Summary
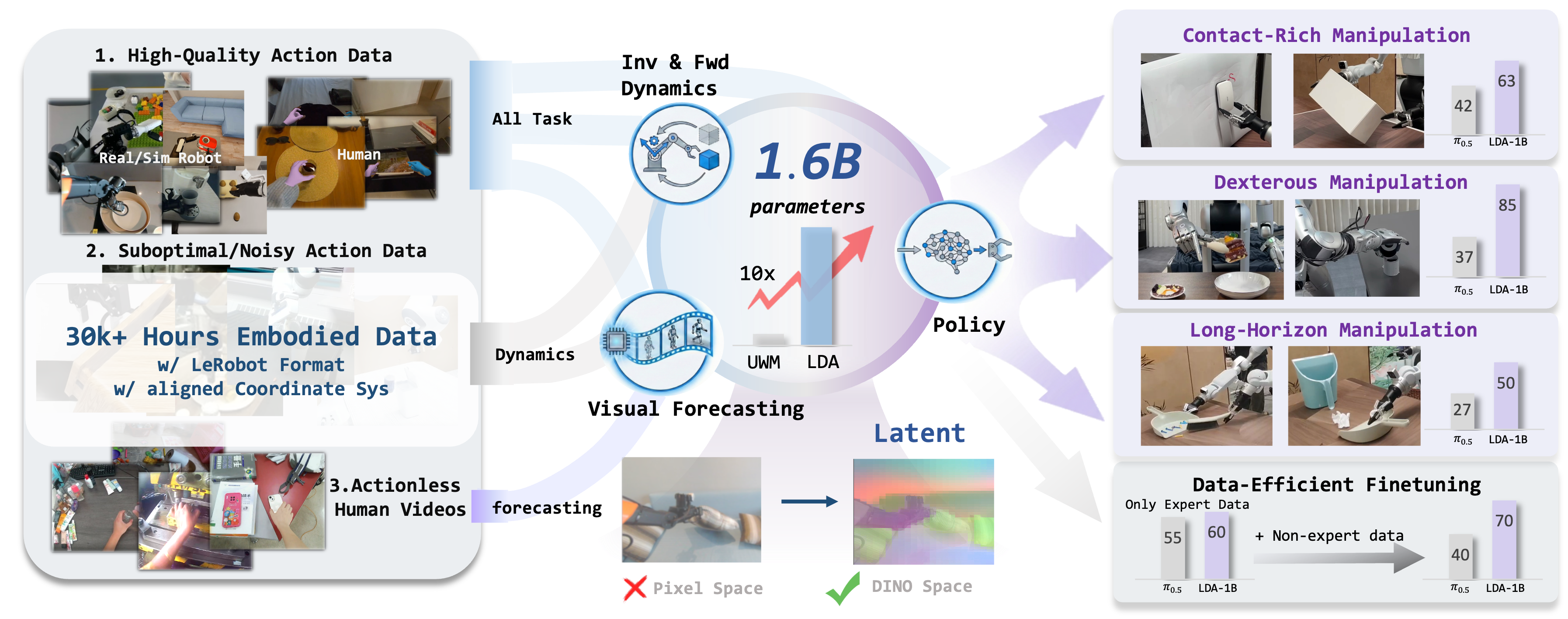
LDA-1B: Scaling Latent Dynamics Action Model via Universal Embodied Data Ingestion
- 核心: 把 UWM 的 joint diffusion 范式 scale 到 1B / 30k h,关键操作有两个:(1) 在 DINO latent space(而非 VAE pixel space)做 forward dynamics,让 dynamics 学习不被 appearance 噪声主导;(2) universal data ingestion——按数据质量把高 / 低质量 robot 轨迹和 action-less 人类视频分配给不同子目标(policy / dynamics / visual forecasting),低质数据反而成为 dynamics 监督的资源而非被丢弃
- 方法: 30k h EI-30k 异构数据集(real robot 8.03k + sim robot 8.6k + 人类 with-action 7.2k + 人类 actionless 10k),统一到 LeRobot 格式 + 对齐 hand-centric end-effector 坐标系;MM-DiT(action / visual experts 解耦 + 共享 self-attn)+ frozen Qwen3-VL & DINOv3,flow-matching 训练 4 个 task embedding(policy / FD / ID / VF)
- 结果: RoboCasa-GR1 55.4% > GR00T-N1.6 47.6% / UWM 14–20%;real-world Galbot 上 contact-rich +21% / dexterous +48% / long-horizon +23% over π0.5;mixed-quality finetune 加 30% 低质数据 LDA +10%(π0.5 反而 -10%–-20%)
- Sources: paper | website | github
- Rating: 2 - Frontier(DINO latent + role-aware data ingestion 是 UWM 路线第一次清晰 scale 到 30k h / 1B,real-world 真机数据漂亮且 mixed-quality finetune 现象具决策价值;但 cite=2/HF=0/⭐=0、距 UWM 增量主要在 latent space + scale + 数据 curation,未到 paradigm-shifting)
Key Takeaways:
- Pixel-space dynamics 是 UWM 路线的瓶颈:UWM-1B + MM-DiT 仅 20.0%,换成 DINO latent 暴涨到 55.4%(+35.4%)。说明 UWM 的 joint diffusion 架构本身没问题,问题在于让 1B model 在 VAE pixel latent 里既学 dynamics 又抑制光照 / 纹理 / 视角变化是 ill-posed 的。这间接给世界模型领域一个清晰的设计指引:dynamics 学习应在 semantic latent 上进行。
- 数据质量不是该过滤就是该用,而是该按角色分配:高质数据进 policy + dynamics + VF;低质 robot 数据只进 dynamics + VF(action 不可信但 transition 仍可信);actionless 人类视频只进 VF。结果是 BC baseline 加低质数据掉点,LDA 加低质数据涨点,把”过滤数据”重新定义为”分类使用数据”——这是 UWM 形式化下的自然结论但 UWM 自己没系统化做。
- Mixed-frequency 视觉 / 动作流:vision 3 Hz + action 10 Hz,承认相邻视觉帧高度冗余而 action 高频,这是相比 UWM / Motus 比较朴素但务实的设计选择,能省 token。
- RoboCasa-GR1 上 GR00T 范式 vs UWM 范式的当前差距:GR00T-EI30k(同 1B、同数据、纯 BC)51.3% vs LDA 55.4%,差距 +4.1%。这说明在 simulator benchmark 上 UWM 路线对 BC 的优势其实很小,但在 real-world few-shot adaptation 和 long-horizon 上拉开 21–48%——隐含 sim benchmark 已不能区分 foundation model 路线。
