Summary
RoboBrain 2.0 Technical Report
- 核心: 统一 perception、reasoning、planning 的 embodied VLM,在空间和时序推理 benchmark 上取得领先结果
- 方法: 异构 ViT + LLM 架构(基于 Qwen2.5-VL),三阶段渐进训练(基础时空学习 → embodied 增强 → CoT 推理 + RLVR)
- 结果: 32B 变体在 12+ benchmark 中 6 个 SOTA,超越 GPT-4o、Gemini-2.5-Pro 等闭源模型
- Sources: paper | website | github
- Rating: 2 - Frontier(当前 embodied VLM 方向的重要 open-weight baseline,3B/7B/32B 全量开源且已被 awesome-list 与后续工作收录;但架构贴合 Qwen2.5-VL 微调、缺 real-robot 定量评估,尚未形成 de facto 基座)
Key Takeaways:
- 三阶段渐进训练: 从基础时空感知到 embodied 增强再到 CoT 推理 + GRPO 强化,逐步提升模型的 embodied reasoning 能力
- 空间数据合成 pipeline: 针对空间数据稀缺问题,构建了大规模高质量空间数据集,涵盖 pointing、affordance、spatial understanding、spatial referring 等 31 种空间概念
- 紧凑模型超越闭源: 7B/32B 模型在多个 embodied benchmark 上超越 GPT-4o、Gemini-2.5-Pro 等,32B 在 RoboSpatial、RefSpatial-Bench、Where2Place 等 benchmark 上大幅领先
Teaser. Benchmark comparison across spatial and temporal reasoning
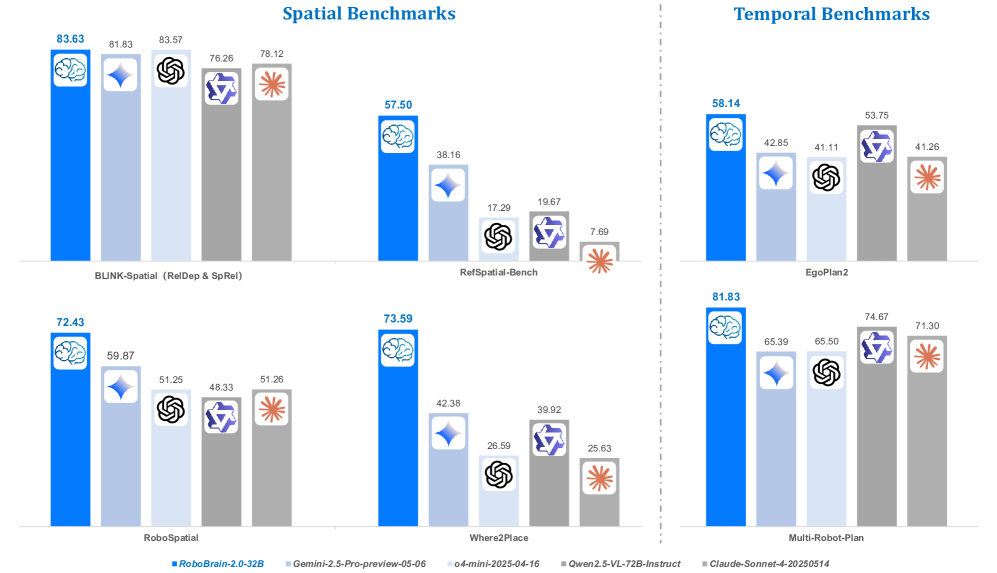
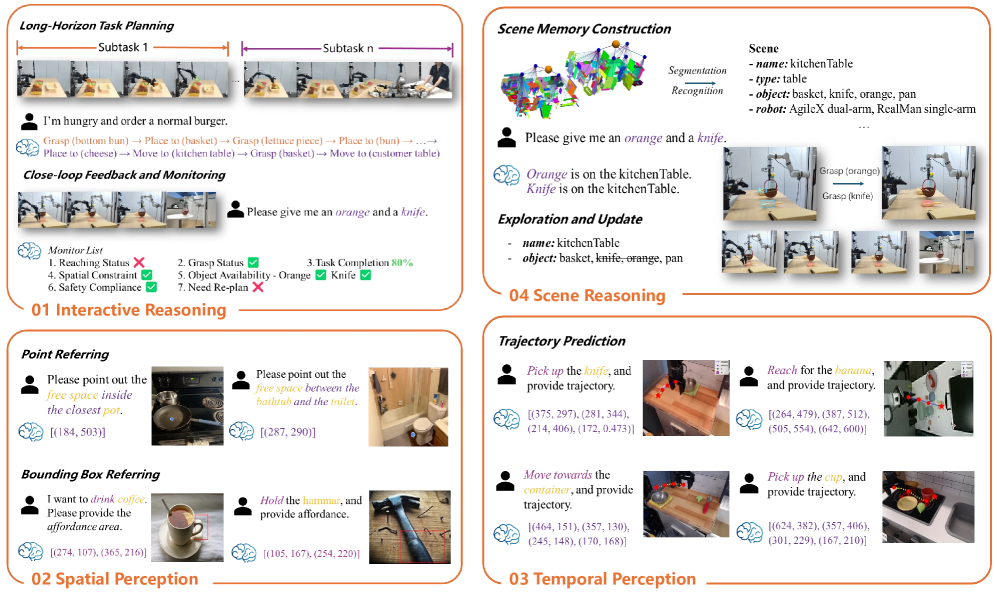
Figure 2. RoboBrain 2.0 能力概览:interactive reasoning、spatial perception、temporal perception、scene reasoning
Architecture
RoboBrain 2.0 采用模块化 encoder-decoder 架构,包含四个核心组件:(1) language tokenizer,(2) vision encoder(~689M 参数),(3) MLP projector,(4) decoder-only LLM backbone(初始化自 Qwen2.5-VL,7B/32B)。
Figure 3. RoboBrain 2.0 架构图
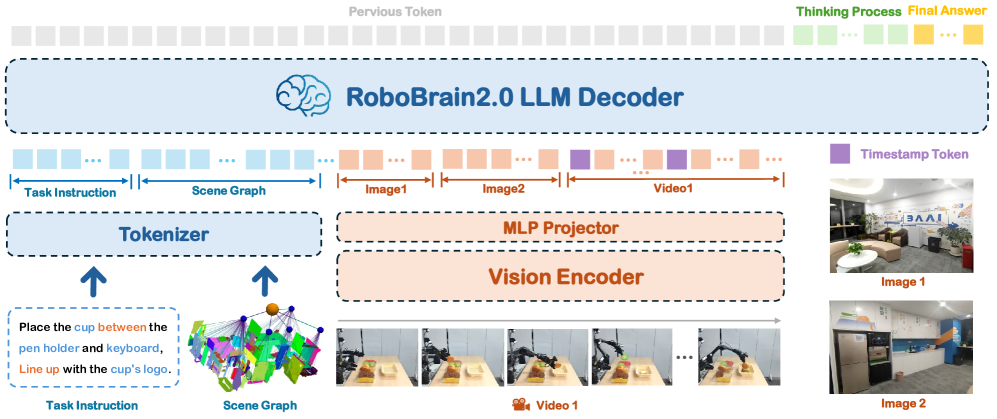
Input Modalities and Tokenization
支持四类输入模态:
- Language instructions:从 high-level 空间指令到 low-level 动作命令
- Scene graph:JSON 格式的环境结构化表示,包含物体类别、空间位置、embodiment 配置
- Multi-view static images:多视角图像(head/wrist camera、multi-view projections)
- Video frames:带 timestamp tokens 的视频序列
Vision Encoder and Projection
Vision encoder 支持 dynamic-resolution 输入,通过 adaptive positional encoding 和 windowed attention 处理高分辨率/多视角视觉输入。采用 frame-wise visual tokenization + multi-dimensional RoPE 做时空编码。
