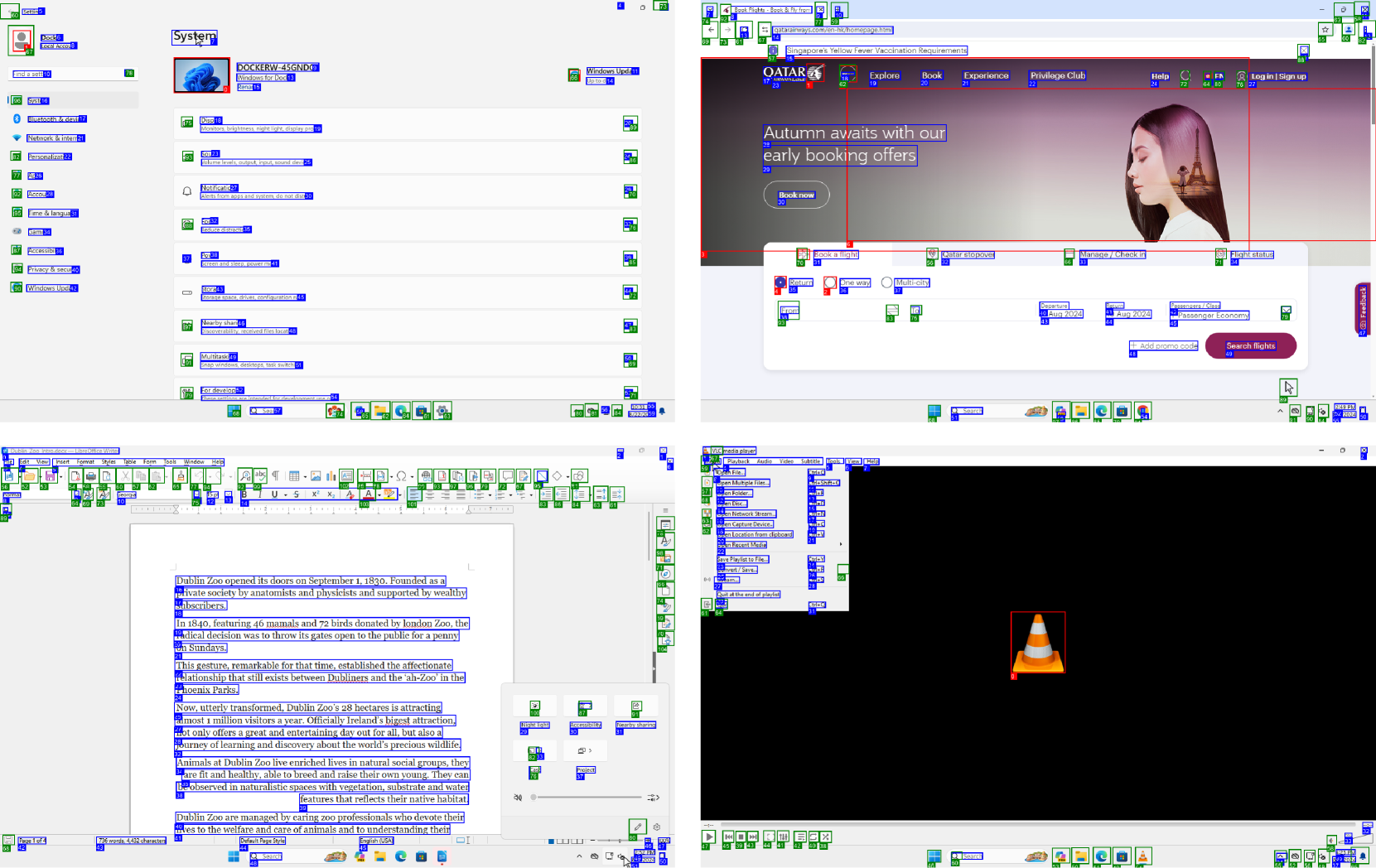
Figure. Omniparser 版 SoM:text 蓝色 / icons 绿色,附带 icon caption。
5.2 主结果
Table 2. Navi 在 WindowsAgentArena 上的成功率(按 SoM 配置和 base model 分组,节选 GPT-4V-1106 行)。
| SoM 配置 | UIA | Model | Office | Web | WinSys | Coding | Media | Utils | Total |
|---|---|---|---|---|---|---|---|---|---|
| Pytesseract+DOM+GroundingDINO | ✗ | GPT-4V-1106 | 0.0% | 10.3% | 21.3% | 12.5% | 9.8% | 0.0% | 8.6% |
| Pytesseract+DOM+GroundingDINO | ✓ | GPT-4V-1106 | 0.0% | 13.3% | 25.0% | 13.0% | 28.9% | 8.3% | 13.1% |
| OneOCR + proprietary | ✗ | GPT-4V-1106 | 2.3% | 13.7% | 16.7% | 13.6% | 19.3% | 8.3% | 11.3% |
| OneOCR + proprietary | ✓ | GPT-4V-1106 | 0.0% | 26.3% | 16.7% | 17.4% | 19.3% | 0.0% | 13.1% |
| Omniparser | ✗ | GPT-4V-1106 | 2.3% | 23.6% | 20.8% | 8.3% | 20.0% | 0.0% | 12.5% |
| Omniparser | ✓ | GPT-4V-1106 | 0.0% | 27.3% | 33.3% | 27.3% | 30.3% | 8.3% | 19.5% |
| Human | — | — | 75.8% | 76.7% | 83.3% | 68.4% | 42.8% | 91.7% | 74.5% |
(完整 Table 4 还覆盖 Phi3-V / GPT-4o-mini / GPT-4o,结论一致:模型越大越好;GPT-4V-1106 整体最强,比 GPT-4o 在 Omniparser+UIA 上几乎翻倍——9.4% vs 19.5%。)
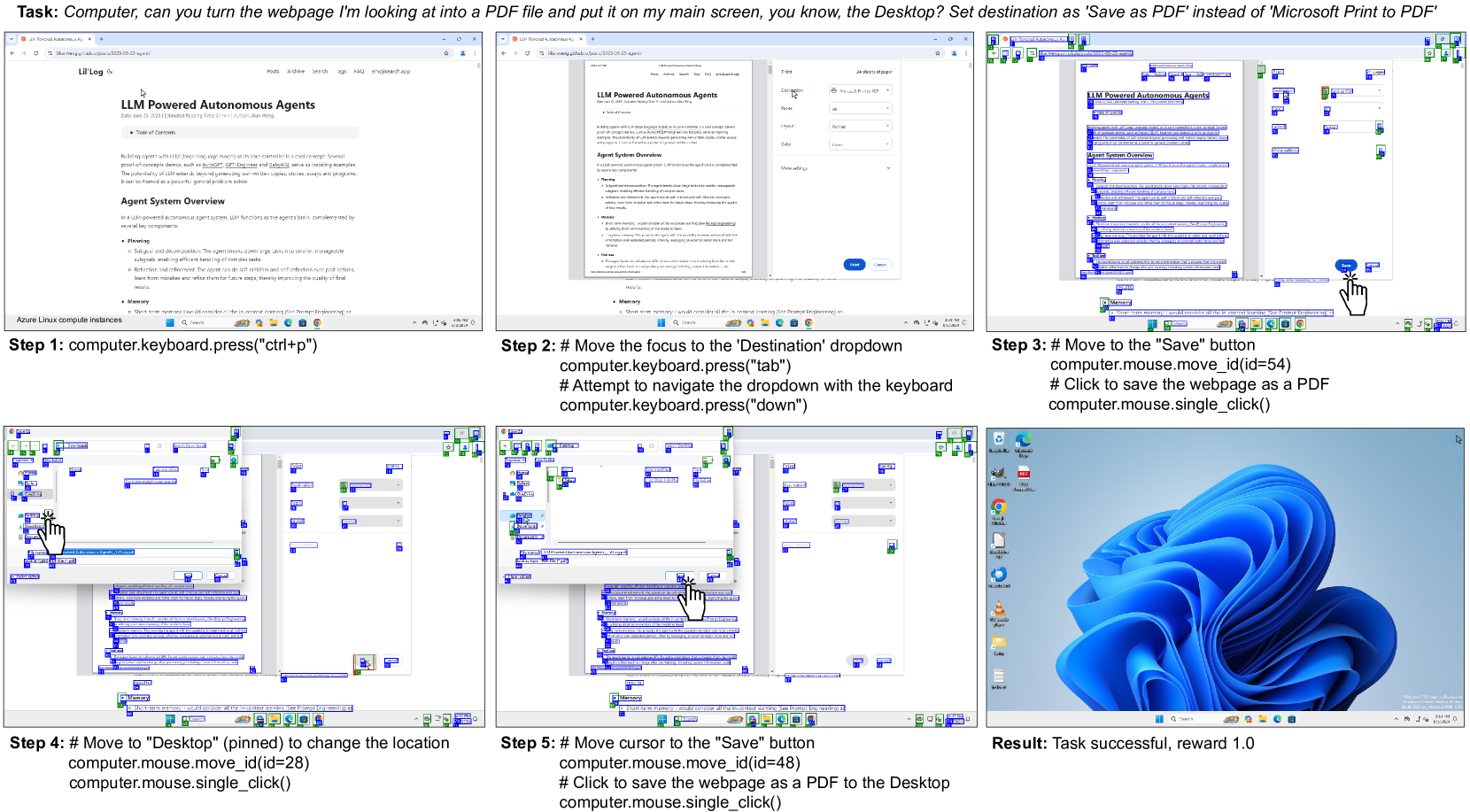
Figure. Navi 成功完成”将网页保存为 PDF 到桌面”任务的轨迹示例。
5.3 关键 Findings
- Generalist zero-shot VLM 远未饱和:19.5% vs 74.5%。Office / Windows Utils 任务接近 0%——这些任务依赖键盘快捷键和小图标,VLM 都不擅长。
- SoM 质量是性能上限:加 UIA marker 在 Omniparser 上让 GPT-4V 提升 57%(12.5% → 19.5%)。代价是 UIA tree 查询慢——复杂屏幕可能要几秒到几分钟。
- Visual-language mis-alignment 是常见 failure mode:agent 文本输出 “move to red”,但选了对应黄色调色板的 SoM #59。这是 VLM 训练数据分布里缺少 “上百个小标号的截图” 的直接后果。Omniparser 的优势很大程度来自 icon captioning——直接给 agent 提供”标号 → 文本含义”的映射。
- Phi3-V 在长上下文时容易 hallucinate:小模型的规划能力跟不上 OS 任务的长度。
5.4 Mind2Web 验证