- Frozen DINOv3 是双刃剑:用现成 DINO latent 是 LDA 能 scale 的关键,但 DINO 没在 robot data 上微调过,paper limitation 自己也承认这是制约——下一步 jointly learn visual rep + dynamics 是显然方向(Motus 和 InternVLA-A1 走了另一条用 video generative model 的路,可对比)。
Teaser. LDA-1B overview. 30k h heterogeneous embodied data → unified DINO latent dynamics + multi-task co-training → 1B foundation model that is both data-efficient at finetune and beats π0.5 on real-world dexterous / long-horizon tasks.
I. Motivation:BC 与 UWM 之间
主流 robot foundation model(π0、π0.5、RDT、OpenVLA)走的是大规模 BC 路线,本质上只能消化 expert teleop / sim 数据——但人类和 OXE-style 异构 robot 数据里的 dynamics 知识被全部丢弃。LDA 把 UWM 路线推到 foundation scale,要解决三个问题:
- 粗粒度数据使用:UWM 把所有数据当同质的,不区分 quality / 监督信号 → 数据 scale 一上来 policy 学到的就是平均轨迹(包括坏 demonstration)
- 缺乏统一的大规模异构数据集:existing dataset 分散,action 表征不齐
- 像素空间 dynamics 学习效率低:VAE latent 让 dynamics 模型把容量浪费在背景纹理 / 光照 / 视角
LDA 对应回答:role-aware co-training + EI-30k + DINO latent。
Table I. 与近期 robot foundation model 的对比——LDA 是表里 (1) 唯一用 UWM 范式 scale 到 30k+ h 的方法 (2) 1B 参数比 π0.5 (3B) / GR00T (3B) / Being-H0 (14B) 都小。
| Model | Data Src. | # Data | Action Quality | Train. | Param. |
|---|---|---|---|---|---|
| π0.5 | Tele. | 10k+ | High | BC | 3B |
| RDT | Tele. | <10k | High | BC | 1B |
| GraspVLA | Sim. | 20k+ | High | BC | 2B |
| InternVLA-M1 | Sim. | <10k | High | BC | 3B |
| Being-H0 | Hum. | <10k | Mixed | Aln. + BC | 14B |
| InternVLA-A1 | Het. | 10k+ | High | VF + BC | 3B |
| GR00T-N1.6 | Het. | <10k | Mixed | LA + BC | 1B |
| UniVLA | Het. | <10k | Mixed | LA + BC | 7B |
| LDA-1B | Het. | 30k+ | Mixed | UWM | 1B |
❓ Being-H0 14B 在 <10k 上算特例,Mixed action quality + Alignment+BC 训练范式更接近 LDA 思路而不像表上分得那么开。这个 table 对 UWM 范式的”独占性”叙事有一定 marketing。
II. Method:Latent Dynamics Action Model
II-A 形式化:Unified World Model
给定当前观测 ,UWM 联合建模四个分布:
- Policy:
- Forward Dynamics:
- Inverse Dynamics:
- Visual Planning / Forecasting:
通过给 action 和 observation 独立采样的扩散 timestep ,单一模型在 inference 时根据 timestep 取值切换不同条件分布(这点和 UWM 完全一致,是 UWM 的核心 trick):
