Summary
ACE-Brain-0: Spatial Intelligence as a Shared Scaffold for Universal Embodiments
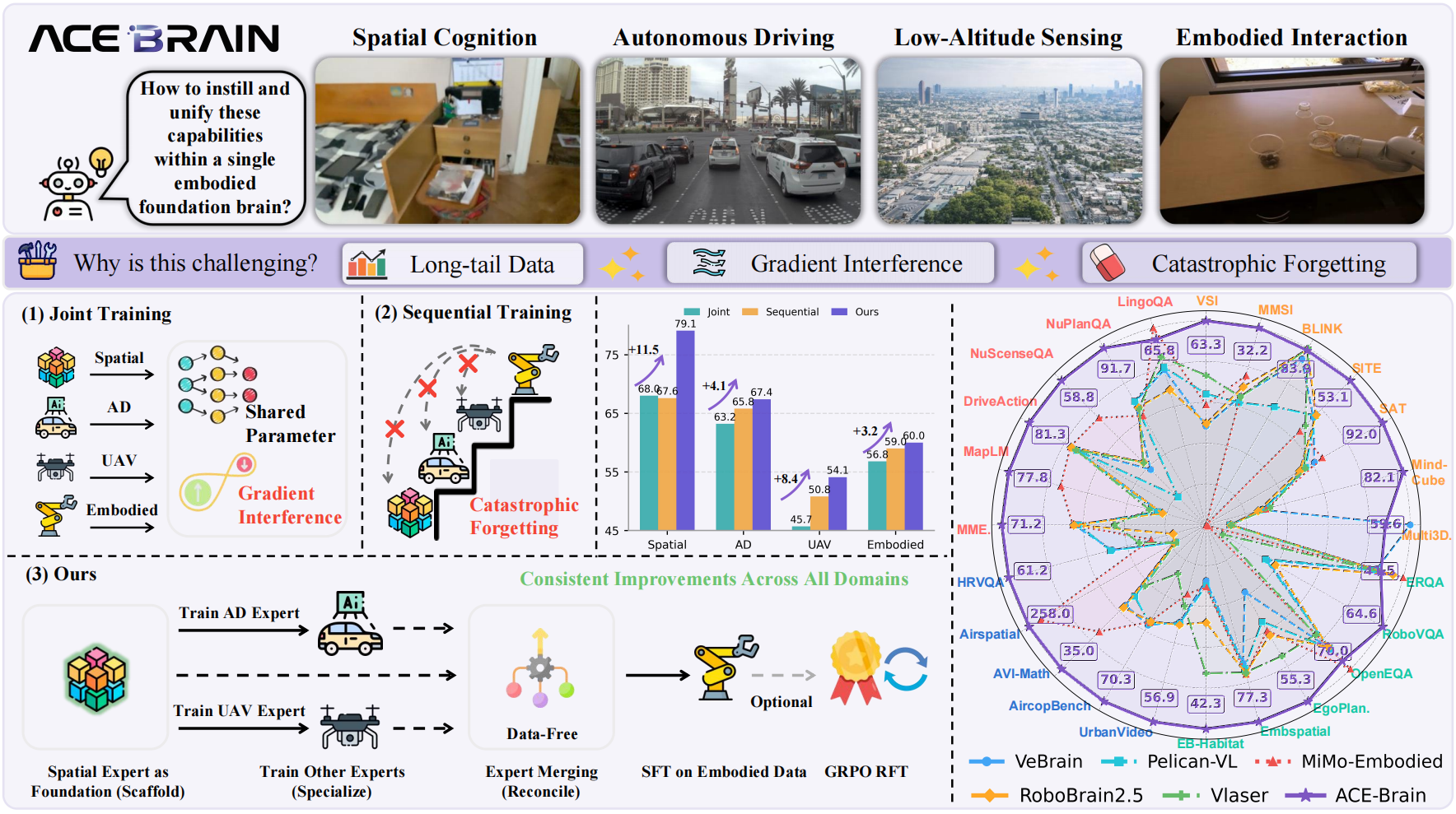
- 核心: 以 spatial intelligence 为共享 scaffold,通过 Scaffold-Specialize-Reconcile (SSR) 范式训练统一跨 embodiment 的 generalist brain
- 方法: 先训 Spatial Expert 作为 scaffold,再分支训练 AD/UAV domain expert,data-free model merging 合并,最后 Embodied SFT + GRPO
- 结果: 8B 模型在 24 个 benchmark(Spatial / AD / UAV / Embodied)上取得 competitive 或 SOTA 性能
- Sources: paper | website | github
- Rating: 2 - Frontier(最新的 cross-embodiment MLLM 代表作,SSR 范式与 24-benchmark 综合评测是 frontier 级别,但尚未被社区广泛采用为 de facto baseline)
Key Takeaways:
- Spatial intelligence as universal scaffold: 不同 embodiment(车辆、机器人、UAV)虽然 morphology 不同,但都依赖 3D spatial understanding,spatial cognition 是天然的 domain-agnostic foundation
- Scaffold-Specialize-Reconcile (SSR) paradigm: 先建 spatial scaffold,再分支训 domain expert(避免 gradient interference),最后通过 data-free model merging 合并(避免 catastrophic forgetting)——比 joint training 和 sequential training 都好
- GRPO for embodied RL: 用 Group Relative Policy Optimization 做 reward-guided post-training,进一步提升 multi-step task planning 能力
Teaser. ACE-Brain-0 的跨 embodiment 统一能力展示——覆盖 Spatial Cognition、Autonomous Driving、Low-Altitude Sensing、Embodied Interaction 四个领域
ACE-Brain-0 Architecture
Task Formulation
将跨 domain 的 embodiment 学习建模为统一的条件自回归生成问题。定义 domain 集合:
每个 domain 对应任务分布 ,训练样本 : 是多模态观测(图像/视频), 是文本条件, 是目标输出。所有任务统一为:
Multimodal Architecture
三个核心组件:
- Vision Encoder + MLP Projector: 处理单图 / 多视图 / 视频输入,提取视觉特征并投影到 LLM embedding space
- Tokenizer: 将自然语言指令转为 text tokens
- ACE-Brain-0 LLM Decoder: 自回归生成输出 tokens
视觉 tokens 按 domain 概念性地组织为五类:General、Spatial、Driving、Aerial、Embodied。
Equation 3. Forward pass
符号说明: 为 Vision Encoder, 为 MLP Projector, 为 Tokenizer, 为 LLM Decoder。
Multimodal Autoregressive Objective
Equation 4. Full autoregressive objective
实际训练中 loss 仅计算 text tokens(visual tokens 仅作为 conditioning context):
Equation 5. Text-only supervised objective
采用 square averaging 平衡不同长度样本的 gradient contribution。
Training Strategy
五阶段训练流程,对应 SSR 范式的实现:
Stage 1: Spatial Scaffold Training
从 Qwen3-VL 出发,先用 general data(Cambrain-737K)训练 做 early activation,再用大规模 spatial data 训练 Spatial Expert ——作为后续所有 domain expert 的共享初始化。
Stage 2: Supervised Specialized Expert Fine-Tuning
从 分支,独立训练三个 expert:
- : spatial cognition expert
