Summary
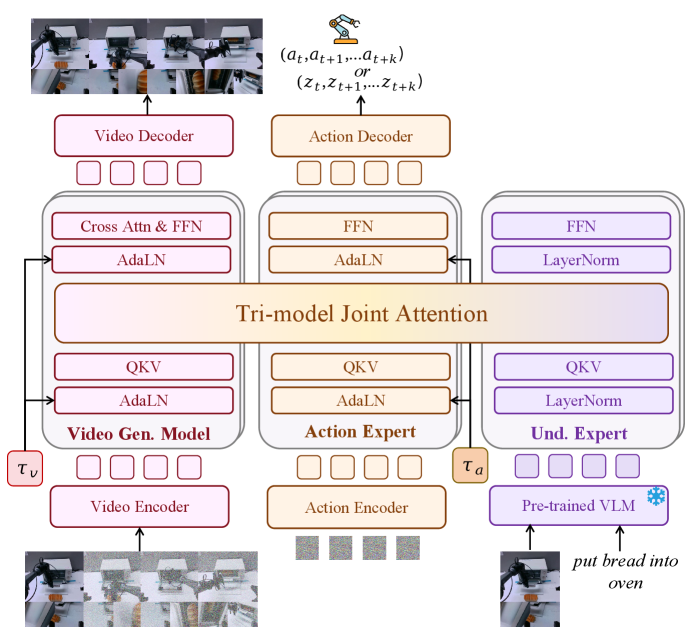
Motus: A Unified Latent Action World Model
- 核心: 用 Mixture-of-Transformers 把预训练 VGM、VLM、action expert 串起来,配合 UniDiffuser 风格的多时间步调度器,实现一个模型在 VLA / WM / IDM / VGM / 视频-动作联合预测五种推理模式间自由切换
- 方法: Tri-modal Joint Attention + 基于 optical flow 的 latent action(用 DC-AE + 14 维线性投影对齐真实 action 空间)+ 三阶段训练(VGM 预训 → latent action 预训 → target-robot SFT)+ 六层数据金字塔
- 结果: RoboTwin 2.0 randomized 上 +43% over π0.5 / +14% over X-VLA;real-world AC-One 上 partial success rate 从 14.79% (π0.5) 提到 63.22%;LIBERO-Long 97.6 持平 SOTA
- Sources: paper | website | github
- Rating: 2 - Frontier(5-mode unified VLA/WM/IDM/VGM/Joint 最完整的工程实现,真实机器人长任务提升可观,但架构相对 UWM/Bagel 偏合并、算力门槛极高、跨 embodiment 卖点未验证,属前沿参考而非奠基)
Key Takeaways:
- Mixture-of-Transformers + Tri-modal Joint Attention: 不像 UWM 直接拼 token 走单一 backbone,每个 expert 保留独立 Transformer module,仅通过共享 self-attention 做跨模态融合——既保留 pretrained 能力又允许信息交流
- UniDiffuser 风格调度器统一五种 mode:给 video 和 action 分配独立 timestep ,推理时通过把某一模态的 timestep 钉死在 0 (clean condition) 或 (pure noise/丢弃) 来切换 VLA / WM / IDM / VGM / Joint
- Optical-flow latent action 作为跨 embodiment 的”通用动作”: DPFlow 抽 flow → DC-AE 编码 → 投影到 14 维(贴合典型机器人 action 维度),90% unlabeled 重建 + 10% labeled 弱监督让 latent space 自动对齐真实控制分布
- Action-Dense Video-Sparse: video 8 帧 @ 5Hz vs action 48 帧 @ 30Hz——降低 video token 占比避免 attention 被 video 主导,实测必要
- 数据金字塔从 web → target-robot 6 级:Egodex (230K) + AgiBot (728K) + RDT/RoboMind + RoboTwin + 任务无关数据 + 2K target-robot in-house,验证 unlabeled 视频 + multi-robot 数据 + target-robot SFT 的复合效果
Teaser. Motus architecture overview. 三个 expert 共享 self-attention,video 和 action 分别走各自的 rectified flow。
Background and Problem
五种 embodied 建模范式
当前 embodied foundation model 的能力被人为切成五种独立 paradigm:
- VLA:
- WM (World Model):
- IDM (Inverse Dynamics):
- VGM (Video Generation Model):
- Video-Action Joint:
UWM 已尝试用单一 diffusion backbone 统一这五种分布,但是 from-scratch 训练,没用到 VLM/VGM 的 pretrained prior。F1 拼了 VLA + IDM 但还是缺 WM 和 VGM。Motus 的定位:在保留 pretrained prior 的前提下完整覆盖五种 mode。