为了证明 Navi 不是只在自己 benchmark 上 work,作者把它跑到 Mind2Web。
Table 3. Navi 在 Mind2Web 上的结果。
| Modality | Model | Inputs | Element Acc | Op F1 | Step SR |
|---|---|---|---|---|---|
| Text-Only | GPT-4o | DOM | 26.3% | 69.1% | 24.6% |
| Multimodal | GPT-4o | SoM (DOM + Pixel) | 37.4% | 79.2% | 35.1% |
| Multimodal | GPT-4o | SoM (Pixel) | 40.6% | 84.5% | 38.3% |
| Multimodal | GPT-4o | SoM (DOM) | 38.7% | 81.1% | 36.9% |
| Multimodal | GPT-4o | Image+SoM (DOM) | 42.8% | 84.3% | 40.7% |
| Multimodal | GPT-4o | Image+SoM (DOM + Pixel) | 47.3% | 85.8% | 45.2% |
| SeeAct | GPT-4V | Image+SoM (DOM) | 44.3% | 71.8% | 38.3% |
结论:Image + SoM(DOM+Pixel) 组合最好,跟 WAA 上 UIA + 像素混合的结论同构——多源 grounding 信号融合是 SoM agent 的通用 pattern。
6. Discussion 中作者自己的开放问题
- Full autonomy vs human-in-the-loop:让 agent 主动 ask user clarification 可能提升成功率,但 benchmark 评估变难。
- Generalist vs specialized agents:“agent of agents”——通用大模型协调 fine-tuned domain sub-agent。
- Imitation vs RL:OS agent 缺 ground-truth action data,类似 robotics。WAA 的 reward function 天然适合做大规模 RL 数据生成。
- Action space 设计:free-form code vs predefined skill library 是开放问题——后者执行精度高但限制 agent 推理空间。
关联工作
基于
- OSWorld:WAA 直接 fork OSWorld 的任务结构和 evaluator 设计,2/3 任务从 Linux 移植。OSWorld 是 WAA 的最重要前置工作。
- Set-of-Marks (SoM) prompting:把”在图上画标号 + 让 VLM 用标号交互”作为 grounding 范式,WAA 的 Navi 是 SoM 在 OS-level 任务上的扩展。
- dockur/windows:Docker 镜像用 QEMU/KVM 跑 Windows VM 的开源方案,WAA 部署的底层依赖。
对比
- AndroidWorld:同期的 mobile OS benchmark,思路相同(real OS + execution-based reward)。
- WebArena / VisualWebArena / WorkArena:纯 web domain 的交互式 benchmark;WAA 跨 web + desktop apps 是 superset。
- SeeAct:Mind2Web 上的强 baseline,Navi 在 Mind2Web 上的对比对象。
方法相关
