Summary
DART-GUI:把 GUI Agent RL 拆成四个异步模块 + 多粒度数据 curation
- 核心:OSWorld 这种长 horizon、稀疏奖励、任务难度极度不均衡的 GUI 环境里,RL wallclock 性能的 bottleneck 是 system + data,而不是算法本身。DART 同时解这两条轴:四模块异步框架把 GPU/env 利用率推上去,四级 data curation 把有限算力压在真正产生信号的决策点上。
- 方法:Env Cluster / Rollout Service / Data Manager / Trainer 完全解耦 + rollout-wise sampling + per-worker model sync;四级 curation:dynamic rollout N(task)、dynamic trajectory length(trajectory)、top-80% entropy step selection(step)、truncated importance sampling(token)。
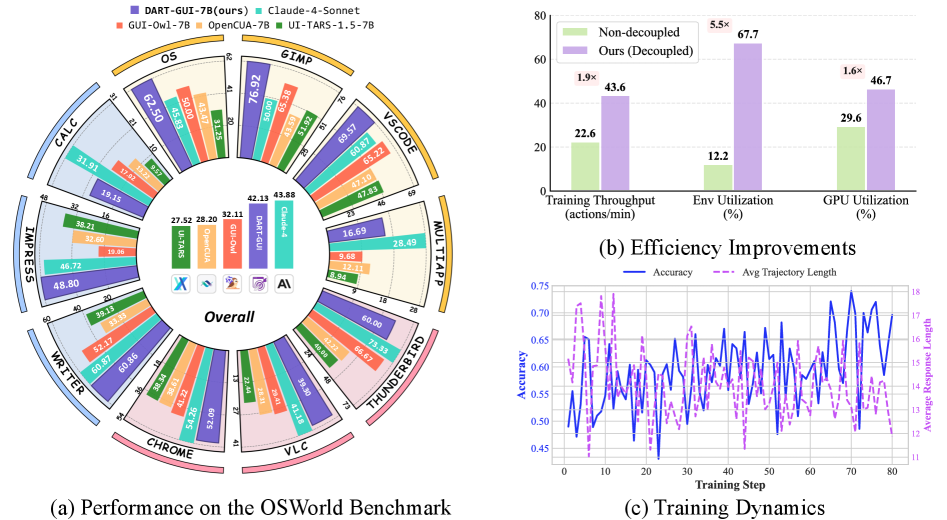
- 结果:DART-GUI-7B 在 OSWorld-Verified 上以 max 30 steps 达到 42.13% SR(base UI-TARS-1.5-7B 100 steps 下 27.52%,+14.61 abs;open-source SOTA +7.34 abs),几乎与 Claude-4-Sonnet(100 steps, 41.39%)持平。效率:rollout GPU util 1.6×,env util 5.5×,training throughput 1.9×。
- Sources:paper | website | github
- Rating:2 – Frontier。GUI agent RL 场景下少有的全流程开源 baseline(代码 + checkpoint + SQL schema + Docker 都 release),OSWorld 绝对数值与 sample efficiency 提升都显著;但方法是工程巧思 + 已知 curation tricks 的组合,single-component algorithmic novelty 有限。
Key Takeaways:
- GUI RL 的真正瓶颈是 pipeline coupling,不是算法:OSWorld 单 episode 几十分钟,coupled pipeline 中 “等 batch 内最长 trajectory 结束” 的阻塞把 GPU/env 利用率拖到 30%/12% 量级。rollout-wise scheduling + per-worker 滚动同步这两条系统层面的改动直接把这两个数拉到 47%/68%,对应 1.9× training throughput——这不是算法红利,是阻塞消除后的底线。
- Sparse-reward 长 horizon 场景下,data curation 的信号放大远强于 GRPO 本身:45-task ablation 里 Pass@1 从 28.67% → 72.28%,其中 DR(dynamic rollout)贡献最大(+22.23),DTL(dynamic trajectory length)再+15.21,HE(high-entropy step selection)再+2.22,DA(distribution alignment)再+2.22——决定胜负的是”让哪些 step 进 loss”,不是 loss 长什么样。
- Experience Pool 是对 GRPO 组内方差的工程修补:pass@32=0 的 22 个 task 靠预采successful trajectory 兜底,让每个 batch 至少有一个正样本,SR 从 0% 爬到 46%。这是典型的 off-policy 注入,说明 GRPO 在 pure online 设定下在极难 task 上的 credit 信号完全失效。
- Truncated importance sampling 是任何 decoupled RLVR 框架的必需项:rollout engine(vLLM + 量化)和 trainer(FSDP + BF16)天然 off-policy,加上 experience pool 带来的再一层 distribution shift,用
min(π_train_old / π_rollout_old, C)做 clip 就能稳住训练(ablation 里显示无 DA 时 step 60 后 collapse 到 ~0%)——这个 trick 在 AREAL / ROLL / 所有 async RL 框架里都通用。 - DART-GUI-7B 以 30 步接近 100 步 Claude-4-Sonnet,sample efficiency 比绝对 SR 更值得注意:说明当前 closed-source 在 GUI 任务上的优势可能更多来自 trajectory length budget,而不是模型能力本身。
Teaser. DART 框架整体 overview——四模块异步协作与关键 implementation techniques 注解