LDA 在此基础上加了 language 条件(通过 frozen Qwen3-VL)。
II-B Universal Data Ingestion:role-aware co-training
LDA 的关键概念创新——不是按 quality 过滤数据,而是按 quality 分配 supervision objectives:
| 数据类型 | Policy | Forward Dyn. | Inverse Dyn. | Visual Forecast |
|---|---|---|---|---|
| 高质 robot + 人类 demo | ✓ | ✓ | ✓ | ✓ |
| 低质 robot 轨迹 | ✗ | ✓ | ✓ | ✓ |
| Actionless 人类视频 | ✗ | ✗ | ✗ | ✓ |
实现机制:4 个 learnable task embedding(policy / FD / ID / VF)+ 2 个 learnable register token(action / visual register,作为缺失模态的占位符)。比如训 policy 时输入 noisy action token + visual register;训 VF 时输入 noisy visual token + action register。flow-matching 损失:
各项 loss 按 task embedding 决定是否激活——这是把 UWM 的”timestep ≡ soft mask”再升一级到”task embedding ≡ 训练目标 ≡ 数据使用方式”。
II-C 预测目标的表征
Visual:用 frozen DINOv3 latent(不是 VAE)。理由:DINO latent 编码高层 semantic + spatial structure,suppress 低层纹理 / 光照变化 → dynamics 学习对环境变化更鲁棒。
Action:统一的 hand-centric action space——delta wrist pose + finger configuration。
- 平行夹爪:1-DoF gripper width
- 多指 dexterous hand:keypoints in wrist frame
- 人类:6-DoF wrist pose + MANO 全参数
Temporal alignment:vision 3 Hz / action 10 Hz 异步流——降低视觉帧间冗余,保留 action 高频细节。
II-D MM-DiT 架构
Figure 2. LDA 架构:MM-DiT joint denoise action chunk + future DINO latent。Action / visual expert 各自有独立 QKV projection 和 FFN(保留 modality-specific inductive bias),但共享 self-attention(实现跨模态交互)。Language token 通过 cross-attention 注入。条件信号(VLM token、diffusion timestep、task embedding)通过 AdaLN 注入每个 transformer block。
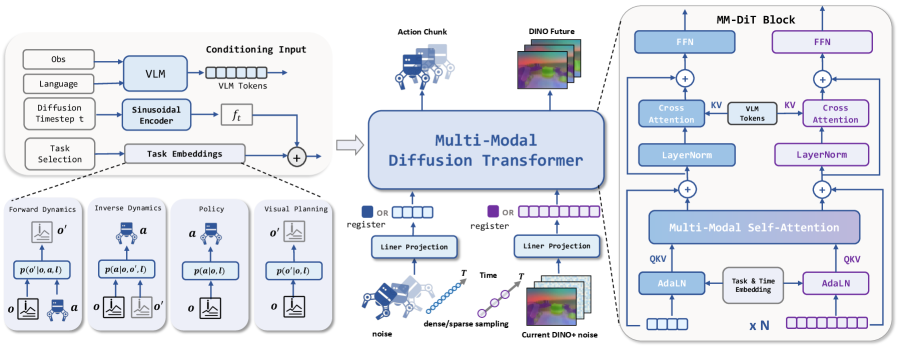
❓ 这个设计很像 SD3 的 MM-DiT,对 UWM 原版 DiT 的最大改进是 modality-specific FFN——但 ablation(Table II)显示去掉 MM-DiT 仅 -6.5%,相比 DINO 换 VAE 的 +35% 是小头。
II-E 训练配置
- 48 × NVIDIA H800,400k iterations,总计 4,608 GPU 小时
- VLM (Qwen3-VL) 和 DINOv3 encoder 全程 frozen,只更新 MM-DiT + action encoder/decoder
- Post-training(finetuning)走和 pretraining 同样的 data regime——直接吃未过滤的 mixed-quality teleop 数据
❓ 4608 H800-h 在 1B / 30k h scale 上算偏少(约 96 h × 48 GPU),猜测要么 training 收敛快、要么是早期 checkpoint。论文没给 loss curve / learning rate schedule,复现难。
III. EI-30K 数据集
Figure 4. EI-30K 统计:30k+ h,覆盖 4 类数据,episode 长度和任务多样。