两个核心 Challenge
- 多模态生成能力的统一:how to integrate VLM 的 vision-language understanding prior + VGM 的 physical interaction prior + action 生成能力
- 异构数据利用:action space 跨 embodiment 不可复用,且 internet video / egocentric human video 缺 action label——如何让 action expert 也能 large-scale pretraining
Method
1. Mixture-of-Transformers 架构
关键设计:每个 expert(understanding / VGM / action)保留独立的 Transformer 栈,只在 multi-head self-attention 层做跨 expert 拼接(Tri-modal Joint Attention)。这样:
- 保留各 expert 的 specialized function(不像 UWM 那样一锅烩进单一 transformer)
- 允许 cross-modal feature fusion
Expert 选择:
- VGM (生成 expert): Wan 2.2 5B,扩展其 self-attention context 接入 Tri-model Joint Attention
- VLM (understanding expert backbone): Qwen3-VL-2B(看中其 3D grounding / spatial understanding / object localization 能力)
- Action expert: 与 Wan 同深度的 Transformer,每 block 含 AdaLN(注入 rectified flow timestep)+ FFN + Tri-model Joint Attention
- Understanding expert head: 取 Qwen3-VL last-layer token,过若干 LayerNorm + FFN + Tri-model Joint Attention block
总参数:~8B(VGM 5B + VLM 2.13B + Action 641M + Und. 253M)
2. Rectified flow + UniDiffuser 调度
训练时 video 和 action 分配独立 timestep 、独立 noise,loss 是两路 rectified-flow velocity loss 之和:
推理切 mode 的 trick——通过把某模态的 timestep 钉死实现:
| Mode | start | start | 含义 |
|---|---|---|---|
| VGM | (denoise) | (保持纯噪) | 生 video,action 当作未知 noise |
| WM | (denoise) | (clean cond) | 用 clean action 条件生 video |
| IDM | (clean cond) | (denoise) | 看完整视频反推动作 |
| VLA | (保持纯噪) | (denoise) | 只输出动作,video 当未知 |
| Joint | (denoise) | (denoise) | 同时去噪 video + action |
❓ 个人观察:这个调度比 UWM 的版本更显式——UWM 的”模式切换”也是基于 conditioning 但一个 backbone 同时建模五个分布的 capacity 容易打架,Motus 借助 MoT 把 capacity 在物理上分了开。
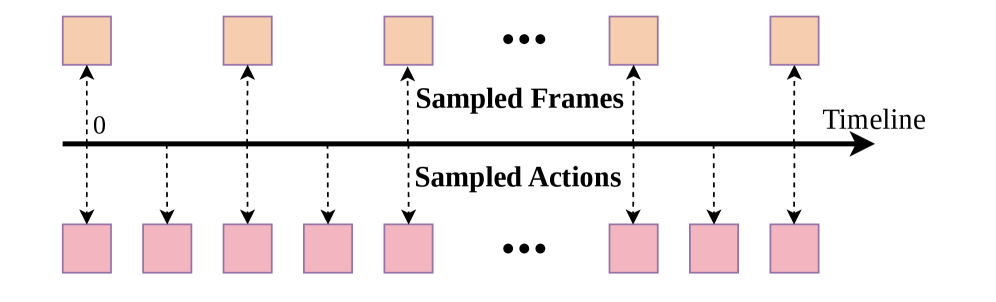
3. Action-Dense Video-Sparse Prediction
问题:video token 数量远多于 action token → Joint Attention 中 video 占绝对优势 → action 学不好。
做法:训练和推理都把 video 帧率降到 action 帧率的 1/6。最终配置 video 8 帧 @ 5Hz vs action 48 chunk @ 30Hz。
Figure 2. Action-Dense Video-Sparse Prediction sampling schematic.