- Omniparser:Microsoft 自家的屏幕解析模型(OCR + icon detection + caption),是 Navi 最佳配置的关键组件。
- Grounding DINO:开源 icon detection 替代品。
- GPT-4V / GPT-4o / Phi3-V:base VLM,决定 agent 推理上限。
- UFO / OS-Copilot / CC-Net / CogAgent:同期或更早的 OS / desktop agent 工作。
论文点评
Strengths
- 工程价值清晰:Azure-native 并行 + 容器化 VM 把 OS agent 评估从 days 压到 20 minutes,这是 OSWorld 的实质改进,对所有做 OS agent 的人都有用。
- SoM 多源融合做了系统的 ablation:不是单纯刷 SOTA,而是把 OCR / icon / DOM / UIA / Omniparser 排列组合都跑了一遍,给后人一张明确的”什么 grounding 信号有用”的地图。
- 诚实报告 failure modes:visual-language mis-alignment、Phi3-V hallucination、Office 类任务接近 0%——这些 negative result 比 main number 信息量更大。
- 跨 benchmark 验证:在 Mind2Web 上重复了”多源 grounding 信号融合最好”的结论,说明 finding 不是 WAA-specific artifact。
Weaknesses
- 任务规模偏小:154 个任务 vs OSWorld 369 个、WorkArena 18000+。给定 zero-shot agent 的高方差,这个规模做 model comparison 的统计置信度不高(每个 cell 平均才 ~25 任务)。
- 没有 agentic RL 实验:一直在讨论”WAA 适合做 RL data generation”,但论文里全是 zero-shot prompted result。这是最显然的 follow-up 但没做。
- Navi 是 reference baseline,不是 contribution:把 Navi 称作”new agent”有点 overclaim——核心是 SoM prompting + chain-of-thought,跟 SeeAct 思路同构。真正的 novelty 在 environment,不在 agent。
- Win11 license 限制损害复现性:用户得自己从 Microsoft 拉 trial image。trial 过期、Windows update 改 UI 都可能让历史结果不再可复现——这是基于 commercial OS 做 benchmark 的根本困境。
- 没讨论”过 benchmark”导致的 hill-climb 风险:154 个任务规模下,如果未来 agent 团队针对每个任务做 prompt engineering 或 fine-tuning,benchmark 很快被 overfit。
可信评估
Artifact 可获取性
- 代码: inference + 基础设施开源(agent loop、Docker、Azure deployment scripts 全公开);training 不适用——Navi 是 prompted agent
- 模型权重: Navi 本身只是 prompt + scaffolding;底层 VLM (GPT-4V/4o) 闭源;Omniparser 已开源(2024-10-23 Microsoft 单独 release)
- 训练细节: 不适用(无训练);prompt 全文在 Appendix D
