Summary
RoboBrain 2.5: Depth in Sight, Time in Mind
- 核心: Embodied AI 基座模型,在 RoboBrain 2.0 基础上新增 Precise 3D Spatial Reasoning 和 Dense Temporal Value Estimation 两大能力
- 方法: 采用 decoupled 表示做 3D spatial trace generation;hop-normalized temporal transition labels + multi-perspective fusion 做 dense value estimation;基于 Qwen3-VL 8B 架构两阶段训练 12.4M 样本
- 结果: 2D/3D spatial reasoning benchmarks SOTA;temporal value estimation VOC 远超 GPT-5.2 和 Gemini-3-Pro-Preview,尤其 reverse VOC 差距极大;RL 训练 20min 实现 95%+ 成功率
- Sources: paper | website | github
- Rating: 2 - Frontier(RoboBrain 系列最新迭代,将 metric 3D spatial 与 dense temporal value 引入 embodied foundation model,方法新颖且在多 benchmark SOTA,但尚未成为方向必引的奠基工作)
Key Takeaways:
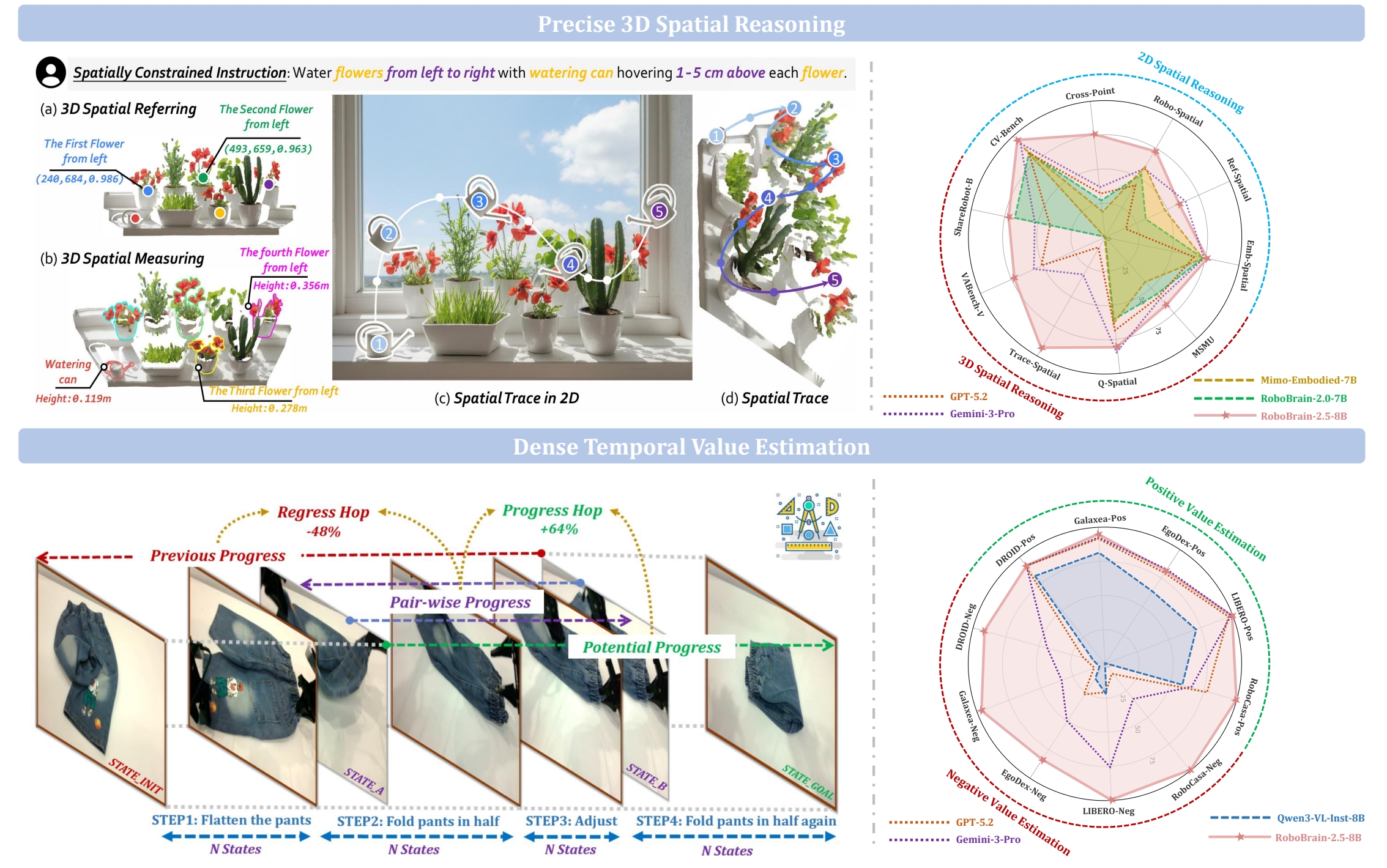
- Precise 3D Spatial Reasoning: 从 2D pixel grounding 升级到 depth-aware 坐标预测,支持 3D spatial referring、measuring 和 trace generation,能生成满足物理约束的完整操作轨迹
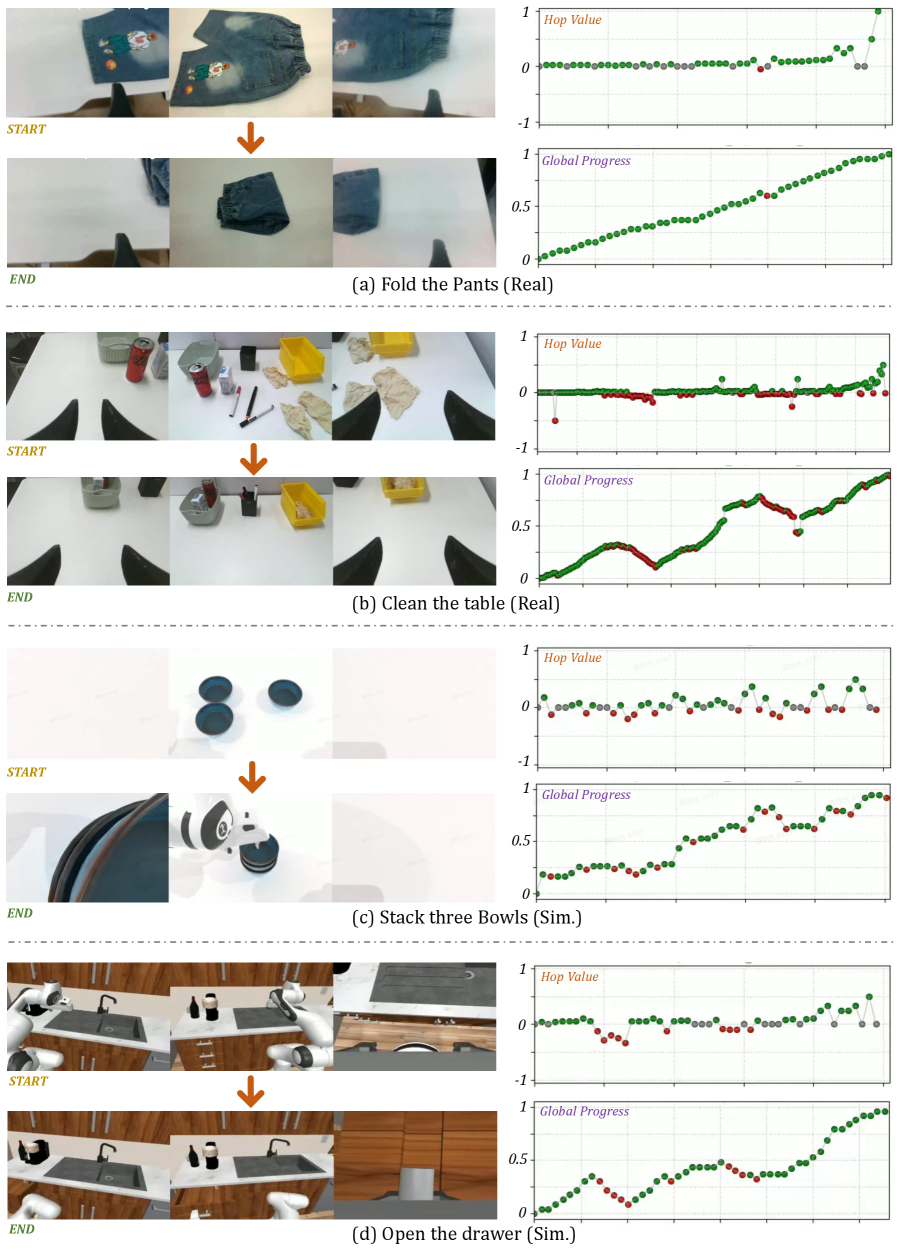
- Dense Temporal Value Estimation: 通过 hop-normalized temporal transition labels 学习相对进度,结合 multi-perspective fusion 和 bi-directional consistency checking,提供 dense、step-aware 的执行状态反馈,可直接作为 RL reward signal
- Cross-accelerator training: 在 NVIDIA 和 Moore Threads GPU 集群上都完成了训练,两者性能高度一致(loss 收敛差距 < 0.62%),展示了 FlagScale 框架的跨加速器训练能力
Teaser. RoboBrain 2.5 新特性概览:3D 空间推理(深度感知 grounding、度量测量、操作轨迹生成)和 dense temporal value estimation(进度/退步预测与 benchmark 性能对比)
Overview
RoboBrain 2.5 是 BAAI 推出的下一代 embodied AI 基座模型,在 RoboBrain 2.0 基础上解决了两个根本性限制——“metric blindness”(空间维度缺乏绝对深度和尺度信息)和 “open-loop prediction”(时间维度缺乏执行进度监控),通过大规模高质量时空监督训练实现了从 semantic reasoner 到 physically-grounded agent 的范式转变。
New Feature
