Summary
WholeBodyVLA: Unified Latent VLA for Whole-Body Loco-Manipulation
- 核心: 把 humanoid loco-manipulation 当成一个统一的 VLA 问题——上层 VLA 从 action-free egocentric video 中学统一 latent action(locomotion + manipulation 两个 LAM 分别训),下层用为 loco-manipulation 量身定制的、采用离散 command 接口的 RL controller 取代常规连续 velocity-tracking
- 方法: 双 LAM (manipulation LAM on AgiBot World + locomotion LAM on自采 head-mounted 视频) → VLA 联合预测两类 latent code → 轻量 decoder 输出 (上肢 joint, 离散 locomotion command) → LMO RL 50 Hz 执行
- 结果: AgiBot X2 上 3 个真机任务(bag packing / box loading / cart pushing 50kg),相对 modular pipeline / GR00T N1.5 / OpenVLA-OFT 平均高 21.3% 与 24.0%
- Sources: paper | website | github
- Rating: 2 - Frontier(ICLR 2026 最新成果,双 LAM + 离散 command LMO 的 system-level framing 对 VLA + controller 接口设计有迁移价值,但代码未开源、关键 ablation 渲成 PNG、尚未被后续工作大规模采用为 baseline,不到 Foundation 档)
Key Takeaways:
- 诊断到位:humanoid loco-manipulation 落不下来的两个 root cause 被分得很清——(a) data scarcity 阻碍上层 policy 学到 manipulation-aware locomotion;(b) 现有 RL controller 用 continuous velocity tracking,对”上车 / 停车 / 转向”这类 episode 级位姿控制不够 reliable。文章针对这两个根因分别给方法。
- 双 LAM 比单 LAM 更合适:作者明确指出,manipulation 视频 camera 几乎静止、变化由手臂主导;locomotion 视频 camera 持续移动、变化由场景相对运动主导。混合训单一 LAM 会产生 attention 冲突 + 把”相对位姿变化”全部解释成手臂运动的 ambiguity。两个 LAM 解耦后再联合监督是简单但 principled 的修复。
- LMO 把”连续速度”换成”三元离散 flag + 站姿高度”:command 接口变成 ,强制 explicit start-stop 语义,降低 trajectory variance,同时让上层 VLA 更易预测——这是个偏 system-design 的 insight:低层接口的 simplicity 直接影响 high-level policy 学习难度。
- Pretrain 用 action-free 数据:与 LAPA / UniVLA 同思路,但首次把这条路径推到 humanoid loco-manipulation;自采的 head-mounted 单人视频成本远低于 MoCap / teleop。
- 代码暂未开源:仓库目前只是 awesome-list 形式,作者明确”no concrete timeline”。
Teaser. AgiBot X2 端到端连续完成 loco-manipulation 序列。
Figure 1. Overview——bag packing → side-step → squat to place → squat to lift → turn to place onto cart → push 50 kg cart。

Video. Long-horizon bimanual loco-manipulation 演示。
1. Motivation
Humanoid loco-manipulation 的核心挑战不是单独的 walking 或单独的 grasping,而是 manipulation-aware locomotion:locomotion 要主动为后续 manipulation 创造前置条件(approach / orient / stabilize),而不是把两者当独立 stage 串起来。文章把现有方案分成两类并各自指出失败模式:
- Modular pipeline(VLM planner + 切换 nav / grasp skill,如 Being-0、HEAD、):closed-loop 反馈弱,没有 end-to-end 联合优化,机器人执行完 nav 后常处于不利于 manipulation 的位姿。
- End-to-end imitation(HumanoidVLA、GR00T、Boston Dynamics demo):原则上能 alleviate handoff 问题,但需要大规模 whole-body teleoperation 数据,而这种数据获取成本极高。
两条路最终都卡在数据稀缺——没有大规模 humanoid loco-manipulation 轨迹,模型就学不到 locomotion 与 manipulation 之间的耦合。
❓ Modular pipeline 的失败统计来自 Appendix C.3 的 failure cases,没在主文给出绝对数字。如果”很多 modular failures 来自 RL controller 而非 high-level VLA”是核心论点之一,建议 main paper 留个总数表。
2. Method
整体 pipeline 见下图:上层 VLM 同时输出 manipulation latent + locomotion latent,下层 LMO RL 在 50 Hz 跑。
Figure 2. WholeBodyVLA pipeline.