构成(共 33.83k h):
- Real-world robot:8.03k h(包括 OXE、AgiBot World、DROID、RH20T 等)
- Sim robot:8.6k h(BEHAVIOR-1k、InternVLA-M1 等)
- Human with action:7.2k h(Ego4D、EPIC-Kitchens、HOI4D、EgoDex 等带 hand pose 的)
- Human actionless:10k h(pure egocentric video)
三个数据工程要点:
-
统一格式:全部转成 LeRobot 格式
-
对齐 action 表征:手 / 末端执行器在 shared coordinate frame 下表达,camera extrinsics 单独保留以解耦 wrist 运动和 head egomotion
Figure 3. 对齐的 end-effector 坐标系:手动对齐不同 robot 和人类 embodiment 的坐标系,让 joint training 在几何上一致。

-
质量标注:每条轨迹打 quality label,不做激进过滤——保留低质数据让 quality-aware training 用。
❓ 对齐 hand-centric coordinate 是 LDA 在数据工程上最重要的贡献之一,但论文给的细节非常少(手动对齐的具体规则、误差来源、不同来源的失败案例),这部分可能比方法本身更难复现。
IV. 实验
IV-A Simulation:RoboCasa-GR1
Setup:24 个 tabletop / articulated-object 任务,GR-1 humanoid + Fourier dexterous hand,egocentric RGB only。每任务 1k 轨迹 finetune,51 trial 评测。
Table II. RoboCasa-GR1 主结果与消融:
| Model | Vis. Rep. | MM-DiT | VLM | Success Rate ↑ |
|---|---|---|---|---|
| GR00T-N1.6 (3B) | - | - | Cosmos | 47.6 |
| StarVLA | - | - | Qwen3-VL | 47.8 |
| GR00T-EI30k (1B repro, BC) | - | - | Qwen3-VL | 51.3 |
| UWM-0.1B | VAE | ✗ | - | 14.2 |
| UWM-1B | VAE | ✗ | Qwen3-VL | 19.3 |
| UWM (MM-DiT) | VAE | ✓ | Qwen3-VL | 20.0 |
| LDA (DiT) | DINO | ✗ | Qwen3-VL | 48.9 |
| LDA-0.5B | DINO | ✓ | Qwen3-VL | 50.7 |
| LDA-1B | DINO | ✓ | Qwen3-VL | 55.4 |
关键消融拆解:
- DINO vs VAE latent(同 1B、同 MM-DiT):20.0 → 55.4,+35.4%——这是 LDA 最大的 single design decision
- Scale UWM:UWM-0.1B (14.2) → UWM-1B (19.3) → UWM-1B-MMDiT (20.0),scale 几乎不带来提升 → 印证 VAE latent 是瓶颈
- MM-DiT vs DiT(同 1B、DINO latent):48.9 → 55.4,+6.5%
- 0.5B → 1B:50.7 → 55.4,+4.7%,LDA 在该 setup 下 scale 单调增长
与 BC baseline 的对比:LDA-1B (55.4) vs GR00T-EI30k 1B repro BC (51.3) = +4.1%。simulation 上 UWM 范式对 BC 的增量并不大——主要差距出现在 real-world。
IV-B Real-world:Galbot G1 + Sharpa / BrainCo dexterous hands
Figure 5. 真实机器人平台:(top-left) Galbot G1 + Sharpa hand,(middle/bottom-left) Unitree G1 + BrainCo hand,(right) Galbot G1 + 平行夹爪。

每任务收集 100 条未过滤 teleop(50–80% 是 expert 行为,其余有 pause / retry / 低效轨迹)。Baseline (π0.5、GR00T) 只在 expert 子集 finetune,LDA 用全部 mixed-quality 数据。