1. 问题与动机
GUI agent(VLM-based,e.g. UI-TARS、OS-Atlas、Aguvis)在 OSWorld 上需要长 horizon 多轮交互才能完成桌面任务(打开应用、编辑文件、切换窗口)。把 RL 用到这个场景面临两个结构性 bottleneck:
- Pipeline coupling:现有 RL 实现里 action prediction → env step → data buffer → trainer 是顺序阻塞的。GUI 任务单步要等浏览器 / OS 响应(秒级),整条 trajectory 几十分钟,coupled pipeline 让 GPU 大量空转。
- Task difficulty heterogeneity + sparse reward:同 batch 内任务难度差异大;简单任务容易过拟合,难任务大概率全 rollout 都 0 reward → 没有 learning signal。已有工作(GUI-R1、InfiGUI-R1、ARPO、ZeroGUI)在 OSWorld 上 RL 提升只有 2–4%,整体仍远落后 closed-source。
作者把 problem framing 切成 “system efficiency” 和 “data curation” 两条互相正交的轴,这是这篇 paper 的核心 framing 选择。切法本身合理——RL 的 wallclock 性能确实由 system + algorithm 共同决定——但也使 contribution 变成 “系统工程 + 一组已知 curation tricks 的组合”,没有单一的算法 insight 作为 anchor。
2. DART 框架
2.1 Formulation
GUI 任务建模为 sequential decision-making。在 step :state 是 screenshot,history 包含过去 步的 ( 是 thought, 是 action)。policy 在 上生成新的 thought 和 action 。执行后环境给出新 screenshot ,直到 termination 或达到最大步数。
2.2 架构:四个解耦模块
Figure 2. DART 的整体架构——Rollout Service 并行对接多环境生成 trajectory,Data Manager 过滤后送 Trainer 更新,policy 滚动回流到 Rollout Service
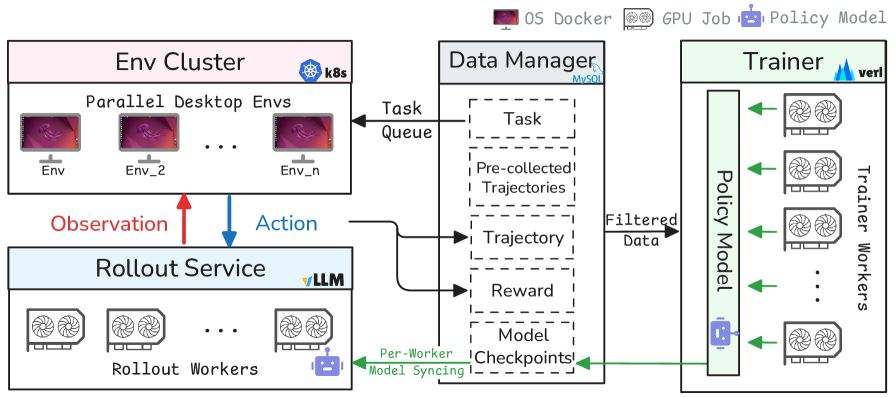
| 模块 | 职责 |
|---|---|
| Env Cluster | Kubernetes 编排 180 个并行 Ubuntu Docker 容器,每个容器跑一个独立 OSWorld env,接收 action、返回 screenshot |
| Rollout Service | vLLM 部署的多实例 policy 推理(worker = 2 × H100),负载均衡,per-worker 滚动同步新权重 |
| Data Manager | 基于 MySQL 的中心化数据协调层(11 张表:checkpoint/current_model/model_registry/datasets/dataset_usage_events/rollout_run/rollout_chunk/trainable_group/update_model_task/inference_node/inference_tasks),落盘 trajectory、管理 experience pool、按规则分发训练数据 |
| Trainer | 8 × H100 + FSDP(via verl),step-wise GRPO 更新,收到一组 条 trajectory 就训 |
四个模块两两之间完全非阻塞:Env Cluster 持续送 trajectory 给 Data Manager,Rollout Service 按需从 Env Cluster 接 action 请求,Trainer 只要 Data Manager 里攒够一组 trajectory 就开训——没有全局 barrier。
2.3 Asynchronous Trainer(Step-wise GRPO)
Trainer 异步收 trajectory,做 step-wise GRPO:对每个 task 采 条 trajectory ,trajectory 的长度 、reward 。把所有 trajectory 拆成 step-level 样本,按 task 做 group 计算 advantage:
GRPO 目标(省略 KL 项简写):
其中 是 training engine 内的 IS 比。关键参数:、(follow DAPO 的 dynamic clip)、、lr=1e-6、采 、max 30 steps per episode、采样 temperature 1.0。
2.4 Rollout-wise Sampling:trajectory 是最小调度粒度
Figure 3. 三种 sampling 策略的时间线对比(4 task × 2 batch × 8 env)

- batch-wise (a):等 batch 内最长 trajectory 结束才开始下一 batch → 大量 env/GPU 空转。