- 数据集: 154 个任务 JSON 配置全部开源;Win11 VM image 因 license 问题用户需自行下载 trial
Claim 可验证性
- ✅ “154 个任务可在 ~20 分钟内并行跑完”:基础设施开源,Appendix A.7 给了 Azure VM 类型,可独立验证
- ✅ “UIA + Omniparser + GPT-4V-1106 达 19.5%“:Table 4 完整 ablation 展示数据点,配置和 prompt 都开源
- ⚠️ “Navi 在 Mind2Web 上 SOTA”:只跟 SeeAct 比较,没对比同期更新的 web agent(如 WebVoyager、AutoWebGLM),SOTA claim 范围窄
- ⚠️ “Human 74.5%“:人数、被试招募方式、是否给操作时长上限等没披露细节,作为 upper bound 有不确定性
- ⚠️ “OSWorld 单机并行 limited to single digits”:没给具体数字证据,更像 design rationale 而非测量结果
Notes
- WAA 的真正贡献是 infrastructure,不是 agent。它把 “OS agent benchmark 怎么做才能 scale” 这个问题做出了一个 reference answer:容器化 VM + 云端 worker pool。这套基础设施可以直接迁移到任何需要”在真实 OS 里跑 multi-step task” 的工作(包括 RL 训练数据生成)。
- 对我来说最有用的 takeaway 是 SoM grounding 的 ablation——accessibility tree 信号(UIA / DOM)跟 pixel-based 检测是互补的,融合后才能逼近 ceiling。这个原则对设计 GUI agent 的 perception stack 是直接可用的。
- 一个值得追问的方向:OS agent 的 visual-language mis-alignment 问题能否通过 in-context fine-tuning 解决? 论文把这归因到 VLM 训练分布缺乏”上百个小标号的截图”——那么用 WAA 自己生成的 trajectory 做 SFT data 应该能补上。这是个明显的 follow-up。
- 19.5% 这个数字在 2024-09 是 reasonable 的,但放到 2026 应该已经被远超。值得追踪后续在 WAA 上的 SOTA 进展(比如 Anthropic computer use、UI-TARS / UI-TARS-2、Agent S2 系列)来评估 OS agent 这两年的真实进步幅度。
Rating
Metrics (as of 2026-04-24): citation=124, influential=19 (15.3%), velocity=6.39/mo; HF upvotes=48; github 856⭐ / forks=96 / 90d commits=0 / pushed 10d ago
分数:2 - Frontier 理由:WAA 作为 Windows OS agent 的代表性 benchmark,提供了可复现的云端并行评估基础设施(Strengths #1)和系统的 SoM ablation(Strengths #2),被后续 OS/GUI agent 工作作为重要参考;但相较 OSWorld 已成为 Linux OS agent 的 de facto 标准(引用数与社区采纳显著更高),WAA 任务规模偏小(Weaknesses #1)、Win11 license 损害复现性(Weaknesses #4),在社区采纳度上尚未达到 Foundation 档,更符合 Frontier 定位——重要参考但非必读必引的奠基工作。