Gripper Manipulation
Figure 6. 真机 gripper manipulation 任务成功率:8 个任务覆盖 Pick-and-Place、Contact-rich、Fine、Long-horizon,LDA 全面优于 π0.5 和 GR00T-N1.6。最具代表性的是 Clean the Rubbish(双臂 + 工具使用 + 长时序):LDA 35% vs π0.5 / GR00T 0%。
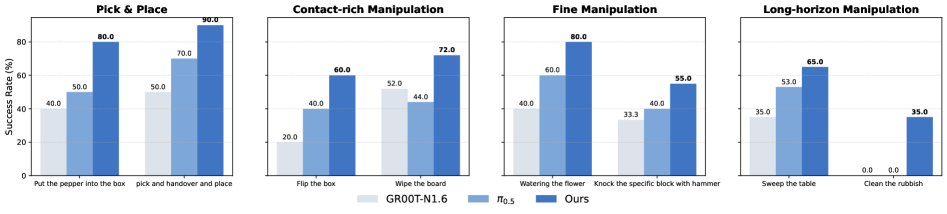
Real-world demos(来自项目页):
Pick & Place 跨 object / position / background(6× speed)
Clean the Rubbish——双臂 + 工具 + 长时序的代表任务(4× speed)
Dexterous Manipulation
Figure 7. 真机 dexterous manipulation 成功率对比:低 DoF(BrainCo 10-DoF)3 个任务 + 高 DoF(Sharpa 22-DoF)2 个任务。Pull Nail:LDA 80% vs π0.5 ~0%。Flip Bread:LDA 90% vs π0.5 10%。

这里的 +48% dexterous gain 论文归因为”大规模人类 hand-centric 数据带来的 latent prior”——这个 attribution 受得住挑战吗?因为 π0.5 也用了 OXE 类数据但没用 7.2k h 人类 with-action 数据,LDA 的优势可能是 (a) 人类数据 (b) DINO latent (c) UWM dynamics 三者复合作用。
Sharpa 22-DoF:Use a clamp to place object(1× speed)
BrainCo 10-DoF:Unscrew the cap(10× speed)
Generalization
Table III. 视觉 / 空间扰动下的泛化——Pick-and-place,三个扰动维度:
| Method | Object | Background | OOD Pos. |
|---|---|---|---|
| π0.5 | 26.7 | 20.0 | 6.7 |
| GR00T | 40.0 | 40.0 | 20.0 |
| LDA-1B | 60.0 | 60.0 | 40.0 |
LDA 在所有三轴上都比 BC baseline 好 ~2×。论文归因为 latent dynamics pretraining 让模型 focus 在 task-critical affordance 上而忽略视觉 distractor。
Mixed-Quality Finetuning
Table IV. 混合质量 finetune 数据——分别用 (a) 仅 high quality 和 (b) high+low quality 全集 finetune:
| Method | Pen-into-box: 63 H | Pen-into-box: 63 H + 37 L | Bimanual lid: 66 H | Bimanual lid: 66 H + 34 L |
|---|---|---|---|---|
| π0.5 | 60 | 40 (↓20) | 50 | 40 (↓10) |
| Ours | 70 | 80 (↑10) | 50 | 60 (↑10) |
这是这篇文章最有用的实证:BC 路线加低质数据确切地掉点,而 LDA 加同样数据确切地涨点。意味着 LDA 把”数据收集成本 / 数据筛选成本”这一项实际成本砍掉一半以上——对 deployment-side scaling 是非常 actionable 的指引。
IV-C Scaling Analysis
Figure 10. Scaling 分析(在 AgiBot World held-out 测的 action L1 error)。Top:30k h 数据 → 误差降到 6.6,且加入 actionless human video 仍继续下降,说明 LDA 能从无 action 数据榨出 supervision。Bottom:LDA 在 0.1B → 1B 单调下降而 UWM 快速饱和。
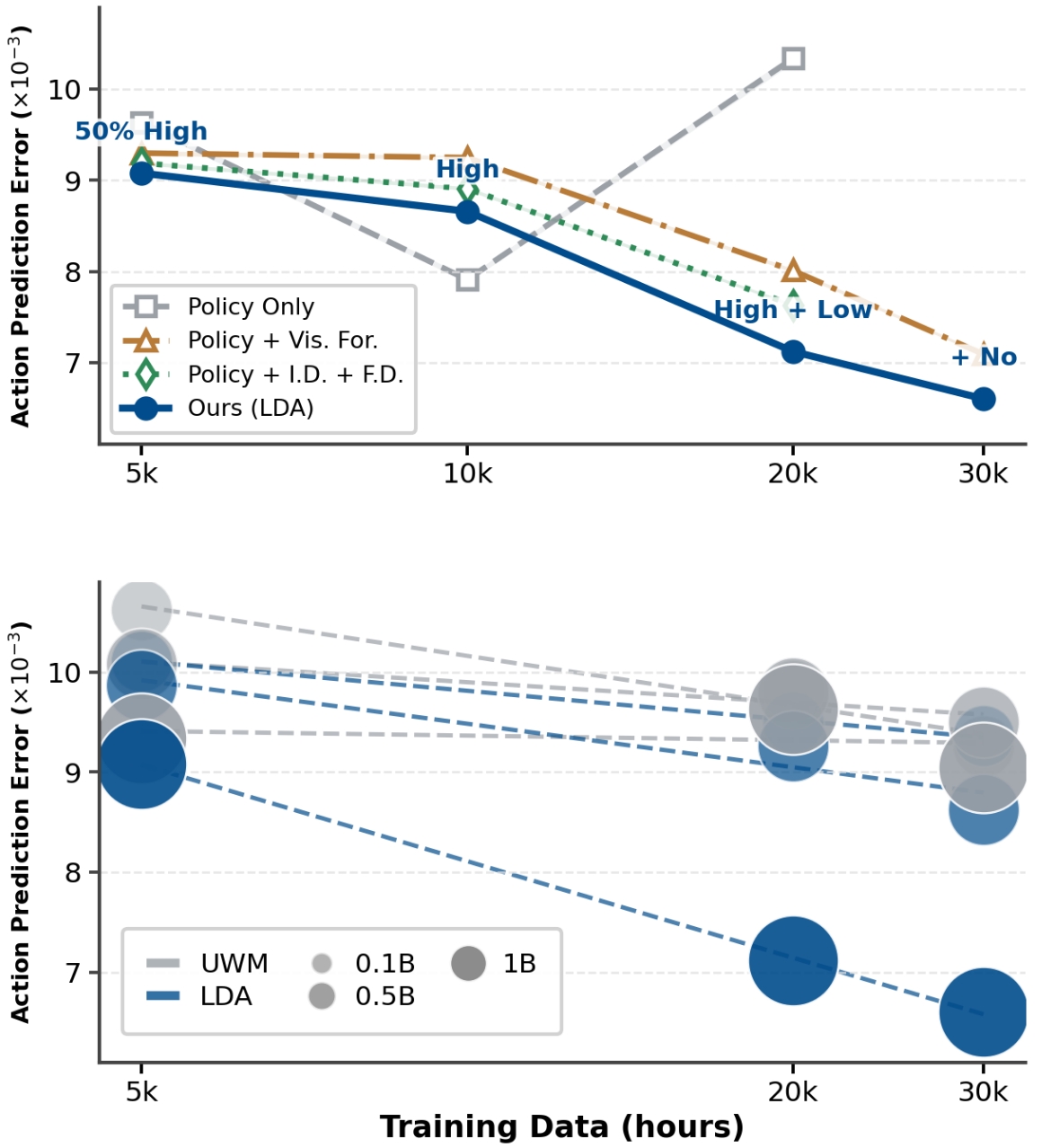
三个核心结论:
- Universal data ingestion 必须 data scale + objectives 一起 scale:Policy-only objective 下加更多(含低质)数据反而 unstable;只有全部 4 个 objectives 共训才单调下降。
- Latent space 决定 scaling 是否有效:UWM(VAE) 早早饱和;LDA(DINO) 单调改善。这个对比直接指向”latent 表征要足够 semantic 才能让 dynamics 学习随 capacity 持续受益”。
- Model scale 1B vs 0.5B vs 0.1B 单调降低 error——显示 capacity-data-objective 三轴对齐是 reliable 的。
IV-D Dynamics Learning 分析
Latent forward dynamics 可视化(项目页 video)——模型给出与 ground truth 一致的 future DINO latent(PCA 投影后),保留物体永久性、接触连续性、运动一致性,且对 distractor 不敏感:
Dexterous Manipulation:Original RGB / DINO latent / Model prediction
Human Demonstration
Figure 11. Action-conditioned attention heat map:对比 active motion command 和 No-Op 的 attention 差,揭示哪些区域是 action-conditioned 的关注重点。Push Right 高亮 mug 前缘和运动方向;Push Close 集中在抽屉接触面;背景杂物被 suppress。

❓ Attention diff 这种可视化工具在 BC baseline 上没做对照,无法判断 LDA 的 attention 是不是真的”更 action-aware”——这个 finding 偏 anecdotal。
V. 局限
论文自己列的:
- Frozen DINO 限制了 visual representation 适应新 viewpoint / multi-modal sensor 的能力
- Egocentric / head-mounted camera 主导:跨视角泛化未验证
- Data role 是预先手工指派的,没自动化
我加上的:
- 超参 / 数据混合比 / training schedule 在论文里几乎没披露——“4608 GPU h” 是唯一硬数字,复现门槛高
- GR00T-EI30k baseline 是自己 reproduce 的 1B 版本,不是官方 GR00T-N1.6 (3B)。和官方相比 +7.8%,但官方 3B 的 capacity 优势在 BC 范式下应该更大;这里的 setup 公平性需要自己交叉对比
- Real-world 评测 trial 数偏少(每任务 ~10 次),±10% 在 100% scale 上是噪声门槛
关联工作
基于
- UWM (Zhu et al., 2025): LDA 直接继承的 paradigm——joint diffusion + 独立 timestep。LDA 的两大改动:(1) VAE latent → DINO latent;(2) 同质 data 用法 → role-aware ingestion。在 RoboCasa-GR1 上 LDA 从 20.0% 拉到 55.4% 是这两改动的复合效果。
- DiT / MM-DiT: AdaLN-conditioned diffusion transformer(SD3 同源),LDA 用 multi-modal 双 expert 共享 attention 的变体。
- DINOv3: frozen visual representation 做 dynamics target——这是把 DINO-WM / LaDi-WM 的小 scale 实验放大到 30k h foundation scale。
- Flow Matching: 训练目标。
- MANO: 人类手部参数化,给 cross-embodiment 对齐用。
对比
- π0.5 (Physical Intelligence): real-world 主要 baseline,3B BC,LDA 1B 在 contact-rich / dexterous / long-horizon 上分别 +21% / +48% / +23%,且 mixed-quality finetune 上 LDA +10% 而 π0.5 -10%–-20%