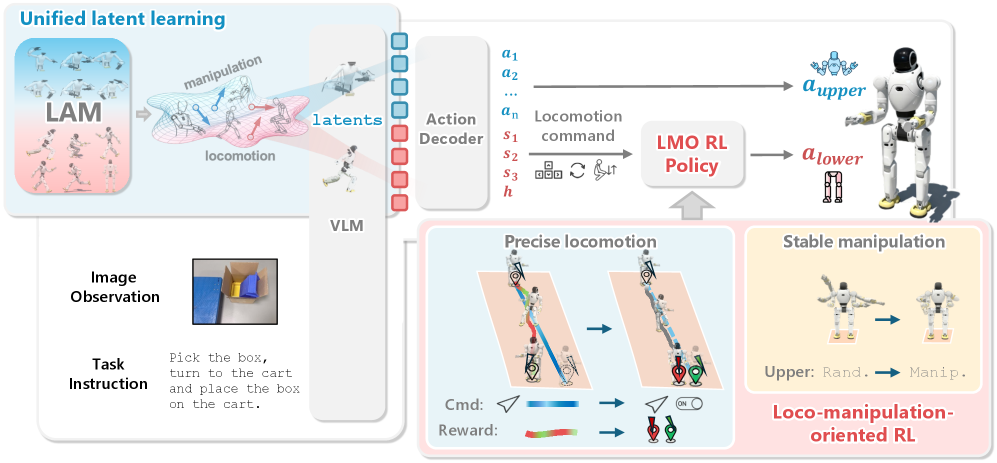
2.1 Unified Latent Action Model(双 LAM)
为什么要两个 LAM? 作者尝试单一 LAM 训混合数据,结果不佳,归因有二:
- Attention conflict:manipulation 视频图像变化被手臂支配 → LAM 偏向 attend arm region;locomotion 视频变化由场景相对运动支配 → LAM 必须 attend 整个 scene。两种目标相互冲突。
- Ambiguous encoding:在 manipulation 数据里 “arm-environment 相对位姿变化” 被编码为手臂动作;在 loco-manipulation 数据里同样的相对位姿变化其实是相机(即整个 base)在动。混合训会让 LAM 把 base motion 误编码为手臂动作。
❓ 这条 ambiguity 论证看起来 reasonable,但论文没有给一个 clean ablation 来量化 attention conflict 的严重程度(比如 visualize 单 LAM vs 双 LAM 的 attention map)。Table 2 ablation 里”single LAM on mixed data”和”manipulation-only LAM”的差距能间接说明,但中间那一步是”差距来自 attention conflict 还是来自 codebook 容量”是混淆的。
架构:跟 Genie / UniVLA 一致——VQ-VAE 架构,encoder 建在 DINOv2 特征上。
给定相邻帧 :
其中 。Decoder 用 重建 ,按标准 VQ-VAE loss 训练。
VLA 训练目标——联合预测两类 latent:
为语言指令,CE loss。这一步强制模型把 locomotion 与 manipulation 学进同一个 cohesive action space——想 grasp 远处物体就必须”想清楚怎么走过去”。
Decoder grounding:finetune 时附加轻量 decoder :
输出 (i) 上肢 joint angles 与 (ii) 下肢 locomotion command(送给 LMO RL)。
Manipulation-aware locomotion data 自采:
- 单人 + head-mounted 单目相机,无 MoCap、无 teleop
- 覆盖所有 humanoid primitives(advance, turn, squat)
- goal-directed:操作者必须以 contact 一个潜在 manipulation 目标为终点,确保 locomotion 数据与 loco-manipulation 学习对齐
2.2 LMO RL Policy(离散 command 接口)
问题:现有 RL controller 用 continuous velocity tracking 目标,per-step 跟踪指令速度。这套目标对”巡航”够用,但对 loco-manipulation 需要的 episode-level controllability(精准制动、heading fidelity)几乎没有监督,且让 controller 更难训。
解法:换成 goal-conditioned regulation + 离散 command。
Observation:纯 proprioception,
Discrete command:
是 forward / lateral / turning 的三元 flag, 是 stance height。这种接口自带 explicit start-stop 语义,降低 trajectory variance,同时让上层 VLA 容易预测。
Reference shaping 防止突然加速——把 ternary flag 通过平滑门控映射到参考速度:
Two-stage curriculum:
- Stage I (basic gait):每个轴随机采样 ,sign 由 决定;上肢按 HOMIE 风格 track 随机姿态,joint limit 通过 curriculum 渐放。目标是不摔。
- Stage II (precision & stability):固定每轴巡航速度为常数;用 directional accuracy 指标 强制 onset / offset 不诱发 yaw drift;manipulation side 从 AgiBot World 采真实手臂 motion 注入扰动,让腿学会补偿真实的 inertial coupling 而非随机扰动;静止 episode 加 stand-still penalty 。