- task-wise (b):task 内提前完成的 rollout 等同 task 其他 rollout → 部分改善。
- rollout-wise (c, 本文):单个 trajectory 完成就立即起下一个——无等待、无 barrier。
叠加 dynamic load balancing:不把 env 绑死到固定 worker,而是把所有 GPU pool 起来,按实时利用率路由 inference 请求。好处是统一接口 + GPU 负载均衡——直接拿到 1.6× rollout GPU utilization。
2.5 Per-Worker Model Synchronization:滚动权重刷新
Figure 4. Global sync(a)vs Per-worker sync(b)的时间线对比(4 GPU × 80 env,两次模型更新)

传统异步 RL 的 model sync 有一次全局 barrier:trainer 训完一步后所有 rollout worker 停服、接收新权重、再恢复。DART 改为错峰更新——一次只更新一个 worker 的权重,其他 worker 继续用旧版模型提供 inference。副作用是 rollout 里会混入不同模型版本生成的 trajectory,但这个 staleness 由后面 §3.4 的 truncated importance sampling 兜底。
3. 多粒度数据 Curation
3.1 Task 级:Performance-Aware Task Rollout
Figure 5. Dynamic rollout 随 task success rate 变化的示意——高成功率 task rollout 数降到低值,低成功率 task 保持 max

- Dynamic Rollout Frequency:持续监控每个 task 的 success rate。SR > 0.6 时把 rollout 数从 8 降下来(防过拟合简单 task),SR 低则保持 max=8(给难 task 更多探索)。
- Dynamic Trajectory Length:为每个 task 维护一个历史成功轨迹的 max length,作为该 task 的 trajectory length cap——避免在无望的长 trajectory 上烧算力,也不用全局 fix 一个保守的 cap。简单 click 类可能 10 步终止,复杂 multi-app 可能 50 步。
3.2 Trajectory 级:Experience Pool
极难 task(pass@32 = 0)的 rollout 全失败 → GRPO 的 group advantage 退化成 0。作者预先采集 high-quality successful trajectory 存进 experience pool,训练时一旦检测到某 task 当前 batch 全失败,就从 pool 里随机抽一条注入 batch。保证每个 task 至少有一条正样本,把 sparse-reward 情形的 gradient 从 0 拉回来。
❓ Experience pool 的 successful trajectory 是怎么预采的?如果是用更强的 teacher agent 跑出来的(比如 Claude),那这部分实际上是把 closed-source 的能力 distill 进来;如果是用 UI-TARS-1.5-7B 自己大量采样中偶然成功的,那属于 GRPO 内部的 replay buffer。论文没有明确说明,但这里的区别对”方法 novelty”判断影响很大。
3.3 Step 级:High-Entropy Step Selection
Inspired by Wang et al. (2025b) “high-entropy tokens as critical forks”——只在 step-level entropy 的 top 80% 上算 GRPO loss。step entropy 定义为该 step 所有 thought+action token entropy 的平均:
把 high-entropy token selection 直接抬到 step-level 是自然 extension,但 step entropy 是对 token entropy 的平均——等价于把 “整句都不确定” 的 step 选出来。对于 GUI action(click 坐标、hotkey),坐标 token 天然有高不确定性,这种 selection 实际更接近 “是否含 grounding 决策”,和 “critical decision” 的原始语义有区别。
3.4 Token 级:Truncated Importance Sampling(Distribution Alignment)
Rollout engine(量化推理,vLLM)和 Trainer(FSDP + BF16)的 action distribution 天然有差距,experience pool 注入的 trajectory 进一步加剧 distribution shift。follow Yao et al. (2025) 加一个 truncated IS 权重 ,。最终 HE + DA 合并目标:
其中 是 “step entropy ≥ group 20% 分位数” 的 indicator——即只算 top 80% entropy step 的 loss。
4. 实验
4.1 Setting
- 环境:OSWorld-Verified(Xie et al. 2024),10 个应用(chrome/gimp/calc/impress/writer/multi_apps/os/thunderbird/vlc/vs_code)共约 360+ task,execution-based validation script 给 [0,1] reward。
- 训练集:follow Lu et al. 2025(ARPO)的采样方案,从 OSWorld 取 203 tasks。
- policy:UI-TARS-1.5-7B 作 base,不引入 multi-agent / 外部 API / 工作流脚手架。
- 硬件:8 × H100 做 trainer,多组 2 × H100 作 rollout worker,180 个 Ubuntu container 作 env。
4.2 主结果
DART-GUI-7B 在max 30 步的限制下取得 42.13% OSWorld SR:
- vs baseline UI-TARS-1.5-7B (100 steps): 27.52% → +14.61 abs
- vs open-source SOTA: OpenCUA-32B (100 steps, 34.79%) / GUI-Owl-7B (15 steps, 32.11%) → +7.34 vs OpenCUA-32B(模型还是 ~1/5 参数量)
- vs closed-source: 接近 Claude-4-Sonnet (100 steps, 41.39%)、UI-TARS-250705 (100 steps, 41.84%),超过 OpenAI CUA o3 (100 steps, 23.00%)
分应用看,显著提升集中在 OS (+31.25)、LibreOffice Writer (+21.73)、Thunderbird (+20.00)、GIMP (+25.00)——全是长 horizon、多窗口、状态依赖强的任务,正是 curated RL 应该 shine 的地方。提升最小的是 multi_apps (+7.75),跨应用切换依然是开放问题。
这里 DART-GUI-7B 用 30 max steps 去比 baseline 的 100 max steps 不完全公平。理论上 30 步比 100 步更难(更严格的 budget),但也意味着 DART-GUI 可能在 “必须一次打对” 的 decision-making 上收紧了,而非真的 “学到了更强的 long-horizon 规划”。更 fair 的对比需要把 baseline 也限 30 步、或把 DART-GUI 放开到 100 步看上限。
4.3 Efficiency Analysis
| System Setup | Training Throughput (actions/min) | Env Util. (%) | GPU Util. (%) |
|---|---|---|---|
| Non-Decoupled | 22.6 | 12.2 | 29.6 |
| Decoupled (Ours) | 43.6 | 67.7 | 46.7 |
| Improvement | 1.9× | 5.5× | 1.6× |
Env Util 的 5.5× 是三项提升里最 impressive 的——从 12% 到 68%。这侧面说明现有 “coupled” baseline 有多浪费:大部分时间 180 个 Ubuntu 容器都在等 batch 内的 stragglers。
但论文没有说明 “Non-Decoupled baseline” 具体是哪个实现(自己的 naive 版本?还是某个开源 baseline 如 verl 的 stock 配置?),这使得 1.6×/1.9×/5.5× 的 grounding 偏弱——“baseline” 可以被设计得非常弱。
4.4 Ablation
Figure 6. Ablation——(a) dynamic rollout frequency vs model accuracy;(b) dynamic trajectory length vs model accuracy;(c) experience pool on 22 难 task;(d) distribution alignment 的训练稳定性对比

45-task subset 上的分层 ablation(Pass@1 %):
| Baseline | w/ DR | w/ DTL | w/ HE | w/ DA | Ours (全套) |
|---|---|---|---|---|---|
| 28.67 | 50.90 | 66.11 | 68.33 | 70.55 | 72.28 |
- Dynamic Rollout:rollout 频率随训练从 8.0 降到 5.0,避免重复采样已学会的 task → +22.23 abs(最大贡献项)。
- Dynamic Trajectory Length:平均 trajectory length 从 30 降到 < 10 → +15.21 abs。
