Summary
EmbodiedBrain: Expanding Performance Boundaries of Task Planning for Embodied Intelligence
- 核心: 在 Qwen2.5-VL 7B/32B 上做 SFT + RL 后训练,输出
<response>/<plans>/<actions>三段式结构,目标是把高层任务规划做成可执行的原子动作序列- 方法: (1) “agent-aligned” 数据格式(response + plans + actions tuple),(2) 两阶段训练—rejection-sampling SFT cold-start + Step-GRPO(在 GRPO 里把 ground-truth 计划的前 k 步作为 “Guided Precursor” 提示),(3) Generative Reward Model 走异步推理给规划合理性打分
- 结果: 7B/32B 在 14 个 benchmark 全面超过 Qwen2.5-VL baseline 与同尺寸 RoboBrain 2.0;自建闭环 sim benchmark VLM-PlanSim-99 上 32B 达 46.46% 成功率(baseline ~25%)
- Sources: paper | website
- Rating: 1 - Archived(方法上是 Qwen2.5-VL 之上的 embodied post-training recipe,Step-GRPO 是可借鉴的工程 trick,但架构零创新、评估有选择性、闭环 benchmark 规模偏小;2026-04 复核 cite=2/inf=0/HF=0/6mo、无 github 链接,社区 traction 接近零——被同期 MiMo-Embodied / Pelican-VL 等后续工作分流)
Key Takeaways:
- Step-GRPO 是 GRPO + curriculum 的简单 trick:长 horizon 的 planning rollout 几乎全负样本,advantage 退化;把真值前 k 步当 prompt 注入(k 随机),把任务 chunk 成易后段,等价于按难度分层学。本质是 “QuestA-style hint injection” 移植到 embodied planning。
- Agent-aligned 三段式输出强调 plans 与 actions 的解耦:plans 用
[Navigate]/[Manipulate]高层 tag,actions 是可直接对接 API 的 verb-object tuple。这种结构化模板加上格式 reward 容易被下游 controller 解析,但同时也固化了动作空间,迁移成本高。 - Rejection sampling 通过视觉 mask 探测难度:对每个样本以 0.0~0.9 的比率随机遮挡像素 10 次,找最小掩码率使 Pc<0.1 作为 “视觉依赖” 指标,过滤掉纯文本 prior 就能解的”伪多模态”样本。比 length / perplexity filter 更针对性。
- VLM-PlanSim-99 是少数闭环 benchmark:99 个手工标注、AI2-THOR 验证可执行的家务任务,配套 Stage A→B→C 解析+执行 pipeline,比 EgoPlan 这类 offline 选择题更接近真实部署。规模太小,更像 stress test。
- Spatial perception 才是涨幅最大的部分(BLINK 58.74→88.11、CV-Bench 62→80.69),不是 planning。说明此类工作受益于”VLM 本身空间能力差 + 海量 EmbSpatial 类合成数据”的简单组合,并非新方法贡献。
Teaser. EmbodiedBrain 架构总览 — 多模态输入(多视图图像、长视频、语言指令)经 Qwen2.5-VL ViT + MLP projector + LLM decoder,输出 response/plans/actions 三段。

架构
EmbodiedBrain 完全继承 Qwen2.5-VL 的 modular encoder-decoder:原生分辨率 ViT(windowed attention + 2D RoPE)+ MLP merger + Qwen2.5 LLM decoder(带 multimodal RoPE aligned to absolute time)。没有任何架构改动——所有变化都在数据格式、训练策略、reward 设计上。
输出被规约为:
<response>{自然语言确认/状态}</response>
<plans>
1.[manipulate] Locate the dirty clothes in the basket
2.[navigate] Navigate to the basket
...
</plans>
<actions>
[['Search','Dirty clothes'], ['Navigate','Basket'], ['Pick','Dirty clothes'], ...]