- : 初始化自 ,在低空感知/导航数据上训练
- : 初始化自 ,在自动驾驶数据上训练
分支训练避免 domain 间的 gradient interference。
Stage 3: Across-Embodiment Reconcile Model Merging
通过 data-free model merging 将多个 expert 合并为统一模型。采用 optimization-based Merging(WUDI),核心思想是在线性子空间中最小化 task interference:
Equation 7. Model merging objective
Equation 9. Closed-form solution
使用 Adam optimizer(lr=1e-5,1000 iterations),通过 FusionBench 框架实现。对比了 AVG Merging、TSVM、WUDI 三种策略,WUDI 效果最佳(super-additive composition effect)。
Stage 4: Supervised Fine-Tuning on Embodied Data
合并后的 在大规模 embodied 数据上做 SFT,得到 。训练数据包含 embodied interaction、task planning、action prediction。
Stage 5: Reinforcement Learning with GRPO
使用 100k mixed data(spatial / AD / UAV / embodied)做 GRPO 强化学习。
Equation 10. GRPO objective
Equation 11. Group-relative advantage
去掉了 KL divergence penalty(clipped surrogate objective 本身提供足够 regularization)。
Table 1. SSR 训练策略各阶段详细配置
| Stage-1 | Stage-2 | Stage-3 | Stage-4 | Stage-5 | |
|---|---|---|---|---|---|
| Target | Scaffold SFT | Specialize SFT | Expert Reconcile | Embodied SFT | RFT |
| Data Domain | Spatial | AD, UAV | - (Data-Free) | Embodied | Mixed |
| Base Model | |||||
| Optimizer | AdamW | AdamW | Adam | AdamW | AdamW |
| LR | |||||
| Merging Steps | - | - | 1,000 | - | - |
Experiments
ACE-Brain-0-8B 在 24 个 benchmark 上的综合评测,覆盖四大领域。
Table. 24 Benchmarks 综合对比(ACE-Brain-0 vs. 代表性 Embodied Brains)
| Benchmark | VeBrain | Pelican-VL | MiMo-Embodied | RoboBrain2.5 | Vlaser | ACE-Brain-0 |
|---|---|---|---|---|---|---|
| Spatial Cognition | ||||||
| VSIBench | 39.9 | 52.8 | 48.5 | 41.0 | 60.3 | 63.3 |
| MMSI-Bench | 27.3 | 26.0 | 31.7 | 29.3 | 27.2 | 32.2 |
| BLINK | 79.7 | 56.8 | 0.0 | 84.3 | 84.9 | 83.9 |
| SITE | 51.4 | 52.3 | 44.8 | 52.6 | 47.5 | 53.1 |
| SAT | 73.3 | 67.3 | 78.7 | 63.3 | 66.7 | 92.0 |
| MindCube | 30.1 | 31.0 | 32.3 | 28.1 | 34.6 | 82.1 |
| Multi3DRef | 67.8 | 7.9 | 8.2 | 8.2 | 8.2 | 59.6 |
| Autonomous Driving | ||||||
| MME-RealWorld | 60.1 | 57.9 | 60.3 | 60.0 | 41.6 | 71.2 |
| MAPLM | 22.9 | 24.9 | 74.5 | 22.5 | 29.1 | 77.8 |
| DriveAction | 78.3 | 77.2 | 81.0 | 80.5 | 78.1 | 81.3 |
| NuscenesQA | 29.3 | 14.8 | 56.7 | 33.2 | 33.1 | 58.8 |
| NuPlanQA | 82.9 | 83.4 | 73.7 | 79.3 | 78.3 | 91.7 |
| LingoQA | 55.0 | 56.0 | 69.9 | 48.0 | 59.6 | 65.8 |
| Low-Altitude Sensing | ||||||
| UrbanVideo-Bench | 36.5 | 37.1 | 26.0 | 37.5 | 30.4 | 56.9 |