- Experience Pool(22 个 pass@32=0 的极难 task):初始 0% → 训练后 46%,pure online GRPO 做不到。
- High-Entropy Step Selection:+2.22 abs,相对小——但对训练稳定性的贡献大于绝对数值。
- Distribution Alignment:无 DA 时 step 60 后 SR 从 55% collapse 到接近 0%,加上 DA 后稳在 70%,峰值 78%——不加 DA 的 async RL 会发散。
Ablation 设计的主要短板:每一行是累加(w/ DR = baseline+DR,w/ DTL = baseline+DR+DTL…)还是独立(w/ DTL = baseline+DTL only)?从数值看像累加,但论文没明说。这直接影响能否判断 DR vs DTL vs HE 的相对贡献。此外 45 task subset 很小,不排除 ablation 结论和全 203 task 训练结果有偏差。
4.5 Failure Cases & Limitations(Appendix A.6)
论文自己列的 failure:
- (a) Chrome 里 enable “Do Not Track”:模型错点 “Site settings” 而非 “Third-party cookies”——语义理解失误,和 RL 无关。
- (b) VS Code 里同时打开两个 workspace:模型试图 Ctrl+click 组合键,但 action space 里 hotkey 和 click 是分离的,导致 Ctrl 松开后再 click 变成单选——action space 设计 bug,DART 的 framework 无法解决。
关联工作
基于 / 前置
- UI-TARS-1.5-7B(Qin et al. 2025):policy 初始化,DART-GUI 直接继承 UI-TARS 的 action space(click/drag/hotkey/type/scroll/wait/finished)和 system prompt。
- OSWorld(Xie et al. 2024):训练和评测环境,203 task 训练子集 follow ARPO 的 sampling methodology。
- GRPO(DeepSeek-Math / R1):step-wise GRPO 是 DART trainer 的核心优化算法。
- DAPO(Yu et al. 2025):dynamic clip boundaries 、 直接 follow。
- High-entropy token selection(Wang et al. 2025b):step-level HE selection 是对这篇 token-level 工作的 multi-turn 推广。
- Truncated IS(Yao et al. 2025):distribution alignment 直接 port。
- verl(Sheng et al. 2024):trainer side 的 FSDP 分布式训练骨架。
对比(OSWorld 上的其他 RL 工作)
- GUI-R1(Luo et al. 2025)、InfiGUI-R1(Liu et al. 2025):offline RL,struggle with distribution shift + multi-turn reasoning。
- ARPO(Lu et al. 2025):GRPO 的 multi-turn 扩展,15 步限制下 29.9%——DART 的 203 task 训练子集就是 follow ARPO。
- ZeroGUI(Yang et al. 2025):VLM 自动生成 task + reward,15 步 20.2%。
- ComputerRL(Lai et al. 2025):同为 async 架构但针对 API-equipped agent;DART 聚焦纯 screenshot agent。
- OpenCUA-32B(Wang et al. 2025e):当前开源 SOTA (34.79%),SFT-only,没 RL。DART 在 ~1/5 参数量下超过它 7.34 abs。
- GUI-Owl-7B(Ye et al. 2025):15 步 32.11%,同为 7B 规模 online RL;DART 的 +10 abs 说明 curation 的价值。
方法相关(其他 async LLM RL 框架)
- AREAL(Fu et al. 2025b):separate rollout from training with staleness-aware PPO。DART 的 per-worker sync + truncated IS 思路与此同构,但 target 是多模态长 horizon。
- ROLL(Wang et al. 2025c):通用 RL library。对比下 DART 是垂直到 GUI domain 的全栈 system(含 180 Ubuntu container orchestration + MySQL data manager),而非通用库。
- UI-TARS-2:同期的 GUI agent 更新,可作为后续对比 baseline。
