Summary
Pelican-VL 1.0: A Foundation Brain Model for Embodied Intelligence
- 核心: 提出 DPPO(Deliberate Practice Policy Optimization)训练框架,通过 RL-SFT metaloop 迭代训练最大规模开源 embodied VLM(7B-72B)
- 方法: DPPO metaloop = RL 探索弱项 → 难样本发现 → SFT 巩固,统一于 preference learning 框架;从 4B+ token 中蒸馏高质量数据
- 结果: 72B 模型在 embodied benchmark 上平均 63.8%,超越 Qwen2.5-VL-72B 基座 20.3%,比肩 GPT-5 等闭源系统
- Sources: paper | website | github
- Rating: 2 - Frontier(开源最大规模 embodied VLM + 新颖 DPPO 训练框架,但基座依赖和 clean ablation 缺失使其尚未达到 Foundation 级别)
Key Takeaways:
- DPPO Metaloop 框架: 受 deliberate practice 启发,交替执行 RL(探索弱项 + skill refinement)和 SFT(巩固 + competence expansion),形成自进化闭环。RL 和 SFT 被统一为 preference learning 的两个特例
- 大规模训练: 1000+ A800 GPU,每个 checkpoint 50k+ GPU-hours,数据涵盖 231M 图像 + 29k 小时视频 + 4B training tokens
- 全栈 embodied 验证: 首个 VLM 闭合触觉感知运动环路(预测 + 调整抓取力);affordance reasoning 实现零样本操作;多机器人协作的长程规划
Teaser. Performance comparison
Introduction
Embodied AI 领域存在两大策略分歧:(1) 数据规模化(Gemini Robotics, π0.5, GR00T N1 等),通过海量数据适配 foundation model;(2) 架构精细化(Helix, Wall-OSS 等),用大 VLM 做高层推理 + 小 policy 做低层控制。两者各有不足——前者缺乏精细的学习框架来管理异质数据,后者缺乏大规模数据支撑泛化。
Pelican-VL 1.0 试图统一这两个范式:在大规模数据基础上,引入 DPPO 作为智能的自适应学习机制。其核心理念是 computational metacognition——让 AI 学会如何学习。
Methodology
Problem Formulation
将 embodied 场景建模为复合多模态环境。给定视觉输入 (图像或视频帧)和文本输入 (指令、问题),模型预测输出 ,可以是 reasoning traces、task plans、action sequences 或 structured function calls。
高维状态-动作空间和复杂多任务需求使得单阶段训练(纯 SFT 或纯 RL)不够用。
Training Framework: DPPO