| AirCop | 51.9 | 50.8 | 50.2 | 49.9 | 25.3 | 70.3 |
| AVI-Math | 25.4 | 22.5 | 33.7 | 26.1 | 19.3 | 35.0 |
| Airspatial (lower better) | 1583.4 | 1586.6 | 289.4 | 1509.3 | 1597.7 | 258.0 |
| HRVQA | 37.9 | 38.6 | 22.2 | 13.4 | 27.0 | 61.2 |
| Embodied Interaction | ||||||
| ERQA | 40.3 | 39.8 | 46.8 | 44.3 | 41.0 | 41.5 |
| RoboVQA | 29.2 | 28.1 | 0.9 | 32.9 | 7.9 | 64.6 |
| OpenEQA | 63.8 | 63.3 | 74.1 | 62.6 | 56.3 | 70.0 |
| EgoPlan2 | 27.3 | 39.4 | 43.0 | 44.9 | 53.4 | 55.3 |
| EmbSpatial | 70.5 | 73.2 | 76.2 | 75.6 | 75.3 | 77.3 |
| EB-Habitat | 15.0 | 16.3 | 16.7 | 26.3 | 40.0 | 42.3 |
Insights: ACE-Brain-0 在 24 个 benchmark 中的 20 个取得最佳结果。在 SAT (+12.7 vs. Gemini-2.5-Pro)、MindCube (+29.9)、RoboVQA (+30.1 vs. GPT-4o) 上优势最大。仅在 BLINK、Multi3DRef、LingoQA、ERQA、OpenEQA 上未排第一。
Ablation Study
Spatial Intelligence as a Shared Scaffold
关键发现:从 spatial-centric pretrained checkpoint 初始化 expert,比从 base model 初始化有 +19.3% AD、+16.5% UAV、+5.4% Embodied 的提升。这证明 spatial knowledge 是可迁移的 structural scaffold,而非仅限于 spatial benchmarks 的能力。
Importance of Data-free Model Merging (Reconcile)
三种 merging 策略对比:
- AVG Merging: 简单平均,已有 noticeable improvement
- TSVM: SVD-based Task Singular Vector Merging,进一步提升
- WUDI: optimization-based merging,效果最佳——在所有 domain 领先,且展现 super-additive composition effect(合并后表现超过单个最强 expert)
Effectiveness of SSR Training Paradigm
SSR vs. Joint Training vs. Sequential Training 的对比:
- Joint Training: Spatial -4.5, AD -7.3, UAV -8.6, Embodied -1.3(各 domain 都有损失)
- Sequential Training: Spatial -4.9, AD -2.5, UAV -3.5, Embodied +0.9(catastrophic forgetting 明显)
- SSR: Spatial +6.0, AD -0.6, UAV -3.2, Embodied +1.6(综合最优,+GRPO 进一步提升到 Spatial +6.6, Embodied +1.9)
关联工作
基于
- Qwen3-VL: ACE-Brain-0 的 base model 和 vision encoder 架构
- Cambrain-737K: Stage 1 general data 来源
- GRPO: Stage 5 的 reinforcement learning 方法
- FusionBench: model merging 的实现框架
对比
- VeBrain-7B: 7B embodied brain baseline
- Pelican-VL-7B: 7B embodied brain baseline
- MiMo-Embodied-7B: Xiaomi 的 embodied MLLM
- RoboBrain2.5-8B: 8B embodied brain baseline
- Vlaser-8B: 8B embodied brain with spatial reasoning
- GPT-4o / Gemini-2.5-Pro / Claude-4-Sonnet: closed-source MLLM baselines
方法相关
- AdaMerging: 首个将 adaptive merging 引入 multi-task model merging 的工作
- WUDI: optimization-based model merging(TSVM 的改进版)