基于 Qwen3-VL 架构,RoboBrain 2.5 在 RoboBrain 2.0 基础上引入两大核心增强:Precise 3D Spatial Reasoning(从 monocular RGB 输入推导 metric-grounded 的 3D 能力)和 Dense Temporal Value Estimation(从 multi-view RGB-only 观测学习通用的 step-aware process modeling)。
Precise 3D Spatial Reasoning
核心思想是将 3D spatial tracing 形式化为预测有序 3D 点序列 ,每个点 包含图像平面坐标和绝对深度。
这个 表示的设计优势:
- 解耦表示:不要求 VLM 隐式学习相机几何,利用已知 camera intrinsics 即可转换到 3D 坐标
- 数据复用:去掉 得 2D visual trace,只保留首尾点得 spatial referring data,兼容已有 2D 数据集,支持多任务 co-training
- 三层能力递进:3D Spatial Referring(定位目标物体)→ 3D Spatial Measuring(估计绝对度量量如距离、间隙)→ 3D Spatial Trace Generation(生成无碰撞关键点轨迹)
Dense Temporal Value Estimation
为解决 sparse feedback 的局限性,提出基于视觉的 dense temporal value estimation 机制。
Hop-wise Progress Construction: 将 value estimation 建模为任务进度估计。三阶段数据 curation pipeline:
- Step-wise discretization: 用人工标注的 multi-view keyframes 分割 expert trajectory 为子任务,adaptive sampling 得到状态序列 ,ground-truth 进度
- Hop-based normalization: 不直接回归进度差 (会误差累积且可能超出 ),而是学习 hop label ,将进度变化相对于剩余距离(forward)或已走距离(backward)归一化到
Equation 2. Hop label 定义
含义: 前进时归一化于到目标的剩余距离,后退时归一化于已走过的距离。关键理论优势:迭代应用预测 hop 重建全局进度时, 保证严格在 内。
Multi-Perspective Progress Fusion: 融合三个互补视角——Incremental Prediction(逐帧累积,捕捉局部动态)、Forward-Anchored Prediction(锚定初始状态 )、Backward-Anchored Prediction(锚定目标状态 ),通过平均得到 robust 的最终进度估计。
Bi-directional Consistency Checking: 解决 online RL 中的 OOD hallucination 问题。利用 forward 和 backward predictions 的一致性作为可靠性代理:OOD 观测下两者严重分歧,in-distribution 时保持一致。通过 Gaussian kernel 计算 confidence weight ,采用 conservative update rule 替代 naive averaging。
Training Data
约 12.4M 高质量样本,分三大类。
Figure 2. 训练数据分布
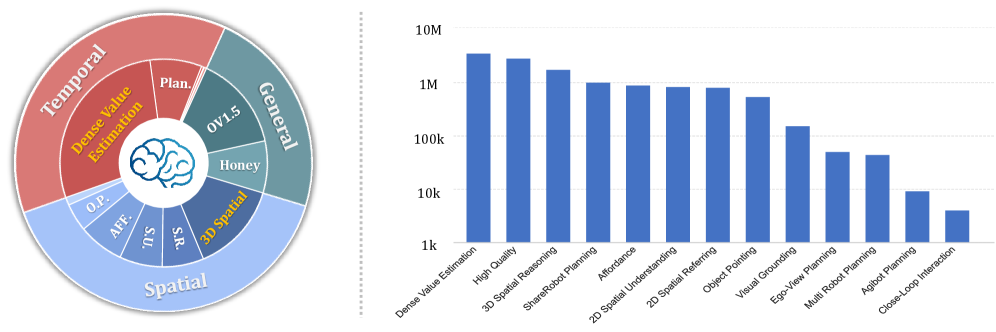
- General MLLM Data (~2.83M): Honey-Data-1M(截断 CoT 只保留 final answer)+ LLaVA-Onevision-1.5-Instruct-Data(过滤 text-only、balanced sampling、sample packing),去重后 2.83M