LLM Decoder and Output Representations
Decoder 支持三种输出:
- Free-form text:任务分解、scene graph 更新、agent 调用
- Spatial coordinates:点位置、bounding box、轨迹
- Reasoning traces(Optional):长链 CoT 推理
Training Data
训练数据涵盖三大类:general multimodal understanding、spatial perception、temporal modeling。
Figure 4. 训练数据分布
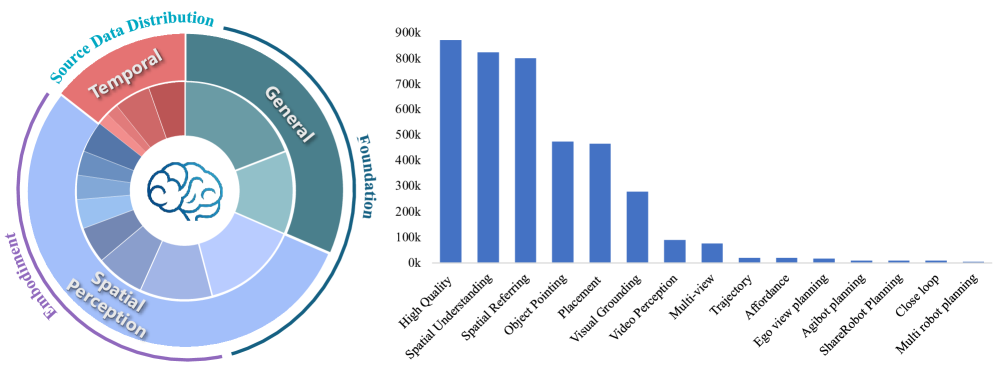
General MLLM VQA
873K 高质量样本,来自 LLaVA-665K 和 LRV-400K。处理后保留 531K + 342K 样本,覆盖 VQA、region-level queries、OCR-VQA、visual dialogues。
Spatial Data
空间数据包含五个子类:
- Visual Grounding:基于 LVIS 的 152K 图像,86K 对话序列
- Object Pointing:基于 Pixmo-Points(190K QA pairs)和 RoboPoint(347K QA annotations),经过 GPT-4o 过滤确保 indoor 相关性
- Affordance:基于 PACO-LVIS(561K QA pairs)和 RoboPoint(320K QA pairs),覆盖 object affordance 和 spatial affordance
- Spatial Understanding:826K 样本,涵盖 31 种空间概念(远超此前~15 种),通过 2D web images → pseudo-3D scene graph 转换和 3D scene-based videos 构建
- Spatial Referring:802K 样本,面向 unambiguous single target,支持 precise pick-and-place
Temporal Data
时序数据包含五个子类:
- Ego-View Planning:基于 EgoPlan-IT(50K 样本),egocentric task planning
- ShareRobot Planning:1M QA pairs,51K instances,12 种 robot embodiments
- AgiBot Planning:9,148 QA pairs,19 manipulation tasks
- Multi-Robot Planning:基于 RoboOS 模拟,1,659 类协作任务,44,142 样本(由 DeepSeek-V3 生成)
- Close-Loop Interaction:在 AI2Thor 中生成 OTA(Observation-Thought-Action)轨迹,120 种 indoor 环境,4000+ 交互物体
Training Strategy
三阶段渐进训练策略:
Stage 1: Foundational Spatiotemporal Learning — 在大规模多模态数据集上 SFT,学习基础的 spatial perception 和 temporal understanding。全模型训练,4.8M 样本。
Stage 2: Embodied Spatiotemporal Enhancement — 引入 high-resolution、multi-view、egocentric video 数据,学习 long-horizon temporal dependencies 和 multi-agent coordination。224K 样本。