4. Latent Action via Optical Flow
为了让 action expert 也能从 unlabeled video 上预训练,引入 latent action(“pixel-level delta action”):
Pipeline:
- DPFlow 算 consecutive frame 间 optical flow,转成 RGB image
- 预训练的 deep convolutional VAE (DC-AE) 把 flow 压成 4 × 512 token
- 一个轻量 encoder 把 4×512 投到 14 维(贴合典型机器人 action 空间维度)
对齐到真实 action 分布:90% 数据走自监督 flow reconstruction + 10% 带 label 的数据(含 AnyPos 风格的 task-agnostic 随机采样 action 数据 + 标准 robot demo)做弱 action 监督。Loss:
Figure 3. Latent Action VAE.
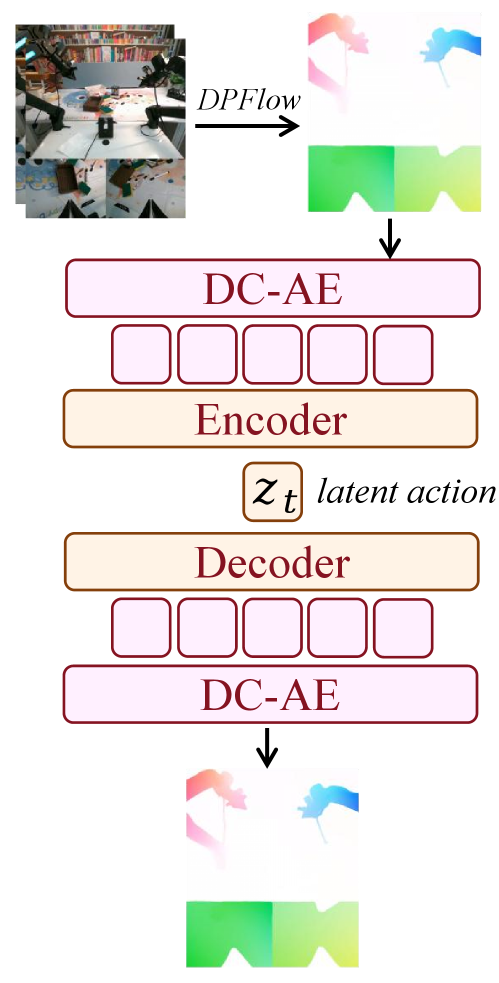
❓ 14 维这个数字明显是为 Aloha 类双臂机器人量身定的。换 humanoid 或 dexterous hand 时这个维度该不该换?论文没说。
5. 三阶段训练 + 六层数据金字塔
Figure 4. Embodied Data Pyramid. 从 web data (Level 1) 到 target-robot demo (Level 6),量从大到小、质从低到高。
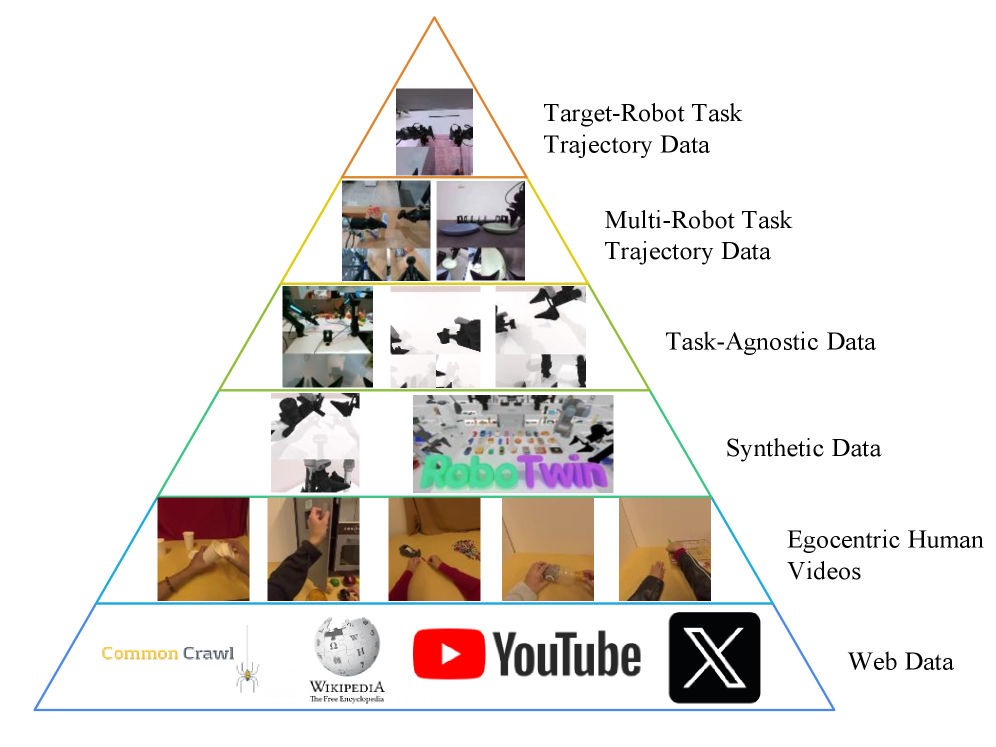
Table 1. Motus Training Stages.
| Stage | Data Levels | Training |
|---|---|---|
| 预训 foundation | L1: Web Data | VGM 和 VLM(即 Wan2.2 / Qwen3-VL,off-the-shelf) |
| Stage 1 (VGM 适配) | L2 + L3 + L5 | 只训 VGM |
| Stage 2 (Unified Pretrain w/ Latent Actions) | L2 + L3 + L4 + L5 | 全部 Motus(VLM 冻结),用 latent action |
| Stage 3 (SFT) | L6: Target-Robot 数据 | 全部 Motus,用真 action |
实际数据量:
| Dataset | Size | Embodiment | Pyramid Level |