Figure 2. DPPO 训练框架总览
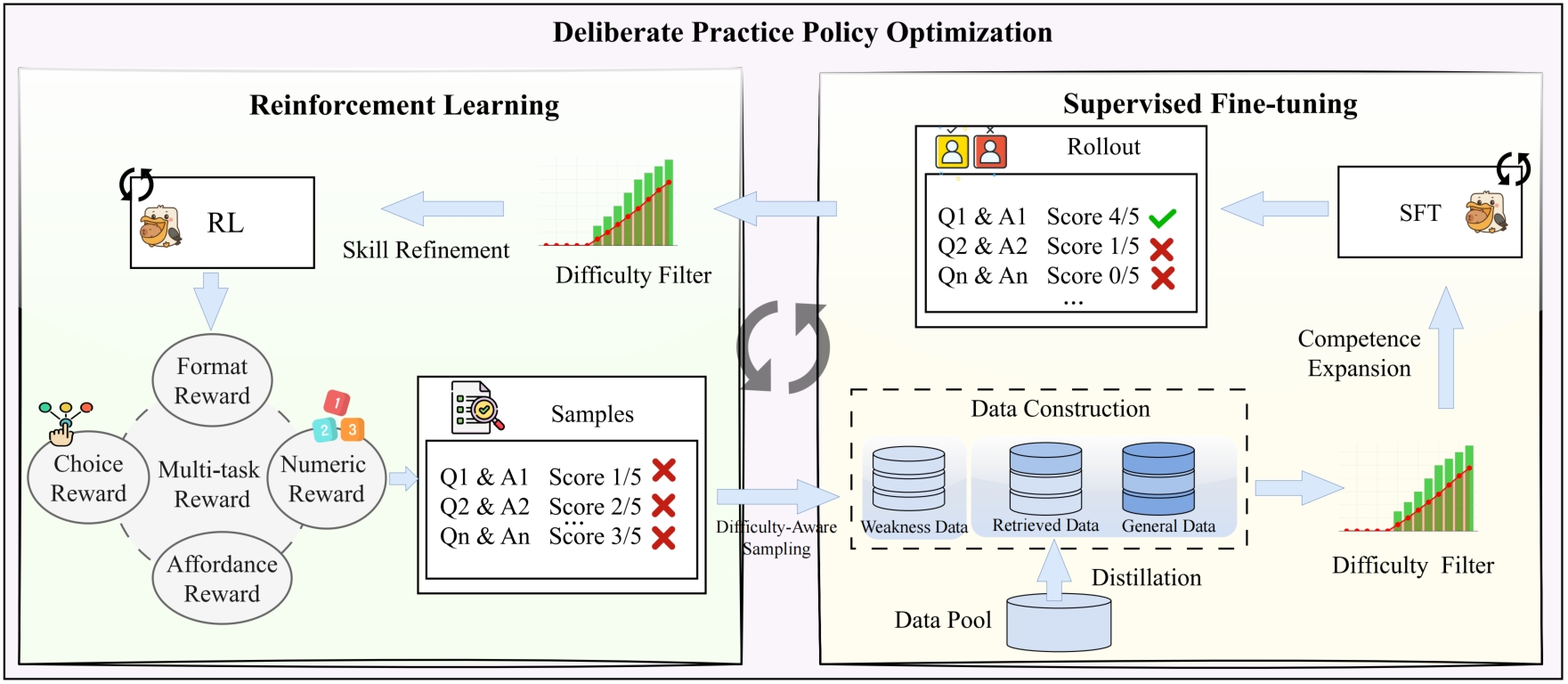
DPPO 通过 metaloop 交替执行两个互补阶段:
Phase selector 决定当前迭代的优化目标:
符号说明: 是 GRPO 中 KL 正则化的参考策略; 是当轮 RL 产出的轨迹集; 是根据当前弱项动态生成的指令数据。
每轮循环:先 RL 探索发现弱项,再 SFT 用弱项数据巩固和扩展能力边界。
Exploratory Grounding
采用 GRPO 强化学习范式,配合多模态多任务奖励函数。策略梯度为:
多任务奖励设计覆盖六个核心目标:affordance reasoning、counting/distance estimation、causal/temporal reasoning、task success、task planning、task prediction。每个 rollout 获得复合奖励 。
Difficulty-Aware Sampling: 对每条轨迹计算难度分数 ,高难度样本优先进入后续 SFT 阶段。
Task Saturation 停止准则: 监控 ,当 时自动终止 RL。
Targeted Remediation
SFT 阶段的训练数据由三部分构成:
- :RL 阶段 difficulty-aware sampling 发现的困难样本
- :根据弱能力维度从数据集中检索的相关 embodied 样本
- :VLM 生成的数据,用于丰富上下文和语言多样性
Unified Preference Learning
理论上,SFT 和 GRPO 被统一为 preference learning 的两个特例。统一目标函数:
- SFT 的 preference sample 是单条专家轨迹 ,
- GRPO 的 preference sample 是轨迹排序列表,用 Plackett-Luce 模型建模排名概率
两者协同:SFT 提供 knowledge enhancement(只看正样本),RL/GRPO 提供 weakness detection and refinement(同时利用正负样本)。
Data Curation
Data for Training
数据池包含 231M 图像 + 29k 小时视频,覆盖 231M 开放式 QA、9M grounding 标注、2M 多选题。从中采样 1.3M 实例用于 SFT、0.5M 用于 RL(共 4B tokens)。数据按四大能力维度组织:
- Physical, Spatial and Numerical Reasoning
- Perception, Grounding and Multi-Object Consistency
- Temporal, Functional and Scene Understanding
- Decision Making and Task Planning
Metaloop Data Selection
Figure 3. Metaloop 数据选择流程

两个关键策略:
从自然世界学习 embodied 知识: 利用 SpatialVID 数据集的原始视频(丢弃已有标注),用 Qwen3VL-Plus 生成 24 个 spatial QA / 视频,InternVL3.5-38B 做二次过滤验证,最终得到 14k QA。再加上 InternSpatial 的 19k QA,共 33k QA 覆盖八类空间推理任务。