Stage 3: Chain-of-Thought Reasoning — 两阶段 CoT 训练:
- CoT-SFT Phase:用 GPT-4o 标注 10% 训练数据的 CoT rationales(195K 样本)
- RFT Phase:采用 GRPO(Group Relative Policy Optimization)做强化微调(45K 样本,3 epochs),reward function 评估 answer accuracy 和 format correctness
Table 1. 各训练阶段配置
| Stage-1 SFT | Stage-2 SFT | Stage-3 CoT-SFT | Stage-3 RFT (RLVR) | |
|---|---|---|---|---|
| Dataset | Foundation | Embodied | Embodied (Phase 1) | Embodied (Phase 2) |
| Samples | 4.8M | 224K | 195K | 45K |
| Trainable Part | Full Model | Full Model | Full Model | Full Model |
| Tunable Params | 8.29B or 33.45B | 8.29B or 33.45B | 8.29B or 33.45B | 8.29B or 33.45B |
| LR | 1e-4 | 1e-5 | 1e-5 | 1e-6 |
| Epoch | 1 | 1 | 1 | 3 |
| Max Seq. Length | 16384 | 16384 | 32768 | 32768 |
| GPU Nums | 16/64 x 8 | 16/64 x 8 | 4 x 8 | 4 x 8 |
Evaluation Results
Spatial Reasoning Capability
Table 2. 五个空间推理 benchmark 上的表现
| Models | BLINK All | CV-Bench | EmbSpatial | RoboSpatial | RefSpatial-Bench All |
|---|---|---|---|---|---|
| Gemini-2.5-Pro | 81.83 | 84.59 | 78.74 | 59.87 | 38.16 |
| GPT-o4-mini | 83.57 | 85.21 | 78.29 | 51.25 | 17.29 |
| GPT-4o | 77.90 | 78.63 | 71.92 | 44.42 | 8.78 |
| Qwen2.5-VL-32B | 81.37 | 81.59 | 74.45 | 52.16 | 13.72 |
| Qwen2.5-VL-72B | 76.26 | 82.68 | 73.30 | 48.33 | 19.67 |
| RoboBrain-7B-2.0 | 83.95 | 85.75 | 76.32 | 54.23 | 32.50 |
| RoboBrain-32B-2.0 | 83.63 | 83.92 | 78.57 | 72.43 | 54.00 |
Table 3. 四个空间推理 benchmark 上的表现
| Models | SAT | VSI-Bench | Where2Place All | ShareRobot Afford. | ShareRobot Traj. (DFD↓) |
|---|---|---|---|---|---|
| Gemini-2.5-Pro | 79.33 | 47.81 | 42.38 | 10.26 | 0.7666 |
| GPT-o4-mini | 82.00 | 41.96 | 26.59 | 8.27 | 0.5726 |
| Qwen2.5-VL-72B | 58.67 | 35.51 | 39.92 | 23.80 | 0.5034 |
| RoboBrain-7B-2.0 | 75.33 | 36.10 | 63.59 | 28.05 | 0.5512 |