|---|---|---|---|
| Egodex | 230,949 | Human | L2 |
| AgiBot | 728,209 | Genie-1 | L5 |
| RDT | 6,083 | Aloha | L5 |
| RoboMind Franka | 9,589 | Franka | L5 |
| RoboMind Aloha | 7,272 | Aloha | L5 |
| RoboTwin | 27,500 | Aloha | L3 |
| Task-Agnostic | 1,000 | Aloha | L4 |
| In-house | 2,000 | Aloha | L6 |
算力:Stage 1 ~8000 GPU-hours,Stage 2 ~10000 GPU-hours,Stage 3 ~400 GPU-hours。
Experiments
Sim:RoboTwin 2.0(50 任务,含 randomized scene)
50 task multi-task setting,每 task clean 50 demo + randomized 500 demo。所有 baseline 同样 40k step finetune。
Table 2 (摘录). RoboTwin 2.0 average success rate (%).
| X-VLA | w/o Pretrain | Stage1 only | Motus | ||
|---|---|---|---|---|---|
| Clean | 42.98 | 72.80 | 72.8 | 82.86 | 88.66 |
| Rand. | 43.84 | 72.84 | 77.00 | 81.86 | 87.02 |
关键观察:
- Stage 1 (只训 VGM) 已经把 w/o-pretrain 推上 5 个点,说明 VGM 学到的 visual dynamics 对 action 也有帮助
- Stage 2 (加 latent action 预训) 又推上 5 个点
- 在 X-VLA 完全失败的 task(如 Stack Blocks Three: 10% → 95%、Pick Diverse Bottles: 36% → 91%)上 Motus 收益最大——暗示这些任务更需要 motion prior 而非 visual reasoning
Real-World:AC-One + Agilex-Aloha-2
每 task 100 trajectories,用 partial success rate(按 subgoal 加权打分)。
Table 3. Real-World Partial Success Rate (%).