弱项数据注入: 每轮 metaloop 后对 RL 数据做 4 轮 rollout 推理 → rule-based 筛选 → VLM 打分 + 投票策略 → 人工抽检,精选弱项样本注入 SFT。
Experiment
Performance Evolution Across Metaloop
Figure 4. DPPO 各阶段性能演进
Figure 5. RL 训练中数据分布变化

实验进行了三轮 metaloop,每轮含 RL + SFT。关键发现:
- 无灾难性遗忘: MVBench 分数在整个训练过程中保持稳定(69.7),因为在 metaloop 中注入了通用数据
- Embodied 能力持续提升: RefSpatialBench(24.7→49.5)、Where2Place(38.1→64.0)、COSMOS(62.5→68.5)等 benchmark 显著改善
- 渐进式时序扩展: 第一轮限制 <32s 视频片段,第二轮放宽到 <64s
Final Result
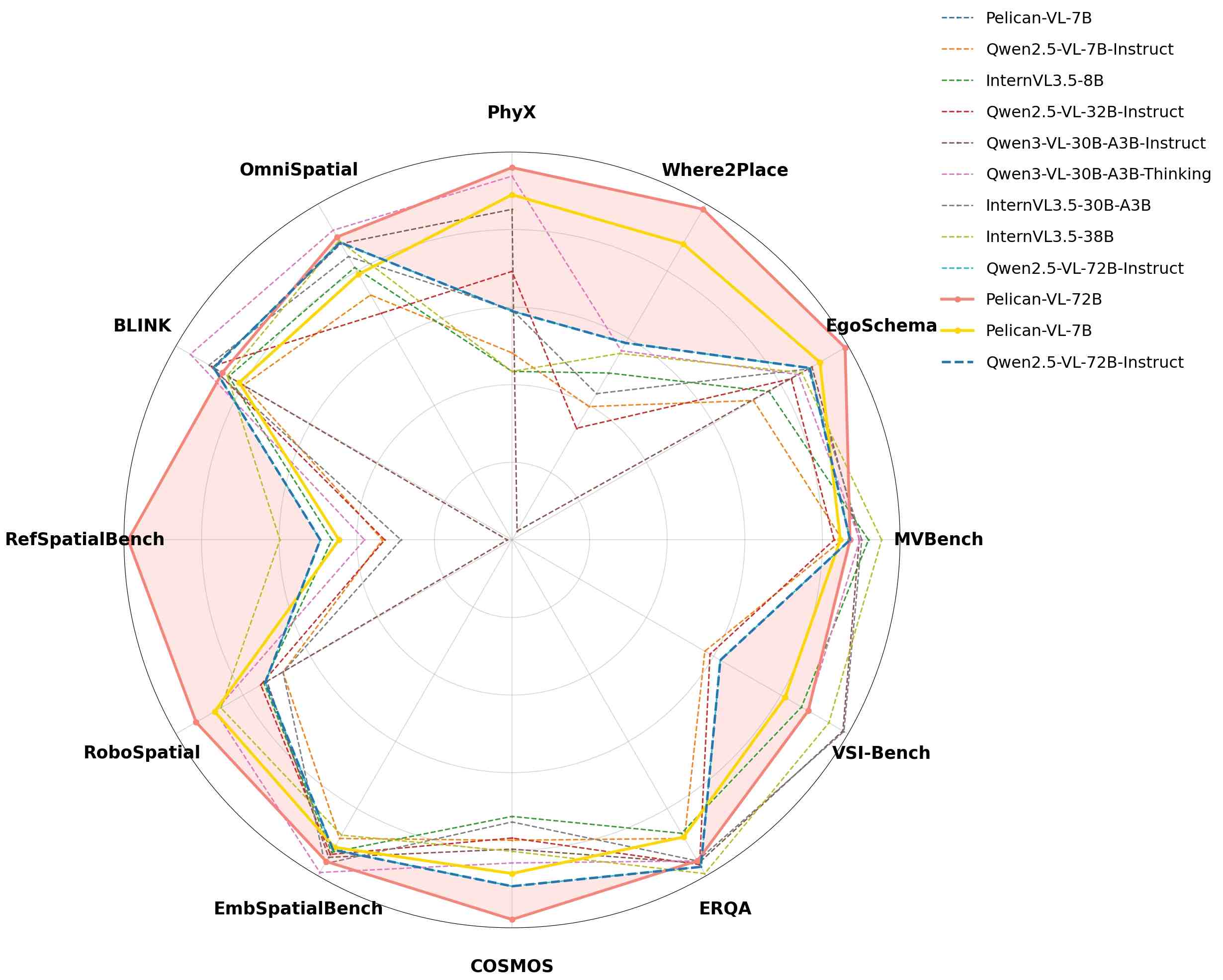
Figure 6. 九维 embodied 能力雷达图
≤100B 模型对比(部分关键数据):
| Benchmark | Qwen2.5-VL-72B | InternVL3.5-38B | Pelican-VL 72B |
|---|---|---|---|
| RoboSpatial | 47.7 | 56.3 | 61.1 |
| PhyX | 53.1 | 39.1 | 86.4 |
| Where2Place | 38.1 | 36.1 | 64.0 |
| EgoSchema | 70.9 | 69.0 | 79.3 |
| RefSpatialBench | 24.7 | 29.9 | 49.5 |
| COSMOS | 62.5 | 56.2 | 68.5 |
| Average | 53.0 | 53.9 | 63.8 |
>100B 模型对比(部分关键数据):
| Benchmark | Qwen3-VL-235B-Thinking | GPT-5 | Gemini2.5-Flash | Pelican-VL 72B |
|---|---|---|---|---|
| PhyX | 85.3 | 83.6 | 77.7 | 86.4 |
| Where2Place | 52.2 | 38.6 | 35.1 | 64.0 |
| EgoSchema | 72.1 | 73.7 | 61.8 | 79.3 |
| RefSpatialBench | 39.4 | 21.6 | 35.4 | 49.5 |
| COSMOS | 62.3 | 64.8 | 30.3 | 68.5 |
| Average | 63.4 | 61.2 | 53.5 | 63.8 |
Pelican-VL 72B 仅用 1M 轨迹和 100K 对象训练,即在 embodied benchmark 上与 GPT-5 持平,显著超越 Gemini2.5-Flash。
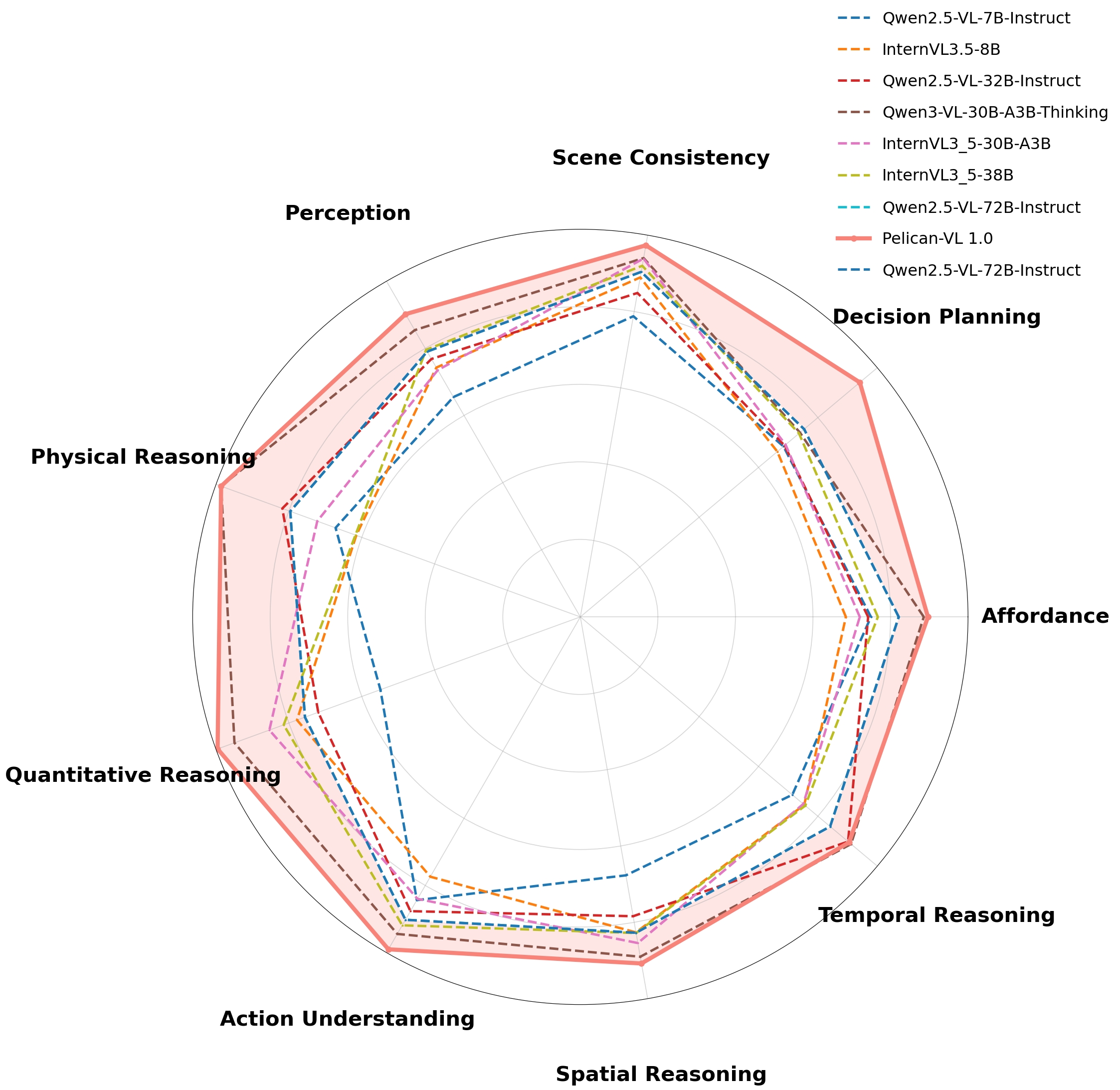