| RoboBrain-32B-2.0 | 86.67 | 42.69 | 73.59 | 35.28 | 0.2368 |
Insights: RoboBrain-32B 在 embodied-specific benchmark(RoboSpatial、RefSpatial-Bench、Where2Place、ShareRobot)上的优势远大于 general spatial benchmark(BLINK、CV-Bench),说明 embodied 增强训练阶段在 robotic spatial tasks 上的效果显著。7B 模型在 BLINK 和 CV-Bench 上甚至超越 32B,可能因 Stage 1 的 foundation 数据对通用空间感知贡献更大。
Temporal Reasoning Capability
Table 4. 三个时序推理 benchmark 上的表现
| Models | Multi-Robot Planning All | Ego-Plan2 All | RoboBench Plan. |
|---|---|---|---|
| GPT-4o | 74.50 | 41.79 | 68.60 |
| Qwen2.5-VL-72B | 74.67 | 53.75 | 66.94 |
| Claude-Sonnet-4 | 71.30 | 41.26 | 70.21 |
| RoboBrain-7B-1.0 | 5.50 | - | 38.93 |
| RoboBrain-7B-2.0 | 81.50 | 33.23 | 72.16 |
| RoboBrain-32B-2.0 | 80.33 | 57.23 | 68.33 |
Insights: RoboBrain 7B-2.0 在 Multi-Robot Planning(81.50)上甚至略超 32B(80.33),但在 Ego-Plan2 上远低于 32B(33.23 vs 57.23)。Multi-Robot Planning 的巨大提升(7B-1.0: 5.50 → 7B-2.0: 81.50)直接归因于 RoboOS 模板生成的 44K 协作训练数据。
Video. System Stability 演示
Video. Real-time Scene Adaptation 演示
关联工作
基于
- Qwen2.5-VL: LLM backbone 初始化来源
- Reason-RFT: Stage 3 CoT+RFT 两阶段框架的核心训练策略
- RoboOS: Multi-robot coordination 系统,用于生成 multi-robot planning 训练数据
- RoboBrain 1.0: 前身,CVPR 2025
对比
- Cosmos-Reason1-7B: embodied baseline
- VeBrain-8B: embodied baseline
- Magma-8B: embodied baseline
方法相关
- GRPO: Stage 3 RFT 的优化算法
- FlagScale: 开源训练框架,支持 hybrid parallelism
- RefSpatial: 空间数据构建 pipeline
- RoboPoint: Object pointing 和 spatial affordance 数据来源
论文点评
Strengths
- 全面的空间数据构建 pipeline:从 2D web image 到 pseudo-3D scene graph 的转换,以及 31 种空间概念的覆盖,在空间数据稀缺的现状下是实质性的贡献
- 三阶段训练设计合理:基础 → 增强 → CoT+RLVR 的渐进策略比单阶段训练更有效,Stage 3 的 GRPO 强化在 embodied reasoning 上是值得探索的方向
- Benchmark 覆盖广泛:在 12+ benchmark 上系统评估,且包含多个 embodied-specific benchmark(不只是通用 VQA),结果具有参考价值