- Spatial Reasoning Data: Visual Grounding (152K images, 86K conversations from LVIS)、Object Pointing (190K QA from Pixmo-Points)、Affordance (561K QA from PACO-LVIS + 320K QA from RoboPoint)、Spatial Understanding (826K samples, 31 spatial concepts)、Spatial Referring (802K samples)、3D Spatial Reasoning (1.74M samples, 8.08M QA pairs) — 新特性,metric-grounded,使用 CA-1M、ScanNet、AgiBot-Beta、DROID、RoboTwin 2.0
- Temporal Prediction Data: Ego-View Planning (50K from EgoPlan-IT)、ShareRobot Planning (1M QA)、AGIBot Planning (9K QA)、Multi-Robot Planning (44K samples)、Close-Loop Interaction (from AI2Thor)、Dense Value Estimation (~3.5M downsampled from 35M) — 新特性,60% real-world + 13% simulation + 26% human-centric
Training Strategy
两阶段渐进训练:
Stage 1: Foundational Spatiotemporal Learning (8.3M samples)
- 目标:General Visual Perception + 2D Grounding & Qualitative 3D Understanding + Planning & Temporal Logic
- 包含 text-based QA from 3D Spatial Reasoning dataset(定性理解,不回归精确坐标)
- Temporal Value Comparison task(排序 keyframes,建立初步时间进度感知)
Stage 2: Specific Spatiotemporal Enhancement (4.1M samples)
- Metric-Aware 3D Tracing:从定性理解转向定量感知,预测绝对 3D 坐标和 metric 距离
- Dense Value Estimation:从 pairwise comparison 转向显式 Hop prediction
- Anti-Forgetting:随机采样 15% Stage-1 数据混入 Stage-2
训练配置:8B 全模型训练,global batch size 1024,TP=2, PP=2,AdamW,cosine LR schedule,max seq length 16384。NVIDIA 和 Moore Threads 两套集群分别训练(各 512/1024 GPU)。
Infrastructure
基于 FlagScale 分布式训练框架,核心优化:
- Uneven Pipeline Parallelism: ViT 模块放在 pipeline 前端,减少第一 stage 的语言层数量,平衡跨 stage 计算负载
- Dynamic Pre-Allocated Memory: 首次迭代 pad 到最大序列长度做一次性内存预分配,后续复用,避免 GPU memory fragmentation 和 OOM;仅在 visual token 长度超过当前最大值时 reset
- Cross-Accelerator Training: 在非 NVIDIA 加速器(Moore Threads)千卡集群完成端到端训练,loss 收敛差距控制在 0.62% 以内,checkpoint 可无缝迁移到 NVIDIA 平台评估