- GR00T-N1.6 (NVIDIA): simulation 主要 baseline,LDA 在 RoboCasa-GR1 +7.8%(vs 3B 原版)/ +4.1%(vs 1B 同数据 BC repro)
- OpenVLA / π0 / RDT: 第一代 BC 路线 robot foundation model,LDA 整体定位是给”BC 之后下一步”的代表
- Motus (concurrent): 也走 UWM 路线但用 Mixture-of-Transformers + 视频生成 prior + optical-flow latent action;LDA 走 DINO latent + 单一 MM-DiT,更轻
- InternVLA-A1: VF + BC,3B,未走完整 UWM
- UniVLA / GR00T-N1.6: 走 latent action modeling (LA) 路线(用预训练 latent action codec 提取人类动作),LDA 用 hand-centric coordinate alignment 直接对齐,回避 latent action 路线对 codec 质量的依赖
方法相关
- Genie / video world model 路线:与 LDA 都做 forward dynamics,但 video model 在 pixel space 工作 + 不联合 policy;LDA 在 latent space + joint policy
- Diffusion Policy: action 端的祖先,LDA 把 action diffusion 嵌入 UWM
- EI-30k 数据来源:OXE / AgiBot World / DROID / RH20T / Ego4D / EPIC-Kitchens / HOI4D / EgoDex / BEHAVIOR-1k 等
论文点评
Strengths
- DINO latent 替换 VAE 是 UWM 路线的关键 unlock:+35.4% 的消融数字非常硬,对整个 video world model + policy 联合训练社区有指导意义——pixel space 是 dynamics 学习的瓶颈,semantic latent 才能让 capacity scale 起来
- Universal data ingestion 把”数据过滤”重新定义为”数据角色分配”:Table IV 的 mixed-quality finetune 现象(LDA +10% vs π0.5 -20%)直接转化成 deployment 价值,比 abstract scaling number 更可 actionable
- 完整的 cross-embodiment 数据工程:33.83k h 跨 robot / human / sim / real / actionless 的统一格式 + hand-centric 坐标对齐,是 BC 路线少做的脏活
- 完整的 ablation:DINO vs VAE / MM-DiT vs DiT / scale 0.1B-0.5B-1B / data scale + objective combinations,每一个设计选择都被消融
- Real-world 任务多样性:8 + 5 个真机任务跨两种 dexterous hand,比纯 sim 论文可信度高
Weaknesses
- 方法层面增量集中:相比 UWM 主要是 (a) latent 换成 DINO (b) 数据按 role 分配 (c) scale 上去——三件事每一件单独都不算颠覆,组合起来才出效果。属于”系统工程级”贡献,不是”概念级”
- 复现细节缺失:4608 GPU h、48 H800 是唯一硬数字;data mixing ratio、loss weight、curriculum、optimizer schedule 几乎没说
- GR00T-EI30k 是自己复现的 baseline,复现的 BC 模型和官方 3B 不可直接比较,给出的 51.3% 数字带主观性
- Real-world trial 数偏少:每任务 ~10–15 次,±10% 在该 scale 上波动门槛接近成功率间隔
- Frozen visual encoder 自带天花板:作者自己也承认。jointly learn rep + dynamics 是显然下一步,Motus 的 video generative prior 路线提供了一个对比方案
- Attribution 不够干净:dexterous +48% 同时受益于 (a) 人类数据 (b) DINO latent (c) UWM 范式 (d) hand-centric alignment,论文没拆开
可信评估
Artifact 可获取性