此外,论文提出了九维 embodied intelligence taxonomy(Physical & Causal、Perception & Grounding、Quantitative & Numerical、Spatial & Geometric、Temporal & Sequential、Affordance & Function、Multi-Object & Scene Consistency、Scene & Action Understanding、Decision & Task Planning),对 27,667 样本重标注分析,揭示现有 benchmark 的能力覆盖不均衡问题。
Downstream Applications
Zero-shot Object Manipulation with Affordance
Figure 7. Affordance-based robot action planner

系统采用层级控制架构:Visual Perception(多视角 RGB 提取结构化表示)→ Embodied Planning(VQA 分解操作目标)→ Function Calling(转换为可执行的 tool call)。
Figure 8. 多视角一致性 affordance 到 3D 三角化

核心优势:通过多视角训练保证 affordance 生成的一致性,利用 ≥3 个标定视角的 2D 结果三角化重建 3D 操作目标。系统支持用户指令模式和自主模式(自动生成随机任务用于大规模数据收集)。
Figure 9. 泛化到新物体和新场景

Closing the Sensorimotor Loop
Figure 10. 自适应抓取架构

受 Johansson & Flanagan 人类抓取研究启发,构建 prediction → tactile adaptation → memory update 的闭环。Pelican-VL 1.0 从视觉输入预测初始抓取力先验 ,然后粒子滤波在线估计摩擦系数 ,比例控制器实时调整夹爪位置。成功交互存入 knowledge graph 用于后续 prior 优化。
Figure 11. 精细抓取演示

这是首个 VLM 闭合触觉感知运动环路的工作——从预测抓取力到持续调整,实现对海绵、气球、薯片等柔性/脆弱物体的稳定抓取。
Embodied Function Call
Figure 12. 多机器人协作 function call

系统包含三种机器人形态(轮式人形、双足人形、工业机械臂)和三类控制工具(VLA、WBC、传统运动规划)。通过 MCP(Model Context Protocol)缓存功能工具,Pelican-VL 1.0 在 multi-turn 对话中分解系统级任务为多机器人行为级任务,再进一步分解为参数化 action function calls。
在 Berkeley Function-Calling Leaderboard 上达到 46.0% overall accuracy,超越 DeepSeek-V3 (45.2%) 等大参数模型。
Long-Horizon Task Reasoning and Planning
Figure 13. 真实家居环境长程任务执行