| Task | w/o Pretrain | Motus | |
|---|---|---|---|
| AC-One avg | 14.79 | 25.86 | 63.22 |
| Brew Coffee using Drip Machine | 0 | 0 | 62 |
| Grind Coffee Beans | 8 | 0 | 92 |
| Pour Water from Kettle | 5 | 5 | 65 |
| Place Cube into Plate (OOD) | 28.1 | 18.8 | 75 |
| Agilex-Aloha-2 avg | 48.60 | 26.60 | 59.30 |
| Get Water from Dispenser | 62 | 8 | 96 |
Figure 5. Task definitions and visualizations.

Video 1. Brew coffee using drip coffee machine, AC-One. 这是表里 0% → 62% 的长任务。
Video 2. Grind coffee beans with grinder, AC-One. 8% → 92% 的最大跃升 task。
Video 3. Fold pink lettered towel, AC-One. Deformable object manipulation.
❓ AC-One 的 from-scratch baseline (25.86%) 反而比 π0.5 (14.79%) 好,提示 Motus 的架构本身(即使没 Stage 1/2 预训)就已经比 π0.5 强;这个对比稍微稀释了”预训贡献”的解读。
五种 mode 都跑得通
Table 6. Motus 在 World Model mode 下的视频生成质量(real-world robot data).
| Platform | FID ↓ | FVD ↓ | SSIM ↑ | LPIPS ↓ | PSNR ↑ |
|---|---|---|---|---|---|
| Agilex-Aloha-2 | 9.46 | 49.28 | 0.886 | 0.054 | 26.10 |
| AC-One | 12.96 | 73.13 | 0.846 | 0.073 | 24.04 |
Table 7. IDM Action MSE on RoboTwin 2.0 randomized.
| ResNet18+MLP | DINOv2+MLP | Motus (IDM mode) |
|---|---|---|
| 0.044 | 0.122 | 0.014 |
Table 8. VLA mode vs Joint mode on RoboTwin 2.0 randomized.
| Motus (VLA mode) | Motus (Joint mode) |
|---|---|
| 83.90 | 87.02 |
即使 VLA mode 也已经 beat 了所有外部 baseline——说明大部分增益来自架构 + 预训而非 joint inference 本身。joint mode 多带来的 +3 点是 video 协同推理的边际收益。
LIBERO-Long
Table 9. LIBERO-Long avg success.
| GR00T-N1 | UniVLA | OpenVLA-OFT | X-VLA | Motus | |
|---|---|---|---|---|---|
| 85.2 | 90.6 | 94.0 | 94.5 | 97.6 | 97.6 |
LIBERO-Long 已经接近上限,Motus 与 X-VLA 持平。
Ablation
Figure 6. RoboTwin 2.0 randomized 多任务 ablation.