- TSVM: SVD-based Task Singular Vector Merging
论文点评
Strengths
- 清晰的 insight: “spatial intelligence as universal scaffold” 比简单的 multi-task training 有更深的认识——不同 embodiment 的共同需求是 3D spatial understanding,这个 framing 很有说服力
- SSR 范式设计合理: 将 scaffold / specialize / reconcile 解耦,每个阶段各司其职,避免了 joint training 和 sequential training 的核心问题(gradient interference / catastrophic forgetting)
- 消融实验充分: Table 6-8 三个消融分别验证了 spatial scaffold 的迁移性、model merging 的有效性、SSR 整体范式的优势,逻辑闭环
- 评测覆盖广: 24 个 benchmark 跨 4 个 domain,覆盖了 spatial / AD / UAV / embodied 的主要评测
Weaknesses
- 无 action generation: ACE-Brain-0 是 QA-style 的 MLLM,不是 VLA——所有评测都是 perception / reasoning / planning 的语言输出,没有连续 action 生成的能力,限制了作为 “embodied brain” 的实际应用
- Model merging 的 scalability 未探索: 目前只合并 3 个 expert(Spatial / AD / UAV),如果 domain 更多(e.g., humanoid locomotion, surgical robotics),merging 的效果是否保持 super-additive 未知
- Base model 选择的影响未讨论: 基于 Qwen3-VL,但没有讨论 backbone 选择对 SSR 范式的影响
- Embodied benchmarks 偏 perception: 6 个 embodied benchmark(ERQA, RoboVQA, OpenEQA, EmbSpatial, EgoPlan2, EB-Habitat)主要测 QA 和 planning reasoning,不涉及真实 robot execution
可信评估
Artifact 可获取性
- 代码: inference-only(基于 Qwen3-VL 的推理代码)
- 模型权重: ACE-Brain-0-8B(HuggingFace)
- 训练细节: 超参 + 数据配比完整(Table 1 详细列出了 5 个 stage 的所有训练超参)
- 数据集: 部分公开——general data 使用 Cambrain-737K(公开),spatial / AD / UAV / embodied 数据来源有说明但具体配比未完全公开
Claim 可验证性
- ✅ 24 benchmarks SOTA/competitive: 论文提供了完整的 benchmark 对比表(Table 2-5),且 HuggingFace 有 checkpoint 可复现
- ✅ SSR 优于 joint/sequential training: Table 8 有完整消融,控制了 total training budget
- ✅ Spatial scaffold 可迁移: Table 6 对比了不同初始化路线的效果
- ⚠️ WUDI merging 的 “super-additive composition”: 仅在 3-expert 场景验证,是否 scale 到更多 expert 未知
- ⚠️ “Generalist foundation brain”: 仅限 QA/reasoning 输出,不具备 continuous action generation 能力,作为 “brain” 的完整性有待商榷
Notes
Rating
Metrics (as of 2026-04-24): citation=0, influential=0 (0%), velocity=0.0/mo; HF upvotes=4; github 75⭐ / forks=2 / 90d commits=23 / pushed 42d ago
分数:2 - Frontier 理由:SSR 范式(scaffold / specialize / reconcile)与 24-benchmark 的 cross-domain SOTA 验证使其成为当前 cross-embodiment MLLM 的重要参考——Strengths 里的 “清晰 insight” 与 “消融闭环” 支持它作为 frontier 代表作。但正如 Weaknesses 所指出,它不是 VLA(无 action generation),且 evaluation 局限于 QA/reasoning;方法组合(model merging + GRPO + staged SFT)也更像 engineering 整合而非开创性贡献,加之 2026-03 新发布、尚未被社区广泛采纳为 baseline,因此落在 Frontier 而非 Foundation。