</actions>
[Navigate] 对应下肢移动,[Manipulate] 对应上肢操作;actions 是 binary/ternary tuple,可直接调 robot API。
❓ 这套 schema 和 RoboBrain 2.0 / Robix 的”thinking + plan + action”基本同构。从设计上看,EmbodiedBrain 把动作集合写死在 ontology 里(Search/Navigate/Pick/Place/Open/…),灵活性差,对开放世界的可迁移性存疑。
训练数据
数据格式:agent-aligned
<response> / <plans> / <actions> 的三段式上面已说明。设计目标是同时做到:human-readable confirmation、可解释的高层 plan、可机器执行的动作序列。
SFT 数据组成(约 253K)
通过五配置消融,选定 General : Spatial : Planning : Video = 52K : 130K : 51.5K : 20K 作为 cold-start mix(Table 1 显示这是唯一同时维持 spatial avg 70.27% 和 planning avg 64.64% 的配比)。
Table 1. Cold-Start SFT 数据配比消融
| Data Mix (K) | Spatial Avg | Planning Avg |
|---|---|---|
| 30:50:70:- | 68.95 | 61.05 |
| 30:50:45.5:- | 69.75 | 61.69 |
| 30:50:51.5:- | 69.18 | 62.31 |
| 52:130:51.5:- | 70.87 | 60.87 |
| 52:130:51.5:20 | 70.27 | 64.64 |
子数据集:
- General MLLM: tulu-3-sft-personas-IF(10K)、UltraIF-sft-175k(20K)、MM-IFInstruct-23k(22K)—— 都是 instruction-following 重点
- Spatial: EmbSpatial-SFT 经 Qwen2.5-VL-7B × 8 rejection sampling + GPT-4o 二级验证 → 50K;pixmo-points 聚合成 multi-turn QA → 60K
- Planning: 基于 ALFRED 的 PDDL 解析 pipeline,把 25,743 任务转成 plan + bbox 序列。导航动作分
[Navigate](目标可见)和[Map](需要搜索)两档 - Video Understanding: Ego4D + Epic-Kitchens + EgoPlan-IT 注释,构造 retrospective + proactive QA,用 Qwen2.5-VL-72B 配 CoT 过滤
RL 数据
Spatial:EmbSpatial 25K(Qwen2.5-VL-72B + Qwen3-32B + 人工三方共识)+ Orsta-Data-47k 子集(counting 1.7K + detection 8K + grounding 4.9K)。
Planning:SelfReVision 26K(Qwen3-32B 重格式化为 tagged plan + tuple)+ ALFRED 22K(多视图 RGB + 动态 bbox)。
❓ ALFRED 既出现在 SFT 又出现在 RL,没有说明分割。如果是同一份 trajectory,RL 会被 SFT cold-start 覆盖、advantage 退化(model 几乎已经能 reproduce)。
训练策略
Stage 1: 多模态拒绝采样 SFT
两级 rejection sampling:
- Coarse: Qwen2.5-VL-7B 生成多个候选,用 Qwen3-30B-A3B-Instruct-2507 评分,全错则丢弃
- Fine: 用 Qwen2.5-VL-72B 当 oracle 重答一次,若与原 GT 显著不一致则视为标签噪声丢弃
Cold-start 用上面消融选出的 52:130:51.5:20 mix。