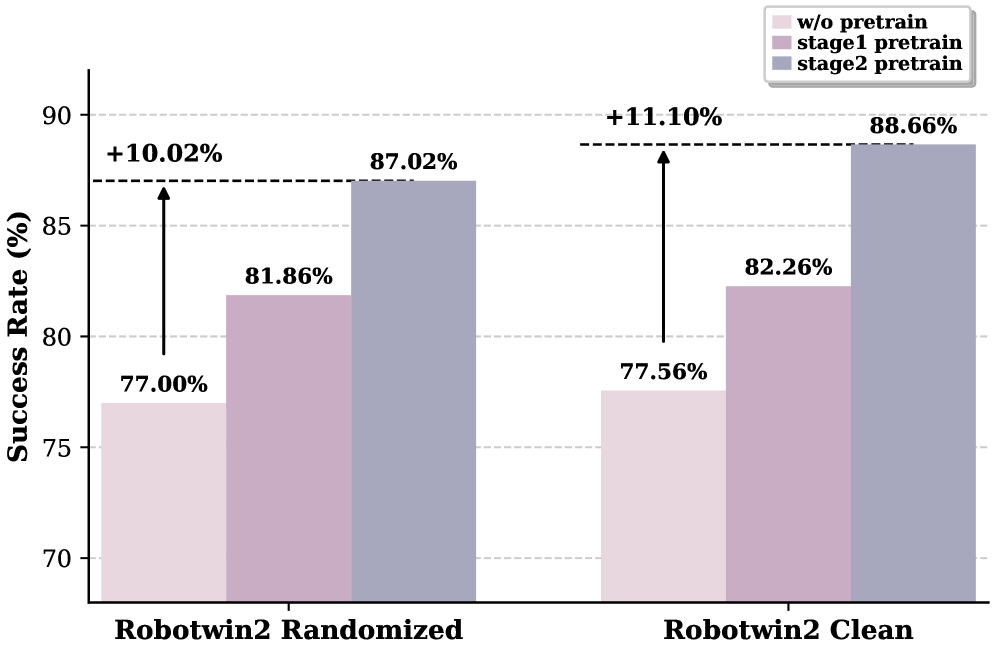
w/o Pretrain (77%) → Stage 1 only (82%) → Motus full (87%)。每个阶段都有几个点贡献。
Architecture hyperparameters
Table 11 (摘录).
| Component | Value |
|---|---|
| Action Expert | hidden 1024, 30 layers, 24 heads |
| Understand Expert | hidden 512, 30 layers, 24 heads |
| Sampling | Video 8 frames @ 5Hz, Action chunk 48 @ 30Hz |
| Flow Matching | 10 inference steps, Logit Normal sampling |
| (action align) | 1.0 |
| (KL) |
关联工作
基于
- Wan 2.2 5B: 视频生成 backbone,提供 physical interaction prior
- Qwen3-VL-2B: 视觉理解 backbone,提供 spatial / 3D grounding 能力
- DC-AE: deep compression autoencoder for optical flow latent
- DPFlow: optical flow estimator
- rectified flow / flow matching: action 和 video 的统一生成 objective
- AnyPos: task-agnostic action data 收集,做 latent ↔ real action 对齐
对比
- π0 / π0.5: VLA 主基线,real-world 主 baseline
- X-VLA: VLA 强基线,sim 主要 SOTA 对手
- GR00T-N1: VLA baseline on LIBERO-Long
- OpenVLA / OpenVLA-OFT: VLA baseline
- UWM: 最直接对比的 unified work,Motus 的关键 delta = MoT + 引入 pretrained VLM/VGM
- F1: VLA + IDM 拼接,Motus 进一步覆盖 WM/VGM
- ResNet18+MLP / DINOv2+MLP: Tab. 7 IDM 对比 baseline
方法相关
- Bagel (deng2025): 用 MoT 在 understanding + generation expert 间共享 self-attention,Motus 的 Tri-modal Joint Attention 直接借鉴
- UniDiffuser: 多 timestep diffusion 调度,Motus 借此切五种推理 mode
- Latent action 类: LAPA / LAPO / Moto / Genie / AdaWorld / UniVLA / LAOM —— Motus 用 optical flow 而非 RGB / DINOv2 feature 作为重建目标
- Action chunking (ACT): Motus 用 chunk size 48 @ 30Hz 沿用此范式
论文点评
Strengths
- 覆盖完整的 5-mode 统一:是当前少数同时把 VLA / WM / IDM / VGM / Joint 五种 paradigm 都做出来并定量评估的工作;UWM 同方向但缺 pretrained prior,F1 缺 WM/VGM 的 generation
- MoT + Tri-modal Joint Attention 是合理的妥协:保留 pretrained expert 各自能力(不会被互相 overwrite),又允许跨模态信息流;比”拼 token 走单 backbone”更尊重 pretrained 知识结构
- Optical flow latent action 作为跨 embodiment 桥梁:14 维投影 + 弱 action 监督把 latent space 锚到真实控制分布,让 action expert 能从 internet/egocentric video 预训练——这在原则上比 LAPA / DINOv2-feature 类方法更接”motion 物理本质”
- Real-world 提升幅度可观且任务非 trivial:长任务 partial success rate 从 0/14% 跳到 60%+,且涵盖 deformable / fluid / long-horizon——不是常见的 pick-and-place 注水
- 架构 + 预训 + 数据三条 ablation 都有数据:Stage 1 / Stage 2 / w/o pretrain 完整对比