- 代码: GitHub repo 已建(PKU-EPIC/LDA),但 main 分支无 README,截至 2026-04-29 是 0 ⭐ / 0 fork(项目页声称 “Code & Data” 即将放)。实际可用代码:未发布
- 模型权重: 未发布的 checkpoint
- 训练细节: 仅披露 GPU 总时(4608 h)和 frozen 组件,超参 / 数据配比 / 训练步数详细配置未披露
- 数据集: EI-30k 由 公开数据 + 自建处理脚本 组成,subdataset 名字给了(OXE / DROID / Ego4D / EPIC-Kitchens 等)但统一后的 30k h LeRobot 格式 dump 是否会发布未说明
Claim 可验证性
- ✅ DINO latent vs VAE +35.4%:Table II 同条件直接消融,强 grounding
- ✅ RoboCasa-GR1 55.4%:仿真 benchmark,可独立复现(需 1k traj/task fin tune setup)
- ✅ Mixed-quality finetune +10% vs BC -10%:Table IV,跨两个任务一致,方向正确
- ⚠️ Real-world +21% / +48% / +23%:trial 数小(每任务 ~10–15 次)+ baseline 是 finetune-on-expert-only 与 LDA-finetune-on-all 的对比,不是 100% apple-to-apple——LDA 多用了低质数据这一资源
- ⚠️ EI-30k 30k+ h:组成统计给了,但人类 actionless 10k h 部分是否真用上 / 各组件配比对结果的边际贡献,scaling 图里仅区分”加 / 不加 actionless”
- ⚠️ GR00T-EI30k 1B 51.3%:自己复现的 baseline,权威性弱于官方 GR00T-N1.6 (47.6, 3B)
- ❌ “breaks the 6k-hour ceiling of hybrid methods”:是 marketing 话术——之前方法 ≤6k h 不是 hard ceiling 而是 setup 选择
Notes
- 这是 PKU EPIC + Galbot 的工业 + 学术联合工作,He Wang 实验室 + Galbot 公司体制,和 GR00T / π0 形成的是真正商业意义的对标
- Mixed-frequency vision/action 设计(3Hz/10Hz)是务实的工程优化,但论文没消融——猜测对结果影响 < 5% 但 token 数砍掉了 70%
- 论文题目里”Latent Dynamics”是 thesis statement——把所有方法选择都收敛到”latent dynamics 是 robot foundation 的 organizing principle”。这个 framing 和 UWM 的”action 和 observation 都是同一 diffusion 过程的两端”互补但不冲突
- 与 Motus 形成 contemporary 对比:Motus 走 video generative prior + MoT,LDA 走 DINO latent + MM-DiT;下一步 community 收敛方向值得关注
Rating
Metrics (as of 2026-04-29): citation=2, influential=0 (0%), velocity=1.0/mo (publish < 3 mo, 不作为降档依据); HF upvotes=0; github 0⭐ / forks=0 / 90d commits=24 / pushed 61d ago · code-not-yet-public
分数:2 - Frontier
理由:方法是 UWM 路线第一次清晰 scale 到 30k h / 1B foundation scale,DINO latent + role-aware data ingestion 两个设计选择都有非常硬的消融数字(+35.4% / mixed-quality finetune +20% gap)和真实机器人验证。但论文不到 3 个月、社区信号几乎为零、代码未放出,且方法相对 UWM 的核心增量是工程组合而非范式突破——所以暂归 Frontier 而非 Foundation。后续若代码 + 模型权重发布且 community 接住其 latent dynamics 范式(特别是用 DINO 类 semantic latent 做 dynamics 这一点被广泛复用),可升档。