在真实家居环境中,模型接收自然语言指令(“把鞋放到鞋架上,把桌上的垃圾扔进垃圾桶,把沙发上的脏衣服放进洗衣机”),自主完成多阶段感知、空间推理和动态任务排序,跨越多个空间区域执行操作。
关联工作
基于
- Qwen2.5-VL: Pelican-VL 的基座模型
- GRPO (DeepSeek): RL 阶段的优化算法
- Swift: 训练和部署框架
对比
- Gemini Robotics: Google 的 embodied AI,数据规模化策略代表
- π0.5: Physical Intelligence 的 flow-based VLA,数据规模化策略代表
- GR00T N1: NVIDIA 的 humanoid 控制模型
- InternVL3.5: Benchmark 对比的主要 baseline
方法相关
- MCP (Model Context Protocol): 多机器人协作中用于工具注册和功能缓存
- Deliberate Practice (Ericsson): DPPO 的认知科学灵感来源
论文点评
Strengths
- 系统性的训练框架: DPPO 将 RL 和 SFT 统一于 preference learning 理论框架,交替迭代的 metaloop 设计比单阶段训练更适合 embodied 场景的复杂性。Task Saturation 停止准则和 Difficulty-Aware Sampling 使得训练过程可控且高效
- 全面的下游验证: 不止于 benchmark 刷分,在触觉操作、affordance 推理、多机器人协作、长程规划四个轴上都做了真实硬件验证,特别是首次用 VLM 闭合感知运动环路的触觉操作
- 九维 embodied 能力 taxonomy: 对现有 benchmark 的分析揭示了能力覆盖不均衡问题,提出了比 task-level Pass/Fail 更有诊断价值的评估维度
- 开源力度: 开放 7B/72B checkpoint + LoRA 微调代码 + 评估复现指南,基于 Swift 框架降低了使用门槛
Weaknesses
- 基座依赖不透明: 基于 Qwen2.5-VL 微调,但 20.3% 的提升中有多少来自 DPPO 框架本身、多少来自数据规模和质量,缺乏 clean ablation。与 Qwen2.5-VL + 等量数据 SFT-only baseline 的对比缺失
- 数据细节不足: 4B tokens 数据的具体构成、各能力维度的数据比例、metaloop 每轮注入多少弱项数据等关键信息缺乏定量描述
- 训练成本极高: 50k+ A800 GPU-hours / checkpoint,三轮 metaloop 意味着总训练成本巨大,对大多数研究团队不可复现
- 下游任务评估缺乏量化: 触觉操作、affordance 操作、长程规划等下游实验主要展示定性结果,缺少系统性的成功率统计和与 baseline 的定量对比
- 理论统一较为表面: 将 SFT 和 GRPO 统一为 preference learning 的推导虽然正确但不深入,更像是事后解释而非指导设计的理论
可信评估
Artifact 可获取性
- 代码: inference + LoRA fine-tuning(基于 Swift 框架)
- 模型权重: Pelican1.0-VL-7B、Pelican1.0-VL-72B(HuggingFace + ModelScope),后续新增 3B 版本