Weaknesses
- 几乎全部实验绑死 Aloha-like 双臂 14-DoF:sim (RoboTwin Aloha) + real (AC-One Aloha + Agilex-Aloha-2) 都是同一类 embodiment。“cross-embodiment latent action” 的卖点在评测里几乎没体现——预训用了 Egodex / Franka / Genie-1 但下游评测全是 Aloha。真正的跨形态迁移(Aloha 预训 → Franka SFT、或 humanoid)没做
- Latent action 14 维的设计选择太硬编码:贴 Aloha 维度的同时也可能成为换平台时的瓶颈,没消融”维度 ↔ 性能”
- Architecture novelty vs UWM 偏增量:MoT + UniDiffuser scheduler 的组合 idea 上是 UWM + Bagel 的合并,主要 delta 在工程实现 + scale 而非理论
- 对算力门槛沉默:18000 GPU-hour 量级(Stage 1+2),Stage 3 也要 400 hour——对学术界基本不可复现;论文没讨论 minimum viable training budget
- “+45% over π0.5”的对比有水分:π0.5 在 RoboTwin 2.0 randomized 上只有 43.84%,远低于其在原论文中的报告,怀疑 π0.5 baseline 没充分调优;w/o-pretrain 都比 π0.5 高 33 个点这件事本身可疑
- Latent action 的可解释性 / 失败模式没分析:14 维 latent 在 unseen motion 上的泛化、以及当 latent action 与真 action 对不齐时会怎样,没 case study
- VGM 作为 world model 的指标只有 FID/FVD/SSIM:没测 action-conditioned counterfactual 的物理一致性(如给定不同 action 是否生成不同 future)——这是 world model 的核心 utility 但没单独评
可信评估
Artifact 可获取性
- 代码: inference + training(GitHub README 列出 Installation / Running Inference / Training,Apache-2.0 license)
- 模型权重: motus-robotics 在 HuggingFace 发布(https://huggingface.co/motus-robotics 及 motus-robotics/Motus),具体 checkpoint 名称在 README 的 “Model Checkpoints” 部分列出
- 训练细节: 较完整——三个 stage 的 batch size / lr / optimizer / weight decay / GPU hours 都给(Tab. 13),架构超参(Tab. 11)也全;但 lr schedule / warmup / loss weighting 没说
- 数据集: 大部分公开(Egodex / AgiBot / RDT / RoboMind / RoboTwin 都是开源数据集,Tab. 12 给了引用),但 in-house 2K target-robot 数据私有,task-agnostic 数据未明确开源状态
Claim 可验证性
- ✅ RoboTwin 2.0 +43% over π0.5 / +14% over X-VLA:Tab. 2 / Tab. 14 50-task 完整结果可查,code + checkpoint 公开可复现
- ✅ 五种 inference mode 可切换:Sec. 7 给了所有 6 个算法的伪代码,每个 mode 有定量或定性结果(Tab. 6/7/8 + Fig 7-12)
- ✅ LIBERO-Long 97.6:标准 benchmark,与 X-VLA 并列 SOTA
- ✅ IDM mode 0.014 MSE 超过 ResNet18+MLP / DINOv2+MLP baseline:但 baseline 比较弱,未对比 UWM 等 unified model 的 IDM mode
- ⚠️ “+11~48% real-world improvement over π0.5”:partial success rate 是论文自定义的加权指标(subgoal 0.2/0.4/…),主观性强;某些 task 的”提升”伴随 OOD 性能下降(Agilex-Aloha-2 上 Grab Cube OOD 反而 Motus 31.25% < π0.5 68.75%,论文表里没强调)