Stage 2: Step-GRPO
多模态难度筛选:对每个图文样本 ,遍历 mask ratio ,每个 ratio 随机遮挡 K=10 次,计算正确率:
定义失败阈值 ()。 越小,样本越依赖视觉信息——这些是真正值得 RL 训练的样本。
Step-GRPO 算法核心:受 QuestA 启发,在长 horizon planning rollout 时,把 ground-truth 计划的随机长度前缀作为 “Guided Precursor” 注入 prompt,让模型从中段开始 rollout,简化问题、稳定 reward 动态、避免全负样本。
Figure 4. Step-GRPO 流程
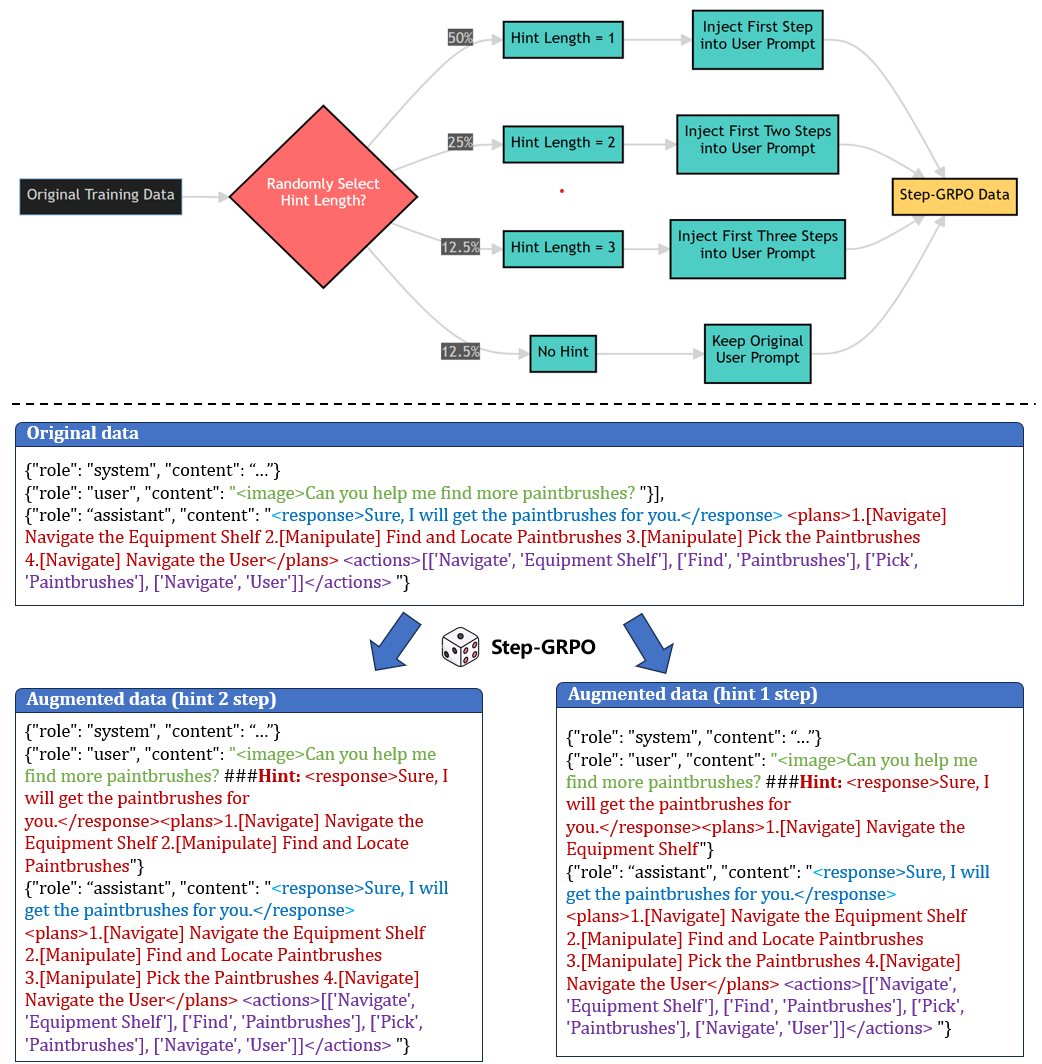
四类任务的 reward 设计:
- Instruction Following: 仅对 IF 子集计算 correctness reward,其它任务 skip
- Visual Perception: 自动识别任务类型(grounding/detection/counting),grounding/detection 用加权 IoU,counting 用精确匹配
- Spatial Perception: 区分多选与描述题;多选按答案格式调严格度并惩罚冗余;描述题做语义匹配(同义词、反义词、prep/主宾交换检测)
- Task Planning: 双 reward——rule-based 检查 XML tag 完整性 + GRM (Qwen3-30B-A3B) 评估 plan 合理性。论文承认权重平衡是 tuning 难点,rule reward 偏重会导致”安全但无效”的 plan
GRM 异步加速:把 RM inference 从主 RL loop 解耦到独立多线程,端到端训练时间提速约 20%,性能不降。
❓ Step-GRPO 的 hint 机制和近期 RoboGPT-R1、Reinforced Reasoning for Embodied Planning 在思路上极其相似(curriculum + hint + GRPO 变体),论文没有比较与之的差异——只对比了 standard GRPO 和 DAPO。
评估
14 个 benchmark 横跨三个领域,与 Qwen2.5-VL 和 RoboBrain 2.0 的 7B/32B 直接对比。
Table 2. 14 benchmark 综合对比(节选)
| Benchmark | Qwen2.5VL-7B | RoboBrain2.0-7B | EmbodiedBrain-7B | Qwen2.5VL-32B | RoboBrain2.0-32B | EmbodiedBrain-32B |
|---|---|---|---|---|---|---|
| MM-IFEval | 39.56 | 30.82 | 43.61 | 46.66 | 39.75 | 46.98 |
| MMStar | 62.27 | 59.40 | 62.17 | 64.70 | 65.80 | 65.40 |
| BLINK (spatial) | 58.74 | 62.94 | 88.11 | 73.43 | 68.53 | 87.41 |
| CV-Bench | 62.03 | 62.97 | 80.69 | 75.57 | 68.27 | 83.64 |
| EmbSpatial | 51.76 | 52.12 | 75.04 | 67.39 | 62.95 | 77.03 |
| ERQA | 41.00 | 42.50 | 41.75 | 44.61 | 45.11 | 43.50 |
| EgoPlan-Bench | 41.30 | 36.73 | 49.10 | 51.11 | 46.83 | 54.66 |
| EgoPlan-Bench2 | 38.63 | 33.54 | 49.58 | 49.81 | 49.96 | 57.11 |
| EgoThink | 52.13 | 44.92 | 53.54 | 56.75 | 49.33 | 53.92 |
| Internal Planning (F1) | 30.0 | 68.3 | 85.8 | 28.3 | 75.9 | 90.5 |