- 开源完整:3B/7B/32B 三个变体均开源权重,代码和评估工具齐全
Weaknesses
- 架构无创新:直接基于 Qwen2.5-VL,核心贡献在数据和训练策略而非架构设计。模型本身是 Qwen2.5-VL 的 embodied 微调版本
- 缺乏 real-robot 定量评估:所有 benchmark 都是 vision-language 层面的评估,没有 real-world manipulation/navigation 的 success rate 数据。Demo 视频展示了 real-robot 能力但无定量结果
- 训练数据部分依赖合成:44K multi-robot planning 由 DeepSeek-V3 生成,CoT rationale 由 GPT-4o 标注——合成数据的分布偏差和上界问题未讨论
- Temporal reasoning 不均衡:7B 在 Ego-Plan2 上仅 33.23,远低于 Qwen2.5-VL-32B 的 56.25,说明小模型的 temporal reasoning 能力还有明显短板
可信评估
Artifact 可获取性
- 代码: inference+training(通过 FlagScale 框架开源)
- 模型权重: RoboBrain2.0-3B、RoboBrain2.0-7B、RoboBrain2.0-32B(均在 HuggingFace BAAI 组织下发布)
- 训练细节: 超参 + 数据配比 + 训练阶段完整披露(Table 1)
- 数据集: 部分公开——基于多个公开数据集(LVIS、Pixmo-Points、PACO-LVIS、EgoPlan-IT 等)构建,但合成数据(44K multi-robot、CoT rationale、OTA 轨迹)是否开源未说明
Claim 可验证性
- ✅ Spatial benchmark SOTA(BLINK、CV-Bench、RoboSpatial 等):有完整的对比实验和评估框架 FlagEvalMM,开源权重可复现
- ✅ Temporal benchmark 领先(Multi-Robot Planning、RoboBench):结果可通过开源 checkpoint 复现
- ⚠️ “unify perception, reasoning, and planning”:模型确实支持多种任务,但”统一”更多是 multi-task SFT 而非真正的 unified representation
- ⚠️ “practical step toward building generalist embodied agents”:缺乏 real-robot 定量评估,从 vision-language benchmark 到实际部署的 gap 未量化
Notes
Rating
Metrics (as of 2026-04-24): citation=69, influential=9 (13.0%), velocity=7.11/mo; HF upvotes=36; github 868⭐ / forks=72 / 90d commits=6 / pushed 54d ago
分数:2 - Frontier 理由:从 Strengths 看,3B/7B/32B 全量开源 + 12+ benchmark 系统评估 + 31 类空间概念数据 pipeline,使其成为 embodied VLM 方向当前必引的 open-weight baseline(已被 awesome-embodied-vla 等列入代表工作,与 VeBrain、Cosmos-Reason1 形成同期对比)。但从 Weaknesses 看,架构只是 Qwen2.5-VL 的 embodied 微调,没有 real-robot 定量评估,也未形成 de facto benchmark 或被多数后续工作作为核心比较基座,不足以升 3;同时其完整的 artifact 开放度和紧凑模型打赢闭源的结果明显高于一次性参考,不应降 1。