Summary
Visual Embodied Brain (VeBrain)
- 核心: 将机器人控制重新表述为 2D 视觉空间中的文本 MLLM 任务(keypoint detection + skill recognition),统一多模态理解、空间推理和机器人控制
- 方法: 基于 Qwen2.5-VL-7B,通过 robotic adapter(point tracker + movement controller + skill executor + dynamic takeover)将 MLLM 文本信号转换为运动策略;构建 VeBrain-600k 指令数据集
- 结果: 在 13 个多模态 benchmark 上平均超越 Qwen2.5-VL(MMVet +5.6%),在足式机器人任务上平均成功率 86.4%(+50% vs Qwen2.5-VL),在机械臂任务上成功率 74.3%(+42.9% vs π0)
- Sources: paper | website | github
- Rating: 2 - Frontier(统一 MLLM+VLA 的代表方法,keypoint reformulation 设计简洁有效,但自建 eval、控制数据私有且代码未开源,尚未成为 de facto 标准)
Key Takeaways:
- 统一目标空间: 将机器人控制重新表述为 2D 视觉空间中的文本任务,避免 VLA 直接输出 action policy 导致的多模态能力遗忘问题
- Robotic Adapter 闭环: 通过 point tracker、movement controller、skill executor、dynamic takeover 四模块将 MLLM 的 2D keypoint + skill 文本决策转换为 3D 运动策略,实现动态鲁棒控制
- VeBrain-600k 数据引擎: 200k 多模态理解 + 312k 空间推理 + 88k 机器人控制数据,通过 multimodal CoT 混合不同能力到单个对话中
Teaser. VeBrain 概览——统一多模态理解、空间推理和机器人控制的框架及 VeBrain-600k 数据集

Video. VeBrain demo 展示
Introduction
现有 MLLM 在扩展到物理实体时面临根本挑战:VLA 模型直接将多模态输入映射到物理运动策略,与 MLLM 在 2D 视觉空间的跨模态对齐目标本质不同,导致知识遗忘和任务冲突。VeBrain 的核心思想是将机器人控制表述为 MLLM 的常规文本任务,具体分解为 keypoint detection 和 embodied skill recognition 两个子任务。
Method
Task Formulations
所有任务统一为 的形式,其中 为视觉输入, 为文本 prompt, 为答案。三个设计原则:
- 统一输入输出空间: 所有任务使用相同的 input-output mapping
- 2D 视觉空间中的文本任务: 机器人控制定义为 point detection 等常规 MLLM 任务
- Task-specific CoT: 按步骤引导模型解决复杂问题
对于机器人控制,CoT 过程包含:环境感知 → 任务规划 → 当前决策(keypoint detection + skill recognition)。
VeBrain Framework
Figure 2. VeBrain 架构和 Robotic Adapter 的闭环控制系统
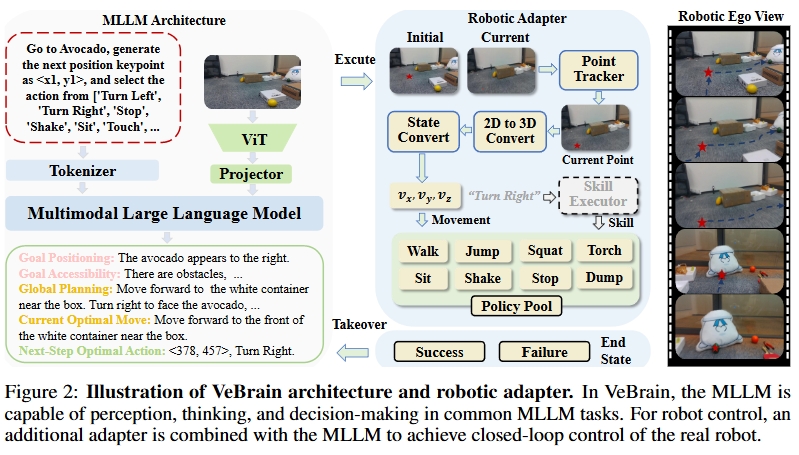
MLLM Architecture
基于 Qwen2.5-VL,包含 vision encoder(stride 14 的 ViT,使用 RMSNorm、SwiGLU、2D-RoPE、window attention)、projector 和 LLM。前向过程:
Equation 1. MLLM 前向推理
符号说明: 为 next-token 概率, 为词表大小, 为 ViT + MLP, 为文本 tokenizer, 为 LLM。 含义: 训练时冻结 vision encoder 和 projector,只训练 LLM 部分。
Robotic Adapter
MLLM 的 2D keypoint 预测与真实世界部署之间存在三个 gap:2D→3D 转换、ego-view 实时变化导致的 keypoint 失配、MLLM 无法感知机器人状态。Robotic adapter 四个模块:
- Point Tracker: 使用 LocoTrack 实时追踪 keypoint,在机器人移动时持续更新 2D keypoint 以匹配新视角
- Movement Controller: 通过 RGBD 相机获取深度信息,将 2D keypoint 经标定矩阵转换为 3D 点,估计运动速度驱动底层运动策略
- Skill Executor: 维护预训练技能策略库(walking、jumping 等),根据 MLLM 预测的技能名称调用对应策略
- Dynamic Takeover: 当 keypoint 丢失数帧或子任务完成时,将控制权交还 MLLM 重新规划
VeBrain-600k Data Engine
Figure 3. VeBrain-600k 数据引擎

三类数据构成:
- 200k 多模态理解: 2D 图像、视频和文本描述,来源于 ShareGPT4V、MMInstruct 等开源数据集 + GPT-4o 生成
- 312k 空间推理: 来源于 GPT4Scene 和自标注数据(基于 ScanNet 的 counting、object size、distance 等)
- 88k 机器人控制: 4 名专家 80+ 小时采集足式机器人和机械臂的视频 episode 和运动状态,5 名专家标注 keypoint 和 action
CoT 生成: 使用 Gemini-2.0 和 GPT-4o 生成 CoT 内容,采用 cross-model validation(Gemini-2.0 评估 GPT-4o 生成的 CoT 的逻辑/物理合理性),人工抽检 10% 数据仅 5.3% 被排除。
Experiments
Implementation Details
- 基座: Qwen2.5-VL-7B-Instruct
- 训练: 32x A100 GPU,2 天,lr=5e-6,1 epoch,4865 steps,batch size 128
- 冻结 vision tower 和 multimodal projector,仅训练 LLM decoder
- 部署: MLLM 在云端 A100 上运行(0.5Hz),tracking model 在 Jetson Orin 上运行(15Hz)
- 足式机器人: Unitree Go2 + RealSense D435i + Jetson AGX Orin
- 机械臂: 7-DoF Franka Emika Panda + Robotiq 2F-85 gripper
Quantitative Results
Table 1. 框架和数据的消融实验
| 配置 | MMVet | MMBench | ScanQA (CIDEr) | VSI-Bench | Complex Find | Transporting | Avg |
|---|---|---|---|---|---|---|---|
| Qwen2.5-VL | 67.1 | 83.5 | 62.7 | 35.9 | 0.0 | 10.0 | 43.2 |
| + Robotic Adapter | 67.1 | 83.5 | 62.7 | 35.9 | 0.0 | 40.0 | 48.2 |
| + Control Data | 67.2 | 82.7 | 56.8 | 32.8 | 30.0 | 50.0 | 53.3 |
| + Spatial Reasoning Data | 64.7 | 82.1 | 102.2 | 40.3 | 65.0 | 70.0 | 70.7 |
| + Multimodal Understanding Data | 72.7 | 83.7 | 101.5 | 39.9 | 80.0 | 90.0 | 78.0 |
Insights: 关键发现——加入 control data 后多模态能力基本保持(MMVet 67.2 vs 67.1),验证了将控制重新表述为 2D MLLM 任务的设计能有效避免能力冲突。每类数据对对应能力贡献显著(spatial data → VSI-Bench +7.5%)。
Table 2. 与 MLLM 和 VLA 框架的对比
| 框架 | 控制信号 | Adapter | MMVet | MMBench | ScanQA | VSI-Bench | Complex Find | Transporting | Avg |