这个 LMO 的设计哲学很值得思考:low-level 接口的简化反而让 high-level learning 更容易。这跟”离散 action space 的 RL agent 比 continuous 的更易学”是同一个直觉,但这里把它从 RL 内部搬到了 hierarchy 接口上。
3. Experiments
3.1 Setup
- Hardware:AgiBot X2 prototype——7-DoF arms + Omnipicker grippers, 6-DoF legs, 1-DoF waist, Intel RealSense D435i。
- Tasks:(i) bag packing—抓纸袋→侧步→蹲下→放进 carton;(ii) box loading—蹲下抓盒→转身→放上手推车;(iii) cart pushing—抓 50 kg 推车把手→直线推。
- Data:每个 task 50 条 VR + joystick teleop。
- Baselines:navigation-assisted Modular Design、GR00T N1.5、OpenVLA-OFT(后两者都被 adapt 成输出 dual-arm joint + 同款离散 locomotion command,由 LMO 执行),以及 ablation 变体(去 LMO / 去 LAM / mani-only LAM / single shared LAM on mixed data)。
3.2 Main Results(Q1)
Table 2. 三任务、各 2 subgoal 上的成功率。
WholeBodyVLA 全面超过 modular 与 end-to-end baseline。文章 abstract 给出的 21.3% 与 24.0% 是相对最强 baseline 的平均提升。
Video. Bag packing 成功 vs baseline 失败。
baseline 典型 failure mode(“Stumble to stop”、“lose balance and kick the box”):
3.3 Ablations(Q2 & Q3)
主文 Table 2 的 ablation 行同时回答了 Q2(latent learning 的 contribution)与 Q3(LMO 的 contribution)。两者都被报告为”显著贡献”,但具体每条线的数值需要看 paper Table 2 的图(论文这里把 table 渲成了 figure x3.png)。
❓ 把 Table 渲成 figure 让 grep 不到原始数字,对复现 / 引用都不友好。
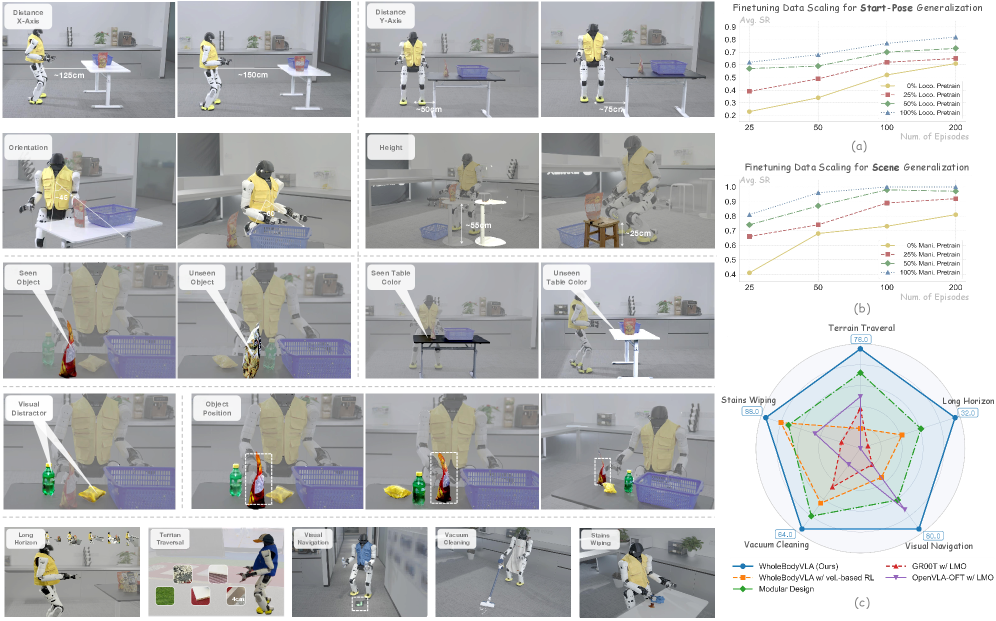
3.4 Generalization(Q4)
文章 project page 演示了多种 generalization 维度:
- Object generalization:unseen 物体外观 / 位置 / 桌色。
- Start-pose generalization:X / Y 偏移、orientation、桌高都覆盖到——这是 LMO 离散 command + reference shaping 的直接好处。
- Terrain generalization:unever terrain。
- Long-horizon bimanual、额外任务(wiping / vacuum / 倒水 / 搬椅子 / 上楼梯)——展示 system extensibility。
关联工作
基于
- Genie: VQ-VAE 形式的 latent action model 起源;本文沿用其编码器 + 离散 codebook 设计
- LAPA / UniVLA: 把 latent action learning 推到 VLA 预训练,本文的 unified latent learning 是其在 humanoid loco-manipulation 上的延伸
- π0 / π0.5 / OpenVLA / RT-2 / RDT: 同时代 VLA 系列;本文 position 是”补上 whole-body locomotion 的那一块”
- DINOv2: LAM encoder backbone
对比(baseline)
- GR00T N1.5: humanoid-native VLA,被 adapt 成同款离散 locomotion 接口后作为 end-to-end baseline