论文点评
Strengths
- 完整的 reproducibility 承诺且真的兑现:从 github README 看(2025-12-10 完成),已 release training code / sampling code / SQL schema / Docker image / checkpoint,这在当前 GUI agent RL 领域非常稀缺——多数工作只给 inference code。
- OSWorld 上的绝对数值与 sample efficiency 提升显著:42.13% @ 30 steps ≈ Claude-4-Sonnet @ 100 steps,这个 sample efficiency 的 message 比绝对 SR 更 valuable。
- System 工程 + data curation 两条正交轴的切分 clean:rollout-wise sampling、per-worker sync、dynamic rollout/length、experience pool、HE selection、truncated IS——每一项都是独立可插拔的工程模块,可以被后续工作单独 borrow。
- Ablation 分量清晰:45 task subset 上从 28.67% → 72.28% 的四层 ablation 让 “哪部分 contribute 多少” 比较清楚(尽管有 accumulative vs independent 的歧义)。
Weaknesses
- 30 vs 100 max step 对比不对等:DART-GUI-7B 限 30 步,所有 open-source baseline 都是 50/100 步,这让 “7.34 abs improvement” 的 framing 有点 marketing 嫌疑。需要补 100 max-step 版本的 DART-GUI-7B 结果和 30 max-step 版本的 baseline。
- 单一算法 novelty 薄弱:每个 curation trick(DR/DTL/HE/IS)单独看都是已知 technique;experience pool 在强化学习里叫 prioritized replay / offline-to-online warmstart 也不是新概念。论文 value 主要在集成度与工程落地,不在 algorithmic insight。
- Ablation setting 不透明:(a) “w/ X” 是累加还是独立?(b) 45 task subset 是从 203 task 里怎么挑的?(c) efficiency baseline “Non-Decoupled” 具体是哪个实现?
- Experience Pool 的成功 trajectory 来源未交代:若是用更强 teacher agent 采的,那一部分性能实际是 distill;若是 UI-TARS-1.5-7B 自己反复采出来的,那数据 collection 成本应该单独汇报。
- Cross-application generalization 没评估:训练集和测试集都来自 OSWorld 的 203 task(同 benchmark),没有跨 benchmark(如 WebArena、AndroidWorld)的 out-of-distribution 测试——不能判断是否在 OSWorld exploit 了某种 bias。
- 28.67% 的 baseline 和 Table 1 里 UI-TARS-1.5-7B 27.52% 不一致:Table 3 里 “Baseline” 28.67% 应该是 45-task subset 上的 baseline Pass@1,但没明说——读者容易误以为 main table 的 baseline 和 ablation baseline 是一个数。
可信评估
Artifact 可获取性
- 代码:inference + training 均开源(github.com/computer-use-agents/dart-gui),README 显示 2025-12-10 完整 release 了 training / sampling code + SQL schema + Docker。
- 模型权重:DART-GUI-7B checkpoint 已发布(huggingface.co/dart-gui/dart-gui-7b)。
- 训练细节:完整——lr=1e-6、β=0.1、ε_low=0.2、ε_high=0.28、C=1、n_rollout=8、max 30 steps、temperature=1.0、8×H100 trainer + 2×H100/worker rollout + 180 Ubuntu container env 都在 Appendix A.4 写明。
- 数据集:203 task 训练子集 follow 公开的 ARPO sampling(OSWorld 子集),公开;experience pool 的具体 successful trajectory 组成未披露。
Claim 可验证性