|---|---|---|---|---|---|---|---|---|---|
| MLLM | Text | ✗ | 67.1 | 83.5 | 62.7 | 35.9 | 10.0 | 20.0 | 46.5 |
| VLA | Action policy | ✗ | 50.8 | 73.4 | 55.1 | 29.8 | 50.0 | 30.0 | 48.2 |
| VeBrain | Points & Action | ✓ | 72.7 | 83.7 | 101.5 | 39.9 | 80.0 | 90.0 | 78.0 |
Insights: VLA 在控制任务上可用但严重牺牲多模态能力(MMVet -16.3%),MLLM 保留理解但控制弱。VeBrain 在所有维度均最优,平均 +31.5%。
Table 6. 足式机器人 7 个任务的性能对比(10 次试验成功率)
| 模型 | Adapter | Find | Track | Interaction | Complex Find | Complex Interaction | Transport | Complex Transport | Overall |
|---|---|---|---|---|---|---|---|---|---|
| VLA | ✗ | 70.0 | 30.0 | 20.0 | 50.0 | 15.0 | 30.0 | 10.0 | 32.1 |
| VLM-PC | ✗ | 60.0 | 40.0 | 10.0 | 10.0 | 5.0 | 20.0 | 0.0 | 20.7 |
| GPT-4o | ✓ | 40.0 | 10.0 | 35.0 | 10.0 | 5.0 | 40.0 | 10.0 | 21.4 |
| Qwen2.5-VL-7B | ✓ | 100.0 | 100.0 | 15.0 | 20.0 | 10.0 | 40.0 | 10.0 | 42.1 |
| VeBrain | ✓ | 100.0 | 100.0 | 90.0 | 80.0 | 85.0 | 90.0 | 60.0 | 86.4 |
Insights: VeBrain 在复杂组合任务上优势最大(Complex Transport 60% vs 其他 ≤10%),体现了统一感知-推理-控制能力在长程复杂任务中的价值。
Table 7. 机械臂 7 个任务的性能对比(10 次 demo 训练)
| 模型 | Move In (Banana) | Move In (Pepper) | Move Out (Carrot) | Move Out (Kiwifruit) | Open Drawer | Long-Horizon (Carrot) | Long-Horizon (Pepper) | Overall |
|---|---|---|---|---|---|---|---|---|
| OpenVLA | 0.0 | 10.0 | 10.0 | 20.0 | 40.0 | 0.0 | 0.0 | 11.4 |
| π0 | 0.0 | 30.0 | 90.0 | 50.0 | 50.0 | 0.0 | 0.0 | 31.4 |
| VeBrain | 70.0 | 70.0 | 90.0 | 60.0 | 90.0 | 60.0 | 80.0 | 74.3 |
Insights: VeBrain 在 long-horizon 任务上优势极大(60-80% vs π0 0%),表明 keypoint-based 控制方式在需要多步推理的任务上远优于端到端 action policy。
Visualizations
Figure 3. VeBrain 在机械臂和足式机器人上的可视化结果

VeBrain 通过组合能力处理复杂机器人任务:例如寻找隐藏的辣椒时,能正确推测可能位置并逐步执行;在搬运任务中能判断货物是否已送达目的地。
关联工作
基于
- Qwen2.5-VL: 作为 MLLM backbone,冻结 vision encoder 和 projector 进行 SFT
- LocoTrack: 用于 robotic adapter 中的 point tracking 模块
对比
- OpenVLA: 端到端 VLA baseline,训练后完全丧失多模态理解能力
- π0: VLA baseline,在 long-horizon 机械臂任务上成功率为 0%