- OpenVLA-OFT: 同上,被 adapt
- HOMIE / FALCON / AMO / R²S² / ULC: velocity-tracking RL controller 家族,本文 LMO 的对照面
- Being-0 / HEAD / : modular pipeline 代表
方法相关
- AgiBot World: 用作 manipulation LAM 训练数据 + LMO Stage II 上肢扰动来源
- Boston Dynamics Atlas demo: 重 MoCap 路线的代表,本文用作 motivation 的反例
论文点评
Strengths
- 诊断 + 修复对得很齐。两个 root cause(data scarcity / controller 不精准)各自有针对性 module,没有 over-engineering。
- Double-LAM 的论证 principled。基于”camera 是否动”的物理直觉去 motivate 双 LAM,而不是 hand-wavy”双倍容量更好”。
- LMO 的 system-level insight 有迁移价值。离散 command 接口本身不是新东西(HOMIE 之类的 gait controller 早有 discrete 选择),但把它定位为”为了让上层 VLA 学得更稳而专门简化的 ABI”是个干净的 framing,VLA + low-level controller 的 interface design 可以广泛参考。
- 真机 setup 完整:3 task × 2 subgoal × multiple baseline + ablation,加上 50 kg cart pushing 这种带 load 的 demo,对 humanoid loco-manipulation 这个 noisy benchmark 算是覆盖到位。
Weaknesses
- 代码与权重均未开源,README 明说 “no concrete timeline”。仓库目前是个 awesome-list,对独立复现非常不友好。
- 核心 ablation 表(Table 2)以图片形式给出,grep 不到原始数字;正文也没把 ablation 各行的具体提升列在 prose 里——读者只能靠肉眼读图。
- Latent action 的有效性论证仍是经验性的。“双 LAM > 单 LAM” 是 result-driven,缺中间分析(attention map / codebook usage / 重建质量对比)。
- 泛化测试样本量未公开。project page 视频展示了 generalization,但没有量化的 success rate。
- 跟最新 humanoid-VLA / EgoHumanoid 等同期工作的直接对比缺失——baseline 选了 GR00T N1.5 与 OpenVLA-OFT(被 adapt),没有跟 humanoid-native 的最新方法(如 EgoHumanoid、HumanoidExo、VisualMimic)正面 head-to-head。
- LAM 真的把 locomotion 学到了吗?——locomotion latent 的 codebook 是否退化、是否被 manipulation 信号 dominate,文中未给 codebook entropy / usage 分析。
可信评估
Artifact 可获取性
- 代码:未开源(README 明示 “no concrete timeline”)
- 模型权重:未发布
- 训练细节:仅高层描述(双 LAM + Stage I/II curriculum 框架);超参 / 数据配比 / 训练步数主要放在 Appendix(未在抓取的主文件中验证完整度)
- 数据集:自采的 manipulation-aware locomotion 视频未公开;预训练用的 AgiBot World 已开源;teleop trajectories(每 task 50 条)未公开
Claim 可验证性
- ✅ 真机系统 work 在 AgiBot X2:project page 视频充分展示 bag packing / box loading / 50 kg cart pushing;视频本身是可信证据(但不能反推数值差距)
- ⚠️ “21.3% / 24.0% 优于 baseline”:来自 Table 2,但 baseline 的具体 setup 是被 adapt 的 GR00T N1.5 / OpenVLA-OFT(套上同款 LMO controller),公平性取决于 adaptation 实现细节;且 50 条 teleop demos × 3 任务的 evaluation rollout 数(论文未在 main text 给出每任务 trial 数)会显著影响置信区间