- ⚠️ “learn cross-embodiment transferable motion knowledge”:所有下游评估都是 Aloha 类双臂,跨 embodiment 的迁移没有直接验证;“latent action 学到的 motion prior 帮助下游”被 Stage 2 ablation 间接支持但因为预训和下游都用 Aloha,无法分离”motion prior” vs “Aloha-specific data 增量”
- ⚠️ VGM mode 的 world model 价值:FID/FVD/SSIM 指标只衡量视觉质量,不衡量 action-conditioned counterfactual 准确性,无法单独支持 “world model 提供物理 prior” 这一 claim
- ❌ “all functionalities and priors significantly benefits downstream robotic tasks”:5 种 mode 切换的 utility 没在下游任务中分别评——除了 VLA / Joint 在 RoboTwin 上的对比(仅 +3 点),其他 mode(WM、VGM、IDM)能否真的”用于”具体下游 benefit 没有 case study
Notes
- “用 optical flow 当跨 embodiment 通用 motion 表征” 的赌注 strong——这个假设的边界在哪?例如 dexterous in-hand manipulation 中接触面 occluded 时 optical flow 估计不可靠,latent action 还能用吗?想看一组在 contact-rich / occluded 任务上的失败分析
- MoT 共享 attention 但分离 FFN 是个值得跟的设计 pattern——和 UWM 单 backbone vs Motus 三 expert 的 head-to-head ablation 会很有说服力(论文里只对比了 RoboTwin success rate,没控制其他变量)
- “Joint mode 比 VLA mode 只 +3 点”这件事其实削弱了”unify 是关键”的叙事——如果 VLA mode 单独就接近最优,那么把 5 种 mode 都做出来的工程价值是否值得 2 万 GPU-hour?或许真正的价值在于”5 种 mode 共享同一组参数减少部署复杂度”,而非”5 种 mode 协同推理”
- 对自己 idea 的启发:latent action via optical flow + 弱监督对齐到真实 action 空间这一招,对我做”VLA 在 robot 数据稀缺设定下的预训练”是直接可借鉴的——核心机制是用大量 unlabeled video 学 motion 先验,少量 label 把 latent 锚到控制空间
- 后续值得追:Stage 2 latent action 预训如果换成 Genie / Moto / LAPA 风格的 latent,性能差多少?optical flow 真的是更好的 representation 吗?
Rating
Metrics (as of 2026-04-24): citation=32, influential=6 (18.8%), velocity=7.44/mo; HF upvotes=0; github 995⭐ / forks=48 / 90d commits=0 / pushed 108d ago
分数:2 - Frontier 理由:按 Strengths 所述,Motus 是目前少数把 VLA/WM/IDM/VGM/Joint 五种 paradigm 同一模型同一组参数跑通并给出完整定量评估的工作,真实机器人长任务(coffee / grinder / towel folding)从个位数跃升到 60%+ 的幅度与 LIBERO-Long 97.6 持平 X-VLA SOTA,使其作为当前 unified VLA+WM 方向的 must-compare baseline 当之无愧;但 Weaknesses 指出架构 novelty 相对 UWM + Bagel 偏合并、18000 GPU-hour 门槛远超学术可复现范围、且”cross-embodiment”卖点下游评测全是 Aloha 未被直接验证——这些阻止了它跨入 3 - Foundation 的”方向必读奠基”档,属于需要跟进引用但尚未经过时间检验定型的前沿工作。2026-04 复核:4.3 月 32 citation / 6 influential (18.8%,远高于典型 ~10%,说明方法被实质继承) / velocity 7.44/mo / github 995⭐ 表明早期采纳活跃;但近 90 天 0 commit、HF=0 且”cross-embodiment” claim 仍未在 non-Aloha 下游验证,升级到 Foundation 的证据尚不足,维持 Frontier。