Evaluation Results
2D Spatial Reasoning
在 CV-Bench、CrossPoint、RoboSpatial、RefSpatial、EmbSpatial 五个 benchmark 上评估。
| Models | CV-Bench | CrossPoint | RoboSpatial | RefSpatial | EmbSpatial | AVG |
|---|---|---|---|---|---|---|
| Gemini-3-Pro-Preview | 92.00 | 38.60 | 57.96 | 65.50 | 76.62 | 66.14 |
| GPT-5.2 | 86.84 | 33.00 | 43.78 | 15.00 | 68.02 | 49.33 |
| Qwen3-VL-8B-Inst. | 92.89 | 28.40 | 66.90 | 54.20 | 78.50 | 64.18 |
| RoboBrain-2.0 (7B) | 85.75 | 26.00 | 54.23 | 32.50 | 76.32 | 54.96 |
| RoboBrain-2.5 (8B) NV | 94.58 | 75.40 | 73.03 | 60.50 | 75.58 | 75.82 |
| RoboBrain-2.5 (8B) MTT | 93.90 | 76.30 | 73.00 | 59.00 | 76.92 | 75.82 |
Insights: CrossPoint(跨视角点对应)上优势极大(75-76 vs 第二名 38.60),说明 3D spatial reasoning 训练显著提升了 fine-grained 点级匹配能力。
3D Spatial Reasoning
| Models | MSMU | Q-Spatial | TraceSpatial (3D Start / End / Success) | VABench-V | ShareRobot-T |
|---|---|---|---|---|---|
| Gemini-3-Pro-Preview | 59.44 | 81.37 | 19 / 25 / 7 | 0.1705 | 0.1899 |
| GPT-5.2 | 57.96 | 69.16 | 3 / 8 / 0 | 0.1962 | 0.2379 |
| Qwen3-VL-8B-Inst. | 43.48 | 70.74 | 30 / 20 / 6 | 0.1979 | 0.2347 |
| RoboBrain-2.5 (8B) NV | 64.17 | 73.53 | 83 / 63 / 44 | 0.1281 | 0.1164 |
| RoboBrain-2.5 (8B) MTT | 61.66 | 78.31 | 80 / 65 / 36 | 0.1189 | 0.1171 |
Insights: TraceSpatial 上差距最为惊人(Success: 44 vs 7),说明 3D trace generation 是其独特能力,通用 VLM 几乎无法完成此任务。
Temporal Value Estimation
采用 General Process Reward Modeling (GPRM) paradigm,报告 Forward VOC / Reverse VOC。
| Models | AgiBot | DROID | Galaxea | EgoDex | LIBERO | RoboCasa |
|---|---|---|---|---|---|---|
| Gemini-3-Pro-Preview | 81.36/58.70 | 90.57/44.15 | 88.86/35.34 | 80.48/50.15 | 98.42/76.31 | 67.89/34.28 |