- ⚠️ “双 LAM 优于单 LAM”:用的是 task success rate 这个下游指标,没有直接的 representation-level 评估(attention / codebook / 重建质量)
- ⚠️ “LMO 显著贡献 stability”:定性描述明确,但 main text 没列出 LMO ablation 的具体 success-rate delta(图 x3.png 内的数字未在文本里复述)
- ❌ “first to enable large-space humanoid loco-manipulation”:这种 “first” 的措辞偏 marketing——Boston Dynamics demo、、HEAD 等都至少能做部分 large-space loco-manipulation;本文的合理 claim 应是”first end-to-end VLA for it”
Notes
- 这种”用 action-free egocentric 视频 pre-train + 双 LAM 解耦 motion modality”的思路对我自己 humanoid VLA 方向有 take-away:当 multi-modal 数据来源差异大(静态 vs 移动 camera)时,把 latent space 拆开训 比 hope-it-emerges 一个统一空间更现实。值得在自己的 latent VLA 设定里抄过来。
- LMO 的 framing”low-level 接口越简单,high-level 越好学”对我设计 hierarchy interface 有提醒——下次设计 VLA + controller stack 时,先问”上层模型预测这个 command space 的难度有多大”,而不是只看 controller 自身的 expressiveness。
- 代码不开源 + 关键 ablation 表渲成 PNG 是两个执行层面的 red flag,跟踪后续 release 与同期 follow-up 比一手复现优先级高。
- ❓ 双 LAM 是否需要 cross-modality alignment?纯独立训练,VLA 联合预测时有没有”manipulation latent 想前进、locomotion latent 想转弯”这种 conflict?文中未讨论。
- ❓ 50 kg cart pushing 是否依赖特定地面摩擦?project page 没演示不同地面材料的 cart pushing 泛化。
Rating
Metrics (as of 2026-04-24): citation=17, influential=0 (0.0%), velocity=3.86/mo; HF upvotes=N/A; github 375⭐ / forks=8 / 90d commits=4 / pushed 71d ago
分数:2 - Frontier 理由:ICLR 2026 刚放出(2025-12),在 humanoid loco-manipulation 这个正在快速发育的子方向里,本文是少数把 “action-free video pre-train + 双 LAM + 离散 command controller interface” 整套 end-to-end 跑通到真机的工作,system-level insight(LMO 的接口简化为上层 VLA 服务)对未来 VLA + controller stack 设计有迁移价值,属于当前方向前沿必读。但还没到 Foundation 档:代码与权重均未开源(README 明示 “no concrete timeline”),社区尚未把它作为 de facto baseline,而且关键论证(双 LAM vs 单 LAM)仍是 result-driven,缺 representation-level 证据;相邻的 Archived 档不合适是因为该工作的 framing 与 baseline 选择(adapt GR00T N1.5 / OpenVLA-OFT)对同期 humanoid VLA 方向仍有明确参考价值。2026-04 复核:4.4 月 17 citation / 影响力 0 / velocity 3.86/mo / github 375⭐ 且仍在缓慢更新(近 90 天 4 commits),早期采纳信号中等;但代码仍未开源,维持 Frontier。