- ✅ 42.13% OSWorld SR / 14.61 abs gain vs baseline / 7.34 abs vs open-source SOTA:Table 1 有完整 10 app × 多 model 对比,且明确 “我们在自部署设备上用官方 codebase + Docker 评测”;再加上 open checkpoint,可独立 reproduce。
- ✅ 1.6× / 1.9× / 5.5× 效率提升:给出具体数值(22.6 → 43.6 actions/min 等),虽然 “Non-Decoupled” baseline 含义略含糊,但数值本身可验证。
- ✅ 45 task subset ablation:Pass@1 28.67 → 72.28,ablation 表有具体数。
- ⚠️ “可超过 Claude-4-Sonnet”:论文说 “comparable”,但严格看 42.13 vs 41.39(100 steps)/ 43.88(50 steps)在统计误差内;且 DART 的 30 vs Claude 的 100 步 budget 不对等——不是纯粹的能力对比。
- ⚠️ “open-source SOTA”:成立但有期限。UI-TARS-250705 在 Table 1 就已经 41.84%(100 steps),UI-TARS-2 是同期工作;DART 的 “SOTA” 依赖精确的时间窗口和 7B 量级限定。
- ⚠️ “critical decision points” 的解释:HE selection 只贡献 +2.22 abs,把它包装成 “focus on critical decisions” 有点过度 marketing;实际 ablation 显示 DR+DTL 才是主力(+37.44 abs)。
- ❌ 无明显营销话术——论文整体 claim 克制,没有 “first to…” 或 “approaches human performance” 类修辞。
Notes
- 本 paper 的 contribution shape 更像一个 “engineering white paper” + “ablation-heavy RL recipe”,而不是算法论文。对研究价值的正确 framing:它是后续 GUI agent RL 工作应该 compare / borrow code 的 baseline,而非应该 cite 为 “首次提出 X” 的 foundational 工作。
- 对我 agent RL 研究的可迁移点:(a) rollout-wise sampling + per-worker sync 是 long-horizon agent RL 的通用 recipe,值得迁移到 VLA / Embodied RL;(b) experience pool 兜底对所有 sparse-reward 任务都通用;(c) truncated IS 在任何 inference/training 引擎分离的设定下都必要。
- 打开的问题:(1) 如果把 max step 拉回 100 并继续训,SR 能否推到 50%+?(2) 实验 pool 的成功 trajectory 来自哪个 source?(3) 这套 curation 在 AndroidWorld / WebArena 上能否迁移?
- 相关 vault 笔记:ComputerRL(同期 async GUI RL)、UI-TARS(base policy)、OSWorld(benchmark)、OpenCUA(open-source SFT baseline)。
Rating
Metrics (as of 2026-04-24): citation=5, influential=0 (0.0%), velocity=0.74/mo; HF upvotes=14; github 87⭐ / forks=6 / 90d commits=1 / pushed 57d ago
分数:2 - Frontier
理由:从 “是不是方向必读” 的角度,这篇是当前 (2026-04) 做 GUI agent RL 的人绕不过去的参考——不是因为它有奠基性 insight,而是因为它是OSWorld 上唯一一个把 system + data curation + open-source artifact 都做扎实的工作,且数值(42.13% @ 30 steps)进入了 closed-source 竞争区间。但 algorithmic novelty 和 cross-benchmark 验证都不足以把它抬到 Foundation——每个 component 都可以在 prior work 里找到,且没有 cross-domain generalization 的证据。等 UI-TARS-2 或下一代 GUI agent RL 工作出来,它会快速降到 1 的候选。属于典型的 “重要 baseline,有效期 6-12 个月”。2026-04 复核:cite=5/inf=0/vel=0.74/mo、HF=14、87⭐/90d 仅 1 commit,social signal 偏弱;发布 6.8mo 已不在 <3mo 保护期,但早期 influential=0 让 Frontier 档略偏乐观——保留 2 是因为 GUI agent RL 方向 OSWorld 全流程 open-source baseline 仍稀缺,社区采纳还在爬坡阶段;若 6 个月内仍无 inf>0,需考虑降 1。