- 训练细节: 仅高层描述(metaloop 三轮、每轮 RL+SFT、50k GPU-hours/checkpoint),超参和数据配比未完整披露
- 数据集: 训练数据私有;LoRA demo 使用公开数据集(Cosmos Reasoning SFT、RoboPoint GQA、VSI-Bench ScanNetpp)
Claim 可验证性
- ✅ Benchmark SOTA: 提供了详细的 benchmark 数字和统一评估协议,可复现
- ✅ 开源模型可下载: HuggingFace/ModelScope 上可获取
- ⚠️ 20.3% uplift from base model: 基座模型 Qwen2.5-VL-72B 公开可查,但 DPPO vs SFT-only 的增量贡献不明确
- ⚠️ “首个 VLM 闭合感知运动环路”: 触觉操作实验展示了定性视频,但缺少与其他方法的定量对比和统计显著性
- ⚠️ “on par with leading proprietary systems”: 在 embodied benchmark 上确实接近 GPT-5,但在通用 benchmark(MVBench 69.7 vs 73.1)上仍有差距
- ❌ “currently the largest-scale open-source embodied multimodal brain model”: 模糊的 marketing claim,“largest-scale” 的标准未定义
Notes
Rating
Metrics (as of 2026-04-24): citation=2, influential=0 (0.0%), velocity=0.34/mo; HF upvotes=0; github 78⭐ / forks=3 / 90d commits=0 / pushed 143d ago
分数:2 - Frontier 理由:方法层面 DPPO metaloop 虽有 systematicness(Strengths #1),但理论统一偏事后解释(Weaknesses #5),clean ablation 缺失(Weaknesses #1)使其难以被后续工作作为必引奠基;作为 artifact,开源 72B embodied VLM + 全栈 downstream 验证(Strengths #2、#4)使其成为当前 embodied VLM 方向的重要参考 baseline,符合 Frontier 定义。论文发布时间较近(2025-11),尚未沉淀出”de facto”级别的社区采纳证据,因此不到 Foundation 档。2026-04 复核:5.8mo 发布、cite=2/inf=0/vel=0.34/mo、HF=0、gh=78⭐/90d 无 commit(pushed 143d ago)——rubric 特例 early signal 三条均偏弱,且与同期 MiMo-Embodied (vel=2.16) / Vlaser (vel=1.59) 相比明显落后;暂保留 2 给予 DPPO metaloop 与 72B 开源 checkpoint 的方法/artifact 价值一次观察机会,若 2026Q3 仍无 inf>0 或明显 star/HF 增长则降 1。