| GPT-5.2 | 90.02/15.91 | 91.45/15.29 | 88.76/10.03 | 78.12/22.79 | 96.97/19.19 | 77.91/10.71 |
| RoboBrain-2.5 (8B) NV | 83.08/88.58 | 90.82/90.07 | 93.38/95.79 | 79.14/84.99 | 98.97/98.94 | 98.47/98.75 |
| RoboBrain-2.5 (8B) MTT | 87.36/87.48 | 93.67/89.26 | 94.58/94.54 | 80.67/81.12 | 98.88/98.91 | 98.54/99.58 |
Insights: 核心发现在 Reverse VOC 上——通用 VLM forward 方向尚可但 reverse 几乎崩溃(GPT-5.2 多数 <20),说明它们只是利用了某种统计 bias 而非真正理解任务进度。RoboBrain 2.5 forward/reverse 高度对称,说明学到了真正的 temporal progress understanding。
Figure 10. 多任务 dense value prediction 可视化
关联工作
基于
- RoboBrain 2.0: 前代模型,RoboBrain 2.5 在其 general perception 和 reasoning 基础上新增 3D spatial reasoning 和 temporal value estimation
- Qwen3-VL: 底座架构,8B 参数
- TraceSpatial / RoboTracer: 3D Spatial Reasoning 的方法来源和 benchmark
- Robo-Dopamine: Dense Temporal Value Estimation 的方法来源和评估范式
对比
- Gemini-3-Pro-Preview: 通用 VLM baseline,spatial reasoning 部分指标接近但 temporal 远弱
- GPT-5.2: 通用 VLM baseline,forward VOC 尚可但 reverse VOC 极低
- Mimo-Embodied (7B): Embodied baseline
方法相关
- FlagScale: BAAI 自研分布式训练框架,支持 cross-accelerator training
- Hop-based labeling: 来自 Dopamine-Reward pipeline 的时间进度标注方法
论文点评
Strengths
- 问题定义清晰: “metric blindness” 和 “open-loop prediction” 两个概念精准描述了当前 embodied foundation model 的根本限制, decoupled representation 和 hop-normalized labeling 都是简洁优雅的解法
- Hop-based value estimation 设计精巧: 将进度变化相对于剩余/已走距离归一化,理论上保证重建进度在 内,且 bi-directional consistency checking 提供了对 OOD hallucination 的内建防御
- Reverse VOC 指标设计好: 时间反转后重新评估,能区分真正的进度理解 vs 统计 shortcut,这是一个值得推广的评估范式
- Cross-accelerator training 工程价值高: 在非 NVIDIA 千卡集群完成训练且性能几乎一致,对国产算力生态有直接价值
Weaknesses
- 缺乏 end-to-end manipulation 评估: 所有评估都是感知/推理层面的 benchmark,没有在真实机器人上做 end-to-end 操作成功率对比(real-world RL demo 只有 insert block 单个任务的定性展示)