| VLM-PlanSim-99 | 23.2 | 21.21 | 31.31 | 25.25 | 24.24 | 46.46 |
几个值得注意的现象:
- Spatial perception 涨幅最大:BLINK 50%+ relative improvement、CV-Bench 30%+;这部分主要受益于 EmbSpatial 大量 SFT/RL 数据,不是新方法贡献
- General ability 几乎持平:成功避免 catastrophic forgetting,训练规模没有破坏 base model
- ERQA 略低于 RoboBrain 2.0:作者没解释;ERQA 比其他空间 benchmark 更靠近真实物理推理,可能是 EmbSpatial 数据 distribution skew 的副作用
- Internal Planning F1 = 0.86/0.91 vs Qwen2.5-VL 0.30:差距过大反而可疑——内部 benchmark 由 Qwen30B-A3B 生成 GT,且评估也用 GPT-5-Mini,存在评估口径偏向 EmbodiedBrain 的风险
Internal Planning Benchmark 的评估方法
值得记下:
- 提取
<actions>字段的 action list,过滤低层动作(find/navigate) - 构造 m×n cross-matching matrix,逐对调用 GPT-5-Mini 判断匹配
- M-QUANTITY:用 Hungarian algorithm 求最大二分匹配,归一化得 P/R/F1
- M-ORDER:用 LCS 算受 M 约束的最长公共子序列,归一化得 P/R/F1
设计上比纯 BLEU/ROUGE 合理,但用 GPT-5-Mini 做 matching 评判带来 evaluator-aware overfitting 风险(如果训练数据也用类似 GPT 生成)。
VLM-PlanSim-99 闭环 benchmark
99 个 AI2-THOR 家务任务,每个由人工标注 + 仿真器验证 GT 可执行。3 阶段执行 pipeline:
- Stage A: VLM inference 生成原始 plan
- Stage B: Unified Parsing 走 4-Layer Object Resolution(LLM parsing → static mapping → context caching → smart translation)
- Stage C: Simulation Validation 在 AI2-THOR 跑闭环,记录 task success rate
Video. VLM-PlanSim-99 案例:洗碗+微波加热
任务步骤包括 navigate to bowl → pick → place in sink → turn on water → … → place in microwave → close → turn on → take out。展示模型在长 horizon、多状态依赖任务上的执行链路。
关联工作
基于
- RoboBrain / RoboBrain 2.0 / RoboBrain 2.5: 同样思路的 embodied foundation model 系列(CPT + SFT + RL + 任务规划),EmbodiedBrain 直接以其作为主要对比
- Qwen2.5-VL: 完全沿用其架构,未做改动
对比
- Gemini Robotics / Gemini Robotics-ER 1.6: 闭源对手,论文 intro 提及但不在 benchmark 表中
- Robix: 同期 unified planning model,论文相关工作提及但未对比
- Embodied-R: 同样做 embodied reasoning + RL,论文相关工作提及
方法相关
- MiMo-Embodied / Pelican-VL / HY-Embodied 0.5: 后续/同期 embodied foundation model
- Embodied-R1: 同样以 RL post-training 增强 embodied reasoning