- RoboBrain: 同样尝试统一多模态和机器人控制的 VLA,但在 OCR/Chart benchmark 上明显落后
- ChatVLA: 保留部分多模态能力的 VLA,但整体性能仍低于 VeBrain
- GPT4Scene-HDM: 3D 空间推理专家模型,VeBrain 作为通用模型仍超越
方法相关
- VLM-PC: MLLM 直接通过文本描述控制机器人的 baseline 方法
- GPT4Scene: 提供空间推理训练数据的来源
论文点评
Strengths
- 问题定义精准: 识别出 VLA 与 MLLM 目标空间不一致是导致能力冲突的根本原因,将控制重新表述为 2D 视觉空间的文本任务是一个简洁优雅的解决方案
- Robotic Adapter 设计务实: point tracker + dynamic takeover 形成闭环,解决了 ego-view 变化和意外情况的实际问题,而非理想化的端到端方案
- 实验充分: 覆盖 13 个多模态 benchmark + 5 个空间推理 benchmark + 14 个真实机器人任务,跨足式机器人和机械臂两种平台验证
- 消融设计清晰: Tab 1/2 清楚展示了每个设计选择的贡献,特别是控制数据不损害多模态能力这一关键结论
Weaknesses
- Robotic Adapter 依赖预训练技能库: skill executor 依赖预先收集的动作策略(walking、jumping 等),新技能的扩展性和泛化到未见技能的能力未讨论
- 0.5Hz 推理频率: MLLM 部署在云端 A100 上仅 0.5Hz,实际控制依赖 point tracker 的 15Hz 插值,快速动态场景的适应能力存疑
- 评估规模有限: 每个机器人任务仅 10 次试验,统计置信度不高;自建评估场景缺乏社区标准 benchmark 的可比性
- 训练数据中 88k 控制数据全部自采: 泛化到未见场景/物体的能力验证不充分
可信评估
Artifact 可获取性
- 代码: 未开源(GitHub README 仅有简介和 citation)
- 模型权重: 已发布在 HuggingFace(OpenGVLab/VeBrain),基于 Qwen2.5-VL-7B
- 训练细节: 超参完整披露(Tab 8),包括 lr、batch size、训练步数、冻结策略等
- 数据集: VeBrain-600k 未明确开源计划;部分基于开源数据(ShareGPT4V、MMInstruct、ScanNet),88k 控制数据为私有
Claim 可验证性
- ✅ 多模态 benchmark 性能(MMVet +5.6%、平均 77.1):基于公开 benchmark,可独立复现
- ✅ 空间推理性能(ScanQA CIDEr 101.5、VSI-Bench 39.9):公开 benchmark 可验证
- ⚠️ 机器人控制成功率(86.4% 足式、74.3% 机械臂):仅 10 次试验、自建场景,统计置信度有限
- ⚠️ “首次在多模态任务上超越 SOTA MLLM 同时保留机器人控制能力”:依赖于比较范围和指标选择(normalized average)
Notes
Rating
Metrics (as of 2026-04-24): citation=23, influential=3 (13.0%), velocity=2.13/mo; HF upvotes=35; github 88⭐ / forks=7 / 90d commits=0 / pushed 321d ago · stale
分数:2 - Frontier 理由: VeBrain 以 keypoint+skill 文本化的 reformulation 提供了一个简洁有效的统一 MLLM 与 VLA 的范式,实验覆盖 13+ 多模态 benchmark 与双平台真机任务,是同期 unified embodied MLLM 方向的代表工作之一(与 RoboBrain、ChatVLA 形成直接对比)。但不够格升 3:代码未开源、VeBrain-600k 中 88k 控制数据私有、机器人评估自建且仅 10 次试验,未形成 de facto benchmark 或被后续主要工作广泛作为基准;也不应降 1:来自 Shanghai AI Lab/OpenGVLab 的高质量执行、问题定义清晰、消融完整,仍是该方向必须参考的 frontier 工作。