- Dense value estimation 作为 reward 的 RL 训练细节缺失: “20分钟训练达到 95% 成功率”仅在 qualitative examples 中提到,缺乏系统性的 RL 实验(多少任务、多少 seeds、learning curve)
- Spatial trace generation 与 action generation 的 gap 未讨论: keypoints 到实际机器人关节空间动作的转换依赖外部控制器,这个 gap 的影响未分析
- 数据规模与效率: 12.4M 样本中大量来自已有开源数据集(DROID、OXE 系列),核心新增数据的独立贡献不明
可信评估
Artifact 可获取性
- 代码: inference-only(GitHub 提供 quickstart inference 代码)
- 模型权重: RoboBrain2.5-8B-NV、RoboBrain2.5-8B-MT(HuggingFace/ModelScope)、RoboBrain2.5-4B
- 训练细节: 超参 + 数据配比 + 训练策略完整披露(Table 1 详细配置)
- 数据集: 主要使用公开数据集组合(LVIS、Pixmo-Points、CA-1M、ScanNet、DROID 等),数据处理 pipeline 有描述但不开源
Claim 可验证性
- ✅ 2D/3D spatial reasoning benchmark SOTA:FlagEvalMM 框架评估,benchmark 公开
- ✅ Temporal value estimation VOC 指标:评估方法可复现
- ⚠️ “20分钟训练 95%+ 成功率”:仅 insert block 单个任务,qualitative 展示,无系统 ablation
- ⚠️ “physically grounded and execution-aware intelligence”:没有对 physical grounding 质量的系统量化,spatial trace success rate 44% 说明仍有很大提升空间
- ⚠️ Cross-accelerator “loss 收敛差距 0.62%“:数字精确但缺乏具体 loss curve 对比图
Notes
Rating
Metrics (as of 2026-04-24): citation=7, influential=2 (28.6%), velocity=2.26/mo; HF upvotes=13; github 868⭐ / forks=72 / 90d commits=6 / pushed 54d ago
分数:2 - Frontier 理由:作为 RoboBrain 系列最新迭代,在多 spatial/temporal benchmark 上取得 SOTA(CrossPoint、TraceSpatial、Reverse VOC 等,尤其 TraceSpatial Success 44 vs 7 的巨大差距),并提出 hop-normalized value estimation 和 reverse VOC 评估这类值得推广的设计,因此高于 Archived;但尚未达到 Foundation 档——缺乏 end-to-end manipulation 评估、RL 应用仅有 qualitative demo、核心新增数据独立贡献不明,社区采纳度也需时间验证是否会成为 de facto embodied foundation。2026-04 复核:3.1 月 7 citation / 2 influential (28.6%,远高于 ~10% 典型值,说明方法被实质继承) / github 868⭐ / HF upvotes=13 / 仍在维护(pushed 54d、90 天 6 commits),早期采纳信号强于同期作品;但与方向 landmark(π0 系列)的 adoption 差距仍大,维持 Frontier。