- DAPO / GRPO / Dr.GRPO: 论文 Step-GRPO 声称优于 standard GRPO 和 DAPO;缺乏曲线对比
- QuestA: Step-GRPO 的 “hint injection” 直接灵感来源
- ALFRED / AI2-THOR: 训练数据与 VLM-PlanSim-99 评估环境的底座
论文点评
Strengths
- Step-GRPO 是个落地友好的工程 trick:在 long-horizon RL 全负样本退化场景里,hint injection + chunked reward 是低成本稳定 advantage 的方法,可移植到 manipulation/web agent 等其他长链任务。
- 多模态难度筛选用 mask ratio 探测视觉依赖度比 length/perplexity 更切题,对 RL 数据 curation 是个可复用 protocol。
- VLM-PlanSim-99 闭环 benchmark + 完整执行 pipeline填补了 embodied planning 领域 offline-only 评估的空白。规模小但每个任务都是 sim 验证可执行,质量高。
- GRM 异步推理 20% 加速是工程层面的实在贡献,对所有 reward model-based RL pipeline 都适用。
- 完全开源(数据 + 权重 + 评估)——值得肯定的开放姿态。
Weaknesses
- 架构上零创新:完全沿用 Qwen2.5-VL,所有提升都来自数据 + 后训练。论文标题”Expanding Performance Boundaries”略显夸张,实质是”在 Qwen2.5-VL 上做了一套 embodied 后训练 recipe”。
- 没有与同期 hint-based GRPO 工作对比:RoboGPT-R1、Reinforced Reasoning for Embodied Planning(同样用 RL + hint + planning 数据)都没出现在 baseline 里。
- Internal Planning benchmark 数据生成与评估都是 GPT 系:训练用 Qwen30B-A3B 生成 GT、评估用 GPT-5-Mini 匹配。EmbodiedBrain 比 baseline 高 50+ 个 F1 的差距很难单纯归因于模型能力。
- Step-GRPO 的核心实验缺失 ablation:没有”hint length 分布的影响”、“hint 占比对最终性能的影响”、“GRPO vs Step-GRPO 训练曲线对比”等 RL 论文应有的诊断图。Figure 4 只是流程图。
- VLM-PlanSim-99 仅 99 个任务:作为 stress test 可以,但作为新 SOTA benchmark 偏小,且全是 AI2-THOR 家务场景,覆盖度不够。
- ERQA 上落后 RoboBrain 2.0 作者不愿详谈,可能透露 EmbSpatial 数据存在 distribution overfit。
可信评估
Artifact 可获取性
- 代码: 项目页声称完全开源,但论文与项目页都未给出 GitHub 链接,需到 ZTE NebulaBrain 主页确认
- 模型权重: 7B、32B 两版承诺开源,未在 paper / project page 显示具体 HuggingFace 路径
- 训练细节: 数据配比和 reward 设计较完整;具体 hyperparameter(learning rate、batch size、step 数、KL 权重等)未披露
- 数据集: 大部分是公开数据集二次处理(EmbSpatial、ALFRED、Ego4D、SelfReVision 等);VLM-PlanSim-99 承诺开源
Claim 可验证性
- ✅ Step-GRPO 提升长 horizon planning:grounding 在 Internal Planning F1 与 VLM-PlanSim-99 success rate 上有数值;但缺乏与同类 hint-based 工作的对比
- ✅ Spatial perception 大幅提升:BLINK/CV-Bench/EmbSpatial 数字一致上涨,但很可能主要是数据贡献而非方法
- ⚠️ “State-of-the-art for embodied foundation models”:仅对比了 Qwen2.5-VL baseline 和 RoboBrain 2.0,没有 Robix、Pelican-VL、HY-Embodied 等同期 model
- ⚠️ Internal Planning F1 = 0.90:评估器是 GPT-5-Mini 配 Hungarian/LCS,存在 evaluator bias 风险
- ⚠️ GRM 异步加速 20% “无性能损失”:没给出具体对比表
- ❌ “the most powerful Embodied vision-language foundation model among both open-sourced and closed-sourced models”(intro):没有与 GPT-4o、Gemini 2.5、Claude 等闭源前沿模型在相同 benchmark 上的对比
Notes
- 方法上 incremental,工程上扎实:架构零改动 + 数据 recipe + Step-GRPO 这套配方,复现门槛不高,但也意味着 insight 复用价值有限。Step-GRPO 的 hint injection 思路是少数可以单独借走的部分。
- 评估池有意挑选:选 Qwen2.5-VL 与 RoboBrain 2.0 作为唯二对比,回避了 Robix、Gemini Robotics、闭源前沿等。从 publishable 角度合理,从 important 角度欠缺。
- VLM-PlanSim-99 值得关注:闭环 sim benchmark 在 embodied planning 领域稀缺,规模小是缺陷但定位明确。如果开源后扩到 ~500 任务、纳入更多场景,可能成为可信 reference benchmark。
- 关于 “Step-GRPO” 命名:本质是 “GRPO + curriculum hint”。叫 “Step-Augmented GRPO” 但不与同期同类工作(QuestA、RoboGPT-R1、Reinforced Reasoning for Embodied Planning)对比是个明显缺陷。
- 可借鉴的 RL data curation idea:用 visual mask sensitivity 筛选 RL 训练样本(找最小 使 )这个 protocol 在我们做 VLM agentic-RL 时可以直接借用,比 length filter / perplexity filter 更针对性。
Rating
Metrics (as of 2026-04-24): citation=2, influential=0 (0.0%), velocity=0.33/mo; HF upvotes=0; github=N/A (无代码仓库)
分数:1 - Archived 理由:作为 2025Q4 embodied foundation model 赛道的同期工作,方法上是 Qwen2.5-VL 之上扎实的 post-training recipe,Step-GRPO (QuestA-style hint injection) 和 visual-mask-based RL data curation 都是可借用的工程 trick;但如 Weaknesses 指出,架构零创新、仅对比 Qwen2.5-VL 与 RoboBrain 2.0、内部 benchmark 评估存在 evaluator bias 风险,且与 QuestA / RoboGPT-R1 等同类 hint-based GRPO 工作无对比。2026-04 复核:发布 6mo、cite=2/inf=0/vel=0.33/mo、HF=0、笔记 frontmatter 的 github 字段已为空——rubric 特例中”inf>0、star velocity、HF upvotes”三条 early signal 任一都不成立,且同期有 MiMo-Embodied、Pelican-VL 等更有实证发现的 recipe 在竞争同一生态位;降为 1 - Archived:Step-GRPO 的 hint-injection protocol + visual-mask RL curation 仍可作为一次性方法参考,但方向主脉络已绕开。